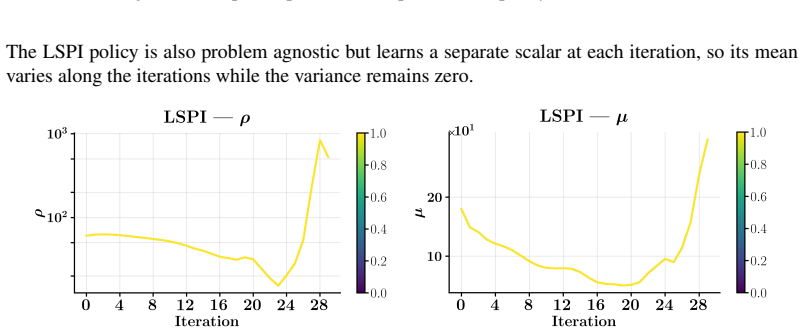
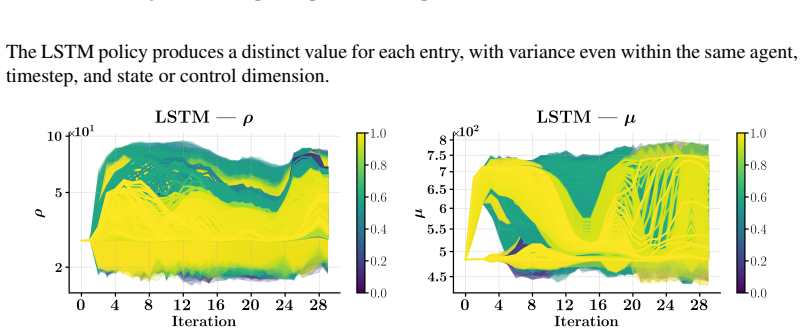
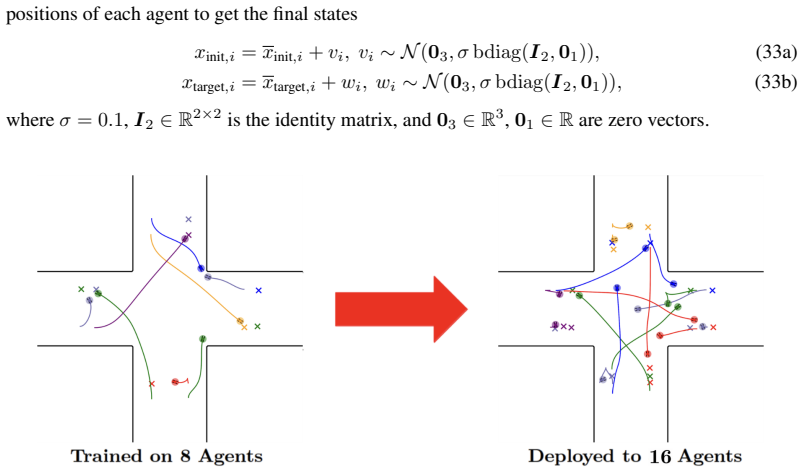
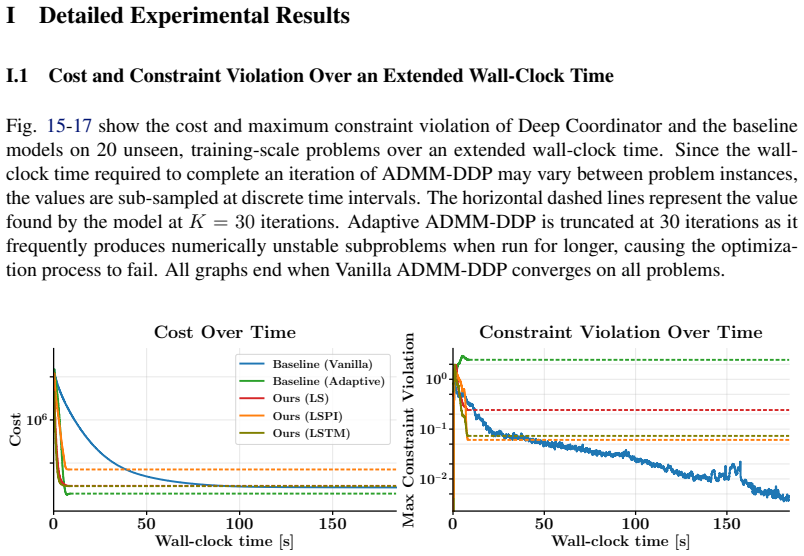
Deep-Unfolded Coordination
Pith reviewed 2026-06-26 17:03 UTC · model grok-4.3
The pith
A deep-unfolded network learns to adjust ADMM-DDP penalty parameters at solve time for faster multi-agent robotics optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
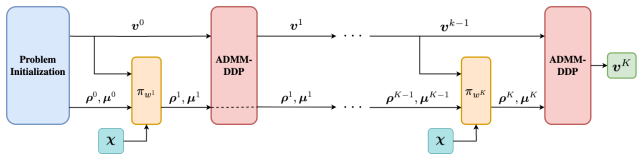
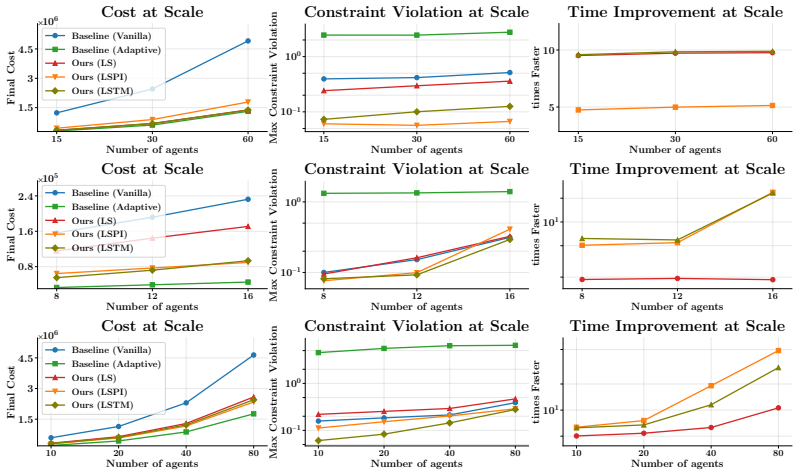
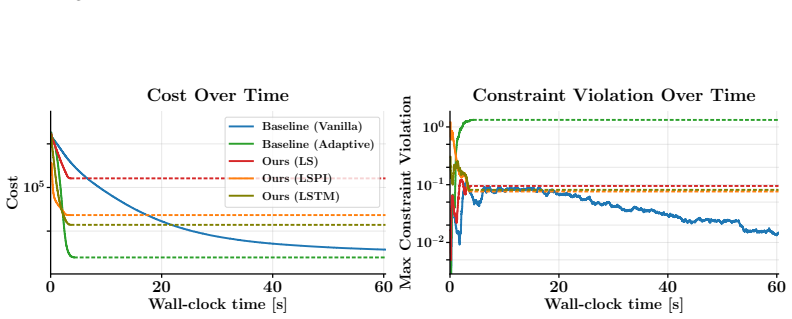
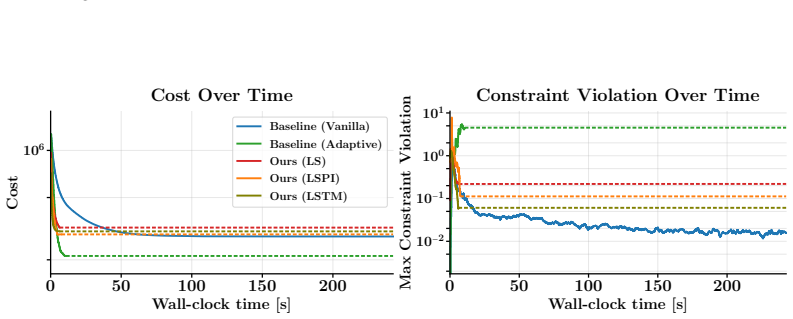
Deep Coordinator is the first deep-unfolding framework to adapt the penalty parameters of a non-convex optimizer at solve-time by unrolling ADMM-DDP iterations into a network with learnable functions between layers that map optimizer state to next hyperparameters, trained via an unsupervised scheme to avoid degenerates, resulting in comparable quality trajectories at 6.18-9.44x the speed of conventional solvers and retaining benefits on systems up to 8x larger.
What carries the argument
The unrolled ADMM-DDP network with learnable mappings from optimizer state to penalty parameters, trained unsupervised.
