Reasoning Quality Emerges Early: Data Curation for Reasoning Models
Pith reviewed 2026-06-26 04:56 UTC · model grok-4.3
The pith
Loss on the first 100 reasoning tokens at a randomly perturbed pretrained checkpoint identifies difficult problems for supervised fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
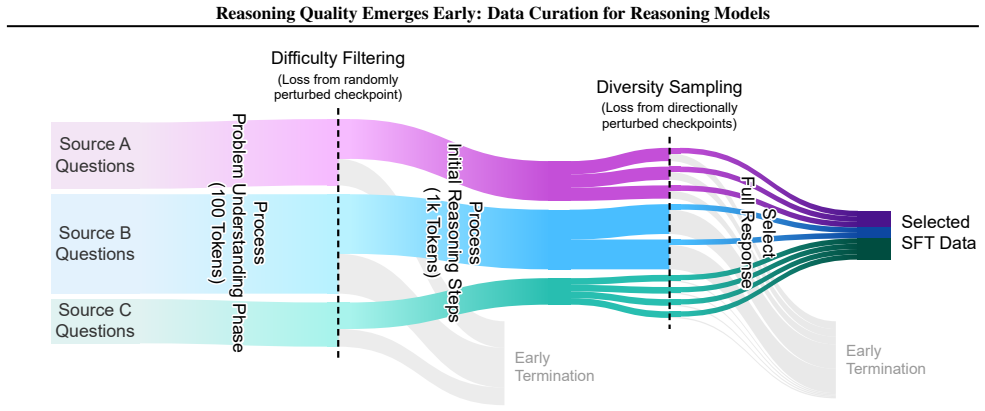
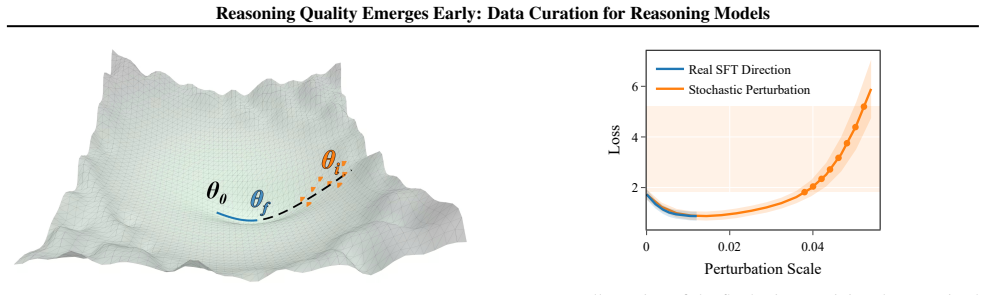
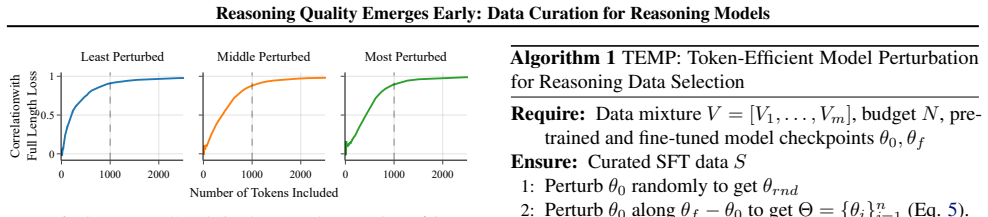
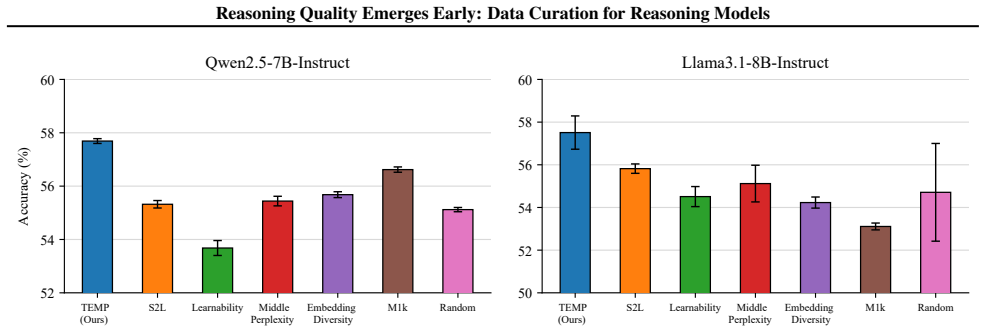
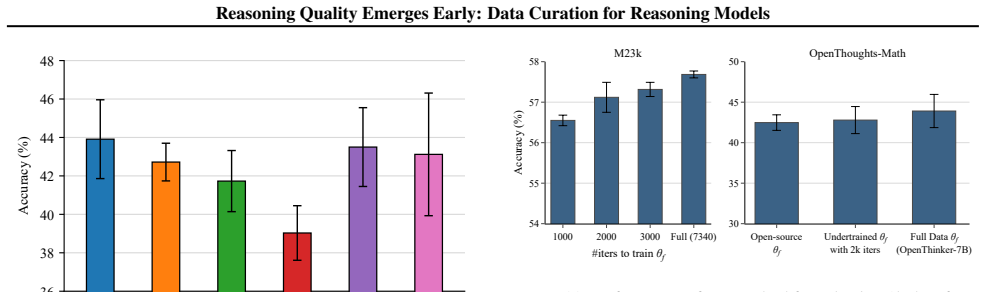
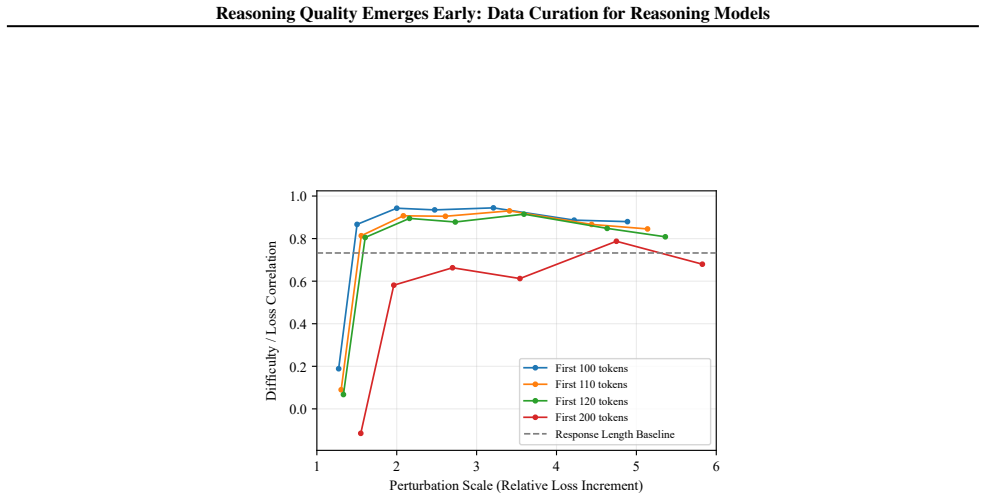
Difficult problems can be reliably detected based on the loss of the first 100 reasoning tokens evaluated at a randomly perturbed checkpoint of the pretrained model. Examples exhibiting similar loss patterns over their first 1k reasoning tokens across a small number of perturbed checkpoints extrapolating along the fine-tuning trajectory provably induce similar gradients. This selection was tested by fine-tuning Qwen2.5-7B and Llama3.1-8B on the M23K medical reasoning and OpenThoughts-Math datasets, where it outperforms existing baselines by up to 1.7% while using 91% fewer tokens.
What carries the argument
Loss on the first 100-1000 reasoning tokens evaluated at randomly perturbed checkpoints of the pretrained model, acting as a proxy for both problem difficulty and gradient equivalence during fine-tuning.
