ANCHOR: Abductive Network Construction with Hierarchical Orchestration for Reliable Probability Inference in Large Language Models
Pith reviewed 2026-06-30 22:38 UTC · model grok-4.3
The pith
ANCHOR builds hierarchical factor spaces and causal networks to make LLM probability estimates more reliable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
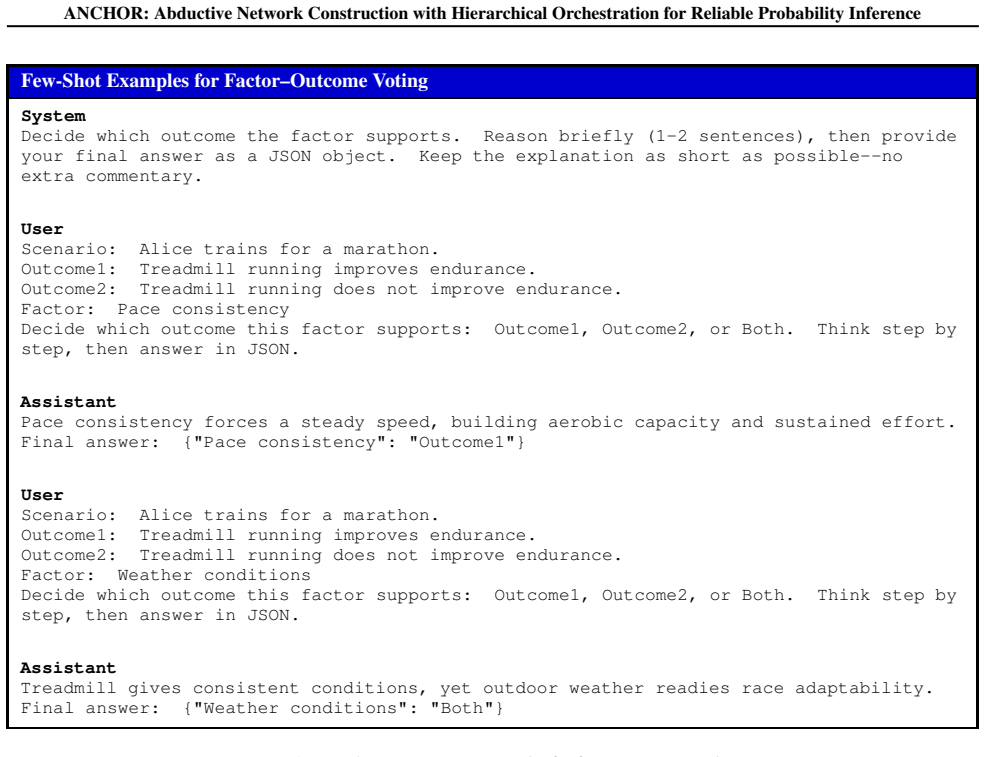
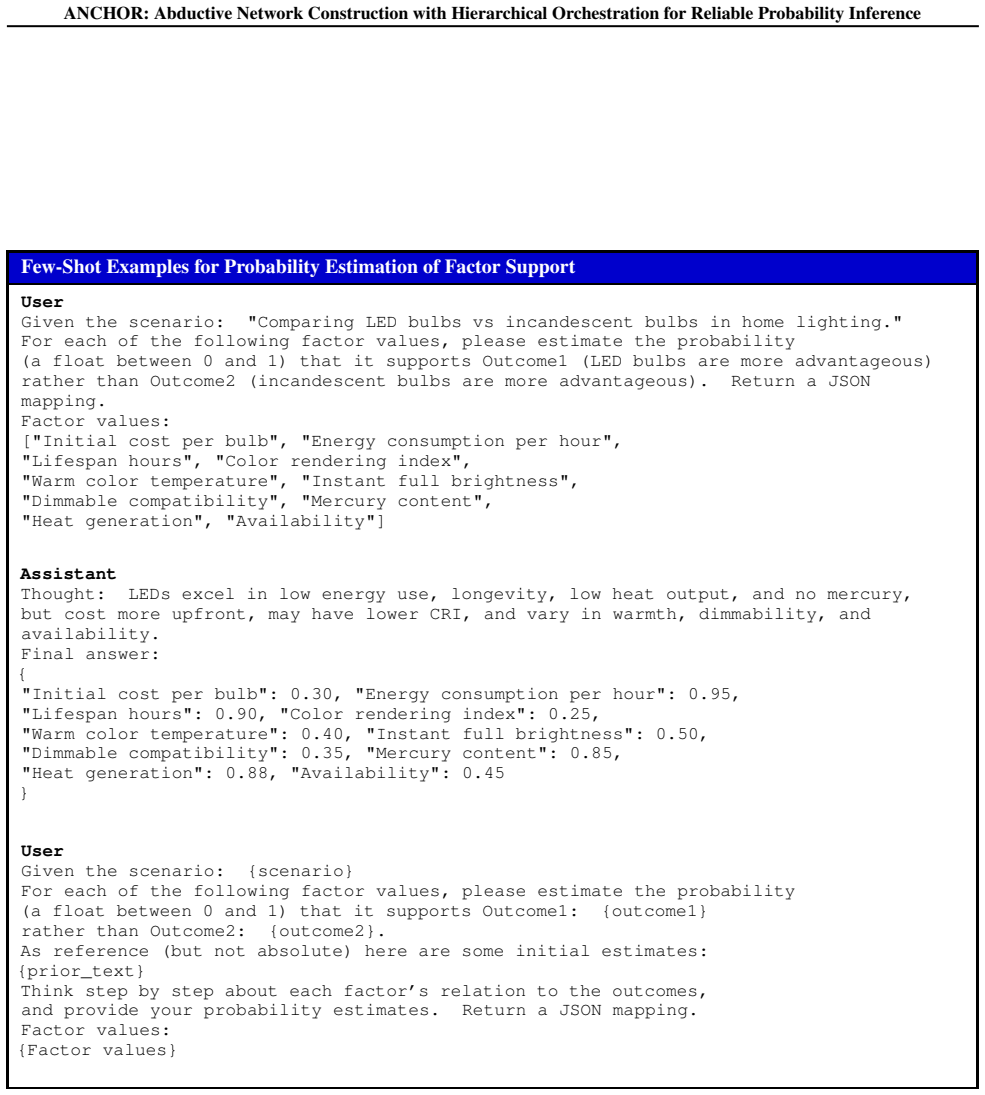
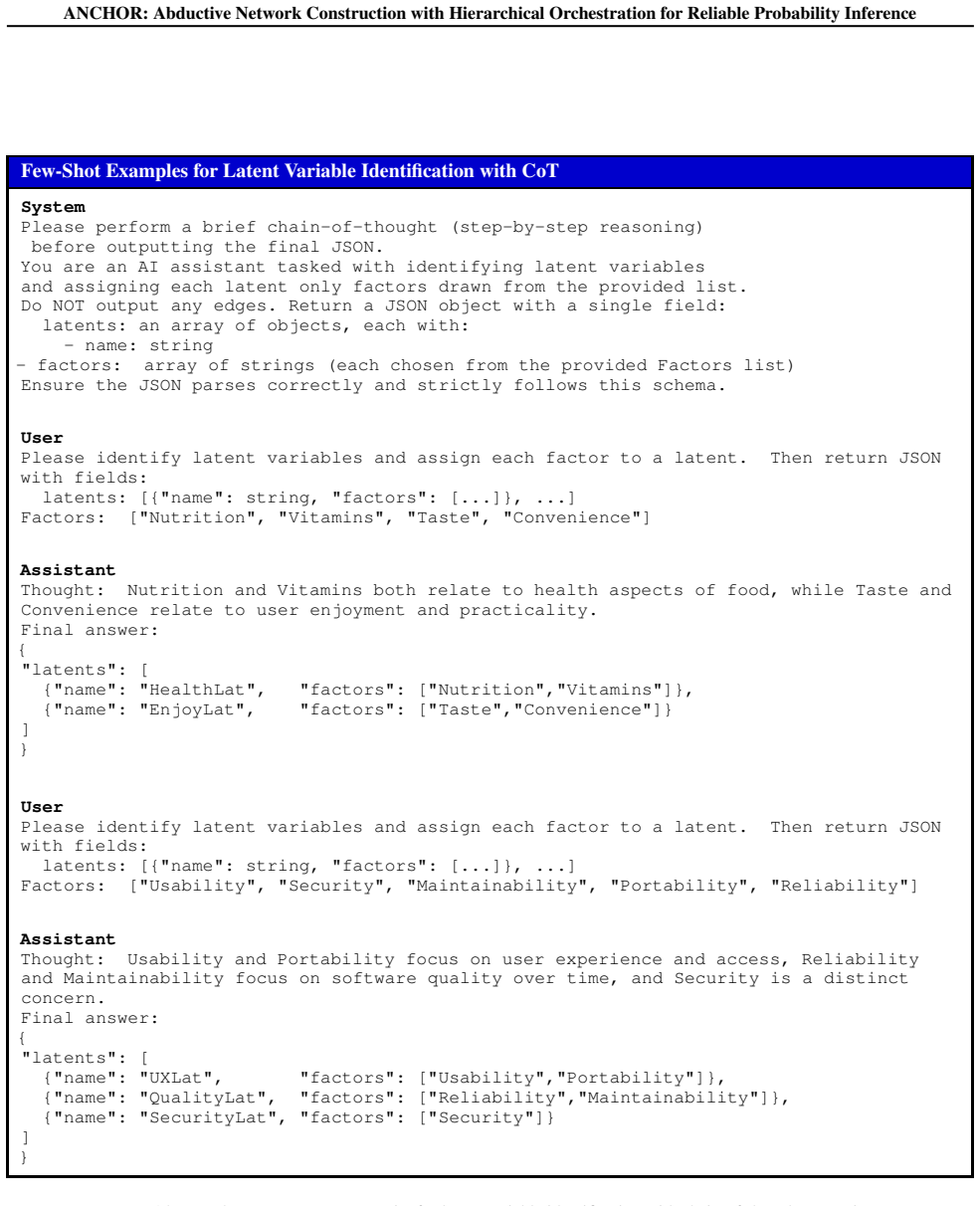
ANCHOR is an aggregated Bayesian inference framework over a hierarchical factor space that constructs dense factor hierarchies through iterative generation and clustering, maps contexts via hierarchical retrieval and refinement, and augments Naive Bayes with a Causal Bayesian Network to model latent factor dependencies, thereby reducing unknown predictions and improving the reliability of probability estimates.
What carries the argument
Hierarchical factor space with iterative generation and clustering, augmented by a Causal Bayesian Network over a Naive Bayes base.
If this is right
- The rate of unknown predictions drops compared with direct LLM baselines.
- Probability estimates become more reliable than those from standard Naive Bayes over factor combinations.
- The method reaches state-of-the-art performance on the evaluated tasks.
- Time and token usage fall substantially relative to direct LLM querying.
Where Pith is reading between the lines
