A Novel Approach to OCR using Image Recognition based Classification for Ancient Tamil Inscriptions in Temples
Pith reviewed 2026-05-25 09:34 UTC · model grok-4.3
The pith
A 2D CNN linked to Tesseract recognizes 7th-12th century Tamil inscriptions at 77.7 percent combined efficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
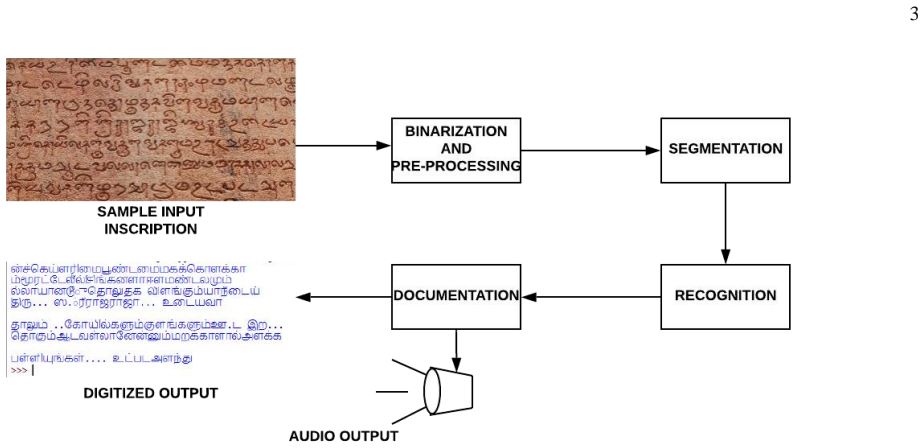
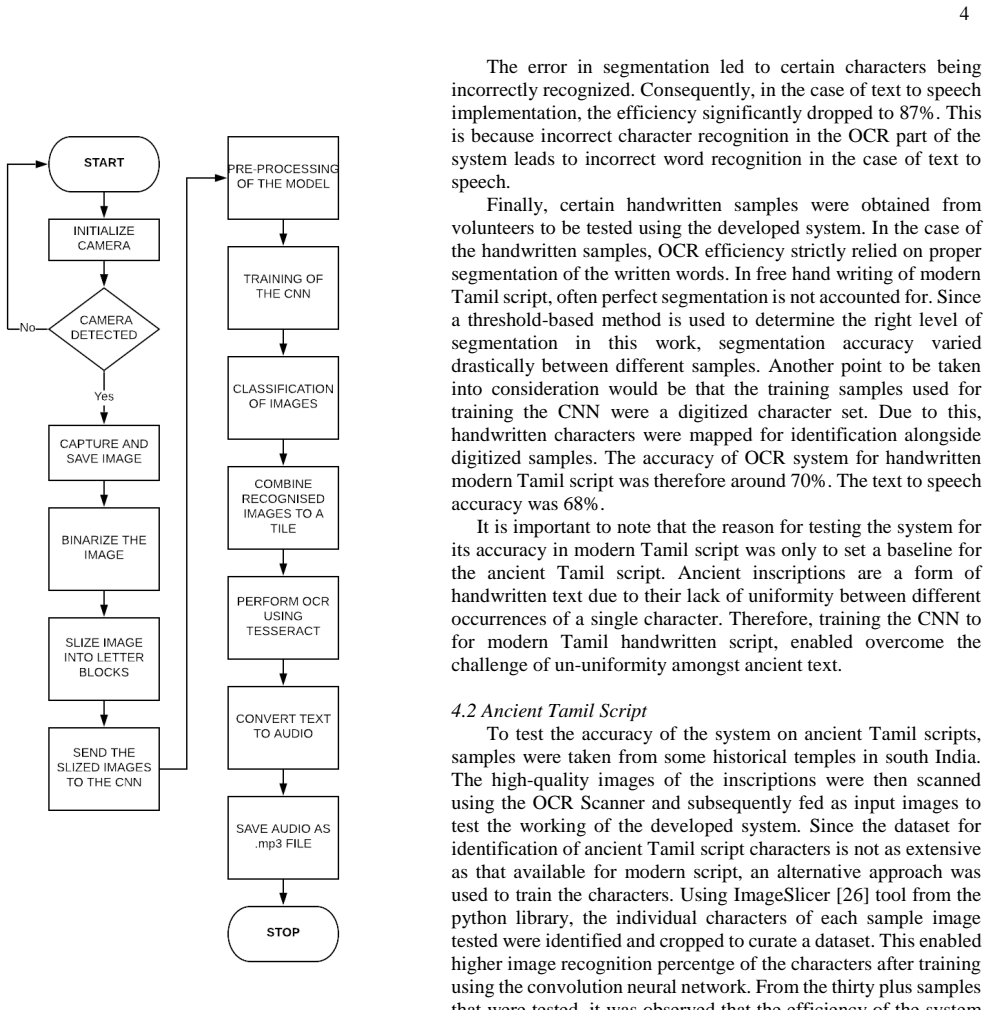
After binarization with Otsu thresholding, a two-dimensional convolutional neural network is trained on cropped images of characters from certain 7th-12th century temple inscriptions; this network is interfaced with Tesseract via pytesseract to classify and recognize the characters, producing digitized text that is also rendered as audio through Google's text-to-speech engine, for an overall efficiency of 77.7 percent on the inscriptions examined.
