PerspectiveGap: A Benchmark for Multi-Agent Orchestration Prompting
Pith reviewed 2026-06-27 18:17 UTC · model grok-4.3
The pith
PerspectiveGap benchmark measures LLMs' ability to write orchestration prompts for multi-agent systems and finds most models perform poorly at it.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
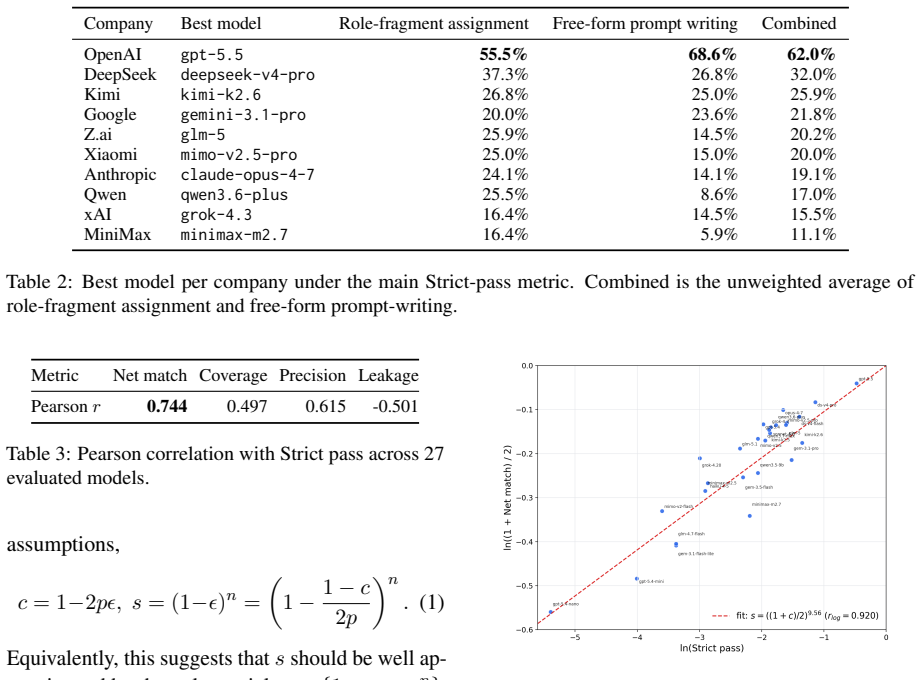
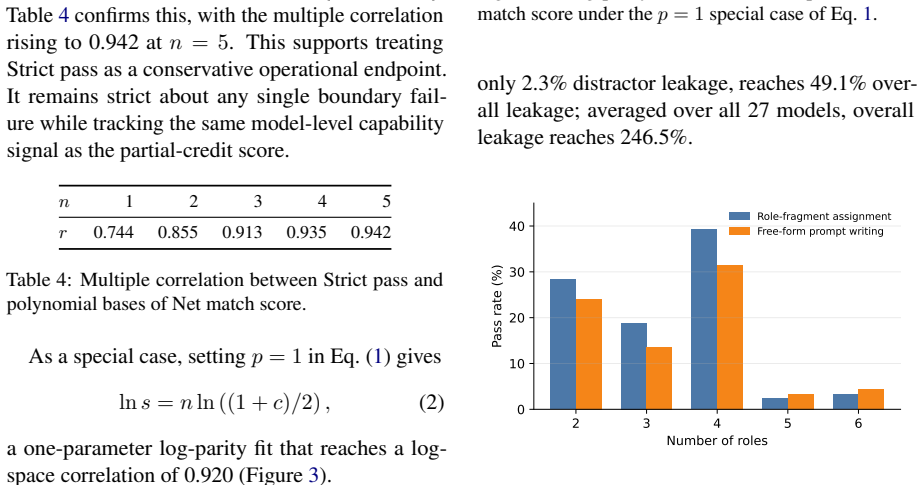
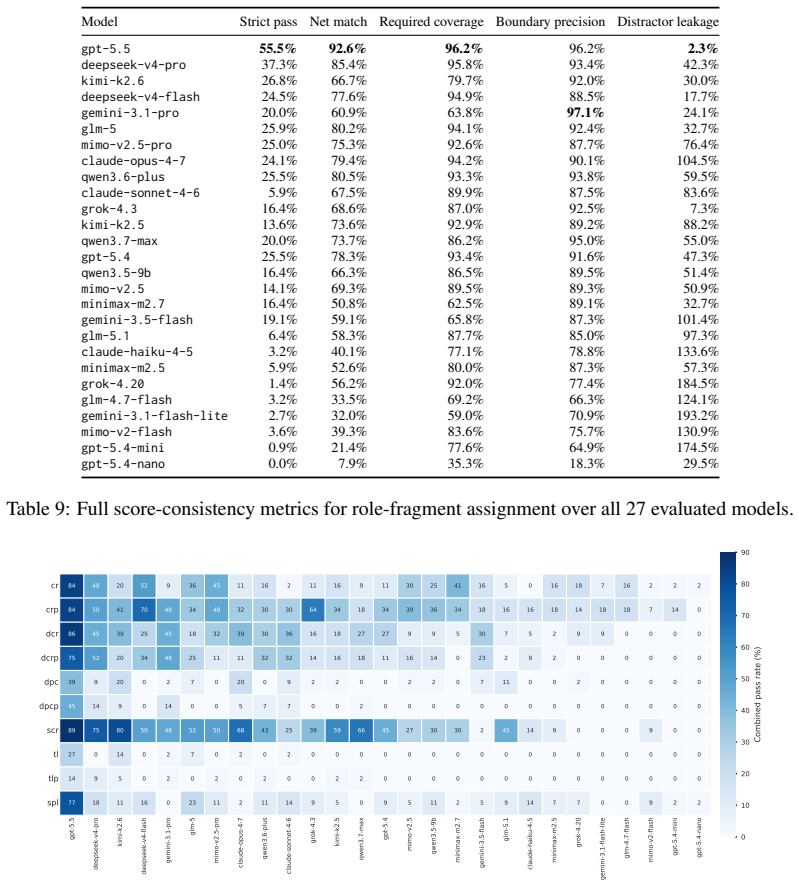
PerspectiveGap evaluates LLMs on two task formats per scenario, role-fragment assignment and free-form prompt writing, across 10 topologies distilled from real-world practice and organized by the Prompt Economy