ARIADNE: Agnostic Routing for Inference-time Adapter DyNamic sElection
Pith reviewed 2026-06-26 20:51 UTC · model grok-4.3
The pith
ARIADNE selects the best adapter for an unlabeled input by measuring how close its embedding lies to each adapter's training centroids in latent space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
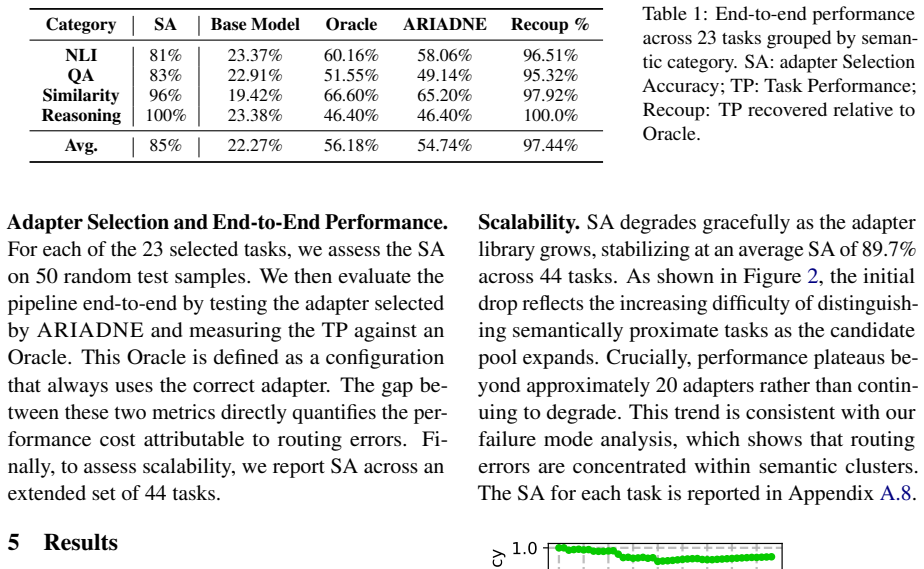
ARIADNE represents each adapter through a set of centroids computed from embeddings of its training set, capturing the data distribution associated with that adapter. Given an unlabeled input, it selects an adapter by measuring proximity to these centroids in latent space. Because routing is performed entirely in the input embedding space, ARIADNE is compatible with arbitrary PEFT methods and requires no modification to the adapters or training procedures. Primarily evaluated with Llama 3.2 1B Instruct on 23 diverse NLP tasks, ARIADNE recovers 97.44% of the upper bound performance. Scaling to 44 tasks, it achieves 89.7% average selection accuracy, without additional training or access to ada
What carries the argument
Per-adapter centroids formed from training embeddings, used as reference points for nearest-centroid selection in the model's latent space.
If this is right
- Adding a new adapter requires only computing its training centroids; no router retraining or architecture changes are needed.
- The same routing logic applies unchanged to any parameter-efficient fine-tuning method because it never inspects adapter weights or gradients.
- Selection accuracy holds at 89.7 percent when the adapter pool is scaled from 23 to 44 tasks.
- Overall task performance reaches 97.44 percent of the oracle upper bound that always picks the single best adapter for each input.
Where Pith is reading between the lines
- The method could extend to continual adapter addition in deployed systems, since each new task needs only its centroid set computed once from its data.
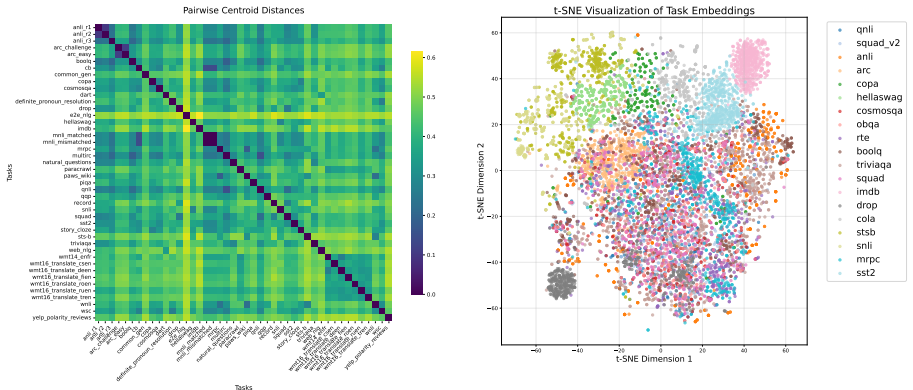
- Heavy overlap between task distributions in embedding space would likely increase selection errors, pointing to possible hybrid routing that adds a lightweight fallback check.
