MNAR-k-means: A k-means Clustering for Data Missing Not at Random with Magnitude-Decaying Probability
Pith reviewed 2026-07-01 04:26 UTC · model grok-4.3
The pith
A constrained k-means variant recovers true cluster centers from magnitude-decaying MNAR data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under a magnitude-decaying MNAR mechanism, adding a size constraint on the imputed values to the k-means objective produces cluster-center estimates that are statistically consistent for the centers of the fully observed data.
What carries the argument
A magnitude constraint on imputed values inside the k-means loss, solved by alternating minimization between cluster assignments and center updates.
If this is right
- Estimated centers remain consistent for the complete-data centers as sample size grows.
- Clustering assignments improve relative to mean-imputation k-means on the same MNAR data.
- The alternating algorithm converges to a stationary point of the constrained objective.
- Bias in center estimates decreases as the decay rate of missingness increases.
Where Pith is reading between the lines
- The same size-constraint idea could be inserted into other distance-based procedures such as hierarchical clustering.
- Real-world sensor or survey data often exhibit exactly this magnitude-decaying missing pattern and would therefore be a natural test bed.
- Extending the consistency proof to the case of unknown decay rate would require an additional estimation step for that rate.
Load-bearing premise
Missingness probability decreases as the absolute value of each entry increases.
What would settle it
Generate fully observed data with known centers, impose missingness whose probability does not decay with magnitude, run the method, and check whether the recovered centers still converge to the true centers.
Figures
read the original abstract
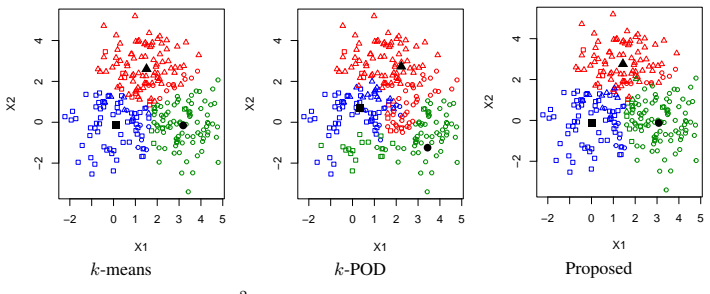
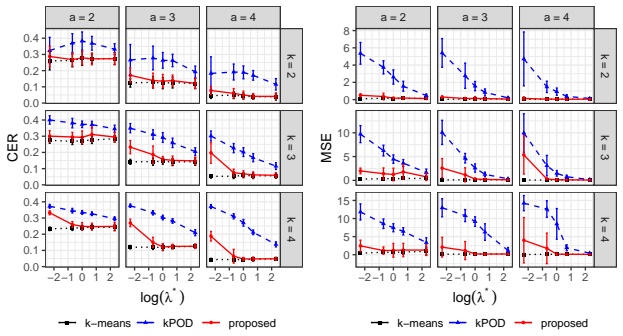
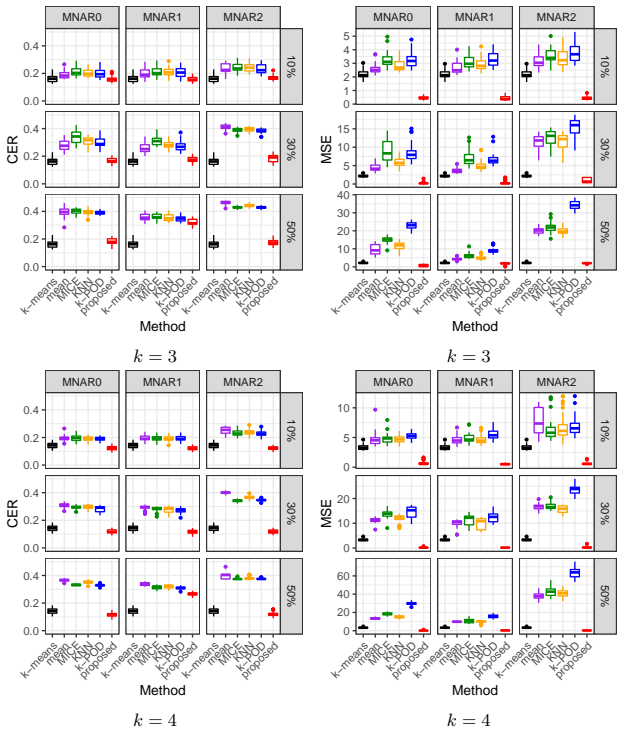
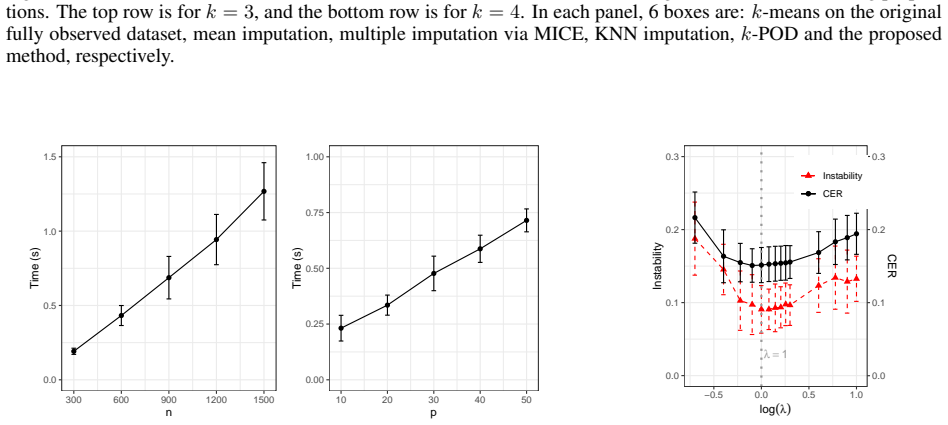
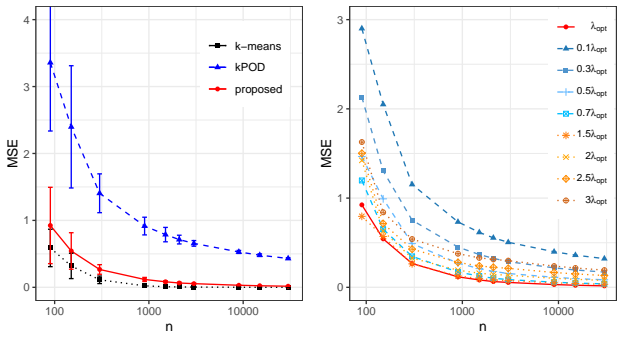
