Benchmarking Local LLMs for Natural-Language-to-SQL Querying in Biopharmaceutical Manufacturing: An Empirical Benchmark on Consumer-Grade Hardware
Pith reviewed 2026-06-28 17:02 UTC · model grok-4.3
The pith
Code-tuned general-purpose LLMs outperform a domain-specific biomedical model on natural-language-to-SQL for biopharmaceutical manufacturing data when run locally on consumer hardware.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
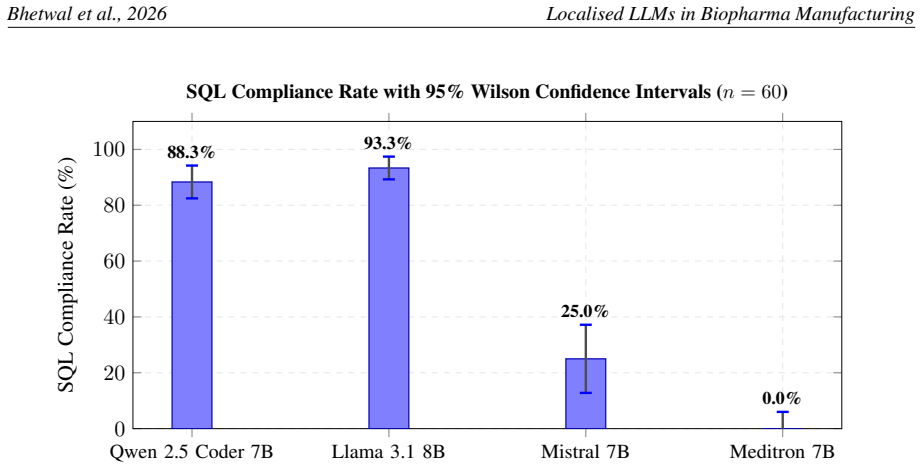
Qwen 2.5 Coder 7B, Llama 3.1 8B, and Mistral 7B generated SQL for all tasks while Meditron 7B failed on nearly all due to context-window and SQL capability limits; Llama achieved highest SQL compliance and Qwen the strongest text similarity and factual consistency, with no statistically significant difference between the two leaders. The results indicate that code-tuned general-purpose LLMs outperform the domain-specific biomedical model on structured query generation for pharmaceutical manufacturing data.
What carries the argument
The PharmaBatchDB AI FastAPI evaluation platform that runs the four LLMs locally against a 63,000-record synthetic Microsoft SQL Server database covering Batch, MES, and CIP modules and scores them on SQL extraction rate, compliance, factual consistency, ROUGE-L, hallucination rate, throughput, and latency across 60 domain questions.
If this is right
- Code-tuned LLMs can produce usable SQL from natural language for manufacturing execution and clean-in-place data without sending data to external servers.
- A domain-specific biomedical LLM is not automatically the best choice for technical structured-query tasks in this setting.
- Fully local GxP-aligned natural-language query systems are technically possible on consumer-grade hardware.
- Current performance still requires human oversight and downstream validation before use in regulated pharmaceutical environments.
Where Pith is reading between the lines
- The same local-LLM approach could be tested in other regulated data domains such as clinical trial records or financial compliance logs.
- Fine-tuning a code model on additional pharma-specific SQL examples might raise consistency without needing larger context windows.
- Adding an automated validation layer that checks generated SQL against known schema constraints could reduce the oversight burden over time.
Load-bearing premise
The synthetic database and the set of 60 domain-specific natural-language questions sufficiently stand in for real biopharmaceutical manufacturing data and user needs.
What would settle it
Running the identical models and questions against an actual non-synthetic biopharmaceutical manufacturing database and finding substantially lower SQL compliance or factual consistency scores.
