MoE-Prefill: Zero Redundancy Overheads in MoE Prefill Serving
Pith reviewed 2026-05-19 17:38 UTC · model grok-4.3
The pith
MoE prefill serving eliminates redundant overheads by asynchronously gathering expert weights during compute-bound phases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MoE-Prefill uses AsyncEP to gather experts by weight asynchronously rather than routing activations synchronously, fully overlapping the AllGather with the long forward passes of large-batch prefill, while the frontend uses prefix-aware routing and true-FLOPs load tracking to enforce saturation thresholds.
What carries the argument
Asynchronous Expert Parallelism (AsyncEP), which streams expert weights in the background to replace per-layer activation AllToAll with overlapped weight AllGather.
If this is right
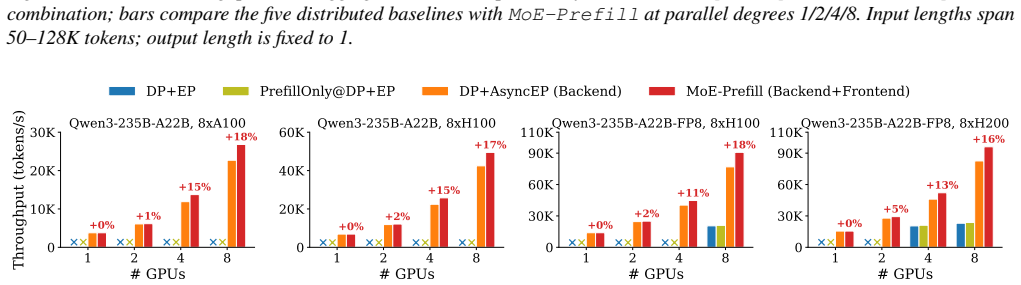
- Throughput improves by 1.35-1.37x over the strongest baseline on real-world workloads for Qwen3-235B-A22B.
- Up to 1.59x throughput gain on long-context synthetic workloads.
- Per-GPU model FLOPs utilization reaches 29.8-36.2% across four hardware and precision setups.
- The approach maintains accuracy with no new bottlenecks introduced by the weight streaming.
Where Pith is reading between the lines
- This separation of prefill parallelism from decode strategies could lead to specialized serving systems that switch modes based on workload type.
- Similar asynchronous weight movement might apply to other compute-heavy phases in distributed model serving beyond MoE.
- Adoption could reduce reliance on complex tensor and pipeline parallelism for prefill, simplifying deployment on heterogeneous hardware.
Load-bearing premise
The per-layer compute time during large-batch prefill is sufficiently long to allow complete overlapping of the asynchronous expert weight AllGather without introducing stalls or accuracy degradation.
What would settle it
An experiment showing that on the evaluated hardware configurations, the time to perform the weight AllGather exceeds the available compute window for some layers, resulting in no throughput improvement or utilization below 29 percent.
Figures










read the original abstract
Production LLM workloads increasingly serve discriminative tasks, such as classification, recommendation, and verification, whose answers are read from the logits of a single prefill pass with no autoregressive decoding. Serving these prefill-only workloads on mixture-of-experts (MoE) models is bottlenecked not by compute but by the distributed execution required to fit the model: existing parallel strategies (tensor, expert, and pipeline parallelism) trade memory pressure for redundant computation, communication, and synchronization, severely degrading MoE prefill serving efficiency. We observe that these overheads stem from coupling expert placement with synchronous activation routing -- a design inherited from the decoding era. The long, compute-bound forward passes of large-batch prefill open a per-layer window wide enough to stream expert weights in the background, replacing per-layer activation AllToAll with asynchronous weight AllGather fully overlapped with computation. We propose MoE-Prefill, a prefill-only serving system whose backend, AsyncEP (Asynchronous Expert Parallelism), gathers experts by weight rather than routing them by activation, and whose frontend co-enforces a physically-derived saturation threshold through prefix-aware routing and true-FLOPs load tracking. On Qwen3-235B-A22B across four hardware/precision configurations, MoE-Prefill delivers 1.35-1.37x throughput over the strongest distributed baseline on real-world workloads and up to 1.59x on long-context synthetic workloads, sustaining 29.8-36.2% per-GPU model FLOPs utilization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MoE-Prefill, a prefill-only serving system for large MoE models that replaces per-layer activation AllToAll with asynchronous weight AllGather (via AsyncEP) fully overlapped with the long compute-bound forward passes of large-batch prefill. A frontend enforces a saturation threshold via prefix-aware routing and true-FLOPs load tracking. On Qwen3-235B-A22B across four hardware/precision configurations, it reports 1.35-1.37x throughput over the strongest distributed baseline on real-world workloads, up to 1.59x on long-context synthetic workloads, and 29.8-36.2% per-GPU model FLOPs utilization.
