Revisiting Action Factorization for Complex Action Spaces
Pith reviewed 2026-06-26 05:42 UTC · model grok-4.3
The pith
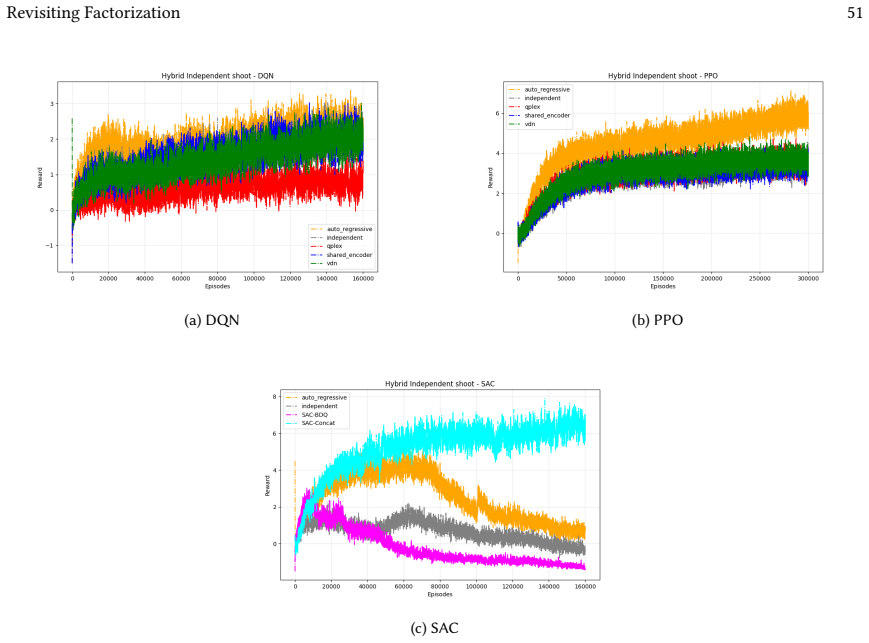
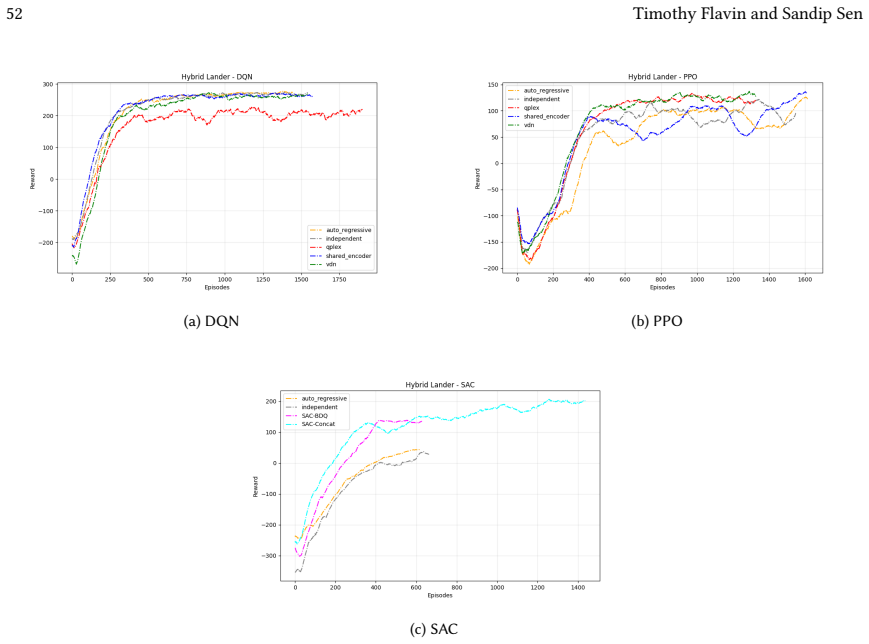
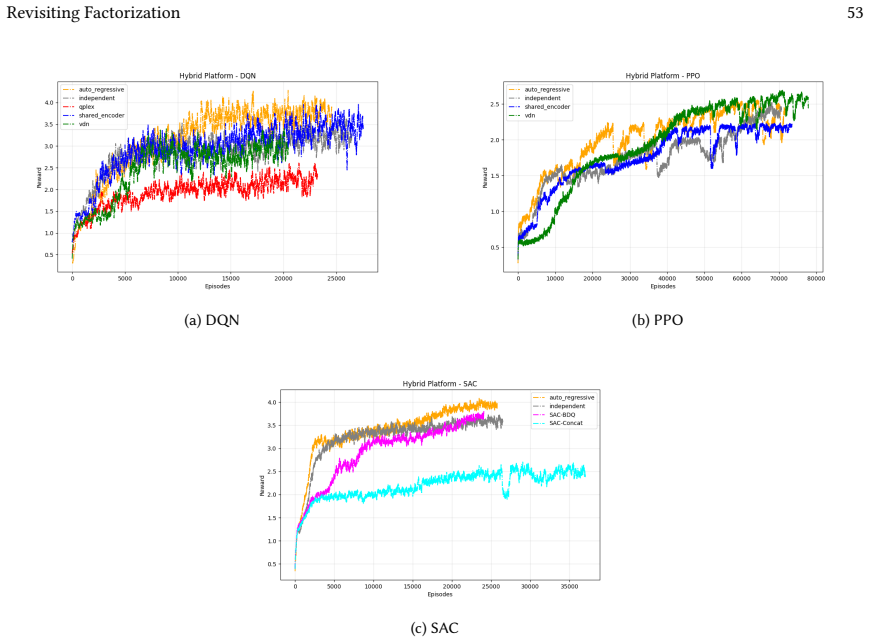
VDN-PPO and PPO-MIX outperform other PPO factorizations in hybrid action spaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
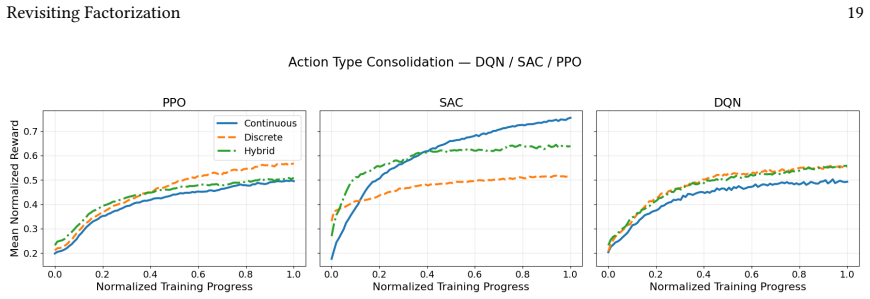
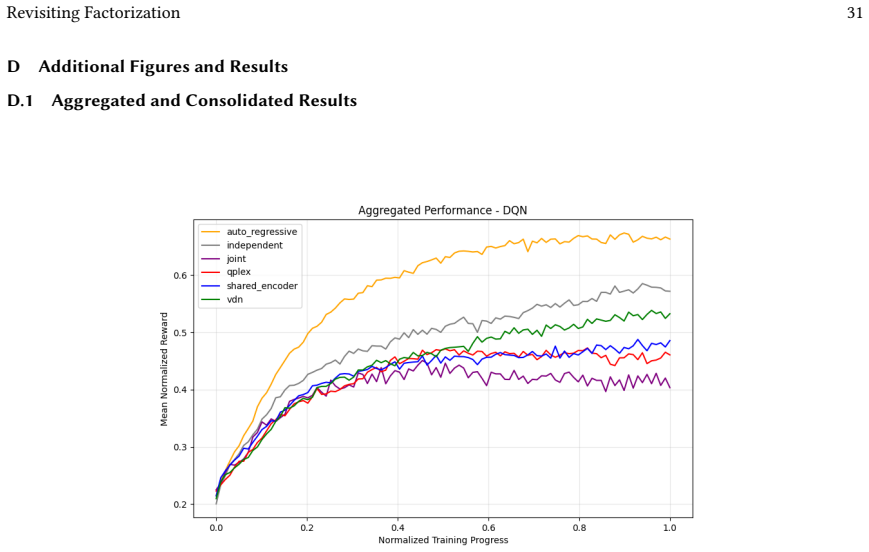
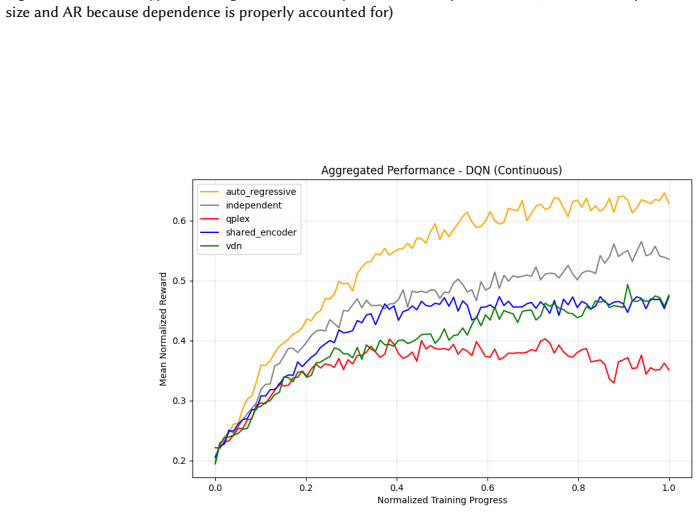
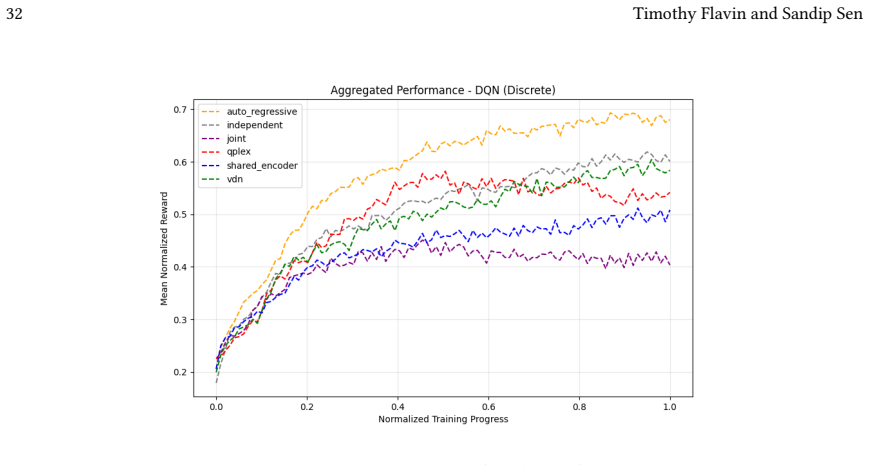
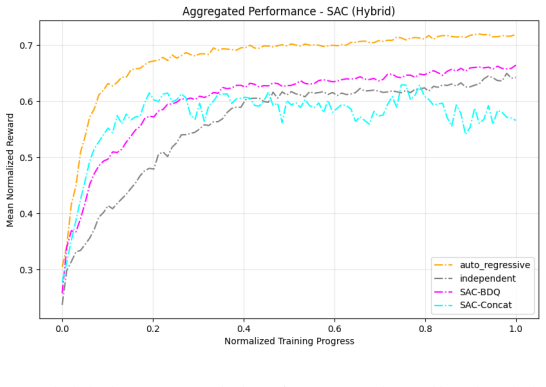
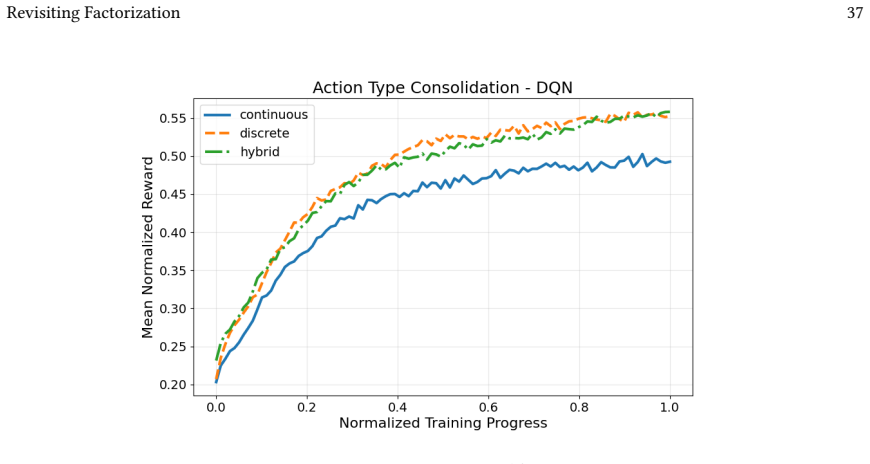
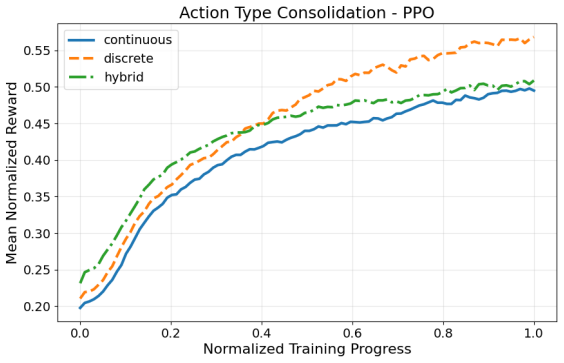
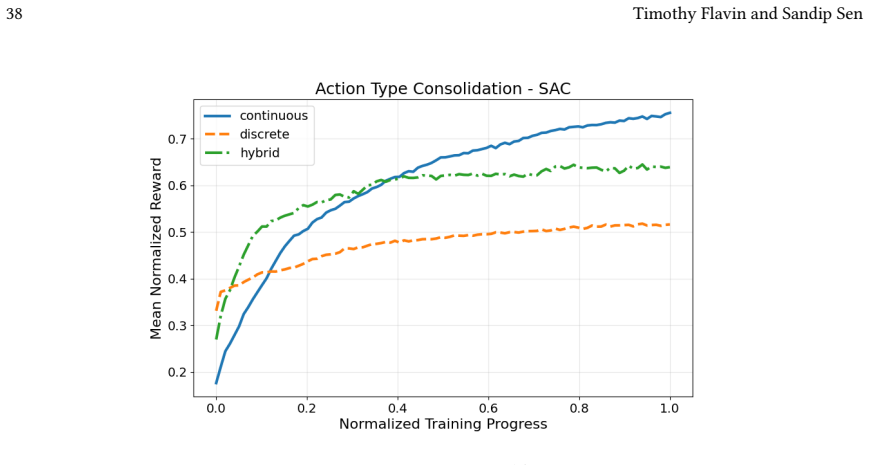
Across 220 valid configurations, VDN-PPO and PPO-MIX surpass all other tested PPO factorizations. Branching dueling architectures deliver the most favorable compute-performance trade-off. Auto-regressive action selection produces the overall best scores. Native continuous SAC beats both discrete and hybrid algorithms, though it requires more computation.
What carries the argument
Branching critic that assigns credit across multiple action heads in VDN-PPO and PPO-MIX, combined with factorization schemes that decompose hybrid discrete-continuous actions.
If this is right
- Branching dueling networks become the default choice when both speed and score matter.
- Auto-regressive factorization should be preferred when maximum performance is the goal and compute is available.
- Continuous SAC is the strongest option for purely continuous control despite its cost.
- New lightweight environments can be used to benchmark future factorization methods before scaling to heavyweight simulators.
- VDN-style credit assignment extends usefully from value-based to policy-gradient methods.
Where Pith is reading between the lines
- Real-world systems such as autonomous driving may gain immediate performance by swapping in the branching PPO variants without changing the underlying simulator.
- The same branching critic idea could be tested inside other on-policy algorithms beyond PPO.
- The observed cost-performance curves suggest a practical decision rule: start with branching dueling, move to auto-regressive only when extra accuracy justifies the added latency.
Load-bearing premise
The four lightweight environments capture the state-dependent inter-action dependence that appears in real hybrid control tasks.
What would settle it
Re-running the identical 220 configurations on a heavier benchmark such as CARLA or a larger multi-agent task and obtaining reversed performance orderings among the factorization methods would falsify the ranking.
Figures

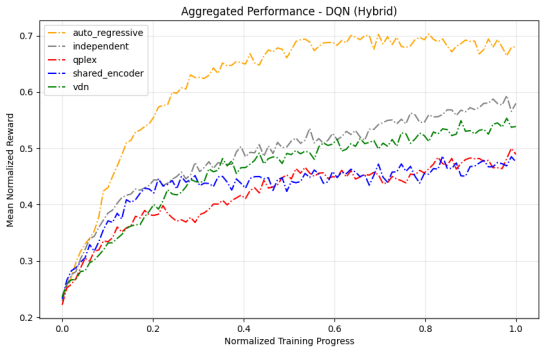
