Sculpting NeRF Geometry: Human-Preference Fine-Tuning of a 3D-Aware Face GAN
Pith reviewed 2026-06-26 05:31 UTC · model grok-4.3
The pith
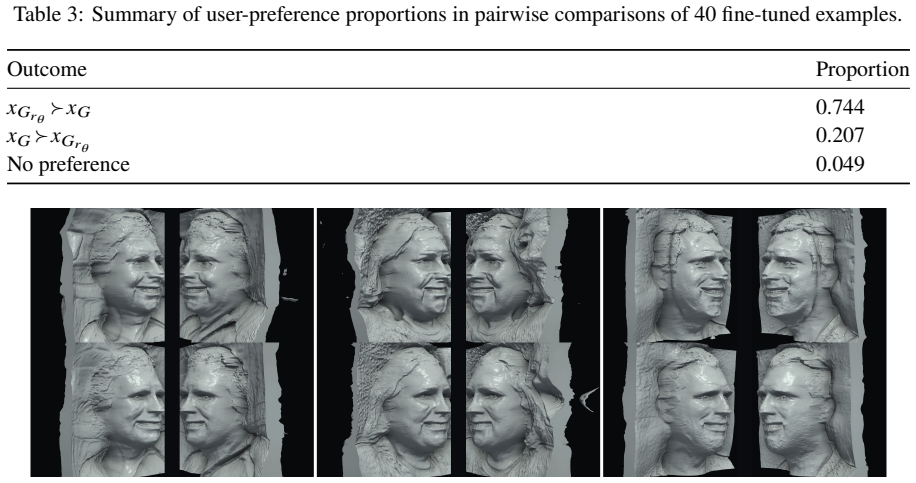
Human preferences on NeRF density fine-tune a 3D face GAN to produce geometries preferred in 74.4% of comparisons.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
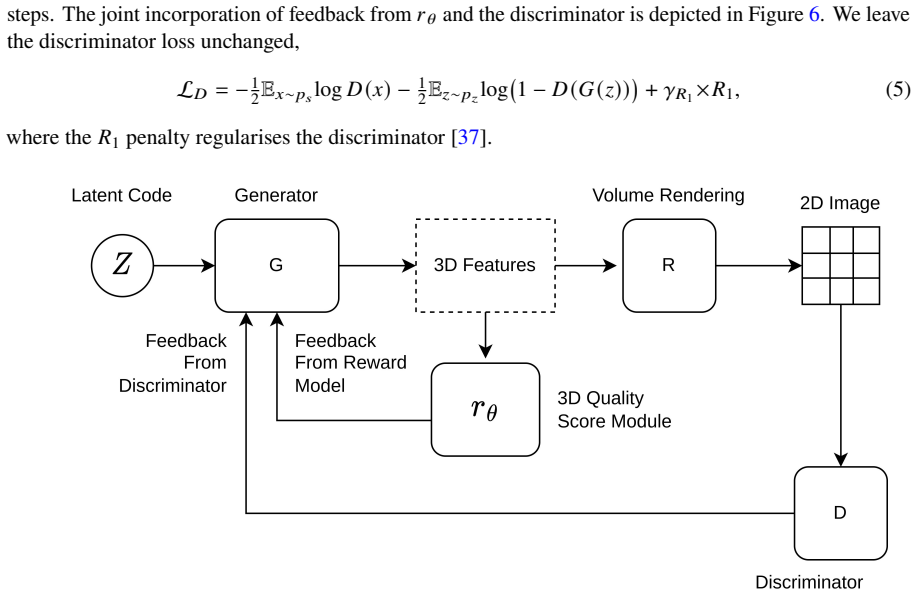
Core claim
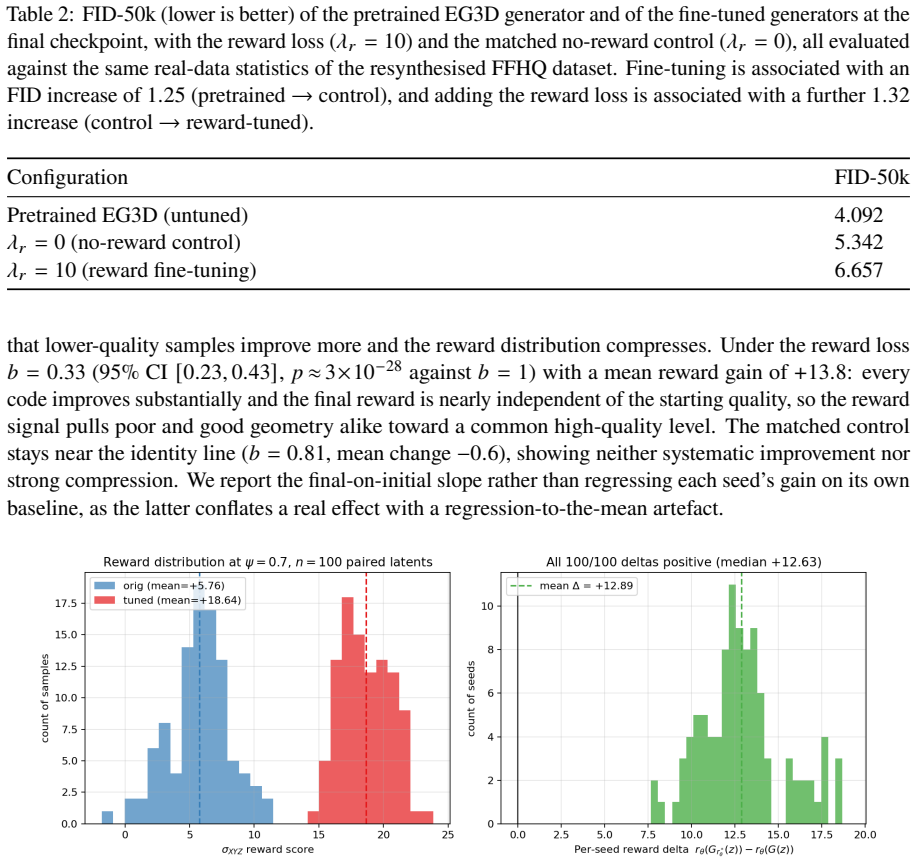
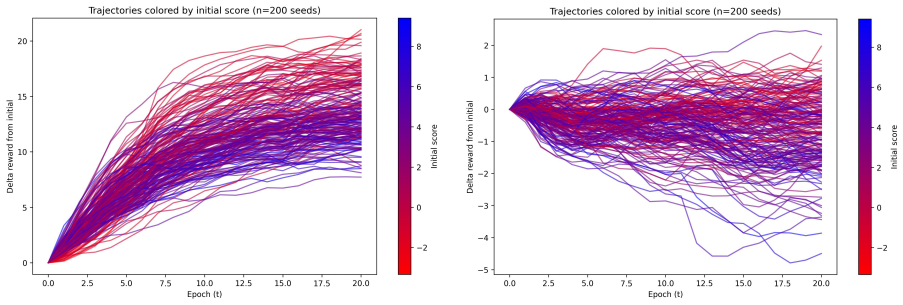
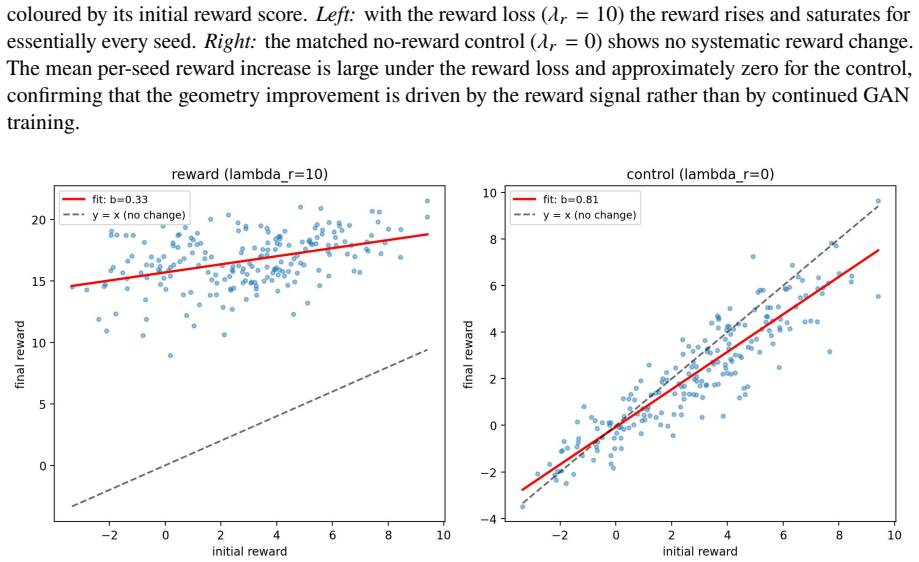
Working on an unconditional 3D-aware face GAN, the authors learn a reward directly from the 3D density field of the NeRF and apply it during fine-tuning under a density-consistency constraint. This produces face geometries preferred by users in 74.4% of pairwise comparisons without text conditioning, mesh extraction, or multi-view rendering, at a bounded distributional cost.
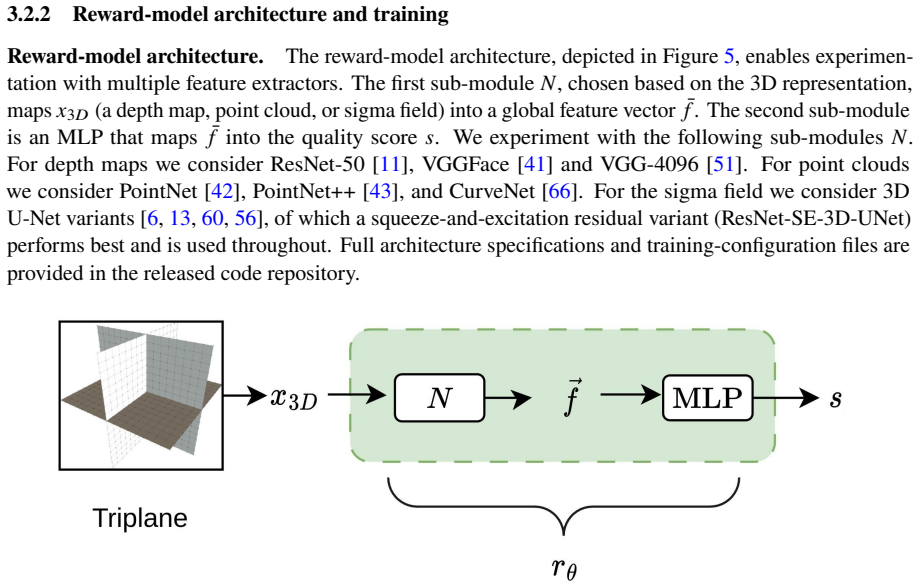
What carries the argument
A reward model that reads the continuous 3D density field of the NeRF directly to supply a geometry-only learning signal, together with a density-consistency constraint that preserves 2D appearance during reshaping.
If this is right
- Geometry can be reshaped directly inside the radiance field without converting to meshes or supplying external shape priors.
- 2D appearance remains close enough that FID increases only from 4.09 to 6.66.
- A small preference set collected from a single annotator is enough to train an effective reward model.
- The same pipeline demonstrates RLHF applied to 3D-aware GANs without multi-view rendering or surface supervision.
Where Pith is reading between the lines
- The density-based reward could be tested on other unconditional 3D generators to see if the approach generalizes beyond faces.
- Skipping mesh extraction steps may reduce compute in future preference-tuning pipelines for 3D models.
- Very small numbers of annotations per user could enable practical personalization of 3D face generators.
- The bounded FID cost suggests the method can be combined with other signals if density consistency proves robust across domains.
Load-bearing premise
The density-consistency constraint keeps the 2D appearance qualitatively similar while the geometry is reshaped.
What would settle it
A larger user study that measures whether the 74.4% preference rate holds across multiple annotators or drops when the density-consistency constraint is ablated and appearance changes become visible.