Significance. If the asynchronous overlap can be shown to complete without stalls, load imbalance, or accuracy loss, the approach would meaningfully advance efficient serving of prefill-dominant discriminative workloads on MoE models by removing redundancy from traditional tensor/expert/pipeline parallelism. The multi-configuration empirical results on real hardware provide a concrete basis for assessing practical gains in throughput and utilization.
major comments (3)
- [§4 and Evaluation] §4 (AsyncEP design) and Evaluation: The central performance claims rest on the assertion that per-layer compute windows are wide enough to fully hide the cost of background expert weight AllGather. No quantitative overlap fractions, per-layer timing breakdowns, communication volume measurements, or memory-footprint data during streaming are provided to confirm absence of stalls or new bottlenecks.
- [Evaluation section] Evaluation section: Throughput and MFU numbers (1.35-1.59x, 29.8-36.2%) are reported without sufficient detail on baseline implementations, exact workload definitions, measurement methodology, or statistical variance across runs. This information is required to substantiate the gains over the strongest distributed baseline.
- [§3 and Accuracy] §3 (frontend routing) and Accuracy: Prefix-aware routing combined with true-FLOPs tracking is claimed to prevent imbalance, yet no load-imbalance metrics, expert utilization histograms, or end-to-end accuracy verification on the reported workloads are shown. Any drift here would directly undermine the reported MFU and throughput.
minor comments (2)
- [§3] Clarify the exact definition and computation of the 'saturation threshold' and 'true-FLOPs' tracking in the frontend description.
- [Related Work] Add a brief related-work paragraph contrasting AsyncEP with prior asynchronous communication techniques in MoE inference.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable comments on our manuscript. We address each of the major comments in detail below. We are committed to improving the clarity and completeness of the paper based on this feedback.
read point-by-point responses
-
Referee: [§4 and Evaluation] §4 (AsyncEP design) and Evaluation: The central performance claims rest on the assertion that per-layer compute windows are wide enough to fully hide the cost of background expert weight AllGather. No quantitative overlap fractions, per-layer timing breakdowns, communication volume measurements, or memory-footprint data during streaming are provided to confirm absence of stalls or new bottlenecks.
Authors: We acknowledge that the manuscript would benefit from more detailed profiling to explicitly demonstrate the overlap. In the revised version, we will add quantitative overlap fractions, per-layer timing breakdowns, and communication volume measurements from our experiments. These will confirm that the AllGather is fully overlapped without introducing stalls or new bottlenecks, as evidenced by the sustained high MFU and throughput gains. revision: yes
-
Referee: [Evaluation section] Evaluation section: Throughput and MFU numbers (1.35-1.59x, 29.8-36.2%) are reported without sufficient detail on baseline implementations, exact workload definitions, measurement methodology, or statistical variance across runs. This information is required to substantiate the gains over the strongest distributed baseline.
