GEAR-Seg: A Grounded Explainable Agent for Reasoning Segmentation and Data Engine
Pith reviewed 2026-07-02 14:31 UTC · model grok-4.3
The pith
GEAR-Seg decouples segmentation, text description, and LLM deduction to turn implicit reasoning into an explicit logic chain.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
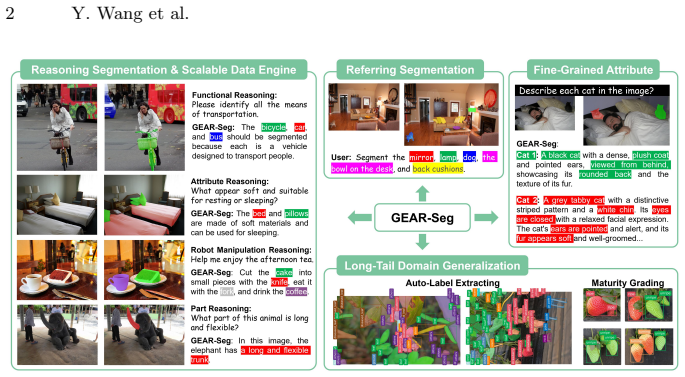
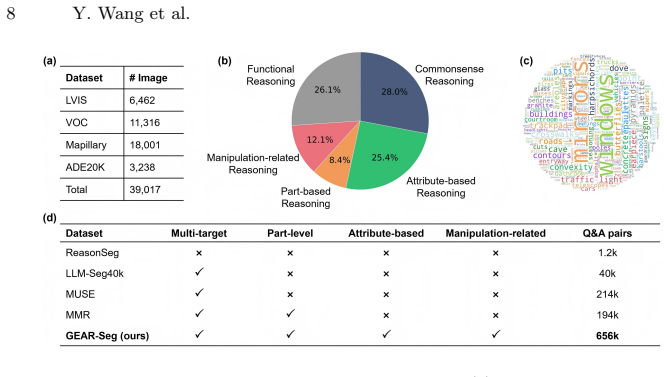
By decoupling class-agnostic segmentation, semantic description, and Large Language Model deduction, GEAR-Seg converts implicit visual reasoning into an explicit, trackable logic chain. As a zero-shot framework it matches competitive performance on reasoning and referring segmentation benchmarks. The same architecture functions as a scalable data engine that produces the GEAR-131K benchmark containing more than 38k images and 656k QA-mask pairs organized under a manipulation-oriented taxonomy. Distillation experiments show that models trained solely on the automatically generated data approach the accuracy of models trained on human-annotated data.
What carries the argument
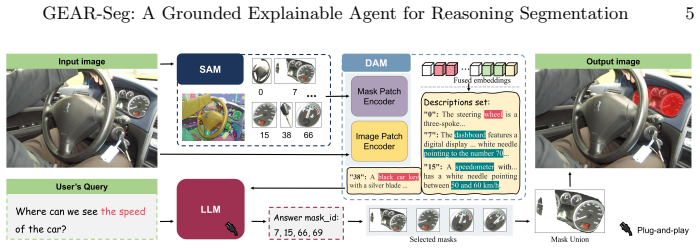
Three-stage decoupled pipeline that first extracts class-agnostic regions, then renders each region as attribute-rich text, then applies LLM deduction on the resulting text descriptions.
Load-bearing premise
Converting visual regions into dense attribute-rich text descriptions preserves all information needed for accurate LLM deduction on complex implicit queries without introducing critical omissions or hallucinations.
What would settle it
On a held-out set of complex implicit queries, measure whether GEAR-Seg's LLM deductions systematically miss targets that a direct end-to-end model correctly segments; a large gap would indicate information loss in the text step.
