COCOLogic-V2: Identifying Logical Inconsistencies via Truly Hard-Negatives
Pith reviewed 2026-06-29 04:28 UTC · model grok-4.3
The pith
COCOLogic-V2 shows models distinguish far negatives but fail on near-boundary logical violations in real images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
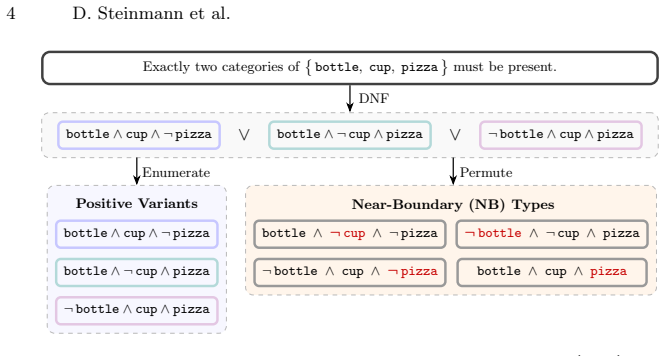
COCOLogic-V2 categorizes samples into positives, near-boundary negatives, and far-from-boundary negatives so that models which separate positives from far negatives but collapse on near-boundary negatives have not internalized the logical rules.
What carries the argument
The near-boundary versus far-from-boundary negative split, which supplies a fine-grained test of whether models have captured the logical rules rather than surface patterns.
If this is right
- Models that succeed on far-from-boundary negatives but fail on near-boundary negatives have not captured the target logical rules.
- Perceptual noise and large rule-induced search spaces create additional failure modes in few-shot visual reasoning.
- Interpretability techniques such as concept bottleneck models require stronger tests on near-boundary cases to verify rule adherence.
Where Pith is reading between the lines
- The same boundary-based negative construction could diagnose rule understanding in other modalities such as text or audio.
- Training objectives that explicitly penalize near-boundary errors might close the observed gap.
- Scaling the dataset to more complex rules would test whether the current failure pattern persists at higher logical depth.
Load-bearing premise
That the near-boundary versus far-from-boundary split of negatives gives a reliable signal of whether a model has understood the logical rules instead of relying on superficial cues.
What would settle it
A model achieving high accuracy on near-boundary negatives while preserving accuracy on positives and far negatives would falsify the diagnosis that current models fail to understand the rules.
Figures


read the original abstract
While interpretable models such as concept bottleneck models (CBMs) and program synthesis methods enable verification of model decisions, their evaluation is typically limited to simple tasks, leaving complex reasoning on real-world images largely unexplored. We introduce COCOLogic-V2, an object-centric dataset for visual inductive reasoning on real-world images covering a broad subset of first-order logic. By categorizing samples into positive variants, near-boundary (NB), and far-from-boundary (FB) negatives, COCOLogic-V2 enables fine-grained diagnosis of model accountability. Our evaluations show that models tend to separate positive and FB samples well but fail on NB samples, while perceptual noise and large rule-induced search spaces pose additional challenges in few-shot settings. Together, these results highlight that visual inductive reasoning remains an open challenge and COCOLogic-V2 provides a concrete foundation for advancing methods in this direction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
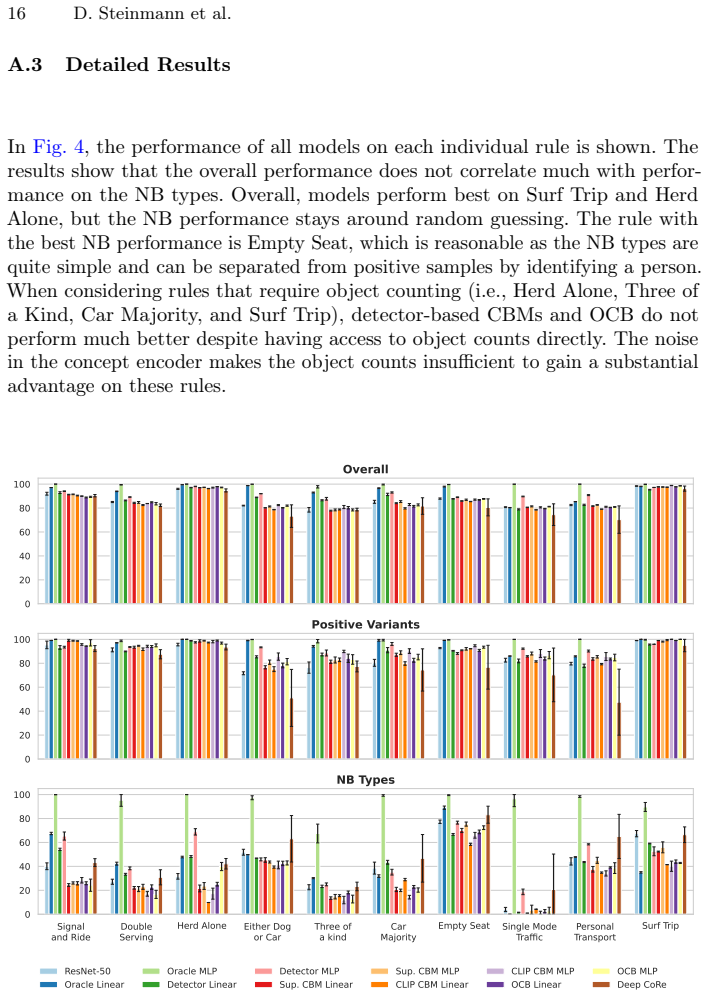
