Doing well with less! On Sampling Techniques for Empirical Pairwise Loss Estimation/Minimization
Pith reviewed 2026-06-28 12:32 UTC · model grok-4.3
The pith
Direct sampling of pairs rather than observations allows near-full pairwise loss performance with far fewer pairs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A frugal approach that retains only a fraction of the available information on pairs can achieve estimation or optimization performance comparable to that obtained by using all pairs, by leveraging survey sampling techniques. Such sampling plans must target pairs directly rather than individual observations. Assigning higher inclusion probabilities to informative pairs using suitable auxiliary information yields performance close to full pairwise evaluation for losses between high-dimensional vectors such as embeddings.
What carries the argument
Survey sampling plans that assign inclusion probabilities directly to pairs using auxiliary information to prioritize informative pairs.
If this is right
- Performance remains close to full pairwise evaluation when pairs are sampled directly with auxiliary guidance.
- A principled accuracy-computation trade-off becomes available for pairwise losses at scale.
- The same sampling logic applies to embeddings in vision and graph learning tasks.
- Sampling individual observations is provably less effective than direct pair sampling for these losses.
Where Pith is reading between the lines
- The method could be tested by varying the quality of auxiliary information to measure how much guidance is actually required.
- Integration with online or streaming settings might allow the sampling probabilities to adapt as new data arrives.
- Memory savings from storing only sampled pairs could extend the approach to datasets too large to hold in full.
- Similar pair-targeting ideas might apply to higher-order losses involving triples or larger tuples.
Load-bearing premise
Suitable auxiliary information exists that can guide pair sampling without introducing unacceptable bias or extra computational overhead.
