LIST3R: Long-sequence Instance-aware 3D Reconstruction
Pith reviewed 2026-07-02 15:06 UTC · model grok-4.3
The pith
Persistent instance anchors reconnect video subsequences to produce consistent global 3D reconstructions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
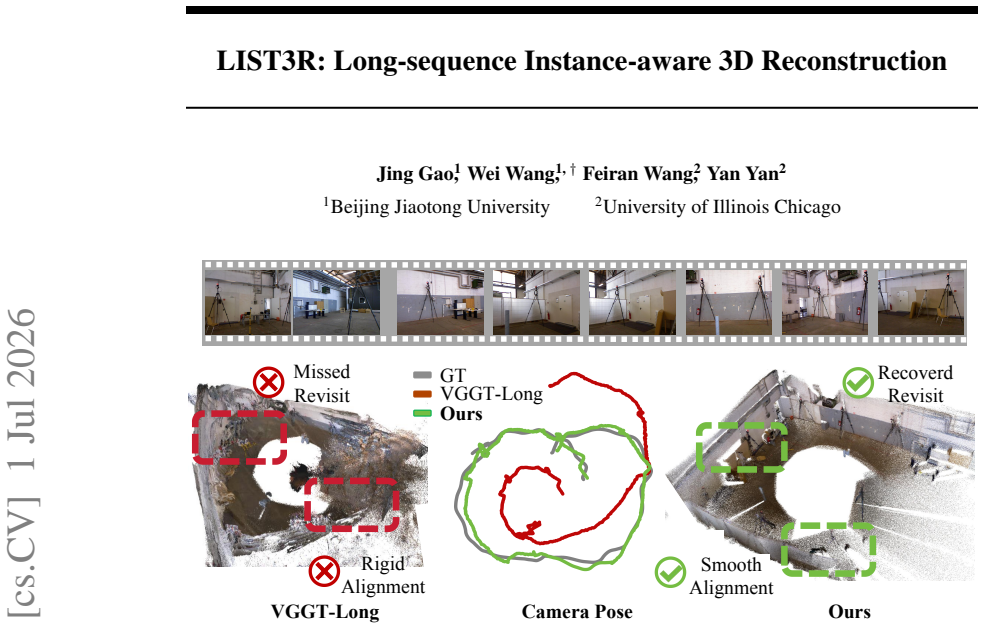
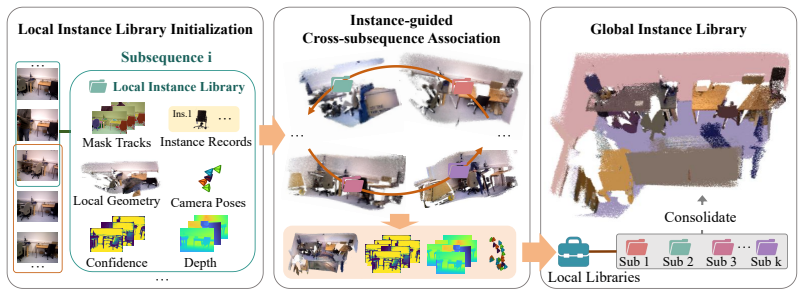
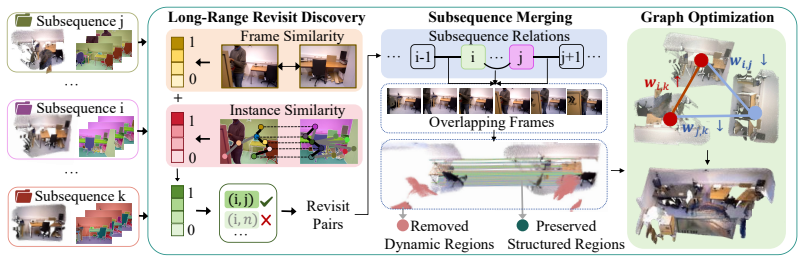
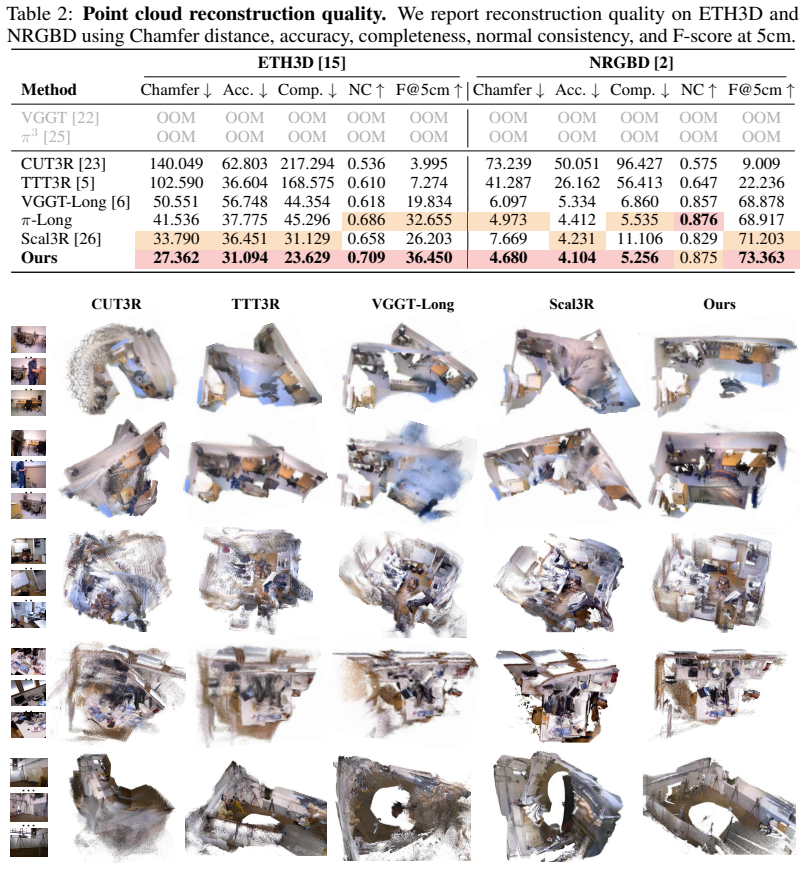
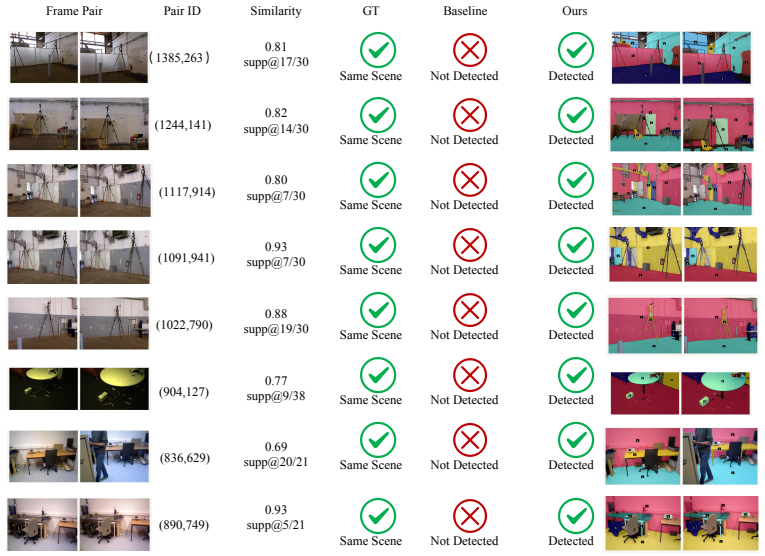
Given a long video, the method partitions it into overlapping subsequences, builds structured local instance libraries that keep persistent trackable anchors with semantic and geometric evidence, matches those anchors across subsequences to recover revisited regions and enforce object-aware alignment constraints, and progressively updates the libraries until they form a unified global 3D instance library that yields a single consistent reconstruction.
What carries the argument
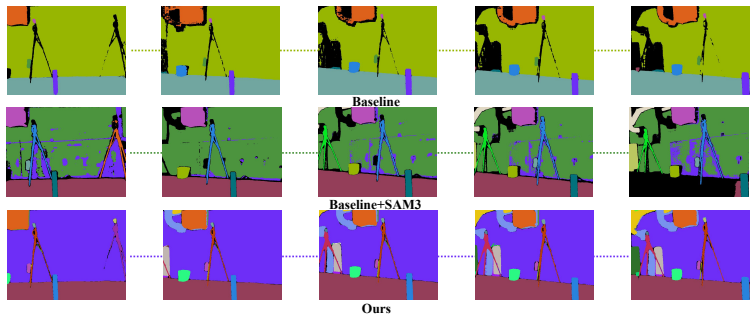
Persistent instance anchors: stable objects that carry semantic and geometric evidence to enable cross-subsequence matching and object-aware fragment alignment.