principle of maximizing utility with minimal roles. In tests on 27 commercial models the average combined pass rate is 14.9 percent while the average overall leakage rate reaches 246.5 percent, establishing that multi-agent orchestration prompting constitutes a distinct and under-evaluated capability for which PerspectiveGap supplies a systematic measurement foundation.
What carries the argument
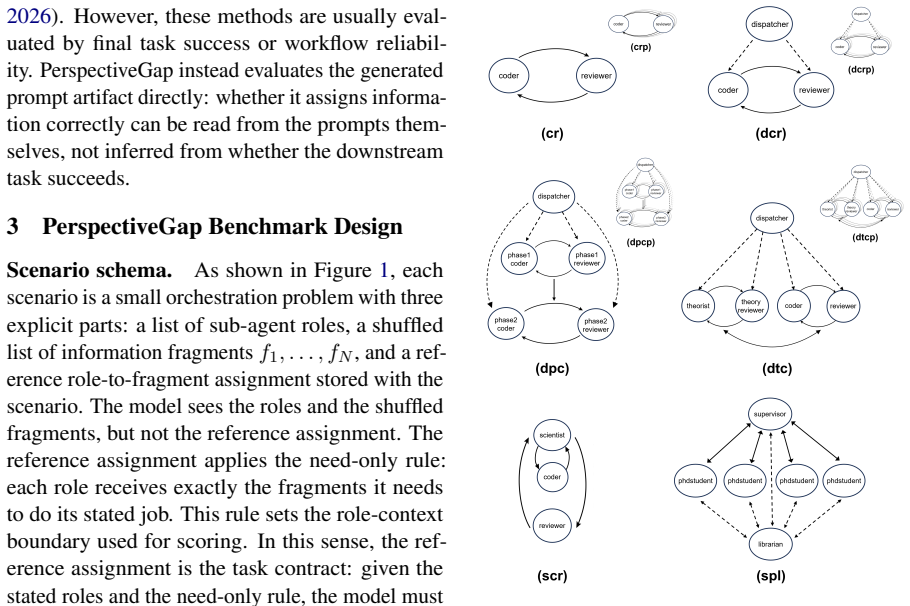
PerspectiveGap benchmark of 110 scenarios in 10 topologies, each tested in distractor-mixed role-fragment assignment and free-form prompt writing formats, framed by the Prompt Economy principle for loop-centered orchestrations.
