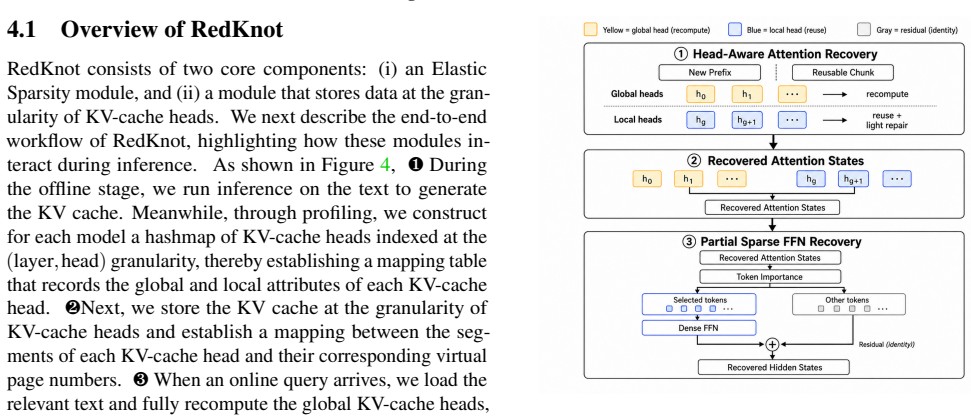
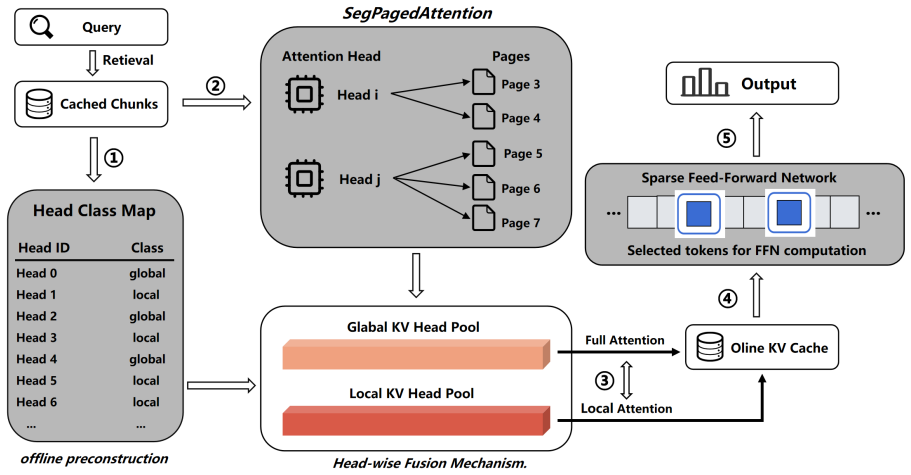
RedKnot: Efficient Long-Context LLM Serving with Head-Aware KV Reuse and SegPagedAttention
Pith reviewed 2026-06-29 05:05 UTC · model grok-4.3
The pith
RedKnot decomposes the KV cache along individual attention heads to support reuse, compression, separation, and distribution without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
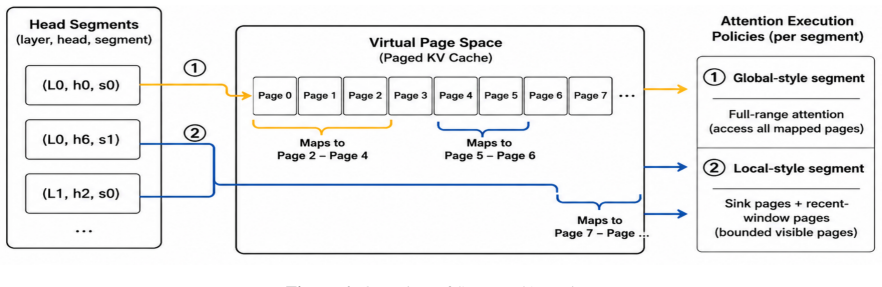
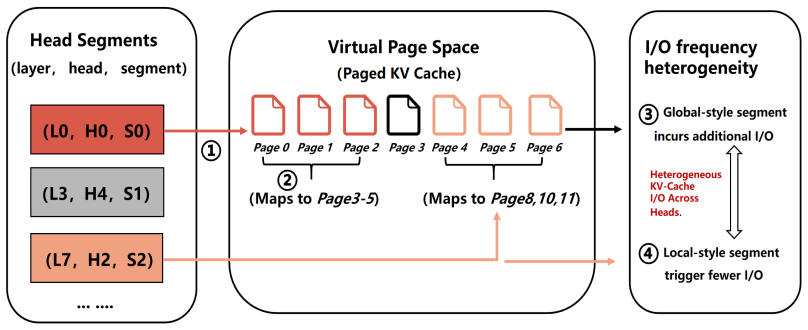
RedKnot breaks the conventional monolithic KV cache abstraction by decomposing the KV cache along KV heads, whose importance and effective attention ranges vary significantly across serving scenarios. This head-level decomposition turns the KV cache from a monolithic tensor abstraction into a structured memory object, enabling uniform support for position-independent KV reuse, prefix KV compression, hot/cold KV separation, and distributed KV placement while preserving output fidelity and improving resource efficiency, without requiring model retraining or fine-tuning.
What carries the argument
Head-aware decomposition of the KV cache into per-head structured memory objects, paired with SegPagedAttention for segmented paged attention management.
If this is right
- Position-independent KV reuse becomes possible without custom per-scenario code.
- Prefix KV compression can be applied selectively to low-importance heads.
- Hot and cold KV data can be separated at head granularity for better eviction.
- Distributed placement decisions can route individual heads to different nodes.
- Overall GPU memory capacity and serving concurrency increase while output fidelity stays the same.