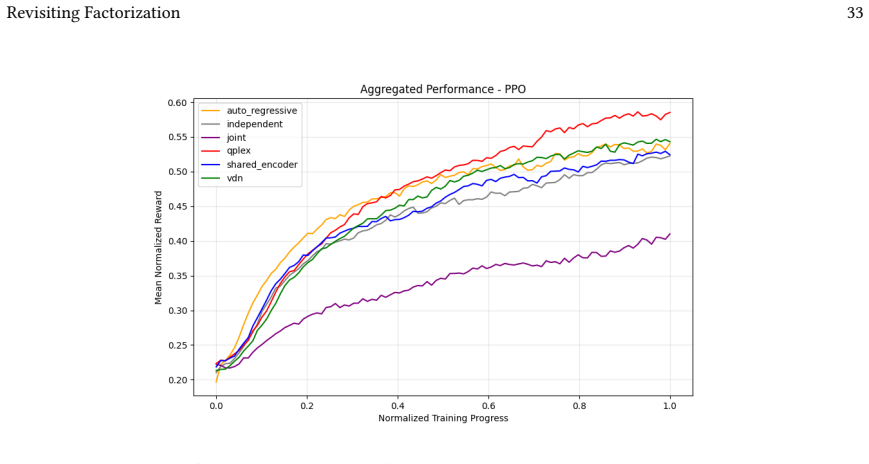
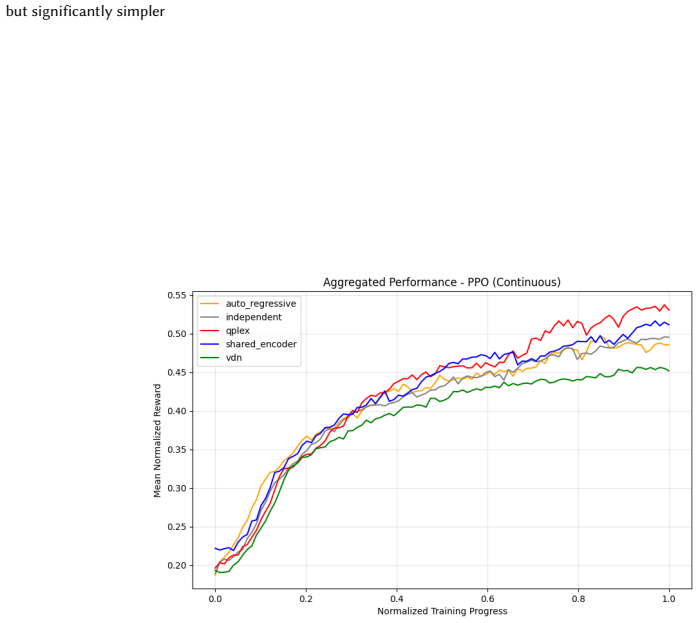
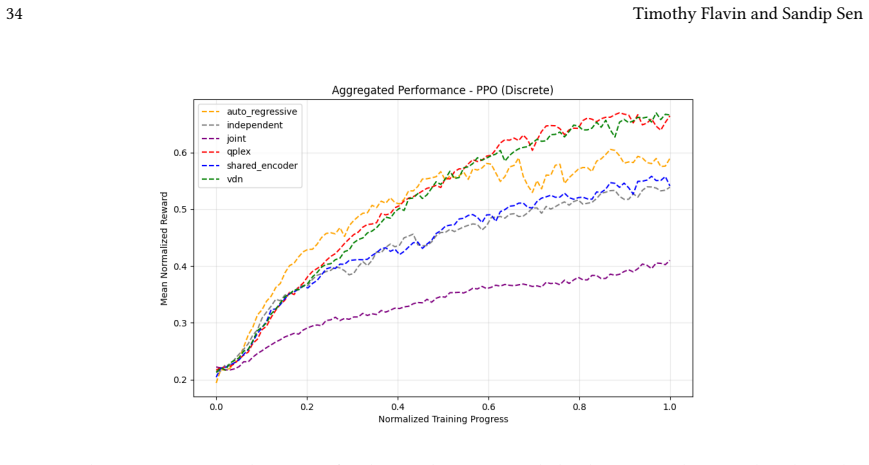
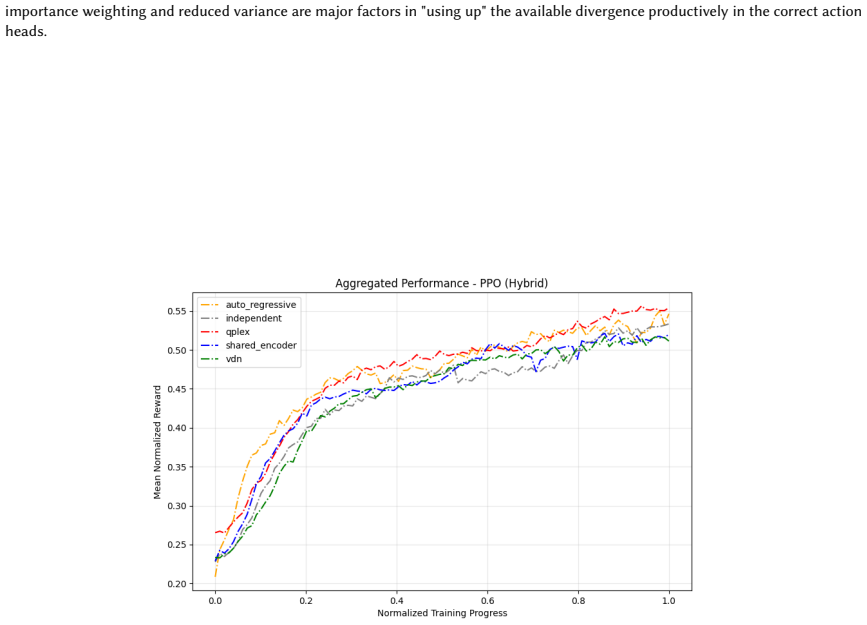
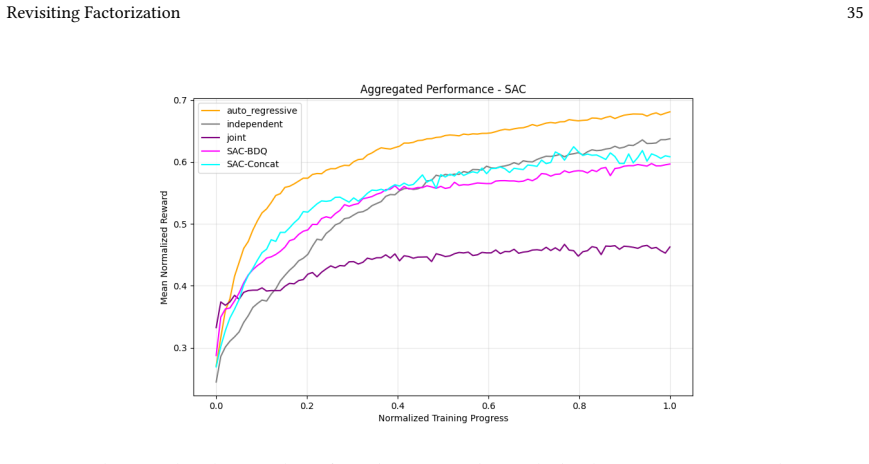
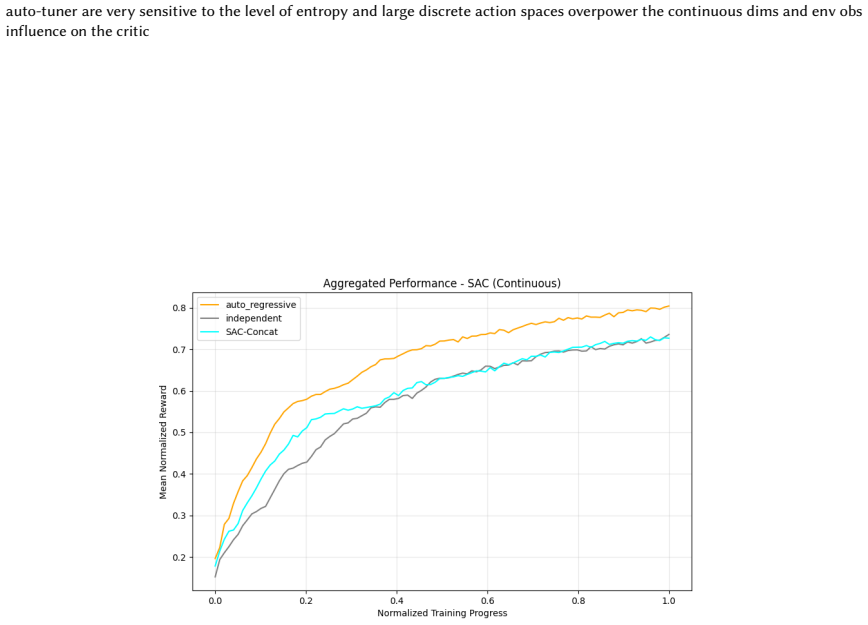
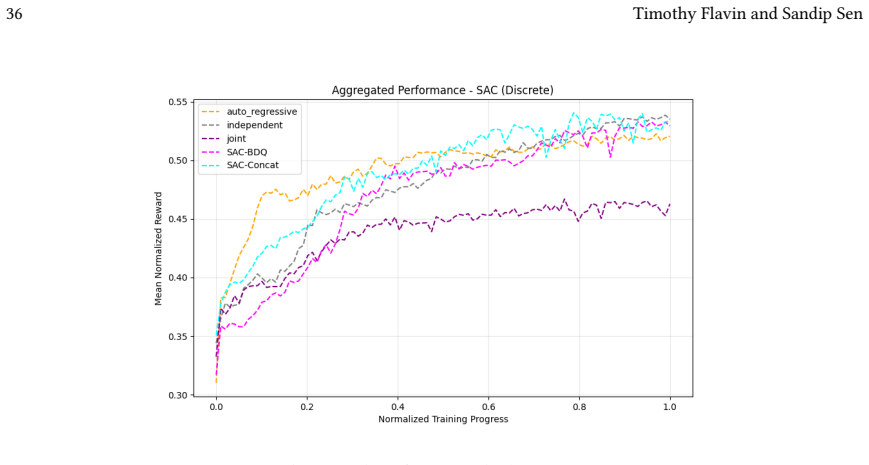
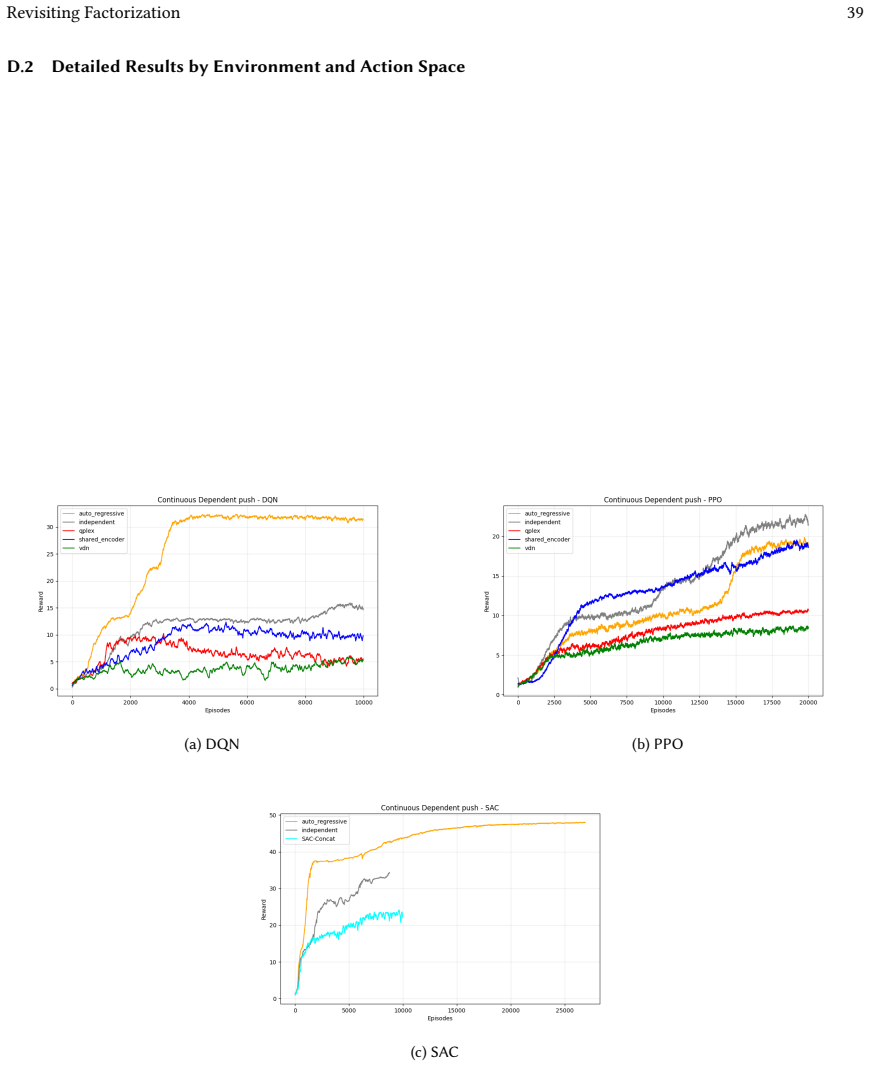
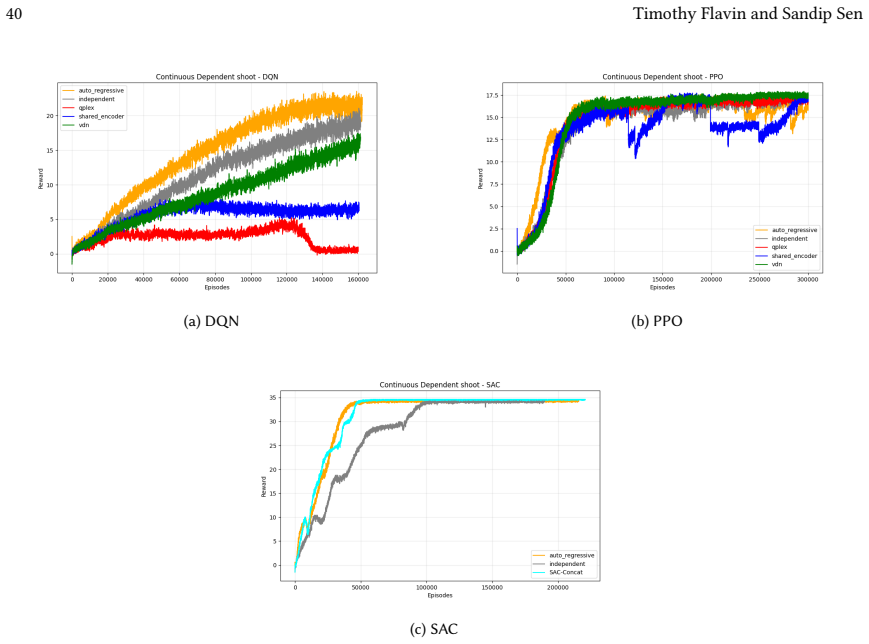
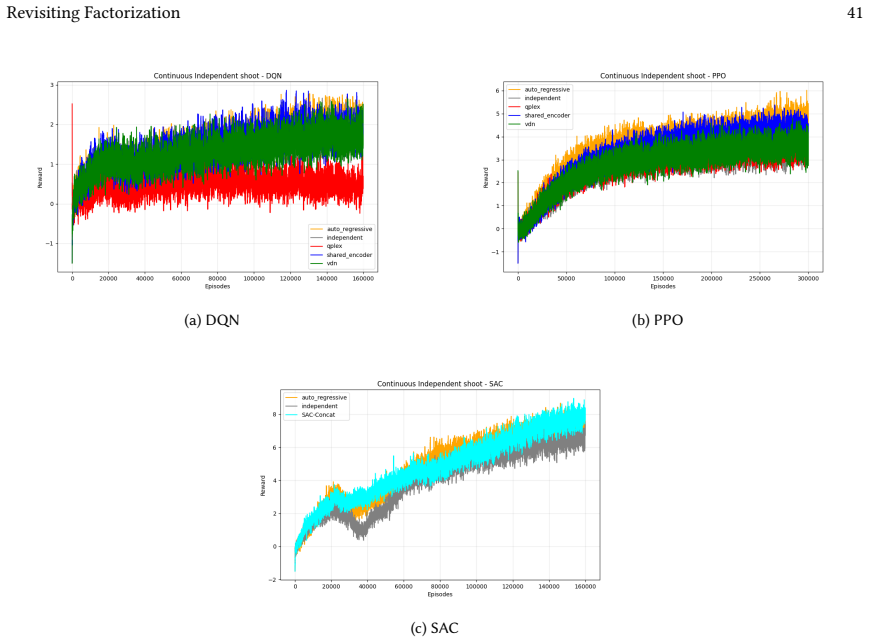
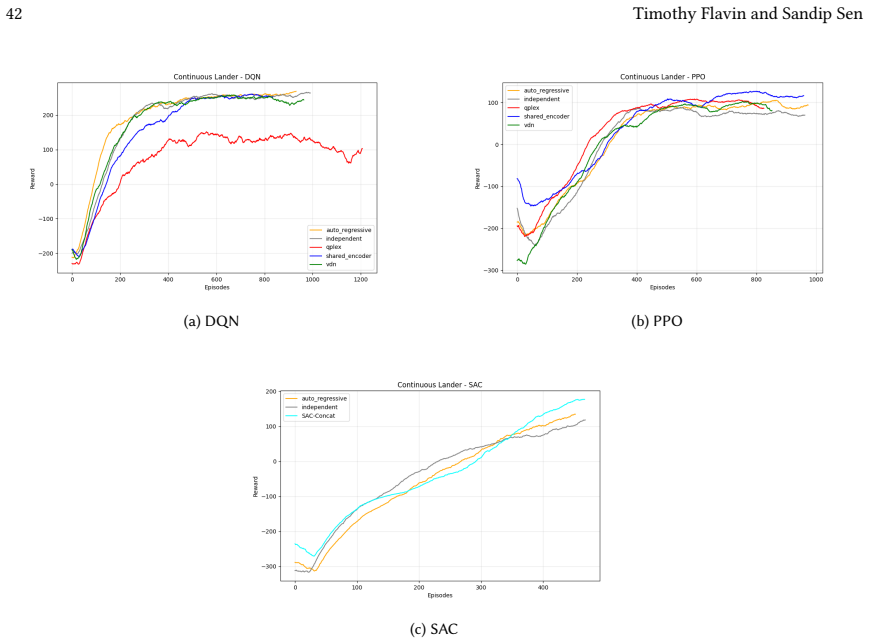
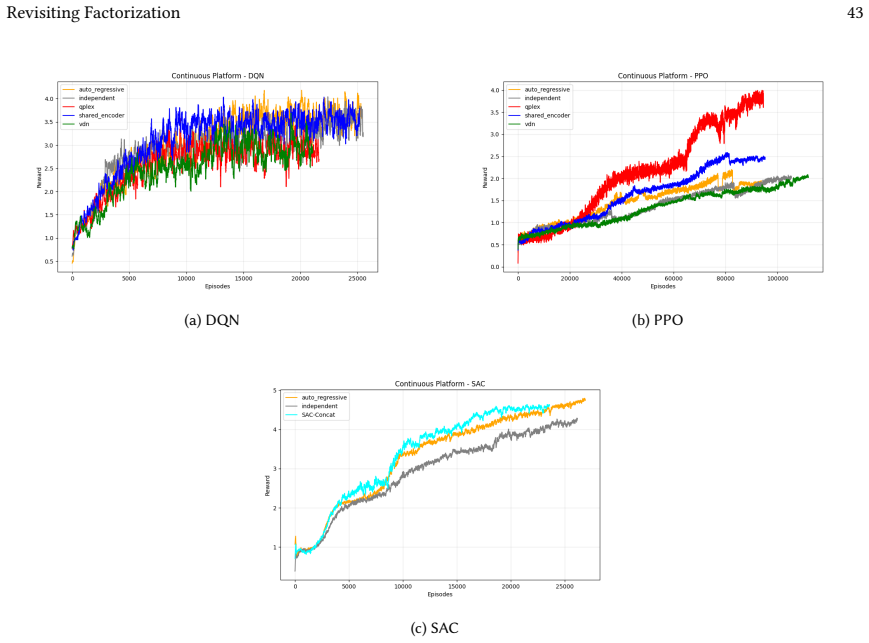
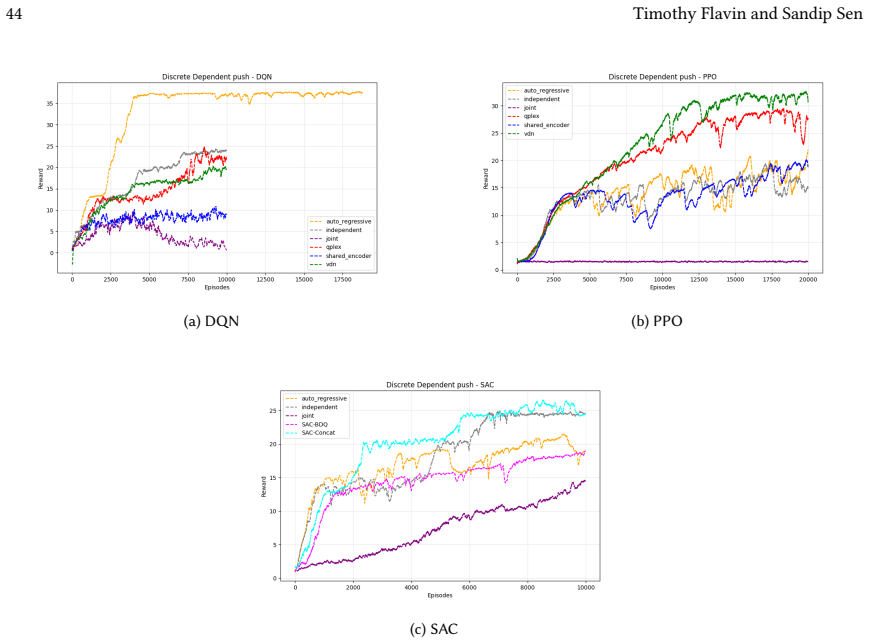
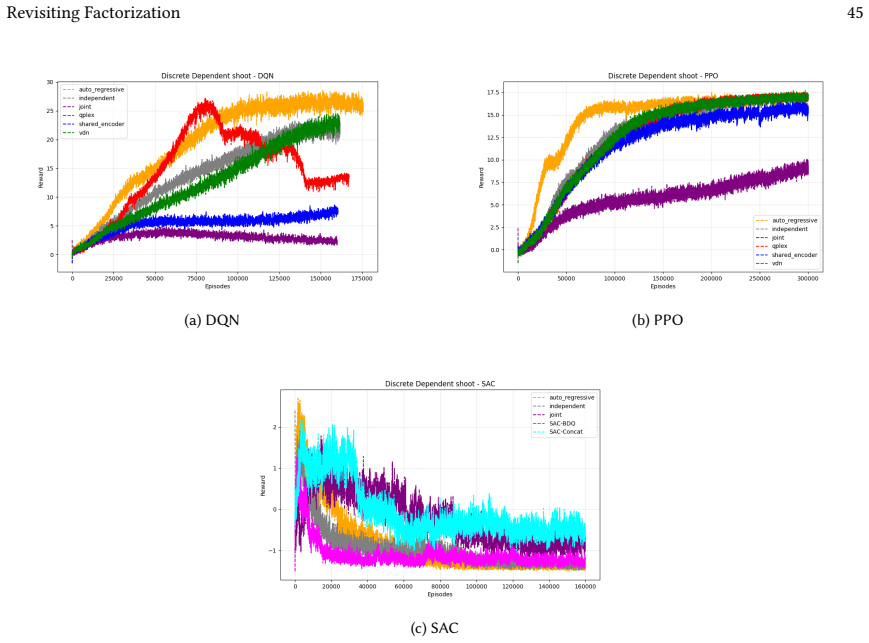
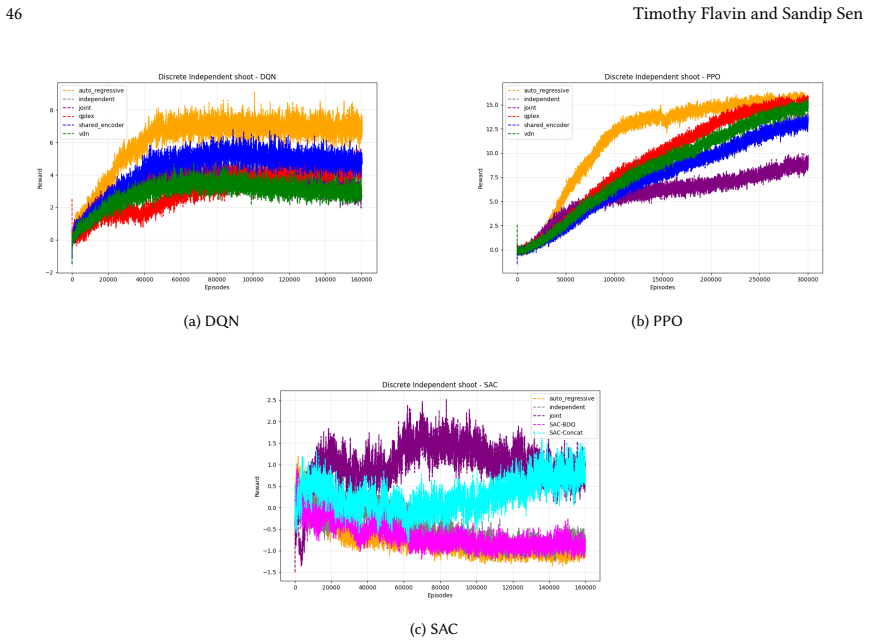
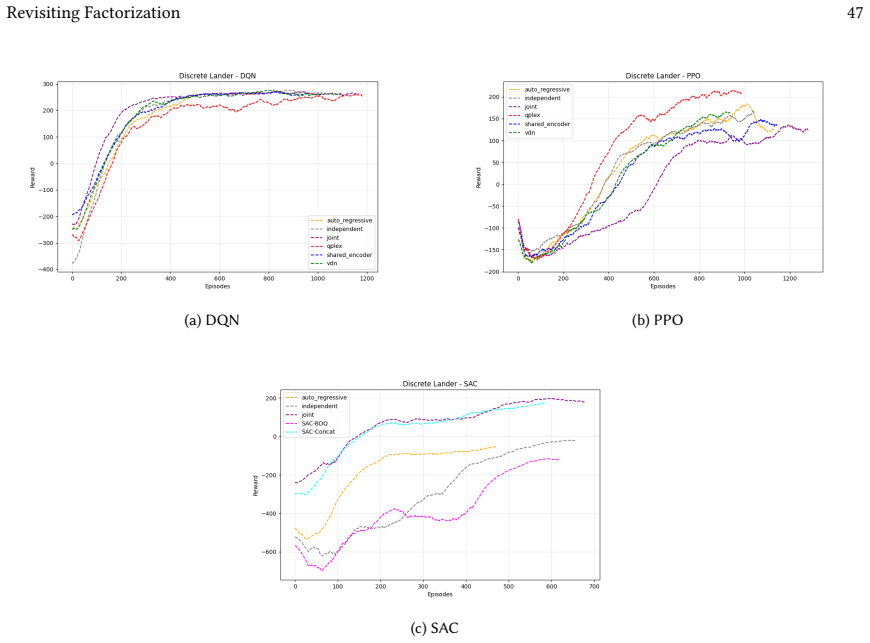
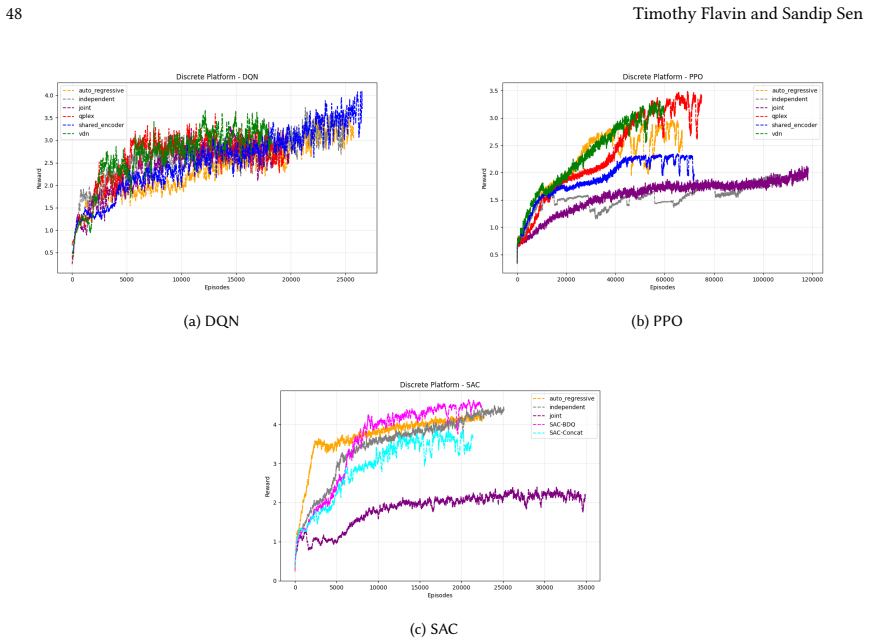
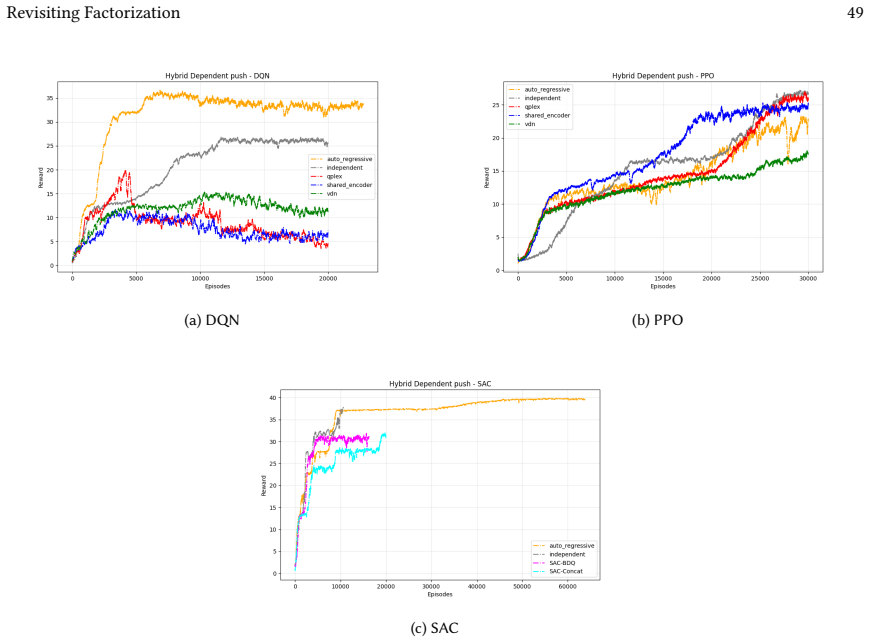
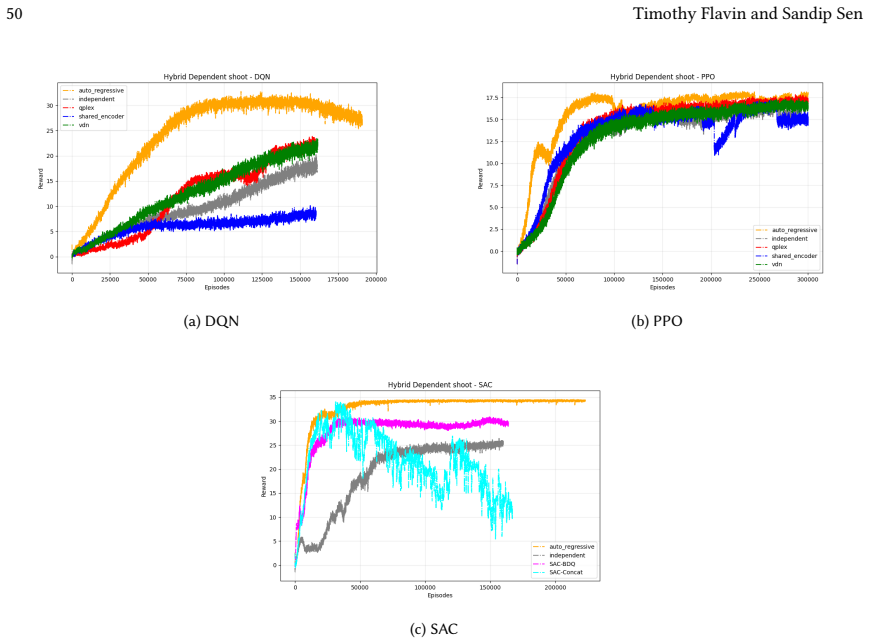
read the original abstract
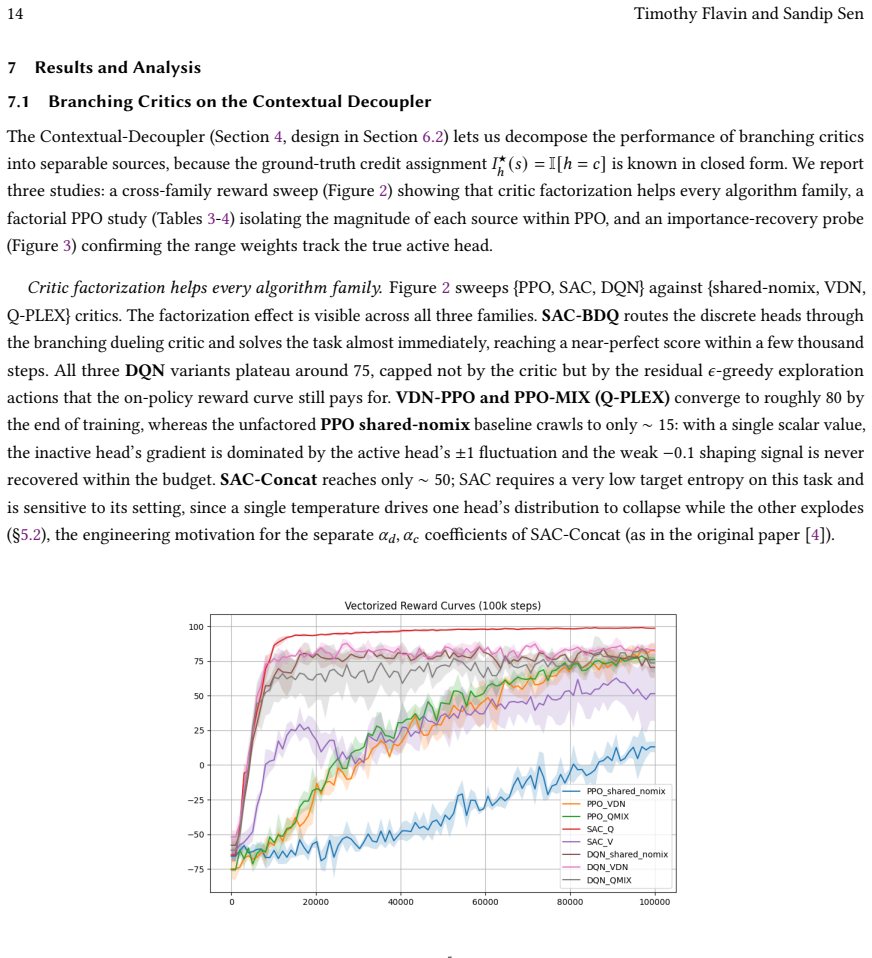
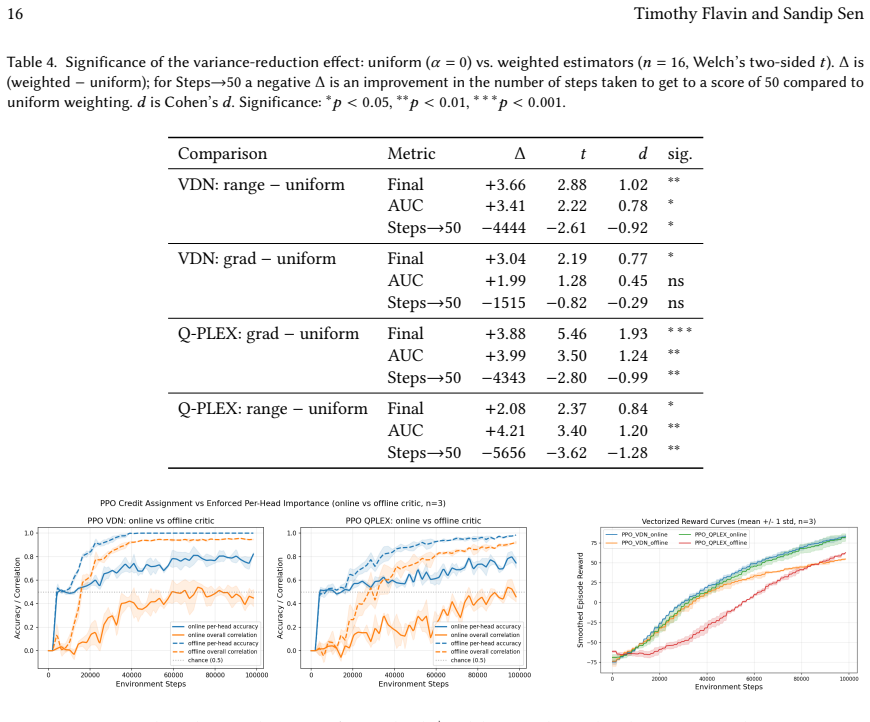
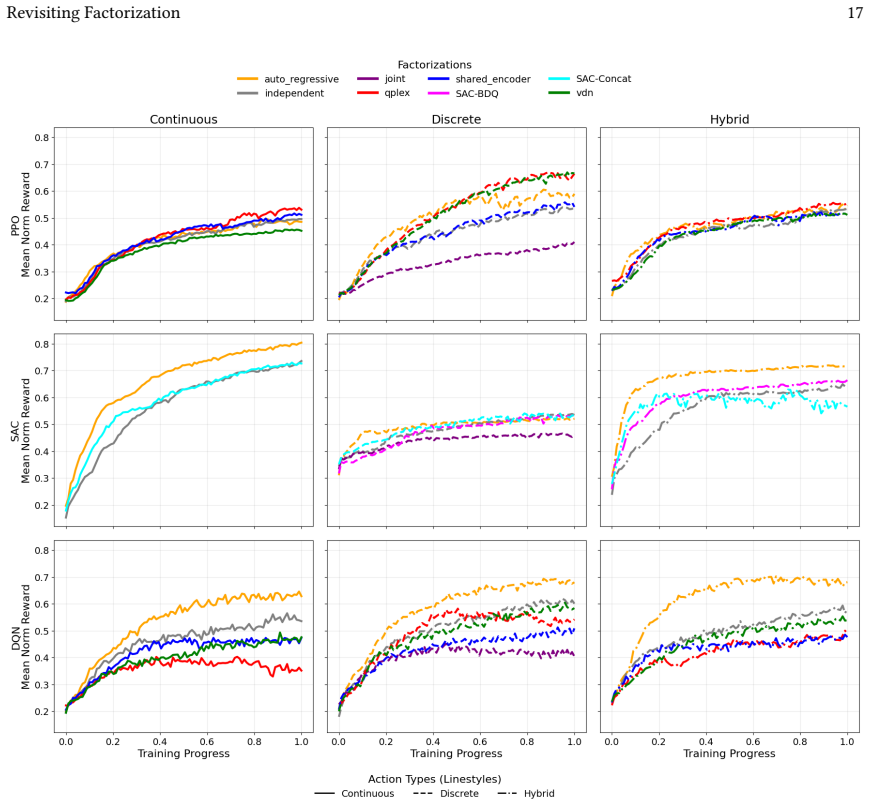
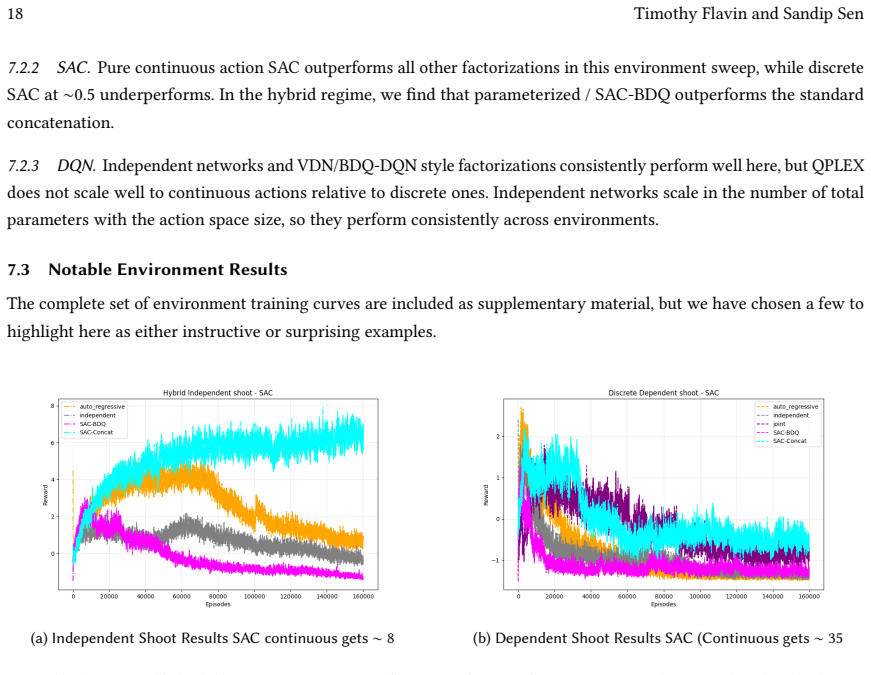
Many real-world control problems involve hybrid discrete-continuous action spaces. For example, steering and signaling in autonomous driving, and aiming and firing in robotics or video-games. Despite real-world hybrid factorization and reinforcement learning framework support for complex action spaces (e.g., Gymnasium, PettingZoo, TorchRL, SeedRL, Mujoco, etc), the default environments within those frameworks often implement uniform action space configurations (LunarLander, Walker2D, Cheetah, SMAC, SUMO, Ant, Atari). Landmark hybrid-action benchmarks (RoboCup 2D HFO, SC2LE, Platform, CARLA, etc) are mostly heavyweight or archival implementations originating from papers which test one or a small number of competing factorization methods on one kind of control. This article provides a cross-sectional study of factorization methods [independent networks, shared encoder, VDN, QPLEX, Joint, Auto-Regressive] on each of three families of algorithms [PPO, SAC, DQN] across three action spaces [discretized, hybrid, continuous] over four lightweight environments [Platform, hybrid-LunarLander, Hybrid-Shoot, CoopPush]. Accounting for some invalid pairings such as joint-continuous, we are left with 220 configurations to analyze each method. We provide two new C++ parallel gymnasium and petting-zoo compliant environments [CoopPush, Hybrid-Shoot] to isolate particular challenges such as state-dependent inter-action dependence. Finally, we introduce VDN-PPO and PPO-MIX which use a branching critic to assign credit to multi-headed PPO. These variants out-perform all other tested PPO factorizations. Our results suggest that branching dueling architectures balance compute and performance most effectively, with Auto-Regressive actions reaching