Behind Python: The Languages That Power AI
Pith reviewed 2026-06-26 21:43 UTC · model grok-4.3
The pith
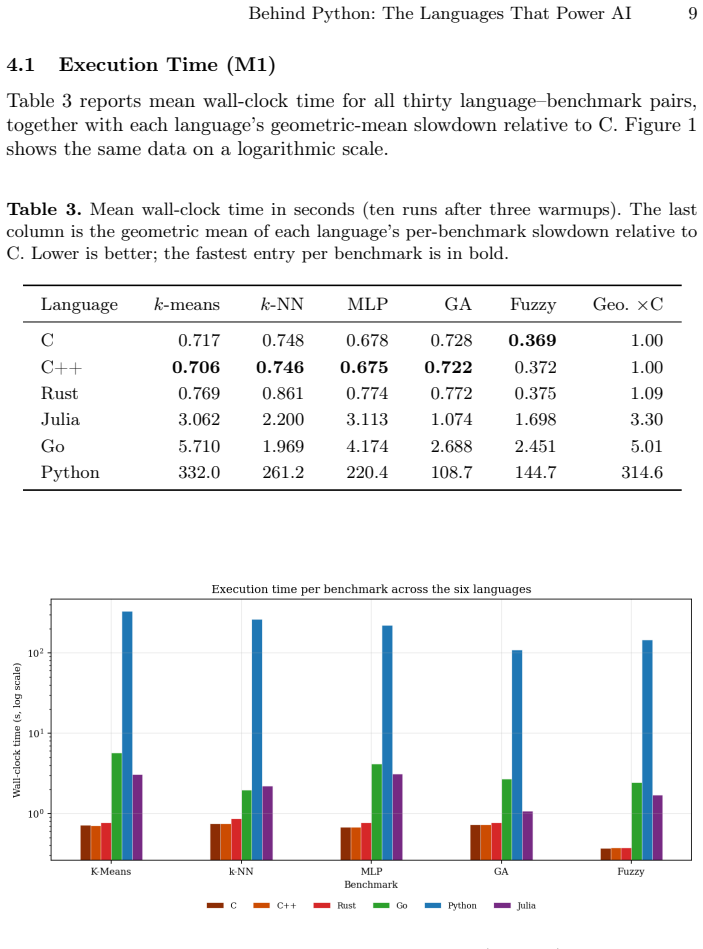
C and C++ tie as fastest for AI algorithms implemented from scratch, with Python 315 times slower.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
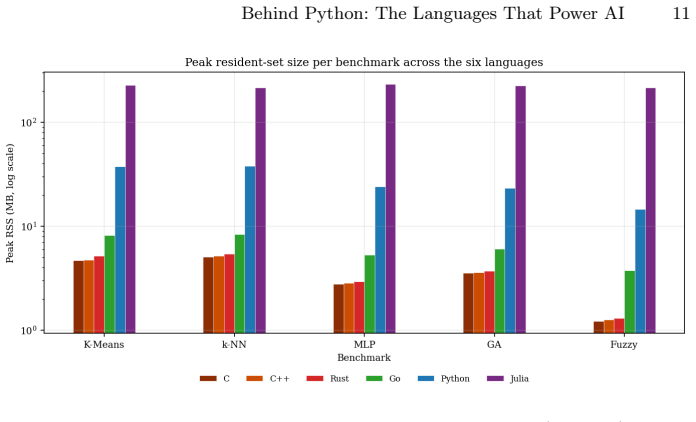
When the same five algorithms (k-means, k-NN, MLP backpropagation, genetic algorithm, Mamdani inference) are written in Python, C, C++, Rust, Go, and Julia with identical logic and outputs, C and C++ achieve essentially identical runtimes, Rust trails by nine percent geometric mean, Julia runs 3.3 times slower than C, Go runs 5.0 times slower, and Python runs 315 times slower; Julia's JIT imposes a fixed 224 MiB memory cost while the others stay under 6 MiB, and Go's slowdown ranges from 2.6 times to 8.0 times depending on the algorithm.
What carries the argument
The six parallel implementations of each algorithm that share a common pseudo-random generator and produce bit-identical results, isolating language-level performance differences.