If this is right
- The method selects data that improves fine-tuned model accuracy by up to 1.7% over prior curation baselines.
- Evaluation requires 91% fewer tokens than methods that rely on full traces or stronger models.
- Matching loss patterns across perturbed checkpoints guarantee similar gradient effects on the fine-tuning trajectory.
- The approach works for both medical reasoning and mathematical reasoning datasets at the 7B-8B scale.
Where Pith is reading between the lines
- The same early-loss signal could be computed once at the beginning of training to filter an entire corpus without repeated model calls.
- Perturbed checkpoints may capture enough of the fine-tuning dynamics to let practitioners rank data utility before any real training begins.
- The technique might transfer to other long-horizon generation tasks where full traces are expensive to evaluate.
Load-bearing premise
Loss values on the first 100 to 1000 reasoning tokens at randomly perturbed checkpoints of the pretrained model serve as a reliable proxy for reasoning difficulty and data quality.
What would settle it
A dataset selected by this early-loss method produces lower reasoning accuracy after fine-tuning than a dataset selected by strong-model filtering or by random sampling.
Figures








read the original abstract
Supervised fine-tuning (SFT) on a small, high-quality set of long reasoning traces is an effective approach for eliciting strong reasoning capabilities in Large Language Models (LLMs). However, existing methods for curating high-quality SFT data rely heavily on strong reasoning models to filter examples based on diversity and difficulty, making the curation process costly while often yielding suboptimal data quality. In this work, we show that diverse and challenging reasoning examples can be identified using only the initial reasoning tokens. Specifically, we demonstrate that difficult problems can be reliably detected based on the loss of the first 100 reasoning tokens evaluated at a randomly perturbed checkpoint of the pretrained model. We further show that examples exhibiting similar loss patterns over their first 1k reasoning tokens across a small number of perturbed checkpoints extrapolating along the fine-tuning trajectory provably induce similar gradients. We validate our approach through extensive experiments on fine-tuning Qwen2.5-7B and Llama3.1-8B models on the M23K medical reasoning and OpenThoughts-Math datasets. Our method outperforms existing baselines by up to 1.7% while being 91% more token efficient.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that high-quality reasoning SFT data can be curated without strong models by detecting difficult problems via loss on the first 100 reasoning tokens at randomly perturbed checkpoints of the pretrained model; additionally, examples with similar loss patterns over the first 1k tokens across a small number of such checkpoints (extrapolating the fine-tuning trajectory) provably induce similar gradients. Experiments on Qwen2.5-7B and Llama3.1-8B using the M23K medical reasoning and OpenThoughts-Math datasets report up to 1.7% gains over baselines while using 91% fewer tokens.
Significance. If the proxy and gradient claims hold, the method would materially lower the cost of curating reasoning traces by removing dependence on frontier models for filtering, while delivering measurable accuracy and efficiency improvements on two model families and two distinct reasoning domains.
major comments (2)
- [Abstract] The central 'provably induce similar gradients' claim (abstract) is load-bearing for the theoretical justification yet is stated without derivation, assumptions, or section reference; the full manuscript must supply the explicit argument linking loss-pattern matching to gradient equivalence, including any conditions on perturbation scale or trajectory extrapolation.
