Self-Compacting Language Model Agents
Pith reviewed 2026-06-26 08:27 UTC · model grok-4.3
The pith
A model can invoke its own compaction tool guided by a short rubric to summarize agent traces at structurally good moments, matching fixed-interval methods at much lower token cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
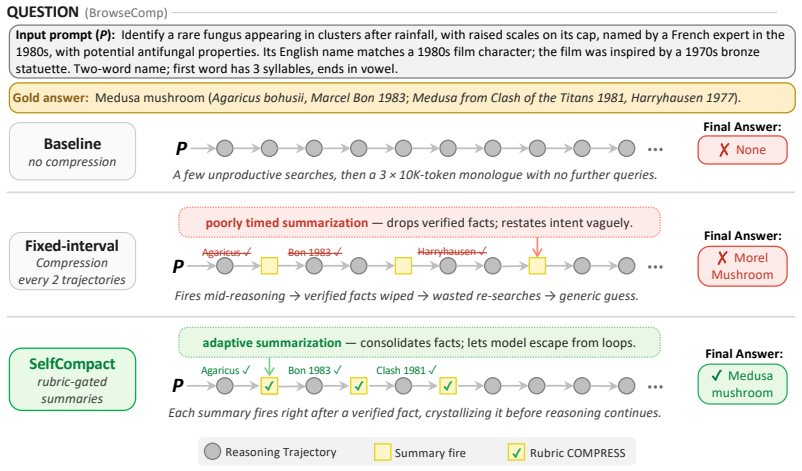
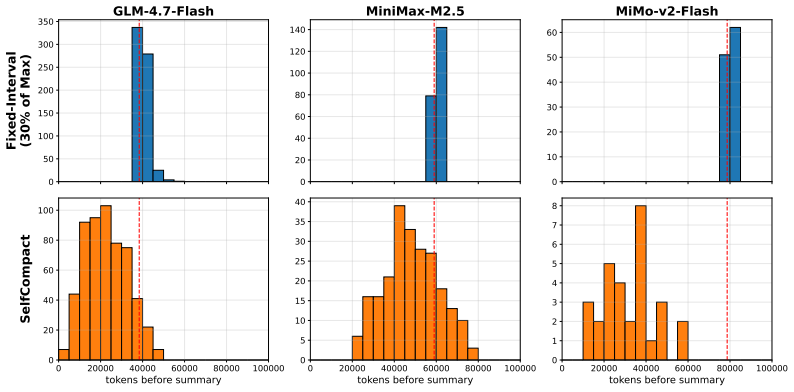
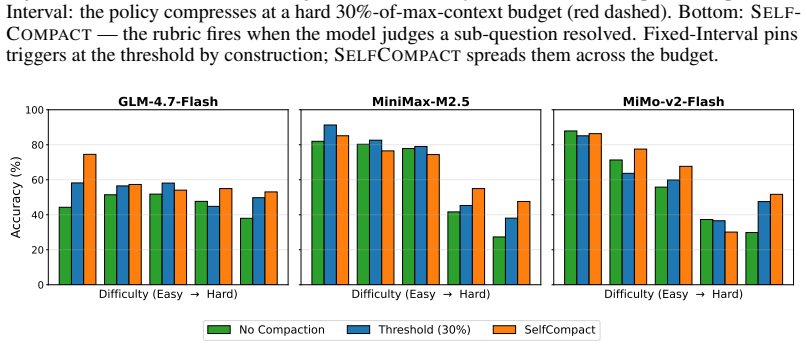
SelfCompact pairs a compaction tool the model can invoke with a lightweight rubric that specifies compaction at sub-task resolution or convergence and suppression during active derivation or when stuck. Together they produce adaptive summarization without fine-tuning or external supervision, so the model prunes stale content at appropriate structural points rather than at arbitrary token thresholds, delivering performance that matches or exceeds fixed-interval compaction on competitive math and agentic search tasks.
What carries the argument
The compaction tool the model invokes, paired with the lightweight rubric that defines when to fire or suppress it.
