On the Viability of Requirements Generation From Code: An Experience Report
Pith reviewed 2026-06-25 20:05 UTC · model grok-4.3
The pith
LLMs cannot reliably generate requirements from code or introduce and detect smells in them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
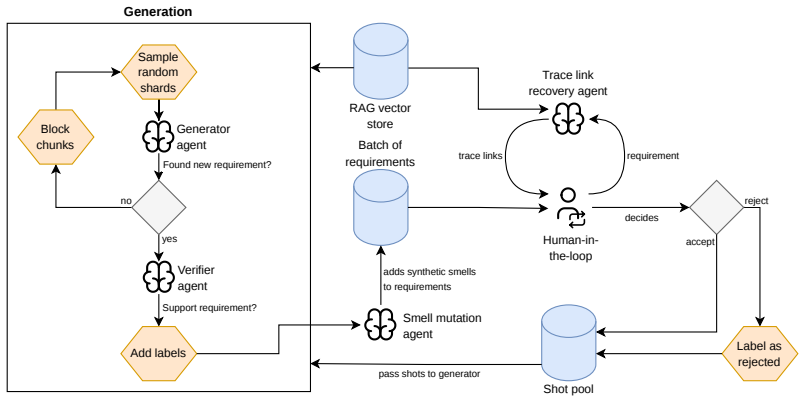
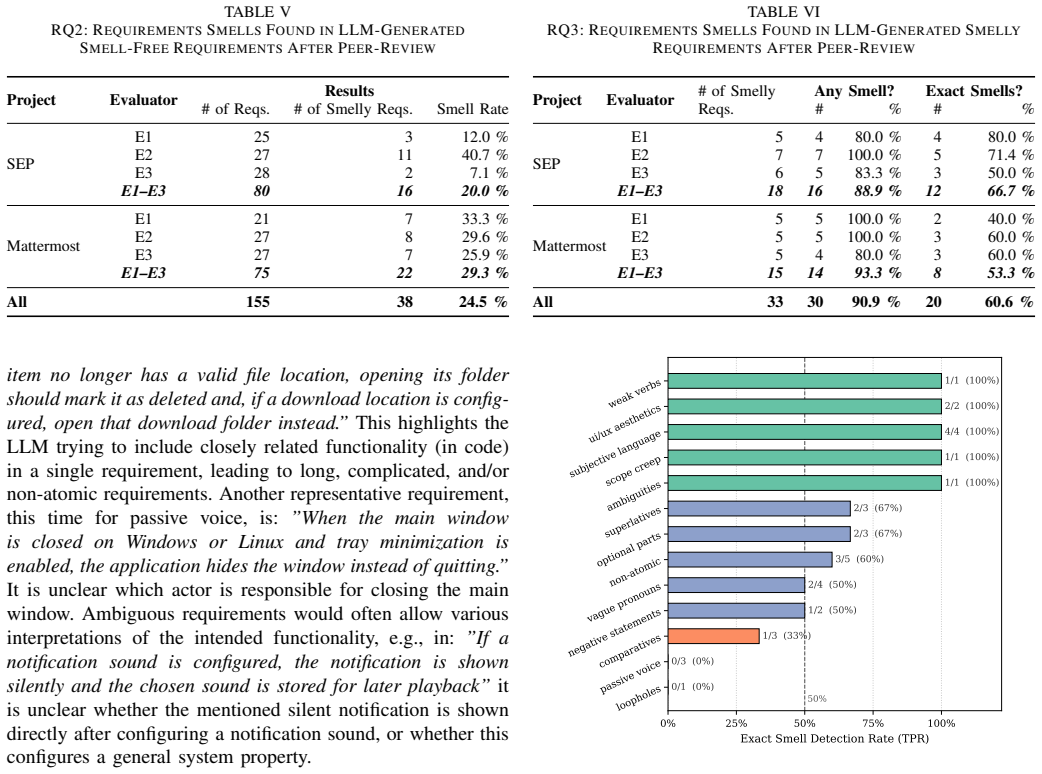
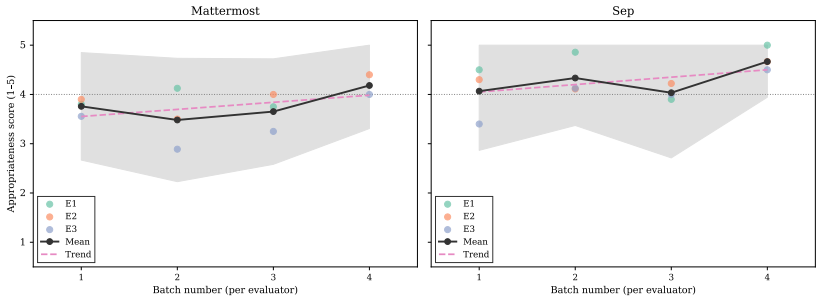
The authors tested an LLM-based and RAG-supported agentic approach intended to generate requirements from source code, verify their implementation status with human assistance, and synthetically introduce requirements smells to mimic real datasets. Contrary to initial expectations, the LLM proved unable to generate non-implemented requirements reliably, unable to generate high-quality requirements, and unable to introduce synthetic requirements smells in a controlled way. Neither the LLM nor a single human-in-the-loop reviewer could detect requirements smells reliably. The authors therefore state that the generation of code-to-requirements datasets using LLMs is not yet viable and requires h
What carries the argument
LLM-based and RAG-supported agentic system that generates requirements from code, checks implementation status via human-in-the-loop, and injects synthetic requirements smells.
If this is right
- Code-to-requirements datasets cannot be created reliably with current LLMs without extensive human supervision for quality assurance.
- Empirical research in requirements engineering will continue to lack adequate paired datasets under current LLM methods.
- Requirements smells cannot be introduced or detected reliably by the tested LLM or by one human reviewer.
- Generating non-implemented requirements from existing code remains outside the reliable capability of LLMs.
- High-quality requirements generation from code is not achievable with the evaluated LLM and RAG setup.
Where Pith is reading between the lines
- Multiple human reviewers working together might improve smell detection where a single reviewer fails.
- Similar reliability problems could appear in other tasks that ask LLMs to reverse-engineer specifications from code.
- Researchers may need to invest more effort in collecting authentic paired datasets rather than attempting synthetic generation.
- Tool builders for requirements-from-code tasks should plan for validation steps beyond single LLM or single-reviewer checks.
Load-bearing premise