What would settle it
An experiment on high-dimensional embedding losses in which uniform random sampling of pairs performs as well as auxiliary-guided pair sampling would falsify the need for targeted direct-pair plans.
Figures
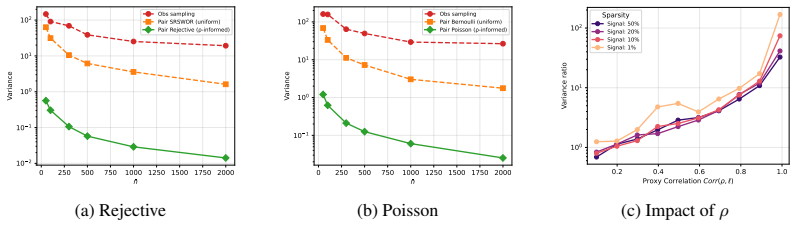
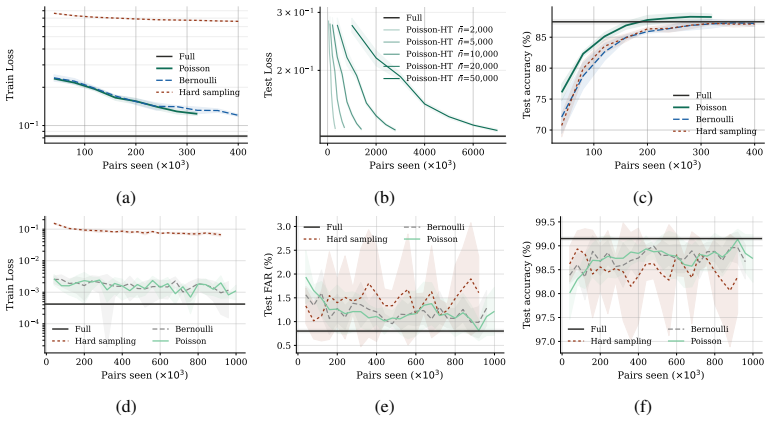
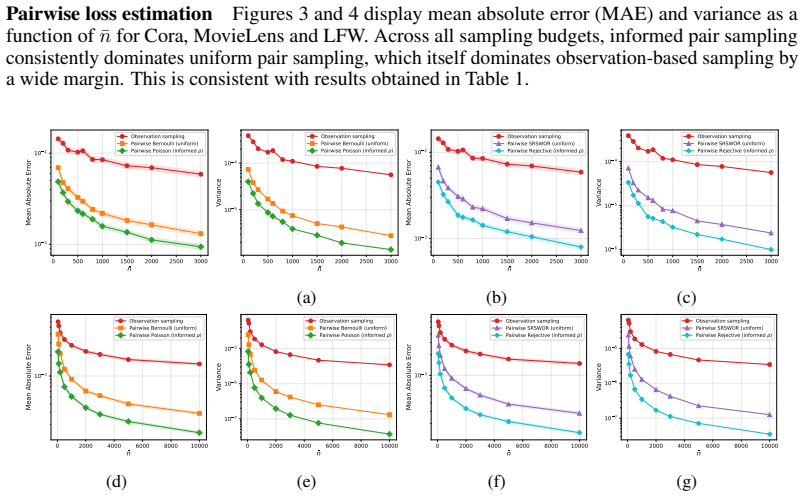
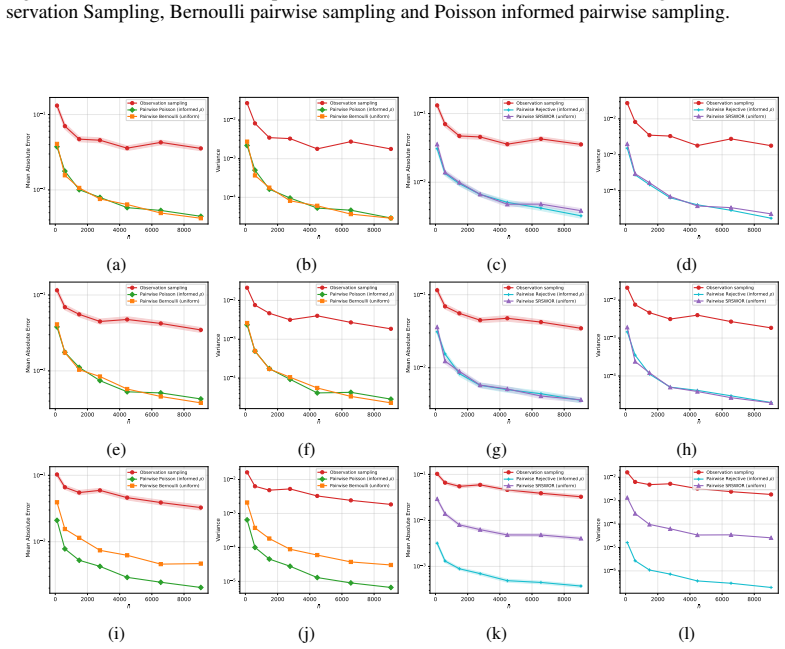
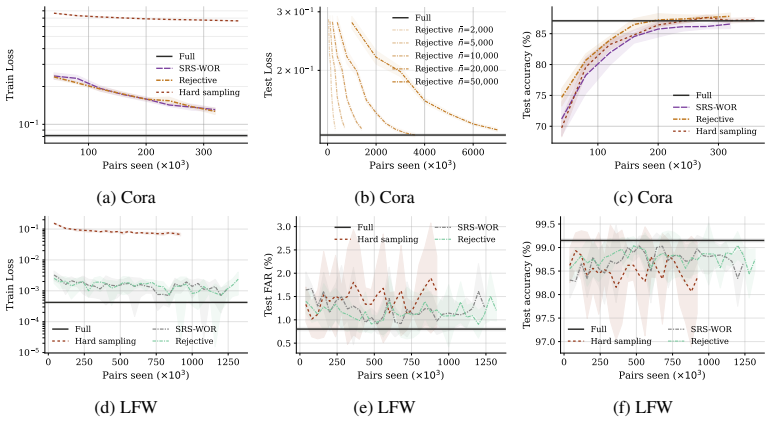
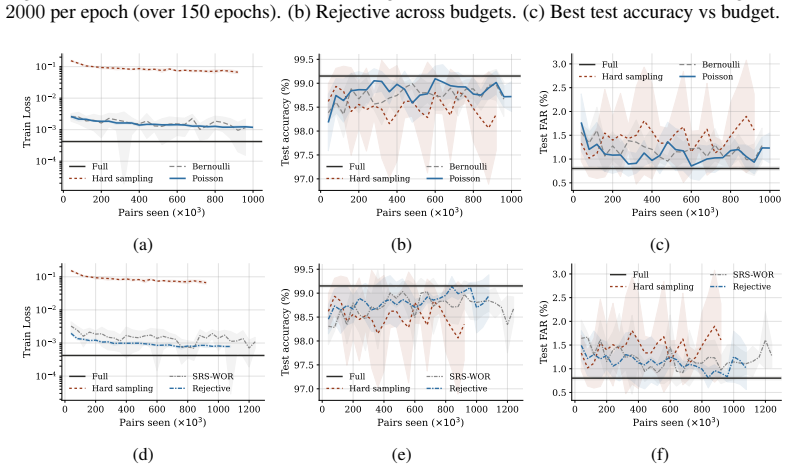
read the original abstract
Many machine learning problems, including similarity learning, ranking, and clustering, rely on empirical pairwise loss functions whose quadratic computational cost quickly becomes prohibitive at scale. We demonstrate how a frugal approach that retains only a fraction of the available information on pairs can achieve estimation or optimization performance comparable to that obtained by using all pairs, by leveraging survey sampling techniques. A central finding, supported by both theory and experiments, is that such sampling plans must target pairs directly rather than individual observations. In particular, for pairwise losses between high-dimensional vectors such as embeddings in vision or graph learning, assigning higher inclusion probabilities to informative pairs using suitable auxiliary information yields performance close to full pairwise evaluation, providing a principled and theoretically grounded trade-off between accuracy and computational cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes applying survey sampling techniques to estimate or minimize empirical pairwise loss functions at scale. It claims that sampling plans must target pairs directly (rather than observations), and that using auxiliary information to assign higher inclusion probabilities to informative pairs yields performance close to full pairwise evaluation, with supporting theory and experiments for high-dimensional embedding tasks in vision and graph learning.