If this is right
- Produces trajectories of comparable quality 6.18-9.44x faster than conventional solvers
- Retains performance benefits when deployed to systems up to 8x larger than trained on
- Avoids degenerate solutions that arise under mainstream supervised training
- Enables dynamic adjustment of hyperparameters for non-convex ADMM-DDP at solve-time
Where Pith is reading between the lines
- The learned adaptation could extend to other distributed optimizers used in logistics or sensor networks.
- Real-time hardware deployment might gain further from the method in changing environments where fixed tuning fails.
- The unsupervised scheme could inspire similar training for other non-convex solvers where good labels are unavailable.
Load-bearing premise
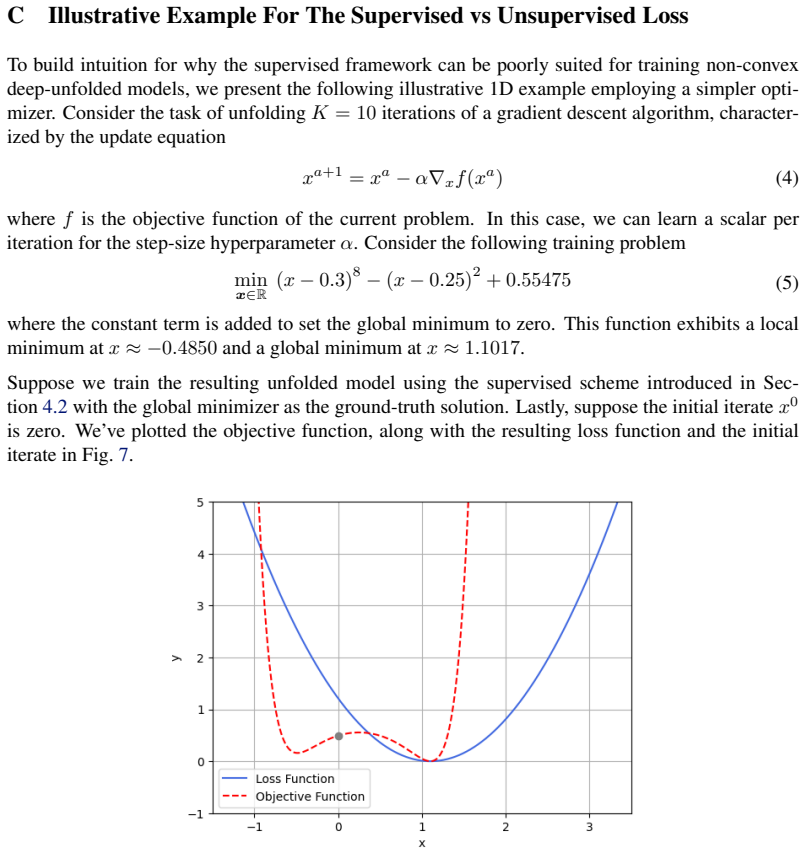
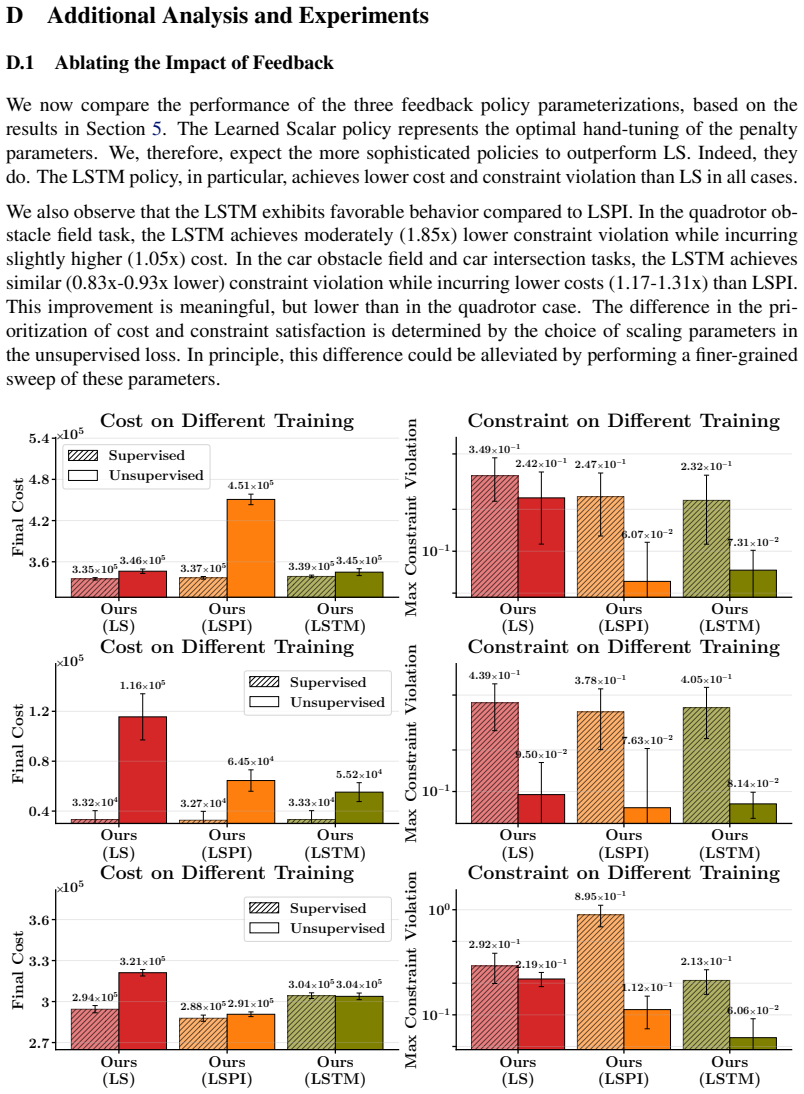
The unsupervised learning scheme successfully avoids the degenerate solutions that arise under mainstream supervised training.
What would settle it
Running the Deep Coordinator on a fleet of 16 quadrotors and checking whether solve times stay below one-sixth of the conventional solver while trajectory costs remain within 10 percent would test the scaling and speedup claims.
