Beyond Text Prompts: Visual-to-Visual Generation as A Unified Paradigm
Pith reviewed 2026-05-13 05:56 UTC · model grok-4.3
The pith
Visual specification pages replace text prompts in frozen generators without any retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
V2V-Zero is a training-free framework that conditions existing VLM-based generators by replacing text-only inputs with final-layer hidden states extracted from visual specification pages, exploiting the fact that the frozen VLM already projects both modalities into the generator's conditioning space.
What carries the argument
V2V-Zero framework that substitutes text conditioning with final-layer hidden states from visual pages in VLM-conditioned generators.
If this is right
- Existing commercial and open-weight generators can accept visual conditioning through the same interface without architectural modification.
- Attribute binding succeeds reliably while structural alignment and novel content synthesis remain weak points even in closed models.
- The same conditioning swap extends directly to video generators and yields measurable though lower performance.
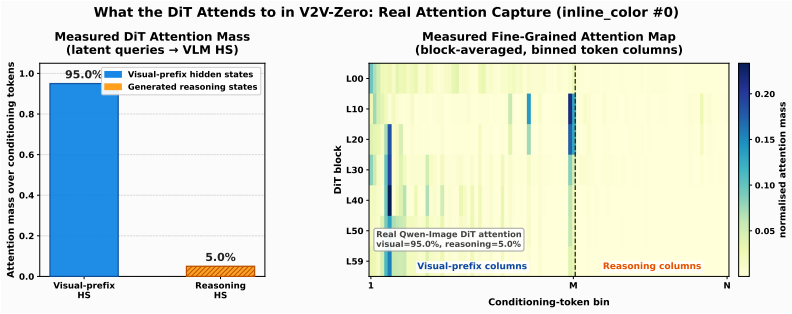
- Conditioning-token attention concentrates 95 percent on the visual-page states, indicating the default reasoning path is visually routed.
Where Pith is reading between the lines
- Users could shift from prompt engineering to creating and editing visual reference documents as the primary creative interface.
- The observed hierarchy of task difficulty points to specific places where future models would need stronger visual-semantic integration.
- If the mapping property holds across more VLMs, visual-to-visual may become the default conditioning mode rather than a special case.
Load-bearing premise
The frozen VLM already maps both text and visual pages into the generator's conditioning space so that the visual hidden states can stand in for text without any fine-tuning.
What would settle it
An experiment that swaps the visual-page hidden states for random vectors while keeping every other model component fixed and measures whether GenEval and Simple-V2V Bench scores collapse toward zero.
Figures










read the original abstract
Humans often specify and create through visual artifacts: typography sheets, sketches, reference images, and annotated scenes. Yet modern visual generators still ask users to serialize this intent into text, a bottleneck that compresses signals like spatial structure, exact appearance, and glyph shape. We propose \textbf{\emph{visual-to-visual} (V2V)} generation, in which the user conditions a generative model with a visual specification page rather than a text prompt. The page is not an edit target, but a visual document that specifies the desired output. We introduce \textbf{V2V-Zero}, a training-free framework that exposes this interface in existing vision-language model (VLM) conditioned generators by replacing text-only conditioning with final-layer hidden states extracted from visual pages, exploiting the fact that the frozen VLM already maps both text and images into the generator's conditioning space. On GenEval, V2V-Zero reaches 0.85 with a frozen Qwen-Image backbone, closely matching its optimized text-to-image performance without fine-tuning. To evaluate the broader V2V space, we introduce \textbf{Simple-V2V Bench}, spanning seven visual-conditioning tasks and seven models, including GPT Image 2, Nano Banana 2, Seedream 5.0 Lite, open-weight baselines, and a video extension. V2V-Zero scores 32.7/100, outperforming evaluated open-weight image baselines and revealing a clear capability hierarchy: attribute binding is strong, content generation is unreliable, and structural control remains hard even for commercial systems. A HunyuanVideo-1.5 extension scores 20.2/100, showing the interface transfers beyond images. Mechanistic analysis shows the default reasoning path is primarily visually routed, with 95.0\% of conditioning-token attention mass on visual-page hidden states.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes visual-to-visual (V2V) generation as an alternative to text prompting, where a visual specification page (sketches, glyphs, annotations) conditions a generative model. It introduces the training-free V2V-Zero framework that extracts final-layer hidden states from a frozen VLM processing the visual page and substitutes them for text conditioning tokens, exploiting the claim that the VLM already maps both modalities into the generator's conditioning space. On GenEval, V2V-Zero achieves 0.85 with a frozen Qwen-Image backbone, matching its text-to-image performance; a new Simple-V2V Bench yields 32.7/100 across seven tasks and models (with a HunyuanVideo extension at 20.2/100), and mechanistic analysis reports 95% attention mass on visual states.
