T-IMPACT: A Severity-Aware Benchmark for Contextual Image-Text Manipulation
Pith reviewed 2026-06-26 10:57 UTC · model grok-4.3
The pith
T-IMPACT supplies 98,786 image-text pairs labeled with continuous severity scores for how much an edit shifts news interpretation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
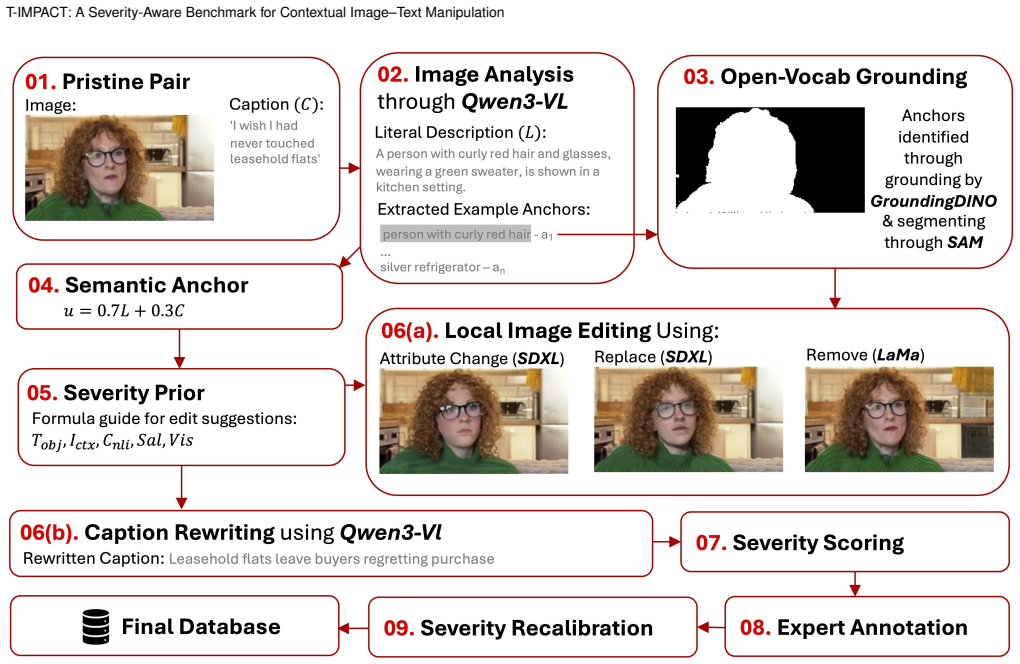
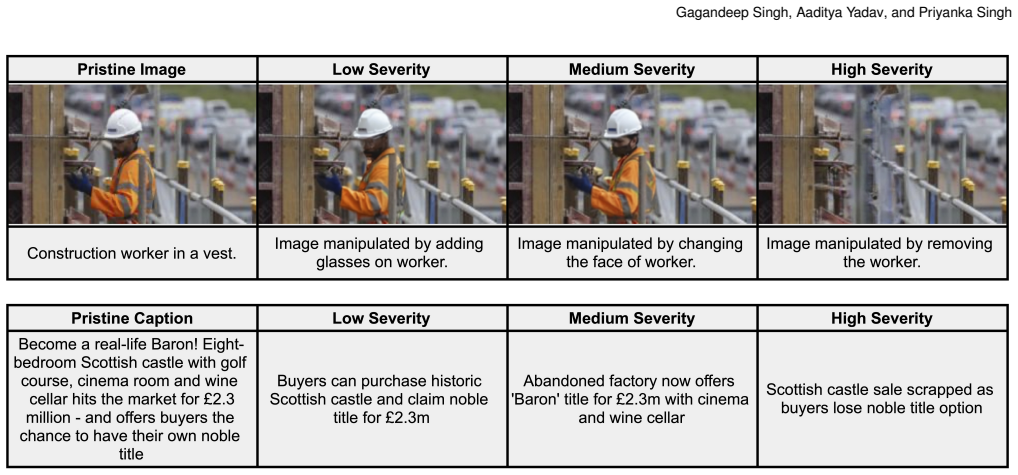
T-IMPACT contains 98,786 examples spanning pristine, image-only, text-only, and joint manipulations, with a calibrated continuous severity signal, coarse low/medium/high labels, and supporting grounding metadata. The generation pipeline extracts semantic anchors from the original pair, grounds them spatially, performs localized image edits and constrained caption rewrites, and calibrates contextual-impact scores using limited human ratings. In this release the continuous score is the primary target while the bands serve as coarse operating buckets. Current models recover some authenticity signal, but severity prediction remains substantially harder and only weakly aligned with human judgment
What carries the argument
The generation and calibration pipeline that extracts semantic anchors, grounds them spatially, applies localized edits and constrained rewrites, then converts limited human ratings into a continuous contextual-impact score.
