Bayesian Model Averaging under Predictor Redundancy via Density-Ratio Posterior Compression
Pith reviewed 2026-06-26 13:11 UTC · model grok-4.3
The pith
Bayesian posteriors over redundant predictor supports can be summarized by regions with explicit density-ratio distortion bounds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
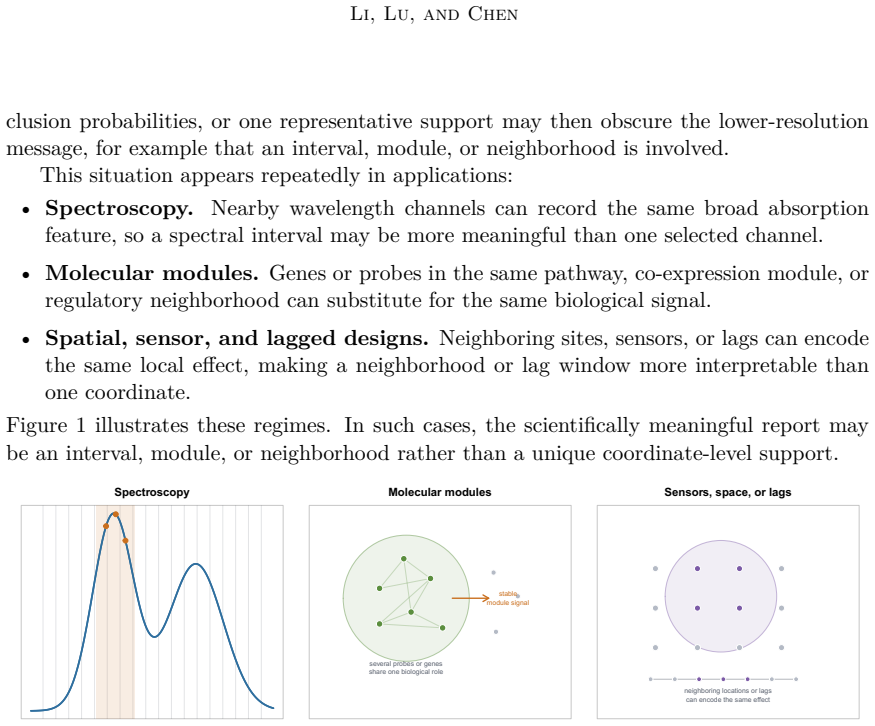
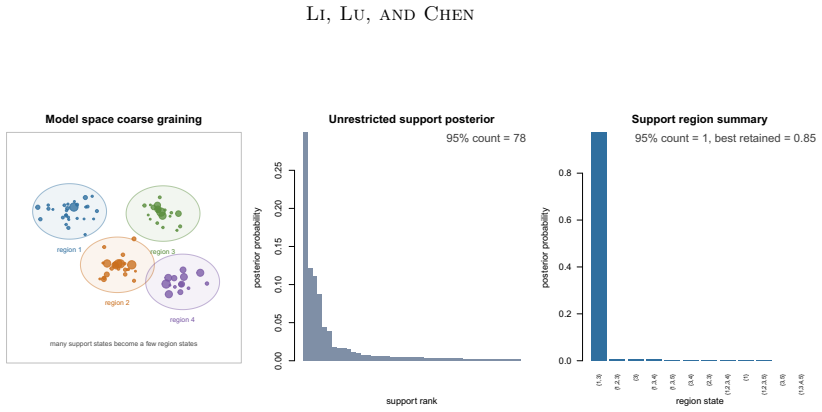
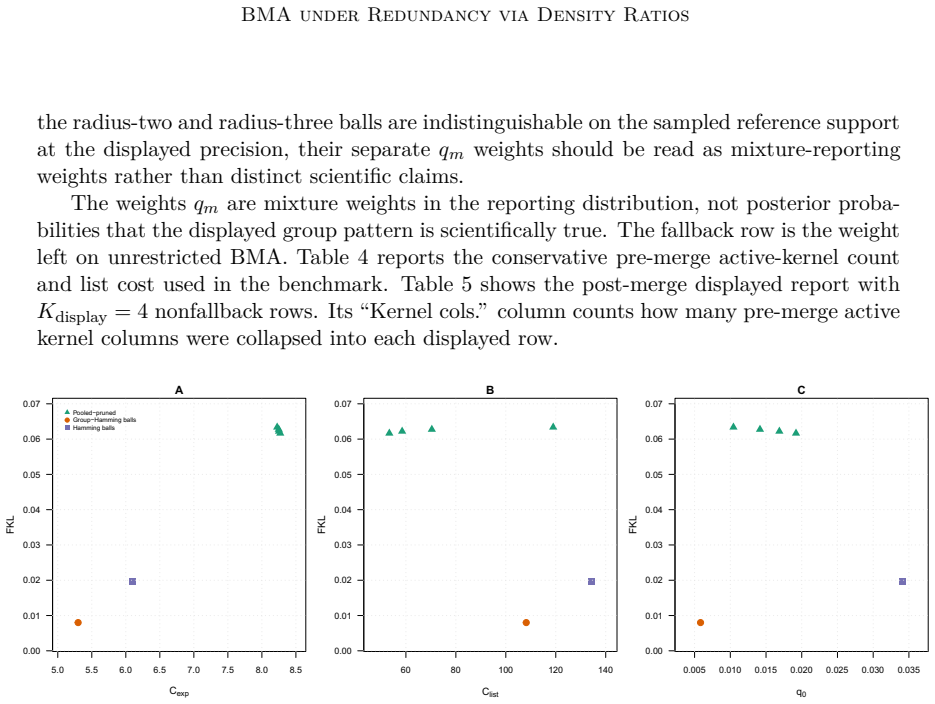
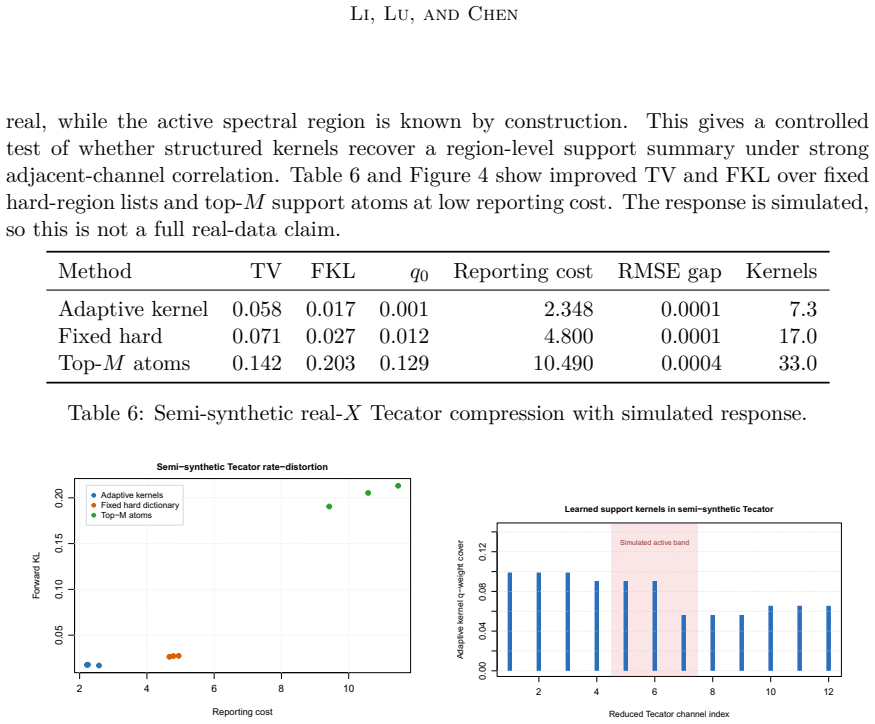
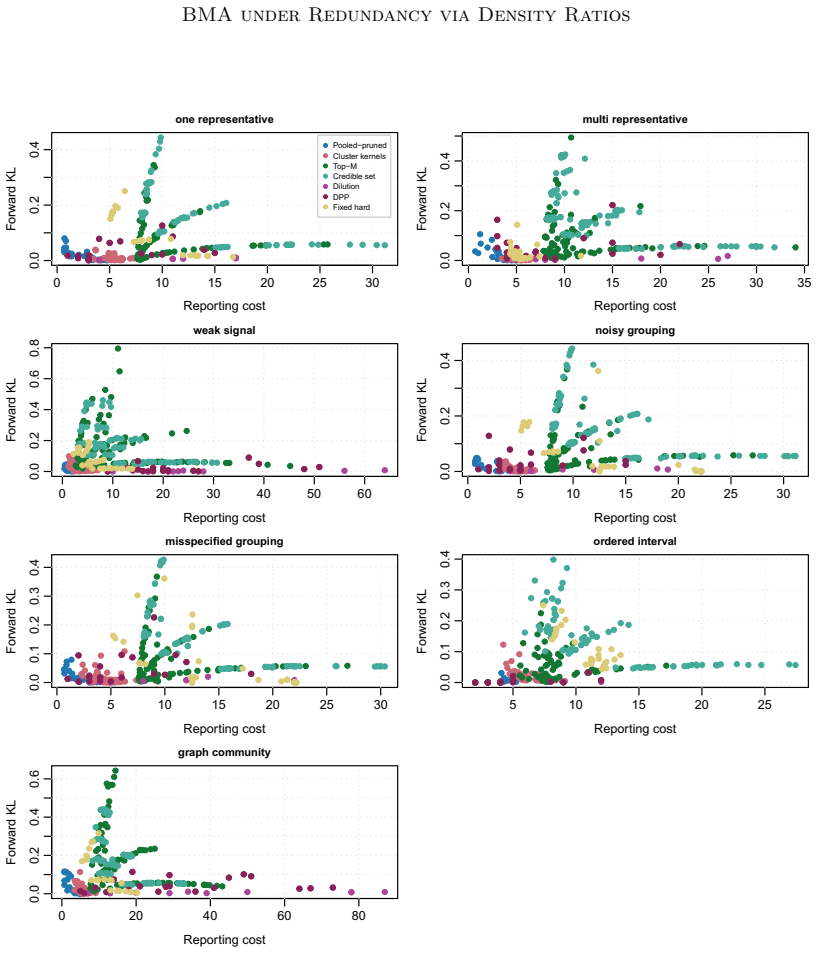
A report uses hard or soft regions of support space, and its compressed reporting law is compared with the reference posterior through an explicit density ratio. This ratio gives computable total-variation and Kullback-Leibler distortion, bounds for bounded predictive summaries, retained-mass diagnostics, and fallback-weight diagnostics. The framework covers fixed hard regions, metric-ball regions, posterior-cluster regions, and pooled-pruned region dictionaries. We prove exact error formulas and validation bounds for these region reports, and give conditions under which a few regions can replace a long list of individual supports.
What carries the argument
The explicit density ratio between a region-based reporting law and the reference posterior, which directly quantifies total-variation and Kullback-Leibler distortion plus predictive bounds.
If this is right
- Region reports often give shorter and clearer summaries while preserving the main posterior information.
- Density-ratio diagnostics show when too much information has been lost.