Summary. The manuscript introduces COCOLogic-V2, an object-centric dataset for visual inductive reasoning on real-world images that covers a broad subset of first-order logic. Samples are categorized into positive variants, near-boundary (NB) negatives, and far-from-boundary (FB) negatives to support fine-grained diagnosis of whether models have learned the underlying logical rules. The authors report that models separate positives and FB samples well but fail on NB samples, and that perceptual noise plus large rule-induced search spaces create additional difficulties in few-shot regimes. The work positions the dataset as a foundation for advancing methods in visual inductive reasoning.
Significance. If the NB/FB split can be shown to isolate logical rule understanding from correlated perceptual or statistical cues, the dataset would provide a useful benchmark for evaluating accountability in vision models on complex real-world reasoning tasks, extending beyond the simple tasks typically used for CBMs and program synthesis. The emphasis on truly hard negatives addresses a recognized gap in current evaluation practices.
major comments (2)
- [Abstract] Abstract: the claim that 'models tend to separate positive and FB samples well but fail on NB samples' is asserted without any quantitative results, error bars, dataset statistics, model descriptions, or evaluation protocols. This renders the central empirical claim unverifiable from the provided text and undermines the fine-grained diagnosis argument.
- [Abstract] Abstract: the NB/FB boundary is presented as supplying a reliable diagnosis of logical rule understanding, yet the text does not establish that the boundary construction controls for perceptual statistics, object co-occurrence, or search-space size (factors explicitly listed as separate challenges). Without such controls or a concrete test (e.g., ablation on cue-matched controls), the split risks confounding logical proximity with non-logical cues.
minor comments (1)
- [Abstract] The abstract refers to 'a broad subset of first-order logic' without specifying which fragment or providing an enumeration of the covered predicates and quantifiers.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback on the abstract. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of results and controls.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'models tend to separate positive and FB samples well but fail on NB samples' is asserted without any quantitative results, error bars, dataset statistics, model descriptions, or evaluation protocols. This renders the central empirical claim unverifiable from the provided text and undermines the fine-grained diagnosis argument.
Authors: We agree that the abstract, as a high-level summary, should include concrete quantitative support to make the central claim verifiable on its own. The detailed results (including accuracies, error bars, dataset statistics, model descriptions, and protocols) appear in Section 4 and the appendix, but we will revise the abstract to incorporate key quantitative highlights such as separation metrics between positive/FB and NB samples. revision: yes
-
Referee: [Abstract] Abstract: the NB/FB boundary is presented as supplying a reliable diagnosis of logical rule understanding, yet the text does not establish that the boundary construction controls for perceptual statistics, object co-occurrence, or search-space size (factors explicitly listed as separate challenges). Without such controls or a concrete test (e.g., ablation on cue-matched controls), the split risks confounding logical proximity with non-logical cues.
