Flexible Online Representation Learning Based on Similarity Matching
Pith reviewed 2026-06-28 15:38 UTC · model grok-4.3
The pith
An online biologically plausible algorithm learns sparse shift-invariant representations via similarity matching.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors present a versatile online biologically plausible learning algorithm based on similarity matching that learns sparse shift-invariant representations by enforcing row-sum constraints on the output similarity matrix during streaming updates, thereby enabling the same rule to perform clustering, manifold tiling, or sparse coding depending on the structure present in the data.
What carries the argument
Similarity-matching online update rule that enforces row-sum constraints while preserving shift-invariance.
If this is right
- The same rule can extract community structure from large graphs without batch matrix operations.
- Representations remain useful for tiling low-dimensional manifolds because of the enforced shift-invariance.
- Sparse coding tasks become feasible in an online setting on high-dimensional data.
- The method scales to data sets whose size would render conventional doubly nonnegative relaxations impractical.
- The approach supplies a candidate model for how neural circuits might form similar sparse codes from streaming input.
Where Pith is reading between the lines
- The rule could be tested on image or time-series streams to check whether the induced sparsity matches known sparse-coding benchmarks.
- Connections may exist to other local learning rules that also maintain normalization constraints without global optimization.
- The framework might be extended by replacing the similarity measure with task-specific kernels while retaining the online constraint enforcement.
- Performance on graphs of varying density could reveal limits on the sparsity level achievable under the row-sum condition.
Load-bearing premise
That an online update rule can enforce the row-sum constraints required for shift-invariance without violating biological plausibility or sparsity.
What would settle it
Empirical runs on a dataset with known shift structure in which the learned representations lose invariance under shifts or fail to produce the expected tiling or clustering behavior.
Figures
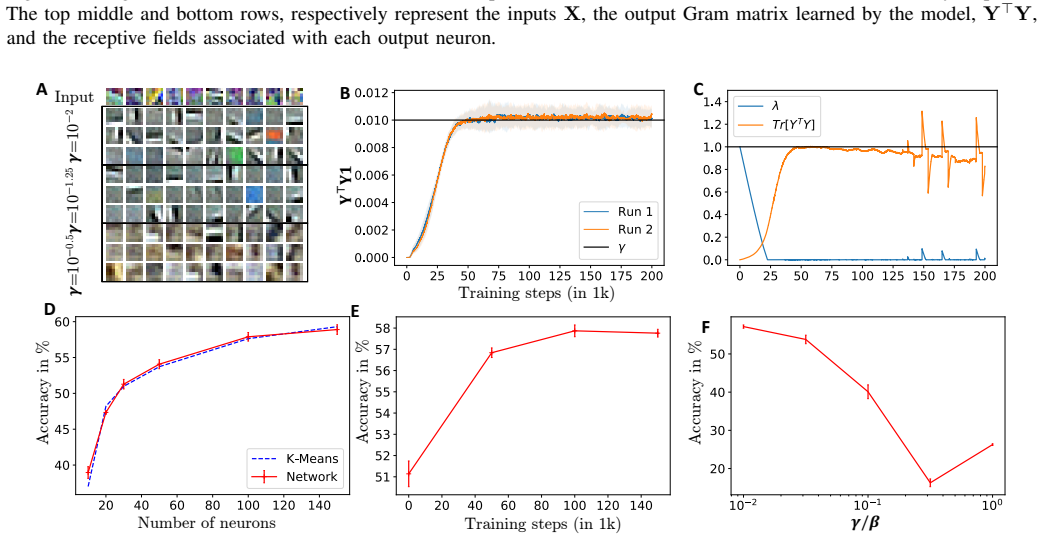
read the original abstract
Sparse high-dimensional representations are conducive to uncovering nontrivial structures in unsupervised exploration of data. Such a representation can deal with the dense connectivity in graphs relevant to community detection problems. However, sparse high-dimensional representations are capable of doing more, including manifold tiling and feature learning. Conventional algorithms optimize in the space of computationally intractable completely positive matrices or relax the problem to the space of doubly nonnegative matrices that scale with sample size in a way rendering them impractical for large data sets. Some of these methods also impose a row sum constraint, such as double stochasticity. Row sum constraints have the added advantage of being shift-invariant, in the context of manifold tiling. Constraints on the row sum of output similarity matrices require nontrivial online learning rules. Addressing these needs, we propose a versatile online biologically plausible learning algorithm capable of learning sparse shift-invariant representations, useful for clustering, manifold tiling, or sparse coding, depending on the data structure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a versatile online biologically plausible learning algorithm for sparse shift-invariant representations, which can adapt to tasks like clustering, manifold tiling, or sparse coding depending on data structure. It addresses limitations of prior methods that optimize over intractable completely positive matrices or scale poorly with sample size, and claims to supply a nontrivial online rule enforcing row-sum constraints (e.g., double stochasticity) on output similarity matrices while preserving shift-invariance.