- If embedding centroids prove stable across model scales, the same routing tables could be reused when swapping to a larger backbone without recomputation.
Load-bearing premise
Proximity of an input embedding to an adapter's training centroids is enough to identify the adapter that will produce the highest performance on that input.
What would settle it
Finding an input whose closest centroid belongs to adapter A yet yields measurably higher task performance when routed to adapter B would falsify the claim that centroid proximity suffices for optimal selection.
Figures


read the original abstract
The increasing deployment of parameter-efficient fine-tuning (PEFT) has led to model ecosystems in which a single backbone is paired with many task-specialized adapters. In this setting, inference-time queries often arrive without task labels, requiring the system to automatically select the most appropriate adapter from a growing and heterogeneous adapter pool. Existing routing methods either depend on access to adapter internals, such as weight decompositions or gradient-based statistics, or require additional router training, which limits scalability and portability as new adapters are added. We introduce ARIADNE, a training-free, adapter-agnostic routing framework for dynamic adapter selection at inference time. ARIADNE represents each adapter through a set of centroids computed from embeddings of its training set, capturing the data distribution associated with that adapter. Given an unlabeled input, it selects an adapter by measuring proximity to these centroids in latent space. Because routing is performed entirely in the input embedding space, ARIADNE is compatible with arbitrary PEFT methods and requires no modification to the adapters or training procedures. Primarily evaluated with Llama 3.2 1B Instruct on 23 diverse NLP tasks, ARIADNE recovers 97.44% of the upper bound performance. Scaling to 44 tasks, it achieves 89.7% average selection accuracy, without additional training or access to adapter internals.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ARIADNE, a training-free, adapter-agnostic routing framework for inference-time selection among multiple PEFT adapters attached to a single backbone. Each adapter is represented by centroids computed from embeddings of its training set in the frozen backbone's latent space; an unlabeled query is routed to the adapter whose centroid is nearest in embedding distance. On Llama 3.2 1B Instruct the method recovers 97.44% of upper-bound performance across 23 NLP tasks and achieves 89.7% average selection accuracy when scaled to 44 tasks, without router training or access to adapter internals.
Significance. If the central result holds, the work offers a portable, scalable solution for routing in growing adapter ecosystems that avoids the cost of learned routers and the requirement to inspect adapter weights. The training-free and PEFT-agnostic properties are genuine strengths that could enable practical deployment. Credit is due for the explicit design choice to operate solely in the base embedding space.
major comments (2)
- [§4] §4 (Experimental setup): The claim of recovering 97.44% of upper-bound performance is load-bearing, yet the manuscript provides no explicit definition or computation protocol for the upper bound, no description of whether task labels are withheld from all methods during evaluation, and no error bars or statistical tests across the 23 tasks; without these the reported recovery percentage cannot be verified as robust.
- [§3.2] §3.2 (Routing rule): The decision rule selects the adapter whose training centroid is closest in embedding space without any reference to adapter weights, gradients, or task loss; the manuscript does not include an ablation or counter-example set demonstrating that this proximity is the causal driver of performance rather than a side-effect of well-separated task distributions, which directly undermines the generality of the 89.7% accuracy claim on 44 tasks.
minor comments (2)
- [§3.1] Notation for centroid computation and distance metric should be formalized with an equation in §3.1 rather than left in prose.
- [Tables] Table captions should explicitly state whether selection accuracy is measured with or without access to ground-truth task labels.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and robustness where appropriate.
read point-by-point responses
-
Referee: [§4] §4 (Experimental setup): The claim of recovering 97.44% of upper-bound performance is load-bearing, yet the manuscript provides no explicit definition or computation protocol for the upper bound, no description of whether task labels are withheld from all methods during evaluation, and no error bars or statistical tests across the 23 tasks; without these the reported recovery percentage cannot be verified as robust.
Authors: We agree that an explicit definition and additional details are required for verifiability. The upper bound is the performance obtained by an oracle that always routes each query to the adapter trained on its ground-truth task. We will add a precise definition and computation protocol to Section 4. Task labels are withheld from all routing methods during evaluation, as the queries are unlabeled; this will be clarified. We will also include error bars (standard deviation across the 23 tasks) and statistical tests (e.g., paired t-tests against baselines) in the revised manuscript. revision: yes
-
Referee: [§3.2] §3.2 (Routing rule): The decision rule selects the adapter whose training centroid is closest in embedding space without any reference to adapter weights, gradients, or task loss; the manuscript does not include an ablation or counter-example set demonstrating that this proximity is the causal driver of performance rather than a side-effect of well-separated task distributions, which directly undermines the generality of the 89.7% accuracy claim on 44 tasks.