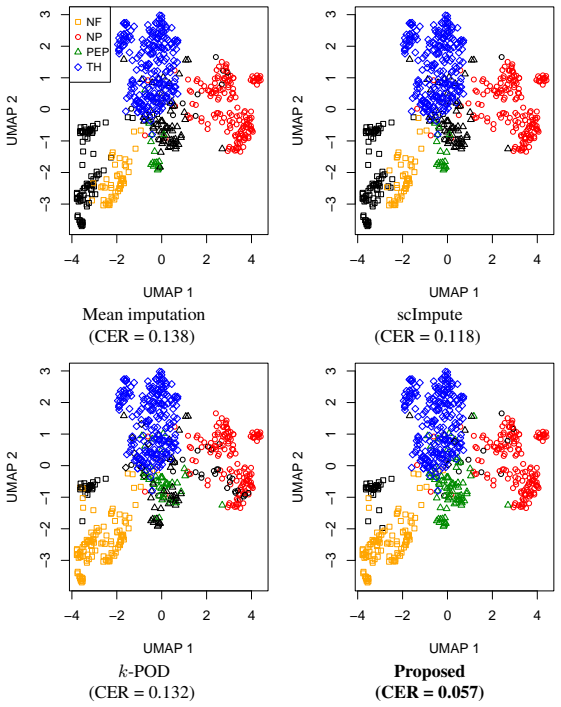
The classical $k$-means clustering, based on distances computed from all data features, cannot be directly applied to incomplete data with missing values. A natural extension of $k$-means to missing data is to involve only the observed positions in clustering, which is equivalent to imputing missing values by corresponding cluster means. However, for data missing not at random (MNAR), since missingness is related to data values, such a mean-imputation-based method may lead to the distortion of estimated cluster centers, resulting in a poor clustering result. Since MNAR mechanisms are very common in reality, it is necessary to improve the performance of $k$-means-based clustering methods for such data. In this paper, we focus on a magnitude-decaying MNAR scenario where data is more likely to be missing at positions with smaller absolute values, and we propose a novel $k$-means clustering method based on the constraint of the size of imputation values, which enjoys a good mathematical interpretation. Moreover, we establish the statistical consistency of the estimated cluster centers of the proposed method to the true cluster centers of fully observed data, and solve the optimization of the proposed loss function via an alternative minimization algorithm. Simulation experiments verify the effect of the proposed method in improving clustering results and reducing the bias of estimated cluster centers. Applications to real-world missing data further show the utility of the proposed method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MNAR-k-means, a constrained variant of k-means for magnitude-decaying MNAR data that imputes missing entries subject to a size constraint on the imputed values. It claims to prove statistical consistency of the resulting cluster-center estimates to the centers that would be obtained from the fully observed data, solves the finite-sample objective via alternating minimization, and reports improved performance in simulations and real-data examples relative to standard mean-imputation k-means.