Significance. If the algorithm delivers local updates that exactly enforce the row-sum property without non-local operations, it would enable scalable unsupervised representation learning on large datasets and provide a biologically plausible mechanism for shift-invariant sparse coding, with potential impact on both machine learning and computational neuroscience.
major comments (2)
- The central claim that the proposed rule enforces exact row-sum constraints via purely local updates (pre- and post-synaptic activities only) while remaining shift-invariant is load-bearing, yet the manuscript provides no explicit update equations, convergence analysis, or proof that no global summation or auxiliary aggregation is used; without this, the biological-plausibility and online guarantees cannot be verified.
- § on algorithm derivation (or equivalent): the assumption that nontrivial online rules exist for row-sum constraints is stated but not demonstrated with a concrete local rule that works for arbitrary data; if the implementation relies on any offline matrix operation or non-local normalization, the shift-invariance and plausibility claims collapse.
minor comments (1)
- The abstract and any introductory sections would benefit from a brief statement of the specific local update rule or pseudocode to allow immediate assessment of locality.
Simulated Author's Rebuttal
We thank the referee for their careful reading and for highlighting the need for explicit verification of the local update rules. We agree that the biological plausibility and online guarantees rest on these details and will revise the manuscript to supply them.
read point-by-point responses
-
Referee: The central claim that the proposed rule enforces exact row-sum constraints via purely local updates (pre- and post-synaptic activities only) while remaining shift-invariant is load-bearing, yet the manuscript provides no explicit update equations, convergence analysis, or proof that no global summation or auxiliary aggregation is used; without this, the biological-plausibility and online guarantees cannot be verified.
Authors: We accept this criticism. The current version states the existence of a local rule but does not display the update equations or the supporting analysis. In the revision we will insert a new subsection that (i) derives the exact local updates from the similarity-matching objective, (ii) proves that each update uses only pre- and post-synaptic terms, (iii) shows that the row-sum constraint is satisfied at every step without any global summation, and (iv) provides a convergence argument for the online, shift-invariant case. revision: yes
-
Referee: § on algorithm derivation (or equivalent): the assumption that nontrivial online rules exist for row-sum constraints is stated but not demonstrated with a concrete local rule that works for arbitrary data; if the implementation relies on any offline matrix operation or non-local normalization, the shift-invariance and plausibility claims collapse.
Authors: We agree that a concrete demonstration is required. The revised manuscript will expand the algorithm-derivation section to present the explicit local rule, verify that it operates for arbitrary input statistics, and confirm that no offline matrix operations or non-local normalizations are employed, thereby preserving both shift-invariance and biological plausibility. revision: yes