Where Pith is reading between the lines
- Serving frameworks could adopt dynamic per-head eviction thresholds that adapt at runtime based on observed attention patterns.
- Model architectures that explicitly differentiate head roles during pretraining might amplify the efficiency gains shown here.
- Combining head decomposition with existing sparse or local attention mechanisms could further reduce the active cache footprint.
- The same decomposition principle might extend to other per-head structures such as activation caches or optimizer states.
Load-bearing premise
KV cache utility differs enough across heads that separate management policies preserve exact model outputs in every serving scenario.
What would settle it
A controlled run on a production long-context workload in which applying identical management rules to every head produces the same latency, memory footprint, and output quality as head-specific rules.
Figures

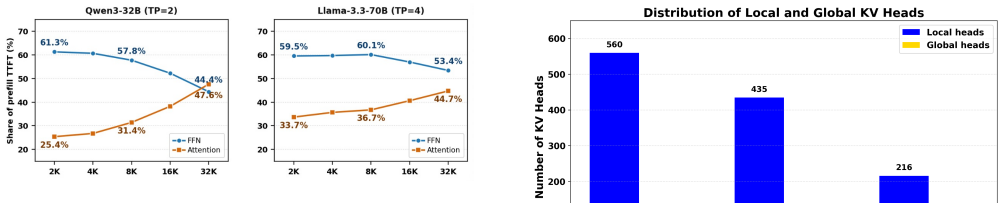
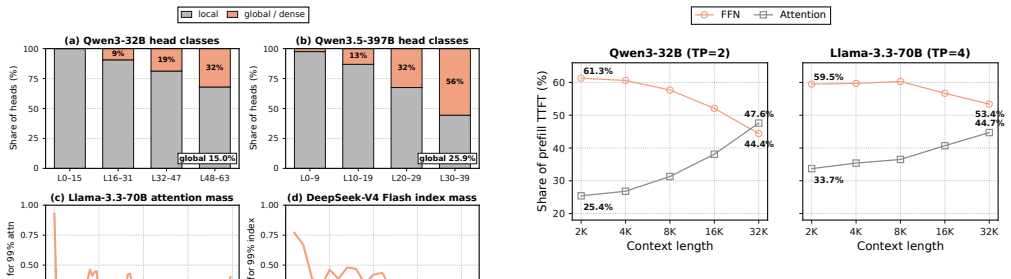


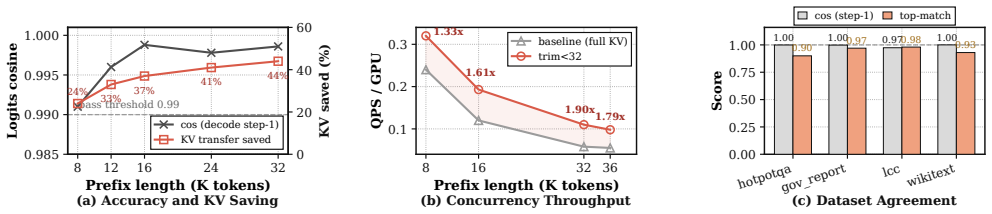
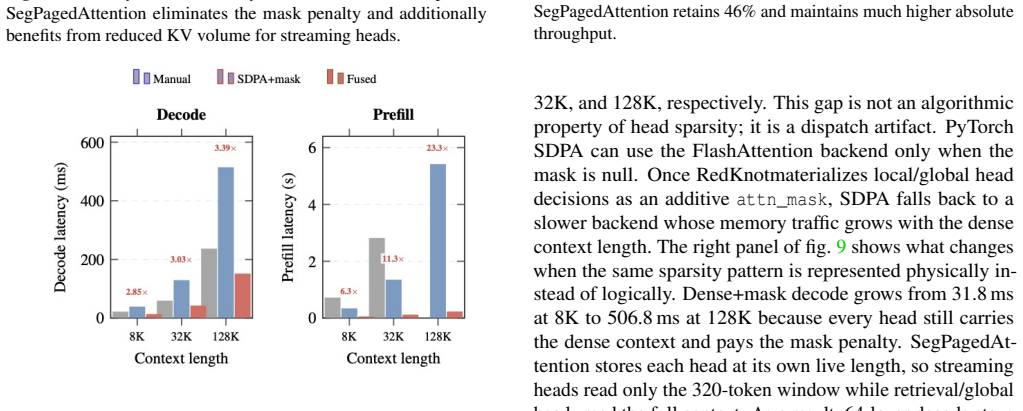
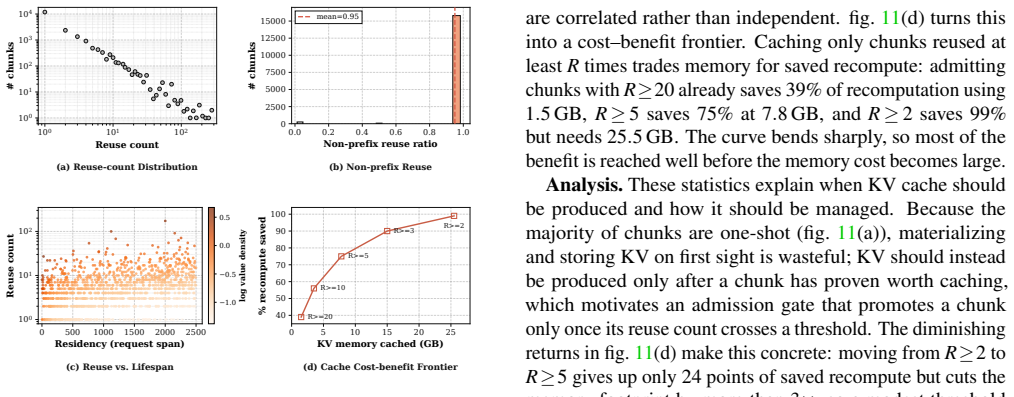
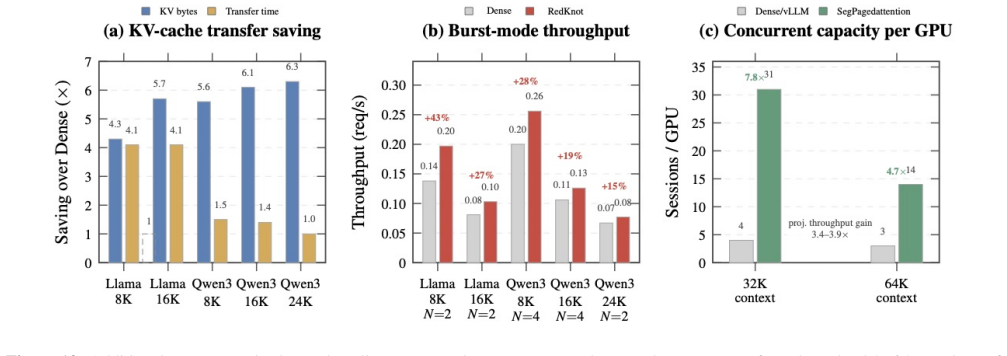
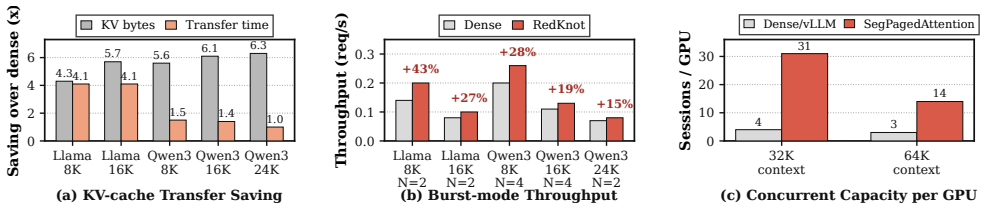
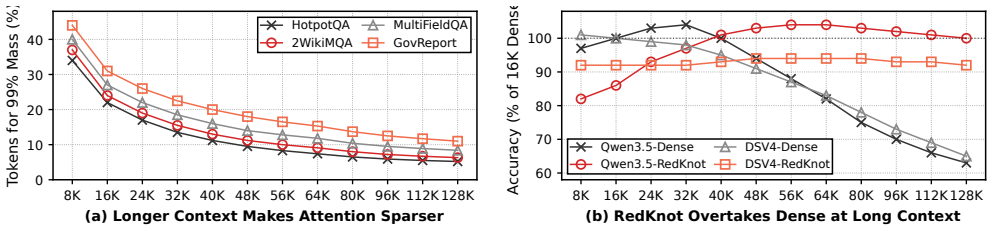
