Variance Reduction for Stochastic Gradient Generalized Non-reversible Langevin Monte Carlo Algorithms
Pith reviewed 2026-06-30 08:59 UTC · model grok-4.3
The pith
An anti-symmetric perturbation strictly reduces the leading-order fluctuation constant of stochastic gradient non-reversible Langevin estimators relative to the reversible baseline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under standard operator-theoretic assumptions, an anti-symmetric perturbation strictly reduces the leading-order fluctuation constant relative to the reversible baseline for the empirical average over a horizon of order the inverse squared stepsize in the vanishing-stepsize regime.
What carries the argument
The operator form of the limiting variance constant obtained from the Poisson equation of the full-gradient diffusion, which connects the discrete estimator variance to the continuous-time asymptotic variance and permits direct comparison under anti-symmetric perturbations.
If this is right
- Bounded smooth predictive observables satisfy the central limit theorem with the reduced variance constant.
- Closed-form variance formulas are available for quadratic Hamiltonians and linear observables.
- The framework covers Hessian-free high-resolution dynamics and a positive-definite subclass of gradient-adjusted underdamped Langevin dynamics.
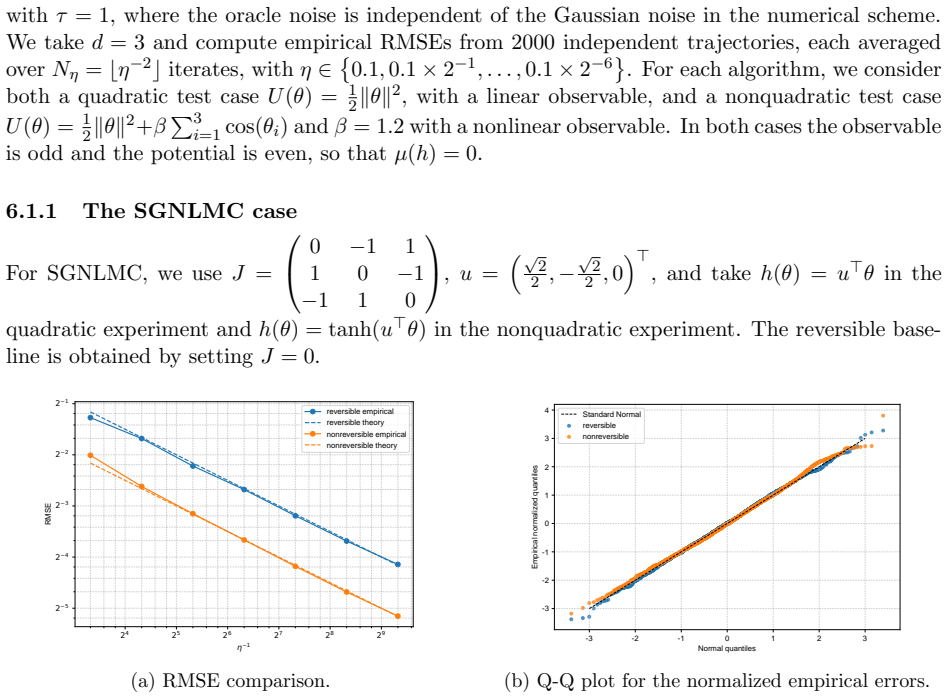
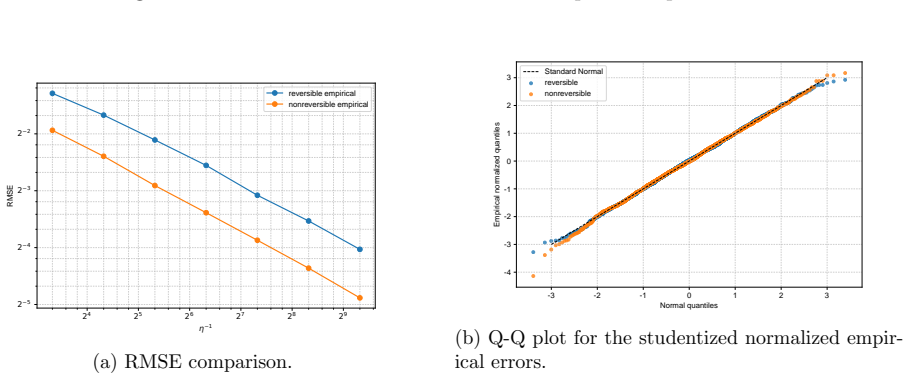
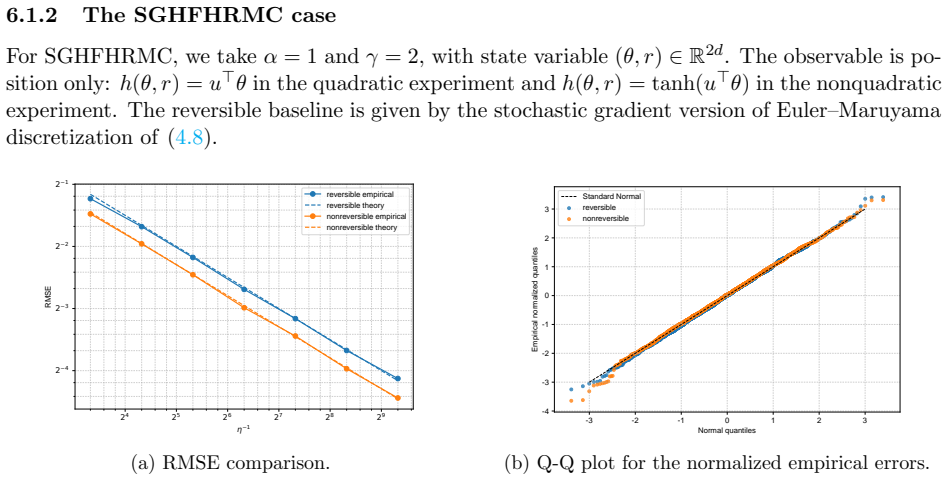
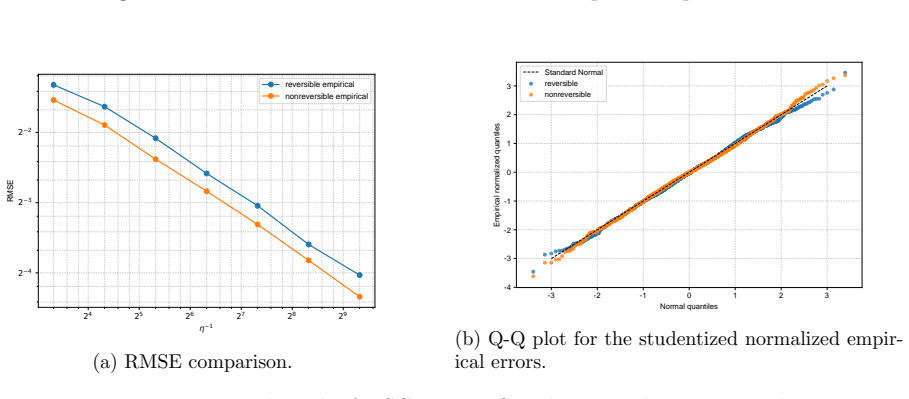
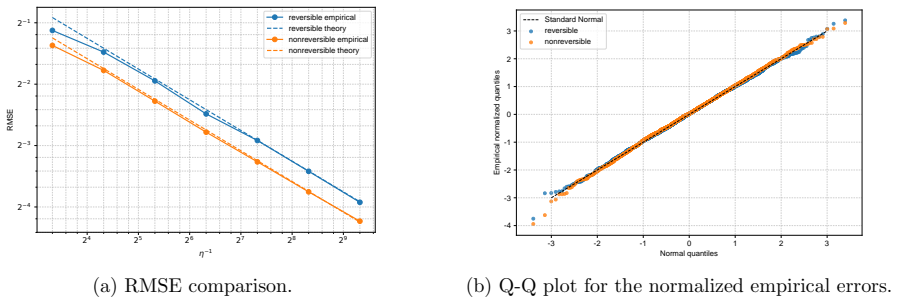
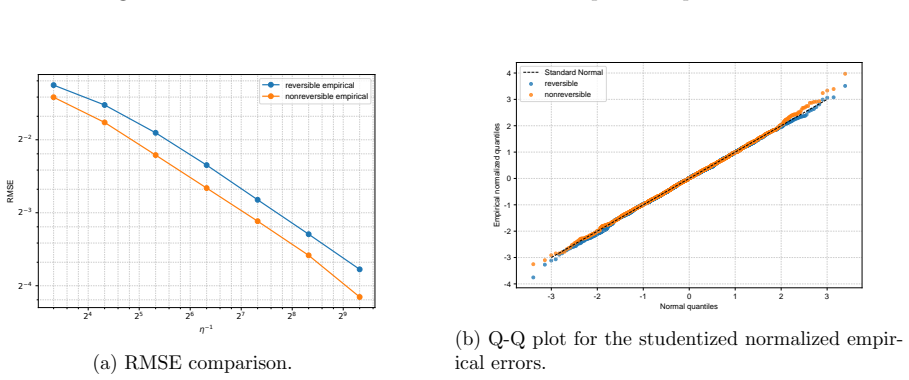