the highest performance overall and native continuous SAC outperforming discrete and hybrid algorithms, albiet both at increased computational cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a cross-sectional empirical study of action factorization methods (independent networks, shared encoder, VDN, QPLEX, Joint, Auto-Regressive) applied to PPO, SAC, and DQN across discretized, hybrid, and continuous action spaces in four lightweight environments (Platform, hybrid-LunarLander, Hybrid-Shoot, CoopPush). It introduces two new Gymnasium/PettingZoo-compliant environments (CoopPush, Hybrid-Shoot) and proposes VDN-PPO and PPO-MIX (branching-critic variants of PPO), claiming these outperform other tested PPO factorizations. Results indicate branching dueling architectures balance compute/performance, Auto-Regressive reaches highest performance overall, and native continuous SAC outperforms discrete/hybrid variants (at higher cost), based on 220 configurations.
Significance. If the empirical claims hold after addressing verification gaps, the work offers a useful broad benchmark for hybrid action spaces, new environments targeting state-dependent inter-action dependence, and the VDN-PPO/PPO-MIX variants as practical contributions. The scale of 220 configurations and explicit comparison across algorithm families provides practitioners with trade-off insights not available in single-method papers.
major comments (2)
- [Abstract] Abstract: The central performance claims (VDN-PPO and PPO-MIX outperforming other PPO factorizations; Auto-Regressive highest overall; native continuous SAC outperforming) are presented without any reference to statistical tests, error bars, number of random seeds, or hyperparameter search details. This directly affects verifiability of the outperformance assertions that form the paper's headline results.
- [Abstract] Abstract: The new environments are introduced 'to isolate particular challenges such as state-dependent inter-action dependence,' yet the text supplies no mechanism, state-feature definition, or example demonstrating how the coupling between discrete and continuous actions is made conditional on state (as opposed to fixed or state-independent hybrids like standard LunarLander). This is load-bearing for the claim that the 220 configurations test the motivating regime rather than uniform benchmarks.
minor comments (1)
- [Abstract] Abstract contains a typo: 'albiet' should be 'albeit'.
Simulated Author's Rebuttal