If this is right
- Evaluation of manipulation detectors can now include a continuous severity target in addition to binary authenticity labels.
- Training objectives can be designed to predict the calibrated impact score rather than only the presence of an edit.
- The low/medium/high bands can serve as operating thresholds for triage systems that prioritize high-impact edits.
- Grounding metadata supplied with each example enables localized analysis of which image regions drive the severity score.
Where Pith is reading between the lines
- Systems that combine authenticity detection with severity ranking could reduce alert fatigue by focusing human review on high-impact cases.
- The same pipeline could be applied to social-media posts outside the news domain if the semantic-anchor extraction step is adapted.
- Repeated application of the benchmark over time would allow measurement of whether model severity prediction improves as training data grows.
Load-bearing premise
The limited human ratings collected produce a reliable continuous severity signal that generalizes beyond the specific edits generated by the pipeline.
What would settle it
Collect new human ratings on a held-out set of the generated edits and test whether the original calibrated scores still rank the edits in the same order; a large reversal in ranking would falsify the claim that the scores capture a stable severity signal.
Figures
read the original abstract
Recent advances in vision-language models and generative editing systems have made it increasingly easy to produce persuasive multimodal misinformation by altering images, text, or both jointly. However, existing datasets focus mainly on authenticity, out-of-context mismatch, or manipulation type, and rarely capture how strongly an edit changes the likely interpretation of a post. We introduce T-IMPACT, a first-release severity-aware benchmark for manipulated news-style image-text pairs. T-IMPACT contains 98,786 examples spanning pristine, image-only, text-only, and joint manipulations, with a calibrated continuous severity signal, coarse low/medium/high labels, and supporting grounding metadata. Starting from a news image-text pair, the pipeline extracts semantic anchors, grounds them spatially, performs localized image edits and constrained caption rewrites, and calibrates contextual-impact scores using limited human ratings. In this release, the calibrated continuous score is the primary severity target, while the low/medium/high bands should be interpreted as coarse operating buckets rather than balanced classes. Experiments show that current models recover some authenticity signal, but severity prediction remains substantially harder and only weakly aligned with human judgment. T-IMPACT provides an initial benchmark for studying multimodal manipulation beyond binary real/fake classification toward graded contextual impact.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces T-IMPACT, a benchmark of 98,786 news-style image-text pairs spanning pristine, image-only, text-only, and joint manipulations. It describes a pipeline that extracts semantic anchors, grounds them spatially, applies localized edits and constrained caption rewrites, and derives a calibrated continuous contextual-impact score (plus coarse low/medium/high bands) from limited human ratings. The central experimental claim is that current models recover some authenticity signal while severity prediction remains substantially harder and only weakly aligned with human judgment.
Significance. If the severity calibration yields a stable, generalizable signal, the benchmark would usefully shift focus from binary authenticity to graded contextual impact in multimodal misinformation research. The scale, inclusion of grounding metadata, and explicit distinction between continuous scores and coarse buckets are positive features. The absence of reported calibration statistics, however, leaves the primary contribution's reliability unverified.
major comments (2)
- [Abstract] Abstract: the description of severity calibration via 'limited human ratings' supplies no quantitative details on rater count, inter-rater agreement (e.g., Krippendorff's alpha or ICC), calibration procedure, error bars, exclusion criteria, or validation against edits generated by methods other than the described pipeline. This is load-bearing because the continuous severity score is presented as the primary target and the basis for the claim that severity prediction is substantially harder.
- [Abstract] Abstract / Experiments: the statement that 'severity prediction remains substantially harder and only weakly aligned with human judgment' is reported without accompanying metrics (correlation coefficients, MAE, or performance deltas with confidence intervals) or baseline comparisons, preventing assessment of whether the observed difficulty is robust or pipeline-specific.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the description of severity calibration via 'limited human ratings' supplies no quantitative details on rater count, inter-rater agreement (e.g., Krippendorff's alpha or ICC), calibration procedure, error bars, exclusion criteria, or validation against edits generated by methods other than the described pipeline. This is load-bearing because the continuous severity score is presented as the primary target and the basis for the claim that severity prediction is substantially harder.
