Gaussian Mixture Attention: Linear-Time Sequence Mixing via Probabilistic Latent Routing
Pith reviewed 2026-06-27 13:31 UTC · model grok-4.3
The pith
Gaussian Mixture Attention routes queries and keys through K learned Gaussian components to induce implicit affinities without building the full pairwise matrix.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
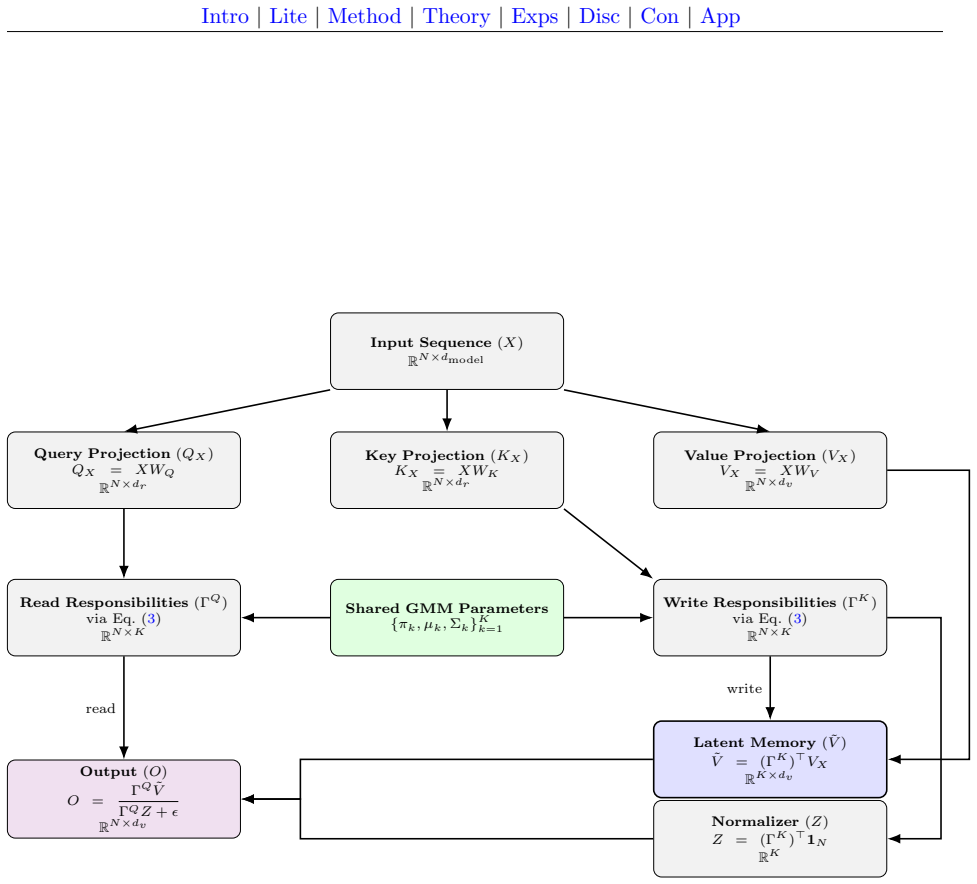
GMA maps each token to a responsibility vector over K Gaussian mixture components; the affinity between any two tokens is the inner product of their responsibility vectors, and value aggregation occurs through a K-dimensional latent memory. Because matrix multiplication is associative, the N-by-N affinity matrix never materializes; only the two N-by-K responsibility matrices are stored and multiplied, yielding O(NK) memory for fixed K. The parameterization of the mixture means and covariances is end-to-end differentiable, and the resulting gradient flow is modulated by the responsibility assignments.
What carries the argument
Posterior responsibility vectors over K shared Gaussian mixture components whose overlap supplies the implicit affinity and whose K-slot memory stores and retrieves values.
If this is right
- Memory and compute remain linear in sequence length once K is fixed.