Significance. If the core substitution holds, the work offers a practical route to richer conditioning interfaces that preserve spatial and structural signals lost in text serialization, with the training-free property and video transfer as clear strengths. The competitive GenEval number and attention analysis provide initial support, but the absence of error bars, distribution-shift tests, and detailed ablations limits the strength of the evidence for broad adoption.
major comments (2)
- [Abstract] Abstract: The central claim that final-layer VLM hidden states from visual pages occupy the same conditioning manifold as text tokens (allowing direct substitution without fine-tuning or architectural changes) is load-bearing yet unverified; no direct comparison of state distributions, positional encoding effects, or out-of-distribution visual-page tests is reported to rule out systematic shifts that GenEval may tolerate but other tasks would not.
- [Abstract] GenEval results: The reported 0.85 score is presented as closely matching optimized text-to-image performance, but lacks error bars, variance across runs, or explicit controls for visual-page composition (e.g., sketch vs. annotated scene), making it impossible to assess whether the match is robust or coincidental.
minor comments (1)
- [Abstract] Abstract: The description of Simple-V2V Bench mentions seven tasks and seven models but provides no definition of the scoring scale (out of 100) or task breakdown, which would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will incorporate revisions to strengthen the empirical support for the core substitution claim and the reported results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that final-layer VLM hidden states from visual pages occupy the same conditioning manifold as text tokens (allowing direct substitution without fine-tuning or architectural changes) is load-bearing yet unverified; no direct comparison of state distributions, positional encoding effects, or out-of-distribution visual-page tests is reported to rule out systematic shifts that GenEval may tolerate but other tasks would not.
Authors: We agree that direct verification of manifold alignment (e.g., via distribution comparisons or positional encoding analysis) is absent from the current manuscript and would strengthen the load-bearing claim. The 95% attention mass and GenEval parity provide indirect support, but we will add a dedicated analysis section in the revision that includes cosine similarity between text and visual hidden states on held-out sets, positional encoding ablation, and out-of-distribution visual-page tests to rule out systematic shifts. revision: yes
-
Referee: [Abstract] GenEval results: The reported 0.85 score is presented as closely matching optimized text-to-image performance, but lacks error bars, variance across runs, or explicit controls for visual-page composition (e.g., sketch vs. annotated scene), making it impossible to assess whether the match is robust or coincidental.
Authors: We concur that error bars, run variance, and explicit controls for visual-page composition are needed to demonstrate robustness. In the revised manuscript we will report standard deviations over multiple random seeds, provide per-composition breakdowns (sketch vs. glyph vs. annotated scene), and detail the exact visual-page generation protocol used for the GenEval evaluation. revision: yes
Circularity Check
No significant circularity: V2V-Zero is training-free and exploits pre-existing frozen VLM properties without reducing results to self-defined fits or citations
full rationale
The paper introduces V2V-Zero as a zero-shot substitution of final-layer VLM hidden states from visual pages for text conditioning tokens, explicitly relying on the pre-trained mapping properties of existing frozen models rather than any derivation, parameter fitting, or self-referential construction. Reported metrics such as 0.85 on GenEval and 32.7/100 on Simple-V2V Bench are obtained through direct empirical evaluation on external benchmarks with no equations or steps that redefine outcomes in terms of the paper's own inputs. No self-citations serve as load-bearing uniqueness theorems, no ansatzes are smuggled, and no predictions reduce by construction to fitted quantities. The approach is self-contained against external model properties and benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The frozen VLM already maps both text and images into the generator's conditioning space so that final-layer hidden states from visual pages can replace text conditioning without any fine-tuning or architectural changes.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.