Authors: We agree that additional details on the experimental setup are necessary for reproducibility and to substantiate the claims. We will expand the Evaluation section to include precise descriptions of the baseline implementations (e.g., how tensor, expert, and pipeline parallelism are configured in the strongest baseline), exact definitions of the real-world and synthetic workloads, the measurement methodology (including how throughput and MFU are calculated), and report statistical variance across multiple runs. revision: yes
-
Referee: [§3 and Accuracy] §3 (frontend routing) and Accuracy: Prefix-aware routing combined with true-FLOPs tracking is claimed to prevent imbalance, yet no load-imbalance metrics, expert utilization histograms, or end-to-end accuracy verification on the reported workloads are shown. Any drift here would directly undermine the reported MFU and throughput.
Authors: We will include load-imbalance metrics and expert utilization histograms in the revised manuscript to demonstrate the effectiveness of the prefix-aware routing and true-FLOPs tracking in maintaining balance. Regarding accuracy, since the routing decisions affect only the distribution of computation without altering the model parameters or the final computation graph, the end-to-end accuracy remains identical to the baseline. We will add a note or verification on this point for the reported workloads. revision: yes
Circularity Check
No circularity: empirical systems paper with hardware-validated throughput claims
full rationale
The paper presents an engineering system (AsyncEP + prefix-aware routing) whose core claim is that large-batch prefill compute windows suffice to fully overlap asynchronous expert weight AllGather with per-layer computation, replacing activation AllToAll. This is not derived from equations or fitted parameters but stated as an observation about compute-bound prefill phases, then implemented and measured directly on Qwen3-235B-A22B across four hardware/precision setups. Throughput (1.35-1.59x) and MFU (29.8-36.2%) numbers are reported from real runs rather than any self-referential prediction or self-citation chain. No load-bearing mathematical derivation, uniqueness theorem, or ansatz appears; the work is self-contained against external benchmarks of measured performance.
Axiom & Free-Parameter Ledger
free parameters (1)
- saturation threshold
axioms (2)
- domain assumption Existing tensor, expert, and pipeline parallelism trade memory pressure for redundant computation, communication, and synchronization in MoE prefill.
- domain assumption Per-layer activation AllToAll can be replaced by asynchronous weight AllGather fully overlapped with computation.
invented entities (2)
-
AsyncEP
no independent evidence
-
MoE-Prefill
no independent evidence
Reference graph
Works this paper leans on
-
[1]
gpt-oss-120b & gpt-oss-20b Model Card
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. gpt-oss-120b & gpt- oss-20b model card.arXiv preprint arXiv:2508.10925, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills
Amey Agrawal, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S Gulavani, and Ramachan- dran Ramjee. Sarathi: Efficient llm inference by piggy- backing decodes with chunked prefills.arXiv preprint arXiv:2308.16369, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Deepspeed-inference: enabling efficient in- ference of transformer models at unprecedented scale
Reza Yazdani Aminabadi, Samyam Rajbhandari, Am- mar Ahmad Awan, Cheng Li, Du Li, Elton Zheng, Olatunji Ruwase, Shaden Smith, Minjia Zhang, Jeff Rasley, et al. Deepspeed-inference: enabling efficient in- ference of transformer models at unprecedented scale. In SC22: International Conference for High Performance Computing, Networking, Storage and Analysis, ...
work page 2022
-
[4]
Weilin Cai, Juyong Jiang, Fan Wang, Jing Tang, Sunghun Kim, and Jiayi Huang. A survey on mixture of experts in large language models.IEEE Transactions on Knowledge and Data Engineering, 2025
work page 2025
-
[5]
Moe-lightning: High-throughput moe inference on memory-constrained gpus
Shiyi Cao, Shu Liu, Tyler Griggs, Peter Schafhalter, Xi- aoxuan Liu, Ying Sheng, Joseph E Gonzalez, Matei Za- haria, and Ion Stoica. Moe-lightning: High-throughput moe inference on memory-constrained gpus. InPro- ceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1, pages 715–...
