Analysis of the Neglect-Zero Effect in Large Language Models
Pith reviewed 2026-06-28 01:34 UTC · model grok-4.3
The pith
Large language models do not exhibit the neglect-zero effect that humans show when reasoning about empty sets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Using structural priming, the study finds that the tested LLMs do not neglect zero-models in the manner humans do. Primes designed to highlight empty-set cases do not produce the facilitation pattern expected if the models were ignoring those cases on their own; instead, the models treat the zero-model inferences similarly to non-zero-model inferences throughout.
What carries the argument
Structural priming paradigm that presents a prime sentence forcing consideration of a zero-model before a target sentence whose interpretation could also rest on a zero-model.
If this is right
- LLMs may treat vacuous truths as ordinary cases rather than defaulting to neglect.
- Differences between LLM and human inference patterns appear even in tasks that rest on basic set emptiness.
- The absence of the bias holds across the specific models and inference types examined in the experiments.
- Training or architectural features may prevent the formation of the neglect-zero shortcut.
Where Pith is reading between the lines
- If the result generalizes, LLMs could serve as test subjects for logical reasoning that avoids certain human shortcuts.
- Prompt engineering that works on humans by countering neglect may be unnecessary for these models.
- The finding leaves open whether the same pattern appears in zero-shot settings without any priming sentences.
Load-bearing premise
The structural priming setup cleanly reveals whether an LLM is already considering zero-models rather than being shaped by prompt wording or memorized training examples.
What would settle it
A replication in which the same LLMs produce reliably faster or more probable responses on zero-model targets after zero-model primes, matching the human priming pattern, would contradict the reported result.
Figures


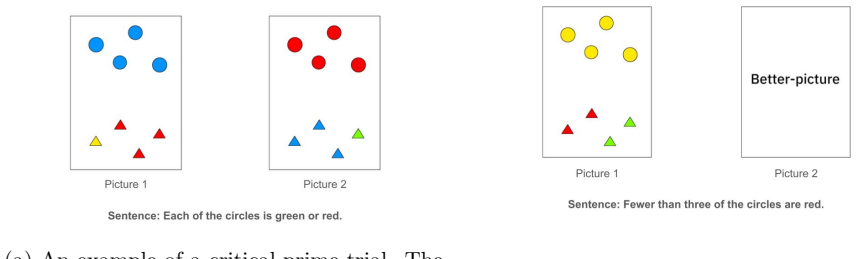

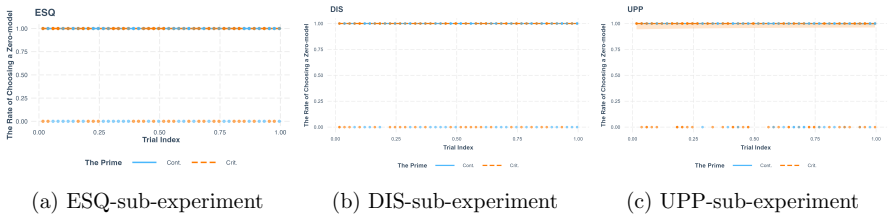
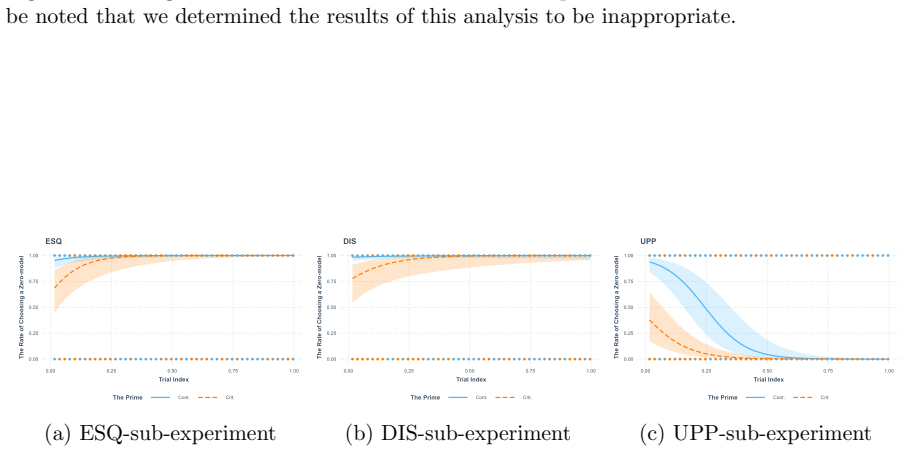
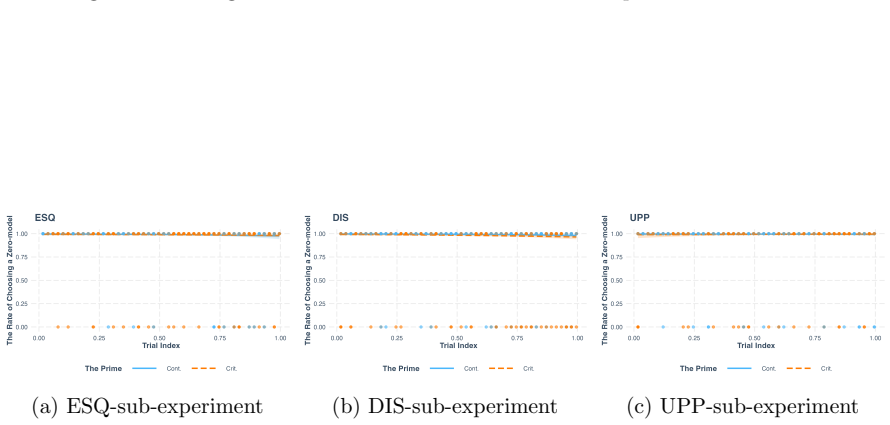

read the original abstract