What carries the argument
The 2D convolutional neural network trained on cropped temple-inscription character images and linked to Tesseract OCR through pytesseract.
If this is right
- The same pipeline processes both modern Tamil and the studied ancient samples.
- Recognized text is converted to spoken audio output.
- A usable dataset for this period can be assembled from limited temple sources rather than exhaustive collection.
- The method supplies a concrete digitization route for inscriptions whose character forms have changed over centuries.
Where Pith is reading between the lines
- Comparable small-dataset CNN approaches could be tested on other historical scripts that also lack large public corpora.
- Accuracy might rise if the same architecture receives additional images from a wider range of temples or if the network depth is adjusted.
- The workflow suggests a route for epigraphers to move from physical inscriptions to searchable digital text without first building massive labeled sets.
Load-bearing premise
The small collection of cropped character images from selected temple inscriptions is representative enough for the 2D CNN to learn features that generalize across 7th-12th century Tamil script without overfitting.
What would settle it
Apply the trained system to an independent collection of 7th-12th century Tamil inscriptions not used in training and check whether the measured recognition rate is substantially lower than 77.7 percent.
Figures

read the original abstract
Recognition of ancient Tamil characters has always been a challenge for epigraphers. This is primarily because the language has evolved over the several centuries and the character set over this time has both expanded and diversified. This proposed work focuses on improving optical character recognition techniques for ancient Tamil script which was in use between the 7th and 12th centuries. While comprehensively curating a functional data set for ancient Tamil characters is an arduous task, in this work, a data set has been curated using cropped images of characters found on certain temple inscriptions, specific to this time as a case study. After using Otsu thresholding method for binarization of the image a two dimensional convolution neural network is defined and used to train, classify and, recognize the ancient Tamil characters. To implement the optical character recognition techniques, the neural network is linked to the Tesseract using the pytesseract library of Python. As an added feature, the work also incorporates Google's text to speech voice engine to produce an audio output of the digitized text. Various samples for both modern and ancient Tamil were collected and passed through the system. It is found that for Tamil inscriptions studied over the considered time period, a combined efficiency of 77.7 percent can be achieved.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a system for OCR of ancient Tamil inscriptions (7th-12th centuries) from temple sources. It curates a dataset of cropped character images, applies Otsu thresholding for binarization, trains a 2D CNN for classification, integrates the output with Tesseract via pytesseract, and adds Google TTS for audio. The central claim is that this pipeline achieves a combined efficiency of 77.7% on the studied inscriptions.
Significance. If the empirical result were reproducible and generalizable, the work would offer a practical tool for digitizing historical Tamil epigraphy. The integration of CNN classification with existing OCR and TTS components is a reasonable engineering approach for a low-resource script, but the absence of any quantitative validation details prevents assessment of whether the 77.7% figure reflects genuine generalization or case-specific performance.
major comments (3)
- [Abstract] Abstract: the reported 77.7% combined efficiency is presented without any dataset statistics (total images, number of distinct characters, temporal distribution across 7th-12th century samples), train/test split, or description of how the metric was computed (per-character, per-inscription, or otherwise). This information is required to evaluate whether the CNN learned generalizable features or simply memorized a small curated collection.
- [Abstract] Abstract and system description: no architecture details, layer counts, filter sizes, or training hyperparameters are supplied for the 2D CNN, nor is any validation procedure (cross-validation, held-out test set) described. Without these, the classification step that underpins the 77.7% claim cannot be reproduced or compared to standard baselines.