Figures


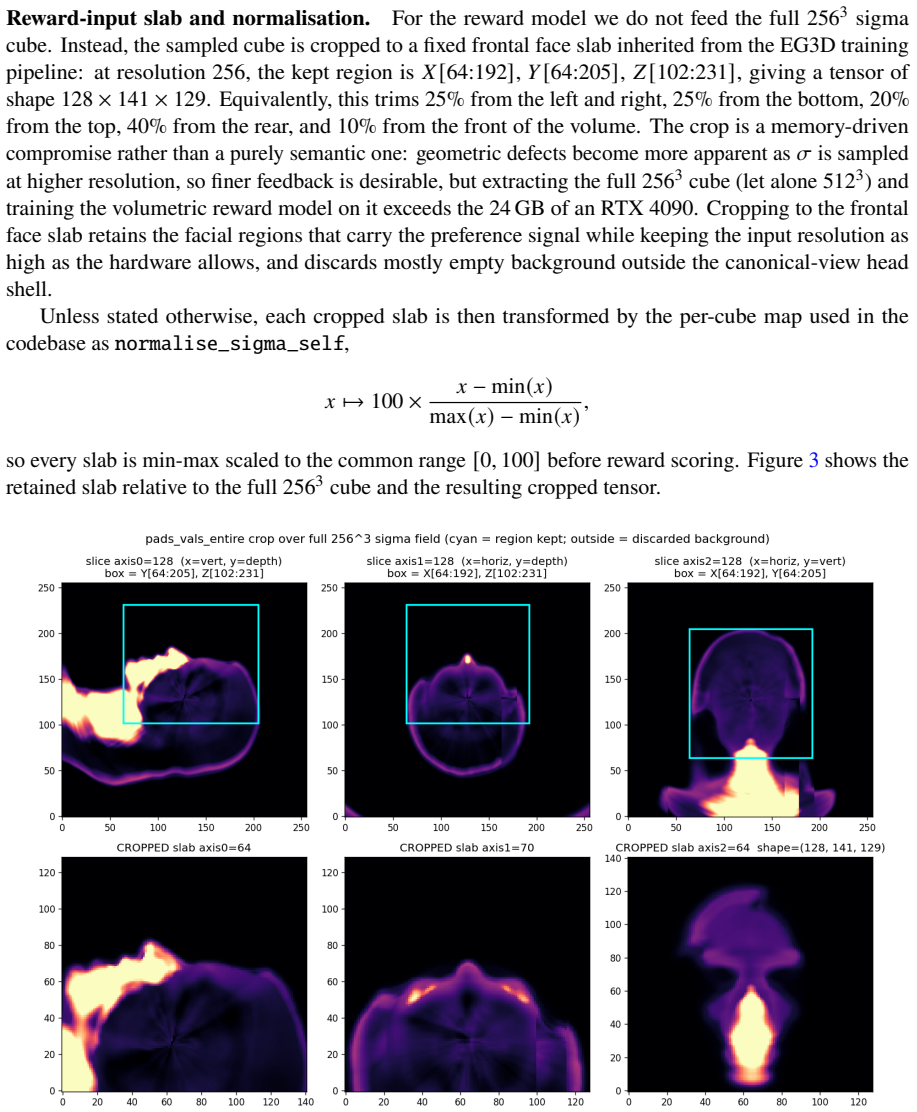
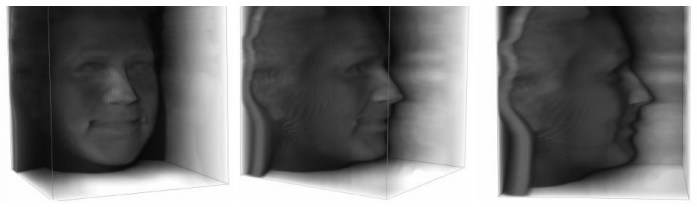
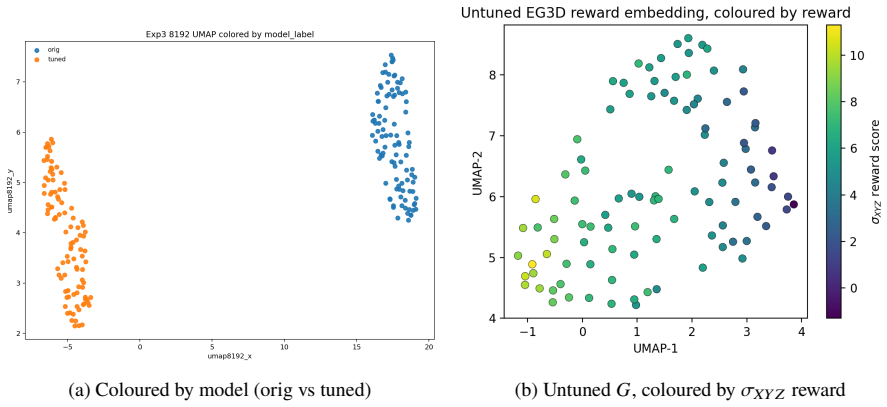



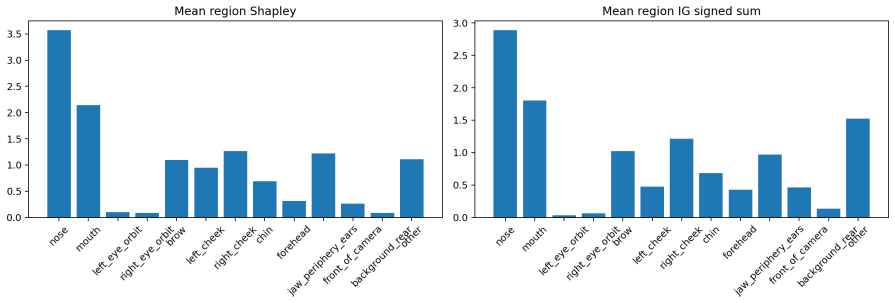

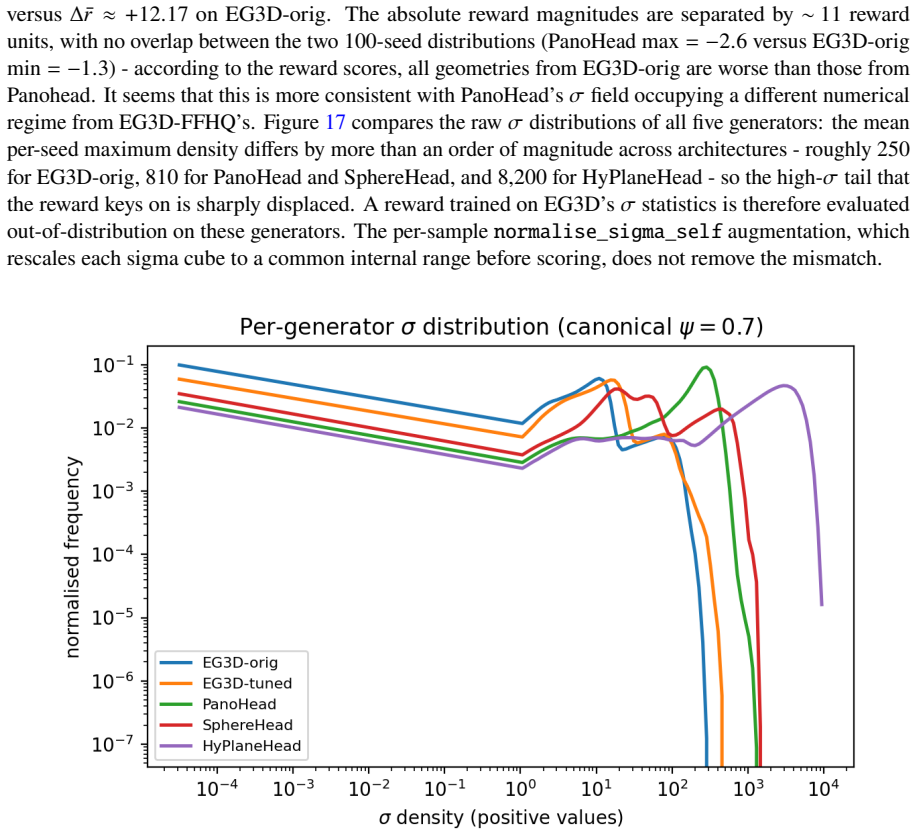
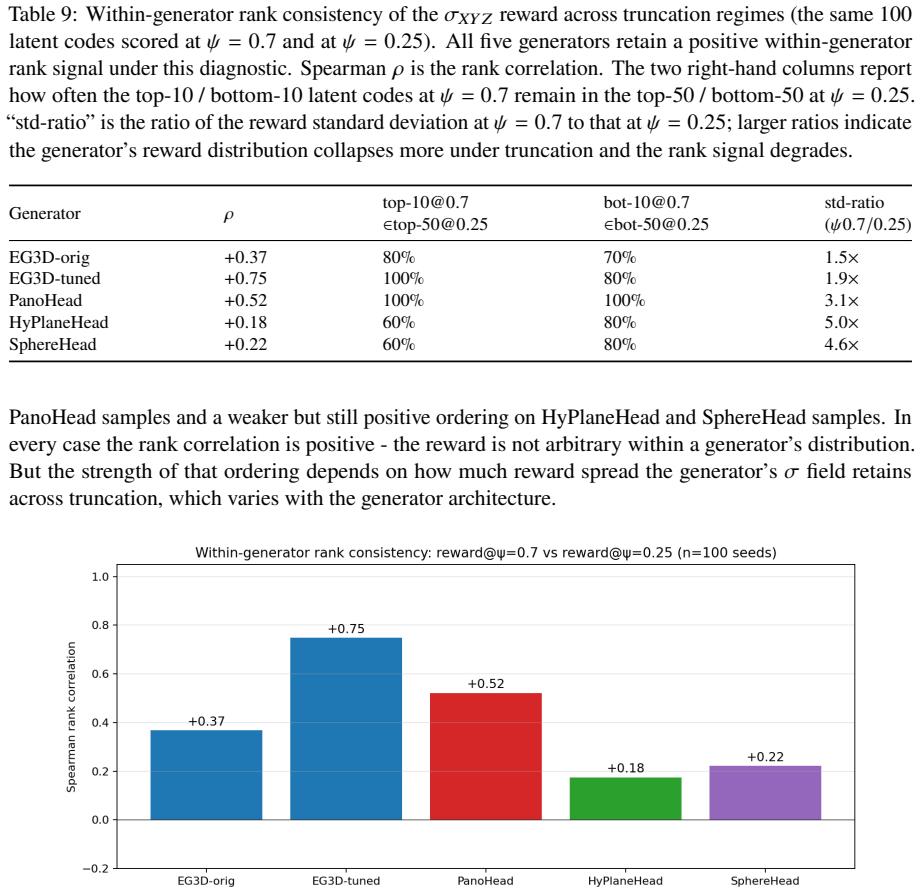


read the original abstract
Reinforcement learning from human feedback (RLHF) for 3D generation is now established across a number of works, but most existing pipelines optimise explicit surface representations, often by converting radiance fields into meshes and training heavily on surface-supervised data. We instead fine-tune a pretrained 3D-aware generative model directly from a learned reward over radiance-field density ($\sigma$) values, with no externally supplied mesh or shape prior. The reward model requires no pretraining, trains easily on a small set of preference samples, and yields robust improvement in 3D geometry. Working on an unconditional 3D-aware face GAN (EG3D), our reward reads the continuous 3D density field of the neural radiance field (NeRF) directly and supplies a geometry-only learning signal, requiring neither text conditioning, mesh extraction, nor multi-view rendering. A density-consistency constraint keeps the 2D appearance qualitatively similar while the geometry is reshaped, at a measurable but bounded distributional cost (FID-50k rises from 4.09 to 6.66): the fine-tuned generator, trained from the preferences of a single annotator as a proof of concept, produces face geometries preferred by users in 74.4% of pairwise comparisons.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a method for fine-tuning a pretrained 3D-aware face GAN (EG3D) via RLHF applied directly to the NeRF density field σ, using a reward model trained on human preference samples without mesh extraction or multi-view rendering. A density-consistency constraint is introduced to preserve 2D appearance during geometry reshaping. As a single-annotator proof of concept, the approach yields a 74.4% user preference win rate in pairwise comparisons, with FID-50k rising from 4.09 to 6.66.
Significance. If the central empirical result holds under proper controls, the work demonstrates a lightweight, mesh-free route to geometry improvement in unconditional 3D GANs by optimizing the density field from preferences. The absence of external shape priors and the direct use of the σ-field constitute a clear methodological distinction from mesh-conversion pipelines; the reported FID bound and user-study win rate provide a concrete, falsifiable benchmark.
major comments (2)
- [Abstract] Abstract, final paragraph: the claim that the density-consistency constraint 'keeps the 2D appearance qualitatively similar while the geometry is reshaped' is load-bearing for attributing the 74.4% preference gain to geometry rather than correlated appearance shifts, yet no geometry-specific verification (multi-view depth/normal consistency, surface-normal variance, or rendered depth-map comparisons) is described; the moderate FID rise alone does not rule out appearance leakage.