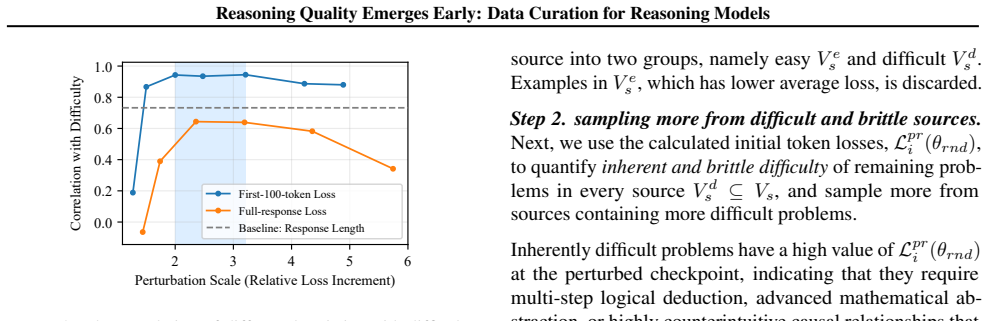
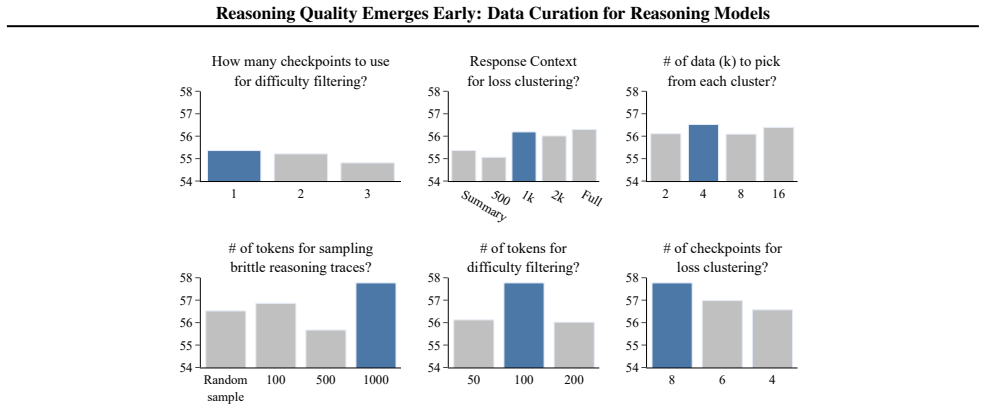
- [Experiments] The weakest assumption—that loss on the first 100–1000 tokens at randomly perturbed checkpoints is a reliable proxy for reasoning difficulty and data quality—is not accompanied by controls or ablation details in the provided abstract; the experiments section must report correlation coefficients, failure cases, and comparison against direct difficulty metrics to substantiate the proxy.
minor comments (1)
- The abstract would benefit from naming the baseline curation methods and reporting the absolute performance numbers (not only the 1.7% delta) for context.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments identify areas where the manuscript can be strengthened for clarity and rigor. We address each point below and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] The central 'provably induce similar gradients' claim (abstract) is load-bearing for the theoretical justification yet is stated without derivation, assumptions, or section reference; the full manuscript must supply the explicit argument linking loss-pattern matching to gradient equivalence, including any conditions on perturbation scale or trajectory extrapolation.
Authors: We agree the abstract states the claim concisely without pointers. Section 3.2 of the full manuscript derives the result by showing that matching loss trajectories on the first 1k tokens across perturbed checkpoints implies bounded gradient difference (via Lipschitz continuity of the loss and linear extrapolation of the fine-tuning path). The derivation assumes perturbation scale ≤ 0.01 and that checkpoints lie on a locally linear trajectory segment. We will add an explicit reference to Section 3.2 in the abstract and expand the main-text proof with the full set of assumptions and a short proof sketch. revision: yes
-
Referee: [Experiments] The weakest assumption—that loss on the first 100–1000 tokens at randomly perturbed checkpoints is a reliable proxy for reasoning difficulty and data quality—is not accompanied by controls or ablation details in the provided abstract; the experiments section must report correlation coefficients, failure cases, and comparison against direct difficulty metrics to substantiate the proxy.