Authors: We agree that the abstract lacks these quantitative details. The manuscript explicitly describes the use of limited human ratings for calibration in this initial release, which constrained the scope of data collection. We will revise the abstract and methods to include the number of raters, a clearer description of the calibration procedure, and any available error estimates or exclusion criteria. Comprehensive inter-rater agreement metrics were not computed due to the limited ratings; we will explicitly note this limitation rather than overstate the calibration robustness. Validation against external edit methods is outside the current pipeline scope but can be flagged as future work. revision: partial
-
Referee: [Abstract] Abstract / Experiments: the statement that 'severity prediction remains substantially harder and only weakly aligned with human judgment' is reported without accompanying metrics (correlation coefficients, MAE, or performance deltas with confidence intervals) or baseline comparisons, preventing assessment of whether the observed difficulty is robust or pipeline-specific.
Authors: The abstract summarizes the experimental outcome at a high level. The full manuscript reports the underlying model evaluations on both authenticity recovery and severity prediction. We will revise the abstract to include the key quantitative results (e.g., correlation coefficients, MAE, performance deltas) with confidence intervals and explicit baseline comparisons. This will allow direct assessment of whether the observed difficulty is robust. revision: yes
Circularity Check
No circularity: severity calibration uses external human ratings independent of model outputs
full rationale
The paper constructs T-IMPACT by running a generation pipeline on news image-text pairs to produce manipulations, then calibrates continuous contextual-impact scores from limited external human ratings. No equations, self-citations, or derivations reduce the reported severity targets or model-performance claims to fitted parameters or self-referential inputs by construction. Authenticity labels follow directly from the generation process (pristine vs. manipulated), while severity is an independent human-derived signal; the empirical finding that severity prediction is harder is an external evaluation result, not a definitional tautology. The derivation chain is self-contained against the stated external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- severity calibration parameters
axioms (2)
- domain assumption Semantic anchors extracted from news image-text pairs can be spatially grounded to support realistic localized edits and constrained caption rewrites.
- domain assumption Limited human ratings collected on the generated manipulations yield a severity signal that reflects true change in contextual interpretation.
Reference graph
Works this paper leans on
-
[1]
Firoj Alam, Stefano Cresci, Tanmoy Chakraborty, Fabrizio Silvestri, Dimitar Dimitrov, Giovanni Da San Martino, Shaden Shaar, Hamed Firooz, and Preslav Nakov. 2022. A Survey on Multimodal Disinformation Detection.Proceedings of the 29th International Conference on Computational Linguistics (COLING) (2022), 6625–6643
2022
-
[2]
Shivangi Aneja, Chris Bregler, and Matthias Nießner. 2021. COSMOS: Catching Out-of-Context Misinformation with Self-Supervised Learning. arXiv:2101.06278
arXiv 2021
-
[3]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
Pith/arXiv arXiv 2025
-
[4]
Wenzhi Cao, Vahid Mirjalili, and Sebastian Raschka. 2019. Rank Consistent Ordinal Regression for Neural Networks with Application to Age Estimation. arXiv preprint arXiv:1901.07884(2019)
arXiv 2019
-
[5]
Megha Chakraborty et al. 2023. FACTIFY3M: Multimodal Fact Verification with 5W Question Answering. arXiv:2306.05523
arXiv 2023
-
[6]
Yuwei Chen, Ming-Ching Chang, Mattias Kirchner, Zhenfei Zhang, Xin Li, Arslan Basharat, and Anthony Hoogs. 2025. A Semantically Impactful Image Manipula- tion Dataset: Characterizing Image Manipulations Using Semantic Significance. T -IMP ACT: A Severity-Aware Benchmark for Contextual Image–T ext Manipulation InProceedings of the IEEE/CVF Winter Conferenc...