We thank the referee for these constructive comments on the abstract. We address each point below and will make revisions to improve verifiability and clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claims (VDN-PPO and PPO-MIX outperforming other PPO factorizations; Auto-Regressive highest overall; native continuous SAC outperforming) are presented without any reference to statistical tests, error bars, number of random seeds, or hyperparameter search details. This directly affects verifiability of the outperformance assertions that form the paper's headline results.
Authors: We agree the abstract should reference these details for self-containment. The experiments use 5 random seeds per configuration with standard deviation error bars in all plots and tables; hyperparameter grids are documented in the appendix. We will revise the abstract to note the seed count, error bars, and that significance testing (paired t-tests) supports the reported outperformance where claimed. revision: yes
-
Referee: [Abstract] Abstract: The new environments are introduced 'to isolate particular challenges such as state-dependent inter-action dependence,' yet the text supplies no mechanism, state-feature definition, or example demonstrating how the coupling between discrete and continuous actions is made conditional on state (as opposed to fixed or state-independent hybrids like standard LunarLander). This is load-bearing for the claim that the 220 configurations test the motivating regime rather than uniform benchmarks.
Authors: The environments were constructed with explicit state-dependent mechanisms (e.g., in CoopPush the continuous push force modulates the discrete grasp/release decision via a state feature combining relative position and velocity thresholds; Hybrid-Shoot conditions the discrete fire action on continuous aim angle and a state-derived target proximity scalar). We will add a dedicated subsection with formal definitions, pseudocode for the coupling, and concrete state examples to the revised manuscript. revision: yes
Circularity Check
No circularity: purely empirical comparison with direct measurements
full rationale
The paper conducts a cross-sectional empirical study of factorization methods across algorithms and action spaces on four environments, reporting performance as direct experimental outcomes. No derivations, fitted parameters renamed as predictions, or self-referential equations are present. New environments (CoopPush, Hybrid-Shoot) and variants (VDN-PPO, PPO-MIX) are introduced and evaluated via measurements, not defined in terms of the results themselves. Self-citations, if any, are not load-bearing for central claims. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gustavo Campos, Nael H El-Farra, and Ahmet Palazoglu. 2022. Soft actor-critic deep reinforcement learning with hybrid mixed-integer actions for demand responsive scheduling of energy systems.Industrial & Engineering Chemistry Research61, 24 (2022), 8443–8461