read the original abstract
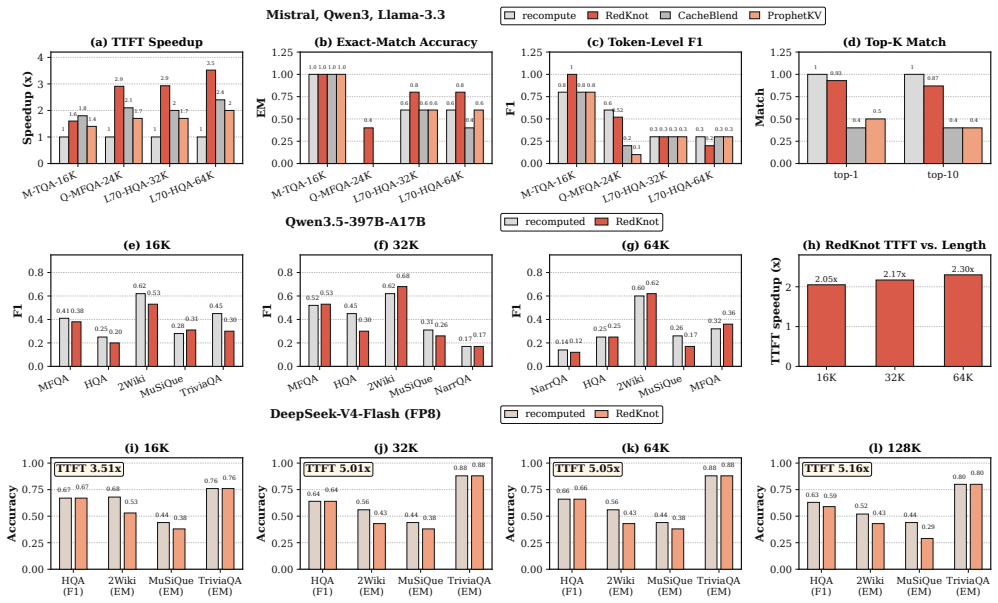
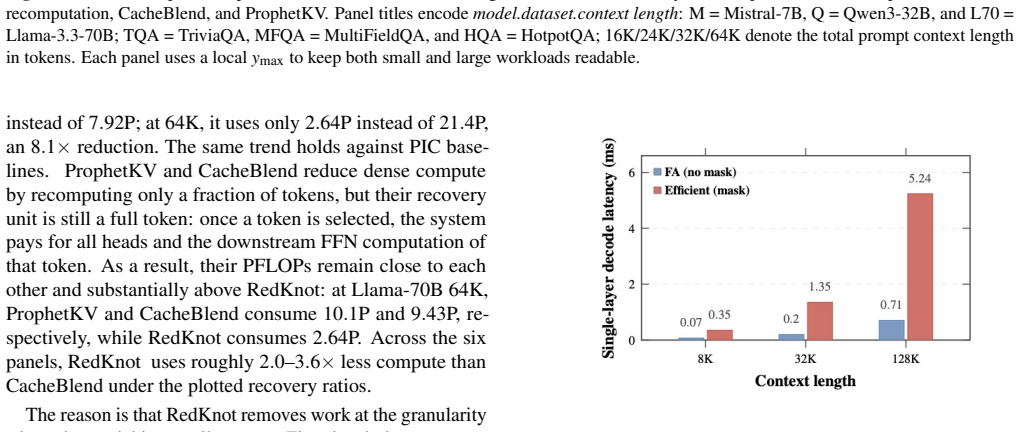
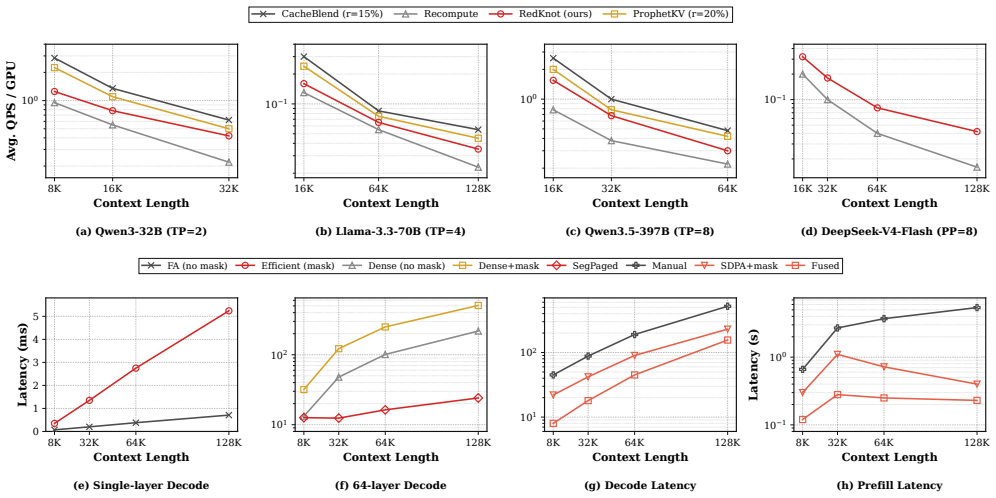
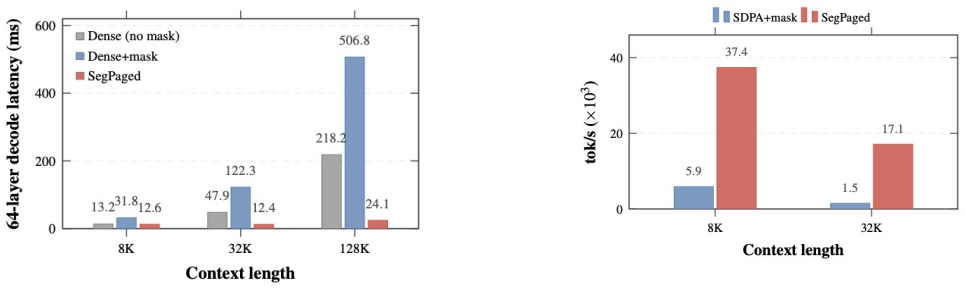
As the input length of large language model (LLM) serving continues to grow, the KV cache has become a dominant bottleneck in AI infrastructure. It limits GPU memory capacity, serving concurrency, cache reuse, and distributed scalability. Multiple important problems, including position-independent KV cache, prefix KV cache compression, hot/cold KV cache separation, and distributed KV cache management, all depend on how the KV cache is represented and managed. However, existing serving systems largely rely on a monolithic KV cache abstraction, where the KV cache is treated as a homogeneous sequence of token-level memory blocks and managed with similar policies across attention heads and serving scenarios. We observe that KV cache utility is highly structured across KV heads: different heads exhibit different functional roles, attention distances, and runtime importance. Therefore, a full KV cache is not always necessary for every head, token range, or serving scenario. We present RedKnot, a head-aware KV cache management system for LLM serving. RedKnot breaks the conventional monolithic KV cache abstraction by decomposing the KV cache along KV heads, whose importance and effective attention ranges vary significantly across serving scenarios. This head-level decomposition turns the KV cache from a monolithic tensor abstraction into a structured memory object, enabling RedKnot to uniformly support position-independent KV reuse, prefix KV compression, hot/cold KV separation, and distributed KV placement while preserving output fidelity and improving resource efficiency, without requiring model retraining or fine-tuning. RedKnot establishes a new foundation for AI infrastructure by transforming the KV cache from a monolithic, passive runtime artifact into a dynamic, model-aware runtime substrate for scalable LLM serving.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes RedKnot, a head-aware KV cache management system for long-context LLM serving. It observes that KV utility is structured across heads (differing functional roles, attention distances, runtime importance) and decomposes the cache along heads to enable position-independent reuse, prefix compression, hot/cold separation, and distributed placement while claiming to preserve output fidelity without retraining or fine-tuning.