Figures

read the original abstract
Biopharmaceutical manufacturing organizations operate under regulatory frameworks such as FDA guidance, EU Good Manufacturing Practice (GMP), and the EU AI Act, which can restrict the use of cloud-based artificial intelligence systems. Locally deployed large language models (LLMs) offer a privacy-preserving alternative, but their suitability for pharmaceutical manufacturing tasks remains underexplored. This study evaluates four open-source LLMs (Qwen 2.5 Coder 7B, Llama 3.1 8B, Mistral 7B, and Meditron 7B) deployed locally via Ollama for natural-language-to-SQL generation over a pharmaceutical manufacturing database. A FastAPI-based evaluation platform, PharmaBatchDB AI, was developed using a synthetic Microsoft SQL Server database containing approximately 63,000 records across Batch, Manufacturing Execution System (MES), and Clean-In-Place (CIP) modules. Models were benchmarked on 60 domain-specific natural-language questions using metrics including SQL extraction rate, SQL compliance, factual consistency, ROUGE-L, hallucination rate, throughput, and latency. Qwen 2.5 Coder 7B, Llama 3.1 8B, and Mistral 7B generated SQL for all evaluation tasks, while Meditron 7B failed on nearly all tasks due to context-window limitations and poor SQL generation capability. Llama 3.1 8B achieved the highest SQL compliance, whereas Qwen 2.5 Coder 7B achieved the strongest overall text similarity and factual consistency. Performance differences between the two leading models were not statistically significant. The results show that code-tuned general-purpose LLMs outperform a domain-specific biomedical model on structured query generation for pharmaceutical manufacturing data. Although fully local, GxP-aligned NLQ systems are feasible on consumer hardware, current performance levels still require human oversight and downstream validation for regulated use.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper benchmarks four locally deployed open-source LLMs (Qwen 2.5 Coder 7B, Llama 3.1 8B, Mistral 7B, Meditron 7B) via Ollama on natural-language-to-SQL generation over a synthetic Microsoft SQL Server database (~63k records in Batch/MES/CIP modules) using 60 domain-specific questions. It develops a FastAPI platform (PharmaBatchDB AI) and reports metrics including SQL extraction rate, compliance, factual consistency, ROUGE-L, hallucination rate, throughput, and latency. Key findings: code-tuned models succeed on all tasks while Meditron fails due to context limits; Llama 3.1 8B leads in SQL compliance and Qwen 2.5 Coder 7B in text similarity/factual consistency (differences not statistically significant); overall, local GxP-aligned NLQ systems are feasible on consumer hardware but require human oversight and validation.
Significance. If the synthetic benchmark generalizes, this provides concrete evidence on the viability of privacy-preserving local LLMs for regulated biopharmaceutical manufacturing tasks, with explicit credit for the reproducible evaluation platform, use of multiple complementary metrics, and direct comparison of code-tuned vs. domain-specific models on consumer hardware. The work fills an underexplored application gap under GxP and EU AI Act constraints.
major comments (2)
- [Abstract and evaluation platform description] Abstract and evaluation platform description: The central feasibility claim for 'fully local, GxP-aligned NLQ systems' in regulated biopharmaceutical manufacturing rests on the synthetic database (~63,000 records across Batch/MES/CIP) and 60 domain-specific questions being representative of real data distributions, join complexities, user query needs, and regulatory edge cases; no validation, schema comparison, or real-world query corpus is provided, so the observed outperformance of code-tuned models and the oversight requirement may not transfer.
- [Results (model performance comparisons)] Results (model performance comparisons): The claim that 'Performance differences between the two leading models were not statistically significant' is presented without error bars, confidence intervals, p-values, test statistic, or sample-size details, preventing assessment of whether the ranking (Llama highest compliance, Qwen highest similarity/consistency) is robust.
minor comments (2)
- The abstract lists throughput and latency among the metrics but provides no quantitative values or hardware specifications for the consumer-grade deployment; adding these would strengthen the feasibility claim.
- Consider adding a table or figure summarizing per-model metric scores with the 60 questions broken down by module (Batch/MES/CIP) to allow readers to inspect where failures occur.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly where appropriate.
read point-by-point responses
-
Referee: [Abstract and evaluation platform description] The central feasibility claim for 'fully local, GxP-aligned NLQ systems' in regulated biopharmaceutical manufacturing rests on the synthetic database (~63,000 records across Batch/MES/CIP) and 60 domain-specific questions being representative of real data distributions, join complexities, user query needs, and regulatory edge cases; no validation, schema comparison, or real-world query corpus is provided, so the observed outperformance of code-tuned models and the oversight requirement may not transfer.