If this is right
- Orchestration prompting must be treated as a distinct training target separate from coding benchmarks.
- Current top models still leak substantial unnecessary information when composing agent prompts.
- The benchmark supplies concrete metrics that can guide iterative improvement of multi-agent prompt design.
- Low overall pass rates indicate that most commercial models cannot reliably determine what each sub-agent needs to know.
- The Prompt Economy framing implies that simpler loop-centered topologies are the right target for initial progress.
Where Pith is reading between the lines
- Developers could adapt the benchmark's scenario generation process to create training data focused on perspective-taking between agents.
- The leakage metric might be extended to measure prompt efficiency in production multi-agent pipelines.
- Open models could be fine-tuned on the benchmark's failure cases to close the gap with leading commercial systems.
- Similar benchmarks might be built for other orchestration patterns not covered by the current 10 topologies.
Load-bearing premise
The 110 scenarios and 10 topologies distilled from real-world engineering practice adequately represent the general challenges of multi-agent orchestration prompting.
What would settle it
A model that scores above 50 percent on PerspectiveGap yet still produces frequent coordination failures when deployed in actual multi-agent applications outside the benchmark's 10 topologies.
Figures

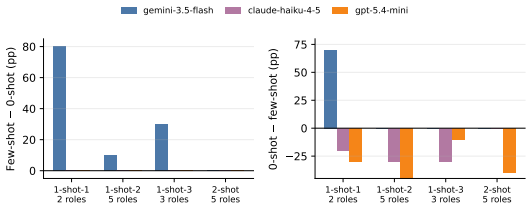
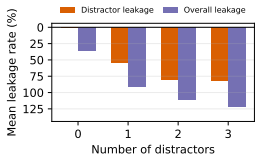
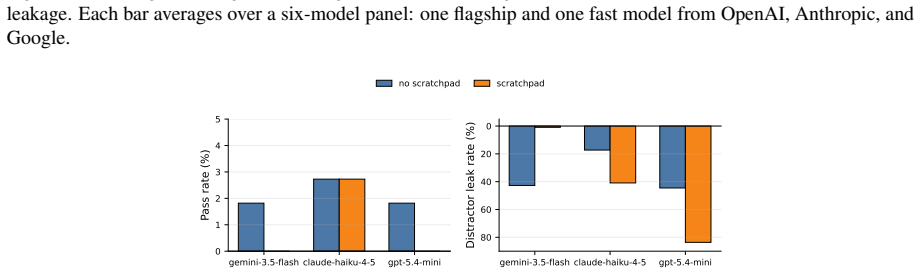
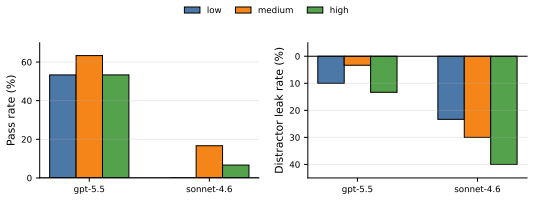
read the original abstract
Real-world LLM applications are moving beyond single-agent workflows toward orchestrated multi-agent systems, yet current models still struggle to determine what each sub-agent needs to know. To measure this, we introduce PerspectiveGap, a benchmark for evaluating LLMs' ability to compose orchestration prompts for multi-agent systems. PerspectiveGap contains 110 scenarios, each evaluated through two distractor-mixed task formats: role-fragment assignment and free-form prompt writing. These scenarios are organized into 10 topologies, which are distilled from the authors' real-world engineering practice and framed by the Prompt Economy principle: building loop-centered orchestrations that maximize utility with minimal role and engineering overhead. In experiments with 27 commercial models from 10 companies, GPT-5.5 substantially outperforms all competitors, whereas Opus 4.7 shows a notable weakness in orchestration prompting despite its strong coding performance. Nevertheless, PerspectiveGap remains challenging: the evaluated models achieve an average combined pass rate of only 14.9\% (GPT-5.5 62.0\%) and an average overall leakage rate of 246.5\% (a per-scenario information leak-event count, not a proportion; GPT-5.5 49.1\%). These findings suggest that multi-agent orchestration prompting is a distinct and under-evaluated capability, and PerspectiveGap provides a foundation for measuring and improving it systematically.