work page 2025
-
[6]
LexGLUE: A benchmark dataset for legal language understanding in English
Ilias Chalkidis, Abhik Jana, Dirk Hartung, Michael Bom- marito, Ion Androutsopoulos, Daniel Martin Katz, and Nikolaos Aletras. LexGLUE: A benchmark dataset for legal language understanding in English. InProceed- ings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 4310–4330, 2022
work page 2022
-
[7]
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways.Journal of machine learning research, 24(240):1–113, 2023
work page 2023
-
[8]
Boolq: Exploring the surprising difficulty of natural yes/no questions
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions. InProceedings of the 2019 conference of the north American chapter of the association for com- putational linguistics: Human language technologies, volume 1 (long and short papers)...
work page 2019
-
[9]
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory- efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344– 16359, 2022
work page 2022
-
[10]
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingx- uan Wang, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
GoE- motions: A dataset of fine-grained emotions
Dorottya Demszky, Dana Movshovitz-Attias, Jeongwoo Ko, Alan Cowen, Gaurav Nemade, and Sujith Ravi. GoE- motions: A dataset of fine-grained emotions. InPro- ceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4040–4054, 2020
work page 2020
-
[12]
Prefillonly: An infer- ence engine for prefill-only workloads in large language model applications
Kuntai Du, Bowen Wang, Chen Zhang, Yiming Cheng, Qing Lan, Hejian Sang, Yihua Cheng, Jiayi Yao, Xi- aoxuan Liu, Yifan Qiao, et al. Prefillonly: An infer- ence engine for prefill-only workloads in large language model applications. InProceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles, pages 399–414, 2025
work page 2025
-
[13]
Glam: Efficient scaling of language models with mixture-of-experts
Nan Du, Yanping Huang, Andrew M Dai, Simon Tong, Dmitry Lepikhin, Yuanzhong Xu, Maxim Krikun, Yanqi Zhou, Adams Wei Yu, Orhan Firat, et al. Glam: Efficient scaling of language models with mixture-of-experts. In International conference on machine learning, pages 5547–5569. PMLR, 2022
work page 2022
-
[14]
Moral stories: Situated reason- ing about norms, intents, actions, and their consequences
Denis Emelin, Ronan Le Bras, Jena D Hwang, Maxwell Forbes, and Yejin Choi. Moral stories: Situated reason- ing about norms, intents, actions, and their consequences. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 698– 718, 2021
work page 2021
-
[15]
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learn- ing Research, 23(120):1–39, 2022
work page 2022
-
[16]
FlashInfer. Cascade Inference. https://flashinfer. ai/2024/02/02/cascade-inference.html, 2024. Blog post. Accessed: 2026-04-23
work page 2024
-
[17]
Trevor Gale, Deepak Narayanan, Cliff Young, and Matei Zaharia. Megablocks: Efficient sparse training with mixture-of-experts.Proceedings of Machine Learning and Systems, 5:288–304, 2023
work page 2023
-
[18]
{Cost-Efficient} large lan- guage model serving for multi-turn conversations with {CachedAttention}
Bin Gao, Zhuomin He, Puru Sharma, Qingxuan Kang, Djordje Jevdjic, Junbo Deng, Xingkun Yang, Zhou 13 Yu, and Pengfei Zuo. {Cost-Efficient} large lan- guage model serving for multi-turn conversations with {CachedAttention}. In2024 USENIX annual technical conference (USENIX ATC 24), pages 111–126, 2024
work page 2024
-
[19]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Ariel Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Elastic MoE: Unlocking the Inference-Time Scalability of Mixture-of-Experts
Naibin Gu, Zhenyu Zhang, Yuchen Feng, Yilong Chen, Peng Fu, Zheng Lin, Shuohuan Wang, Yu Sun, Hua Wu, Weiping Wang, et al. Elastic moe: Unlocking the inference-time scalability of mixture-of-experts.arXiv preprint arXiv:2509.21892, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Sti: Turbocharge nlp inference at the edge via elastic pipelin- ing