If this is right
- C or C++ should be chosen when raw speed is the primary requirement for custom AI code.
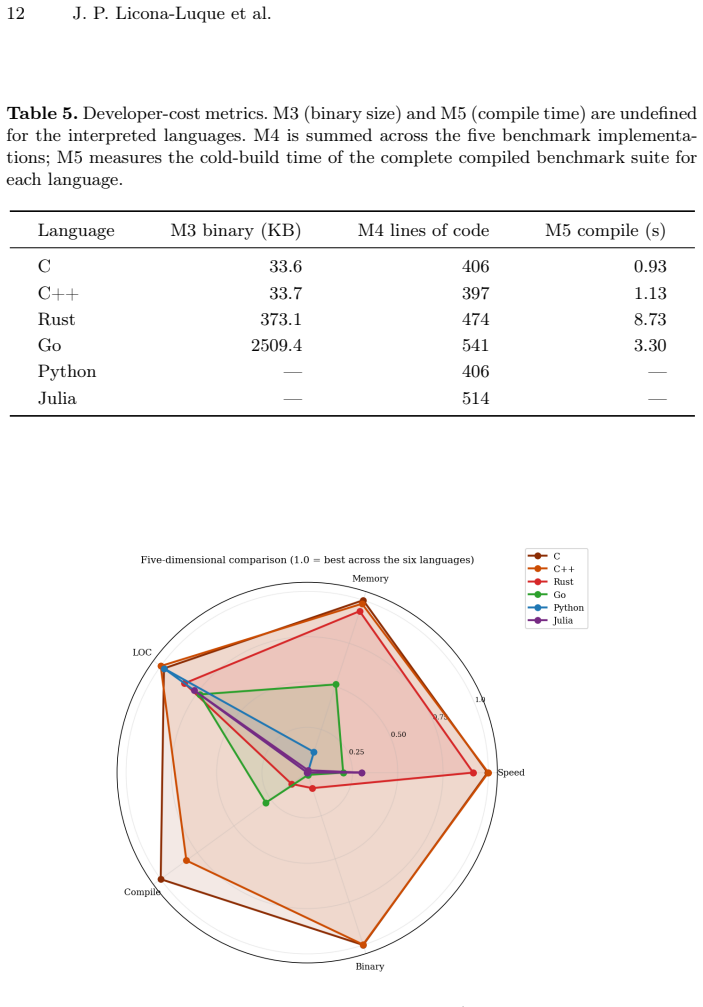
- Rust delivers near-C performance together with memory safety guarantees.
- Go's ranking can move an entire tier depending on the specific algorithm, requiring per-workload testing.
- Julia's fixed high memory footprint makes it unsuitable for memory-constrained targets even when its speed is acceptable.
- Python remains impractical for direct implementation of these algorithms when performance matters.
Where Pith is reading between the lines
- Developers facing mixed workloads may need to profile each component separately rather than rely on a single language ranking.
- The results suggest opportunities for language-specific backends under a common Python interface when both development speed and execution speed are required.
- Memory-constrained embedded AI systems would likely exclude Julia regardless of its speed tier.
Load-bearing premise
The six versions of each algorithm perform exactly the same computation, so any speed or memory difference is caused only by the language.
What would settle it
Any pair of implementations that produce non-identical outputs on the same inputs, or that contain logically inequivalent steps, would invalidate the claim that observed differences are due solely to language choice.