Circularity Check
No circularity; proposal of new online rule is independent of its inputs
full rationale
The abstract identifies a known difficulty (row-sum constraints on similarity matrices require nontrivial online rules) and states that the authors propose an algorithm addressing it while preserving biological plausibility and shift-invariance. No equations, fitted parameters, self-citations, or ansatzes are presented that would reduce the claimed result to a redefinition or statistical forcing of the input data. The derivation chain therefore remains self-contained against external benchmarks; the central claim is the existence and utility of the new rule rather than a tautological restatement of prior quantities.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Sparse high-dimensional representations are conducive to uncovering nontrivial structures in unsupervised exploration of data
- domain assumption Constraints on the row sum of output similarity matrices require nontrivial online learning rules
Reference graph
Works this paper leans on
-
[1]
Direct feedback alignment provides learning in deep neural networks,
A. Nøkland, “Direct feedback alignment provides learning in deep neural networks,”Advances in Neural Information Processing Systems, vol. 29, 2016
2016
-
[2]
Neuroscience-inspired online unsupervised learning algorithms: Artificial neural networks,
C. Pehlevan and D. B. Chklovskii, “Neuroscience-inspired online unsupervised learning algorithms: Artificial neural networks,”IEEE Signal Processing Magazine, vol. 36, no. 6, pp. 88–96, 2019
2019
-
[3]
A Hebbian/anti-Hebbian network for online sparse dictio- nary learning derived from symmetric matrix factoriza- tion,
T. Hu, C. Pehlevan, and D. B. Chklovskii, “A Hebbian/anti-Hebbian network for online sparse dictio- nary learning derived from symmetric matrix factoriza- tion,” in2014 48th Asilomar Conference on Signals, Systems and Computers. IEEE, 2014, pp. 613–619
2014
-
[4]
Online representation learning with single and multi-layer Hebbian networks for image classification,
Y . Bahroun and A. Soltoggio, “Online representation learning with single and multi-layer Hebbian networks for image classification,” inInternational Conference on Artificial Neural Networks. Springer, 2017, pp. 354–363
2017
-
[5]
Cluster- ing is semidefinitely not that hard: Nonnegative SDP for manifold disentangling,
M. Tepper, A. M. Sengupta, and D. Chklovskii, “Cluster- ing is semidefinitely not that hard: Nonnegative SDP for manifold disentangling,”The Journal of Machine Learning Research, vol. 19, no. 1, pp. 3208–3237, 2018
2018
-
[6]
Sengupta, C
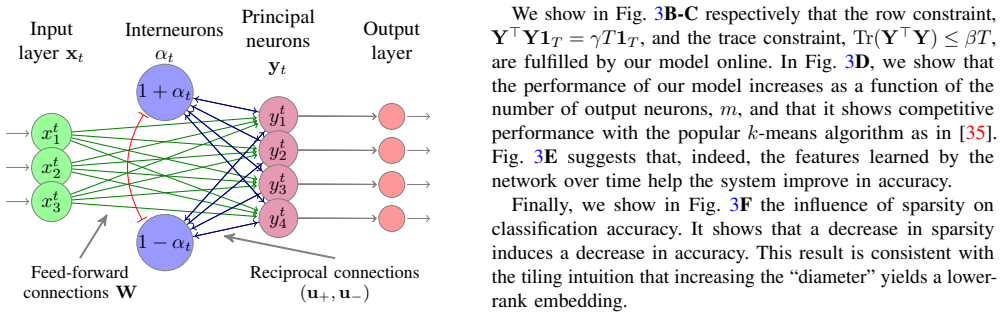
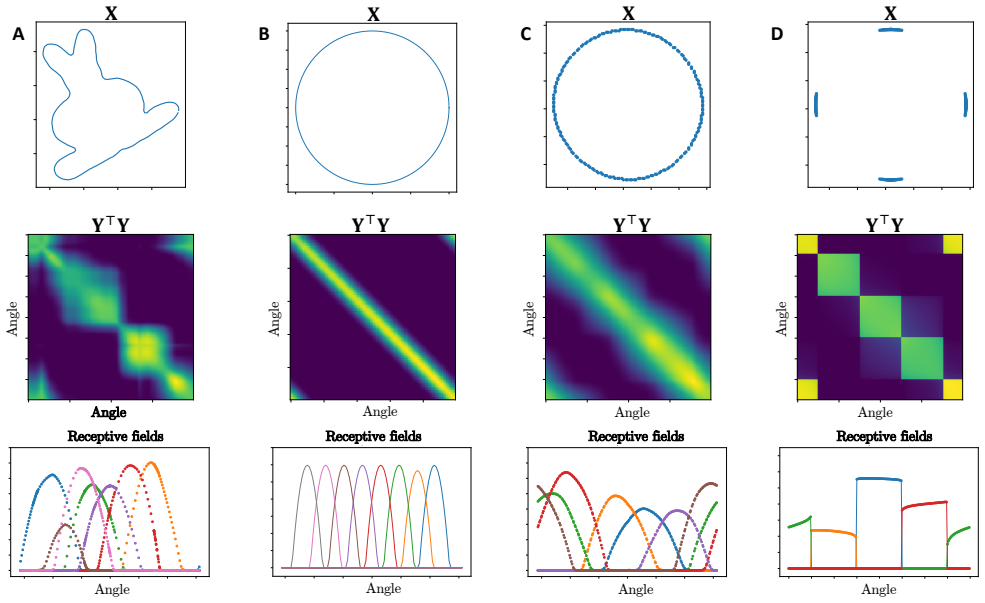
A. Sengupta, C. Pehlevan, M. Tepper, A. Genkin, and D. Chklovskii, “Manifold-tiling localized receptive fields A B 𝐘!𝐘 𝐘!𝐘 Receptive fieldsReceptive fields Angle Angle AngleAngle AngleAngle 𝐗 𝐗 C 𝐘!𝐘 Receptive fields Angle Angle Angle 𝐗D 𝐘!𝐘 Receptive fields Angle Angle Angle 𝐗 Fig. 2: Our algorithm is able to tile various manifolds despite the non-unifor...