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PerspectiveGap, a benchmark with 110 scenarios organized into 10 topologies for evaluating LLMs on composing orchestration prompts for multi-agent systems. Scenarios are distilled from the authors' real-world engineering practice and framed by the Prompt Economy principle of loop-centered orchestrations. Experiments across 27 commercial models from 10 companies report low average performance (14.9% combined pass rate, GPT-5.5 at 62.0%) and high leakage rates, concluding that multi-agent orchestration prompting is a distinct under-evaluated capability and that the benchmark provides a systematic foundation for measurement and improvement.
Significance. If the benchmark's scenarios and topologies validly represent general multi-agent orchestration challenges and the evaluation protocols are sound, the work would usefully highlight a distinct prompting capability separate from single-agent or coding tasks, with the large-scale model comparison (27 models) providing concrete evidence of current limitations. The explicit reporting of both pass rates and leakage metrics is a strength for interpretability.
major comments (2)
- [Abstract] Abstract: The central claim that PerspectiveGap supplies a systematic foundation for measuring multi-agent orchestration prompting requires the 110 scenarios and 10 topologies to capture the general space of challenges, yet the abstract states these were distilled from the authors' practice and framed by the Prompt Economy principle with no external validation, inter-rater agreement, coverage analysis against published multi-agent systems, or comparison to alternative topology taxonomies.
- [Abstract] Abstract: No information is supplied on scoring rules for the role-fragment assignment and free-form prompt writing formats, scenario validation procedures, distractor construction, or statistical controls, so the reported performance numbers (e.g., 14.9% average pass rate, 246.5% average leakage rate) cannot be assessed for reliability or reproducibility.
minor comments (1)
- [Abstract] Abstract: The leakage rate is described as 'a per-scenario information leak-event count, not a proportion'; this definition should be stated explicitly in the main text with an example calculation to avoid misinterpretation.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight key areas for clarifying the benchmark's construction and evaluation. We respond to each major comment below and indicate planned changes to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that PerspectiveGap supplies a systematic foundation for measuring multi-agent orchestration prompting requires the 110 scenarios and 10 topologies to capture the general space of challenges, yet the abstract states these were distilled from the authors' practice and framed by the Prompt Economy principle with no external validation, inter-rater agreement, coverage analysis against published multi-agent systems, or comparison to alternative topology taxonomies.