Figures



read the original abstract
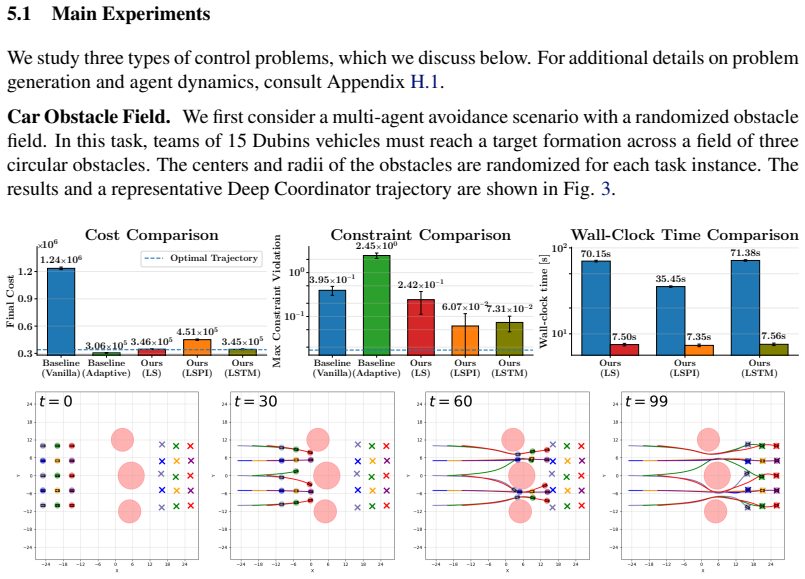
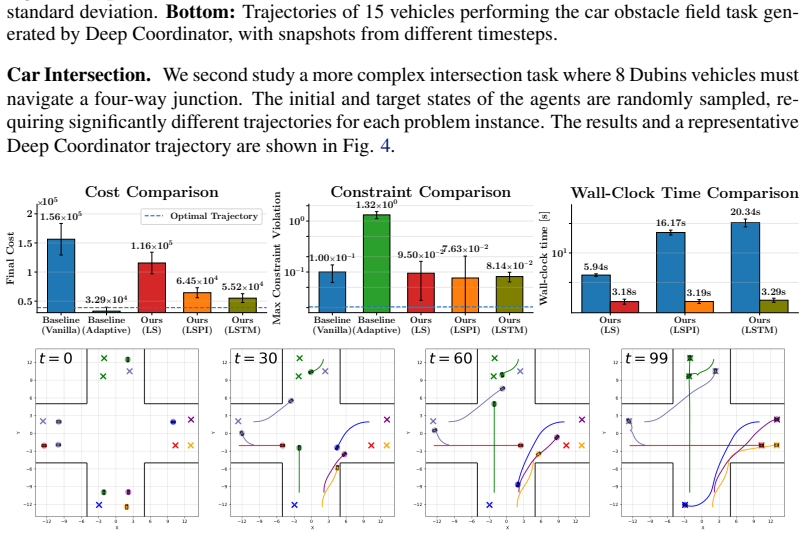
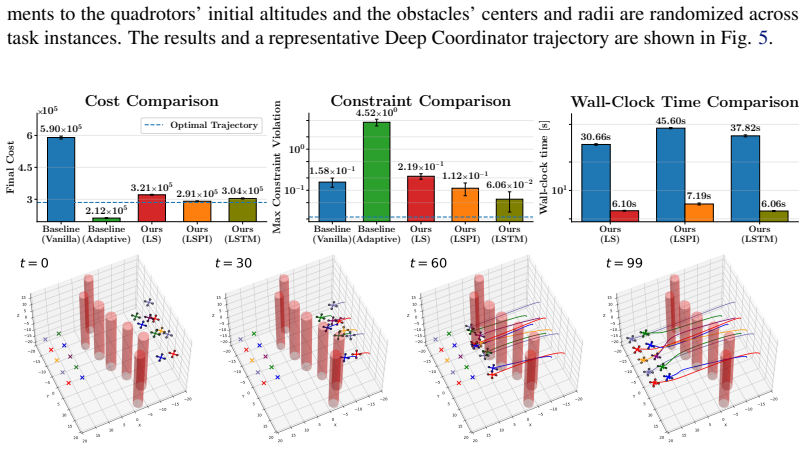
Distributed optimization is a highly scalable and structurally transparent technique to solve multi-agent robotics problems; however, such methods often suffer from the need for highly-specialized, problem-specific hyperparameter tunings. In this work, we propose Deep Coordinator, a deep-unfolding framework that learns to dynamically adjust the hyperparameters of ADMM-DDP, a popular distributed solver for robotics tasks, at solve-time in response to optimizer performance. Our architecture consists of unrolling a fixed number of ADMM-DDP iterations into a neural network with learnable functions between layers mapping the optimizer state to the next hyperparameters. To the best of our knowledge, Deep Coordinator is the first deep-unfolding framework to adapt the penalty parameters of a non-convex optimizer at solve-time; we show that the mainstream supervised approach can yield degenerate solutions when training such models, and propose an unsupervised learning scheme. On simulations with fleets of cars and quadrotors, Deep Coordinator produces trajectories of comparable quality 6.18-9.44x faster than conventional solvers. Furthermore, Deep Coordinator retains its performance benefits when deployed to systems up to 8x larger than trained on.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Deep Coordinator, a deep-unfolding architecture that unrolls a fixed number of ADMM-DDP iterations into a neural network whose layers contain learnable mappings from optimizer state to penalty parameters. It argues that supervised training of such mappings produces degenerates and therefore introduces an unsupervised objective; empirical results on car and quadrotor fleets claim 6.18-9.44× speed-ups at comparable trajectory quality together with retention of the benefit on instances up to 8× larger than the training distribution.
Significance. If the unsupervised objective demonstrably prevents collapse to trivial penalty schedules, the work would offer a practical route to automating hyper-parameter selection inside non-convex distributed solvers, thereby lowering the barrier to deploying ADMM-DDP on larger multi-agent robotics problems.