Authors: Section 3 of the manuscript details the NB/FB construction process, with NB negatives generated via minimal logical perturbations that preserve visual content and FB via larger logical changes. However, we acknowledge that the abstract and main text do not explicitly report controls or ablations for perceptual statistics, co-occurrence, or search-space size. We will add such analyses (e.g., object frequency statistics and similarity measures) in the revision to demonstrate that the split isolates logical proximity. revision: yes
Circularity Check
No circularity; dataset creation and evaluation are self-contained
full rationale
The paper introduces COCOLogic-V2 as a new object-centric dataset with positive, NB, and FB negative samples for visual inductive reasoning, then reports empirical model evaluations on it. No derivations, equations, fitted parameters, or predictions are claimed; the NB/FB boundary is an explicit design choice in dataset construction rather than a derived output. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing. The contribution reduces to dataset release plus initial benchmarking, with no step that reduces by construction to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Model card (2026), https://www.anthropic.com/ claude/opus
Anthropic: Claude opus 4.7. Model card (2026), https://www.anthropic.com/ claude/opus
2026
-
[2]
In: International Conference on Machine Learning
Barbiero, P., Ciravegna, G., Giannini, F., Zarlenga, M.E., Magister, L.C., Tonda, A., Lió, P., Precioso, F., Jamnik, M., Marra, G.: Interpretable neural-symbolic concept reasoning. In: International Conference on Machine Learning. pp. 1801–1825. PMLR (2023)
2023
-
[3]
arXiv preprint arXiv:1911.01547 (2019)
Chollet, F.: On the measure of intelligence. arXiv preprint arXiv:1911.01547 (2019)
Pith/arXiv arXiv 1911
-
[4]
In: 2009 IEEE conference on computer vision and pattern recognition
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large-scale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition. pp. 248–255. Ieee (2009)
2009
-
[5]
Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences381(2251) (2023)
Ellis, K., Wong, L., Nye, M., Sable-Meyer, M., Cary, L., Anaya Pozo, L., Hewitt, L., Solar-Lezama, A., Tenenbaum, J.B.: Dreamcoder: growing generalizable, in- terpretable knowledge with wake–sleep bayesian program learning. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences381(2251) (2023)
2023
-
[6]
Advances in neural informa- tion processing systems35, 21400–21413 (2022)
Espinosa Zarlenga, M., Barbiero, P., Ciravegna, G., Marra, G., Giannini, F., Dili- genti, M., Shams, Z., Precioso, F., Melacci, S., Weller, A., et al.: Concept embedding models: Beyond the accuracy-explainability trade-off. Advances in neural informa- tion processing systems35, 21400–21413 (2022)
2022
-
[7]
google/models/gemini/pro/
GoogleDeepMind:Gemini3.1pro(preview).Modelcard(2026), https://deepmind. google/models/gemini/pro/
2026
-
[8]
Model card (2026), https://deepmind.google/ models/gemma/gemma-4/
Google DeepMind: Gemma 4. Model card (2026), https://deepmind.google/ models/gemma/gemma-4/
2026
-
[9]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (2023)
Gupta, T., Kembhavi, A.: Visual programming: Compositional visual reasoning without training. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (2023)
2023
-
[10]
In: Proceedings of the IEEE international conference on computer vision
He, K., Gkioxari, G., Dollár, P., Girshick, R.: Mask r-cnn. In: Proceedings of the IEEE international conference on computer vision. pp. 2961–2969 (2017)
2017
-
[11]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016) COCOLogic-V2: Identifying Logical Inconsistencies via Truly Hard-Negatives 9
2016
-
[12]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Jiang, H., Ma, X., Nie, W., Yu, Z., Zhu, Y., Anandkumar, A.: Bongard-hoi: Bench- marking few-shot visual reasoning for human-object interactions. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 19056–19065 (2022)
2022
-
[13]
In: The Fourteenth International Conference on Learning Representations (2026)
Kamali, D., Kordjamshidi, P.: NePTune: A neuro-pythonic framework for tun- able compositional reasoning on vision-language. In: The Fourteenth International Conference on Learning Representations (2026)
2026
-
[14]
Transactions on Machine Learning Research (2026)
Knab, P., Steinmann, D., Bartelt, C., Kersting, K., Schiele, B., Seidl, T., Schlegel, U., Stammer, W.: What’s in the bottle? a survey and roadmap of concept bottleneck models. Transactions on Machine Learning Research (2026)
2026
-
[15]
In: International Conference on Machine Learning (ICML)
Koh, P.W., Nguyen, T., Tang, Y.S., Mussmann, S., Pierson, E., Kim, B., Liang, P.: Concept bottleneck models. In: International Conference on Machine Learning (ICML). pp. 5338–5348 (2020)
2020
-
[16]
In: European conference on computer vision
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision. pp. 740–755. Springer (2014)
2014
-
[17]
In: European Conference on Computer Vision (ECCV)