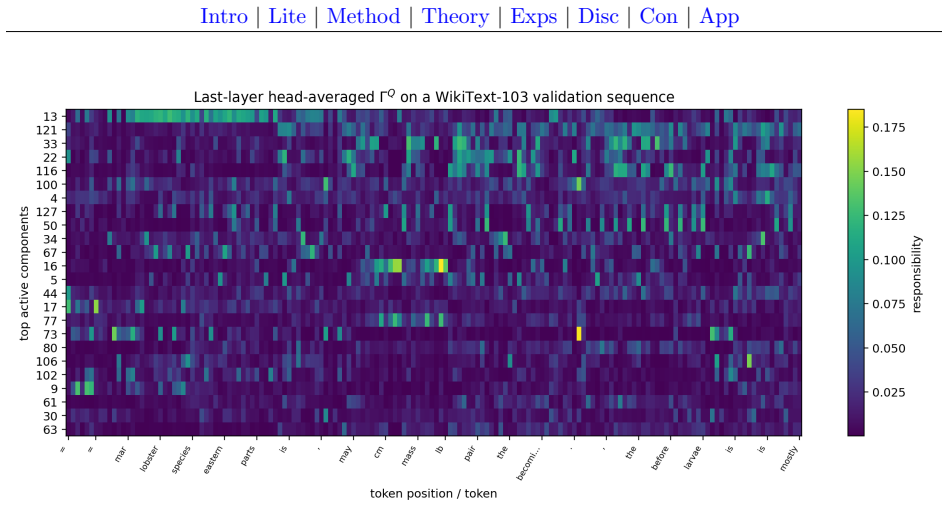
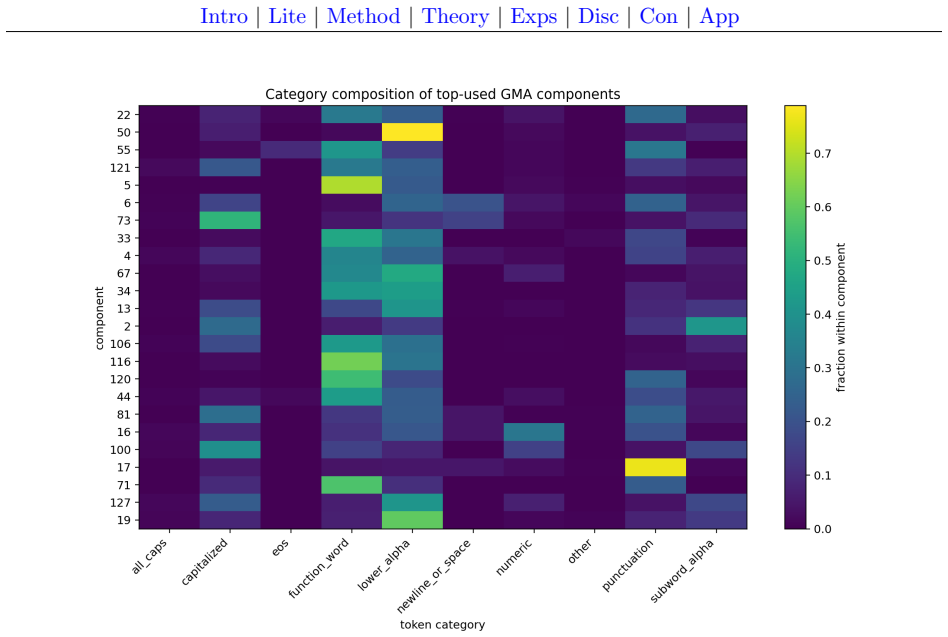
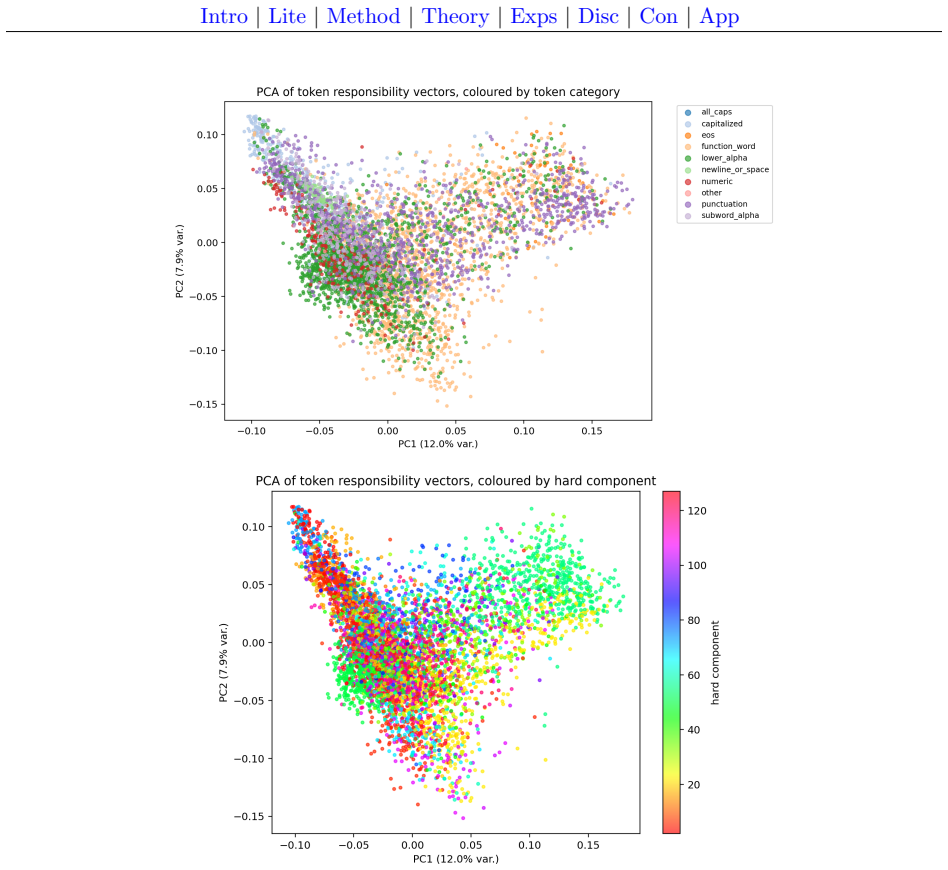
- The model produces responsibility vectors that can be inspected for alignment with surface token categories.
- Causal GMA outperforms tested linear and random-feature