Liwei Guo, Wonkyo Choe, and Felix Xiaozhu Lin. Sti: Turbocharge nlp inference at the edge via elastic pipelin- ing. InProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, pages 791– 803, 2023
work page 2023
- [22]
-
[23]
Fastermoe: modeling and optimizing training of large-scale dy- namic pre-trained models
Jiaao He, Jidong Zhai, Tiago Antunes, Haojie Wang, Fuwen Luo, Shangfeng Shi, and Qin Li. Fastermoe: modeling and optimizing training of large-scale dy- namic pre-trained models. InProceedings of the 27th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, pages 120–134, 2022
work page 2022
-
[24]
Jun He, Liqun Wang, Liu Liu, Jiao Feng, and Hao Wu. Long document classification from local word glimpses via recurrent attention learning.IEEE Access, 7:40707– 40718, 2019
work page 2019
-
[25]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[26]
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Dehao Chen, Mia Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V Le, Yonghui Wu, et al. Gpipe: Effi- cient training of giant neural networks using pipeline parallelism.Advances in neural information processing systems, 32, 2019
work page 2019
-
[27]
Changho Hwang, Wei Cui, Yifan Xiong, Ziyue Yang, Ze Liu, Han Hu, Zilong Wang, Rafael Salas, Jithin Jose, Prabhat Ram, et al. Tutel: Adaptive mixture-of-experts at scale.Proceedings of Machine Learning and Systems, 5:269–287, 2023
work page 2023
-
[28]
Pre- gated moe: An algorithm-system co-design for fast and scalable mixture-of-expert inference
Ranggi Hwang, Jianyu Wei, Shijie Cao, Changho Hwang, Xiaohu Tang, Ting Cao, and Mao Yang. Pre- gated moe: An algorithm-system co-design for fast and scalable mixture-of-expert inference. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA), pages 1018–1031. IEEE, 2024
work page 2024
-
[29]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, et al. Llama guard: Llm-based input-output safeguard for human-ai conversations.arXiv preprint arXiv:2312.06674, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, De- vendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts.arXiv preprint arXiv:2401.04088, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Chenyu Jiang, Ye Tian, Zhen Jia, Shuai Zheng, Chuan Wu, and Yida Wang. Lancet: Accelerating mixture- of-experts training via whole graph computation- communication overlapping.Proceedings of Machine Learning and Systems, 6:74–86, 2024
work page 2024
-
[32]
Fu, Christopher Ré, and Azalia Mirhoseini
Jordan Juravsky, Bradley Brown, Ryan Ehrlich, Daniel Y Fu, Christopher Ré, and Azalia Mirhoseini. Hydra- gen: High-throughput llm inference with shared prefixes. arXiv preprint arXiv:2402.05099, 2024
-
[33]
Keisuke Kamahori, Tian Tang, Yile Gu, Kan Zhu, and Baris Kasikci. Fiddler: Cpu-gpu orchestration for fast inference of mixture-of-experts models.arXiv preprint arXiv:2402.07033, 2024
-
[34]
Swapmoe: Serving off-the-shelf moe-based large language models with tunable memory budget
Rui Kong, Yuanchun Li, Qingtian Feng, Weijun Wang, Xiaozhou Ye, Ye Ouyang, Linghe Kong, and Yunxin Liu. Swapmoe: Serving off-the-shelf moe-based large language models with tunable memory budget. InPro- ceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6710–6720, 2024
work page 2024
-
[35]
Vijay Anand Korthikanti, Jared Casper, Sangkug Lym, Lawrence McAfee, Michael Andersch, Mohammad Shoeybi, and Bryan Catanzaro. Reducing activation re- computation in large transformer models.Proceedings of Machine Learning and Systems, 5:341–353, 2023
work page 2023
-
[36]
Efficient memory manage- ment for large language model serving with pagedatten- tion
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory manage- ment for large language model serving with pagedatten- tion. InProceedings of the 29th symposium on operating systems principles, pages 611–626, 2023. 14