If this is right
- Matches or exceeds fixed-interval summarization on the tested benchmarks
- Improves over no-summarization baselines by up to 18.1 points on math and 5-9 points on agentic search
- Reduces per-question token cost by 30-70 percent relative to fixed-interval methods
- Exposes a meta-cognitive gap in unprompted models that the rubric closes without training
Where Pith is reading between the lines
- The same tool-plus-rubric pattern could be tested on other long-horizon agent tasks such as web navigation or multi-step planning where context decay is costly.
- Over repeated use the rubric might be internalized by the model so that external prompting becomes unnecessary.
- The approach reframes certain timing decisions as scaffoldable capabilities rather than capabilities that must be trained into the base model.
Load-bearing premise
A lightweight rubric can reliably guide unprompted models to invoke the compaction tool at structurally appropriate moments without fine-tuning or external supervision.
What would settle it
Compare runs that give the model the compaction tool alone against runs that also supply the rubric, measuring whether invocation timing stays helpful and whether accuracy or cost gains disappear without the rubric.
Figures
read the original abstract
Long agent traces composed of chains of thought and tool calls accumulate stale content that anchor subsequent generations, and eventually outgrow the context window. Existing scaffolds mitigate it with fixed-interval compaction triggered at a token threshold. Such triggers pay no heed to trajectory structure, risking discard of partial results mid-derivation or mid-search. We propose SelfCompact, a scaffold that allows the model itself to decide when and how to compact. Specifically, it pairs two inference-time elements: (i) a compaction tool the model invokes to summarize the accumulated context, and (ii) a lightweight rubric specifying when to fire (a sub-task has resolved, or the trajectory is converging) and when to suppress (mid-derivation, or when stuck). Both are needed. The tool alone is unevenly used across open-weight models, often invoked at unhelpful moments or not at all; the rubric alone cannot act. Together, they elicit effective adaptive compaction without any fine-tuning or external supervision. We present empirical results on six benchmarks (competitive math and agentic search) and seven models. Our results show that SelfCompact matches or exceeds fixed-interval summarization at a fraction of the token cost, improving over a no-summarization baseline by up to 18.1 points on math and 5-9 points on agentic search at 30-70% lower per-question cost. Our results expose a meta-cognitive gap: although unprompted models cannot reliably tell when their own context is rotting, a lightweight rubric closes this gap, reframing when to compact as a capability that scaffolds can supply without training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SelfCompact, an inference-time scaffold pairing a compaction tool (invoked by the model to summarize context) with a lightweight rubric that specifies when to compact (post-subtask resolution or convergence) and when to suppress (mid-derivation). It claims this elicits adaptive compaction without fine-tuning or external supervision, matching or exceeding fixed-interval summarization at 30-70% lower token cost while improving over no-summarization baselines by up to 18.1 points on math and 5-9 points on agentic search across six benchmarks and seven models.
Significance. If the empirical results hold under rigorous controls, the work is significant for showing that simple scaffolds can supply meta-cognitive context-management capabilities to unprompted models, reframing compaction timing as an elicitable behavior rather than a training target. The evaluation across seven models and six benchmarks (competitive math and agentic search) provides a broad test of generality and includes explicit token-cost comparisons, which strengthens the efficiency claims.
major comments (3)
- [§3] §3 (Method description of the rubric): the central claim that the lightweight rubric elicits structurally appropriate compaction timing 'without any fine-tuning or external supervision' cannot be evaluated because the exact rubric text is not provided; without it, it is impossible to determine whether the rubric embeds benchmark-specific meta-cognition or remains truly general.
- [§4] §4 (Experiments) and §5 (Results): no ablation isolating the rubric's contribution from the compaction tool is reported, despite the abstract stating that 'both are needed' and that the tool alone is used unevenly; this is load-bearing for the no-training claim and the assertion that the rubric closes the meta-cognitive gap.
- [§5] §5 (Results tables): the reported gains (e.g., up to 18.1 points on math) lack accompanying statistical significance tests, variance across runs, or explicit controls for post-hoc rubric or benchmark phrasing choices, which directly affects verifiability of the cross-model consistency asserted in the abstract.
minor comments (2)
- Figure captions and axis labels in the cost-vs-performance plots could be clarified to explicitly show the 30-70% token reduction range for each model.