Significance. If the consistency result holds for the estimator that is actually computed, the method would supply a theoretically supported clustering procedure for a practically relevant MNAR regime and could reduce bias relative to naive imputation approaches.
major comments (2)
- [Abstract / theoretical analysis] Abstract and theoretical-results section: the consistency statement is phrased for 'the estimated cluster centers of the proposed method,' yet the only optimization procedure described is alternating minimization. No convergence guarantee to a global minimizer (or even to a stationary point whose limit is consistent) is indicated; therefore the headline consistency claim does not automatically transfer to the implemented estimator.
- [Theoretical analysis] Consistency theorem (presumably the main result): if the theorem is stated only for the population or sample minimizer of the constrained loss, an additional argument is required to show that the alternating-minimization sequence inherits the same limit; without it the central claim is not fully supported by the stated theory.
minor comments (1)
- [Model section] The precise functional form of the magnitude-decaying missingness probability (e.g., the decay rate or the threshold) should be stated explicitly in the model definition rather than left at the level of the abstract description.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the distinction between the theoretical minimizer and the output of the alternating-minimization procedure. We address each major comment below and will revise the manuscript accordingly to make the scope of the consistency result precise.
read point-by-point responses
-
Referee: [Abstract / theoretical analysis] Abstract and theoretical-results section: the consistency statement is phrased for 'the estimated cluster centers of the proposed method,' yet the only optimization procedure described is alternating minimization. No convergence guarantee to a global minimizer (or even to a stationary point whose limit is consistent) is indicated; therefore the headline consistency claim does not automatically transfer to the implemented estimator.
Authors: We agree that the consistency theorem applies to the global minimizer of the constrained objective rather than directly to the output of any particular solver. The manuscript presents alternating minimization solely as a computational method for the finite-sample problem. In the revision we will update the abstract and the theoretical-results section to state explicitly that consistency holds for the minimizer of the proposed loss; we will also add a brief discussion noting that alternating minimization is used in practice and that its empirical behavior is examined in the simulation studies. revision: yes
-
Referee: [Theoretical analysis] Consistency theorem (presumably the main result): if the theorem is stated only for the population or sample minimizer of the constrained loss, an additional argument is required to show that the alternating-minimization sequence inherits the same limit; without it the central claim is not fully supported by the stated theory.
Authors: The observation is correct: an additional argument linking the iterates of alternating minimization to the consistent minimizer would be needed to transfer the limit result. Because establishing such a guarantee for the non-convex alternating procedure lies outside the present scope, we will revise the manuscript to restrict the consistency claim to the exact minimizer of the constrained loss and to clarify the role of the algorithm as a practical approximation whose performance is supported by the reported experiments. revision: yes
Circularity Check
No circularity: consistency targets external true centers of fully observed data
full rationale
The paper defines a constrained k-means loss for magnitude-decaying MNAR data and claims statistical consistency of its estimated centers to the true centers of the fully observed data. This target is external and independent of the method's fitted values. The alternating minimization is presented only as a computational solver for the loss; no equation or self-citation reduces the consistency statement to a tautology, a fitted parameter renamed as prediction, or a self-referential definition. The derivation chain therefore remains self-contained against the stated external benchmark.
Axiom & Free-Parameter Ledger
free parameters (1)
- imputation size constraint threshold
axioms (1)
- domain assumption Missingness occurs with probability that decays with absolute magnitude (magnitude-decaying MNAR)
Reference graph
Works this paper leans on
-
[1]
doi: https://doi.org/10.1016/j.knosys.2019.07.009
ISSN 0950-7051. doi: https://doi.org/10.1016/j.knosys.2019.07.009. S. Datta, S. Bhattacharjee, and S. Das. Clustering with missing features: a penalized dissimilarity measure based approach.Machine Learning, 107:1987–2025,
-
[2]
doi: https://doi.org/10.1016/j.patcog.2015.10.001
ISSN 0031-3203. doi: https://doi.org/10.1016/j.patcog.2015.10.001. Z. Ghahramani and M. I. Jordan. Learning from incomplete data. Technical Report AIM-1509CBCL-108, Mas- sachusetts Institute of Technology,
-
[3]
doi: https://doi.org/10.1016/j.ins.2010.12.017
ISSN 0020-0255. doi: https://doi.org/10.1016/j.ins.2010.12.017. J. Jin and W. Wang. Influential features pca for high dimensional clustering.The Annals of Statistics, 44(6):2323 – 2359,
-
[4]
J. Li, S. Song, Y . Zhang, and Z. Zhou. Robust k-median and k-means clustering algorithms for incomplete data. Mathematical Problems in Engineering, 2016(1):4321928,
2016
-
[5]
doi: https://doi.org/10.1016/j.neucom.2016.12.081
ISSN 0925-2312. doi: https://doi.org/10.1016/j.neucom.2016.12.081. Neural Networks : Learning Algorithms and Classification Systems. M. Mohri, A. Rostamizadeh, and A. Talwalkar.Foundations of machine learning. MIT press,
-
[6]
doi: https://doi.org/10.1016/j.neunet.2020.06
ISSN 0893-6080. doi: https://doi.org/10.1016/j.neunet.2020.06
-
[7]
Proof.Consider a function class onX × {0,1} p as follows: Gk = gk,M : (x,r)7→min l=1,...,k pX j=1 rj(xj −µ lj)2 +λ(1−r j)µ2 lj ∀M∈ M,∥µ l∥2 ≤B, l= 1, . . . , k . For a size-nrandom sample of missing data(X,R) ={(x 1,r 1), . . . ,(xn,r n)}, we can write Lλ(M) =E x1,r1 [gk,M (x1,r 1)]and bLλ n(M) = 1 n nX i=1 gk,M (xi,r i). First, we prove the expectationE ...