- The same hierarchical construction could be tested on uncertainty tasks outside probability estimation, such as ranking or recommendation under partial information.
- Explicit causal modeling between generated factors may prove useful in other LLM pipelines that currently rely on independence assumptions.
- If the hierarchy depth can be tuned automatically, the framework might scale to domains with far larger numbers of latent variables.
- The reduction in unknown cases suggests the method could support real-time decision systems that previously fell back to human review too often.
Load-bearing premise
Iterative generation and clustering of factors plus the Causal Bayesian Network will capture genuine latent dependencies without adding new spurious correlations or biases.
What would settle it
Run both ANCHOR and direct LLM baselines on a test set with known ground-truth probabilities and measure the difference in calibration error plus the count of unknown outputs.
Figures




















read the original abstract
A central challenge in large-scale decision-making under incomplete information is estimating reliable probabilities. Recent approaches use Large Language Models (LLMs) to generate explanatory factors and coarse-grained probability estimates, which are then refined by a Na\"ive Bayes model over factor combinations. However, sparse factor spaces often yield ``unknown'' predictions, while expanding factors increases noise and spurious correlations, weakening conditional independence and degrading reliability. To address these limitations, we propose \textsc{Anchor}, an aggregated Bayesian inference framework over a hierarchical factor space. It constructs dense factor hierarchies through iterative generation and clustering, maps contexts via hierarchical retrieval and refinement, and augments Na\"ive Bayes with a Causal Bayesian Network to model latent factor dependencies. Experiments show that \textsc{Anchor} markedly reduces ``unknown'' predictions and produces more reliable probability estimates than direct LLM baselines, achieving state-of-the-art performance while significantly reducing time and token overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ANCHOR, an aggregated Bayesian inference framework for reliable probability estimation in LLMs under incomplete information. It constructs dense hierarchical factor spaces via iterative generation and clustering of factors, performs hierarchical retrieval and refinement for context mapping, and augments a Naive Bayes model with a Causal Bayesian Network to capture latent factor dependencies, addressing sparsity-induced 'unknown' predictions and violations of conditional independence. The abstract claims that experiments demonstrate marked reductions in 'unknown' predictions, more reliable probability estimates than direct LLM baselines, state-of-the-art performance, and significantly lower time and token overhead.