Authors: The 10 topologies and 110 scenarios were derived from patterns observed across multiple real-world multi-agent deployments in our engineering practice, using the Prompt Economy principle to prioritize loop-centered designs that minimize role overhead. We did not conduct formal external validation or inter-rater agreement studies because the content reflects concrete, non-subjective engineering cases rather than open-ended judgments. In revision we will add a dedicated subsection on topology derivation that includes explicit comparisons to taxonomies in related work (e.g., AutoGen, LangGraph, CrewAI) and a high-level coverage mapping against published multi-agent systems. A limitations paragraph will also note the absence of inter-rater metrics. We maintain that grounding in practice supplies a valid, if not exhaustive, systematic foundation. revision: partial
-
Referee: [Abstract] Abstract: No information is supplied on scoring rules for the role-fragment assignment and free-form prompt writing formats, scenario validation procedures, distractor construction, or statistical controls, so the reported performance numbers (e.g., 14.9% average pass rate, 246.5% average leakage rate) cannot be assessed for reliability or reproducibility.
Authors: The abstract omitted these details, but the full manuscript defines them in Sections 3 and 4: role-fragment scoring uses exact match plus partial credit for correct fragments; free-form prompts are scored by two human raters on correctness and completeness with reported agreement; scenarios were validated through pilot testing with practicing engineers; distractors were generated via embedding similarity to select challenging negatives; and statistical controls include three independent runs per model with variance reported. We will revise the abstract to include a concise methods summary and insert an early 'Evaluation Protocol' subsection with a metrics table. Evaluation code and rubrics will be released to support reproducibility. revision: yes
Circularity Check
No circularity in benchmark definition or claims
full rationale
The paper defines PerspectiveGap by distilling 110 scenarios and 10 topologies from the authors' engineering practice and the Prompt Economy principle. This is an independent construction step with no self-referential equations, fitted parameters renamed as predictions, or load-bearing self-citations. The central claim that the benchmark measures a distinct capability rests on external model evaluations rather than reducing to its own inputs by construction. Representativeness is an external-validity issue, not circularity.
Axiom & Free-Parameter Ledger
free parameters (2)
- 110 scenarios
- 10 topologies
axioms (2)
- ad hoc to paper The Prompt Economy principle is a sound organizing frame for orchestration topologies
- domain assumption Performance on these scenarios reflects general multi-agent orchestration ability
invented entities (1)
-
Prompt Economy principle
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2023 , eprint=
ChatDev: Communicative Agents for Software Development , author=. 2023 , eprint=
2023
-
[2]
2023 , eprint=
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework , author=. 2023 , eprint=
2023
-
[3]
2024 , eprint=
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery , author=. 2024 , eprint=
2024
-
[4]
2026 , eprint=
ReSearch: A Multi-Stage Machine Learning Framework for Earth Science Data Discovery , author=. 2026 , eprint=
2026
-
[5]
2026 , eprint=