attention baselines on WikiText-103 language modeling.
- The formulation admits both bidirectional and strictly causal variants with the same latent-routing machinery.
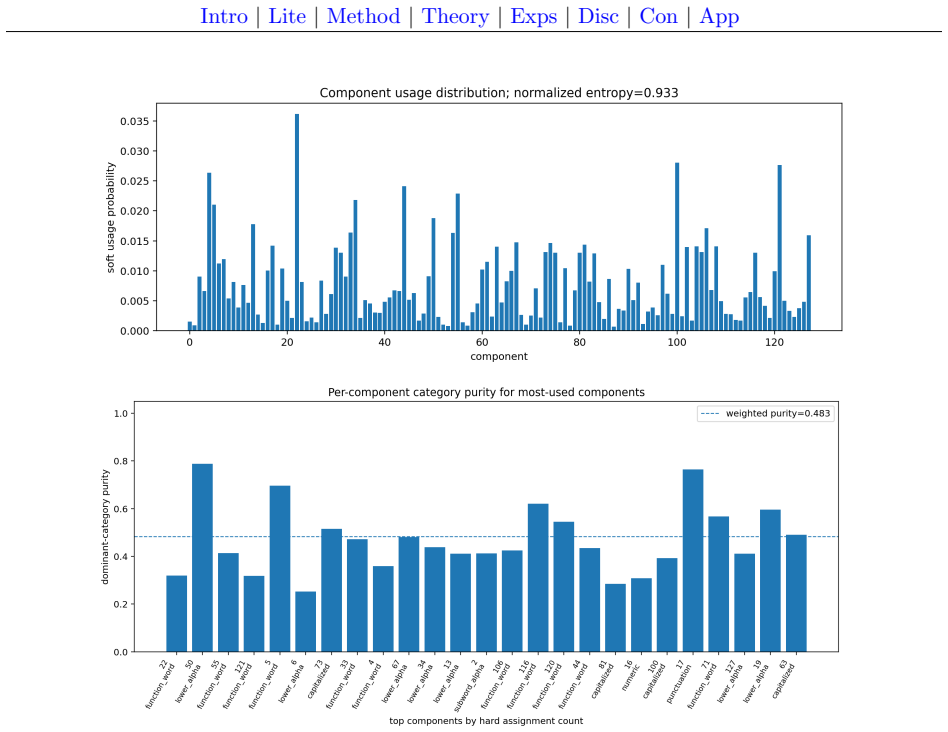
- Component usage is broad and the learned routing exhibits moderate stability properties.