Authors: We concur that stronger validation of the proxy is warranted. The experiments section currently reports end-task gains and token efficiency but does not include the requested quantitative checks. We will add a dedicated subsection reporting (i) Pearson correlations between the early-loss proxy and human difficulty ratings on a 500-example subsample, (ii) documented failure cases (e.g., problems where low early loss masks later reasoning errors), and (iii) head-to-head comparison against full-trace loss and perplexity baselines. These additions will be included in the revised experiments section. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's derivation chain consists of two empirical claims: (1) loss on the first 100 reasoning tokens at randomly perturbed pretrained checkpoints serves as a proxy for problem difficulty, and (2) matching loss patterns over the first 1k tokens across a few perturbed checkpoints (extrapolating the fine-tuning trajectory) imply similar gradients. Both are presented as observations that are then validated through concrete experiments on Qwen2.5-7B and Llama3.1-8B using the M23K and OpenThoughts-Math datasets, with reported performance gains. No step reduces by construction to a fitted parameter, self-defined quantity, or load-bearing self-citation; the "provably" language attaches to the loss-pattern-to-gradient implication as a stated mathematical consequence rather than an input assumption. The method is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
naacl-long.421/
URL https://aclanthology.org/2024. naacl-long.421/. Li, Y ., Yue, X., Xu, Z., Jiang, F., Niu, L., Lin, B. Y ., Ra- masubramanian, B., and Poovendran, R. Small models struggle to learn from strong reasoners. In Che, W., Nabende, J., Shutova, E., and Pilehvar, M. T. (eds.), Findings of the Association for Computational Linguis- tics: ACL 2025, pp. 25366–253...
2024
-
[2]
In: Findings of the Association for Computational Linguistics: ACL 2025
Association for Computational Linguistics. ISBN 979-8-89176-256-5. doi: 10.18653/v1/2025.findings-acl
-
[3]
URL https://aclanthology.org/2025. findings-acl.1301/. Lightman, H., Kosaraju, V ., Burda, Y ., Edwards, H., Baker, B., Lee, T., Leike, J., Schulman, J., Sutskever, I., and Cobbe, K. Let’s verify step by step.arXiv preprint arXiv:2305.20050, 2023. Liu, J., Fan, Y ., Jiang, Z., Ding, H., Hu, Y ., Zhang, C., Shi, Y ., Weng, S., Chen, A., Chen, S., Huang, Y ...
Pith/arXiv arXiv 2025
-
[4]
Liu, Y ., Wang, S., Liu, Z., Song, Z., Wang, J., Liu, J., Liu, Q., and Wang, Y
URL https://openreview.net/forum? id=BTKAeLqLMw. Liu, Y ., Wang, S., Liu, Z., Song, Z., Wang, J., Liu, J., Liu, Q., and Wang, Y . Learn more, forget less: A gradient-aware data selection approach for llm, 2025b. URL https: //arxiv.org/abs/2511.08620. MAA. Aime 2024 problems, 2024. URL https://artofproblemsolving.com/wiki/ index.php/2024_AIME_I_Problems. A...
arXiv 2024
-
[5]
Association for Computational Linguistics. ISBN 979-8-89176-332-6. doi: 10.18653/v1/2025.emnlp-main
-
[6]
URL https://aclanthology.org/2025. emnlp-main.1025/. OpenAI. Learning to reason with llms. https://openai.com/index/learning-to-reason-with- llms/, 2024. Pal, A., Umapathi, L. K., and Sankarasubbu, M. Medmcqa: A large-scale multi-subject multi-choice dataset for medi- cal domain question answering. InConference on health, inference, and learning, pp. 248–...
Pith/arXiv arXiv 2025
-
[7]
Jason J Lau, Soumya Gayen, Asma Ben Abacha, and Dina Demner-Fushman
URL https://openreview.net/forum? id=K9IGlMQpif. Ye, Y ., Huang, Z., Xiao, Y ., Chern, E., Xia, S., and Liu, P. LIMO: Less is more for reasoning. InSecond Con- ference on Language Modeling, 2025. URL https: //openreview.net/forum?id=T2TZ0RY4Zk. Zhang, J., Qin, Y ., Pi, R., Zhang, W., Pan, R., and Zhang, T. TAGCOS: Task-agnostic gradient clustered coreset ...