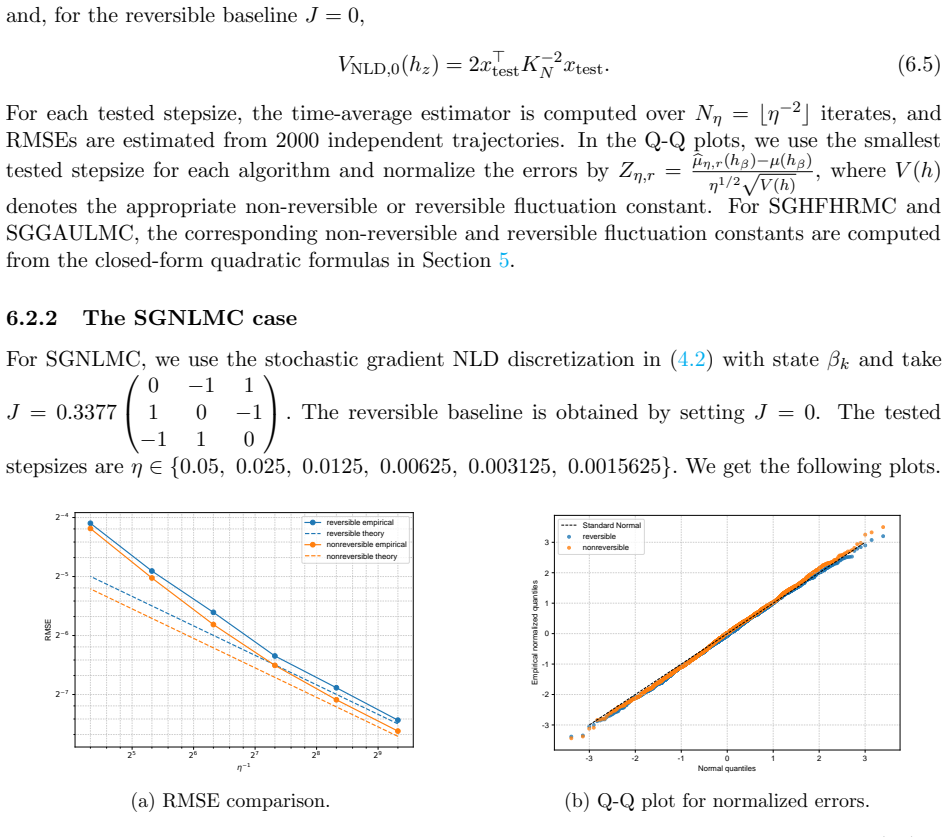
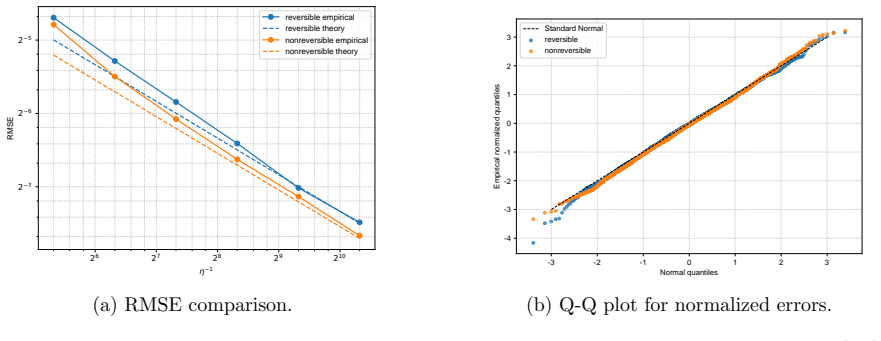
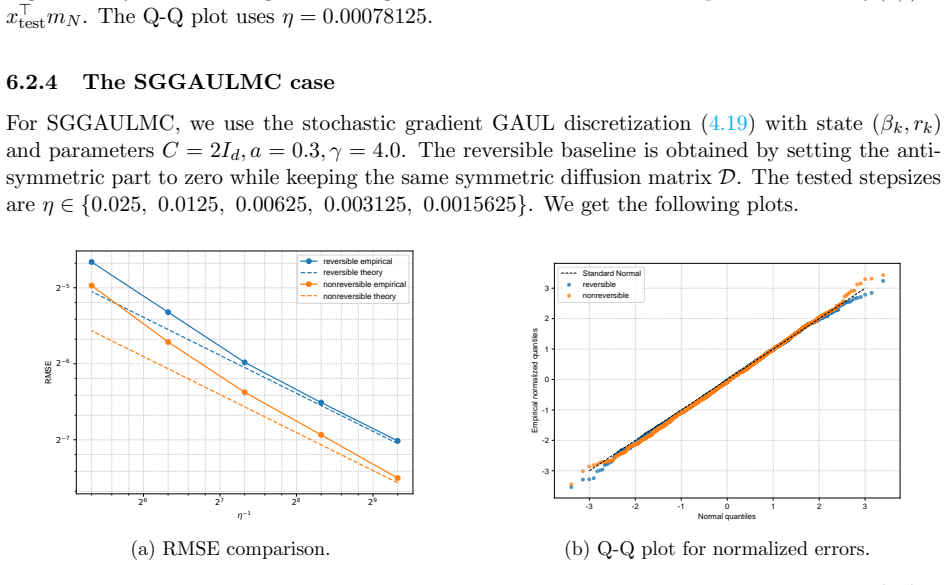
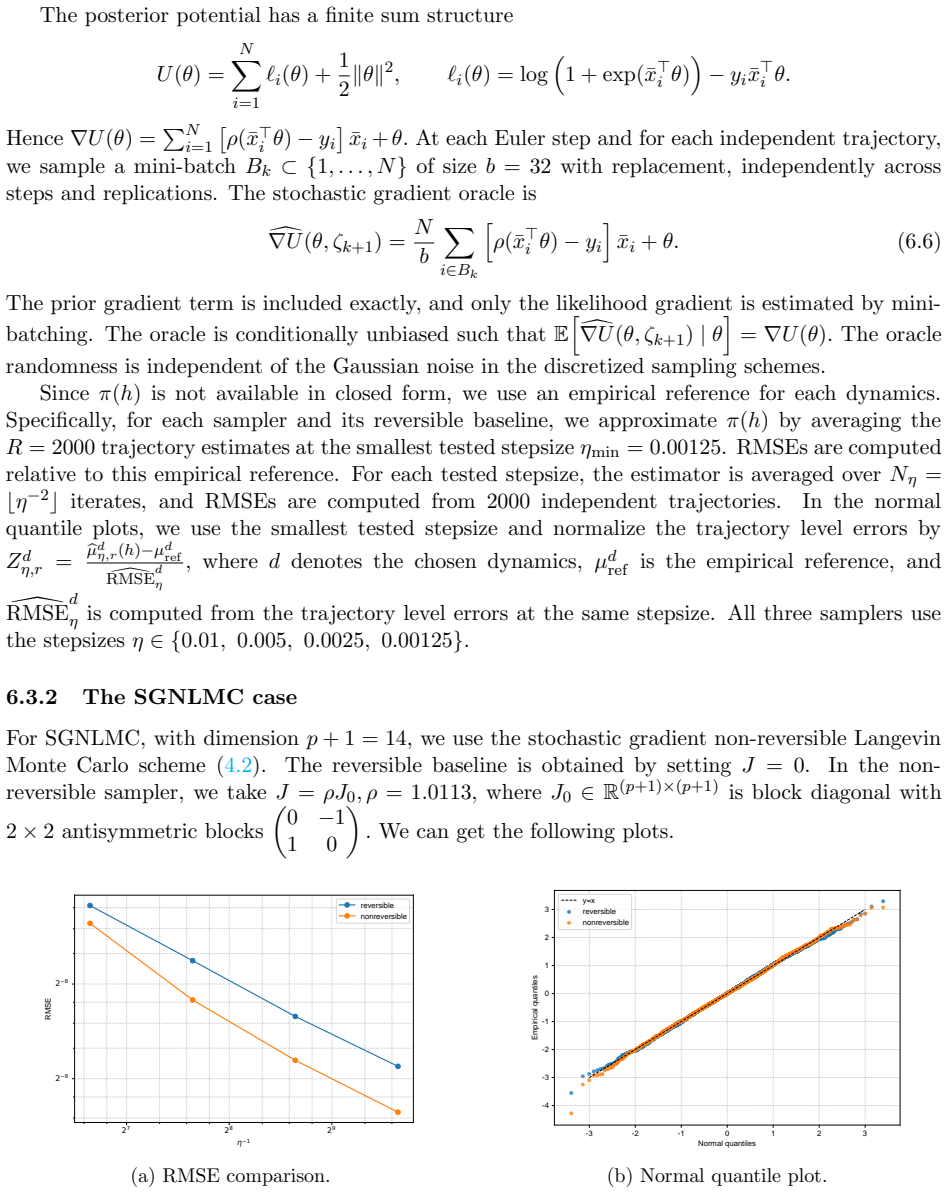
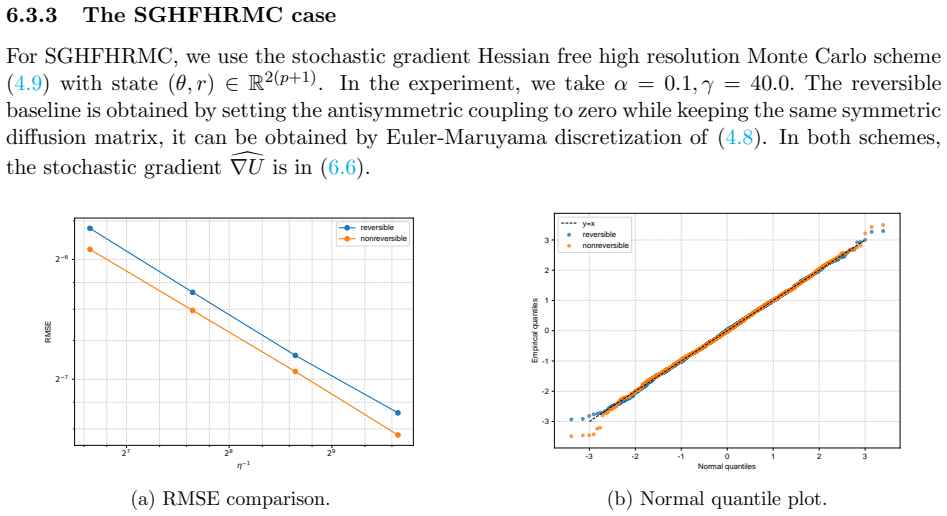
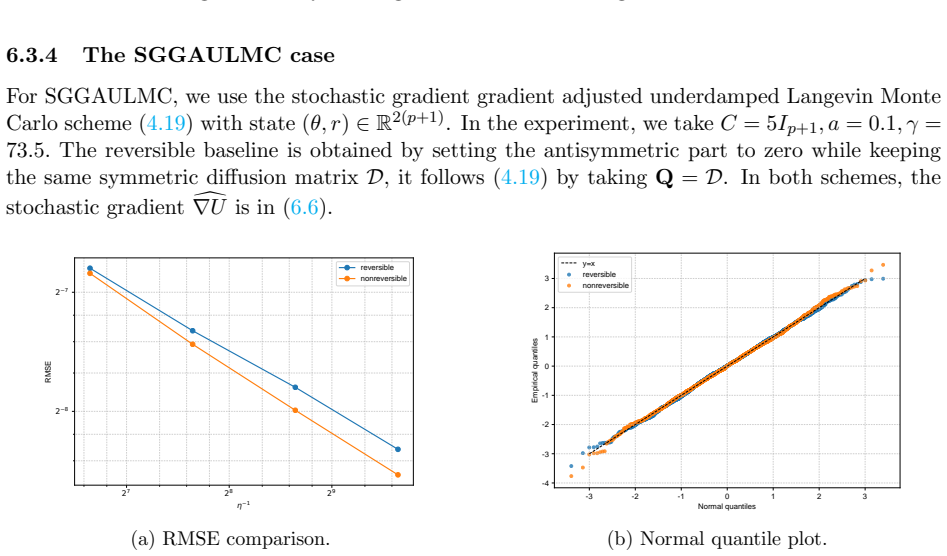
- Numerical experiments on Bayesian linear and logistic regression show lower root-mean-squared error for the non-reversible schemes.