work page 2023
-
[37]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, De- hao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. Gshard: Scaling gi- ant models with conditional computation and automatic sharding.arXiv preprint arXiv:2006.16668, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[38]
Fast inference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. In International Conference on Machine Learning, pages 19274–19286. PMLR, 2023
work page 2023
-
[39]
Accelerating distributed {MoE} training and inference with lina
Jiamin Li, Yimin Jiang, Yibo Zhu, Cong Wang, and Hong Xu. Accelerating distributed {MoE} training and inference with lina. In2023 USENIX Annual Technical Conference (USENIX ATC 23), pages 945–959, 2023
work page 2023
-
[40]
PyTorch Distributed: Experiences on Accelerating Data Parallel Training
Shen Li, Yanli Zhao, Rohan Varma, Omkar Salpekar, Pieter Noordhuis, Teng Li, Adam Paszke, Jeff Smith, Brian Vaughan, Pritam Damania, et al. Pytorch dis- tributed: Experiences on accelerating data parallel train- ing.arXiv preprint arXiv:2006.15704, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[41]
Ring Attention with Blockwise Transformers for Near-Infinite Context
Hao Liu, Matei Zaharia, and Pieter Abbeel. Ring at- tention with blockwise transformers for near-infinite context.arXiv preprint arXiv:2310.01889, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Cachegen: Kv cache compression and streaming for fast large lan- guage model serving
Yuhan Liu, Hanchen Li, Yihua Cheng, Siddhant Ray, Yuyang Huang, Qizheng Zhang, Kuntai Du, Jiayi Yao, Shan Lu, Ganesh Ananthanarayanan, et al. Cachegen: Kv cache compression and streaming for fast large lan- guage model serving. InProceedings of the ACM SIG- COMM 2024 Conference, pages 38–56, 2024
work page 2024
-
[43]
Learning word vectors for sentiment analysis
Andrew Maas, Raymond E Daly, Peter T Pham, Dan Huang, Andrew Y Ng, and Christopher Potts. Learning word vectors for sentiment analysis. InProceedings of the 49th annual meeting of the association for computa- tional linguistics: Human language technologies, pages 142–150, 2011
work page 2011
-
[44]
Factscore: Fine-grained atomic evaluation of factual precision in long form text generation
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. Factscore: Fine-grained atomic evaluation of factual precision in long form text generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12076–12100, 2023
work page 2023
-
[45]
Pipedream: Gen- eralized pipeline parallelism for dnn training
Deepak Narayanan, Aaron Harlap, Amar Phanishayee, Vivek Seshadri, Nikhil R Devanur, Gregory R Ganger, Phillip B Gibbons, and Matei Zaharia. Pipedream: Gen- eralized pipeline parallelism for dnn training. InPro- ceedings of the 27th ACM symposium on operating sys- tems principles, pages 1–15, 2019
work page 2019
-
[46]
Twitter Financial News Sentiment
Neural Magic. Twitter Financial News Sentiment. https://huggingface.co/datasets/zeroshot/ twitter-financial-news-sentiment , 2022. Hug- ging Face dataset. Accessed: 2026-04-23
work page 2022
-
[47]
NVIDIA H100 Tensor Core GPU Archi- tecture Whitepaper
NVIDIA. NVIDIA H100 Tensor Core GPU Archi- tecture Whitepaper. https://www.nvidia.com/en- us/data-center/h100/, 2026. Accessed: 2026-04- 23
work page 2026
-
[48]
NVIDIA. TensorRT-LLM. https://github.com/ NVIDIA/TensorRT-LLM, 2026. GitHub repository. Ac- cessed: 2026-04-23
work page 2026
-
[49]
Richard Yuanzhe Pang, Alicia Parrish, Nitish Joshi, Nikita Nangia, Jason Phang, Angelica Chen, Vishakh Padmakumar, Johnny Ma, Jana Thompson, He He, et al. Quality: Question answering with long input texts, yes! InProceedings of the 2022 Conference of the North American Chapter of the Association for Com- putational Linguistics: Human Language Technologies...