- [Abstract] Abstract: the 74.4% pairwise preference result is presented without any description of the reward-model architecture, training procedure, number of preference samples, statistical testing, or how single-annotator labels were collected and validated; these omissions make the central user-study claim impossible to assess for robustness.
minor comments (1)
- The manuscript would benefit from an explicit equation or pseudocode block defining the density-consistency loss term and its weighting relative to the preference reward.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript accordingly to improve clarity and support for the central claims.
read point-by-point responses
-
Referee: [Abstract] Abstract, final paragraph: the claim that the density-consistency constraint 'keeps the 2D appearance qualitatively similar while the geometry is reshaped' is load-bearing for attributing the 74.4% preference gain to geometry rather than correlated appearance shifts, yet no geometry-specific verification (multi-view depth/normal consistency, surface-normal variance, or rendered depth-map comparisons) is described; the moderate FID rise alone does not rule out appearance leakage.
Authors: We agree that the abstract's claim would be strengthened by explicit geometry-specific metrics beyond FID. The density-consistency constraint operates directly on the σ-field to limit appearance drift, but the current manuscript does not report multi-view depth or normal consistency checks. In revision we will add quantitative comparisons of rendered depth maps and surface normals across views in the experiments section, and update the abstract to reference these results. This directly addresses the concern about potential appearance leakage. revision: yes
-
Referee: [Abstract] Abstract: the 74.4% pairwise preference result is presented without any description of the reward-model architecture, training procedure, number of preference samples, statistical testing, or how single-annotator labels were collected and validated; these omissions make the central user-study claim impossible to assess for robustness.
Authors: The abstract summarizes the result as a single-annotator proof of concept. The full manuscript describes the reward model (a lightweight MLP reading σ values), the collection of preference pairs, and the training procedure in Section 3. However, we acknowledge that the abstract itself lacks these specifics and that statistical testing details (e.g., binomial test p-value) are not highlighted. We will expand the abstract with a concise description of the reward model, sample count, and validation approach, and ensure the main text includes explicit statistical analysis of the 74.4% win rate. revision: yes
Circularity Check
No circularity: empirical fine-tuning with external human evaluation
full rationale
The paper describes an empirical RLHF-style fine-tuning procedure on a pretrained EG3D model, using a reward derived from human preference samples over NeRF density values and a density-consistency constraint. Performance is assessed via external user pairwise comparisons (74.4% preference) and FID metric. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains are present in the provided text. The central claim reduces to measured outcomes against independent human judgments rather than any internal reduction to inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ogras, and Linjie Luo
Sizhe An, Hongyi Xu, Yichun Shi, Guoxian Song, Umit Y. Ogras, and Linjie Luo. PanoHead: Geometry-aware 3D full-head synthesis in 360 degrees. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
2023
-
[2]
Chan, Marco Monteiro, Petr Kellnhofer, Jiajun Wu, and Gordon Wetzstein
Eric R. Chan, Marco Monteiro, Petr Kellnhofer, Jiajun Wu, and Gordon Wetzstein. pi-GAN: Periodic implicit generative adversarial networks for 3D-aware image synthesis.arXiv preprint arXiv:2012.00926, 2020
arXiv 2012
-
[3]
Chan, Connor Z
Eric R. Chan, Connor Z. Lin, Matthew A. Chan, Koki Nagano, Boxiao Pan, Shalini De Mello, Orazio Gallo, Leonidas J. Guibas, Jonathan Tremblay, Sameh Khamis, Tero Karras, and Gordon Wetzstein. Efficient geometry-aware 3D generative adversarial networks. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022
2022
-
[4]
Victoria Yue Chen, Emery Pierson, Léopold Maillard, and Maks Ovsjanikov. Beyond prompts: Unconditional 3D inversion for out-of-distribution shapes.arXiv preprint arXiv:2604.14914, 2026
Pith/arXiv arXiv 2026
-
[5]
Christiano, Jan Leike, Tom B
Paul F. Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. InAdvances in Neural Information Processing Systems, 2017
2017
-
[6]
Lienkamp, Thomas Brox, and Olaf Ronneberger
Özgün Çiçek, Ahmed Abdulkadir, Soeren S. Lienkamp, Thomas Brox, and Olaf Ronneberger. 3D U-Net: Learning dense volumetric segmentation from sparse annotation. InMedical Image Computing and Computer-Assisted Intervention (MICCAI), pages 424–432, 2016
2016
-
[7]
Routledge, 2013
Jacob Cohen.Statistical Power Analysis for the Behavioral Sciences. Routledge, 2013
2013
-
[8]
Morphable face models – an open framework
Thomas Gerig, Andreas Morel-Forster, Clemens Blumer, Bernhard Egger, Marcel Luthi, Sandro Schönborn, and Thomas Vetter. Morphable face models – an open framework. In2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), pages 75–82, 2018
2018
-
[9]
Jiatao Gu, Lingjie Liu, Peng Wang, and Christian Theobalt. StyleNeRF: A style-based 3D-aware generator for high-resolution image synthesis.arXiv preprint arXiv:2110.08985, 2021. 32
arXiv 2021
-
[10]
HuTuMotion: Human-tuned navigation of latent motion diffusion models with minimal feedback
Gaoge Han, Shaoli Huang, Mingming Gong, and Jinglei Tang. HuTuMotion: Human-tuned navigation of latent motion diffusion models with minimal feedback. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 2031–2039, 2024