Where Pith is reading between the lines
- The variance reduction may persist for non-quadratic potentials if the operator inequality continues to hold.
- The same operator comparison could be applied to other stochastic-gradient Markov chains whose generators admit an anti-symmetric splitting.
- The explicit Gaussian formulas offer a benchmark for testing numerical implementations of the small-stepsize limit.
Load-bearing premise
The structural assumptions required for the small-stepsize central limit theorem together with an unbiased stochastic gradient oracle.
What would settle it
For a quadratic Hamiltonian and linear observable, compute the explicit limiting variance constant with and without the anti-symmetric term and verify whether the non-reversible value is strictly smaller.
Figures
read the original abstract
We study the leading-order fluctuation of stochastic gradient Euler-Maruyama estimators for generalized non-reversible Langevin dynamics. Under structural assumptions tailored to the small-stepsize central limit theorem and under an unbiased stochastic gradient oracle, we prove that the empirical average over a horizon of order the inverse squared stepsize satisfies a central limit theorem in the vanishing-stepsize regime. The limiting variance is characterized through the Poisson equation of the limiting full-gradient diffusion. We then rewrite this constant in an operator form that links it to the continuous-time asymptotic variance and, under standard operator-theoretic assumptions, derive a sufficient condition under which an anti-symmetric perturbation strictly reduces the leading-order fluctuation constant relative to the reversible baseline. We also identify bounded smooth predictive observables that re directly covered by the main theorem. As a separate Gaussian calculation beyond the bounded-test-function regime, we obtain closed-form formulas for quadratic Hamiltonians and linear observables. The framework covers non-reversible Langevin dynamics and augmented-state examples including Hessian-free high-resolution dynamics and a positive-definite subclass of gradient-adjusted underdamped Langevin dynamics that allow stochastic gradients. Numerical experiments on basic examples and Bayesian linear regression using synthetic data, and Bayesian logistic regression using real data support the predicted Gaussian fluctuations and show that the non-reversible schemes consistently reduce the root mean squared error (RMSE) relative to their reversible baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that under structural assumptions tailored to the small-stepsize CLT and an unbiased stochastic gradient oracle, the empirical average of stochastic gradient Euler-Maruyama discretizations of generalized non-reversible Langevin dynamics satisfies a central limit theorem whose limiting variance is characterized via the Poisson equation of the limiting diffusion. Rewriting this variance in operator form yields, under standard operator-theoretic assumptions, a sufficient condition for an anti-symmetric perturbation to strictly reduce the leading-order fluctuation constant relative to the reversible baseline. The framework is said to cover non-reversible Langevin and augmented-state examples (Hessian-free high-resolution, positive-definite gradient-adjusted underdamped); closed-form expressions are derived for quadratic Hamiltonians with linear observables, and numerical experiments on regression tasks are presented to support Gaussian fluctuations and RMSE reduction.