Authors: ARIADNE is intentionally defined to use only embedding-space centroid proximity, and the 89.7% selection accuracy on 44 tasks provides direct empirical evidence of its utility. We acknowledge that an explicit ablation isolating proximity from distribution separability would further strengthen the generality claim. We will add a discussion in Section 3.2 together with an analysis (using inter-centroid distances and overlap metrics) showing that routing accuracy correlates with proximity as predicted by the method; a limited synthetic ablation on task subsets with controlled overlap will be included if space permits. revision: partial
Circularity Check
No circularity; method is a direct embedding-based heuristic with empirical evaluation
full rationale
The paper defines ARIADNE explicitly as computing per-adapter centroids from training embeddings and routing via nearest-centroid distance in the frozen backbone embedding space. This construction is stated directly from the inputs (embeddings) with no intervening derivation, equations, or fitted parameters that are then relabeled as predictions. No self-citations, uniqueness theorems, or ansatzes are invoked in the provided text to justify the core routing rule. The reported recovery percentages and selection accuracies are presented as outcomes of applying this heuristic to held-out tasks, not as quantities forced by the definition itself. The approach is therefore self-contained as an empirical proposal rather than a closed logical loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Proximity in input embedding space to an adapter's training centroids indicates the adapter that will perform best on the query
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Loraretriever: Input-aware lora retrieval and composition for mixed tasks in the wild , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[9]
arXiv preprint arXiv:2402.05859 , year=
Learning to route among specialized experts for zero-shot generalization , author=. arXiv preprint arXiv:2402.05859 , year=
-
[10]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Glider: Global and local instruction-driven expert router , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[11]
arXiv preprint arXiv:2405.11157 , year=
Towards modular llms by building and reusing a library of loras , author=. arXiv preprint arXiv:2405.11157 , year=
-
[12]
Edward J Hu and yelong shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo. 2022 , url=
2022
-
[13]
International conference on machine learning , pages=
Parameter-efficient transfer learning for NLP , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[14]
Prefix-tuning: Optimizing continuous prompts for generation , author=. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages=
-
[15]
Advances in Neural Information Processing Systems , volume=
Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
arXiv preprint arXiv:2310.11454 , year=
Vera: Vector-based random matrix adaptation , author=. arXiv preprint arXiv:2310.11454 , year=
-
[17]
Forty-first International Conference on Machine Learning , year=
Dora: Weight-decomposed low-rank adaptation , author=. Forty-first International Conference on Machine Learning , year=
-
[18]
arXiv preprint arXiv:2303.10512 , year=
Adalora: Adaptive budget allocation for parameter-efficient fine-tuning , author=. arXiv preprint arXiv:2303.10512 , year=
-
[19]
Findings of the Association for Computational Linguistics: EACL 2023 , pages=
Adaptersoup: Weight averaging to improve generalization of pretrained language models , author=. Findings of the Association for Computational Linguistics: EACL 2023 , pages=
2023
-
[20]
arXiv preprint arXiv:2307.13269 , year=
Lorahub: Efficient cross-task generalization via dynamic lora composition , author=. arXiv preprint arXiv:2307.13269 , year=
-
[21]
arXiv preprint arXiv:2202.13914 , year=
Combining modular skills in multitask learning , author=. arXiv preprint arXiv:2202.13914 , year=
-
[22]
Advances in Neural Information Processing Systems , volume=
Multi-head adapter routing for cross-task generalization , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
Neural computation , volume=
Adaptive mixtures of local experts , author=. Neural computation , volume=. 1991 , publisher=
1991
-
[24]
Journal of Machine Learning Research , volume=
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity , author=. Journal of Machine Learning Research , volume=
-
[25]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
Adamix: Mixture-of-adaptations for parameter-efficient model tuning , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