work page 2022
-
[50]
Splitwise: Efficient generative llm inference using phase splitting
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. Splitwise: Efficient generative llm inference using phase splitting. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA), pages 118–132. IEEE, 2024
work page 2024
-
[51]
Yulei Qian, Fengcun Li, Xiangyang Ji, Xiaoyu Zhao, Jianchao Tan, Kefeng Zhang, and Xunliang Cai. Eps- moe: Expert pipeline scheduler for cost-efficient moe inference.arXiv preprint arXiv:2410.12247, 2024
-
[52]
Chengwei Qin, Aston Zhang, Zhuosheng Zhang, Jiaao Chen, Michihiro Yasunaga, and Diyi Yang. Is chat- gpt a general-purpose natural language processing task solver? InProceedings of the 2023 conference on em- pirical methods in natural language processing, pages 1339–1384, 2023
work page 2023
-
[53]
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Heyi Tang, Feng Ren, Teng Ma, Shangming Cai, Yineng Zhang, Mingxing Zhang, et al. Mooncake: A kvcache- centric disaggregated architecture for llm serving.ACM Transactions on Storage, 2024
work page 2024
-
[54]
Deepspeed-moe: Advancing mixture-of-experts inference and training to power next-generation ai scale
Samyam Rajbhandari, Conglong Li, Zhewei Yao, Min- jia Zhang, Reza Yazdani Aminabadi, Ammar Ahmad Awan, Jeff Rasley, and Yuxiong He. Deepspeed-moe: Advancing mixture-of-experts inference and training to power next-generation ai scale. InInternational confer- ence on machine learning, pages 18332–18346. PMLR, 2022
work page 2022
-
[55]
Zero: Memory optimizations toward train- ing trillion parameter models
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory optimizations toward train- ing trillion parameter models. InSC20: international 15 conference for high performance computing, networking, storage and analysis, pages 1–16. IEEE, 2020
work page 2020
-
[56]
Zero-infinity: Breaking the gpu memory wall for extreme scale deep learning
Samyam Rajbhandari, Olatunji Ruwase, Jeff Rasley, Shaden Smith, and Yuxiong He. Zero-infinity: Breaking the gpu memory wall for extreme scale deep learning. In Proceedings of the international conference for high per- formance computing, networking, storage and analysis, pages 1–14, 2021
work page 2021
-
[57]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[58]
Flexgen: High-throughput generative inference of large language models with a single gpu
Ying Sheng, Lianmin Zheng, Binhang Yuan, Zhuohan Li, Max Ryabinin, Beidi Chen, Percy Liang, Christopher Ré, Ion Stoica, and Ce Zhang. Flexgen: High-throughput generative inference of large language models with a single gpu. InInternational Conference on Machine Learning, pages 31094–31116. PMLR, 2023
work page 2023
-
[59]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: Training multi-billion parameter lan- guage models using model parallelism.arXiv preprint arXiv:1909.08053, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[60]
Elasticmoe: An effi- cient auto scaling method for mixture-of-experts models
Gursimran Singh, Timothy Yu, Haley Li, Cheng Chen, Hanieh Sadri, Qintao Zhang, Yu Zhang, Ying Xiong, Yong Zhang, and Zhenan Fan. Elasticmoe: An effi- cient auto scaling method for mixture-of-experts models. arXiv preprint arXiv:2510.02613, 2025
-
[61]
Text classifi- cation via large language models
Xiaofei Sun, Xiaoya Li, Jiwei Li, Fei Wu, Shangwei Guo, Tianwei Zhang, and Guoyin Wang. Text classifi- cation via large language models. InFindings of the As- sociation for Computational Linguistics: EMNLP 2023, pages 8990–9005, 2023
work page 2023
-
[62]
Surge AI. The Toxicity Dataset. https://github. com/surge-ai/toxicity, 2022. GitHub repository. Accessed: 2026-04-23
work page 2022
-
[63]
Characterizing and optimizing llm inference workloads on cpu-gpu coupled architectures