- Exact error formulas and validation bounds apply to fixed hard regions, metric-ball regions, posterior-cluster regions, and pooled-pruned dictionaries.
- Under the stated conditions a few regions can replace a long list of individual supports.
Where Pith is reading between the lines
- The same density-ratio comparison could be applied to compress other high-dimensional posteriors that exhibit redundancy or near-interchangeable modes.
- Practitioners might use the retained-mass and fallback-weight diagnostics to set thresholds for accepting a compressed report in applied work.
- The framework suggests a general route for stable reporting of posteriors over discrete structures whenever the reference distribution can be sampled from.
Load-bearing premise
The density ratio between any chosen reporting law and the reference posterior can be evaluated or bounded sufficiently well to deliver the claimed total-variation, Kullback-Leibler, and predictive distortion guarantees without introducing post-hoc fitting that alters the reported quantities.
What would settle it
A concrete simulation or dataset in which the observed total-variation distance or predictive distortion between the region report and the full posterior exceeds the upper bound computed from the density ratio.
Figures
read the original abstract
Bayesian model averaging in support-indexed regression induces a posterior distribution over active predictor supports. Under predictor redundancy, posterior mass can spread across many nearly interchangeable supports, making exact-support summaries unstable or hard to interpret even when prediction is stable. We study how to report an already fitted Bayesian model averaging posterior without changing the Bayesian target. A report uses hard or soft regions of support space, and its compressed reporting law is compared with the reference posterior through an explicit density ratio. This ratio gives computable total-variation and Kullback--Leibler distortion, bounds for bounded predictive summaries, retained-mass diagnostics, and fallback-weight diagnostics. The framework covers fixed hard regions, metric-ball regions, posterior-cluster regions, and pooled-pruned region dictionaries. We prove exact error formulas and validation bounds for these region reports, and give conditions under which a few regions can replace a long list of individual supports. In simulations, our region reports often give shorter and clearer summaries while preserving the main posterior information, and the density-ratio diagnostics show when too much information has been lost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a framework for compressing already-fitted Bayesian model averaging posteriors over supports in the presence of predictor redundancy. It defines hard or soft region-based reporting laws (fixed regions, metric balls, posterior clusters, pooled-pruned dictionaries) and compares each to the reference posterior via an explicit density ratio, from which it derives exact total-variation and KL distortion formulas, predictive-summary bounds, retained-mass diagnostics, and fallback-weight diagnostics. The manuscript states that it proves these exact error formulas and validation bounds and supplies simulation evidence that a small number of regions can replace long lists of individual supports while preserving main posterior information.