Figures





read the original abstract
Reasoning segmentation requires localizing targets based on complex, implicit queries. Current end-to-end models typically entangle perception and deduction into an opaque black box, severely limiting interpretability and scalability. To address this, we propose GEAR-Seg (Grounded Explainable Agent for Reasoning Segmentation), an explicitly decoupled agent that shifts the paradigm by translating visual pixels into dense, attribute-rich text. By decoupling class-agnostic segmentation, semantic description, and Large Language Model (LLM) deduction, GEAR-Seg transforms implicit reasoning into an explicit, trackable logic chain. As a zero-shot inference framework, it achieves highly competitive performance across diverse reasoning and fine-grained referring segmentation benchmarks. Furthermore, GEAR-Seg inherently functions as a highly scalable data engine. Utilizing this engine, we construct GEAR-131K, a massive benchmark (over 38k images, 656k QA-mask pairs) introducing a multifaceted taxonomy tailored for complex real-world manipulation-oriented reasoning. Finally, distillation experiments demonstrate that lightweight models supervised exclusively by our automated pipeline closely match the upper-bound performance of costly human-annotated baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GEAR-Seg, a decoupled agent framework for reasoning segmentation that separates class-agnostic mask generation, VLM-based dense semantic description of regions, and LLM-based deduction to produce an explicit, trackable reasoning chain. It claims competitive zero-shot performance on reasoning and fine-grained referring segmentation benchmarks, positions the method as a scalable data engine to create the GEAR-131K benchmark (38k+ images, 656k QA-mask pairs with a manipulation-oriented taxonomy), and reports that lightweight models distilled from the automated pipeline match human-annotated upper bounds.
Significance. If the empirical claims hold with supporting evidence, the work would offer a concrete advance in interpretability for complex vision-language reasoning tasks and a practical route to large-scale automated dataset creation, reducing reliance on costly human annotations while maintaining performance.
major comments (2)
- [Abstract] Abstract: The central claims of 'highly competitive performance across diverse reasoning and fine-grained referring segmentation benchmarks' and that 'lightweight models supervised exclusively by our automated pipeline closely match the upper-bound performance of costly human-annotated baselines' are stated without any quantitative tables, benchmark scores, error bars, or ablation results; this absence prevents evaluation of the empirical soundness of the zero-shot and distillation results.
- [Section 3] Section 3 (method): The pipeline generates per-region captions via a vision-language model and concatenates them as input to the LLM for deduction; this step assumes the text descriptions preserve all spatial relations, occlusion details, texture gradients, and context needed for accurate deduction on implicit manipulation queries, yet no validation, failure-case analysis, or comparison against direct visual input is provided to test this assumption, which is load-bearing for the 'explicit, trackable logic chain' claim.
minor comments (1)
- [Abstract] Abstract: The dataset is described as 'GEAR-131K' with 'over 38k images, 656k QA-mask pairs'; the naming convention and exact scope of the 131K figure should be clarified relative to the reported counts.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for quantitative support in the abstract and validation of the text-based reasoning assumption. We address both points below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of 'highly competitive performance across diverse reasoning and fine-grained referring segmentation benchmarks' and that 'lightweight models supervised exclusively by our automated pipeline closely match the upper-bound performance of costly human-annotated baselines' are stated without any quantitative tables, benchmark scores, error bars, or ablation results; this absence prevents evaluation of the empirical soundness of the zero-shot and distillation results.
Authors: We agree that the abstract would be strengthened by including key quantitative results. In the revised version, we will add specific benchmark scores (e.g., mIoU on reasoning segmentation tasks and comparison to baselines) with references to the main tables, while keeping the abstract concise. This directly addresses the concern about empirical soundness. revision: yes
-
Referee: [Section 3] Section 3 (method): The pipeline generates per-region captions via a vision-language model and concatenates them as input to the LLM for deduction; this step assumes the text descriptions preserve all spatial relations, occlusion details, texture gradients, and context needed for accurate deduction on implicit manipulation queries, yet no validation, failure-case analysis, or comparison against direct visual input is provided to test this assumption, which is load-bearing for the 'explicit, trackable logic chain' claim.