2022
-
[2]
Yash Chandak, Georgios Theocharous, James Kostas, Scott Jordan, and Philip Thomas. 2019. Learning action representations for reinforcement learning. InInternational conference on machine learning. PMLR, 941–950
2019
-
[3]
Shaotao Chen, Xihe Qiu, Xiaoyu Tan, Zhijun Fang, and Yaochu Jin. 2022. A model-based hybrid soft actor-critic deep reinforcement learning algorithm for optimal ventilator settings.Information sciences611 (2022), 47–64
2022
-
[4]
Olivier Delalleau, Maxim Peter, Eloi Alonso, and Adrien Logut. 2019. Discrete and continuous action representation for practical rl in video games. arXiv preprint arXiv:1912.11077(2019)
arXiv 2019
-
[5]
Yan Duan, Xi Chen, Rein Houthooft, John Schulman, and Pieter Abbeel. 2016. Benchmarking deep reinforcement learning for continuous control. In International conference on machine learning. PMLR, 1329–1338
2016
-
[6]
Benjamin Ellis, Jonathan Cook, Skander Moalla, Mikayel Samvelyan, Mingfei Sun, Anuj Mahajan, Jakob Foerster, and Shimon Whiteson. 2023. Smacv2: An improved benchmark for cooperative multi-agent reinforcement learning.Advances in Neural Information Processing Systems36 (2023), 37567–37593
2023
-
[7]
Lasse Espeholt, Hubert Soyer, Remi Munos, Karen Simonyan, Vlad Mnih, Tom Ward, Yotam Doron, Vlad Firoiu, Tim Harley, Iain Dunning, et al
-
[8]
InInternational conference on machine learning
Impala: Scalable distributed deep-rl with importance weighted actor-learner architectures. InInternational conference on machine learning. PMLR, 1407–1416
-
[9]
Zhou Fan, Rui Su, Weinan Zhang, and Yong Yu. 2019. Hybrid actor-critic reinforcement learning in parameterized action space.arXiv preprint arXiv:1903.01344(2019)
Pith/arXiv arXiv 2019
-
[10]
Jakob Foerster, Gregory Farquhar, Triantafyllos Afouras, Nantas Nardelli, and Shimon Whiteson. 2018. Counterfactual multi-agent policy gradients. InProceedings of the AAAI conference on artificial intelligence, Vol. 32
2018
-
[11]
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. 2018. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. InInternational conference on machine learning. Pmlr, 1861–1870
2018
-
[12]
Pablo Hernandez-Leal, Bilal Kartal, and Matthew E Taylor. 2019. A survey and critique of multiagent deep reinforcement learning.Autonomous Agents and Multi-Agent Systems33, 6 (2019), 750–797
2019
-
[13]
Eric Jang, Shixiang Gu, and Ben Poole. 2016. Categorical reparameterization with gumbel-softmax.arXiv preprint arXiv:1611.01144(2016)
Pith/arXiv arXiv 2016
-
[14]
Dmytro Korenkevych, A Rupam Mahmood, Gautham Vasan, and James Bergstra. 2019. Autoregressive policies for continuous control deep reinforcement learning.arXiv preprint arXiv:1903.11524(2019)