2031
-
[11]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InIEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016
2016
-
[12]
AlecHelbling,ChristopherJ.Rozell,MatthewO’Shaughnessy,andKionFallah.PrefGen: Preference guided image generation with relative attributes.arXiv preprint arXiv:2304.00185, 2023
arXiv 2023
-
[13]
Squeeze-and-excitationnetworks
JieHu,LiShen,andGangSun. Squeeze-and-excitationnetworks. InIEEEConferenceonComputer Vision and Pattern Recognition, pages 7132–7141, 2018
2018
-
[14]
DreamControl: Control-based text-to-3D generation with 3D self-prior
Tianyu Huang, Yihan Zeng, Zhilu Zhang, Wan Xu, Hang Xu, Songcen Xu, WH Lau Ryson, and Wangmeng Zuo. DreamControl: Control-based text-to-3D generation with 3D self-prior. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5364–5373, 2024
2024
-
[15]
HumanNorm: Learning normal diffusion model for high-quality and realistic 3D human generation
Xin Huang, Ruizhi Shao, Qi Zhang, Hongwen Zhang, Ying Feng, Yebin Liu, and Qing Wang. HumanNorm: Learning normal diffusion model for high-quality and realistic 3D human generation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4568–4577, 2024
2024
-
[16]
Pixel-in-pixel net: Towards efficient facial landmark detection in the wild.International Journal of Computer Vision, 129(12):3174–3194, 2021
Haibo Jin, Shengcai Liao, and Ling Shao. Pixel-in-pixel net: Towards efficient facial landmark detection in the wild.International Journal of Computer Vision, 129(12):3174–3194, 2021
2021
-
[17]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4401–4410, 2019. Source of the FFHQ dataset used to train EG3D
2019
-
[18]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019. Source of FFHQ dataset
2019
-
[19]
Alias-free generative adversarial networks
TeroKarras,MiikaAittala,SamuliLaine,ErikHärkönen,JanneHellsten,JaakkoLehtinen,andTimo Aila. Alias-free generative adversarial networks. InAdvances in Neural Information Processing Systems, 2021
2021
-
[20]
Preference-based image generation
Hadi Kazemi, Fariborz Taherkhani, and Nasser Nasrabadi. Preference-based image generation. In IEEE/CVF Winter Conference on Applications of Computer Vision, 2020
2020
-
[21]
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
Pith/arXiv arXiv 2014
-
[22]
Understanding the effects of RLHF on LLM generalisation and diversity
Robert Kirk, Ishita Mediratta, Christoforos Nalmpantis, Jelena Luketina, Eric Hambro, Edward Grefenstette, and Roberta Raileanu. Understanding the effects of RLHF on LLM generalisation and diversity. InInternational Conference on Learning Representations, 2024
2024
-
[23]
Pick-a-Pic: An open dataset of user preferences for text-to-image generation
Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Matiana, Joe Penna, and Omer Levy. Pick-a-Pic: An open dataset of user preferences for text-to-image generation. InAdvances in Neural Information Processing Systems, 2023
2023
-
[24]
Fast radiance field reconstruction from sparse inputs.Pattern Recognition, 157, 2025
Song Lai, Linyan Cui, and Jihao Yin. Fast radiance field reconstruction from sparse inputs.Pattern Recognition, 157, 2025. doi: 10.1016/j.patcog.2024.110863
-
[25]
LN3Diff: Scalable latent neural fields diffusion for speedy 3D generation
Yushi Lan, Fangzhou Hong, Shuai Yang, Shangchen Zhou, Xuyi Meng, Bo Dai, Xingang Pan, and Chen Change Loy. LN3Diff: Scalable latent neural fields diffusion for speedy 3D generation. In European Conference on Computer Vision, 2024. 33
2024
-
[26]
SphereHead: Stable 3D full-head synthesis with spherical tri-plane representation
Heyuan Li, Ce Chen, Tianhao Shi, Yuda Qiu, Sizhe An, Guanying Chen, and Xiaoguang Han. SphereHead: Stable 3D full-head synthesis with spherical tri-plane representation. InEuropean Conference on Computer Vision, pages 324–341. Springer, 2024
2024
-
[27]
HyPlaneHead: Rethinking tri-plane-like representations in full-head image synthesis
Heyuan Li, Kenkun Liu, Lingteng Qiu, Qi Zuo, Keru Zheng, Zilong Dong, and Xiaoguang Han. HyPlaneHead: Rethinking tri-plane-like representations in full-head image synthesis. InAdvances in Neural Information Processing Systems, 2025. arXiv:2509.16748
arXiv 2025
-
[28]
CraftsMan3D:High-fidelitymeshgenerationwith3Dnativediffusionand interactivegeometryrefiner
Weiyu Li, Jiarui Liu, Hongyu Hu, Rui Chen, Yixun Liu, Cheng Tan, Xuan Lin, Jingwei Tang, Junjie Zhao,XiaoxiaoLiu,etal. CraftsMan3D:High-fidelitymeshgenerationwith3Dnativediffusionand interactivegeometryrefiner. InIEEE/CVFConferenceonComputerVisionandPatternRecognition, 2025
2025
-
[29]
Yuanzhi Liang, Yijie Fang, Rui Li, Ziqi Ni, Ruijie Su, and Chi Zhang. Integrating reinforcement learning with visual generative models: Foundations and advances.Vicinagearth, 3(1):2, 2026. doi: 10.1007/s44336-025-00030-z. arXiv:2508.10316
-
[30]
Fangfu Liu, Junliang Ye, Yikai Wang, Hanyang Wang, Zhengyi Wang, Jun Zhu, and Yueqi Duan. DreamReward-X: Boosting high-quality 3D generation with human preference alignment.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025. doi: 10.1109/TPAMI.2025. 3609680
-
[31]
DreamAlign: Dynamic text-to-3D optimization with human preference alignment
Gaofeng Liu, Zhiyuan Ma, and Tao Fang. DreamAlign: Dynamic text-to-3D optimization with human preference alignment. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 5424–5432, 2025
2025
-
[32]
Mesh-RFT:Enhancingmeshgeneration via fine-grained reinforcement fine-tuning
Jian Liu, Jing Xu, Song Guo, Jing Li, Jingfeng Guo, Jiaao Yu, Haohan Weng, Biwen Lei, Xianghui Yang,ZhuoChen,FangqiZhu,TaoHan,andChunchaoGuo. Mesh-RFT:Enhancingmeshgeneration via fine-grained reinforcement fine-tuning. InAdvances in Neural Information Processing Systems (Spotlight), 2025
2025
-