Significance. If the central claims hold, the work supplies a principled, sampling-theory-grounded method for reducing the quadratic cost of pairwise losses while preserving accuracy. Explicit credit is due for grounding the approach in external survey sampling results rather than ad-hoc heuristics and for the empirical demonstration that pair-targeted unequal-probability sampling outperforms observation-level sampling.
major comments (2)
- [Abstract and §1] The load-bearing assumption that suitable auxiliary information exists which is both cheap to compute and strongly correlated with pair informativeness is stated in the abstract and §1 but is not accompanied by a concrete cost analysis or bias bound that would confirm the auxiliary itself does not approach the cost of full pairwise evaluation. Without this, the claimed accuracy-cost trade-off cannot be verified.
- [Theory section (presumed §3)] The manuscript asserts that the Horvitz-Thompson or similar weighting corrects for the unequal inclusion probabilities induced by the auxiliary; however, no explicit statement appears on whether the auxiliary is required to be independent of the target loss or how dependence would affect unbiasedness of the estimator.
minor comments (2)
- Notation for inclusion probabilities and auxiliary variables should be introduced with a single consistent table or list of symbols.
- [Experiments] The experimental section would benefit from an explicit statement of the computational cost metric used to compare sampling plans against the full-pair baseline.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's significance. We address each major comment below and will incorporate clarifications and additions in a revised manuscript.
read point-by-point responses
-
Referee: [Abstract and §1] The load-bearing assumption that suitable auxiliary information exists which is both cheap to compute and strongly correlated with pair informativeness is stated in the abstract and §1 but is not accompanied by a concrete cost analysis or bias bound that would confirm the auxiliary itself does not approach the cost of full pairwise evaluation. Without this, the claimed accuracy-cost trade-off cannot be verified.