If this is right
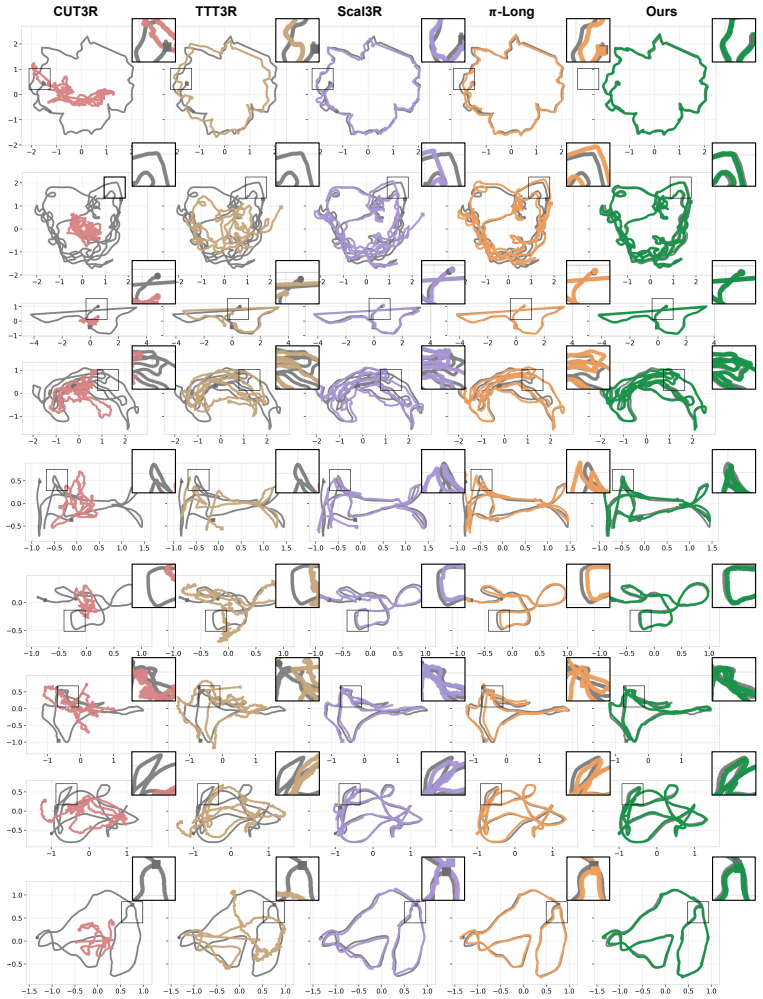
- More accurate camera trajectories result from the additional object-aware constraints supplied by matched anchors.
- Higher-quality 3D reconstructions are obtained because local observations are consolidated around consistent instance identities rather than drifting independently.
- Revisited regions are reconnected without requiring exhaustive global optimization at every step.
- Local instance libraries evolve into a unified global library that maintains object-level organization throughout the process.
Where Pith is reading between the lines
- Object-centric constraints may scale better than purely geometric loop closure when sequences grow to hours rather than minutes.
- The same anchor-matching logic could be tested on dynamic scenes by allowing anchors to update their geometric descriptors over time.
- Robotics navigation systems that already maintain object maps might integrate this alignment step to reduce map fragmentation in extended environments.
Load-bearing premise
Instance anchors can be reliably detected, persistently tracked, and correctly matched across subsequences without introducing alignment errors that propagate through the global reconstruction.
What would settle it
Running the method on standard long-sequence benchmarks and finding no improvement in trajectory accuracy or reconstruction quality relative to non-instance-aware baselines would falsify the central claim.
