Multi-Task Bayesian In-Context Learning
Pith reviewed 2026-06-26 17:34 UTC · model grok-4.3
The pith
A transformer matches exact Bayesian predictors on new priors by treating prior information as an in-context prefix.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
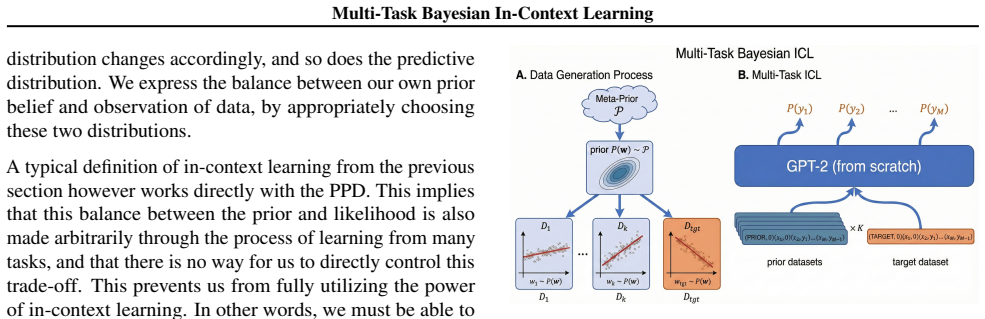
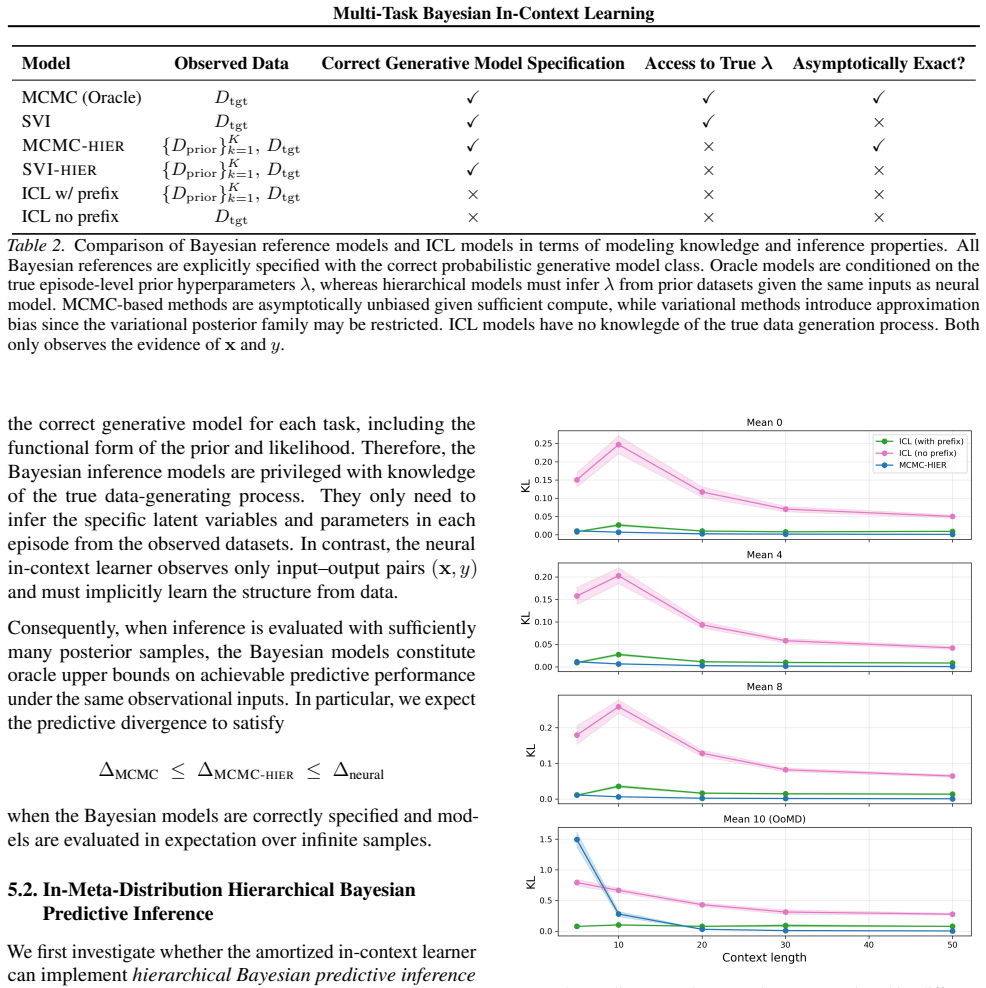
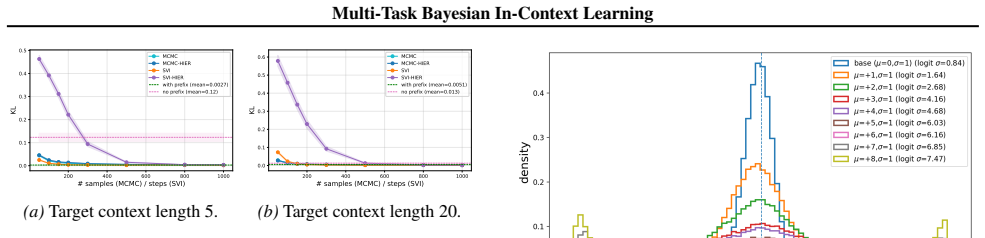
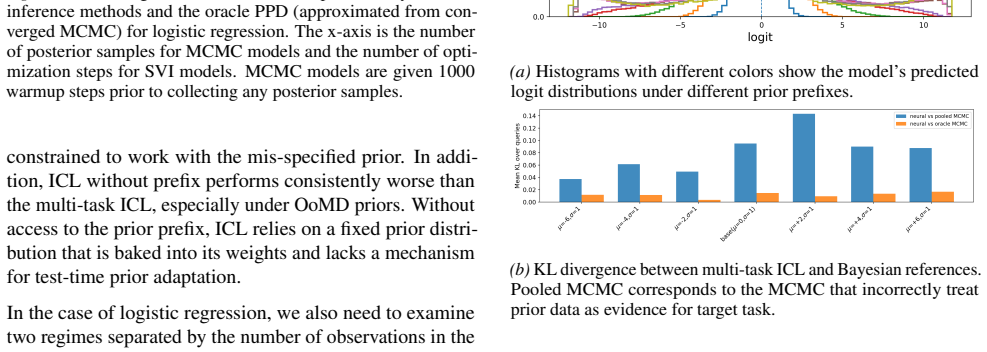
Training a transformer on multi-task sequences that include prior information as an