2002
-
[8]
24√n Z ∥G∥L2 (Pn ) 0 p log(N(τ,G,L 2(Pn)))dτ # =E X,R
Then for anyg µ ∈ G, we have|g µ(x,r)| ≤G(x,r)holds for any(x,r)∈ X × {0,1} p. Under Assumption 2 (i.e., x1 is sub-Gaussian), we haveE x1[∥x1∥4 2]<∞, it follows thatE x1,r1[(G(x1,r 1))2]<∞. We write σ2 G =E x1,r1[(G(x1,r 1))2]. Then, according to Equations (3.8)-(3.13) of Mohri et al. [2018], we have EX,R sup M∈M Lλ(M)− bLλ n(M) ≤2R n(Gk)≤2kR n(G), Thus, ...
2018
-
[9]
sup M∈M 1 n nX i=1 g− k,M (xi,r i) 2 # ≤E X,R
i − 1 n nX i=1 g+ k,M (xi,r i) > ˜ϵ 2 ! :=(I)+(II). 20 Thus, it suffices to prove the two terms converge to zero asn→ ∞. For (I), because ∥g− k,M ∥∞ = sup x,r |g− k,M (x,r)| ≤sup x,r G(x,r)·1(G(x,r)≤ √n) ≤ √n and EX,R " sup M∈M 1 n nX i=1 g− k,M (xi,r i) 2 # ≤E X,R " 1 n nX i=1 (G(xi,r i))2 ·1(G(x i,r i)≤ √n) # ≤E x1,r1 h (G(x1,r 1))2 i =σ 2 G, then accor...
2019
-
[10]
, g1p, g21,
Because anyg µ ∈ Gcan be rewritten as gµ(x,r) = pX j=1 rjx2 j + pX j=1 (−2µj)·(r jxj) + pX j=1 (1−λ)µ 2 j ·r j + pX j=1 λµ2 j = pX j=1 g1j(x,r) + pX j=1 (−2µj)·g 2j(x,r) + pX j=1 (1−λ)µ 2 j ·g 3j(x,r) + pX j=1 λµ2 j ·g 4(x,r), then it is a linear combination of{g 11, . . . , g1p, g21, . . . , g2p, g31 . . . , g3p, g4}, i.e., G ⊂span g11, . . . , g1p, g21,...
2019
-
[11]
is satisfied. Consequently, we can apply the Bernstein inequality (Proposition 2.10 of Wainwright [2019]) to∆ ll′ ij as follows: Pr ∆ll′ ij −E xi h ∆ll′ ij rij = 1,z i =l i ≤ϵ rij = 1,z i =l ≥1−2 exp − ϵ2 2Var(xij |r ij = 1,z i =l) + 2b ljϵ ,∀ϵ >0, 25 which implies Pr ∆ll′ ij ≥E xi h ∆ll′ ij rij = 1,z i =l i −ϵ rij = 1,z i =l ≥1−2 exp − ϵ2 2Var(xij |r ij ...
2019
-
[12]
, n,z ∗∗ i = zi)→ 1under the conditionσ 2 log(n)→0
Because ∥xi −µ ∗∗ l′ ∥2 2 − ∥xi −µ ∗∗ l ∥2 2 = pX j=1 2(µ∗∗ lj −µ ∗∗ l′j)xij + (µ∗∗ l′j)2 −(µ ∗∗ lj )2, and givenz i =l,x ij ∼ N(µ ∗∗ lj , σ2), then by using the same technique, we can obtain Pr(∀i= 1, . . . , n,z ∗∗ i = zi)→ 1under the conditionσ 2 log(n)→0. Combining the consistency results ofˆ z λ i andz ∗∗ i leads to Pr ∀i= 1, . . . , n,ˆ zλ i = z∗∗ i...
1981
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.