[33]
Qingming Liu, Zhen Liu, Dinghuai Zhang, and Kui Jia. Nabla-R2D3: Effective and efficient 3D diffusion alignment with 2D rewards.arXiv preprint arXiv:2506.15684, 2025
arXiv 2025
-
[34]
Point cloud quality assessment: Dataset con- struction and learning-based no-reference metric.ACM Transactions on Multimedia Computing, Communications and Applications, 2022
Yipeng Liu, Qi Yang, Yiling Xu, and Le Yang. Point cloud quality assessment: Dataset con- struction and learning-based no-reference metric.ACM Transactions on Multimedia Computing, Communications and Applications, 2022
2022
-
[35]
Lorensen and Harvey E
William E. Lorensen and Harvey E. Cline. Marching cubes: A high resolution 3D surface construction algorithm.ACM SIGGRAPH Computer Graphics, 21(4):163–169, 1987
1987
-
[36]
Aunifiedapproachtointerpretingmodelpredictions
ScottM.LundbergandSu-InLee. Aunifiedapproachtointerpretingmodelpredictions. InAdvances in Neural Information Processing Systems, 2017
2017
-
[37]
Which training methods for GANs do actually converge? InInternational Conference on Machine Learning, pages 3481–3490, 2018
Lars Mescheder, Andreas Geiger, and Sebastian Nowozin. Which training methods for GANs do actually converge? InInternational Conference on Machine Learning, pages 3481–3490, 2018
2018
-
[38]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. NeRF: Representing scenes as neural radiance fields for view synthesis. InEuropean Conference on Computer Vision, 2020
2020
-
[39]
High-fidelity 3D reconstruction via unified NeRF-mesh optimization with geometric and color consistency.Pattern Recognition, 170:112071,
Rama Bastola Neupane, Kan Li, and Zhuqing Mao. High-fidelity 3D reconstruction via unified NeRF-mesh optimization with geometric and color consistency.Pattern Recognition, 170:112071,
-
[40]
doi: 10.1016/j.patcog.2025.112071. 34
-
[41]
Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.arXiv preprint arXiv:2203.02155, 2022
Pith/arXiv arXiv 2022
-
[42]
Parkhi, Andrea Vedaldi, and Andrew Zisserman
Omkar M. Parkhi, Andrea Vedaldi, and Andrew Zisserman. Deep face recognition. InBritish Machine Vision Conference (BMVC), 2015
2015
-
[43]
Qi, Hao Su, Kaichun Mo, and Leonidas J
Charles R. Qi, Hao Su, Kaichun Mo, and Leonidas J. Guibas. PointNet: Deep learning on point sets for 3D classification and segmentation. InIEEE Conference on Computer Vision and Pattern Recognition, 2017
2017
-
[44]
Qi, Li Yi, Hao Su, and Leonidas J
Charles R. Qi, Li Yi, Hao Su, and Leonidas J. Guibas. PointNet++: Deep hierarchical feature learning on point sets in a metric space. InAdvances in Neural Information Processing Systems, 2017
2017
-
[45]
Pivotaltuningforlatent-based editing of real images.ACM Transactions on Graphics, 42(1):1–13, 2022
DanielRoich,RonMokady,AmitH.Bermano,andDanielCohen-Or. Pivotaltuningforlatent-based editing of real images.ACM Transactions on Graphics, 42(1):1–13, 2022
2022
-
[46]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[47]
GRAF: Generative radiance fields for 3D-aware image synthesis
Katja Schwarz, Yiyi Liao, Michael Niemeyer, and Andreas Geiger. GRAF: Generative radiance fields for 3D-aware image synthesis. InAdvances in Neural Information Processing Systems, 2020
2020
-
[48]
Lloyd S. Shapley. A value for n-person games.Contributions to the Theory of Games, 2, 1953
1953
-
[49]
Deep marching tetrahedra: a hybrid representation for high-resolution 3D shape synthesis
Tianchang Shen, Jun Gao, Kangxue Yin, Ming-Yu Liu, and Sanja Fidler. Deep marching tetrahedra: a hybrid representation for high-resolution 3D shape synthesis. InAdvances in Neural Information Processing Systems, 2021
2021
-
[50]
Deep generative models on 3D representations: A survey.arXiv preprint arXiv:2210.15663, 2022
Zifan Shi, Sida Peng, Yinghao Xu, Yiyi Liao, and Yujun Shen. Deep generative models on 3D representations: A survey.arXiv preprint arXiv:2210.15663, 2022
arXiv 2022
-
[51]
Improving 3D-aware image synthesis with a geometry-aware discriminator
Zifan Shi, Yinghao Shen, Yujun Xu, Yiyi Liao, Deli Yueqian, Qifeng Zhao, and Dit-Yan Yeung. Improving 3D-aware image synthesis with a geometry-aware discriminator. InAdvances in Neural Information Processing Systems, 2022
2022
-
[52]
Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition.arXiv preprint arXiv:1409.1556, 2014
Pith/arXiv arXiv 2014
-
[53]
EpiGRAF: Rethinking training of 3D GANs
Ivan Skorokhodov, Sergey Tulyakov, Yiqun Wang, and Peter Wonka. EpiGRAF: Rethinking training of 3D GANs. InAdvances in Neural Information Processing Systems, 2022
2022
-
[54]
Learning to summarize from human feedback.arXiv preprint arXiv:2009.01325, 2020
NisanStiennon, LongOuyang, JeffWu, DanielM.Ziegler, RyanLowe, ChelseaVoss, AlecRadford, Dario Amodei, and Paul Christiano. Learning to summarize from human feedback.arXiv preprint arXiv:2009.01325, 2020
Pith/arXiv arXiv 2009
-
[55]
Axiomatic attribution for deep networks
Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomatic attribution for deep networks. In International Conference on Machine Learning, pages 3319–3328, 2017
2017
-
[56]
Zhiwei Tang, Dmitry Rybin, and Tsung-Hui Chang. Zeroth-order optimization meets human feedback: Provable learning via ranking oracles.arXiv preprint arXiv:2303.03751, 2023
arXiv 2023
-
[57]
Deep learning semantic segmentation for high-resolution medical volumes
Imad Eddine Toubal, Ye Duan, and Deshan Yang. Deep learning semantic segmentation for high-resolution medical volumes. In2020 IEEE Applied Imagery Pattern Recognition Workshop (AIPR), pages 1–9. IEEE, 2020. 35
2020
-
[58]
MVReward: Better aligning and evaluating multi-view diffusion models with human preferences
Weitao Wang, Haoran Xu, Yuxiao Yang, Zhifang Liu, Jun Meng, and Haoqian Wang. MVReward: Better aligning and evaluating multi-view diffusion models with human preferences. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 7898–7906, 2025