major comments (2)
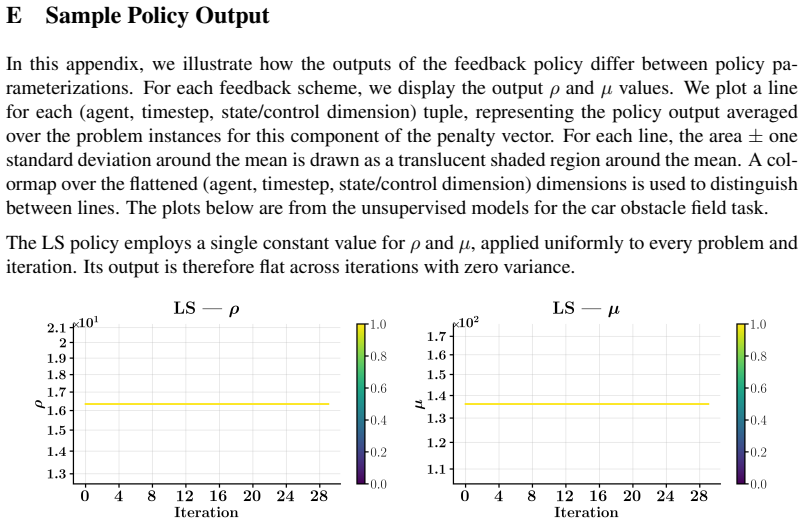
- [Abstract and §4] The central performance claims rest on the unsupervised scheme producing non-degenerate, state-dependent penalty schedules. No section, figure, or table in the manuscript provides direct evidence (e.g., variance of learned penalties across iterations, comparison of learned vs. constant schedules, or an ablation removing the unsupervised term) that the learned mappings avoid the collapse described in the abstract.
- [§4] Table 2 (or equivalent results table): the reported 6.18-9.44× speed-ups are presented without error bars or statistical tests; it is therefore impossible to determine whether the observed gains are distinguishable from the fixed-hyperparameter ADMM-DDP baseline once the unsupervised objective is removed.
minor comments (2)
- [§3] Notation for the state-to-penalty mapping functions is introduced without an explicit equation; a compact definition (e.g., Eq. (X)) would improve readability.
- [§4.3] The generalization experiments to 8× larger systems are described only qualitatively; a table listing training vs. test sizes and corresponding speed-up ratios would strengthen the claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for stronger empirical support of the unsupervised objective and statistical validation of the reported speed-ups. We address each point below.
read point-by-point responses
-
Referee: [Abstract and §4] The central performance claims rest on the unsupervised scheme producing non-degenerate, state-dependent penalty schedules. No section, figure, or table in the manuscript provides direct evidence (e.g., variance of learned penalties across iterations, comparison of learned vs. constant schedules, or an ablation removing the unsupervised term) that the learned mappings avoid the collapse described in the abstract.
Authors: We agree that the manuscript would benefit from explicit visualizations and ablations to directly demonstrate that the unsupervised objective yields non-degenerate, state-dependent schedules. While the text states that supervised training produces degenerates and motivates the unsupervised scheme, we did not include the requested figures or ablation. In revision we will add (i) a plot of learned penalty variance across iterations and states, (ii) a comparison against constant-penalty baselines, and (iii) an ablation removing the unsupervised term, all placed in §4. revision: yes
-
Referee: [§4] Table 2 (or equivalent results table): the reported 6.18-9.44× speed-ups are presented without error bars or statistical tests; it is therefore impossible to determine whether the observed gains are distinguishable from the fixed-hyperparameter ADMM-DDP baseline once the unsupervised objective is removed.
Authors: The speed-up numbers are averages computed over repeated simulation trials, yet we acknowledge the absence of error bars and formal statistical tests. We will revise Table 2 to report standard deviations and include paired t-test p-values comparing Deep Coordinator against the fixed-hyperparameter baseline, thereby clarifying whether the gains remain significant when the unsupervised term is considered. revision: yes
Circularity Check
No circularity: empirical speedups and generalization are measured against external baselines, not defined by the training scheme itself.