The failures seen with the tested LLM, RAG setup, and single human reviewer indicate fundamental limits that hold beyond the specific code bases and choices used in the experiments.
What would settle it
A replication that uses a different LLM or multiple human reviewers and succeeds at producing high-quality requirements, non-implemented requirements, and controlled synthetic smells would show the approach can be viable.
Figures
read the original abstract
Empirical research in Requirements Engineering is hampered by a lack of adequate datasets that pair source code with corresponding requirements. A tempting route to addressing this lack is the use of Large Language Models to synthesize requirements from existing code bases. We investigate this question by evaluating an LLM-based and RAG-supported agentic approach that generates requirements from source code, verifies their implementation status relying on a human-in-the-loop, and synthetically introduces requirements smells and non-implemented requirements. Our goal was to create datasets that mimic reality and foster empirical RE research. However, during the study, various problems arose, leading to this experience report. Contrary to our initial hypotheses, LLMs were unable to (i) generate non-implemented requirements reliably, (ii) generate high quality requirements, and (iii) reliably introduce synthetic requirements smells. Furthermore, neither an LLM nor a single human-in-the-loop suffices to detect requirements smells reliably. These findings suggest that the generation of code-to-requirements datasets using LLMs is not yet viable and requires human supervision, especially for quality assurance. We critically reflect on our lessons learned and draw relevant conclusions for both researchers and practitioners.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper is an experience report describing an attempt to use an LLM-based, RAG-supported agentic workflow to generate requirements from source code, verify implementation status via human-in-the-loop, and synthetically introduce requirements smells and non-implemented requirements. Contrary to the authors' initial hypotheses, the tested approach failed to reliably produce non-implemented requirements, high-quality requirements, or synthetic smells, and neither the LLM nor a single human reviewer could reliably detect smells. The authors conclude that LLM-driven generation of code-to-requirements datasets is not yet viable and requires substantial human supervision for quality assurance.