Significance. If the per-head decomposition is shown to be stable and fidelity-preserving across models and workloads, the work would meaningfully advance LLM serving infrastructure by converting the KV cache from a monolithic tensor into a dynamic, model-aware substrate, uniformly supporting multiple long-standing systems problems.
major comments (1)
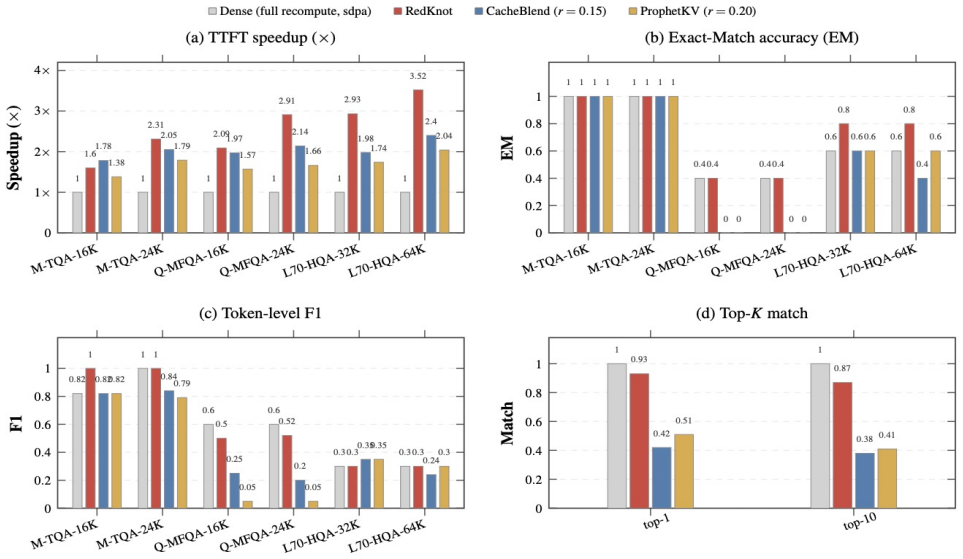
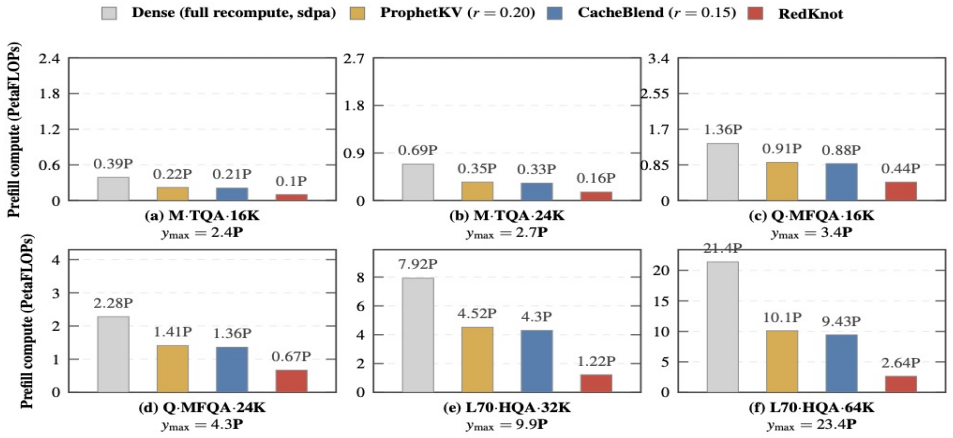
- [Abstract] Abstract: the central claim that head-level decomposition 'preserves output fidelity' while enabling the listed optimizations rests on the unquantified premise that per-head differences in functional roles and attention ranges are both large and stable enough that independent management never alters attention outputs; no fidelity deltas, perplexity measurements, exact-match rates, or head-wise variance statistics are reported to substantiate this.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The single major comment is addressed below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that head-level decomposition 'preserves output fidelity' while enabling the listed optimizations rests on the unquantified premise that per-head differences in functional roles and attention ranges are both large and stable enough that independent management never alters attention outputs; no fidelity deltas, perplexity measurements, exact-match rates, or head-wise variance statistics are reported to substantiate this.
Authors: We agree that the abstract would be strengthened by explicit quantitative support for the fidelity claim. The manuscript's experimental sections evaluate output fidelity via perplexity, downstream task accuracy, and head-wise variance across models and workloads, showing that head-aware management preserves outputs. We will revise the abstract to include a concise summary of these metrics (e.g., perplexity deltas and exact-match rates) to directly address the concern. revision: yes
Circularity Check
No circularity; systems architecture rests on stated observation without equations or self-referential reductions
full rationale
The paper is a systems description of RedKnot that decomposes KV cache along heads based on an empirical observation ('We observe that KV cache utility is highly structured across KV heads'). No equations, fitted parameters, predictions, or derivations appear in the provided text. The central claim is an engineering design that follows from the observation; it does not reduce to a self-definition, a renamed fit, or a self-citation chain. Per rules, absence of quantitative validation is a correctness concern, not circularity. This is a standard non-circular systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gulavani, Alexey Tu- manov, and Ramachandran Ramjee
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S. Gulavani, Alexey Tu- manov, and Ramachandran Ramjee. Taming throughput- latency tradeoff in LLM inference with Sarathi-Serve. In18th USENIX Symposium on Operating Systems De- sign and Implementation (OSDI), pages 117–134, 2024
2024
-
[2]
GQA: Training generalized multi-query transformer models from multi-head checkpoints
Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. GQA: Training generalized multi-query transformer models from multi-head checkpoints. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 4895–4901. Association for Computational Linguistics, 2023
2023
-
[3]
Claude Code
Anthropic. Claude Code. https://www.anthropic.com/ claude-code, 2025. Accessed: 2026-06-04. 21
2025
-
[4]
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. LongBench: A bilingual, multitask bench- mark for long context understanding.arXiv preprint arXiv:2308.14508, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
LongBench v2: Towards deeper understanding and reasoning on realis- tic long-context multitasks
Yushi Bai, Shangqing Tu, Jiajie Zhang, Hao Peng, Xi- aozhi Wang, Xin Lv, Shulin Cao, Jiazheng Xu, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. LongBench v2: Towards deeper understanding and reasoning on realis- tic long-context multitasks. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ...