Authors: We agree this is a substantive limitation. The synthetic database was constructed with domain-expert input to approximate realistic schemas and record volumes for Batch, MES, and CIP modules, and the 60 questions target common query patterns in pharmaceutical manufacturing. However, access to real proprietary data is restricted under GxP regulations. In revision we will add an explicit Limitations subsection that qualifies the feasibility claim as preliminary, discusses the synthetic benchmark's scope, and outlines the need for future validation against anonymized real-world corpora where feasible. revision: partial
-
Referee: [Results (model performance comparisons)] The claim that 'Performance differences between the two leading models were not statistically significant' is presented without error bars, confidence intervals, p-values, test statistic, or sample-size details, preventing assessment of whether the ranking (Llama highest compliance, Qwen highest similarity/consistency) is robust.
Authors: We accept the criticism. The manuscript states the differences are not statistically significant without supporting statistics or variability measures. In the revised version we will either remove this claim or augment the results with per-metric standard deviations across the 60 queries and, where appropriate, bootstrap confidence intervals to allow readers to evaluate robustness directly. revision: yes
Circularity Check
No circularity: purely empirical benchmark with direct measurements
full rationale
The paper is an empirical benchmarking study that deploys four LLMs locally, runs them on 60 fixed natural-language questions against a synthetic 63k-record SQL Server database, and reports observed metrics (SQL extraction rate, compliance, ROUGE-L, etc.). No equations, fitted parameters, derivations, or predictions are present. Claims rest on direct experimental outcomes rather than any self-referential reduction or imported uniqueness result. Self-citations, if any, are not load-bearing for a derivation chain. This is the standard case of an honest non-finding for a measurement paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The synthetic database and 60 questions adequately represent real biopharmaceutical manufacturing data and queries.
- domain assumption Standard metrics (SQL compliance, factual consistency, ROUGE-L) capture suitability for regulated manufacturing use.
Reference graph
Works this paper leans on
-
[1]
2024 , howpublished =
2024
-
[2]
2025 , howpublished =
2025
-
[3]
2026 , howpublished =
2026
-
[4]
arXiv preprint , year =
Li, Xuan and others , title =. arXiv preprint , year =
-
[5]
Information , volume =
Zhang, Wei and others , title =. Information , volume =. 2025 , publisher =
2025
-
[6]
Proceedings of the VLDB Endowment , volume =
Li, Bowen and Luo, Yuyu and Chai, Chengliang and Li, Guoliang and Tang, Nan , title =. Proceedings of the VLDB Endowment , volume =. 2024 , doi =
2024
-
[7]
and Willey, Madeleine and Asija, Akshay and Bianchi, Olivia and Alvarado, Cornelis X
Koretsky, Matthew J. and Willey, Madeleine and Asija, Akshay and Bianchi, Olivia and Alvarado, Cornelis X. and Nayak, Tejaswi and Kuznetsov, Nikita and Kim, Soojin and Nalls, Mike A. and Khashabi, Daniel and Faghri, Faraz , title =. PubMed Central , year =
-
[8]
and Willey, Madeleine and Asija, Akshay and Bianchi, Olivia and Alvarado, Cornelis X
Koretsky, Matthew J. and Willey, Madeleine and Asija, Akshay and Bianchi, Olivia and Alvarado, Cornelis X. and Nayak, Tejaswi and Kuznetsov, Nikita and Kim, Soojin and Nalls, Mike A. and Khashabi, Daniel and Faghri, Faraz , title =. arXiv preprint , year =
-
[9]
JMIR Medical Informatics , year =