- [Abstract] Abstract: the manuscript states that 'various samples for both modern and ancient Tamil were collected and passed through the system' yet supplies no quantitative breakdown of modern vs. ancient performance, error analysis, or comparison against Tesseract alone or other Tamil OCR methods. This omission makes it impossible to isolate the contribution of the CNN component.
minor comments (3)
- [Abstract] The term 'efficiency' is used for the 77.7% figure; the manuscript should clarify whether this denotes accuracy, F1, or another metric and provide the exact formula or aggregation method.
- The description of dataset curation ('cropped images of characters found on certain temple inscriptions') is too vague for a methods section; explicit counts and selection criteria should be added.
- No mention is made of the number of classes (distinct ancient Tamil characters) or class imbalance, both of which are critical for interpreting CNN performance on an evolving script.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the manuscript to supply the missing details where they are available from the original study.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported 77.7% combined efficiency is presented without any dataset statistics (total images, number of distinct characters, temporal distribution across 7th-12th century samples), train/test split, or description of how the metric was computed (per-character, per-inscription, or otherwise). This information is required to evaluate whether the CNN learned generalizable features or simply memorized a small curated collection.
Authors: We agree that these statistics are necessary to assess generalization. The original manuscript described the curation process but omitted numerical details for brevity. In revision we will add the available dataset information, the train/test split employed for the CNN, and clarify that the reported figure is the end-to-end pipeline accuracy on the held-out inscriptions. revision: yes
-
Referee: [Abstract] Abstract and system description: no architecture details, layer counts, filter sizes, or training hyperparameters are supplied for the 2D CNN, nor is any validation procedure (cross-validation, held-out test set) described. Without these, the classification step that underpins the 77.7% claim cannot be reproduced or compared to standard baselines.
Authors: We concur that architecture and training details are required for reproducibility. Although the manuscript refers to a 2D CNN, specific layer counts, filter sizes, and hyperparameters were not listed. We will revise the methods section to document the network architecture and validation procedure used in the original implementation. revision: yes
-
Referee: [Abstract] Abstract: the manuscript states that 'various samples for both modern and ancient Tamil were collected and passed through the system' yet supplies no quantitative breakdown of modern vs. ancient performance, error analysis, or comparison against Tesseract alone or other Tamil OCR methods. This omission makes it impossible to isolate the contribution of the CNN component.
Authors: The work focused on the pipeline for the 7th-12th century inscriptions; modern samples served only for preliminary checks. A full quantitative breakdown, error analysis, or comparison against Tesseract alone and other methods was not performed. We will add a brief discussion of the CNN's role and performance on the ancient samples studied, but a comprehensive comparative evaluation lies outside the original scope. revision: partial
Circularity Check
No circularity: purely empirical result with no derivations or self-referential predictions.
full rationale
The manuscript reports an empirical accuracy of 77.7% obtained by curating a dataset of cropped temple inscription images, applying Otsu binarization, training a 2D CNN, and piping output through Tesseract. No equations, fitted parameters presented as predictions, uniqueness theorems, or self-citations appear in the provided text. The central claim is a direct measurement on the authors' case-study collection rather than a derivation that reduces to its own inputs by construction. This matches the default expectation of a non-circular empirical paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A 2D CNN with unspecified architecture will learn useful features from the curated character images after Otsu binarization.