2018
-
[7]
Training neural networks with local error signals,
A. Nøkland and L. H. Eidnes, “Training neural networks with local error signals,” inInternational Conference on Machine Learning. PMLR, 2019, pp. 4839–4850
2019
-
[8]
Contrastive similarity matching for supervised learning,
S. Qin, N. Mudur, and C. Pehlevan, “Contrastive similarity matching for supervised learning,”Neural Computation, vol. 33, no. 5, pp. 1300–1328, 2021
2021
-
[9]
On semidefinite relaxations for the block model,
A. A. Amini and E. Levina, “On semidefinite relaxations for the block model,”The Annals of Statistics, vol. 46, no. 1, pp. 149–179, 2018
2018
-
[10]
Community detection in graphs,
S. Fortunato, “Community detection in graphs,”Physics reports, vol. 486, no. 3-5, pp. 75–174, 2010
2010
-
[11]
Community structure in social and biological networks,
M. Girvan and M. E. Newman, “Community structure in social and biological networks,”Proceedings of the national academy of sciences, vol. 99, no. 12, pp. 7821– 7826, 2002
2002
-
[12]
Sparse coding of sensory inputs,
B. A. Olshausen and D. J. Field, “Sparse coding of sensory inputs,”Current opinion in neurobiology, vol. 14, no. 4, pp. 481–487, 2004
2004
-
[13]
Some methods for classification and analysis of multivariate observations,
J. MacQueen, “Some methods for classification and analysis of multivariate observations,” inProceedings of the fifth Berkeley symposium on mathematical statistics and probability, vol. 1. Oakland, CA, USA, 1967, pp. 281–297
1967
-
[14]
Least squares quantization in PCM,
S. Lloyd, “Least squares quantization in PCM,”IEEE Transactions on Information Theory, vol. 28, no. 2, pp. 129–137, 1982
1982
-
[15]
Relax, no need to round: Integrality of clustering formulations,
P. Awasthi, A. S. Bandeira, M. Charikar, R. Krishnaswamy, S. Villar, and R. Ward, “Relax, no need to round: Integrality of clustering formulations,” inProceedings of the 2015 Conference on Innovations in Theoretical Computer Science, 2015, pp. 191–200
2015
-
[16]
The non-convex Burer-Monteiro approach works on smooth semidefinite programs,
N. Boumal, V . V oroninski, and A. Bandeira, “The non-convex Burer-Monteiro approach works on smooth semidefinite programs,”Advances in Neural Information Processing Systems, vol. 29, 2016
2016
-
[17]
Approximating k-means-type clus- tering via semidefinite programming,
J. Peng and Y . Wei, “Approximating k-means-type clus- tering via semidefinite programming,”SIAM Journal on Optimization, vol. 18, no. 1, pp. 186–205, 2007
2007
-
[18]
Stochastic blockmodels: First steps,
P. W. Holland, K. B. Laskey, and S. Leinhardt, “Stochastic blockmodels: First steps,”Social Networks, vol. 5, no. 2, pp. 109–137, 1983
1983
-
[19]
A survey on theoretical advances of community detection in networks,
Y . Zhao, “A survey on theoretical advances of community detection in networks,”Wiley Interdisciplinary Reviews: Computational Statistics, vol. 9, no. 5, p. e1403, 2017
2017
-
[20]
Finding and evaluating community structure in networks,
M. E. Newman and M. Girvan, “Finding and evaluating community structure in networks,”Physical Review E, vol. 69, no. 2, p. 026113, 2004
2004
-
[21]
Modularity and community structure in networks,
M. E. Newman, “Modularity and community structure in networks,”Proceedings of the national academy of sciences, vol. 103, no. 23, pp. 8577–8582, 2006
2006
-
[22]
Modularity maximiza- tion using completely positive programming,
S. Yazdanparast and T. C. Havens, “Modularity maximiza- tion using completely positive programming,”Physica A: Statistical Mechanics and its Applications, vol. 471, pp. 20–32, 2017
2017
-