full rationale
The paper's central claims are performance measurements (6.18-9.44x faster trajectories of comparable quality, retained on 8x larger systems) obtained by running the trained Deep Coordinator against conventional ADMM-DDP solvers on car and quadrotor fleets. The unsupervised objective is introduced to avoid degenerate mappings noted under supervised training, but the reported results are obtained by direct comparison on held-out simulation instances and do not reduce to quantities defined inside the same equations or by self-citation. No load-bearing step equates a prediction to a fitted input by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural network weights for state-to-hyperparameter mappings
axioms (1)
- domain assumption ADMM-DDP iterations can be unrolled into a fixed-depth computational graph without losing essential solver behavior
Reference graph
Works this paper leans on
-
[1]
A. Ferraro, V . Nardi, E. D’Amato, I. Notaro, and V . Scordamaglia. Multi-drone systems for search and rescue operations: problems, technical solutions and open issues. In2023 IEEE International Workshop on Technologies for Defense and Security (TechDefense), pages 159– 164, 2023. doi:10.1109/TechDefense59795.2023.10380859
-
[2]
E. Tuci, M. H. M. Alkilabi, and O. Akanyeti. Cooperative object transport in multi-robot systems: A review of the state-of-the-art.Frontiers in Robotics and AI, 5, May 2018. ISSN 2296-9144. doi:10.3389/frobt.2018.00059. URLhttp://dx.doi.org/10.3389/frobt. 2018.00059
-
[3]
M. Hua, X. Qi, D. Chen, K. Jiang, Z. E. Liu, H. Sun, Q. Zhou, and H. Xu. Multi-agent reinforcement learning for connected and automated vehicles control: Recent advancements and future prospects.IEEE Transactions on Automation Science and Engineering, 22:16266– 16286, 2025. doi:10.1109/TASE.2025.3574280
- [4]
-
[5]
Y . Li, S. Zhang, J. Sun, Y . Du, Y . Wen, X. Wang, and W. Pan. Cooperative open-ended learning framework for zero-shot coordination, 2024. URLhttps://arxiv.org/abs/2302.04831
arXiv 2024
-
[6]
C. Sun, S. Huang, and D. Pompili. Llm-based multi-agent reinforcement learning: Current and future directions, 2024. URLhttps://arxiv.org/abs/2405.11106
arXiv 2024
-
[7]
A. D. Saravanos, Y . Aoyama, H. Zhu, and E. A. Theodorou. Distributed differential dynamic programming architectures for large-scale multiagent control.IEEE Transactions on Robotics, 39(6):4387–4407, Dec. 2023. doi:10.1109/TRO.2023.3319894. URLhttps://doi.org/ 10.1109/TRO.2023.3319894
-
[8]
S. Boyd, N. Parikh, E. Chu, B. Peleato, and J. Eckstein. Distributed optimization and statis- tical learning via the alternating direction method of multipliers.F oundations and Trends in Machine Learning, 3:1–122, Jan. 2011. doi:10.1561/2200000016
-
[9]
D. Mayne. A second-order gradient method for determining optimal trajectories of non- linear discrete-time systems.International Journal of Control, 3(1):85–95, Jan. 1966. ISSN 1366-5820. doi:10.1080/00207176608921369. URLhttp://dx.doi.org/10.1080/ 00207176608921369
-
[10]
V . Monga, Y . Li, and Y . Eldar. Algorithm unrolling: Interpretable, efficient deep learning for signal and image processing.IEEE Signal Processing Magazine, 38:18–44, 03 2021. doi: 10.1109/MSP.2020.3016905. 10
-
[11]
A. D. Saravanos, H. Kuperman, A. Oshin, A. T. Abdul, V . Pacelli, and E. Theodorou. Deep dis- tributed optimization for large-scale quadratic programming. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum? id=hzuumhfYSO
2025
-
[12]
Y . Noah and N. Shlezinger. Distributed Learn-to-Optimize: Limited Communications Op- timization Over Networks via Deep Unfolded Distributed ADMM.IEEE Transactions on Mobile Computing, 24(4):3012–3024, Apr. 2025. ISSN 2161-9875. doi:10.1109/tmc.2024. 3502574. URLhttp://dx.doi.org/10.1109/TMC.2024.3502574
-
[13]
D. Lupu and I. Necoara. Deep unfolding projected first order methods-based architectures: application to linear model predictive control. In2023 European Control Conference (ECC), page 1–6. IEEE, June 2023. doi:10.23919/ecc57647.2023.10178167. URLhttp://dx.doi. org/10.23919/ECC57647.2023.10178167
-
[14]