Significance. If validated, the hierarchical orchestration and CBN augmentation could meaningfully improve the reliability of LLM-driven probabilistic inference by mitigating sparse factor spaces and spurious correlations, with potential value for decision-making applications. The approach builds on standard Bayesian components in a structured way, but the manuscript text supplies no quantitative results, baselines, or validation details, preventing any assessment of whether these benefits are realized.
major comments (1)
- [Abstract] Abstract: the assertion that 'Experiments show that ANCHOR markedly reduces "unknown" predictions and produces more reliable probability estimates than direct LLM baselines, achieving state-of-the-art performance while significantly reducing time and token overhead' supplies no data, baselines, error analysis, tables, or validation details; the central empirical claims cannot be evaluated from the given text.
Simulated Author's Rebuttal
We thank the referee for their review and for highlighting the need for empirical substantiation of the abstract claims. We address the comment point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'Experiments show that ANCHOR markedly reduces "unknown" predictions and produces more reliable probability estimates than direct LLM baselines, achieving state-of-the-art performance while significantly reducing time and token overhead' supplies no data, baselines, error analysis, tables, or validation details; the central empirical claims cannot be evaluated from the given text.
Authors: We agree that the abstract makes strong empirical claims that require supporting quantitative evidence, baselines, and analysis to be evaluable. The current manuscript version emphasizes the methodological contributions (hierarchical factor construction, retrieval, and CBN augmentation) but does not include the experimental results, tables, or validation details referenced in the abstract. This is a clear gap. We will revise the manuscript by adding a dedicated Experiments section with the quantitative results, baseline comparisons (including direct LLM and prior Naive Bayes approaches), error analysis on 'unknown' predictions, and overhead measurements to substantiate the claims. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description contain no equations, derivations, fitted parameters presented as predictions, or self-citations. The framework is described at a high level using standard components (Naive Bayes, Causal Bayesian Network, clustering) without any load-bearing step that reduces to its own inputs by construction. No specific reduction (e.g., Eq. X = Eq. Y) can be quoted or exhibited. This is the most common honest finding for papers whose central claims rest on empirical framework description rather than closed-form derivation.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 5 Pith papers
-
DimMem: Dimensional Structuring for Efficient Long-Term Agent Memory
DimMem introduces a dimensional memory framework that structures memories as typed atomic units to improve retrieval efficiency and accuracy for long-term LLM agent tasks.
-
MedSynapse-V: Bridging Visual Perception and Clinical Intuition via Latent Memory Evolution
MedSynapse-V evolves latent diagnostic memories via meta queries, causal counterfactual refinement with RL, and dual-branch memory transition to outperform prior medical VLM methods in diagnostic accuracy.
-
MedSynapse-V: Bridging Visual Perception and Clinical Intuition via Latent Memory Evolution
MedSynapse-V proposes meta-query prior memorization, causal counterfactual refinement via RL, and dual-branch memory transition to evolve implicit diagnostic memories in medical VLMs and boost accuracy over chain-of-t...
-
DimMem: Dimensional Structuring for Efficient Long-Term Agent Memory
DimMem introduces typed dimensional memory units that improve accuracy to 81.43% and 78.20% on two long-term agent benchmarks while cutting token cost by 24% and enabling small models to match larger extractors.
-
MedSynapse-V: Bridging Visual Perception and Clinical Intuition via Latent Memory Evolution
MedSynapse-V proposes a latent diagnostic memory evolution framework using Meta Query, Causal Counterfactual Refinement, and Intrinsic Memory Transition to improve medical VLM diagnostic accuracy over chain-of-thought...