[23]
Maximizing modularity is hard,
U. Brandes, D. Delling, M. Gaertler, R. G ¨orke, M. Hoefer, Z. Nikoloski, and D. Wagner, “Maximizing modularity is hard,”arXiv preprint physics/0608255, 2006
Pith/arXiv arXiv 2006
-
[24]
Robust and computationally feasible community detection in the presence of arbitrary outlier nodes,
T. T. Cai and X. Li, “Robust and computationally feasible community detection in the presence of arbitrary outlier nodes,”The Annals of Statistics, vol. 43, no. 3, pp. 1027– 1059, 2015
2015
-
[25]
Improved graph clustering,
Y . Chen, S. Sanghavi, and H. Xu, “Improved graph clustering,”IEEE Transactions on Information Theory, vol. 60, no. 10, pp. 6440–6455, 2014
2014
-
[26]
Statistical-computational tradeoffs in planted problems and submatrix localization with a growing number of clusters and submatrices,
Y . Chen and J. Xu, “Statistical-computational tradeoffs in planted problems and submatrix localization with a growing number of clusters and submatrices,”The Journal of Machine Learning Research, vol. 17, no. 1, pp. 882– 938, 2016
2016
-
[27]
Fast low-rank semidefinite programming for embedding and clustering,
B. Kulis, A. C. Surendran, and J. C. Platt, “Fast low-rank semidefinite programming for embedding and clustering,” inArtificial Intelligence and Statistics. PMLR, 2007, pp. 235–242
2007
-
[28]
H. S. Seung and J. Zung, “A correlation game for unsupervised learning yields computational interpretations of hebbian excitation, anti-hebbian inhibition, and synapse elimination,”arXiv preprint arXiv:1704.00646, 2017
Pith/arXiv arXiv 2017
-
[29]
T. F. Cox and M. Cox,Multidimensional Scaling. Chap- man and Hall/CRC, 2000
2000
-
[30]
Neural networks, principal components, and sub- spaces,
E. Oja, “Neural networks, principal components, and sub- spaces,”International Journal of Neural Systems, vol. V ol. 01, No. 01, pp. 61–68, 1989
1989
-
[31]
A biologically plausible neural network for multichannel canonical correlation analysis,
D. Lipshutz, Y . Bahroun, S. Golkar, A. M. Sengupta, and D. B. Chklovskii, “A biologically plausible neural network for multichannel canonical correlation analysis,” Neural Computation, vol. 33, no. 9, pp. 2309–2352, 2021
2021
-
[32]
A normative and biologically plausible algorithm for Independent Component Analysis,
Y . Bahroun, D. Chklovskii, and A. Sengupta, “A normative and biologically plausible algorithm for Independent Component Analysis,”Advances in Neural Information Processing Systems, vol. 34, 2021
2021
-
[33]
Kernel similarity matching with hebbian networks,
K. Luther and S. Seung, “Kernel similarity matching with hebbian networks,”Advances in Neural Information Processing Systems, vol. 35, pp. 2282–2293, 2022
2022
-
[34]
O’Keefe and L
J. O’Keefe and L. Nadel,The hippocampus as a cognitive map. Oxford University Press, 1978
1978
-
[35]
An analysis of single- layer networks in unsupervised feature learning,
A. Coates, A. Ng, and H. Lee, “An analysis of single- layer networks in unsupervised feature learning,” in Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics. JMLR Workshop and Conference Proceedings, 2011, pp. 215–223
2011
-
[36]
Learning multiple layers of features from tiny images,
A. Krizhevsky and G. Hinton, “Learning multiple layers of features from tiny images,” 2009
2009
-
[37]
Emergence of simple- cell receptive field properties by learning a sparse code for natural images,
B. A. Olshausen and D. J. Field, “Emergence of simple- cell receptive field properties by learning a sparse code for natural images,”Nature, vol. 381, pp. 607–609, 1996
1996
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.