Significance. If the reported failures are representative, the work provides a cautionary data point for the requirements engineering community on the current limitations of LLMs for synthetic dataset creation, underscoring the need for hybrid human-AI processes and potentially discouraging over-optimistic automation in empirical RE research.
major comments (2)
- [Abstract, §1] Abstract and §1: The central claim that LLM-based requirements generation 'is not yet viable' generalizes from observations on a single LLM, RAG configuration, and set of code bases; no ablation studies, alternative models, or prompt variations are reported to support moving from 'this workflow failed' to a broader viability assessment.
- [Abstract] Abstract: The viability conclusion and the three enumerated failures are stated without any quantitative metrics, failure rates, or controlled baselines, leaving the severity of the problems and the strength of the negative result difficult to calibrate.
minor comments (1)
- The manuscript would benefit from explicit discussion of the specific LLM and RAG implementation details (e.g., model version, retrieval parameters) to allow readers to assess reproducibility of the reported workflow.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments, which help us better position this experience report. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract, §1] Abstract and §1: The central claim that LLM-based requirements generation 'is not yet viable' generalizes from observations on a single LLM, RAG configuration, and set of code bases; no ablation studies, alternative models, or prompt variations are reported to support moving from 'this workflow failed' to a broader viability assessment.
Authors: We agree that the study examines only one specific LLM-based, RAG-supported agentic workflow on a limited set of code bases. As an experience report, the manuscript documents the concrete difficulties encountered rather than claiming that every possible LLM configuration must fail. We will revise the abstract and §1 to explicitly bound the conclusions to the tested workflow and to present the results as lessons learned from this particular attempt, thereby reducing any implication of broader generalization. Additional ablation studies or alternative-model experiments lie outside the scope of an experience report and are not planned. revision: partial
-
Referee: [Abstract] Abstract: The viability conclusion and the three enumerated failures are stated without any quantitative metrics, failure rates, or controlled baselines, leaving the severity of the problems and the strength of the negative result difficult to calibrate.
Authors: The paper is an experience report that records qualitative observations of repeated failures (inability to generate non-implemented requirements, high-quality specifications, and reliable synthetic smells). We will expand the abstract to include brief descriptive statements on the consistency and pervasiveness of these issues across the code bases examined, thereby providing readers with a clearer sense of scale without converting the work into a quantitative study. revision: yes
Circularity Check
No circularity: empirical observations from direct experiments
full rationale
The paper is an experience report whose central claims (LLM inability to generate non-implemented requirements, high-quality output, or synthetic smells; insufficiency of LLM or single human reviewer for smell detection) are stated as direct outcomes of the authors' own experimental runs on chosen code bases. No equations, fitted parameters, or self-citations are used to derive these results; the viability conclusion follows from the reported failures rather than from any self-referential definition or prior-author uniqueness theorem. The generalization concern raised by the skeptic is a question of external validity, not a circular reduction of the reported findings to their inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The chosen code bases, LLM models, and single human reviewer are representative for assessing the general viability of LLM-based requirements generation.