Authors: The referee correctly notes that the captioning step is central to the explicit chain. The current manuscript does not include a dedicated validation study or direct comparison to visual-input baselines. We will add a new subsection with quantitative comparison of LLM deduction accuracy using VLM captions versus direct image input, plus failure-case analysis on spatial/occlusion details. This will either support the assumption or clarify its limitations. revision: yes
Circularity Check
No significant circularity; derivation is empirical and self-contained against external benchmarks
full rationale
The paper describes GEAR-Seg as a zero-shot decoupled framework (class-agnostic masks + VLM captions + LLM deduction) evaluated on external reasoning/referring segmentation benchmarks, with the data engine used to generate new GEAR-131K data and distillation results compared to human baselines. No equations, fitted parameters, or predictions are presented that reduce reported performance or claims to the inputs by construction. No self-citation load-bearing steps or ansatz smuggling appear in the provided text. The central claims rest on empirical outcomes and the explicit decoupling architecture rather than self-referential definitions or renamings of known results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can perform accurate deduction on complex implicit queries when given dense attribute-rich text descriptions of image regions.
invented entities (1)
-
GEAR-Seg agent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Acharya, D.B., Kuppan, K., Divya, B.: Agentic AI: Autonomous intelligence for complex goals—a comprehensive survey. IEEE Access13, 18912–18936 (2025). https://doi.org/10.1109/ACCESS.2025.3532853
-
[2]
Chen, R., Li, C., Wu, Q., Zhong, Y.Z., Han, P., Li, W., Wei, Y., Zhao, Y.: LLM- Seg: Bridging image segmentation and large language model reasoning. In: IEEE Conf. Comput. Vis. Pattern Recog. Worksh. pp. 1765–1774 (2024).https://doi. org/10.1109/CVPRW63382.2024.00183
-
[3]
Capsfusion: Rethinking image-text data at scale
Chen, X., Hu, J., Chen, Z., Li, Y., Darrell, T., Yu, F., Gao, J.: LISA: Reasoning segmentation via large language models. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 9579–9589 (2024).https://doi.org/10.1109/CVPR52733.2024.00915
-
[4]
Chen, Y.C., Li, W.H., Sun, C., Wang, Y.C.F., Chen, C.S.: SAM4MLLM: En- hance multi-modal large language model for referring expression segmentation. In: Eur. Conf. Comput. Vis. pp. 323–340 (2024).https://doi.org/10.1007/ 978-3-031-73004-7_19 16 Y. Wang et al
2024
-
[5]
Capsfusion: Rethinking image-text data at scale
Cheng, T., Song, L., Ge, Y., Liu, W., Wang, X., Shan, Y.: YOLO-World: Real-time open-vocabulary object detection. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 16901–16911 (2024).https://doi.org/10.1109/CVPR52733.2024.01599
-
[6]
Ding, H., Liu, C., Wang, S., Jiang, X.: Vision-language transformer and query generation for referring segmentation. In: Int. Conf. Comput. Vis. pp. 16301–16310 (2021).https://doi.org/10.1109/ICCV48922.2021.01601
-
[7]
Everingham, M., Van Gool, L., Williams, C.K.I., Winn, J., Zisserman, A.: The PASCAL Visual Object Classes (VOC) challenge. Int. J. Comput. Vis.88(2), 303– 338 (2010).https://doi.org/10.1007/s11263-009-0275-4
-
[8]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Let- man, A., Mathur, A., Schelten, A., Vaughan, A., et al.: The Llama 3 herd of mod- els. arXiv preprint arXiv:2407.21783 (2024).https://doi.org/10.48550/arXiv. 2407.21783
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2024
-
[9]