- The related-work section would benefit from additional citations to prior work on adaptive context compression in agent scaffolds.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment point by point below, agreeing where revisions are warranted and outlining the changes we will make.
read point-by-point responses
-
Referee: [§3] §3 (Method description of the rubric): the central claim that the lightweight rubric elicits structurally appropriate compaction timing 'without any fine-tuning or external supervision' cannot be evaluated because the exact rubric text is not provided; without it, it is impossible to determine whether the rubric embeds benchmark-specific meta-cognition or remains truly general.
Authors: We agree that the exact rubric text must be provided to allow evaluation of its generality. The rubric is formulated with only general criteria for sub-task resolution and convergence detection and contains no benchmark-specific language. We will include the complete rubric text as an appendix in the revised manuscript. revision: yes
-
Referee: [§4] §4 (Experiments) and §5 (Results): no ablation isolating the rubric's contribution from the compaction tool is reported, despite the abstract stating that 'both are needed' and that the tool alone is used unevenly; this is load-bearing for the no-training claim and the assertion that the rubric closes the meta-cognitive gap.
Authors: We acknowledge that the current manuscript relies on descriptive evidence of uneven tool usage rather than a controlled ablation. To strengthen the claim that both components are required, we will add an ablation study isolating the rubric's contribution in the revised experiments section. revision: yes
-
Referee: [§5] §5 (Results tables): the reported gains (e.g., up to 18.1 points on math) lack accompanying statistical significance tests, variance across runs, or explicit controls for post-hoc rubric or benchmark phrasing choices, which directly affects verifiability of the cross-model consistency asserted in the abstract.
Authors: We agree that statistical tests, variance reporting, and explicit controls for phrasing would improve verifiability. We will incorporate appropriate significance tests, report standard deviations from multiple runs, and document phrasing controls in the revised results. revision: yes
Circularity Check
No significant circularity; empirical results are self-contained
full rationale
The paper reports direct empirical comparisons of the SelfCompact scaffold (compaction tool + rubric) against fixed-interval and no-summarization baselines on six benchmarks and seven models. Performance gains (up to 18.1 points on math, 5-9 on search at lower cost) are presented as measured outcomes rather than derived quantities. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The rubric's role is an explicit design choice whose effectiveness is tested experimentally, not assumed by construction or reduced to prior author work. This matches the default expectation of a non-circular empirical paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The lightweight rubric is sufficient to elicit appropriate compaction timing from the tested models without any training.
invented entities (2)
-
Compaction tool
no independent evidence
-
Lightweight rubric
no independent evidence
Reference graph
Works this paper leans on
-
[1]
An essay concerning human understanding , author =
-
[2]
C. S. Peirce , year = 1883, booktitle =
-
[3]
Biometrika , pages =
On the likelihood that one unknown probability exceeds another in view of the evidence of two samples , author =. Biometrika , pages =
-
[4]
, year = 1946, journal =
Rogers, Carl R. , year = 1946, journal =
1946
-
[5]
The Journal of Philosophy , volume = 44, number = 5, pages =
The problem of counterfactual conditionals , author =. The Journal of Philosophy , volume = 44, number = 5, pages =
-
[6]
Mind , pages =
Computing machinery and intelligence , author =. Mind , pages =
-
[7]
The annals of mathematical statistics , pages =
A stochastic approximation method , author =. The annals of mathematical statistics , pages =
-
[8]
The Annals of Mathematical Statistics , publisher =
On information and sufficiency , author =. The Annals of Mathematical Statistics , publisher =
-
[9]
Equation of state calculations by fast computing machines , author =
-
[10]
, author =
Analogy in science. , author =. American Psychologist , publisher =
-
[11]
Naval research logistics quarterly , publisher =
An algorithm for quadratic programming , author =. Naval research logistics quarterly , publisher =
-
[12]