AutoNumerics: An Autonomous, PDE-Agnostic Multi-Agent Pipeline for Scientific Computing , author=. 2026 , eprint=
2026
-
[6]
2025 , eprint=
OptimAI: Optimization from Natural Language Using LLM-Powered AI Agents , author=. 2025 , eprint=
2025
-
[7]
2023 , eprint=
Self-Refine: Iterative Refinement with Self-Feedback , author=. 2023 , eprint=
2023
-
[8]
2025 , eprint=
Multi-Agent Collaboration Mechanisms: A Survey of LLMs , author=. 2025 , eprint=
2025
-
[9]
2024 , eprint=
Agent Design Pattern Catalogue: A Collection of Architectural Patterns for Foundation Model based Agents , author=. 2024 , eprint=
2024
-
[10]
2026 , eprint=
Agentic Design Patterns: A System-Theoretic Framework , author=. 2026 , eprint=
2026
-
[11]
2025 , eprint=
Why Do Multi-Agent LLM Systems Fail? , author=. 2025 , eprint=
2025
-
[12]
2026 , eprint=
Understanding Multi-Agent LLM Frameworks: A Unified Benchmark and Experimental Analysis , author=. 2026 , eprint=
2026
-
[13]
2025 , eprint=
Systematic Failures in Collective Reasoning under Distributed Information in Multi-Agent LLMs , author=. 2025 , eprint=
2025
-
[14]
2026 , eprint=
Silo-Bench: A Scalable Environment for Evaluating Distributed Coordination in Multi-Agent LLM Systems , author=. 2026 , eprint=
2026
-
[15]
2026 , eprint=
AgentLeak: A Full-Stack Benchmark for Privacy Leakage in Multi-Agent LLM Systems , author=. 2026 , eprint=
2026
-
[16]
2026 , eprint=
Agent-BRACE: Decoupling Beliefs from Actions in Long-Horizon Tasks via Verbalized State Uncertainty , author=. 2026 , eprint=
2026
-
[17]
2025 , eprint=
OSC: Cognitive Orchestration through Dynamic Knowledge Alignment in Multi-Agent LLM Collaboration , author=. 2025 , eprint=
2025
-
[18]
2026 , eprint=
DecisionBench: A Benchmark for Emergent Delegation in Long-Horizon Agentic Workflows , author=. 2026 , eprint=
2026
-
[19]
2025 , eprint=
Which Agent Causes Task Failures and When? On Automated Failure Attribution of LLM Multi-Agent Systems , author=. 2025 , eprint=
2025
-
[20]
2025 , eprint=
SagaLLM: Context Management, Validation, and Transaction Guarantees for Multi-Agent LLM Planning , author=. 2025 , eprint=
2025
-
[21]
2025 , eprint=
AGENTIF: Benchmarking Instruction Following of Large Language Models in Agentic Scenarios , author=. 2025 , eprint=
2025
-
[22]
2025 , eprint=
Multi-Agent Tool-Integrated Policy Optimization , author=. 2025 , eprint=
2025
-
[23]
2023 , eprint=
Think Twice: Perspective-Taking Improves Large Language Models' Theory-of-Mind Capabilities , author=. 2023 , eprint=
2023
-
[24]
2025 , eprint=
Hypothesis-Driven Theory-of-Mind Reasoning for Large Language Models , author=. 2025 , eprint=
2025
-
[25]
2025 , eprint=
SPIN-Bench: How Well Do LLMs Plan Strategically and Reason Socially? , author=. 2025 , eprint=
2025
-
[26]
2025 , eprint=
SWE-Bench++: A Framework for the Scalable Generation of Software Engineering Benchmarks from Open-Source Repositories , author=. 2025 , eprint=
2025
-
[27]
Hyunwoo Kim and Melanie Sclar and Xuhui Zhou and Ronan Le Bras and Gunhee Kim and Yejin Choi and Maarten Sap , year=. 2310.15421 , archivePrefix=
-
[28]
Yuling Gu and Oyvind Tafjord and Hyunwoo Kim and Jared Moore and Ronan Le Bras and Peter Clark and Yejin Choi , year=. 2410.13648 , archivePrefix=
-
[29]
2024 , eprint=
Explore Theory of Mind: Program-guided adversarial data generation for theory of mind reasoning , author=. 2024 , eprint=
2024
-
[30]
Yashwanth YS and Ruichen Wang and Shihua Zeng and Xuhui Zhou and Koichi Onoue and Vasudha Varadarajan and Maarten Sap , year=. 2605.02307 , archivePrefix=
-
[31]