Where Pith is reading between the lines
- The same responsibility-space view could be applied to other sequence operators that currently rely on explicit pairwise comparisons.
- Because only K slots are maintained, the method may combine naturally with techniques that dynamically adjust K during training or inference.
- The probabilistic interpretation invites direct comparison with mixture-of-experts routing on the same latent space.
Load-bearing premise
Mapping every token to a responsibility vector over the same fixed set of K Gaussians is enough to capture the token interactions required by the tasks.
What would settle it
A controlled experiment in which increasing K does not close the performance gap to full attention on a task known to require fine-grained pairwise distinctions.
Figures

read the original abstract
The dense token-to-token interaction pattern of standard dot-product attention remains a central bottleneck in scaling Transformer architectures to long contexts. We introduce \textbf{Gaussian Mixture Attention (GMA)}, a probabilistic attention-style sequence mixer that replaces explicit pairwise query--key comparison with routing through $K$ learned Gaussian mixture components. Queries and keys are mapped to posterior \textit{responsibility} vectors over a shared latent routing space; their overlap defines an implicit responsibility-space affinity, while values are written into and read from a $K$-slot latent memory. By exploiting the associativity of matrix multiplication, GMA avoids materializing the induced $N\times N$ affinity matrix and instead uses two responsibility matrices whose dominant activation storage scales as $\mathcal{O}(NK)$ rather than $\mathcal{O}(N^2)$ for fixed $K$. We formulate bidirectional and causal variants of GMA, provide an end-to-end differentiable parameterization of the Gaussian mixture components, and analyze its responsibility-modulated gradient structure, constrained non-negative low-rank affinity interpretation, and local routing stability. Empirically, GMA exhibits the intended fixed-$K$ linear memory scaling and is competitive with attention-style baselines on long-context classification, while causal GMA improves over tested linear/random-feature attention variants on WikiText-103 but remains behind optimized causal SDPA and Mamba in the current implementation. Analysis of learned responsibilities further shows broad component usage and moderate alignment with surface-form token categories, supporting GMA as a probabilistic, interpretable, fixed-$K$ linear-time attention-style alternative rather than a universal replacement for optimized softmax attention or state-space models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Gaussian Mixture Attention (GMA), which replaces explicit pairwise query-key dot products with routing of queries and keys to posterior responsibility vectors over K learned Gaussian mixture components in a shared latent space. Implicit affinities arise from responsibility overlaps (dot products in responsibility space), values are read/written via a K-slot latent memory, and linear-time computation follows from associativity of matrix multiplication yielding O(NK) dominant storage instead of O(N^2). Bidirectional and causal variants are defined with an end-to-end differentiable parameterization of the mixture; the work also analyzes responsibility-modulated gradients, a constrained non-negative low-rank affinity view, and local routing stability. Empirical claims include intended fixed-K linear memory scaling, competitiveness with attention baselines on long-context classification, and improvement over tested linear/random-feature attention on WikiText-103 (while trailing optimized SDPA and Mamba).
Significance. The structural linear-complexity claim, which follows directly from associativity applied to the responsibility matrices independent of fitted Gaussian values, is a clear strength and does not rely on circular fitting. If the learned components produce responsibility overlaps that preserve task-relevant token interactions, GMA supplies an interpretable probabilistic fixed-K alternative to standard attention with potential advantages for analysis and long-context scaling. The differentiable parameterization and gradient-structure analysis are additional assets that could aid future work on routing-based mixers.
major comments (2)
- [Abstract] Abstract (performance claims paragraph): the assertion that responsibility-space overlap suffices to capture necessary token interactions (the weakest assumption) is load-bearing for positioning GMA as a viable attention-style alternative, yet the reported evidence is limited to 'broad component usage and moderate alignment with surface-form token categories'; no direct test (e.g., effective-rank comparison, information-preservation metric, or controlled ablation on K versus explicit attention) isolates sufficiency versus mere correlation on the evaluated tasks.