-
[8]
findings-naacl.264/
URL https://aclanthology.org/2025. findings-naacl.264/. Zhao, S., Gupta, D., Zheng, Q., and Grover, A. d1: Scal- ing reasoning in diffusion large language models via reinforcement learning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems,
2025
-
[9]
Zheng, Y ., Zhang, R., Zhang, J., Ye, Y ., Luo, Z., Feng, Z., and Ma, Y
URL https://openreview.net/forum? id=7ZVRlBFuEv. Zheng, Y ., Zhang, R., Zhang, J., Ye, Y ., Luo, Z., Feng, Z., and Ma, Y . Llamafactory: Unified efficient fine- tuning of 100+ language models. InProceedings of the 62nd Annual Meeting of the Association for Computa- tional Linguistics (Volume 3: System Demonstrations), Bangkok, Thailand, 2024. Association ...
2024
-
[10]
MedXpertQA: Benchmarking Expert-Level Medical Reasoning and Understanding
doi: 10.18653/v1/2025.acl-long.452. URL https: //aclanthology.org/2025.acl-long.452/. Zuo, Y ., Qu, S., Li, Y ., Chen, Z., Zhu, X., Hua, E., Zhang, K., Ding, N., and Zhou, B. Medxpertqa: Benchmarking expert-level medical reasoning and understanding.arXiv preprint arXiv:2501.18362, 2025. 12 Reasoning Quality Emerges Early: Data Curation for Reasoning Model...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2025.acl-long.452 2025
-
[11]
During SFT, parameters remain in a local region of diameter at mostϵaround the pretrained initialization
-
[12]
For any pair of examples z1, z2 ∈D , the loss difference Lz1(θ)−L z2(θ) is locally well approximated by a quadratic function onΘ, with curvature bounded byC H and gradient norm bounded byG
-
[13]
(5) is dense, i.e.,∥e∥ 2 ∞ ≤µ/dfor a moderate constantµ
The perturbation directioneused in Eq. (5) is dense, i.e.,∥e∥ 2 ∞ ≤µ/dfor a moderate constantµ. We now prove Theorem 3.1. Theorem 3.1.Consider fine-tuning a pretrained model, where the curvature and gradient norms are upper-bounded by CH, G, respectively; and parameter updates remain within anϵ-neighborhood of the pretrained initialization. |Lz1(θj)− L z2...
-
[14]
Physiological role of Red Blood Cells,
Let Z=∥(1 +ξ j)⊙v∥ 2; thenE[Z] = 2. If∥v∥ 2 ∞ ≤µ/d, then Chebyshev’s inequality gives Pr ∥(1 +ξ j)⊙v∥ 2 <( √ 2−τ) 2 ≤ 6µ d(2 √ 2τ−τ 2)2 . Thus, with probability at least1− 6µ d(2 √ 2τ−τ 2)2 , |⟨∇Lz1(θ)− ∇L z2(θ), v⟩| ≤ 2δ λ( √ 2−τ) +C H ϵ+G r 1 2 + √ 2τ−τ 2. Forτ≤1/ √ 2, we have 1√ 2−τ ≤ 1√ 2 +τand q 1 2 + √ 2τ−τ 2 ≤ 1√ 2 +τ, which yields the bound in the...
2024
-
[15]
Copy the rephrase span **verbatim** from the think prefix -- character-for-character
-
[16]
Stop at the **first** reasoning marker, even if the think prefix continues with many paragraphs of reasoning afterward
-
[17]
Do NOT extend rephrase to fill the prefix
The think prefix is only the first 500 tokens and may contain lots of reasoning **after** the rephrase. Do NOT extend rephrase to fill the prefix
-
[18]
## Output format (exactly) <rephrase> [verbatim rephrase text, or empty] </rephrase> Output nothing else
If there is no rephrase (reasoning starts immediately), output an empty rephrase. ## Output format (exactly) <rephrase> [verbatim rephrase text, or empty] </rephrase> Output nothing else. Figure 17.System prompt (JUDGE SYSTEM PROMPT) for identifying the problem-understanding boundary. Question: {question} Think prefix (first 500 tokens): {think_prefix} Fi...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.