2025
-
[7]
Robert Chesney and Danielle Keats Citron. 2019. Deep Fakes: A Looming Challenge for Privacy, Democracy, and National Security.California Law Review 107, 6 (2019), 1753–1819
2019
-
[8]
Y . Dou, J. Chen, et al. 2021. Weibo-21: A Large-scale Multimodal Social Media Fake News Dataset. InAAAI
2021
-
[9]
Sheetal Harris, Hassan Jalil Hadi, Naveed Ahmad, and Mohammed Ali Alshara
-
[10]
Fake News Detection Revisited: An Extensive Review of Theoretical Frameworks, Dataset Assessments, Model Constraints, and Forward-Looking Research Agendas.Technologies12, 11 (2024), 222
2024
-
[11]
Jack Hessel et al. 2022. Multimodal Inconsistency Detection via Vision-Language NLI. InEMNLP
2022
-
[12]
Zhenglin Huang et al . 2025. SIDA: Social Media Image Deepfake Detection, Localization and Explanation with Large Multimodal Model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2025
-
[13]
Kim et al
T. Kim et al. 2024. M-SegEval: Region-level Semantic Significance Benchmark. InECCV
2024
-
[14]
Berg, Wan-Yen Lo, et al
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Han Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, et al
-
[15]
Segment Anything.arXiv preprint arXiv:2304.02643(2023)
Pith/arXiv arXiv 2023
-
[16]
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. 2024. LLaV A- OneVision: Easy Visual Task Transfer.arXiv preprint arXiv:2408.03326(2024). doi:10.48550/arXiv.2408.03326
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2408.03326 2024
-
[17]
Qing Li et al. 2024. Towards Multimodal Disinformation Detection by Vision– Language Knowledge Interaction.Information Fusion110 (2024), 102037
2024
-
[18]
Shilong Liu et al. 2024. Grounding DINO: Marrying DINO with Grounded Pre- Training for Open-Set Object Detection. InEuropean Conference on Computer Vision (ECCV)
2024
-
[19]
Feng Luo, Ashish Sharma, Matthew Lease, and Ying Ding. 2021. NewsCLIPpings: Automatic Generation of Out-of-Context Multimodal Media. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP). 6829–6843
2021
-
[20]
Suryavardan, Amrit Bhaskar, Parth Patwa, Amitava Das, Asif Ekbal, Amit P
Shreyash Mishra, S. Suryavardan, Amrit Bhaskar, Parth Patwa, Amitava Das, Asif Ekbal, Amit P. Sheth, and Tanmoy Chakraborty. 2021. FACTIFY: A Multimodal Fact Verification Dataset. InProceedings of the 1st Workshop on Multimodal Fact-Checking and Hate Speech Detection (DE-FACTIFY)
2021
-
[21]
Kai Nakamura, Sharon Levy, and William Yang Wang. 2020. r/Fakeddit: A New Multimodal Benchmark Dataset for Fine-Grained Fake News Detection. In Proceedings of the 12th Language Resources and Evaluation Conference (LREC). 6149–6157
2020
-
[22]
Dustin Podell et al. 2023. SDXL: Improving Latent Diffusion Models for High- Resolution Image Synthesis.arXiv preprint arXiv:2307.01952(2023)
Pith/arXiv arXiv 2023
-
[23]
Rui Shao, Tianxing Wu, and Ziwei Liu. 2023. Detecting and Grounding Multi- Modal Media Manipulation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 6904–6913
2023
-
[24]
Roman Suvorov et al . 2022. Resolution-Robust Large Mask Inpainting with Fourier Convolutions. InIEEE/CVF Winter Conference on Applications of Com- puter Vision (WACV)
2022
-
[25]
Bin Xiao, Haiping Wu, Weijian Xu, Xiyang Dai, Houdong Hu, Yumao Lu, Michael Zeng, Ce Liu, and Lu Yuan. 2023. Florence-2: Advancing a Unified Represen- tation for a Variety of Vision Tasks.arXiv preprint arXiv:2311.06242(2023). doi:10.48550/arXiv.2311.06242
-
[26]
Zehong Yan, Peng Qi, Wynne Hsu, and Mong Li Lee. 2025. TRUST-VL: An Explainable News Assistant for General Multimodal Misinformation Detection. arXiv preprint arXiv:2509.04448(2025)
arXiv 2025
-
[27]
Bianca Zadrozny and Charles Elkan. 2002. Transforming Classifier Scores into Accurate Multiclass Probability Estimates. InProceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining
2002
-
[28]
Reza Zafarani, Mohammad Ali Abbasi, and Huan Liu. 2019. Fake News Research: Theories, Detection Strategies, and Open Problems.ACM SIGKDD Explorations Newsletter21, 2 (2019), 1–21
2019
-
[29]
Ye Zhu, Yunan Wang, and Zitong Yu. 2025. Multimodal Fake News Detection: MFND Dataset and Shallow-Deep Multitask Learning. InProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence (IJCAI-25). IJCAI, 8012–8020. doi:10.24963/ijcai.2025/891
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.