Figures





read the original abstract
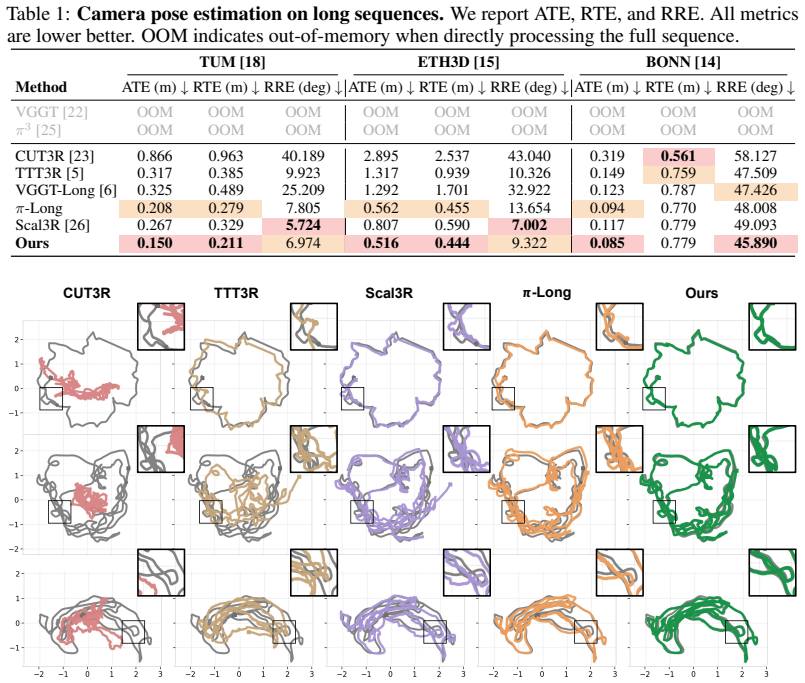
We present LIST3R, an instance-aware framework for long-sequence 3D reconstruction inspired by the way humans organize spatial memory around stable and recognizable objects. LIST3R organizes long-sequence reconstruction around instance anchors, using them to reconnect fragmented subsequences and consolidate local observations into a coherent global 3D scene. Given a long video, our approach partitions it into overlapping subsequences and builds a structured local instance library for each partial reconstruction, maintaining persistent trackable anchors with semantic and geometric evidence. These anchors are matched across subsequences to recover revisited regions and provide object-aware constraints for fragment alignment, producing a consistent global reconstruction. During this process, the evolving geometric evidence updates the local instance libraries and progressively organizes them into a unified global 3D instance library. Experiments on long-sequence benchmarks show that our method produces more accurate trajectories and higher-quality 3D reconstructions, highlighting the effectiveness of persistent instance anchors for organizing long-horizon 3D reconstruction. Our code is available on the project page: https://yixn965.github.io/LIST3R/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents LIST3R, an instance-aware framework for long-sequence 3D reconstruction. It partitions input videos into overlapping subsequences, constructs local instance libraries maintaining persistent trackable anchors with semantic and geometric evidence, matches anchors across subsequences to recover revisited regions and supply object-aware alignment constraints, and progressively consolidates local libraries into a unified global 3D instance library. The central claim is that this organization around persistent instance anchors yields more accurate trajectories and higher-quality 3D reconstructions on long-sequence benchmarks, with code released at the project page.
Significance. If the performance claims are substantiated, the approach could meaningfully advance long-horizon reconstruction by using stable object instances to mitigate fragmentation and supply additional consistency constraints beyond pure geometric features. The public code release is a clear strength for reproducibility.
major comments (2)
- [Abstract] Abstract: the claim that 'experiments on long-sequence benchmarks show that our method produces more accurate trajectories and higher-quality 3D reconstructions' supplies no quantitative results, baselines, error bars, or experimental details, so the data-to-claim link cannot be evaluated.
- [Abstract] Abstract (pipeline description): the cross-subsequence anchor matching step is described only at a high level ('matched across subsequences to recover revisited regions and provide object-aware constraints') with no algorithm, similarity metric, threshold, or failure-mode analysis; because an incorrect match would inject erroneous relative-pose or object-consistency terms into the global optimization, this assumption is load-bearing for the trajectory-accuracy claim yet remains unverified.
minor comments (1)
- [Abstract] Abstract: the sentence on updating local libraries and organizing them into a global library could be clarified to distinguish what is updated versus what is newly created.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each point below and will revise the manuscript to improve clarity where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'experiments on long-sequence benchmarks show that our method produces more accurate trajectories and higher-quality 3D reconstructions' supplies no quantitative results, baselines, error bars, or experimental details, so the data-to-claim link cannot be evaluated.
Authors: We agree that the abstract would be strengthened by including specific quantitative support for the performance claims. In the revised version, we will incorporate key results (e.g., relative trajectory error reductions and reconstruction metrics versus baselines) with references to the corresponding tables and figures. revision: yes
-
Referee: [Abstract] Abstract (pipeline description): the cross-subsequence anchor matching step is described only at a high level ('matched across subsequences to recover revisited regions and provide object-aware constraints') with no algorithm, similarity metric, threshold, or failure-mode analysis; because an incorrect match would inject erroneous relative-pose or object-consistency terms into the global optimization, this assumption is load-bearing for the trajectory-accuracy claim yet remains unverified.