S. G. Krantz and H. R. Parks.The Implicit Function Theorem. Birkh ¨auser Boston, 2003. ISBN 9781461200598. doi:10.1007/978-1-4612-0059-8. URLhttp://dx.doi.org/10. 1007/978-1-4612-0059-8
-
[15]
H. Doerks, P. H ¨ausner, D. H. Escobar, and J. Sj ¨olund. Learning to accelerate distributed ADMM using graph neural networks.arXiv:2509.05288, 2025. URLhttps://arxiv.org/ abs/2509.05288
Pith/arXiv arXiv 2025
-
[16]
Stellato, G
B. Stellato, G. Banjac, P. Goulart, A. Bemporad, and S. Boyd. OSQP: An operator split- ting solver for quadratic programs.Mathematical Programming Computation, 12(4):637–672, 2020
2020
-
[17]
B. Wang, Y . Gao, T. Sun, and L. Zhao. Learning to Coordinate: Distributed Meta-Trajectory Optimization Via Differentiable ADMM-DDP.arXiv:2509.01630, 2025. URLhttps:// arxiv.org/abs/2509.01630
Pith/arXiv arXiv 2025
-
[18]
R. Sambharya and B. Stellato. Learning algorithm hyperparameters for fast parametric convex optimization.arXiv:2411.15717, 2024. URLhttps://arxiv.org/abs/2411.15717
arXiv 2024
-
[19]
A. G. Baydin, B. A. Pearlmutter, A. A. Radul, and J. M. Siskind. Automatic differentiation in machine learning: a survey.Journal of Machine Learning Research, 18(1):5595–5637, Jan
-
[20]
Hochreiter and J
S. Hochreiter and J. Schmidhuber. Long short-term memory.Neural Computation, 9(8):1735– 1780, 1997
1997
-
[21]
Oshin, H
A. Oshin, H. Almubarak, and E. A. Theodorou. Differentiable robust model predictive control. InProceedings of Robotics: Science and Systems, Delft, Netherlands, July 2024. doi:10.15607/ RSS.2024.XX.003
2024
-
[22]
W. Jin, Z. Wang, Z. Yang, and S. Mou. Pontryagin differentiable programming: an end-to- end learning and control framework. In34th International Conference on Neural Information Processing Systems, Dec. 2020. ISBN 9781713829546
2020
-
[23]
W. Jin, S. Mou, and G. J. Pappas. Safe Pontryagin differentiable programming.Advances in Neural Information Processing Systems, 34:16034–16050, 2021
2021
-
[24]
Sabatino
F. Sabatino. Quadrotor control: Modeling, nonlinear control design, and simulation. Master’s thesis, KTH Royal Institute of Technology, 2015
2015
-
[25]
I. Loshchilov and F. Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 11 A Detailed Description of the ADMM-DDP Subproblems In this appendix, we provide the mathematical breakdown of each subproblem of ADMM-DDP. Subproblem 1.For each agenti= 1, ..., N, we solve xa+1 i ,u a+1 i = argmin {xi,ui} T−1X t=0 ˆℓi,t(xi,t,u i,t)...
Pith/arXiv arXiv 2017
-
[26]
Independently adapt each element of the penalty vectorsρ a ∈R N×(T+1)×n x andµ a ∈ RN×T×n u, and
-
[27]
The second property not only increases the flexibility of the trained optimizer, but also allows models to be trained on smaller problems then deployed to much larger ones
Deploy to problems with longer time horizons and larger or different graph topologies underlying the agents than trained on The first property allows for policies that capture complex relationships between hyperparameters that would be impossible to represent with simpler schemes (e.g., re-scaling a fixed vector). The second property not only increases th...
-
[28]
Predict hyperparameters via θa =π wa(θa−1,v a−1,χ)(12)
-
[29]
Solve Subproblem 1 for dynamically-feasible trajectories via za = (xa,u a,y a) =DDP(s a),(13) wherey a are the Lagrange multipliers for the dynamics constraints ands a = (˜za−1,ζ a−1,θ a)collects all inputs to Subproblem 1 at iterationa
-
[30]
Solve Subproblem 2 for safe trajectories via ˜za = (˜xa, ˜ua, ˜ya) =NLP( ˜sa),(14) where ˜ya are the Lagrange multipliers for the safety constraints and ˜sa = (z a,ζ a−1,θ a) collects all inputs to Subproblem 2 at iterationa
-
[31]
Our goal is to compute the hypergradient∇ wLto train the feedback policies via gradient descent
Update dual variables via ζa =ζ a−1 +θ a ⊙((x a,u a)−( ˜xa, ˜ua)).(15) AfterKiterations, the final iteratev K = (z K, ˜zK,ζ K)is used to compute the task lossL(v K). Our goal is to compute the hypergradient∇ wLto train the feedback policies via gradient descent. Throughout the derivation, we use df dx to denote the total derivative, which includes both di...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.