Gupta, A., Doll´ ar, P., Girshick, R.: LVIS: A dataset for large vocabulary instance segmentation. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 5356–5364 (2019). https://doi.org/10.1109/CVPR.2019.00550
-
[10]
Hu, R., Rohrbach, M., Darrell, T.: Segmentation from natural language expres- sions. In: Eur. Conf. Comput. Vis. pp. 108–124 (2016).https://doi.org/10.1007/ 978-3-319-46448-0_7
2016
-
[11]
Jang, D., Cho, Y., Lee, S., Kim, T., Kim, D.: MMR: A large-scale benchmark dataset for multi-target and multi-granularity reasoning segmentation. In: Int. Conf. Learn. Represent. (2025),https://openreview.net/forum?id=mzL19kKE3r
2025
- [12]
-
[13]
In: Lecture Notes in Networks and Systems
Kozlov, A., Lazarevich, I., Shamporov, V., Lyalyushkin, N., Gorbachev, Y.: Neural network compression framework for fast model inference. In: Lecture Notes in Networks and Systems. vol. 285, pp. 240–253 (2021).https://doi.org/10.1007/ 978-3-030-80129-8_17
2021
-
[14]
Li, Y., Chen, C., Dai, X., Chen, H.: Overcoming classifier imbalance for long- tail object detection with balanced group softmax. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 10988–10997 (2020).https://doi.org/10.1109/CVPR42600. 2020.01100
-
[15]
Lian, L., Ding, Y., Ge, Y., Cui, Y., Yala, A., Darrell, T.: DAM: Describe anything model for detailed localized image and video captioning. In: Int. Conf. Comput. Vis. pp. 21766–21777 (2025)
2025
-
[16]
Capsfusion: Rethinking image-text data at scale
Liang, Y., Li, C., Zhang, D., Yang, Z., Wang, B., Mei, T.: CogAgent: A visual language model for GUI agents. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 14281–14290 (2024).https://doi.org/10.1109/CVPR52733.2024.01354
-
[17]
In: Conference on Computer Vision and Pattern Recognition (CVPR)
Liu, C., Ding, H., Jiang, X.: GRES: Generalized referring expression segmentation. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 23592–23601 (2023).https: //doi.org/10.1109/CVPR52729.2023.02259
-
[18]
Liu, Y., Zhang, J., Han, J., Yang, Y., Li, C., Gao, J.: LAVT: Language-aware vision transformer for referring image segmentation. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 18134–18144 (2022).https://doi.org/10.1109/CVPR52688. 2022.01762
-
[19]
Minderer, M., Gritsenko, A., Stone, A., Neumann, M., Weissenborn, D., Doso- vitskiy, A., Mahendran, A., Arnab, A., Dehghani, M., Shen, Z., Wang, X., Zhai, X., Kipf, T., Houlsby, N.: Simple Open-Vocabulary object detection. In: Eur. Conf. Comput. Vis. pp. 728–755 (2022).https://doi.org/10.1007/ 978-3-031-20080-9_42 GEAR-Seg: A Grounded Explainable Agent fo...
2022
-
[20]
Neuhold, G., Ollmann, T., Rota Bulo, S., Kontschieder, P.: The Mapillary Vistas dataset for semantic understanding of street scenes. In: Int. Conf. Comput. Vis. pp. 5122–5130 (2017).https://doi.org/10.1109/ICCV.2017.534
- [21]
-
[22]
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., R¨ adle, R., Rolland, C., Gustafson, L., et al.: SAM 2: Segment anything in images and videos. In: Int. Conf. Learn. Represent. (2024).https://doi.org/10.48550/arXiv.2408. 00714
-
[23]
Reimers, N., Gurevych, I.: Sentence-BERT: Sentence embeddings using Siamese BERT-networks. pp. 3982–3992 (2019).https://doi.org/10.18653/v1/D19-1410
-
[24]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Ren, T., Liu, S., Zeng, A., Lin, J., Li, K., Cao, H., Chen, J., Huang, X., Chen, Y., Yan, F., et al.: Grounded SAM: Assembling open-world models for diverse visual tasks. In: arXiv preprint arXiv:2401.14159 (2024).https://doi.org/10.48550/ arXiv.2401.14159
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Capsfusion: Rethinking image-text data at scale