Significance. If the density ratios are indeed evaluable directly from the reference posterior without post-hoc fitting, the exact distortion formulas would constitute a useful technical contribution for producing concise, interpretable summaries of multimodal BMA posteriors together with rigorous information-loss guarantees. The explicit provision of computable TV/KL expressions and the coverage of multiple region constructions are strengths that could aid interpretability in high-dimensional regression settings.
major comments (2)
- [Abstract] Abstract and the section defining the reporting laws: the central claim that the density ratio between any chosen reporting law and the reference posterior delivers exact, non-vacuous TV/KL/predictive-distortion guarantees rests on the ratio being evaluable or tightly bounded from the reference posterior alone. For posterior-cluster and pooled-pruned region constructions, the manuscript does not demonstrate that the required ratio evaluation avoids data-dependent optimization steps that would render the reported distortions post-hoc rather than exact.
- [Abstract] The statement that 'we prove exact error formulas and validation bounds' is load-bearing for the contribution, yet the provided description gives no indication of how the ratio is constructed or bounded for combinatorial support spaces without introducing quantities fitted from the same data used to define the regions.
minor comments (2)
- Notation for the density ratio and the various region types should be introduced with explicit definitions and running examples to improve readability.
- Simulation section: clarify the data-exclusion rules and whether any region definitions were chosen after inspecting the posterior mass.
Simulated Author's Rebuttal
We thank the referee for the careful review and for highlighting the importance of demonstrating that the density ratios yield exact, non-vacuous guarantees without post-hoc fitting. We address both major comments below and will revise the manuscript to strengthen the exposition of the ratio constructions.
read point-by-point responses
-
Referee: [Abstract] Abstract and the section defining the reporting laws: the central claim that the density ratio between any chosen reporting law and the reference posterior delivers exact, non-vacuous TV/KL/predictive-distortion guarantees rests on the ratio being evaluable or tightly bounded from the reference posterior alone. For posterior-cluster and pooled-pruned region constructions, the manuscript does not demonstrate that the required ratio evaluation avoids data-dependent optimization steps that would render the reported distortions post-hoc rather than exact.
Authors: The density ratio is constructed directly from the already-fitted reference posterior for every reporting law, including posterior-cluster and pooled-pruned dictionaries. Regions are first identified using posterior masses and any auxiliary metric or clustering on the support space; the reporting law is then defined as a (possibly soft) distribution over those regions whose masses are obtained by renormalizing the reference posterior within each region. The ratio r(s) = reporting_law(s) / p(s) is therefore evaluated pointwise on the support space using only quantities already available from p. No additional optimization or data-dependent fitting is performed after the regions are chosen. We will revise Sections 3 and 4 to include explicit algorithmic descriptions and worked examples for the cluster and pooled-pruned cases that make this construction transparent. revision: yes
-
Referee: [Abstract] The statement that 'we prove exact error formulas and validation bounds' is load-bearing for the contribution, yet the provided description gives no indication of how the ratio is constructed or bounded for combinatorial support spaces without introducing quantities fitted from the same data used to define the regions.