Reference graph
Works this paper leans on
-
[1]
URL https: //doi.org/10.1145/3677389.3702605
doi: 10.1145/3677389.3702605. URL https: //doi.org/10.1145/3677389.3702605. Babakov, N., Reiter, E., and Bugarín-Diz, A. Scalabil- ity of Bayesian network structure elicitation with large language models: a novel methodology and compara- tive analysis. In Rambow, O., Wanner, L., Apidianaki, M., Al-Khalifa, H., Eugenio, B. D., and Schockaert, S. (eds.),Pro...
-
[2]
doi: 10.1109/ICCV51070.2023.01398. Edge, D., Trinh, H., Cheng, N., Bradley, J., Chao, A., Mody, A., Truitt, S., and Larson, J. From local to global: A graph RAG approach to query-focused summarization. CoRR, abs/2404.16130, 2024. doi: 10.48550/ARXIV . 2404.16130. Feng, Y ., Zhou, B., Wang, H., Jin, H., and Roth, D. Generic temporal reasoning with differen...
-
[3]
Feng, Y ., Zhou, B., Lin, W., and Roth, D
doi: 10.18653/V1/2023.ACL-LONG.671. Feng, Y ., Zhou, B., Lin, W., and Roth, D. Bird: A trust- worthy bayesian inference framework for large language models. InProceedings of the International Conference on Learning Representations (ICLR), 2025. Fragoso, T., Bertoli, W., and Louzada, F. Bayesian model averaging: A systematic review and conceptual classific...
-
[4]
findings-emnlp.321/
URL https://aclanthology.org/2025. findings-emnlp.321/. Jayaweera, C., Youm, S., and Dorr, B. J. AMREx: AMR for explainable fact verification. In Schlichtkrull, M., Chen, Y ., Whitehouse, C., Deng, Z., Akhtar, M., Aly, R., Guo, Z., Christodoulopoulos, C., Cocarascu, O., Mittal, 10 ANCHOR: Abductive Network Construction with Hierarchical Orchestration for ...
2025
-
[5]
doi: 10.18653/v1/2024.fever-1.26
Association for Computational Linguistics. doi: 10.18653/v1/2024.fever-1.26. Ji, Z., Yu, T., Xu, Y ., Lee, N., Ishii, E., and Fung, P. To- wards mitigating LLM hallucination via self reflection. In Bouamor, H., Pino, J., and Bali, K. (eds.),Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, December 6-10, 2023, pp. 1827–1843...
-
[6]
arXiv preprint arXiv:2508.02085 , year=
URL https://aclanthology.org/2025. findings-acl.1123/. Lin, B. Y ., Fu, Y ., Yang, K., Brahman, F., Huang, S., Bha- gavatula, C., Ammanabrolu, P., Choi, Y ., and Ren, X. Swiftsage: A generative agent with fast and slow think- ing for complex interactive tasks. In Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., and Levine, S. (eds.),Advances in ...
-
[7]
Association for Computational Linguistics. ISBN 979-8-89176-251-0. doi: 10.18653/v1/2025.acl-long
-
[8]
GCoT-Decoding: Unlocking Deep Reasoning Paths for Universal Question Answering
URL https://aclanthology.org/2025. acl-long.536/. Luo, G., Qiu, W., Jian, Z., Wang, M., and Wu, Q. Gcot- decoding: Unlocking deep reasoning paths for universal question answering, 2026a. URL https://arxiv. org/abs/2604.06794. Luo, G., Qiu, W., Zhao, W., Lv, W., Jian, Z., Wang, M., and Wu, Q. Agsc: Adaptive granularity and semantic clustering for uncertain...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.naacl-long.167 2025
-
[10]
doi: https://doi.org/10.1016/j.ijcce.2024.11
-
[11]
Prabha, D., Aswini, J., Maheswari, B., Subramanian, R
URL https://www.sciencedirect.com/ science/article/pii/S2666307424000482. Prabha, D., Aswini, J., Maheswari, B., Subramanian, R. S., Nithyanandhan, R., and Girija, P. A survey on alleviat- ing the naive bayes conditional independence assumption. In2022 International Conference on Augmented Intelli- gence and Sustainable Systems (ICAISS), pp. 654–657. IEEE...