2025
-
[59]
Single image, any face: Generalisable 3D face generation.Pattern Recognition, 178, 2026
Wenqing Wang, Haosen Yang, Josef Kittler, and Xiatian Zhu. Single image, any face: Generalisable 3D face generation.Pattern Recognition, 178, 2026. doi: 10.1016/j.patcog.2026.113375. In press; preprint: arXiv:2409.16990
-
[60]
LLaMA-Mesh: Unifying 3D mesh generation with language models.arXiv preprint arXiv:2411.09595, 2024
Zhengyi Wang, Jonathan Lorraine, Yikai Wang, Hang Su, Jun Zhu, Sanja Fidler, and Xiaohui Zeng. LLaMA-Mesh: Unifying 3D mesh generation with language models.arXiv preprint arXiv:2411.09595, 2024
arXiv 2024
-
[61]
Accurate and versatile 3D segmentation of plant tissues at cellular resolution.Elife, 9:e57613, 2020
Adrian Wolny, Lorenzo Cerrone, Athul Vijayan, Rachele Tofanelli, Amaya Vilches Barro, Marion Louveaux, Christian Wenzl, Sören Strauss, David Wilson-Sánchez, Rena Lymbouridou, et al. Accurate and versatile 3D segmentation of plant tissues at cellular resolution.Elife, 9:e57613, 2020
2020
-
[62]
GPT-4V(ision) is a human-aligned evaluator for text-to-3D generation
Tong Wu, Guandao Yang, Zhibing Li, Kai Zhang, Ziwei Liu, Leonidas Guibas, Dahua Lin, and Gordon Wetzstein. GPT-4V(ision) is a human-aligned evaluator for text-to-3D generation. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22227–22238, 2024
2024
-
[63]
Look at boundary: A boundary-aware face alignment algorithm
Wayne Wu, Chen Qian, Shuo Yang, Quan Wang, Yici Cai, and Qiang Zhou. Look at boundary: A boundary-aware face alignment algorithm. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2129–2138, 2018
2018
-
[64]
Reinforcement learning for large model: A survey.arXiv preprint arXiv:2508.08189, 2025
Weijia Wu, Chen Gao, Joya Chen, Kevin Qinghong Lin, Qingwei Meng, Yiming Zhang, Yuke Qiu, Hong Zhou, and Mike Zheng Shou. Reinforcement learning for large model: A survey.arXiv preprint arXiv:2508.08189, 2025
arXiv 2025
-
[65]
Structured 3D latents for scalable and versatile 3D generation.arXiv preprint arXiv:2412.01506, 2024
Jianfeng Xiang, Zelong Lv, Sicheng Xu, Yu Deng, Ruicheng Wang, Bowen Zhang, Dong Chen, Xin Tong, and Jiaolong Yang. Structured 3D latents for scalable and versatile 3D generation.arXiv preprint arXiv:2412.01506, 2024
Pith/arXiv arXiv 2024
-
[66]
Nativeandcompactstructuredlatents for 3D generation.arXiv preprint arXiv:2512.14692, 2025
Jianfeng Xiang, Xiaoxue Chen, Sicheng Xu, Ruicheng Wang, Zelong Lv, Yu Deng, Hongyuan Zhu, YueDong,HaoZhao,NicholasJingYuan,andJiaolongYang. Nativeandcompactstructuredlatents for 3D generation.arXiv preprint arXiv:2512.14692, 2025. Trellis 2
Pith/arXiv arXiv 2025
-
[67]
Walkinthecloud: Learning curves for point clouds shape analysis
TiangeXiang,ChaoyiZhang,YangSong,JianhuiYu,andWeidongCai. Walkinthecloud: Learning curves for point clouds shape analysis. InIEEE/CVF International Conference on Computer Vision, pages 915–924, 2021
2021
-
[68]
ImageReward: Learning and evaluating human preferences for text-to-image generation
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. ImageReward: Learning and evaluating human preferences for text-to-image generation. In Advances in Neural Information Processing Systems, 2023
2023
-
[69]
Daowu Yang, Ying Liu, Qiyun Yang, and Ruihui Li. FacialTalk: Audio-driven high-fidelity facial portrait generation using 3D facial prior.Pattern Recognition, 171:111994, 2026. ISSN 0031-3203. doi: 10.1016/j.patcog.2025.111994
-
[70]
Hi3DGen: High-fidelity 3D geometry generation from images via normal bridging
Chongjie Ye, Yushuang Wu, Ziteng Lu, Jiahao Chang, Xiaoyang Guo, Jiaqing Zhou, Hao Zhao, and Xiaoguang Han. Hi3DGen: High-fidelity 3D geometry generation from images via normal bridging. arXiv preprint arXiv:2503.22236, 2025
arXiv 2025
-
[71]
DreamReward: Text-to-3D generation with human preference
Junliang Ye, Fangfu Liu, Qixiu Li, Zhengyi Wang, Yikai Wang, Xinzhou Wang, Yueqi Duan, and Jun Zhu. DreamReward: Text-to-3D generation with human preference. InEuropean Conference on Computer Vision, 2024. 36
2024
-
[72]
GaussianCube: Astructuredandexplicitradiancerepresentationfor3Dgenerative modeling
Bowen Zhang, Yiji Cheng, Jiaolong Yang, Chunyu Wang, Feng Zhao, Yansong Tang, Dong Chen, andBainingGuo. GaussianCube: Astructuredandexplicitradiancerepresentationfor3Dgenerative modeling. InAdvances in Neural Information Processing Systems, 2024
2024
-
[73]
Efros, Eli Shechtman, and Oliver Wang
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018
2018
-
[74]
Benchmarking and learning multi- dimensional quality evaluator for text-to-3D generation
Yujie Zhang, Bingyang Cui, Qi Yang, Zhu Li, and Yiling Xu. Benchmarking and learning multi- dimensional quality evaluator for text-to-3D generation. InIEEE/CVF International Conference on Computer Vision, pages 18563–18574, October 2025
2025
-
[75]
DeepMesh: Auto-regressive artist-mesh creation with reinforcement learning
Ruowen Zhao, Junliang Ye, Zhengyi Wang, Guangce Liu, Yiwen Chen, Yikai Wang, and Jun Zhu. DeepMesh: Auto-regressive artist-mesh creation with reinforcement learning. InIEEE/CVF International Conference on Computer Vision, 2025
2025
-
[76]
DreamDPO:Aligning text-to-3D generation with human preferences via direct preference optimization
ZhenglinZhou,XiaoboXia,FanMa,HeheFan,YiYang,andTat-SengChua. DreamDPO:Aligning text-to-3D generation with human preferences via direct preference optimization. InInternational Conference on Machine Learning, 2025
2025
-
[77]
XiandongZou, RuihaoXia,HongsongWang, andPanZhou. DreamCS:Geometry-awaretext-to-3D generation with unpaired 3D reward supervision.arXiv preprint arXiv:2506.09814, 2025. 37
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.