- [Abstract] Empirical evaluation (implied in abstract results): the qualified outcomes ('competitive', 'improves over tested variants but remains behind') are presented without reported experimental setup details, error bars, full baseline specifications, or ablations on mixture-component collapse or K sensitivity; this weakens assessment of whether the low-rank responsibility affinity maintains expressivity comparable to explicit attention when the mapping is imperfect.
minor comments (2)
- [Abstract] Abstract: the description of the causal variant's results could be clarified by explicitly naming the linear/random-feature baselines used, to allow readers to gauge the scope of the improvement claim.
- [Method] Notation: the transition from responsibility vectors to the implicit affinity (R_q R_k^T) is described at a high level; a short explicit equation in the method section would improve readability of the associativity argument.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We respond point-by-point to the major comments below, indicating where revisions to the abstract are warranted.
read point-by-point responses
-
Referee: [Abstract] Abstract (performance claims paragraph): the assertion that responsibility-space overlap suffices to capture necessary token interactions (the weakest assumption) is load-bearing for positioning GMA as a viable attention-style alternative, yet the reported evidence is limited to 'broad component usage and moderate alignment with surface-form token categories'; no direct test (e.g., effective-rank comparison, information-preservation metric, or controlled ablation on K versus explicit attention) isolates sufficiency versus mere correlation on the evaluated tasks.
Authors: We agree the abstract summarizes the supporting analysis concisely. The full manuscript reports empirical competitiveness on long-context tasks together with responsibility analysis showing broad component usage and moderate alignment. These results provide evidence that the overlaps capture task-relevant interactions for the evaluated settings. However, we acknowledge the absence of a direct isolation test such as effective-rank comparison. We have therefore revised the abstract to qualify the claim more precisely, stating that the overlaps enable competitive performance as a probabilistic alternative without asserting universal sufficiency. revision: partial
-
Referee: [Abstract] Empirical evaluation (implied in abstract results): the qualified outcomes ('competitive', 'improves over tested variants but remains behind') are presented without reported experimental setup details, error bars, full baseline specifications, or ablations on mixture-component collapse or K sensitivity; this weakens assessment of whether the low-rank responsibility affinity maintains expressivity comparable to explicit attention when the mapping is imperfect.
Authors: Abstracts are concise summaries and standardly omit full experimental details, error bars, baseline specifications, and ablations; these appear in the methods, results, and appendix sections of the manuscript. The qualified phrasing accurately reflects the reported outcomes without overstatement. We do not consider changes to the abstract necessary on this point. revision: no
Circularity Check
No circularity: linear scaling follows from matrix associativity independent of learned parameters
full rationale
The paper's derivation of O(NK) scaling rests on the explicit algebraic identity that the responsibility-space affinity computation R_q (R_k^T V) can be reassociated without materializing the N x N matrix; this is a structural property of matrix multiplication and holds for any fixed-K responsibility matrices regardless of how the Gaussians are fitted. The mapping of queries/keys to posteriors is defined directly via the mixture model, with no self-referential definitions or fitted inputs renamed as predictions. No self-citations appear in the load-bearing steps, and the claim that the mechanism captures task-relevant interactions is presented as an empirical hypothesis rather than a derived necessity. The overall chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- K
- Gaussian mixture parameters
axioms (1)
- standard math Associativity of matrix multiplication permits computing the output via responsibility matrices without materializing the full affinity matrix.