2022
-
[26]
arXiv preprint arXiv:2309.05444 , year=
Pushing mixture of experts to the limit: Extremely parameter efficient moe for instruction tuning , author=. arXiv preprint arXiv:2309.05444 , year=
-
[27]
Microsoft Research Blog , volume=
Phi-2: The surprising power of small language models , author=. Microsoft Research Blog , volume=
-
[28]
arXiv preprint arXiv:2401.02385 , year=
Tinyllama: An open-source small language model , author=. arXiv preprint arXiv:2401.02385 , year=
-
[29]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[30]
arXiv preprint arXiv:2212.03533 , year=
Text embeddings by weakly-supervised contrastive pre-training , author=. arXiv preprint arXiv:2212.03533 , year=
-
[31]
Representation-based Broad Hallucination Detectors Fail to Generalize Out of Distribution
Dubanowska, Zuzanna and \.Z elaszczyk, Maciej and Brzozowski, Micha and Mandica, Paolo and Karpowicz, Michal P. Representation-based Broad Hallucination Detectors Fail to Generalize Out of Distribution. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.952
-
[32]
Fleshman, William and Van Durme, Benjamin , journal=
-
[33]
Gao, Tianyu and Yao, Xingcheng and Chen, Danqi , booktitle=
-
[34]
Proceedings of the 2018 EMNLP workshop BlackboxNLP: Analyzing and interpreting neural networks for NLP , pages=
GLUE: A multi-task benchmark and analysis platform for natural language understanding , author=. Proceedings of the 2018 EMNLP workshop BlackboxNLP: Analyzing and interpreting neural networks for NLP , pages=
2018
-
[35]
2026 , eprint=
GPart: End-to-End Isometric Fine-Tuning via Global Parameter Partitioning , author=. 2026 , eprint=
2026
-
[36]
Qwen2.5: A Party of Foundation Models , url =
Qwen Team , month =. Qwen2.5: A Party of Foundation Models , url =
-
[37]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , year=
HellaSwag: Can a Machine Really Finish Your Sentence? , author=. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , year=
-
[38]
A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference
Williams, Adina and Nangia, Nikita and Bowman, Samuel. A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). 2018
2018
-
[39]
and Ng, Andrew and Potts, Christopher
Socher, Richard and Perelygin, Alex and Wu, Jean and Chuang, Jason and Manning, Christopher D. and Ng, Andrew and Potts, Christopher. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. 2013
2013
-
[40]
Thirteenth International Conference on the Principles of Knowledge Representation and Reasoning , year=
The winograd schema challenge , author=. Thirteenth International Conference on the Principles of Knowledge Representation and Reasoning , year=
-
[41]
Wang, Alex and Singh, Amanpreet and Michael, Julian and Hill, Felix and Levy, Omer and Bowman, Samuel R. , note=
-
[42]
SQ u AD : 100,000+ Questions for Machine Comprehension of Text
Rajpurkar, Pranav and Zhang, Jian and Lopyrev, Konstantin and Liang, Percy. SQ u AD : 100,000+ Questions for Machine Comprehension of Text. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2016. doi:10.18653/v1/D16-1264
-
[43]
Know what you don ' t know: Unanswerable questions for SQ u AD
Rajpurkar, Pranav and Jia, Robin and Liang, Percy. Know What You Don ' t Know: Unanswerable Questions for SQ u AD. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2018. doi:10.18653/v1/P18-2124
-
[44]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics
Adversarial NLI: A New Benchmark for Natural Language Understanding , author=. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020
2020
-
[45]
Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning , pages=
Resolving complex cases of definite pronouns: the winograd schema challenge , author=. Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning , pages=. 2012 , organization=
2012
-
[46]
Zhang, Yuan and Baldridge, Jason and He, Luheng , booktitle =
-
[47]
arXiv e-prints , year = 2017, eid =
triviaqa: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. arXiv e-prints , year = 2017, eid =
2017
-
[48]
and Angeli, Gabor and Potts, Christopher and Manning, Christopher D
Bowman, Samuel R. and Angeli, Gabor and Potts, Christopher and Manning, Christopher D. A large annotated corpus for learning natural language inference. Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. 2015. doi:10.18653/v1/D15-1075
-
[49]
Proceedings of the 11th international workshop on semantic evaluation (SemEval-2017) , pages=
SemEval-2017 task 1: Semantic textual similarity multilingual and crosslingual focused evaluation , author=. Proceedings of the 11th international workshop on semantic evaluation (SemEval-2017) , pages=
2017
-
[50]