Prabhu Vellaisamy, Thomas Labonte, Sourav Chakraborty, Matt Turner, Samantika Sury, and John Paul Shen. Characterizing and optimizing llm inference workloads on cpu-gpu coupled architectures. In2025 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), pages 49–61. IEEE, 2025
work page 2025
-
[64]
Moe-infinity: Offloading-efficient moe model serving.arXiv e-prints, pages arXiv–2401, 2024
Leyang Xue, Yao Fu, Zhan Lu, Luo Mai, and Mahesh Marina. Moe-infinity: Offloading-efficient moe model serving.arXiv e-prints, pages arXiv–2401, 2024
work page 2024
-
[65]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chen- gen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
Exploiting inter- layer expert affinity for accelerating mixture-of-experts model inference
Jinghan Yao, Quentin Anthony, Aamir Shafi, Hari Sub- ramoni, and Dhabaleswar K DK Panda. Exploiting inter- layer expert affinity for accelerating mixture-of-experts model inference. In2024 IEEE International parallel and distributed processing symposium (IPDPS), pages 915–925. IEEE, 2024
work page 2024
-
[67]
Chunkatten- tion: Efficient self-attention with prefix-aware kv cache and two-phase partition
Lu Ye, Ze Tao, Yong Huang, and Yang Li. Chunkatten- tion: Efficient self-attention with prefix-aware kv cache and two-phase partition. InProceedings of the 62nd An- nual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), pages 11608–11620, 2024
work page 2024
-
[68]
Orca: A distributed serving system for {Transformer-Based} generative models
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soo- jeong Kim, and Byung-Gon Chun. Orca: A distributed serving system for {Transformer-Based} generative models. In16th USENIX symposium on operating sys- tems design and implementation (OSDI 22), pages 521– 538, 2022
work page 2022
-
[69]
Junjie Zhang, Ruobing Xie, Yupeng Hou, Wayne Xin Zhao, Leyu Lin, and Ji-Rong Wen. Recommendation as instruction following: A large language model empow- ered recommendation approach.ACM Transactions on Information Systems, 43(5):1–37, 2026
work page 2026
-
[70]
Yilong Zhao, Shuo Yang, Kan Zhu, Lianmin Zheng, Baris Kasikci, Yang Zhou, Jiarong Xing, and Ion Sto- ica. Blendserve: Optimizing offline inference for auto- regressive large models with resource-aware batching. arXiv preprint arXiv:2411.16102, 2024
-
[71]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody H Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. Sglang: Efficient execution of structured language model pro- grams.Advances in neural information processing sys- tems, 37:62557–62583, 2024
work page 2024
-
[72]
Zhen Zheng, Xin Ji, Taosong Fang, Fanghao Zhou, Chuanjie Liu, and Gang Peng. Batchllm: Optimizing large batched llm inference with global prefix sharing and throughput-oriented token batching.arXiv preprint arXiv:2412.03594, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[73]
{DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. {DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving. In 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pages 193–210, 2024. 16
work page 2024
-
[74]
Yanqi Zhou, Tao Lei, Hanxiao Liu, Nan Du, Yanping Huang, Vincent Zhao, Andrew M Dai, Quoc V Le, James Laudon, et al. Mixture-of-experts with expert choice routing.Advances in Neural Information Processing Systems, 35:7103–7114, 2022
work page 2022
-
[75]
ST-MoE: Designing Stable and Transferable Sparse Expert Models
Barret Zoph, Irwan Bello, Sameer Kumar, Nan Du, Yan- ping Huang, Jeff Dean, Noam Shazeer, and William Fe- dus. St-moe: Designing stable and transferable sparse expert models.arXiv preprint arXiv:2202.08906, 2022. Appendix A Scheduling Algorithm Pseudocode Algorithm 1 summarizes one scheduling round of MoE-Prefill’s frontend (§7), integrating prefix-aware ...
work page internal anchor Pith review Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.