Ren, Z., Huang, Z., Wei, Y., Zhao, Y., Fu, D., Feng, J., Jin, X.: PixelLM: Pixel rea- soning with large multimodal model. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 26374–26383 (2024).https://doi.org/10.1109/CVPR52733.2024.02491
-
[26]
Rezatofighi, H., Tsoi, N., Gwak, J., Sadeghian, A., Reid, I., Savarese, S.: Gen- eralized Intersection Over Union: A metric and a loss for bounding box regres- sion. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 658–666 (2019).https: //doi.org/10.1109/CVPR.2019.00075
-
[27]
Ronneberger, O., Fischer, P., Brox, T.: U-Net: Convolutional networks for biomed- ical image segmentation. In: Med. Image Comput. Comput.-Assist. Intervent. pp. 234–241 (2015).https://doi.org/10.1007/978-3-319-24574-4_28
-
[28]
Sachdeva, N., Dhaliwal, M., Wu, C.J., McAuley, J.: Infinite Recommendation Net- works: A data-centric approach. In: Adv. Neural Inform. Process. Syst. vol. 35, pp. 31292–31305 (2022)
2022
-
[29]
M., S.: YOLOv8: A novel object detection algorithm with enhanced performance and robustness
Varghese, R., S. M., S.: YOLOv8: A novel object detection algorithm with enhanced performance and robustness. In: International Conference on Artificial Intelligence and Data Sciences. pp. 1–6 (2024).https://doi.org/10.1109/ADICS58448.2024. 10533619
-
[30]
Pattern Recognition174, 112799 (2026)
Wang, Y., Fei, Z., Li, R., Ying, Y.: Learn from foundation model: Fruit detec- tion model without manual annotation. Pattern Recognition174, 112799 (2026). https://doi.org/10.1016/j.patcog.2025.112799
-
[31]
Ego4d: Around the world in 3, 000 hours of egocentric video
Wang, Z., Lu, Y., Li, Q., Tao, X., Guo, Y., Gong, M., Liu, T.: CRIS: CLIP-driven referring image segmentation. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 11676–11685 (2022).https://doi.org/10.1109/CVPR52688.2022.01139
-
[32]
Yang, A., Li, A., Yang, B., et al.: Qwen3 technical report. arXiv preprint arXiv:2505.09388 (2025).https://doi.org/10.48550/arXiv.2505.09388
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[33]
In: IEEE Conf
Yu, L., Lin, Z., Shen, X., Yang, J., Lu, X., Bansal, M., Berg, T.L.: MAttNet: Modular attention network for referring expression comprehension. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 1307–1315 (2018)
2018
-
[34]
Agentic AI: A conceptual taxonomy, applica- tions and challenges
Zhang, L., et al.: AI agents vs. Agentic AI: A conceptual taxonomy, applica- tions and challenges. Information Fusion122, 103599 (2025).https://doi.org/ 10.1016/j.inffus.2025.103599
-
[35]
Zheng, S., Lu, J., Zhao, H., Zhu, X., Luo, Z., Wang, Y., Fu, Y., Feng, J., Xiang, T., Torr, P.H.S., et al.: Rethinking semantic segmentation from a sequence-to-sequence 18 Y. Wang et al. perspective with transformers. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 6877–6886 (2021).https://doi.org/10.1109/CVPR46437.2021.00681
-
[36]
Zheng, Z., Wang, P., Liu, W., Li, J., Ye, R., Ren, D.: Distance-IoU loss: Faster and better learning for bounding box regression. In: AAAI. pp. 12993–13000 (2020). https://doi.org/10.1609/aaai.v34i07.6999
-
[37]
Zhou, B., Zhao, H., Puig, X., Fidler, S., Barriuso, A., Torralba, A.: Scene parsing through ADE20K dataset. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 5122– 5130 (2017).https://doi.org/10.1109/CVPR.2017.544
-
[38]
Zhu, L., Chen, T., Xu, Q., Liu, X., Ji, D., Wu, H., Soh, D.W., Liu, J.: Popen: Preference-based optimization and ensemble for LVLM-based reasoning segmen- tation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2025) GEAR-Seg: A Grounded Explainable Agent for Reasoning Segmentation 19 A Supplementary Material ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.