, author =
The magical number seven, plus or minus two: Some limits on our capacity for processing information. , author =. Psych. review , publisher =
-
[13]
IRE Trans
An optimum character recognition system using decision functions , author =. IRE Trans. Electron. Comput. , volume = 6, pages =
-
[14]
, author =
The perceptron: a probabilistic model for information storage and organization in the brain. , author =. Psychological review , publisher =
-
[15]
IBM Journal of Research and Development , volume = 3, number = 3, pages =
Some Studies in Machine Learning Using the Game of Checkers , author =. IBM Journal of Research and Development , volume = 3, number = 3, pages =
-
[16]
The Annals of Mathematical Statistics , volume = 30, number = 4, pages =
Random graphs , author =. The Annals of Mathematical Statistics , volume = 30, number = 4, pages =
-
[17]
Papers Presented at the the March 3-5, 1959, Western Joint Computer Conference , publisher =
An Approach to Computers That Perceive, Learn, and Reason , author =. Papers Presented at the the March 3-5, 1959, Western Joint Computer Conference , publisher =. doi:10.1145/1457838.1457870 , url =
-
[18]
Programs with common sense , author =
-
[19]
Educational and psychological measurement , publisher =
A coefficient of agreement for nominal scales , author =. Educational and psychological measurement , publisher =
-
[20]
On the evolution of random graphs , author =. Publ. Math. Inst. Hung. Acad. Sci , volume = 5, number = 1, pages =
-
[21]
British Journal for the Philosophy of Science , volume = 16, number = 62, url =
Models and analogies in science , author =. British Journal for the Philosophy of Science , volume = 16, number = 62, url =
-
[22]
Psychology Today , volume = 2, pages =
Six degrees of separation , author =. Psychology Today , volume = 2, pages =
-
[23]
IEEE transactions on Systems Science and Cybernetics , publisher =
A formal basis for the heuristic determination of minimum cost paths , author =. IEEE transactions on Systems Science and Cybernetics , publisher =
-
[24]
Applications of theorem proving to problem solving , author =
-
[25]
Convex Analysis , author =
-
[26]
Biometrika , publisher =
Monte Carlo sampling methods using Markov chains and their applications , author =. Biometrika , publisher =
-
[27]
Machine Intelligence , publisher =
First results on the effect of error in heuristic search , author =. Machine Intelligence , publisher =
-
[28]
Space/Time Trade-Offs in Hash Coding with Allowable Errors , author =
-
[29]
Procedures as a representation for data in a computer program for understanding natural language , author =
-
[30]
Joseph L.\ Fleiss , year = 1971, journal =
1971
-
[31]
, author =
Measuring nominal scale agreement among many raters. , author =. Psychological bulletin , publisher =
-
[32]
Reducibility among combinatorial problems , author =
-
[33]
The Theory of Parsing, Translation and Compiling , author =
-
[34]
, author =
Toward a model of children's story comprehension. , author =
-
[35]
Cognitive psychology , publisher =
Understanding natural language , author =. Cognitive psychology , publisher =
-
[36]
Episodic and semantic memory , author =
-
[37]
Zimbardo, Philip G , year = 1973, journal =
1973
-
[38]
The american statistician , publisher =
Graphs in statistical analysis , author =. The american statistician , publisher =
-
[39]
A framework for representing knowledge , author =
-
[40]
Collected papers of charles sanders peirce , author =
-
[41]
Interpolation and approximation , author =
-
[42]
Information sciences , publisher =
The concept of a linguistic variable and its application to approximate reasoning--I , author =. Information sciences , publisher =
-
[43]
, year = 1976, url =
McCarthy, J. , year = 1976, url =. An example for natural language understanding and the
1976
-
[44]
IEEE Transactions on Computers , volume = 25, pages =
A Semantically Guided Deductive System for Automatic Theorem Proving , author =. IEEE Transactions on Computers , volume = 25, pages =. doi:10.1109/TC.1976.1674613 , issn =
-
[45]
Proceedings of the Conference Series in Applied Mathematics , volume = 25, url =
The stability of dynamical systems, society for industrial and applied mathematics , author =. Proceedings of the Conference Series in Applied Mathematics , volume = 25, url =
-
[46]
Wendy G Lehnert , year = 1977, school =
1977
-
[47]
biometrics , pages =
The measurement of observer agreement for categorical data , author =. biometrics , pages =
-
[48]
Representations of Knowledge in a Program for Solving Physics Problems , author =
-
[49]