We investigate the extent to which the language processing of LLMs resembles human cognitive processes, focusing on a human cognitive bias called the $\textit{neglect-zero effect}$. This effect refers to the human tendency to ignore $\textit{zero-models}$, which are configurations that render a proposition vacuously true by virtue of an empty set. We focus on two types of inferences driven by the neglect-zero effect, and examine how LLMs process these inferences by comparing their behavior with that in an inference that does not involve the neglect-zero effect. For this purpose, we employ a paradigm based on $\textit{structural priming}$, where recent exposure to a preceding sentence (the $\textit{prime}$) facilitates the processing of a subsequent sentence (the $\textit{target}$) due to their structural similarity. We prepare primes to force LLMs to consider the zero-model, and analyze whether they also consider it in the target. The results suggest that the neglect-zero effect may not occur in the LLMs analyzed in this study. Our code is available at https://github.com/ynklab/neglect_zero
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates whether LLMs exhibit the neglect-zero effect (human tendency to ignore zero-models that render propositions vacuously true via empty sets) by comparing behavior on two types of zero-model inferences against a non-zero-model inference. It employs a structural priming paradigm in which primes are constructed to force consideration of zero-models, then tests for carry-over facilitation to structurally similar targets; the reported outcome is that the neglect-zero effect appears absent in the LLMs examined.
Significance. If the central claim is confirmed, the work would indicate a systematic divergence between LLM next-token processing and human logical inference on vacuous truths, with potential value for cognitive modeling and reasoning benchmarks. The public release of code at the cited GitHub repository is a clear strength that supports reproducibility.
major comments (2)
- [Methods] Methods section: the structural priming design does not report explicit controls for lexical overlap, prompt-formatting variants, or baseline priming strength in non-zero-model conditions; without these, the observed lack of priming cannot be unambiguously attributed to absence of the neglect-zero bias rather than failure of the prime to engage the intended logical structure.