2025
-
[6]
Extending context window of large language models via positional interpolation, 2023
Shouyuan Chen, Sherman Wong, Liangjian Chen, and Yuandong Tian. Extending context window of large language models via positional interpolation, 2023
2023
-
[7]
NVIDIA Hopper H100 GPU: Scaling performance.IEEE Micro, 43(3):9–17, 2023
Jack Choquette. NVIDIA Hopper H100 GPU: Scaling performance.IEEE Micro, 43(3):9–17, 2023
2023
-
[8]
Damai Dai, Chengqi Deng, Chenggang Zhao, R. X. Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Y . Wu, Zhenda Xie, Y . K. Li, Panpan Huang, Fuli Luo, Chong Ruan, Zhifang Sui, and Wen- feng Liang. DeepSeekMoE: Towards ultimate expert specialization in mixture-of-experts language models, 2024
2024
-
[9]
FlashAttention-2: Faster attention with better parallelism and work partitioning
Tri Dao. FlashAttention-2: Faster attention with better parallelism and work partitioning. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[10]
Smith, and Matt Gardner
Pradeep Dasigi, Kyle Lo, Iz Beltagy, Arman Cohan, Noah A. Smith, and Matt Gardner. A dataset of information-seeking questions and answers anchored in research papers. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), pages 4599–4610, 2021
2021
-
[11]
DeepSeek-V2: A strong, economical, and efficient mixture-of-experts language model, 2024
DeepSeek-AI. DeepSeek-V2: A strong, economical, and efficient mixture-of-experts language model, 2024
2024
-
[12]
DeepSeek-V3 technical report, 2024
DeepSeek-AI. DeepSeek-V3 technical report, 2024
2024
-
[13]
FlashMLA: Efficient multi-head latent attention kernels
DeepSeek-AI. FlashMLA: Efficient multi-head latent attention kernels. https://github.com/deepseek-ai/Flas hMLA, 2025. Accessed: 2026-06-14
2025
-
[14]
DeepSeek-V4-Flash model card
DeepSeek-AI. DeepSeek-V4-Flash model card. https: //huggingface.co/deepseek-ai/DeepSeek-V4-Flash,
-
[15]
Accessed: 2026-06-14
2026
-
[16]
DeepSeek-V4-Pro model card
DeepSeek-AI. DeepSeek-V4-Pro model card. https: //huggingface.co/deepseek-ai/DeepSeek-V4-Pro, 2026. Accessed: 2026-06-14
2026
-
[17]
Huerta, and Hao Peng
Yufeng Du, Minyang Tian, Srikanth Ronanki, Subendhu Rongali, Sravan Babu Bodapati, Aram Galstyan, Az- ton Wells, Roy Schwartz, Eliu A. Huerta, and Hao Peng. Context length alone hurts LLM performance despite perfect retrieval. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 23281–23298, Suzhou, China, 2025. Association for C...
2025
-
[19]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity, 2022
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity, 2022
2022
-
[20]
Tianyu Fu, Haofeng Huang, Xuefei Ning, Genghan Zhang, Boju Chen, Tianqi Wu, Hongyi Wang, Zix- iao Huang, Shiyao Li, Shengen Yan, Guohao Dai, Huazhong Yang, and Yu Wang. MoA: Mixture of sparse attention for automatic large language model compres- sion.arXiv preprint arXiv:2406.14909, 2024
-
[21]
Not all heads matter: A head- level KV cache compression method with integrated retrieval and reasoning
Yu Fu, Zefan Cai, Abedelkadir Asi, Wayne Xiong, Yue Dong, and Wen Xiao. Not all heads matter: A head- level KV cache compression method with integrated retrieval and reasoning. InInternational Conference on Learning Representations, 2025
2025
-
[22]
Retrieval-Augmented Generation for Large Language Models: A Survey
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, and Haofen Wang. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Prompt Cache: Modular attention reuse for low-latency inference
In Gim, Guojun Chen, Seung-seob Lee, Nikhil Sarda, Anurag Khandelwal, and Lin Zhong. Prompt Cache: Modular attention reuse for low-latency inference. In Proceedings of Machine Learning and Systems (MLSys), 2024
2024
-
[24]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Constructing a multi-hop QA dataset for comprehensive evaluation of reasoning steps
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. Constructing a multi-hop QA dataset for comprehensive evaluation of reasoning steps. InProceedings of the 28th International Conference on Computational Linguistics (COLING), pages 6609– 6625, 2020. 22
2020
-
[26]
RULER: What’s the real context size of your long-context language models?, 2024
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shan- tanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. RULER: What’s the real context size of your long-context language models?, 2024. COLM 2024
2024
-
[27]
EPIC: Efficient position-independent caching for serving large language models
Junhao Hu, Wenrui Huang, Weidong Wang, Haoyi Wang, Tiancheng Hu, Zhang Qin, Hao Feng, Xusheng Chen, Yizhou Shan, and Tao Xie. EPIC: Efficient position-independent caching for serving large language models. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofPro- ceedings of Machine Learning Research, pages 24391– 24402. PMLR, 2025
2025
-
[28]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Men- sch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guil- laume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b.arXiv preprint arXi...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Abdi, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu
Huiqiang Jiang, Yucheng Li, Chengruidong Zhang, Qianhui Wu, Xufang Luo, Surin Ahn, Zhenhua Han, Amir H. Abdi, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. MInference 1.0: Accelerating pre-filling for long-context LLMs via dynamic sparse at- tention. InAdvances in Neural Information Processing Systems, 2024
2024
-
[30]
Weld, and Luke Zettlemoyer
Mandar Joshi, Eunsol Choi, Daniel S. Weld, and Luke Zettlemoyer. TriviaQA: A large scale distantly su- pervised challenge dataset for reading comprehension. InProceedings of the 55th Annual Meeting of the As- sociation for Computational Linguistics (ACL), pages 1601–1611, 2017