invented entities (1)
-
Gaussian mixture components as latent routing space
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Ledsam, Agnieszka Grabska- Barwinska, Kyle R
ˇZiga Avsec, Vikram Agarwal, Daniel Visentin, Joseph R. Ledsam, Agnieszka Grabska- Barwinska, Kyle R. Taylor, Yannis Assael, John Jumper, Pushmeet Kohli, and David R. Kelley. Effective gene expression prediction from sequence by integrating long-range interac- tions.Nature Methods, 18:1196–1203, 2021
2021
-
[2]
Neural machine translation by jointly learning to align and translate, 2016
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate, 2016
2016
-
[3]
Peters, and Arman Cohan
Iz Beltagy, Matthew E. Peters, and Arman Cohan. Longformer: The long-document trans- former, 2020
2020
-
[4]
Estimating or propagating gradients through stochastic neurons for conditional computation, 2013
Yoshua Bengio, Nicholas L´ eonard, and Aaron Courville. Estimating or propagating gradients through stochastic neurons for conditional computation, 2013
2013
-
[5]
Christopher M. Bishop. Mixture density networks. Technical Report NCRG/94/004, Neural Computing Research Group, Aston University, 1994
1994
-
[6]
Bishop.Pattern Recognition and Machine Learning
Christopher M. Bishop.Pattern Recognition and Machine Learning. Springer, New York, 2006
2006
-
[7]
Blei and Michael I
David M. Blei and Michael I. Jordan. Variational inference for dirichlet process mixtures. Bayesian Analysis, 1(1):121–143, 2006. Intro|Lite|Method|Theory|Exps|Disc|Con|App
2006
-
[8]
Cambridge University Press, 2018
Stephen Boyd and Lieven Vandenberghe.Introduction to Applied Linear Algebra – Vectors, Matrices, and Least Squares. Cambridge University Press, 2018
2018
-
[9]
Generating long sequences with sparse transformers, 2019
Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers, 2019
2019
-
[10]
Rethinking attention with performers
Krzysztof Marcin Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Quincy Davis, Afroz Mohiuddin, Lukasz Kaiser, David Benjamin Belanger, Lucy J Colwell, and Adrian Weller. Rethinking attention with performers. InInternational Conference on Learning Representations, 2021
2021
-
[11]
Cormen, Charles E
Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein.Introduction to Algorithms. MIT Press, 3 edition, 2009
2009
-
[12]
Switchhead: accelerat- ing transformers with mixture-of-experts attention
R´ obert Csord´ as, Piotr Piekos, Kazuki Irie, and J¨ urgen Schmidhuber. Switchhead: accelerat- ing transformers with mixture-of-experts attention. InProceedings of the 38th International Conference on Neural Information Processing Systems, NIPS ’24, Red Hook, NY, USA, 2024. Curran Associates Inc
2024
-
[13]
Fu, Stefano Ermon, Atri Rudra, and Christopher R´ e
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher R´ e. Flashattention: fast and memory-efficient exact attention with io-awareness. InProceedings of the 36th Interna- tional Conference on Neural Information Processing Systems, NIPS ’22, Red Hook, NY, USA,
-
[14]
Curran Associates Inc
-
[15]
A. P. Dempster, N. M. Laird, and D. B. Rubin. Maximum likelihood from incomplete data via the em algorithm.Journal of the Royal Statistical Society. Series B (Methodological), 39(1):1–38, 1977
1977
-
[16]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations, 2021
2021
-
[17]
Switch transformers: scaling to trillion parameter models with simple and efficient sparsity.J
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: scaling to trillion parameter models with simple and efficient sparsity.J. Mach. Learn. Res., 23(1), January 2022
2022
-
[18]
Ferguson
Thomas S. Ferguson. A bayesian analysis of some nonparametric problems.The Annals of Statistics, 1(2):209–230, 1973
1973
-
[19]
Mamba: Linear-time sequence modeling with selective state spaces, 2024
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces, 2024
2024
-
[20]
Efficiently modeling long sequences with struc- tured state spaces
Albert Gu, Karan Goel, and Christopher R´ e. Efficiently modeling long sequences with struc- tured state spaces. InInternational Conference on Learning Representations, 2022
2022
-
[21]
Classification via score-based generative modelling, 2022
Yongchao Huang. Classification via score-based generative modelling, 2022
2022
-
[22]
Sampling via gaussian mixture approximations, 2025
Yongchao Huang. Sampling via gaussian mixture approximations, 2025
2025
-
[23]
Gaussian joint embeddings for self-supervised representation learning, 2026
Yongchao Huang. Gaussian joint embeddings for self-supervised representation learning, 2026
2026
-
[24]
Neural bayesian sequential routing, 2026
Yongchao Huang. Neural bayesian sequential routing, 2026. Intro|Lite|Method|Theory|Exps|Disc|Con|App
2026
-
[25]
Jacobs, Michael I
Robert A. Jacobs, Michael I. Jordan, Steven J. Nowlan, and Geoffrey E. Hinton. Adaptive mixtures of local experts.Neural Computation, 3(1):79–87, 1991
1991
-
[26]
Perceiver IO: A general architecture for structured inputs & outputs
Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier J Henaff, Matthew Botvinick, Andrew Zisserman, Oriol Vinyals, and Joao Carreira. Perceiver IO: A general architecture for structured inputs & outputs. InInternational Conference on Learnin...