Authors: We agree that an explicit cost analysis would strengthen the claims. In the revised manuscript we will add a dedicated paragraph (likely in §1 or a new subsection) noting that typical auxiliaries such as embedding norms or node degrees are computable in linear O(n) time, which is negligible relative to quadratic pairwise evaluation. On bias, the Horvitz-Thompson estimator remains design-unbiased irrespective of auxiliary quality; any performance gap is variance-driven. We will include a short analytic remark linking variance reduction to the correlation between auxiliary and loss, referencing the existing experiments. revision: yes
-
Referee: [Theory section (presumed §3)] The manuscript asserts that the Horvitz-Thompson or similar weighting corrects for the unequal inclusion probabilities induced by the auxiliary; however, no explicit statement appears on whether the auxiliary is required to be independent of the target loss or how dependence would affect unbiasedness of the estimator.
Authors: The Horvitz-Thompson estimator is unbiased under the sampling design alone, provided inclusion probabilities are known and positive; this holds irrespective of any dependence between the auxiliary (used only to set the design) and the target pairwise loss. Dependence influences variance but not unbiasedness—a standard result in survey sampling. We will insert an explicit clarifying sentence in the theory section of the revision to prevent misinterpretation. revision: yes
Circularity Check
No circularity; derivation relies on external survey sampling theory
full rationale
The paper applies established survey sampling methods (e.g., unequal-probability sampling of pairs with Horvitz-Thompson-style estimators) to pairwise loss estimation. The central claim that pair-targeted sampling with auxiliary information outperforms observation-targeted sampling is presented as a consequence of sampling theory rather than a self-referential fit or definition. No load-bearing step reduces by construction to the paper's own inputs, fitted parameters, or self-citations; the auxiliary-information assumption is stated explicitly and does not derive the performance result. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard survey sampling theory (inclusion probabilities, unbiased estimation) applies directly to empirical pairwise loss functions.
Reference graph
Works this paper leans on
-
[1]
Maillard
R Bardenet and O.A. Maillard. Concentration inequalities for sampling without replacement. Bernoulli, 21(3):1361–1385, 2015
2015
-
[2]
Bellet, A
A. Bellet, A. Habrard, and M. Sebban.Metric Learning. Synthesis Lectures on Artificial Intelli- gence and Machine Learning. Morgan & Claypool Publishers, 2015. ISBN 9781627053662. URLhttps://books.google.fr/books?id=SvzRBgAAQBAJ
2015
-
[3]
Bertail, S
P. Bertail, S. Clémençon, Y . Guyonvarch, and N. Noiry. Learning from biased data: A semi- parametric approach. In Marina Meila and Tong Zhang, editors,Proceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learn- ing Research, pages 803–812. PMLR, 18–24 Jul 2021. URL https://proceedings.mlr. press/v139/b...
2021
-
[4]
Boistard, H.P
H. Boistard, H.P. Lopuhaâ, and A. Ruiz-Gazen. Approximation of rejective sampling inclusion probabilities and application to high order correlations.Electron. J. Statist., 6:1967–1983, 2012
1967
-
[5]
Scandinavian Journal of Statistics , number =
P. Brändén and J. Jonasson. Negative dependence in sampling.Scandinavian Journal of Statis- tics, 39(4):830–838, 2012. doi: https://doi.org/10.1111/j.1467-9469.2011.00766.x. URL https: //onlinelibrary.wiley.com/doi/abs/10.1111/j.1467-9469.2011.00766.x
-
[6]
M. T. Chao. A general purpose unequal probability sampling plan.Biometrika, 69(3):653–656,