Reference graph
Works this paper leans on
-
[1]
Archaeological survey of India
“Archaeological survey of India” [online] Available: http://asi.nic.in/publications/
-
[2]
“Tamil Script” [online] Available: https://en.wikipedia.org/wiki/Tamil_script
-
[3]
"Department of Archaeology" [online] Available: http:// www.tnarch.gov.in/epi/ins2.htm
-
[4]
“Middle Chola Temples” S R Balasubramanyam Available: http://ignca.gov.in/Asi_data/62202.pdf
-
[5]
“Optical Character Recognition” [online] Available: https://en.wikipedia.org/wiki/Optical_character_recognition
-
[6]
Tamil character recognition from ancient epigraphical inscription using OCR and NLP,
T. Manigandan, V. Vidhya, V. Dhanalakshmi and B. Nirmala, "Tamil character recognition from ancient epigraphical inscription using OCR and NLP," 2017 International Conference on Energy, Communication, Data Analytics and Soft Computing (ICECDS), Chennai, 2017, pp. 1008-1011
work page 2017
-
[7]
Century Identification and Recognition of Ancient Tamil Character Recognition,
S. Rajakumar and S. V. Bharathi., "Century Identification and Recognition of Ancient Tamil Character Recognition," International Journal of Computer Applications, vol. 26, no. 4, pp. 32-35, July 2011
work page 2011
-
[8]
A Comparative Study of Optical Character Recognition for Tamil Script
R . J. Kannan and R. Phrabhakar, “A Comparative Study of Optical Character Recognition for Tamil Script”, European Journal of Scientific Research ISSN 1450 -216X Vol.35 No.4 (2009), pp.570-582
work page 2009
-
[9]
Tamil Handwritten Character Recognition: Progress and Challenges
K. Punitharaja, and P. Elango, “Tamil Handwritten Character Recognition: Progress and Challenges” I J C T A, 9(3), 2016, pp. 143-151
work page 2016
-
[10]
Unsupervised Transcription of Historical Documents
T. B. Kirkpatrick, G. Durrett and D. Klein, “Unsupervised Transcription of Historical Documents”, Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, pages 207–217, Sofia, Bulgaria, August 4-9 2013
work page 2013
-
[11]
A Comprehensive Guide to Convolutional Neural Networks- the EL15 way
“A Comprehensive Guide to Convolutional Neural Networks- the EL15 way” [online] Available: https://towardsd atascience.com/a-comprehensive-guide-to-convolutional-neural- networks-the-eli5-way-3bd2b1164a53
-
[12]
“Tesseract OCR” [online] Available: https://opensource. google.com/projects/tesseract
-
[13]
Comparing the OCR Accuracy Levels of Bitonal and Greyscale Images
“Comparing the OCR Accuracy Levels of Bitonal and Greyscale Images” [online] Available: http://www.dlib.org/dli b/march09/powell/03powell.html
-
[14]
“Otsu Thresholding” [online] Available: http://www.labbookpages.co.uk/software/imgProc/otsuThreshold. html
-
[15]
L. Torrey and J. Shavlik, “Transfer Learning”, Appears in the Handbook of Research on Machine Learning Applications, published by IGI Global, edited by E. Soria, J. Martin, R. Magdalena, M. Martinez and A. Serrano, 2009
work page 2009
-
[16]
Keras: The Python Deep Learning library
“Keras: The Python Deep Learning library”, [online] Available: https://keras.io/
-
[17]
An end-to-end open source machine learning plat- form
“An end-to-end open source machine learning plat- form”, [online] Available: https://www.tensorflow.org/
-
[18]
Acceleration and Implementation of JPEG 2000 Encoder on TI DSP platform
L. Chien-Chih, H . Hsueh-Ming, "Acceleration and Implementation of JPEG 2000 Encoder on TI DSP platform" Image Processing, 2007. ICIP 2007. IEEE International Conference on, Vo1. 3, pp. III-329-339, 2005
work page 2000
-
[19]
Convolutional Neural Networks for Visual recognition
“Convolutional Neural Networks for Visual recognition” A Karpathy, [online] Available: http://cs231n.github.io/convolutional-networks/#pool
-
[20]
“Max -pooling/Pooling”, [online] Available: https://computersciencewiki.org/index.php/Maxpooling_/_Poolig
-
[21]
“Euclidean Distance Theory”, [online] Available: https://pythonprogramming.net/euclidean -distance-machine-learnin g-tutorial/
-
[22]
“pytesseract PyPI” [online] Available: https://pypi.org/ project/pytesseract/
-
[23]
“gTTS Documentation”, Pierre -Nick Durette [online] available: https://buildmedia.readthedocs.org/media/pdf/gtts/l atest/gtts.pdf
-
[24]
“Cloud Text to Speech” [online] Available: https://cloud.google.com/text-to-speech/
-
[25]
“Language support” [online] Available: https://cloud.go ogle.com/speech-to-text/docs/languages
-
[26]
S . Dobson, “Image Slicer Documentation” [online] Available: https://buildmedia.readthedocs.org/media/pdf/imag e-slicer/latest/image-slicer.pdf
-
[27]
A Fast and Accurate Dependency Parser using Ne ural Networks
D . Chen and C . D. Manning, “A Fast and Accurate Dependency Parser using Ne ural Networks.” Proceedings of EMNLP 2014. 6 Table 1. Results Obtained Scripture/document/t emple inscription Grayscale Output Binarized Output Digitized text Output in Python shell Case 1: Modern Tamil Case 2: Ancient Tamil Case 3: Ancient Tamil Case 4: Ancient Tamil 7 Inscripti...
work page 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.