Lin, T., Maire, M., Belongie, S.J., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft COCO: common objects in context. In: European Conference on Computer Vision (ECCV). pp. 740–755 (2014)
2014
-
[18]
In: International Conference on Learning Representations (2019)
Mao, J., Gan, C., Kohli, P., Tenenbaum, J.B., Wu, J.: The neuro-symbolic concept learner: Interpreting scenes, words, and sentences from natural supervision. In: International Conference on Learning Representations (2019)
2019
-
[19]
Advances in Neural Information Processing Systems36, 72507–72539 (2023)
Marconato, E., Teso, S., Vergari, A., Passerini, A.: Not all neuro-symbolic concepts are created equal: Analysis and mitigation of reasoning shortcuts. Advances in Neural Information Processing Systems36, 72507–72539 (2023)
2023
-
[20]
Artificial intelligence300, 103546 (2021)
Müller, H., Holzinger, A.: Kandinsky patterns. Artificial intelligence300, 103546 (2021)
2021
-
[21]
System card (2026), https://openai.com/index/ gpt-5-5-system-card/
OpenAI: Gpt-5.5. System card (2026), https://openai.com/index/ gpt-5-5-system-card/
2026
-
[22]
Advances in Neural Information Processing Systems37, 105171–105199 (2024)
Panousis, K.P., Ienco, D., Marcos, D.: Coarse-to-fine concept bottleneck models. Advances in Neural Information Processing Systems37, 105171–105199 (2024)
2024
-
[23]
Nature Machine Intelligence1(5), 206–215 (2019)
Rudin, C.: Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nature Machine Intelligence1(5), 206–215 (2019)
2019
-
[24]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Shang, C., Zhou, S., Zhang, H., Ni, X., Yang, Y., Wang, Y.: Incremental residual concept bottleneck models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 11030–11040 (2024)
2024
-
[25]
Machine Learning112(5), 1465–1497 (2023)
Shindo, H., Pfanschilling, V., Dhami, D.S., Kersting, K.:α ilp: thinking visual scenes as differentiable logic programs. Machine Learning112(5), 1465–1497 (2023)
2023
-
[26]
In: Conference on Computer Vision and Pattern Recognition CVPR
Stammer, W., Schramowski, P., Kersting, K.: Right for the right concept: Revising neuro-symbolic concepts by interacting with their explanations. In: Conference on Computer Vision and Pattern Recognition CVPR. pp. 3619–3629 (2021)
2021
-
[27]
arXiv preprint arXiv:2412.05152 (2024)
Steinmann, D., Divo, F., Kraus, M., Wüst, A., Struppek, L., Friedrich, F., Kersting, K.: Navigating shortcuts, spurious correlations, and confounders: From origins via detection to mitigation. arXiv preprint arXiv:2412.05152 (2024)
arXiv 2024
-
[28]
Advances in Neural Information Processing Systems38, 68899–68924 (2026)
Steinmann, D., Stammer, W., Wüst, A., Kersting, K.: Object-centric concept- bottlenecks. Advances in Neural Information Processing Systems38, 68899–68924 (2026)
2026
-
[29]
In: International Conference on Machine Learning
Vedantam, R., Szlam, A., Nickel, M., Morcos, A., Lake, B.M.: Curi: A benchmark for productive concept learning under uncertainty. In: International Conference on Machine Learning. pp. 10519–10529. PMLR (2021) 10 D. Steinmann et al
2021
-
[30]
Welinder, P., Branson, S., Mita, T., Wah, C., Schroff, F., Belongie, S., Perona, P.: Caltech-ucsd birds 200 (2010)
2010
-
[31]
In: International Conference on Learning Representations
Wu, R., Ma, X., Zhang, Z., Wang, W., Li, Q., Zhu, S.C., Wang, Y.: Bongard- openworld: Few-shot reasoning for free-form visual concepts in the real world. In: International Conference on Learning Representations. vol. 2024, pp. 20688–20718 (2024)
2024
-
[32]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wüst, A., Stammer, W., Shindo, H., Helff, L., Dhami, D.S., Kersting, K.: Synthesiz- ing visual concepts as vision-language programs. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 17346–17356 (2026)
2026
-
[33]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yang, Y., Panagopoulou, A., Zhou, S., Jin, D., Callison-Burch, C., Yatskar, M.: Language in a bottle: Language model guided concept bottlenecks for interpretable image classification. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 19187–19197 (2023)
2023
-
[34]
1 – 2cup, rather than
Zhou, B., Lapedriza, A., Khosla, A., Oliva, A., Torralba, A.: Places: A 10 million image database for scene recognition. IEEE transactions on pattern analysis and machine intelligence40(6), 1452–1464 (2017) COCOLogic-V2: Identifying Logical Inconsistencies via Truly Hard-Negatives 11 Supplementary Materials A Additional Details for COCOLogic-V2 A.1 Positi...
2017
-
[35]
Image Analysis: - Carefully describe each image, noting objects, their attributes, and conceptual features (such as relationships, actions, or settings)
-
[36]
- Confirm that the rule does not hold for the negative examples
Rule Derivation: - From your analysis, infer the rule that uniquely characterizes the positive examples. - Confirm that the rule does not hold for the negative examples. ## Final Answer Format Provide your final answer in the following format: ‘‘‘python answer = { ’rule’: ’[RULE]’, } ‘‘‘ Ensure that the rule is clearly defined and concise. Test Prompt Giv...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.