Significance. If the operator assumptions hold for the advertised dynamics, the work supplies a rigorous operator-theoretic justification for variance reduction in stochastic-gradient non-reversible Langevin Monte Carlo, extending existing reversible analyses. The separate closed-form Gaussian calculation and the explicit coverage of bounded smooth observables constitute concrete strengths that could be directly usable in applications.
major comments (2)
- [the paragraph deriving the sufficient condition under standard operator-theoretic assumptions] The sufficient condition for strict variance reduction (derived after rewriting the limiting variance in operator form) is obtained under 'standard operator-theoretic assumptions,' yet the manuscript provides no explicit verification that the required spectral or inequality properties hold for the Hessian-free high-resolution dynamics or the positive-definite subclass of gradient-adjusted underdamped Langevin dynamics listed in the abstract. Because this condition is the load-bearing step for the headline claim that non-reversible schemes reduce fluctuation relative to reversible baselines, the absence of the check prevents the result from applying to the main examples.
- [the section stating the structural assumptions for the CLT] The CLT statement and the subsequent operator rewriting are proved under structural assumptions 'tailored to the small-stepsize central limit theorem.' No explicit confirmation is given that these assumptions are satisfied by the generators of the two augmented-state examples, which is required to transfer the variance-reduction conclusion to the dynamics the paper advertises.
minor comments (1)
- [Abstract] Abstract contains the typo 're directly covered' (should read 'are directly covered').
Simulated Author's Rebuttal
We thank the referee for the careful and constructive report. The two major comments correctly note the absence of explicit verifications that the operator-theoretic and structural assumptions hold for the advertised augmented-state examples. We will revise the manuscript to supply these verifications.
read point-by-point responses
-
Referee: The sufficient condition for strict variance reduction (derived after rewriting the limiting variance in operator form) is obtained under 'standard operator-theoretic assumptions,' yet the manuscript provides no explicit verification that the required spectral or inequality properties hold for the Hessian-free high-resolution dynamics or the positive-definite subclass of gradient-adjusted underdamped Langevin dynamics listed in the abstract. Because this condition is the load-bearing step for the headline claim that non-reversible schemes reduce fluctuation relative to reversible baselines, the absence of the check prevents the result from applying to the main examples.
Authors: We agree that the manuscript does not contain an explicit check of the operator assumptions for the two augmented-state examples. In the revision we will add a new subsection that verifies the required spectral gap, sectoriality, and inequality conditions for both the Hessian-free high-resolution generator and the positive-definite gradient-adjusted underdamped generator, thereby confirming that the sufficient condition for strict variance reduction applies to these dynamics. revision: yes
-
Referee: The CLT statement and the subsequent operator rewriting are proved under structural assumptions 'tailored to the small-stepsize central limit theorem.' No explicit confirmation is given that these assumptions are satisfied by the generators of the two augmented-state examples, which is required to transfer the variance-reduction conclusion to the dynamics the paper advertises.
Authors: We acknowledge that the paper states coverage of the examples without supplying a direct verification that their generators meet the structural assumptions. The revision will include explicit verification that the generators of the Hessian-free high-resolution and positive-definite gradient-adjusted underdamped dynamics satisfy the required conditions (unbiased oracle, dissipativity, and regularity for the Poisson equation), allowing the CLT and variance-reduction statements to apply directly. revision: yes
Circularity Check
No significant circularity; derivation uses external operator tools
full rationale