Reference graph
Works this paper leans on
-
[1]
Towards FAIR principles for research software,
A.-L. Lamprecht, L. Garcia, M. Kuzak, C. Martinez, R. Arcila, E. Martin Del Pico, V . Dominguez Del Angel, S. van de Sandt, J. Ison, P. A. Martinez, P. McQuilton, A. Valencia, J. Harrow, F. Psomopoulos, J. L. Gelpi, N. Chue Hong, C. Goble, and S. Capella-Gutierrez, “Towards FAIR principles for research software,”Data Science, vol. 3, no. 1, pp. 37–59, 2019
2019
-
[2]
Assessing the impact of requirement ambiguity on LLM-based function-level code generation,
D. Yang, X. Xie, X. Yang, M. Hu, Y . Huang, Y . Zhang, W. Miao, T. Su, C. Wan, and G. Pu, “Assessing the impact of requirement ambiguity on LLM-based function-level code generation,”arXiv preprint arXiv:2604.21505, 2026
Pith/arXiv arXiv 2026
-
[3]
J. L. C. Guo, J.-P. Steghöfer, A. V ogelsang, and J. Cleland-Huang, Natural Language Processing for Requirements Traceability. Springer Nature Switzerland, 2025, pp. 89–116
2025
-
[4]
Characterizing datasets for LLM-based requirements engineering: A systematic mapping study,
Q. Motger, C. Catot, and X. Franch, “Characterizing datasets for LLM-based requirements engineering: A systematic mapping study,” inInternational Conference on Evaluation and Assessment in Software Engineering (EASE). ACM, 2026
2026
-
[5]
A survey on large language models for code generation,
J. Jiang, F. Wang, J. Shen, S. Kim, and S. Kim, “A survey on large language models for code generation,”ACM Transactions on Software Engineering and Methodology (TOSEM), vol. 35, no. 2, pp. 1–72, 2026
2026
-
[6]
Synthline: A product line approach for synthetic requirements engineering data generation using large language models,
A. El-Hajjami and C. Salinesi, “Synthline: A product line approach for synthetic requirements engineering data generation using large language models,” inInternational Conference on Research Challenges in Information Science. Springer, 2025, pp. 208–225
2025
-
[7]
Bridging the gap between source code and requirements using GPT (student abstract),
R. Xu, Z. Xu, G. Li, and V . S. Sheng, “Bridging the gap between source code and requirements using GPT (student abstract),” inAAAI Conference on Artificial Intelligence, vol. 38, no. 21, 2024, pp. 23 686– 23 687
2024
-
[8]
Intelligent traceability to support software main- tainability and accountability,
K. R. Dearstyne, “Intelligent traceability to support software main- tainability and accountability,” inIEEE International Requirements Engineering Conference (RE). IEEE, 2025, pp. 607–611
2025
-
[9]
R2Code: A self-reflective LLM framework for requirements-to-code traceability,
Y . Wang, J. Keung, X. Ma, Z. Mao, K. Chen, and Y . Li, “R2Code: A self-reflective LLM framework for requirements-to-code traceability,” arXiv preprint arXiv:2604.22432, 2026
Pith/arXiv arXiv 2026
-
[10]
Rapid quality assurance with requirements smells,
H. Femmer, D. Méndez Fernández, S. Wagner, and S. Eder, “Rapid quality assurance with requirements smells,”Journal of Systems and Software (JSS), vol. 123, pp. 190–213, 2017
2017
-
[11]
Characterizing requirements smells,
E. Gentili and D. Falessi, “Characterizing requirements smells,” inInter- national Conference on Product-Focused Software Process Improvement (PROFES). Springer, 2023, pp. 387–398
2023
-
[12]
Datasets from fifteen years of automated requirements traceability research: Current state, characteristics, and quality,
W. Zogaan, P. Sharma, M. Mirahkorli, and V . Arnaoudova, “Datasets from fifteen years of automated requirements traceability research: Current state, characteristics, and quality,” inIEEE International Re- quirements Engineering Conference (RE). IEEE, 2017, pp. 110–121
2017
-
[13]
UserTrace: User-level requirements generation and traceability recovery from software project repositories,
D. Jin, Z. Jin, Y . Zhang, Z. Fang, L. Li, Y . He, X. Chen, and W. Sun, “UserTrace: User-level requirements generation and traceability recovery from software project repositories,” 2025
2025
-
[14]
LiSSA: Toward generic traceability link recovery through retrieval- augmented generation,
D. Fuchß, T. Hey, J. Keim, H. Liu, N. Ewald, T. Thirolf, and A. Koziolek, “LiSSA: Toward generic traceability link recovery through retrieval- augmented generation,” inIEEE/ACM International Conference on Software Engineering (ICSE). IEEE, 2025, pp. 1396–1408