Figures
read the original abstract
Python dominates AI development, yet the numerical work behind frameworks like PyTorch and NumPy is executed in C, C++, or Rust. When a developer must implement an algorithm without such libraries -- because none exists, the target is resource-constrained, or a new system is being built -- which language should they choose? This paper answers that question empirically. Five algorithms covering data mining (k-means), machine learning (k-NN), neural networks (MLP with backpropagation), computational intelligence (genetic algorithm), and fuzzy systems (Mamdani inference) are implemented from scratch in Python, C, C++, Rust, Go, and Julia. All implementations share a common pseudo-random generator, consume identical inputs, and produce bit-identical outputs, so every measured difference reflects the language rather than the computation. Three performance tiers emerge: C and C++ are effectively tied; Rust trails them by 9% (geometric mean); Julia runs 3.3x slower than C and Go 5.0x; Python sits at 315x. Memory tells a different story -- Julia's JIT runtime carries a fixed ~224 MiB footprint regardless of workload, while C, C++, and Rust stay below 6 MiB. Crucially, rankings are not stable: Go's slowdown swings from 2.6x on k-NN to 8.0x on k-means, showing that workload characteristics can shift a language's position by a full tier. The results provide concrete, per-workload guidance for choosing an implementation language in AI systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical performance comparison of six languages (Python, C, C++, Rust, Go, Julia) on five algorithms from scratch: k-means, k-NN, MLP with backpropagation, genetic algorithm, and Mamdani inference. All implementations share a common PRNG, identical inputs, and produce bit-identical outputs, allowing attribution of measured differences to language rather than computation. Results identify three tiers (C/C++ tied; Rust 9% slower by geometric mean; Julia 3.3x, Go 5.0x, Python 315x slower than C), note Julia's fixed ~224 MiB memory footprint versus <6 MiB for C/C++/Rust, and observe that rankings are workload-dependent (e.g., Go varies from 2.6x to 8.0x slowdown).
Significance. If the implementation equivalence holds, the work supplies concrete, per-workload guidance for developers implementing AI algorithms without library support in resource-constrained or novel systems. The controlled design and observation of unstable rankings are strengths that distinguish this from typical language benchmarks.
major comments (1)
- [Abstract (and implied Methods)] The central claim rests on logical equivalence of the six implementations per algorithm beyond language-level differences. The abstract states shared PRNG, identical inputs, and bit-identical outputs, but without the full methods section or code artifacts it is not possible to verify how numerical stability, floating-point semantics, and data-structure choices were aligned across languages with differing default precisions and memory models.
minor comments (2)
- Table or figure presenting per-algorithm raw times (not only geometric means) would allow readers to assess the stability claim directly.
- Clarify whether the reported memory figures include only heap or also stack/JIT overhead, and whether measurements were taken after warm-up for JIT languages.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and recommendation of minor revision. The concern regarding verifiability of implementation equivalence is addressed below.
read point-by-point responses
-
Referee: [Abstract (and implied Methods)] The central claim rests on logical equivalence of the six implementations per algorithm beyond language-level differences. The abstract states shared PRNG, identical inputs, and bit-identical outputs, but without the full methods section or code artifacts it is not possible to verify how numerical stability, floating-point semantics, and data-structure choices were aligned across languages with differing default precisions and memory models.
Authors: We agree that greater detail on alignment would improve verifiability. Section 3 of the manuscript already specifies the common PRNG, identical inputs, and bit-identical output requirement, which directly constrains floating-point and numerical behavior because any divergence in semantics or stability would violate the bit-identity condition. Data structures were aligned by using equivalent array and record representations in each language (e.g., contiguous 64-bit float arrays for vectors and matrices). To make this fully transparent, the revised manuscript will add an explicit subsection in Methods describing the precision and structure choices per algorithm, and we will supply a public code repository link as a code artifact so readers can inspect the implementations directly. revision: yes
Circularity Check
No significant circularity; pure empirical measurement study
full rationale
The paper reports direct runtime and memory measurements from six language implementations of five algorithms. All differences are attributed to language after enforcing shared PRNG, identical inputs, and bit-identical outputs. No equations, fitted parameters, predictions, or self-citations appear in the derivation chain; the reported ratios and tiers follow immediately from the timed executions. The study is therefore self-contained against external benchmarks with no reduction of results to prior quantities by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Implementations in each language are logically equivalent such that measured differences reflect only language characteristics.