A conceptual theory of question answering , author =
-
[50]
, author =
Script application: computer understanding of newspaper stories. , author =
-
[51]
, author =
Understanding goal-based stories. , author =
-
[52]
Stochastic models, estimation and control , author =
-
[53]
The Annals of statistics , pages =
Conjugate priors for exponential families , author =. The Annals of statistics , pages =
-
[54]
Theoretical computer science , publisher =
The complexity of computing the permanent , author =. Theoretical computer science , publisher =
-
[55]
The Need for Biases in Learning Generalizations , author =
-
[56]
ACM Transactions on Programming Languages and Systems (TOPLAS) , publisher =
A deductive approach to program synthesis , author =. ACM Transactions on Programming Languages and Systems (TOPLAS) , publisher =
-
[57]
Artificial Intelligence , volume = 13, pages =
Extended Inference Modes in Reasoning by Computer Systems , author =. Artificial Intelligence , volume = 13, pages =
-
[58]
Child Development , publisher =
Developmental patterns in the solution of verbal analogies , author =. Child Development , publisher =
-
[59]
Cognitive psychology , publisher =
Analogical problem solving , author =. Cognitive psychology , publisher =
-
[60]
Cognitive science , publisher =
Mental models in cognitive science , author =. Cognitive science , publisher =
-
[61]
Communications of the ACM , publisher =
Learning and reasoning by analogy , author =. Communications of the ACM , publisher =
-
[62]
Journal of instructional development , publisher =
The use of positive and negative examples during instruction , author =. Journal of instructional development , publisher =
-
[63]
Journal of the Association for Computing Machinery , volume = 28, number = 1, pages =
Alternation , author =. Journal of the Association for Computing Machinery , volume = 28, number = 1, pages =
-
[64]
Mathematics of operations research , publisher =
Optimal auction design , author =. Mathematics of operations research , publisher =
-
[65]
Transactions of the American Mathematical Society , volume = 267, number = 1, pages =
The diameter of random graphs , author =. Transactions of the American Mathematical Society , volume = 267, number = 1, pages =
-
[66]
Cognitive Skills and Their Acquisition , publisher =
Mechanisms of Skill Acquisition and the Law of Practice , author =. Cognitive Skills and Their Acquisition , publisher =
-
[67]
Readings in artificial intelligence , publisher =
Some philosophical problems from the standpoint of artificial intelligence , author =. Readings in artificial intelligence , publisher =
-
[68]
Problem complexity and method efficiency in optimization , author =
-
[69]
Publications Manual , author =
-
[70]
The presocratic philosophers: A critical history with a selcetion of texts , author =
-
[71]
Cognitive science , publisher =
Structure-mapping: A theoretical framework for analogy , author =. Cognitive science , publisher =
-
[72]
Framing: Toward Clarification of a Fractured Paradigm , author =
-
[73]
A method of solving a convex programming problem with convergence rate O bigl(k\^
Nesterov, Yurii Evgen'evich , year = 1983, booktitle =. A method of solving a convex programming problem with convergence rate O bigl(k\^
1983
-
[74]
Machine learning , publisher =
Learning by analogy: Formulating and generalizing plans from past experience , author =. Machine learning , publisher =
-
[75]
, author =
The Copycat Project: An Experiment in Nondeterminism and Creative Analogies. , author =
-
[76]
Artificial Intelligence , volume = 23, number = 2, pages =
Foundations of a functional approach to knowledge representation , author =. Artificial Intelligence , volume = 23, number = 2, pages =
-
[77]
Communications of the ACM , publisher =
A theory of the learnable , author =. Communications of the ACM , publisher =
-
[78]
IEEE Transactions on Acoustics, Speech, and Signal Processing , publisher =
Estimation of probabilities in the language model of the IBM speech recognition system , author =. IEEE Transactions on Acoustics, Speech, and Signal Processing , publisher =
-
[79]
Journal of management information systems , publisher =
Fighting information pollution with decision support systems , author =. Journal of management information systems , publisher =
-
[80]
Selected Areas in Communications, IEEE Journal on , publisher =
Techniques for estimating the bit error rate in the simulation of digital communication systems , author =. Selected Areas in Communications, IEEE Journal on , publisher =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.