Pith/arXiv arXiv 2019
-
[15]
Boyan Li, Hongyao Tang, Yan Zheng, Jianye Hao, Pengyi Li, Zhen Wang, Zhaopeng Meng, and Li Wang. 2021. Hyar: Addressing discrete-continuous action reinforcement learning via hybrid action representation.arXiv preprint arXiv:2109.05490(2021)
arXiv 2021
-
[16]
Chuming Li, Jie Liu, Yinmin Zhang, Yuhong Wei, Yazhe Niu, Yaodong Yang, Yu Liu, and Wanli Ouyang. 2023. Ace: Cooperative multi-agent q-learning with bidirectional action-dependency. InProceedings of the AAAI conference on artificial intelligence, Vol. 37. 8536–8544
2023
-
[17]
Zechu Li, Tao Chen, Zhang-Wei Hong, Anurag Ajay, and Pulkit Agrawal. 2023. Parallel𝑄-Learning: Scaling Off-policy Reinforcement Learning under Massively Parallel Simulation. InInternational Conference on Machine Learning. PMLR, 19440–19459
2023
-
[18]
Timothy P Lillicrap, Jonathan J Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. 2015. Continuous control with deep reinforcement learning.arXiv preprint arXiv:1509.02971(2015)
Pith/arXiv arXiv 2015
-
[19]
Zemin Eitan Liu, Yanfei Li, Quan Zhou, Yong Li, Bin Shuai, Hongming Xu, Min Hua, Guikun Tan, and Lubing Xu. 2024. Deep Reinforcement Learning- Based Energy Management for Heavy Duty HEV Considering Discrete-Continuous Hybrid Action Space.IEEE Transactions on Transportation Electrification10, 4 (2024), 9864–9876. doi:10.1109/TTE.2024.3363650
-
[20]
Ryan Lowe, Yi I Wu, Aviv Tamar, Jean Harb, OpenAI Pieter Abbeel, and Igor Mordatch. 2017. Multi-agent actor-critic for mixed cooperative- competitive environments.Advances in neural information processing systems30 (2017)
2017
-
[21]
Warwick Masson, Pravesh Ranchod, and George Konidaris. 2016. Reinforcement learning with parameterized actions. InProceedings of the AAAI conference on artificial intelligence, Vol. 30
2016
-
[22]
Laetitia Matignon, Guillaume J Laurent, and Nadine Le Fort-Piat. 2012. Independent reinforcement learners in cooperative markov games: a survey regarding coordination problems.The Knowledge Engineering Review27, 1 (2012), 1–31. Manuscript submitted to ACM 22 Timothy Flavin and Sandip Sen
2012
-
[23]
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. 2013. Playing atari with deep reinforcement learning.arXiv preprint arXiv:1312.5602(2013)
Pith/arXiv arXiv 2013
-
[24]
Bei Peng, Tabish Rashid, Christian Schroeder de Witt, Pierre-Alexandre Kamienny, Philip Torr, Wendelin Böhmer, and Shimon Whiteson. 2021. Facmac: Factored multi-agent centralised policy gradients.Advances in neural information processing systems34 (2021), 12208–12221
2021
-
[25]