The central derivation characterizes the CLT limiting variance via the Poisson equation of the limiting diffusion, rewrites the constant in operator form, and invokes standard operator-theoretic assumptions to obtain a sufficient condition for strict variance reduction by anti-symmetric perturbation. These steps rely on established results from stochastic analysis rather than quantities defined, fitted, or renamed within the paper. No self-citations appear as load-bearing premises, no parameters are fitted and relabeled as predictions, and no ansatz or uniqueness claim reduces to prior author work by construction. The framework is self-contained against external benchmarks, with numerical experiments serving only as supporting illustration.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption structural assumptions tailored to the small-stepsize central limit theorem
- domain assumption unbiased stochastic gradient oracle
Reference graph
Works this paper leans on
-
[1]
Bajwa, Mert Gurbuzbalaban, Mustafa Ali Kutbay, Lingjiong Zhu, and Muhammad Zulqarnain
[BGK+25] Waheed U. Bajwa, Mert Gurbuzbalaban, Mustafa Ali Kutbay, Lingjiong Zhu, and Muhammad Zulqarnain. DIGing-SGLD: Decentralized and scalable Langevin sampling over time-varying networks.arXiv:2511.12836,
-
[2]
Large-scale machine learning with stochastic gradient descent
[Bot10] L´ eon Bottou. Large-scale machine learning with stochastic gradient descent. InPro- ceedings of COMPSTAT’2010, pages 177–186. Springer,
2010
-
[3]
Non-reversible Langevin algorithms for constrained sampling.arXiv:2501.11743,
[DFT+25] Hengrong Du, Qi Feng, Changwei Tu, Xiaoyu Wang, and Lingjiong Zhu. Non-reversible Langevin algorithms for constrained sampling.arXiv:2501.11743,
-
[4]
Nonreversible Langevin Samplers: Splitting Schemes, Analysis and Implementation
[DPZ17] Andrew B. Duncan, Grigoris A. Pavliotis, and Konstantinos C. Zygalakis. Nonre- versible Langevin samplers: Splitting schemes, analysis and implementation.arXiv preprint arXiv:1701.04247,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Generalized EXTRA stochastic gradient Langevin dynamics.arXiv preprint arXiv:2412.01993,
[GIWZ24] Mert G¨ urb¨ uzbalaban, Mohammad Rafiqul Islam, Xiaoyu Wang, and Lingjiong Zhu. Generalized EXTRA stochastic gradient Langevin dynamics.arXiv preprint arXiv:2412.01993,
-
[6]
Bayesian Active Learning for Classification and Preference Learning
[HHGL11] Neil Houlsby, Ferenc Husz´ ar, Zoubin Ghahramani, and M´ at´ e Lengyel. Bayesian active learning for classification and preference learning.arXiv preprint arXiv:1112.5745,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
47 [HWG+20] Yuanhan Hu, Xiaoyu Wang, Xuefeng Gao, G¨ urb¨ uzbalaban, and Lingjiong Zhu. Non- convex stochastic optimization via non-reversible stochastic gradient Langevin dynam- ics.arXiv:2004.02823,
-
[8]
Chatterji, Xiang Cheng, Nicolas Flammarion, Peter L
[MCC+21] Yi-An Ma, Niladri S. Chatterji, Xiang Cheng, Nicolas Flammarion, Peter L. Bartlett, and Michael I. Jordan. Is there an analog of Nesterov acceleration for gradient-based MCMC?Bernoulli, 27(3):1942–1992,
1942
-
[9]
Irreversible Langevin samplers and variance reduction: a large deviation approach.Nonlinearity, 28:2081,
[RBS15a] Luc Rey-Bellet and Konstantinos Spiliopoulos. Irreversible Langevin samplers and variance reduction: a large deviation approach.Nonlinearity, 28:2081,
2081
-
[10]
Non-convex learning via stochastic gradient Langevin dynamics: a nonasymptotic analysis
48 [RRT17] Maxim Raginsky, Alexander Rakhlin, and Matus Telgarsky. Non-convex learning via stochastic gradient Langevin dynamics: a nonasymptotic analysis. InProceedings of the 2017 Conference on Learning Theory, volume 65, pages 1674–1703. PMLR,
2017
-
[11]
Statlog (Heart) [Dataset]
[UCI] UCI Machine Learning Repository. Statlog (Heart) [Dataset]. UCI Machine Learning Repository. Accessed: 2026-06-14. [WHC14] Sheng-Jhih Wu, Chii-Ruey Hwang, and Moody T. Chu. Attaining the optimal Gaus- sian diffusion acceleration.Journal of Statistical Physics, 155(3):571–590,
2026
-
[12]
[WWZ25] Xiaoyu Wang, Yingli Wang, and Lingjiong Zhu
To appear. [WWZ25] Xiaoyu Wang, Yingli Wang, and Lingjiong Zhu. Regime-switching Langevin Monte Carlo algorithms.arXiv preprint arXiv:2509.00941,
-
[13]
[WWZ26] Xiaoyu Wang, Yingli Wang, and Lingjiong Zhu. Sampling non-log-concave densities via Hessian-free high-resolution dynamics.arXiv preprint arXiv:2601.02725,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.