-
[7]
URLhttp://www.jstor.org/stable/2336002
ISSN 00063444, 14643510. URLhttp://www.jstor.org/stable/2336002
-
[8]
G. Chauvet and M. Gerber. Exponential inequalities for sampling designs.Statistics & Probabil- ity Letters, 232:110654, 2026. ISSN 0167-7152. doi: https://doi.org/10.1016/j.spl.2026.110654. URLhttps://www.sciencedirect.com/science/article/pii/S0167715226000180
-
[9]
T. Chen, S. Kornblith, M. Norouzi, and G.E. Hinton. A simple framework for contrastive learn- ing of visual representations.CoRR, abs/2002.05709, 2020. URL https://arxiv.org/abs/ 2002.05709
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[10]
Clémençon, G
S. Clémençon, G. Lugosi, and N. Vayatis. Ranking and empirical risk minimization of U- statistics.The Annals of Statistics, 36(2):844–874, 2008
2008
-
[11]
Clémençon, P
S. Clémençon, P. Bertail, and G. Papa. Learning from Survey Training Samples: Rate Bounds for Horvitz-Thompson Risk Minimizers. In Robert J. Durrant and Kee-Eung Kim, editors,Pro- ceedings of The 8th Asian Conference on Machine Learning, volume 63 ofProceedings of Machine Learning Research, pages 142–157. PMLR, 2016
2016
-
[12]
S. Clémençon, P. Bertail, and E. Chautru. Sampling and Empirical Risk Minimization.Statis- tics, 51(1):30–42, 2017. doi: 10.1080/02331888.2016.1259810. URL https://doi.org/10. 1080/02331888.2016.1259810
-
[13]
S. Clémençon, P. Bertail, E. Chautru, and G. Papa. Optimal survey schemes for stochastic gradient descent with applications to M-estimation.ESAIM: PS, 23:310–337, 2019. doi: 10.1051/ps/2018021
-
[14]
Clémençon, I
S. Clémençon, I. Colin, and A. Bellet. Scaling-up empirical risk minimization: Optimization of incomplete u-statistics.Journal of Machine Learning Research, 17(76):1–36, 2016. URL http://jmlr.org/papers/v17/15-012.html
2016
-
[15]
de la Pena and E
V . de la Pena and E. Giné.Decoupling: from Dependence to Independence. Springer, 1999
1999
-
[16]
Dupacova
J. Dupacova. A note on rejective sampling.Contribution to Statistics (J. Hajek memorial volume) Academia Prague, pages 71–78, 1979
1979
-
[17]
Fey and J.E
M. Fey and J.E. Lenssen. Fast graph representation learning with PyTorch Geometric. InICLR Workshop on Representation Learning on Graphs and Manifolds, 2019
2019
-
[18]
R. Hadsell, S. Chopra, and Y . LeCun. Dimensionality reduction by learning an invariant map- ping. In2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), volume 2, pages 1735–1742, 2006. doi: 10.1109/CVPR.2006.100
-
[19]
J. Hajek. Asymptotic theory of rejective sampling with varying probabilities from a finite population.The Annals of Mathematical Statistics, 35(4):1491–1523, 1964
1964
-
[20]
Harper and J.A
F.M. Harper and J.A. Konstan. The MovieLens datasets: History and context.ACM Transactions on Interactive Intelligent Systems, 2015. 10
2015
-
[21]
Hartley and J.N.K
H.O. Hartley and J.N.K. Rao. Sampling with unequal probabilities and without replacement. Ann. Math. Statist., 33:350–374, 1962
1962
-
[22]
Hoeffding
W. Hoeffding. Probability inequalities for sums of bounded random variables.J. Amer. Statist. Assoc., 58:13–30, 1963
1963
-
[23]
Horvitz and D.J
D.G. Horvitz and D.J. Thompson. A generalization of sampling without replacement from a finite universe.JASA, 47:663–685, 1951
1951
-
[24]
Houdré and P
C. Houdré and P. Reynaud-Bouret. Exponential inequalities, with constants, for u-statistics of order two. In E. Giné, C. Houdré, and D. Nualart, editors,Stochastic Inequalities and Applications, pages 55–69, Basel, 2003. Birkhäuser Basel. ISBN 978-3-0348-8069-5
2003
-
[25]
Huang, M
G. Huang, M. Mattar, T. Berg, and E. Learned-Miller. Labeled faces in the wild: A database for studying face recognition in unconstrained environments.Tech. rep., 10 2008