2025 , eprint=
Position: Theory of Mind Benchmarks are Broken for Large Language Models , author=. 2025 , eprint=
2025
-
[32]
Christopher Ackerman , year=. Selective Deficits in. 2603.26089 , archivePrefix=
-
[33]
Revisiting the Evaluation of Theory of Mind through Question Answering , author =. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) , year =. doi:10.18653/v1/D19-1598 , url =
-
[34]
Cognition , volume =
Wimmer, Heinz and Perner, Josef , title =. Cognition , volume =. 1983 , doi =
1983
-
[35]
and Frith, Uta , title =
Baron-Cohen, Simon and Leslie, Alan M. and Frith, Uta , title =. Cognition , volume =. 1985 , doi =
1985
-
[36]
Happ\'e, Francesca G. E. , title =. Journal of Autism and Developmental Disorders , volume =. 1994 , doi =
1994
-
[37]
What do Theory-of-Mind Tasks Actually Measure? Theory and Practice , journal =
Quesque, Fran. What do Theory-of-Mind Tasks Actually Measure? Theory and Practice , journal =. 2020 , doi =
2020
-
[38]
Building Effective Agents , year =
-
[39]
2025 , howpublished =
Huntley, Geoffrey , title =. 2025 , howpublished =
2025
-
[40]
Agentic Design Patterns: A Hands-On Guide to Building Intelligent Systems , publisher =
Gull. Agentic Design Patterns: A Hands-On Guide to Building Intelligent Systems , publisher =. 2025 , isbn =
2025
-
[41]
Richard and Koch, Gary G
Landis, J. Richard and Koch, Gary G. , title =. Biometrics , volume =. 1977 , doi =
1977
-
[42]
2024 , eprint =
Lost in the Middle: How Language Models Use Long Contexts , author =. 2024 , eprint =
2024
-
[43]
Liu, Xiao and Yu, Hao and Zhang, Hanchen and Xu, Yifan and Lei, Xuanyu and Lai, Hanyu and Gu, Yu and Ding, Hangliang and Men, Kaiwen and Yang, Kejuan and Zhang, Shudan and Deng, Xiang and Zeng, Aohan and Du, Zhengxiao and Zhang, Chenhui and Shen, Sheng and Zhang, Tianjun and Su, Yu and Sun, Huan and Huang, Minlie and Dong, Yuxiao and Tang, Jie , year =. 2...
-
[44]
Qin, Yujia and Liang, Shihao and Ye, Yining and Zhu, Kunlun and Yan, Lan and Lu, Yaxi and Lin, Yankai and Cong, Xin and Tang, Xiangru and Qian, Bill and Zhao, Sihan and Hong, Lauren and Tian, Runchu and Xie, Ruobing and Zhou, Jie and Gerstein, Mark and Li, Dahai and Liu, Zhiyuan and Sun, Maosong , year =. 2307.16789 , archivePrefix =
-
[45]
and Burger, Doug and Wang, Chi , year =
Wu, Qingyun and Bansal, Gagan and Zhang, Jieyu and Wu, Yiran and Li, Beibin and Zhu, Erkang and Jiang, Li and Zhang, Xiaoyun and Zhang, Shaokun and Liu, Jiale and Awadallah, Ahmed Hassan and White, Ryen W. and Burger, Doug and Wang, Chi , year =. 2308.08155 , archivePrefix =
-
[46]
Li, Guohao and Hammoud, Hasan Abed Al Kader and Itani, Hani and Khizbullin, Dmitrii and Ghanem, Bernard , year =. 2303.17760 , archivePrefix =
-
[47]
Chen, Weize and Su, Yusheng and Zuo, Jingwei and Yang, Cheng and Yuan, Chenfei and Chan, Chen-Ming and Yu, Heyang and Lu, Yaxi and Hung, Yi-Hsin and Qian, Chen and Qin, Yujia and Cong, Xin and Xie, Ruobing and Liu, Zhiyuan and Sun, Maosong and Zhou, Jie , year =. 2308.10848 , archivePrefix =
-
[48]
Wu, Yufan and He, Yinghui and Jia, Yilin and Mihalcea, Rada and Chen, Yulong and Deng, Naihao , booktitle =. Hi-. 2023 , doi =
2023
-
[49]
2024 , url =
Xu, Hainiu and Zhao, Runcong and Zhu, Lixing and Du, Jinhua and He, Yulan , booktitle =. 2024 , url =
2024
-
[50]
Advances in Neural Information Processing Systems 36 , year =
Understanding Social Reasoning in Language Models with Language Models , author =. Advances in Neural Information Processing Systems 36 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.