-
[12]
2504.08266,arXiv:2504.08266,doi:10.48550/ARXIV.2504.08266
doi: 10.48550/ARXIV .2503.17523. URL https: //doi.org/10.48550/arXiv.2503.17523. Renze, M. and Guven, E. Self-reflection in large language model agents: Effects on problem-solving performance. In2024 2nd International Conference on Foundation and Large Language Models (FLLM), pp. 516–525, 2024. doi: 10.1109/FLLM63129.2024.10852426. Reuter, A., Rudner, T. ...
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[13]
Can LLMs Express Their Uncertainty? An Empirical Evaluation of Confidence Elicitation in LLMs
URL https://aclanthology.org/2022. emnlp-main.134/. Tang, L., Laban, P., and Durrett, G. MiniCheck: Efficient fact-checking of LLMs on grounding documents. pp. 8818–8847, November 2024. doi: 10.18653/v1/2024. emnlp-main.499. URL https://aclanthology. org/2024.emnlp-main.499/. Wang, W., Wei, F., Dong, L., Bao, H., Yang, N., and Zhou, M. Minilm: deep self-a...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024 2022
-
[14]
Curran Associates Inc. Zaidi, N. A., Cerquides, J., Carman, M. J., and Webb, G. I. Alleviating naive bayes attribute independence assumption by attribute weighting.J. Mach. Learn. Res., 14(1):1947–1988, 2013. doi: 10.5555/2567709. 2567725. URL https://dl.acm.org/doi/10. 5555/2567709.2567725. Zhang, H. The optimality of naive bayes. pp. 562–567,
-
[15]
URL http://www.aaai.org/Library/ FLAIRS/2004/flairs04-097.php. Zhang, N. L. and Poole, D. A simple approach to bayesian network computations. InProceedings of the biennial conference-Canadian society for computational studies of intelligence, pp. 171–178. CANADIAN INFORMATION PROCESSING SOCIETY , 1994. Zhang, X., Wang, M., Yang, X., Wang, D., Feng, S., an...
-
[16]
URL https://aclanthology.org/2023. emnlp-main.858/. Zhao, H., Chen, H., Yang, F., Liu, N., Deng, H., Cai, H., Wang, S., Yin, D., and Du, M. Explainability for large language models: A survey.ACM Trans. Intell. Syst. Technol., 15(2), February 2024. ISSN 2157-6904. doi: 10.1145/3639372. Zhou, D., Schärli, N., Hou, L., Wei, J., Scales, N., Wang, X., Schuurma...
-
[17]
Treadmill training allows Alice to maintain a consistent pace and monitor heart rate, boosting her aerobic capacity
-
[18]
User Scenario: Bob studies every evening
The treadmill’s adjustable incline simulates hill workouts, increasing leg strength and stamina. User Scenario: Bob studies every evening. Outcome: Studying in short, focused bursts enhances retention. Opposite Outcome: Studying in short, focused bursts does not enhance retention. Generate 2 sentences. Assistant
-
[19]
Brief study sessions with breaks prevent mental fatigue and improve long-term recall
-
[20]
Frequent reviews in small intervals reinforce memory pathways, aiding retention. Figure 7.Example Prompt for Generating Supporting or Refuting Sentences 29 ANCHOR: Abductive Network Construction with Hierarchical Orchestration for Reliable Probability Inference Few-Shot Examples for Factor Extraction System Extract distinct factors from these sentences. T...
-
[21]
Treadmill training allows maintaining a consistent pace and monitoring heart rate, boosting aerobic capacity
-
[22]
Pace consistency
The treadmill’s adjustable incline simulates hill workouts, increasing leg strength and stamina. Assistant Let me analyze these sentences to identify the key factors: • Pace consistency (ability to maintain steady speed) • Heart rate monitoring (tracking cardiovascular response) • Adjustable incline (variable difficulty/terrain simulation) • Leg strength ...
-
[23]
Group work requires coordination between team members
-
[24]
Coordination requirements
Individual tasks allow for personal control and efficiency. Assistant Let me identify the key factors from these sentences: • Coordination requirements (need for team synchronization) • Personal control (individual autonomy) • Efficiency (productivity/effectiveness) • Team collaboration (working together) Final answer: ["Coordination requirements","Person...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.