Lee, Kyung-Hoon and Jang, Sungwon and Kim, Gab-Jin and Park, Seongwoo and Kim, Doheon and Kwon, Oh-Joong and Lee, Joo-Hyoung and Kim, Young-Hoon , title =. JMIR Medical Informatics , year =
-
[10]
PubMed Central , year =
Sharma, Rohit and others , title =. PubMed Central , year =
-
[11]
and Sablayrolles, Alexandre and Mensch, Arthur and Bamford, Chris and Chaplot, Devendra Singh and
Jiang, Albert Q. and Sablayrolles, Alexandre and Mensch, Arthur and Bamford, Chris and Chaplot, Devendra Singh and. arXiv preprint , year =
-
[12]
2023 , howpublished =
2023
-
[13]
2022 , howpublished =
Tobiasz, Tobias and others , title =. 2022 , howpublished =
2022
-
[14]
Text Summarization Branches Out , year =
Lin, Chin-Yew , title =. Text Summarization Branches Out , year =
-
[15]
2021 , howpublished =
Ram\'. 2021 , howpublished =
2021
-
[16]
1997 , howpublished =
1997
-
[17]
2011 , howpublished =
2011
-
[18]
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages =
Yu, Tao and Zhang, Rui and Yang, Kai and Yasunaga, Michihiro and Wang, Dongxu and Li, Zifan and Ma, James and Li, Irene and Yao, Qingning and Roman, Shanelle and Zhang, Zilin and Radev, Dragomir , title =. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages =. 2018 , publisher =
2018
-
[19]
Proceedings of the ACM on Management of Data , volume =
Luoma, Kyle and Kumar, Arun , title =. Proceedings of the ACM on Management of Data , volume =. 2025 , doi =
2025
-
[20]
Applied Sciences , volume =
Zhou, Ruikang and Zhang, Fan , title =. Applied Sciences , volume =. 2025 , publisher =
2025
-
[21]
and Longo, Antonella and Yeun, Chan Yeob , title =
Puthal, Deepak and Mishra, Amit Kumar and Mohanty, Saraju P. and Longo, Antonella and Yeun, Chan Yeob , title =. SN Computer Science , volume =. 2025 , publisher =
2025
-
[22]
Advances in Neural Information Processing Systems , volume =
Li, Jinyang and Hui, Binyuan and Qu, Ge and Yang, Jiaxi and Li, Binhua and Li, Bowen and Wang, Bailin and Qin, Bowen and Cao, Rongyu and Geng, Ruiying and others , title =. Advances in Neural Information Processing Systems , volume =. 2023 , note =
2023
-
[23]
arXiv preprint , year =
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and others , title =. arXiv preprint , year =
-
[24]
arXiv preprint , year =
Hui, Binyuan and Yang, Jian and Cui, Zeyu and Yang, Jiaxi and Liu, Dayiheng and Zhang, Lei and Liu, Tianyu and Zhang, Jiajun and Yu, Bowen and others , title =. arXiv preprint , year =
-
[25]
arXiv preprint , year =
Chen, Zeming and Hern. arXiv preprint , year =
-
[26]
and Milan, Kieran and Quan, John and Ramalho, Tiago and Grabska-Barwinska, Agnieszka and Hassabis, Demis and Clopath, Claudia and Kumaran, Dharshan and Hadsell, Raia , title =
Kirkpatrick, James and Pascanu, Razvan and Rabinowitz, Neil and Veness, Joel and Desjardins, Guillaume and Rusu, Andrei A. and Milan, Kieran and Quan, John and Ramalho, Tiago and Grabska-Barwinska, Agnieszka and Hassabis, Demis and Clopath, Claudia and Kumaran, Dharshan and Hadsell, Raia , title =. Proceedings of the National Academy of Sciences , volume ...
2017
-
[27]
and Haberland, Matt and Reddy, Tyler and Cournapeau, David and Burovski, Evgeni and Peterson, Pearu and Weckesser, Warren and Bright, Jonathan and others , title =
Virtanen, Pauli and Gommers, Ralf and Oliphant, Travis E. and Haberland, Matt and Reddy, Tyler and Cournapeau, David and Burovski, Evgeni and Peterson, Pearu and Weckesser, Warren and Bright, Jonathan and others , title =. Nature Methods , volume =. 2020 , publisher =
2020
-
[28]
and Malin, Bradley and Klement, William and Eysenbach, Gunther , title =
El Emam, Khaled and Leung, Tiffany I. and Malin, Bradley and Klement, William and Eysenbach, Gunther , title =. Journal of Medical Internet Research , year =. doi:10.2196/52508 , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.