2022
-
[27]
Perceiver: General perception with iterative attention
Andrew Jaegle, Felix Gimeno, Andrew Brock, Andrew Zisserman, Oriol Vinyals, and Joao Carreira. Perceiver: General perception with iterative attention. InInternational Conference on Machine Learning, pages 4651–4664, 2021
2021
-
[28]
Categorical reparameterization with gumbel-softmax
Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameterization with gumbel-softmax. InInternational Conference on Learning Representations, 2017
2017
-
[29]
Transformers are RNNs: Fast autoregressive transformers with linear attention
Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and Fran¸ cois Fleuret. Transformers are RNNs: Fast autoregressive transformers with linear attention. In Hal Daum´ e III and Aarti Singh, editors,Proceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 5156–5165. PMLR, 13–18 Jul 2020
2020
-
[30]
Reformer: The efficient transformer
Nikita Kitaev, Lukasz Kaiser, and Anselm Levskaya. Reformer: The efficient transformer. In International Conference on Learning Representations, 2020
2020
-
[31]
Lee and H
Daniel D. Lee and H. Sebastian Seung. Learning the parts of objects by non-negative matrix factorization.Nature, 401(6755):788–791, oct 1999
1999
-
[32]
Gshard: Scaling giant models with condi- tional computation and automatic sharding, 2020
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. Gshard: Scaling giant models with condi- tional computation and automatic sharding, 2020
2020
-
[33]
Decoupled weight decay regularization, 2019
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization, 2019
2019
-
[34]
Thang Luong, Hieu Pham, and Christopher D. Manning. Effective approaches to attention- based neural machine translation. In Llu´ ıs M` arquez, Chris Callison-Burch, and Jian Su, ed- itors,Proceedings of the 2015 Conference on Empirical Methods in Natural Language Pro- cessing, pages 1412–1421, Lisbon, Portugal, September 2015. Association for Computationa...
2015
-
[35]
Maddison, Andriy Mnih, and Yee Whye Teh
Chris J. Maddison, Andriy Mnih, and Yee Whye Teh. The concrete distribution: A continuous relaxation of discrete random variables. InInternational Conference on Learning Representa- tions, 2017
2017
-
[36]
Andr´ e F. T. Martins and Ram´ on F. Astudillo. From softmax to sparsemax: a sparse model of attention and multi-label classification. InProceedings of the 33rd International Conference on International Conference on Machine Learning - Volume 48, ICML’16, page 1614–1623. JMLR.org, 2016
2016
-
[37]
Wiley Series in Probability and Statistics
Geoffrey McLachlan and David Peel.Finite Mixture Models. Wiley Series in Probability and Statistics. John Wiley & Sons, 2000
2000
-
[38]
Pointer sentinel mix- ture models, 2016
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mix- ture models, 2016. Intro|Lite|Method|Theory|Exps|Disc|Con|App
2016
-
[39]
Chatgpt-5.5
OpenAI. Chatgpt-5.5. Large language model, 2026. Used for assistance with experimental code development
2026
-
[40]
Curran Associates Inc., Red Hook, NY, USA, 2019
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas K¨ opf, Edward Yang, Zach DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala.PyTorch: an imperative style, high-perform...