Tabish Rashid, Mikayel Samvelyan, Christian Schroeder De Witt, Gregory Farquhar, Jakob Foerster, and Shimon Whiteson. 2020. Monotonic value function factorisation for deep multi-agent reinforcement learning.Journal of Machine Learning Research21, 178 (2020), 1–51
2020
-
[26]
Danilo Rezende and Shakir Mohamed. 2015. Variational inference with normalizing flows. InInternational conference on machine learning. PMLR, 1530–1538
2015
-
[27]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347(2017)
Pith/arXiv arXiv 2017
-
[28]
Tim Seyde, Igor Gilitschenski, Wilko Schwarting, Bartolomeo Stellato, Martin Riedmiller, Markus Wulfmeier, and Daniela Rus. 2021. Is bang-bang control all you need? solving continuous control with bernoulli policies.Advances in Neural Information Processing Systems34 (2021), 27209–27221
2021
-
[29]
Satinder P Singh and Richard S Sutton. 1996. Reinforcement learning with replacing eligibility traces.Machine learning22, 1 (1996), 123–158
1996
-
[30]
Kyunghwan Son, Daewoo Kim, Wan Ju Kang, David Earl Hostallero, and Yung Yi. 2019. Qtran: Learning to factorize with transformation for cooperative multi-agent reinforcement learning. InInternational conference on machine learning. PMLR, 5887–5896
2019
-
[31]
Peter Sunehag, Guy Lever, Audrunas Gruslys, Wojciech Marian Czarnecki, Vinicius Zambaldi, Max Jaderberg, Marc Lanctot, Nicolas Sonnerat, Joel Z Leibo, Karl Tuyls, et al. 2017. Value-decomposition networks for cooperative multi-agent learning.arXiv preprint arXiv:1706.05296(2017)
Pith/arXiv arXiv 2017
-
[32]
Richard S Sutton, David McAllester, Satinder Singh, and Yishay Mansour. 1999. Policy gradient methods for reinforcement learning with function approximation.Advances in neural information processing systems12 (1999)
1999
-
[33]
Ming Tan. 1993. Multi-agent reinforcement learning: Independent vs. cooperative agents. InProceedings of the tenth international conference on machine learning. 330–337
1993
-
[34]
Yuval Tassa, Yotam Doron, Alistair Muldal, Tom Erez, Yazhe Li, Diego de Las Casas, David Budden, Abbas Abdolmaleki, Josh Merel, Andrew Lefrancq, et al. 2018. Deepmind control suite.arXiv preprint arXiv:1801.00690(2018)
Pith/arXiv arXiv 2018
-
[35]
Arash Tavakoli, Fabio Pardo, and Petar Kormushev. 2018. Action branching architectures for deep reinforcement learning. InProceedings of the aaai conference on artificial intelligence, Vol. 32
2018
-
[36]
J Terry, Benjamin Black, Nathaniel Grammel, Mario Jayakumar, Ananth Hari, Ryan Sullivan, Luis S Santos, Clemens Dieffendahl, Caroline Horsch, Rodrigo Perez-Vicente, et al. 2021. Pettingzoo: Gym for multi-agent reinforcement learning.Advances in Neural Information Processing Systems34 (2021), 15032–15043
2021
-
[37]