2017
-
[31]
Gonza- lez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonza- lez, Hao Zhang, and Ion Stoica. Efficient memory man- agement for large language model serving with Page- dAttention. InProceedings of the 29th Symposium on Operating Systems Principles (SOSP), pages 611–626, 2023
2023
-
[32]
CATS: Contextually- aware thresholding for sparsity in large language models
Donghyun Lee, Je-Yong Lee, Genghan Zhang, Mo Ti- wari, and Azalia Mirhoseini. CATS: Contextually- aware thresholding for sparsity in large language models. InConference on Language Modeling, 2024
2024
-
[33]
GShard: Scaling gi- ant models with conditional computation and automatic sharding
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, De- hao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. GShard: Scaling gi- ant models with conditional computation and automatic sharding. InInternational Conference on Learning Representations, 2021
2021
-
[34]
Retrieval-augmented generation for knowledge-intensive NLP tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Se- bastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks. In Advances in Neural Information Processing Systems (NeurIPS), volume 33, pages 9459–9474, 2020
2020
-
[35]
NeedleBench: Evaluating LLM retrieval and reasoning across varying information densities, 2024
Mo Li, Songyang Zhang, Taolin Zhang, Haodong Duan, Yunxin Liu, and Kai Chen. NeedleBench: Evaluating LLM retrieval and reasoning across varying information densities, 2024
2024
-
[36]
Xiaolin Lin, Jingcun Wang, Olga Kondrateva, Yiyu Shi, Bing Li, and Grace Li Zhang. CompressKV: Seman- tic retrieval heads know what tokens are not important before generation.arXiv preprint arXiv:2508.02401, 2025
-
[37]
Rethinking RoPE: A mathematical blueprint for n-dimensional positional encoding, 2025
Haiping Liu and Hongpeng Zhou. Rethinking RoPE: A mathematical blueprint for n-dimensional positional encoding, 2025
2025
-
[38]
TEAL: Training- free activation sparsity in large language models
James Liu, Pragaash Ponnusamy, Tianle Cai, Han Guo, Yoon Kim, and Ben Athiwaratkun. TEAL: Training- free activation sparsity in large language models. In International Conference on Learning Representations, 2025
2025
-
[39]
Liu, Kevin Lin, John Hewitt, Ashwin Paran- jape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paran- jape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics, 12:157–173, 2024
2024
-
[40]
CacheSlide: Unlocking cross position-aware KV cache reuse for accelerating LLM serving
Yang Liu, Yunfei Gu, Liqiang Zhang, Chentao Wu, Guangtao Xue, Jie Li, Minyi Guo, Junhao Hu, and Jie Meng. CacheSlide: Unlocking cross position-aware KV cache reuse for accelerating LLM serving. InPro- ceedings of the 24th USENIX Conference on File and Storage Technologies, FAST ’26. USENIX Association, 2026
2026
-
[41]
Scissorhands: Exploiting the persistence of importance hypothesis for LLM KV cache compression at test time
Zichang Liu, Aditya Desai, Fangshuo Liao, Weitao Wang, Victor Xie, Zhaozhuo Xu, Anastasios Kyrillidis, and Anshumali Shrivastava. Scissorhands: Exploiting the persistence of importance hypothesis for LLM KV cache compression at test time. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[42]
Deja Vu: Contextual sparsity for efficient LLMs at inference 23 time
Zichang Liu, Jue Wang, Tri Dao, Tianyi Zhou, Binhang Yuan, Zhao Song, Anshumali Shrivastava, Ce Zhang, Yuandong Tian, Christopher Ré, and Beidi Chen. Deja Vu: Contextual sparsity for efficient LLMs at inference 23 time. InProceedings of the 40th International Confer- ence on Machine Learning (ICML), pages 22137–22176, 2023
2023
-
[43]
Rossi, Seunghyun Yoon, and Hinrich Sch"utze
Ali Modarressi, Hanieh Deilamsalehy, Franck Dernon- court, Trung Bui, Ryan A. Rossi, Seunghyun Yoon, and Hinrich Sch"utze. NoLiMa: Long-context evaluation beyond literal matching, 2025. ICML 2025
2025
-
[44]
NVIDIA H100 Tensor Core GPU architecture
NVIDIA. NVIDIA H100 Tensor Core GPU architecture. Whitepaper, NVIDIA Corporation, 2023
2023
-
[45]
Introducing Codex: A cloud-based software engineering agent
OpenAI. Introducing Codex: A cloud-based software engineering agent. https://openai.com/index/introduci ng-codex/, 2025. Accessed: 2025-05-20
2025
-
[46]
OpenClaw, 2025
OpenClaw Contributors. OpenClaw, 2025
2025
-
[47]
Efficiently scal- ing transformer inference
Reiner Pope, Sholto Douglas, Aakanksha Chowdhery, Jacob Devlin, James Bradbury, Jonathan Heek, Kefan Xiao, Shivani Agrawal, and Jeff Dean. Efficiently scal- ing transformer inference. InProceedings of Machine Learning and Systems (MLSys), 2023
2023
-
[48]
Qwen3.5-35B-A3B model card
Qwen Team. Qwen3.5-35B-A3B model card. https: //huggingface.co/Qwen/Qwen3.5-35B-A3B, 2026. Accessed: 2026-06-14
2026
-
[49]
Qwen3.5-397B-A17B model card
Qwen Team. Qwen3.5-397B-A17B model card. https: //huggingface.co/Qwen/Qwen3.5-397B-A17B, 2026. Accessed: 2026-06-14
2026
-
[50]
Qwen3.5 model collection
Qwen Team. Qwen3.5 model collection. https://huggin gface.co/collections/Qwen/qwen35, 2026. Accessed: 2026-06-14
2026
-
[51]
Qwen3.5: Towards native multimodal agents
Qwen Team. Qwen3.5: Towards native multimodal agents. https://qwen.ai/blog?id=qwen3.5, 2026. Accessed: 2026-06-14
2026
-
[52]
HiCache system design and optimiza- tion
SGLang Team. HiCache system design and optimiza- tion. https://docs.sglang.ai/advanced_features/hicache _design.html, 2025. Accessed: 2026-05-31
2025
-
[54]
FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. FlashAttention- 3: Fast and accurate attention with asynchrony and low- precision.arXiv preprint arXiv:2407.08608, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[55]