2019
-
[41]
Sparse sequence-to-sequence models
Ben Peters, Vlad Niculae, and Andr´ e FT Martins. Sparse sequence-to-sequence models. In Proc. ACL, 2019
2019
-
[42]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In Marina Meila and Tong Zhang, editors,Proceedings of the 38th International Conference on Machin...
2021
-
[43]
The infinite gaussian mixture model
Carl Edward Rasmussen. The infinite gaussian mixture model. InProceedings of the 13th International Conference on Neural Information Processing Systems, NIPS’99, page 554–560, Cambridge, MA, USA, 1999. MIT Press
1999
-
[44]
A constructive definition of dirichlet priors.Statistica Sinica, 4(2):639– 650, 1994
Jayaram Sethuraman. A constructive definition of dirichlet priors.Statistica Sinica, 4(2):639– 650, 1994
1994
-
[45]
Flashattention-3: fast and accurate attention with asynchrony and low-precision
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. Flashattention-3: fast and accurate attention with asynchrony and low-precision. InProceed- ings of the 38th International Conference on Neural Information Processing Systems, NIPS ’24, Red Hook, NY, USA, 2024. Curran Associates Inc
2024
-
[46]
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer
Noam Shazeer, *Azalia Mirhoseini, *Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hin- ton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. InInternational Conference on Learning Representations, 2017
2017
-
[47]
Wellesley-Cambridge Press, 2016
Gilbert Strang.Introduction to Linear Algebra. Wellesley-Cambridge Press, 2016
2016
-
[48]
Long range arena: A benchmark for efficient transformers, 2020
Yi Tay, Mostafa Dehghani, Samira Abnar, Yikang Shen, Dara Bahri, Philip Pham, Jinfeng Rao, Liu Yang, Sebastian Ruder, and Donald Metzler. Long range arena: A benchmark for efficient transformers, 2020
2020
-
[49]
Efficient transformers: A survey
Yi Tay, Mostafa Dehghani, Dara Bahri, and Donald Metzler. Efficient transformers: A survey. ACM Comput. Surv., 55(6), December 2022
2022
-
[50]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InProceedings of the 31st In- ternational Conference on Neural Information Processing Systems, NIPS’17, page 6000–6010, Red Hook, NY, USA, 2017. Curran Associates Inc
2017
-
[51]
Li, Madian Khabsa, Han Fang, and Hao Ma
Sinong Wang, Belinda Z. Li, Madian Khabsa, Han Fang, and Hao Ma. Linformer: Self- attention with linear complexity, 2020. Intro|Lite|Method|Theory|Exps|Disc|Con|App
2020
-
[52]
Nystr¨ omformer: A nystr¨ om-based algorithm for approximating self- attention
Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, and Vikas Singh. Nystr¨ omformer: A nystr¨ om-based algorithm for approximating self- attention. InProceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 14138–14148, 2021
2021
-
[53]
Gated linear attention transformers with hardware-efficient training
Songlin Yang, Bailin Wang, Yikang Shen, Rameswar Panda, and Yoon Kim. Gated linear attention transformers with hardware-efficient training. InProceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org, 2024
2024
-
[54]
Nguyen, Dung D
Tam yen, Tan M. Nguyen, Dung D. Le, Duy Khuong Nguyen, Viet-Anh Tran, Richard G. Baraniuk, Nhat Ho, and Stanley J. Osher. Improving transformers with probabilistic attention keys. InInternational Conference on Machine Learning, 2022
2022
-
[55]
Big bird: transformers for longer sequences
Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, and Amr Ahmed. Big bird: transformers for longer sequences. InProceedings of the 34th International Conference on Neu- ral Information Processing Systems, NIPS ’20, Red Hook, NY, USA, 2020. Curran Associates Inc
2020
-
[56]
Modeling concentrated cross-attention for neural machine translation with gaussian mixture model
Shaolei Zhang and Yang Feng. Modeling concentrated cross-attention for neural machine translation with gaussian mixture model. InFindings of the Association for Computational Linguistics: EMNLP 2021, pages 1401–1411. Association for Computational Linguistics, 2021. A Notation for Gaussian Mixture Attention Table 5 summarizes the notation used in the GMA m...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.