2008
-
[26]
Joag-Dev and F
K. Joag-Dev and F. Proschan. Negative association of random variables with applications.The Annals of Statistics, pages 286–295, 1983
1983
-
[27]
Katharopoulos and F
A. Katharopoulos and F. Fleuret. Not all samples are created equal: Deep learning with impor- tance sampling. InInternational Conference on Machine Learning, pages 2525–2534. PMLR, 2018
2018
-
[28]
Kipf and M
T.N. Kipf and M. Welling. Semi-supervised classification with graph convolutional networks. InInternational Conference on Learning Representations, 2017
2017
-
[29]
Knuth et al.The art of computer programming, volume 3
D.E. Knuth et al.The art of computer programming, volume 3. Addison-Wesley Reading, MA, 1973
1973
-
[30]
Kumar, A.C
N. Kumar, A.C. Berg, P.N. Belhumeur, and S.K. Nayar. Attribute and simile classifiers for face verification. In2009 IEEE 12th International Conference on Computer Vision, pages 365–372,
-
[31]
doi: 10.1109/ICCV .2009.5459250
-
[32]
Lee.U-statistics: Theory and practice
A.J. Lee.U-statistics: Theory and practice. Marcel Dekker, Inc., New York, 1990
1990
-
[33]
K. Musgrave, S. Belongie, and S.N. Lim. A metric learning reality check. InComputer Vision – ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXV, page 681–699, Berlin, Heidelberg, 2020. Springer-Verlag. ISBN 978-3-030-58594-5. doi: 10.1007/978-3-030-58595-2_41. URL https://doi.org/10.1007/978-3-030-58595-2_ 41
-
[34]
E. Ohlsson. Sequential poisson sampling.Journal of Official Statistics, 14(2):149, 1998
1998
- [35]
-
[36]
J. Robinson, C.Y . Chuang, S. Sra, and S. Jegelka. Contrastive learning with hard negative samples.CoRR, abs/2010.04592, 2020. URLhttps://arxiv.org/abs/2010.04592
-
[37]
M. R. Sampford. On sampling without replacement with unequal probabilities of selection. Biometrika, 54:499–513, 1967
1967
-
[38]
Schroff, D
F. Schroff, D. Kalenichenko, and J. Philbin. Facenet: A unified embedding for face recogni- tion and clustering. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 815–823, 2015
2015
-
[39]
Tillé.Sampling algorithms
Y . Tillé.Sampling algorithms. Springer Series in Statistics, 2006
2006
-
[40]
J.S. Vitter. Random sampling with a reservoir.ACM Transactions on Mathematical Software (TOMS), 11(1):37–57, 1985
1985
-
[41]
C.Y . Wu, R. Manmatha, A.J. Smola, and P. Krähenbühl. Sampling matters in deep embedding learning, 2018. URLhttps://arxiv.org/abs/1706.07567
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[42]
Z. Yang, W. Cohen, and R. Salakhutdinov. Revisiting semi-supervised learning with graph embeddings. InInternational Conference on Machine Learning, 2016
2016
-
[43]
Yates and P.M
F. Yates and P.M. Grundy. Selection without replacement from within strata with probability proportional to size.Journal of the Royal Statistical Society: Series B (Methodological), 15(2): 253–261, 1953. 11
1953
-
[44]
J. Zbontar, L. Jing, I. Misra, Y . LeCun, and S. Deny. Barlow twins: Self-supervised learning via redundancy reduction.CoRR, abs/2103.03230, 2021. URL https://arxiv.org/abs/2103. 03230
-
[45]
Zhao and T
P. Zhao and T. Zhang. Stochastic optimization with importance sampling for regularized loss minimization. Ininternational Conference on Machine Learning, pages 1–9. PMLR, 2015
2015
-
[46]
S. Zhou, Y . Lei, and A. Kabán. Randomized pairwise learning with adaptive sampling: A pac- bayes analysis, 2025. URLhttps://arxiv.org/abs/2504.02957. 12 Organisation of the appendix The appendix is organised as follows. • Appendix A gathers additional information regarding notations and survey schemes. • Appendix B presents the proofs of the paper. • App...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.