2025
-
[15]
Improving the effectiveness of traceability link recovery using hierarchical bayesian networks,
K. Moran, D. N. Palacio, C. Bernal-Cárdenas, D. McCrystal, D. Poshy- vanyk, C. Shenefiel, and J. Johnson, “Improving the effectiveness of traceability link recovery using hierarchical bayesian networks,” in ACM/IEEE International Conference on Software Engineering (ICSE). ACM, 2020, pp. 873–885
2020
-
[16]
Establishing traceability between natural language requirements and software artifacts by combining RAG and LLMs,
S. J. Ali, V . Naganathan, and D. Bork, “Establishing traceability between natural language requirements and software artifacts by combining RAG and LLMs,” inInternational Conference on Conceptual Modeling (ER). Springer, 2024, pp. 295–314
2024
-
[17]
Improving traceability link recovery using fine-grained requirements-to-code relations,
T. Hey, F. Chen, S. Weigelt, and W. F. Tichy, “Improving traceability link recovery using fine-grained requirements-to-code relations,” in IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, 2021, pp. 12–22
2021
-
[18]
Traceability transformed: Generating more accurate links with pre-trained BERT models,
J. Lin, Y . Liu, Q. Zeng, M. Jiang, and J. Cleland-Huang, “Traceability transformed: Generating more accurate links with pre-trained BERT models,” inIEEE/ACM International Conference on Software Engineer- ing (ICSE). IEEE, 2021, pp. 324–335
2021
-
[19]
Code2Req: Using generative AI to generate requirements from source code,
E. Persson, E. Alégroth, and T. Gorschek, “Code2Req: Using generative AI to generate requirements from source code,” 2025. [Online]. Available: http://dx.doi.org/10.2139/ssrn.5845431
-
[20]
Scaling retrieval-based language models with a trillion- token datastore,
R. Shao, J. He, A. Asai, W. Shi, T. Dettmers, S. Min, L. Zettlemoyer, and P. W. Koh, “Scaling retrieval-based language models with a trillion- token datastore,”Advances in Neural Information Processing Systems, vol. 37, pp. 91 260–91 299, 2024
2024
-
[21]
On the impact of requirements smells in prompts: The case of automated traceability,
A. V ogelsang, A. Korn, G. Broccia, A. Ferrari, J. Fischbach, and C. Arora, “On the impact of requirements smells in prompts: The case of automated traceability,” inIEEE/ACM International Conference on Software Engineering: New Ideas and Emerging Results (ICSE-NIER), 2025, pp. 51–55
2025
-
[22]
Context-adaptive requirements defect prediction through human-LLM collaboration,
M. Unterbusch and A. V ogelsang, “Context-adaptive requirements defect prediction through human-LLM collaboration,” inIEEE/ACM Interna- tional Conference on Software Engineering: New Ideas and Emerging Results (ICSE-NIER), 2026
2026
-
[23]
Reporting guidelines for controlled ex- periments in software engineering,
A. Jedlitschka and D. Pfahl, “Reporting guidelines for controlled ex- periments in software engineering,” inInternational Symposium on Empirical Software Engineering (ESEM), 2005
2005
-
[24]
LLM- based class diagram derivation from user stories with chain-of-thought promptings,
Y . Li, J. Keung, X. Ma, C. Y . Chong, J. Zhang, and Y . Liao, “LLM- based class diagram derivation from user stories with chain-of-thought promptings,” inIEEE 48th Annual Computers, Software, and Applica- tions Conference (COMPSAC). IEEE, 2024, pp. 45–50
2024
-
[25]
Requirements Quality Is Quality in Use,
H. Femmer and A. V ogelsang, “Requirements Quality Is Quality in Use,” IEEE Software, vol. 36, no. 3, pp. 83–91, May 2019
2019
-
[26]
Identifying Relevant Factors of Requirements Quality: An Industrial Case Study,
J. Frattini, “Identifying Relevant Factors of Requirements Quality: An Industrial Case Study,” inRequirements Engineering: Foundation for Software Quality, D. Mendez and A. Moreira, Eds. Cham: Springer Nature Switzerland, 2024, pp. 20–36
2024
-
[27]
Reporting LLM prompting in automated software engineering: A guideline based on current practices and expectations,
A. Korn, L. Zaruchas, C. Arora, A. Metzger, S. Smolka, F. Wang, and A. V ogelsang, “Reporting LLM prompting in automated software engineering: A guideline based on current practices and expectations,” in ACM International Conference on AI Foundation Models and Software Engineering (FORGE), 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.