Authors: For combinatorial support spaces the ratio is defined at the level of individual supports: once a reporting law q over regions is fixed, r(s) equals q(region(s)) / p(s) for each support s, where both q and p are known from the reference posterior. The exact TV and KL formulas then follow from the standard integral identities TV(p,q) = (1/2) E_p[|1 - r|] and KL(p||q) = E_p[r log r], which hold regardless of how the regions were selected. No auxiliary fitted quantities are introduced. We will expand the abstract and add a short subsection in the methods that spells out this construction for high-dimensional support spaces and reiterates that the distortion calculations remain exact once the reporting law is specified. revision: yes
Circularity Check
No significant circularity; density-ratio framework is definitional and self-contained
full rationale
The paper constructs region reports by user choice of hard/soft regions on support space, then defines the compressed reporting law and compares it to the reference posterior via an explicit density ratio. Distortions (TV, KL, predictive bounds) follow directly from this ratio by standard information-theoretic identities, without any reduction to quantities fitted from the same data or to self-citations. The abstract states that the ratio 'gives computable' quantities and that exact error formulas are proved under this construction; no load-bearing step equates a prediction to its own input or imports uniqueness via prior author work. The framework is therefore independent of the fitted posterior values themselves.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Total variation and Kullback-Leibler divergence are valid distortion measures between probability distributions on support space
Reference graph
Works this paper leans on
-
[1]
Journal of the American Statistical Association , volume =
doi: 10.1080/01621459.2024.2402568. Eric Bair, Trevor Hastie, Debashis Paul, and Robert Tibshirani. Prediction by supervised principal components.Journal of the American Statistical Association, 101(473):119–137,
-
[2]
Prediction by Supervised Principal Components
doi: 10.1198/016214505000000628. Merlise A. Clyde, Joyee Ghosh, and Michael L. Littman. Bayesian adaptive sampling for variable selection and model averaging.Journal of Computational and Graphical Statistics, 20(1):80–101,
-
[3]
and Ghosh, Joyee and Littman, Michael L
doi: 10.1198/jcgs.2010.09049. AnabelForte, GonzaloGarcía-Donato, andMarkF.J.Steel. MethodsandtoolsforBayesian variable selection and model averaging in normal linear regression.International Statis- tical Review, 86(2):237–258,
-
[4]
doi: 10.1111/insr.12249. EdwardI.George. Dilutionpriors: Compensatingformodelspaceredundancy. InBorrowing Strength: Theory Powering Applications, A Festschrift for Lawrence D. Brown, volume 6, pages 158–165. Institute of Mathematical Statistics,
-
[5]
doi: 10.1214/10-IMSCOLL611. Joyee Ghosh and Andrew E. Ghattas. Bayesian variable selection under collinearity.The American Statistician, 69(3):165–173,
-
[6]
Minors of a Class of Riordan Arrays Related to Weighted Partial Motzkin Paths
doi: 10.1080/00031305.2015.1031827. Jennifer A. Hoeting, David Madigan, Adrian E. Raftery, and Chris T. Volinsky. Bayesian model averaging: A tutorial.Statistical Science, 14(4):382–401,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1080/00031305.2015.1031827 2015
-
[7]
Mutsuki Kojima and Fumiyasu Komaki
doi: 10.1214/ss/1 009212519. Mutsuki Kojima and Fumiyasu Komaki. Determinantal point process priors for Bayesian variable selection in linear regression.Statistica Sinica, 26(1):97–117,
-
[8]
47 Li, Lu, and Chen Arun Krishna, Howard D
doi: 10.570 5/ss.202014.0161. 47 Li, Lu, and Chen Arun Krishna, Howard D. Bondell, and Sujit K. Ghosh. Bayesian variable selection using an adaptive powered correlation prior.Journal of Statistical Planning and Inference, 139 (8):2665–2674,
-
[9]
doi: 10.1016/j.jspi.2008.12.005. Kristian Hovde Liland, Bjorn-Helge Mevik, and Ron Wehrens.pls: Partial Least Squares and Principal Component Regression,
-
[10]
Federico Pavone, Juho Piironen, Paul-Christian Bürkner, and Aki Vehtari
doi: 10.1093/biomet/asx019. Federico Pavone, Juho Piironen, Paul-Christian Bürkner, and Aki Vehtari. Using reference models in variable selection.Computational Statistics, 38(1):349–371,
-
[11]
Juho Piironen, Markus Paasiniemi, and Aki Vehtari
doi: 10.1007/s11222-016-964 9-y. Juho Piironen, Markus Paasiniemi, and Aki Vehtari. Projective inference in high- dimensional problems: Prediction and feature selection.Electronic Journal of Statistics, 14(1):2155–2197,
-
[12]
Noah Simon, Jerome Friedman, Trevor Hastie, and Robert Tibshirani
doi: 10.1214/20-EJS1711. Noah Simon, Jerome Friedman, Trevor Hastie, and Robert Tibshirani. A sparse-group lasso.Journal of Computational and Graphical Statistics, 22(2):231–245,
-
[13]
and Hooker, Giles and Staicu, Ana-Maria and Scheipl, Fabian and Ruppert, David , year =
doi: 10.1080/10618600.2012.681250. Hans Henrik Thodberg. Ace of Bayes: Application of neural networks with pruning. Tech- nical Report 1132E, Danish Meat Research Institute,
-
[14]
doi: 10.1111/j.1467 -9868.2005.00532.x. Hui Zou and Trevor Hastie. Regularization and variable selection via the elastic net.Journal of the Royal Statistical Society: Series B, 67(2):301–320,
-
[15]
doi: 10.1111/j.1467-986 8.2005.00503.x. 48
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.