Fast Transformer Decoding: One Write-Head is All You Need
Noam Shazeer. Fast transformer decoding: One write- head is all you need.arXiv preprint arXiv:1911.02150, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[56]
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. InInternational Conference on Learning Representations, 2017
2017
-
[57]
ProSparse: Intro- ducing and enhancing intrinsic activation sparsity within large language models
Chenyang Song, Xu Han, Zhengyan Zhang, Shengding Hu, Xiyu Shi, Kuai Li, Chen Chen, Zhiyuan Liu, Guan- gli Li, Tao Yang, and Maosong Sun. ProSparse: Intro- ducing and enhancing intrinsic activation sparsity within large language models. InProceedings of the 31st In- ternational Conference on Computational Linguistics, 2025
2025
-
[58]
PowerInfer: Fast large language model serving with a consumer-grade GPU
Yixin Song, Zeyu Mi, Haotong Xie, and Haibo Chen. PowerInfer: Fast large language model serving with a consumer-grade GPU. InProceedings of the 30th Symposium on Operating Systems Principles (SOSP), 2024
2024
-
[59]
RoFormer: Enhanced trans- former with rotary position embedding.Neurocomput- ing, 568:127063, 2024
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. RoFormer: Enhanced trans- former with rotary position embedding.Neurocomput- ing, 568:127063, 2024
2024
-
[60]
Ra- zorAttention: Efficient KV cache compression through retrieval heads
Hanlin Tang, Yang Lin, Jing Lin, Qingsen Han, Danning Ke, Shikuan Hong, Yiwu Yao, and Gongyi Wang. Ra- zorAttention: Efficient KV cache compression through retrieval heads. InInternational Conference on Learn- ing Representations, 2025
2025
-
[61]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[62]
MuSiQue: Multihop questions via single hop question composition.Transactions of the Association for Computational Linguistics, 10:539–554, 2022
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. MuSiQue: Multihop questions via single hop question composition.Transactions of the Association for Computational Linguistics, 10:539–554, 2022
2022
-
[63]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, 2017
2017
-
[64]
Shihao Wang, Jiahao Chen, Yanqi Pan, Hao Huang, Yichen Hao, Xiangyu Zou, Wen Xia, Wentao Zhang, Chongyang Qiu, and Pengfei Wang. Prophetkv: User- query-driven selective recomputation for efficient kv cache reuse in retrieval-augmented generation.arXiv preprint arXiv:2602.02579, 2026. 24
-
[65]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. Transformers: State-of-the-art...
2020
-
[66]
LongGenBench: Benchmarking long- form generation in long context LLMs
Yuhao Wu, Ming Shan Hee, Zhiqing Hu, and Roy Ka-Wei Lee. LongGenBench: Benchmarking long- form generation in long context LLMs. InInterna- tional Conference on Learning Representations, 2025. arXiv:2409.02076
-
[67]
DuoAttention: Efficient long-context LLM inference with retrieval and streaming heads
Guangxuan Xiao, Jiaming Tang, Jingwei Zuo, Junxian Guo, Shang Yang, Haotian Tang, Yao Fu, and Song Han. DuoAttention: Efficient long-context LLM inference with retrieval and streaming heads. InInternational Conference on Learning Representations, 2025
2025
-
[68]
Efficient streaming language models with attention sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. InInternational Confer- ence on Learning Representations, 2024
2024
-
[69]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chen- gen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jian- wei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Ya...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[70]
Gated delta networks: Improving Mamba2 with delta rule,
Songlin Yang, Jan Kautz, and Ali Hatamizadeh. Gated delta networks: Improving Mamba2 with delta rule,
-
[71]
Cohen, Ruslan Salakhutdinov, and Christopher D
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Ben- gio, William W. Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. HotpotQA: A dataset for diverse, explainable multi-hop question answering. In Proceedings of the 2018 Conference on Empirical Meth- ods in Natural Language Processing (EMNLP), pages 2369–2380, 2018
2018
-
[72]
CacheBlend: Fast large language model serving for RAG with cached knowledge fusion
Jiayi Yao, Hanchen Li, Yuhan Liu, Siddhant Du, Xie Han, Shan Cao, and Junchen Jiang. CacheBlend: Fast large language model serving for RAG with cached knowledge fusion. InProceedings of the 19th European Conference on Computer Systems (EuroSys), 2025
2025
-
[73]
H2O: Heavy-hitter oracle for efficient generative inference of large language models
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuan- dong Tian, Christopher Ré, Clark Barrett, Zhangyang Wang, and Beidi Chen. H2O: Heavy-hitter oracle for efficient generative inference of large language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[74]
Gonzalez, and Ying Sheng
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Jeff Huang, Chuyue Sun, Cody Hao Yu, Shiyi Cao, Christos Kober, Cedric Shi, Kefan Xiao, Ion Stoica, Hao Zhang, Joseph E. Gonzalez, and Ying Sheng. SGLang: Effi- cient execution of structured language model programs. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[75]
Dist- Serve: Disaggregating prefill and decoding for goodput- optimized large language model serving
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. Dist- Serve: Disaggregating prefill and decoding for goodput- optimized large language model serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI), pages 193–210, 2024. 25
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.