Authors: Abstracts conventionally provide high-level pipeline summaries. The full algorithm for anchor matching—including the combined semantic-geometric similarity metric, adaptive thresholds, and robust outlier rejection via the global optimization—is detailed in Section 3.2. Section 4 presents quantitative validation on long-sequence benchmarks together with ablations that isolate the contribution of cross-subsequence matching; these results directly support the trajectory-accuracy claim. We can add a concise reference to the matching criteria in the abstract if the referee prefers. revision: partial
Circularity Check
No circularity: algorithmic framework with experimental validation only
full rationale
The paper describes an instance-aware pipeline for partitioning videos, maintaining local instance libraries, matching anchors across subsequences, and producing global reconstructions. No equations, fitted parameters presented as predictions, self-definitional steps, or load-bearing self-citations appear in the abstract or described method. Effectiveness claims rest on benchmark experiments rather than any derivation that reduces to its own inputs by construction. The central assumption about reliable anchor matching is an empirical premise, not a circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Robust map optimization using dynamic covariance scaling
Pratik Agarwal, Gian Diego Tipaldi, Luciano Spinello, Cyrill Stachniss, and Wolfram Burgard. Robust map optimization using dynamic covariance scaling. In2013 IEEE international conference on robotics and automation, pages 62–69. Ieee, 2013
2013
-
[2]
Neural rgb-d surface reconstruction
Dejan Azinovi´c, Ricardo Martin-Brualla, Dan B Goldman, Matthias Nießner, and Justus Thies. Neural rgb-d surface reconstruction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6290–6301, 2022
2022
-
[3]
Cognitive mapping style relates to posterior–anterior hippocampal volume ratio.Hippocampus, 29(8):748–754, 2019
Iva K Brunec, Jessica Robin, Eva Zita Patai, Jason D Ozubko, Amir-Homayoun Javadi, Morgan D Barense, Hugo J Spiers, and Morris Moscovitch. Cognitive mapping style relates to posterior–anterior hippocampal volume ratio.Hippocampus, 29(8):748–754, 2019
2019
-
[4]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
TTT3R: 3D Reconstruction as Test-Time Training
Xingyu Chen, Yue Chen, Yuliang Xiu, Andreas Geiger, and Anpei Chen. Ttt3r: 3d reconstruction as test-time training.arXiv preprint arXiv:2509.26645, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Kai Deng, Zexin Ti, Jiawei Xu, Jian Yang, and Jin Xie. Vggt-long: Chunk it, loop it, align it–pushing vggt’s limits on kilometer-scale long rgb sequences.arXiv preprint arXiv:2507.16443, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
DiCarlo and David D
James J. DiCarlo and David D. Cox. Untangling invariant object recognition.Trends in Cognitive Sciences, 11(8):333–341, aug 2007
2007
-
[8]
DiCarlo, Davide Zoccolan, and Nicole C
James J. DiCarlo, Davide Zoccolan, and Nicole C. Rust. How does the brain solve visual object recognition? Neuron, 73(3):415–434, feb 2012
2012
-
[9]
A cortical representation of the local visual environment.Nature, 392(6676):598–601, apr 1998
Russell Epstein and Nancy Kanwisher. A cortical representation of the local visual environment.Nature, 392(6676):598–601, apr 1998
1998
-
[10]
Selective neural representation of objects relevant for navigation.Nature Neuroscience, 7(6):673–677, jun 2004
Gabriele Janzen and Miranda van Turennout. Selective neural representation of objects relevant for navigation.Nature Neuroscience, 7(6):673–677, jun 2004
2004
-
[11]
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
Nikhil Keetha, Norman Müller, Johannes Schönberger, Lorenzo Porzi, Yuchen Zhang, Tobias Fischer, Arno Knapitsch, Duncan Zauss, Ethan Weber, Nelson Antunes, et al. Mapanything: Universal feed-forward metric 3d reconstruction.arXiv preprint arXiv:2509.13414, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Grounding image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and Jérôme Revaud. Grounding image matching in 3d with mast3r. In European conference on computer vision, pages 71–91. Springer, 2024
2024
-
[13]