Reference graph
Works this paper leans on
-
[1]
Bezanson, J., Edelman, A., Karpinski, S., Shah, V.B.: Julia: a fresh approach to numerical computing. SIAM Review59(1), 65–98 (2017). https://doi.org/10.1137/141000671
-
[2]
Jan Hermann, Zeno Schätzle, and Frank Noé
Harris, C.R., Millman, K.J., van der Walt, S.J., et al.: Array programming with NumPy. Nature585, 357–362 (2020). https://doi.org/10.1038/s41586-020-2649-2
-
[3]
In: Advances in Neural Information Processing Systems 32 (NeurIPS), pp
Paszke, A., Gross, S., Massa, F., et al.: PyTorch: an imperative style, high- performance deep learning library. In: Advances in Neural Information Processing Systems 32 (NeurIPS), pp. 8024–8035 (2019)
2019
-
[4]
arXiv preprint arXiv:2211.02740 (2022)
Churavy, V., Godoy, W.F., Bauer, C., et al.: Bridging HPC communities through the Julia programming language. arXiv preprint arXiv:2211.02740 (2022)
arXiv 2022
-
[5]
Prechelt, L.: An empirical comparison of seven programming languages. Computer 33(10), 23–29 (2000). https://doi.org/10.1109/2.876288
-
[6]
https://benchmarksgame- team.pages.debian.net/benchmarksgame/, last accessed 2026/06/09
The Computer Language Benchmarks Game. https://benchmarksgame- team.pages.debian.net/benchmarksgame/, last accessed 2026/06/09
2026
-
[7]
Pereira, R., Couto, M., Ribeiro, F., Rua, R., Cunha, J., Fernandes, J.P., Saraiva, J.: Energy efficiency across programming languages: how do energy, time, and memory relate? In: Proc. 10th ACM SIGPLAN Int. Conf. on Software Language Engineer- ing (SLE), pp. 256–267. ACM (2017). https://doi.org/10.1145/3136014.3136031
-
[8]
arXiv preprint arXiv:2206.05503 (2022)
Bugden, W., Alahmar, A.: Rust: the programming language for safety and perfor- mance. arXiv preprint arXiv:2206.05503 (2022)
arXiv 2022
-
[9]
Nanz, S., Furia, C.A.: A comparative study of programming languages in Rosetta Code. In: Proc. 37th Int. Conf. on Software Engineering (ICSE), pp. 778–788. IEEE (2015). https://doi.org/10.1109/ICSE.2015.90
-
[10]
Lin, W.-C., McIntosh-Smith, S.: Comparing Julia to performance-portable par- allel programming models for HPC. In: Int. Workshop on Performance, Porta- bility and Productivity in HPC (P3HPC), pp. 94–105. IEEE/ACM (2021). https://doi.org/10.1109/P3HPC54578.2021.00010
-
[11]
In: Proc
MacQueen, J.: Some methods for classification and analysis of multivariate obser- vations. In: Proc. 5th Berkeley Symp. on Mathematical Statistics and Probability, vol. 1, pp. 281–297. Univ. of California Press (1967)
1967
-
[12]
Least squares quantization in PCM,
Lloyd, S.P.: Least squares quantization in PCM. IEEE Trans. Inf. Theory28(2), 129–137 (1982). https://doi.org/10.1109/TIT.1982.1056489
-
[13]
Nearest neigh- bor pattern classification.IEEE Transactions on Information Theory, 13(1):21–27, 1967
Cover, T.M., Hart, P.E.: Nearest neighbor pattern classification. IEEE Trans. Inf. Theory13(1), 21–27 (1967). https://doi.org/10.1109/TIT.1967.1053964
-
[14]
Rumelhart, D.E., Hinton, G.E., Williams, R.J.: Learning represen- tations by back-propagating errors. Nature323, 533–536 (1986). https://doi.org/10.1038/323533a0
-
[15]
MIT Press, Cam- bridge, MA (1992)
Holland, J.H.: Adaptation in Natural and Artificial Systems. MIT Press, Cam- bridge, MA (1992)
1992
-
[16]
Mamdani, E.H., Assilian, S.: An experiment in linguistic synthesis with a fuzzy logic controller. Int. J. Man-Machine Studies7(1), 1–13 (1975). https://doi.org/10.1016/S0020-7373(75)80002-2 Behind Python: The Languages That Power AI 17
-
[17]
IEEE: IEEE Standard for Floating-Point Arithmetic. IEEE Std 754-2019 (2019). https://doi.org/10.1109/IEEESTD.2019.8766229
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.