- [Results] Results: the abstract (and by extension the reported evidence) provides only high-level summaries without data tables, error bars, statistical details, or per-model breakdowns, rendering it impossible to verify the strength or robustness of the claim that the effect is absent.
minor comments (1)
- [Abstract] Abstract: notation for the neglect-zero effect and zero-models is introduced with LaTeX italics but without a concise operational definition that would allow readers to map the paradigm directly onto the logical property under test.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript investigating the neglect-zero effect in LLMs. The comments highlight important aspects of methodological transparency and results presentation that we address below.
read point-by-point responses
-
Referee: [Methods] Methods section: the structural priming design does not report explicit controls for lexical overlap, prompt-formatting variants, or baseline priming strength in non-zero-model conditions; without these, the observed lack of priming cannot be unambiguously attributed to absence of the neglect-zero bias rather than failure of the prime to engage the intended logical structure.
Authors: We agree that the methods section would benefit from greater explicitness on these points. Our experimental materials were constructed with distinct lexical items between primes and targets to minimize overlap, multiple prompt phrasings were tested during piloting, and non-zero-model baseline conditions were included to establish priming strength. These elements were part of the design but not described in sufficient detail. We will revise the methods section to add a paragraph explicitly documenting the lexical controls, prompt variants, and baseline results, thereby strengthening the link between the observed lack of priming and the absence of the neglect-zero effect. revision: yes
-
Referee: [Results] Results: the abstract (and by extension the reported evidence) provides only high-level summaries without data tables, error bars, statistical details, or per-model breakdowns, rendering it impossible to verify the strength or robustness of the claim that the effect is absent.
Authors: The full results section contains per-model accuracy figures, statistical tests, and error bars within the figures. Nevertheless, we recognize that the abstract is high-level and that a consolidated table would improve verifiability. We will add a summary table reporting key metrics and statistics to the main text and revise the abstract to reference these quantitative details, allowing readers to assess the robustness of the claim directly. revision: yes
Circularity Check
Empirical behavioral study with no circular derivation chain
full rationale
The paper reports an empirical investigation comparing LLM responses to human neglect-zero bias via structural priming experiments. No equations, fitted parameters, or self-citations are used to derive the central claim; results follow directly from observed model outputs on primes and targets. This is a standard self-contained behavioral comparison against external benchmarks, with no reduction of predictions to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Structural priming paradigm isolates consideration of zero-models
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Neglect zero: Evidence from priming across constructions , url=
Klochowicz, Tomasz and Schlotterbeck, Fabian and Ramotowska, Sonia and Bott, Oliver and Aloni, Maria , booktitle=. Neglect zero: Evidence from priming across constructions , url=. 2025 , pages=
2025
-
[9]
Experimental Pragmatics with Machines: Testing
Tsvilodub, Polina and Marty, Paul and Ramotowska, Sonia and Romoli, Jacopo and Franke, Michael , booktitle=. Experimental Pragmatics with Machines: Testing. 2024 , pages=
2024
-
[10]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[11]
Neural Information Processing Systems , year=
Attention is All you Need , author=. Neural Information Processing Systems , year=
-
[12]
Alec Radford and Karthik Narasimhan and Tim Salimans and Ilya Sutskever , title=
-
[13]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina. BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v...