Emanuel Todorov, Tom Erez, and Yuval Tassa. 2012. Mujoco: A physics engine for model-based control. In2012 IEEE/RSJ international conference on intelligent robots and systems. IEEE, 5026–5033
2012
-
[38]
Mark Towers, Ariel Kwiatkowski, Jordan Terry, John U Balis, Gianluca De Cola, Tristan Deleu, Manuel Goulão, Andreas Kallinteris, Markus Krimmel, Arjun KG, et al. 2024. Gymnasium: A Standard Interface for Reinforcement Learning Environments.arXiv preprint arXiv:2407.17032(2024)
Pith/arXiv arXiv 2024
-
[39]
Nino Vieillard, Olivier Pietquin, and Matthieu Geist. 2020. Munchausen reinforcement learning.Advances in Neural Information Processing Systems 33 (2020), 4235–4246
2020
-
[40]
Oriol Vinyals, Igor Babuschkin, Wojciech M Czarnecki, Michaël Mathieu, Andrew Dudzik, Junyoung Chung, David H Choi, Richard Powell, Timo Ewalds, Petko Georgiev, et al. 2019. Grandmaster level in StarCraft II using multi-agent reinforcement learning.nature575, 7782 (2019), 350–354
2019
-
[41]
Jianhao Wang, Zhizhou Ren, Terry Liu, Yang Yu, and Chongjie Zhang. 2020. Qplex: Duplex dueling multi-agent q-learning.arXiv preprint arXiv:2008.01062(2020)
arXiv 2020
-
[42]
Ze Wang, Ni Li, and Guanghong Gong. 2025. VDMPO: Policy optimization for cooperative multi-agent reinforcement learning based on joint value decomposition.Neurocomputing(2025), 131193
2025
-
[43]
Ziyu Wang, Tom Schaul, Matteo Hessel, Hado Hasselt, Marc Lanctot, and Nando Freitas. 2016. Dueling network architectures for deep reinforcement learning. InInternational conference on machine learning. PMLR, 1995–2003
2016
-
[44]
Jiayi Weng, Min Lin, Shengyi Huang, Bo Liu, Denys Makoviichuk, Viktor Makoviychuk, Zichen Liu, Yufan Song, Ting Luo, Yukun Jiang, et al. 2022. Envpool: A highly parallel reinforcement learning environment execution engine.Advances in Neural Information Processing Systems35 (2022), 22409–22421
2022
-
[45]
Jiechao Xiong, Qing Wang, Zhuoran Yang, Peng Sun, Lei Han, Yang Zheng, Haobo Fu, Tong Zhang, Ji Liu, and Han Liu. 2018. Parametrized deep q-networks learning: Reinforcement learning with discrete-continuous hybrid action space.arXiv preprint arXiv:1810.06394(2018)
Pith/arXiv arXiv 2018
-
[46]
Weirui Ye, Shaohuai Liu, Thanard Kurutach, Pieter Abbeel, and Yang Gao. 2021. Mastering atari games with limited data.Advances in neural information processing systems34 (2021), 25476–25488
2021
-
[47]
inflating
Chao Yu, Akash Velu, Eugene Vinitsky, Jiaxuan Gao, Yu Wang, Alexandre Bayen, and Yi Wu. 2022. The surprising effectiveness of ppo in cooperative multi-agent games.Advances in neural information processing systems35 (2022), 24611–24624. Manuscript submitted to ACM Revisiting Factorization 23 A Theoretical Analysis of Importance-Weighted GAE for Multi-Head ...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.