Précis of O’Keefe & Nadel’s The Hippocampus as a Cognitive Map
John O’Keefe and Lynn Nadel. Précis of O’Keefe & Nadel’s The Hippocampus as a Cognitive Map. Behavioral and Brain Sciences, 2(4):487–494, 1979
1979
-
[14]
Refusion: 3d reconstruction in dynamic environments for rgb-d cameras exploiting residuals
Emanuele Palazzolo, Jens Behley, Philipp Lottes, Philippe Giguere, and Cyrill Stachniss. Refusion: 3d reconstruction in dynamic environments for rgb-d cameras exploiting residuals. In2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 7855–7862. IEEE, 2019
2019
-
[15]
Bad slam: Bundle adjusted direct rgb-d slam
Thomas Schops, Torsten Sattler, and Marc Pollefeys. Bad slam: Bundle adjusted direct rgb-d slam. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 134–144, 2019
2019
-
[16]
A multi-view stereo benchmark with high-resolution images and multi- camera videos
Thomas Schops, Johannes L Schonberger, Silvano Galliani, Torsten Sattler, Konrad Schindler, Marc Pollefeys, and Andreas Geiger. A multi-view stereo benchmark with high-resolution images and multi- camera videos. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3260–3269, 2017
2017
-
[17]
Scale drift-aware large scale monocular slam.Robotics: science and Systems VI, 2(3):7, 2010
Hauke Strasdat, J Montiel, Andrew J Davison, et al. Scale drift-aware large scale monocular slam.Robotics: science and Systems VI, 2(3):7, 2010
2010
-
[18]
A benchmark for the evaluation of rgb-d slam systems
Jürgen Sturm, Nikolas Engelhard, Felix Endres, Wolfram Burgard, and Daniel Cremers. A benchmark for the evaluation of rgb-d slam systems. In2012 IEEE/RSJ international conference on intelligent robots and systems, pages 573–580. IEEE, 2012
2012
-
[19]
Switchable constraints for robust pose graph slam
Niko Sünderhauf and Peter Protzel. Switchable constraints for robust pose graph slam. In2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 1879–1884. IEEE, 2012. 10
2012
-
[20]
Least-squares estimation of transformation parameters between two point patterns.IEEE Transactions on pattern analysis and machine intelligence, 13(4):376–380, 2002
Shinji Umeyama. Least-squares estimation of transformation parameters between two point patterns.IEEE Transactions on pattern analysis and machine intelligence, 13(4):376–380, 2002
2002
-
[21]
Cognimap3d: Cognitive 3d mapping and rapid retrieval.arXiv preprint arXiv:2601.08175, 2026
Feiran Wang, Junyi Wu, Dawen Cai, Yuan Hong, and Yan Yan. Cognimap3d: Cognitive 3d mapping and rapid retrieval.arXiv preprint arXiv:2601.08175, 2026
-
[22]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
2025
-
[23]
Continuous 3d perception model with persistent state
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A Efros, and Angjoo Kanazawa. Continuous 3d perception model with persistent state. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10510–10522, 2025
2025
-
[24]
Dust3r: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vision made easy. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20697–20709, 2024
2024
-
[25]
$\pi^3$: Permutation-Equivariant Visual Geometry Learning
Yifan Wang, Jianjun Zhou, Haoyi Zhu, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Jiangmiao Pang, Chunhua Shen, and Tong He. π3: Permutation-equivariant visual geometry learning.arXiv preprint arXiv:2507.13347, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Scal3R: Scalable Test-Time Training for Large-Scale 3D Reconstruction
Tao Xie, Peishan Yang, Yudong Jin, Yingfeng Cai, Wei Yin, Weiqiang Ren, Qian Zhang, Wei Hua, Sida Peng, Xiaoyang Guo, et al. Scal3r: Scalable test-time training for large-scale 3d reconstruction.arXiv preprint arXiv:2604.08542, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass
Jianing Yang, Alexander Sax, Kevin J Liang, Mikael Henaff, Hao Tang, Ang Cao, Joyce Chai, Franziska Meier, and Matt Feiszli. Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 21924–21935, 2025
2025
-
[28]
Entitysam: Segment everything in video
Mingqiao Ye, Seoung Wug Oh, Lei Ke, and Joon-Young Lee. Entitysam: Segment everything in video. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 24234–24243, 2025. 11 Appendix Table of Contents A Additional Implementation Details. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.