-
[14]
2025 , eprint=
Mixture of Experts (MoE): A Big Data Perspective , author=. 2025 , eprint=
2025
-
[15]
2022 , URL=
Finetuned Language Models are Zero-Shot Learners , author=. 2022 , URL=
2022
-
[16]
2026 , url=
Comparing Open-Source vs Closed LLMs for Enterprise Apps , author=. 2026 , url=
2026
-
[17]
Syntax and Semantics , year=
Logic and conversation , author=. Syntax and Semantics , year=
-
[18]
2020 , eprint=
Language Models are Few-Shot Learners , author=. 2020 , eprint=
2020
-
[19]
Towards a new taxonomy for pragmatic inference:
Horn, Laurence , year =. Towards a new taxonomy for pragmatic inference:. Meaning, Form and Use in Context , editor =
-
[20]
Semantics and Pragmatics 15(5), pp
Aloni, Maria , Title =. Semantics and Pragmatics , Volume =. doi:10.3765/sp.15.5 , Keywords =
-
[21]
Embedded implicatures?!? , volume =
Geurts, Bart and Pouscoulous, Nausicaa , year =. Embedded implicatures?!? , volume =. Semantics and Pragmatics , doi =
-
[22]
1983 , publisher=
Mental Models: Towards a Cognitive Science of Language, Inference, and Consciousness , author=. 1983 , publisher=
1983
-
[23]
(2011): Thinking, Fast and Slow , author=
Kahneman, D. (2011): Thinking, Fast and Slow , author=. Stat Papers , volume=
2011
-
[24]
Cognitive Psychology , volume =
Syntactic persistence in language production , author =. Cognitive Psychology , volume =. 1986 , issn =. doi:https://doi.org/10.1016/0010-0285(86)90004-6 , url =
-
[25]
Structural Priming: A Critical Review , volume =
Pickering, Martin and Ferreira, Victor , year =. Structural Priming: A Critical Review , volume =. Psychological Bulletin , doi =
-
[26]
Do Language Models Exhibit Human-like Structural Priming Effects?
Jumelet, Jaap and Zuidema, Willem and Sinclair, Arabella. Do Language Models Exhibit Human-like Structural Priming Effects?. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.877
-
[27]
2023 , eprint=
LLaMA: Open and Efficient Foundation Language Models , author=. 2023 , eprint=
2023
-
[28]
2024 , eprint=
Gemma: Open Models Based on Gemini Research and Technology , author=. 2024 , eprint=
2024
-
[29]
Implicature priming, salience, and context adaptation , journal =
Paul Marty and Jacopo Romoli and Yasutada Sudo and Richard Breheny , keywords =. Implicature priming, salience, and context adaptation , journal =. 2024 , issn =. doi:https://doi.org/10.1016/j.cognition.2023.105667 , url =
-
[30]
2016 , doi =
Shared and distinct mechanisms in deriving linguistic enrichment , journal =. 2016 , doi =
2016
-
[31]
Marie-Christine Meyer and Roman Feiman , keywords =. Priming reveals similarities and differences between three purported cases of implicature: Some, number and free choice disjunctions , journal =. 2021 , issn =. doi:https://doi.org/10.1016/j.jml.2020.104206 , url =
-
[32]
Free Choice Permission , urldate =
Hans Kamp , journal =. Free Choice Permission , urldate =
-
[33]
Albert and J
A. Albert and J. A. Anderson , journal =. On the Existence of Maximum Likelihood Estimates in Logistic Regression Models , urldate =
-
[34]
Bias Reduction of Maximum Likelihood Estimates , urldate =
David Firth , journal =. Bias Reduction of Maximum Likelihood Estimates , urldate =
-
[35]
Statistics in medicine , volume=
A solution to the problem of separation in logistic regression , author=. Statistics in medicine , volume=. 2002 , urldata=
2002
-
[36]
Is the Pope Catholic? Yes, the Pope is Catholic
Yerukola, Akhila and Vaduguru, Saujas and Fried, Daniel and Sap, Maarten. Is the Pope Catholic? Yes, the Pope is Catholic. Generative Evaluation of Non-Literal Intent Resolution in LLM s. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2024. doi:10.18653/v1/2024.acl-short.26
-
[37]
2025 , eprint=
Large Language Models and Cognitive Science: A Comprehensive Review of Similarities, Differences, and Challenges , author=. 2025 , eprint=
2025
-
[38]
McCurdy, Kate and Goldwater, Sharon and Lopez, Adam. Inflecting When There ' s No Majority: Limitations of Encoder-Decoder Neural Networks as Cognitive Models for G erman Plurals. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.159
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.