Lin, Bill Yuchen and Zhou, Wangchunshu and Shen, Ming and Zhou, Pei and Bhagavatula, Chandra and Choi, Yejin and Ren, Xiang. C ommon G en: A Constrained Text Generation Challenge for Generative Commonsense Reasoning. Findings of the Association for Computational Linguistics: EMNLP 2020. 2020. doi:10.18653/v1/2020.findings-emnlp.165
-
[51]
NAACL , year =
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions , author =. NAACL , year =
-
[52]
2019 ,journal =
Natural Questions: a Benchmark for Question Answering Research ,author =. 2019 ,journal =
2019
-
[53]
Peter Clark and Isaac Cowhey and Oren Etzioni and Tushar Khot and Ashish Sabharwal and Carissa Schoenick and Oyvind Tafjord , title =. arXiv:1803.05457v1 , year =
-
[54]
Findings of the 2016 Conference on Machine Translation , booktitle =
Bojar, Ond. Findings of the 2016 Conference on Machine Translation , booktitle =. 2016 , address =
2016
-
[55]
Findings of the 2014 Workshop on Statistical Machine Translation , booktitle =
Bojar, Ondrej and Buck, Christian and Federmann, Christian and Haddow, Barry and Koehn, Philipp and Leveling, Johannes and Monz, Christof and Pecina, Pavel and Post, Matt and Saint-Amand, Herve and Soricut, Radu and Specia, Lucia and Tamchyna, Ale. Findings of the 2014 Workshop on Statistical Machine Translation , booktitle =. 2014 , address =
2014
-
[56]
DART : Open-Domain Structured Data Record to Text Generation
Nan, Linyong and Radev, Dragomir and Zhang, Rui and Rau, Amrit and Sivaprasad, Abhinand and Hsieh, Chiachun and Tang, Xiangru and Vyas, Aadit and Verma, Neha and Krishna, Pranav and Liu, Yangxiaokang and Irwanto, Nadia and Pan, Jessica and Rahman, Faiaz and Zaidi, Ahmad and Mutuma, Mutethia and Tarabar, Yasin and Gupta, Ankit and Yu, Tao and Tan, Yi Chern...
-
[57]
and Daly, Raymond E
Maas, Andrew L. and Daly, Raymond E. and Pham, Peter T. and Huang, Dan and Ng, Andrew Y. and Potts, Christopher , title =. Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies , month =. 2011 , address =
2011
-
[58]
Dheeru Dua and Yizhong Wang and Pradeep Dasigi and Gabriel Stanovsky and Sameer Singh and Matt Gardner , title=. Proc. of NAACL , year=
-
[59]
Proceedings of North American Chapter of the Association for Computational Linguistics (NAACL) , year =
Daniel Khashabi and Snigdha Chaturvedi and Michael Roth and Shyam Upadhyay and Dan Roth , title =. Proceedings of North American Chapter of the Association for Computational Linguistics (NAACL) , year =
-
[60]
Ba \ n \'o n, Marta and Chen, Pinzhen and Haddow, Barry and Heafield, Kenneth and Hoang, Hieu and Espl \`a -Gomis, Miquel and Forcada, Mikel L. and Kamran, Amir and Kirefu, Faheem and Koehn, Philipp and Ortiz Rojas, Sergio and Pla Sempere, Leopoldo and Ram \'i rez-S \'a nchez, Gema and Sarr \'i as, Elsa and Strelec, Marek and Thompson, Brian and Waites, W...
-
[61]
Shaping the Narrative Arc: An Information-Theoretic Approach to Collaborative Dialogue
Du. Evaluating the. 2020 , month = jan, volume =. doi:10.1016/j.csl.2019.06.009 , archivePrefix =. 1901.11528 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1016/j.csl.2019.06.009 2020
-
[62]
Tackling the Story Ending Biases in The Story Cloze Test
Sharma, Rishi and Allen, James and Bakhshandeh, Omid and Mostafazadeh, Nasrin. Tackling the Story Ending Biases in The Story Cloze Test. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2018. doi:10.18653/v1/P18-2119
-
[63]
arXiv preprint arXiv:1810.12885 , year=
Record: Bridging the gap between human and machine commonsense reading comprehension , author=. arXiv preprint arXiv:1810.12885 , year=
-
[64]
Thirty-Fourth AAAI Conference on Artificial Intelligence , year =
Yonatan Bisk and Rowan Zellers and Ronan Le Bras and Jianfeng Gao and Yejin Choi , title =. Thirty-Fourth AAAI Conference on Artificial Intelligence , year =
-
[65]
Advances in neural information processing systems , volume=
Character-level convolutional networks for text classification , author=. Advances in neural information processing systems , volume=
-
[66]
International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=
CoPA: Hierarchical Concept Prompting and Aggregating Network for Explainable Diagnosis , author=. International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=. 2025 , organization=
2025
-
[67]
arXiv preprint arXiv:2506.05176 , year=
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models , author=. arXiv preprint arXiv:2506.05176 , year=
-
[68]
arXiv preprint arXiv:2402.05672 , year=
Multilingual E5 Text Embeddings: A Technical Report , author=. arXiv preprint arXiv:2402.05672 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.