in-context prefix produces an amortized hierarchical Bayesian predictor capable of adapting to new prior families, including those outside the meta-training distribution, with accuracy matching oracle methods at far lower computational cost.
What carries the argument
The multi-task in-context learning framework that represents prior information as a prefix of in-context datasets before the target task sequence.
Load-bearing premise
A transformer can learn to adapt its predictive behavior to entirely new prior families simply by receiving prior datasets as an in-context prefix during both training and inference.
What would settle it
Running the method on a high-dimensional latent structure prior outside the training distribution and finding that its predictions deviate substantially from those of an exact Bayesian oracle.
Figures
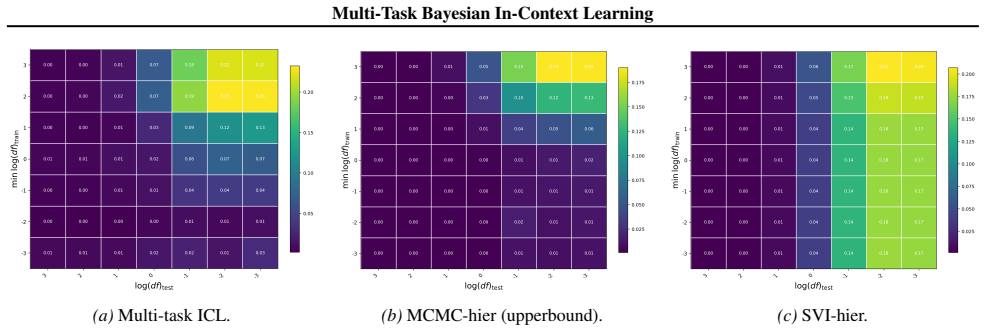
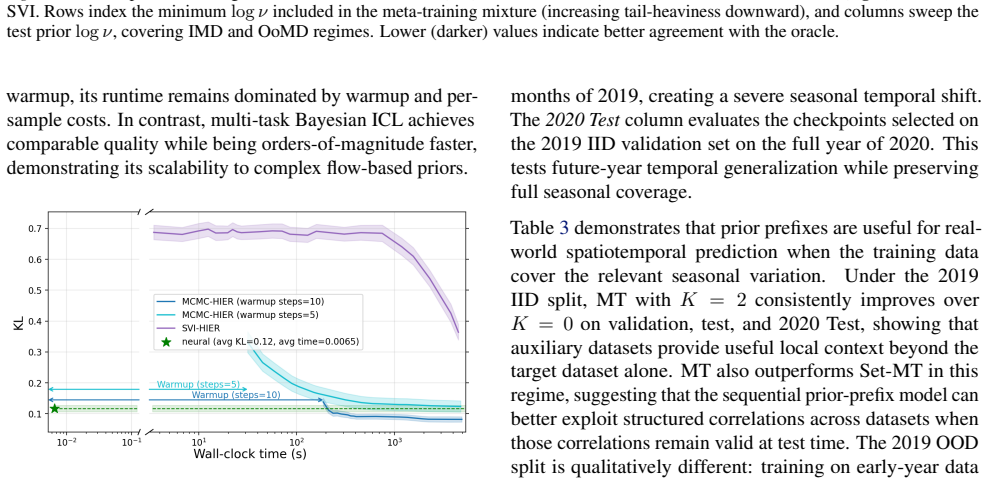

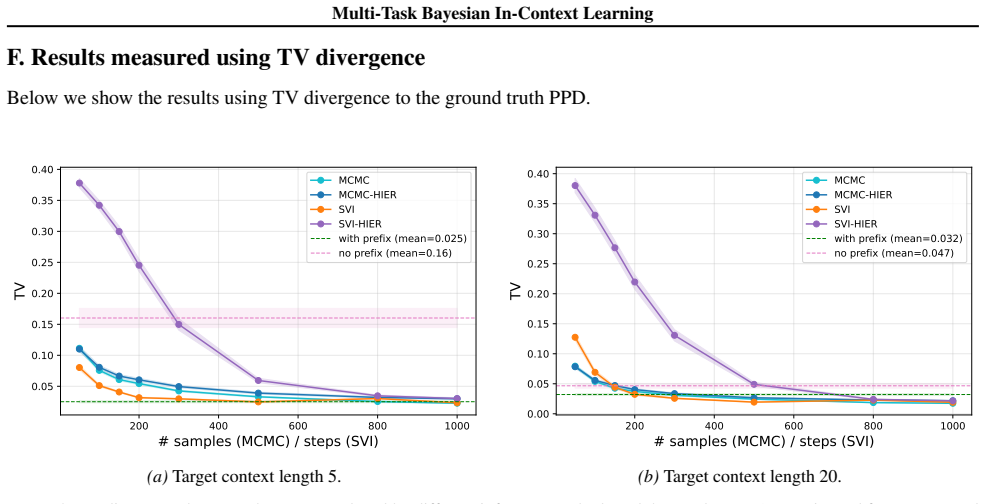
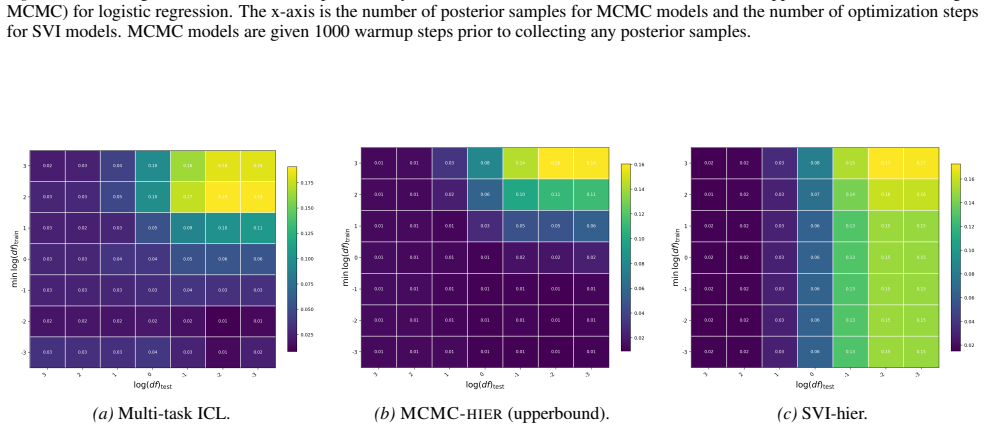
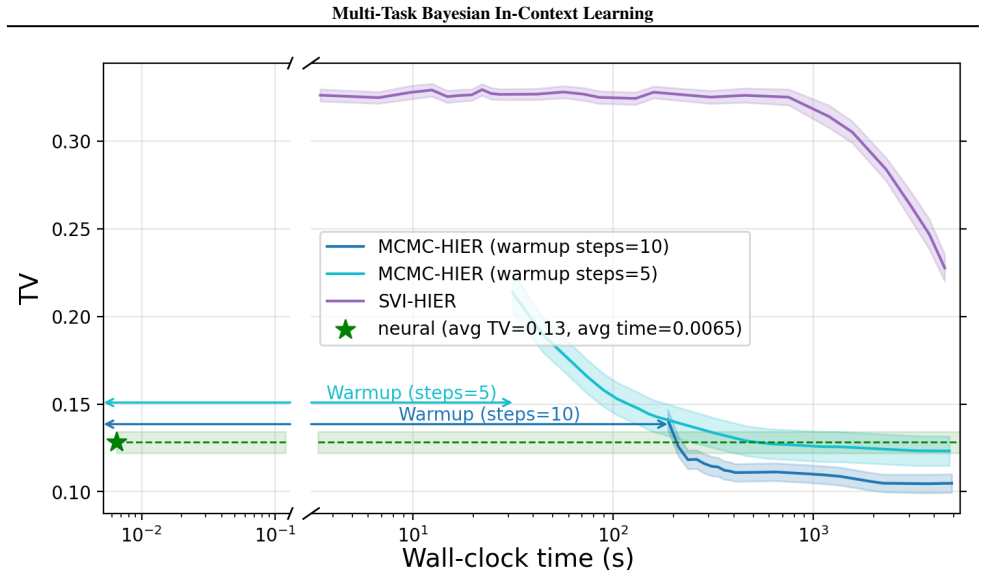
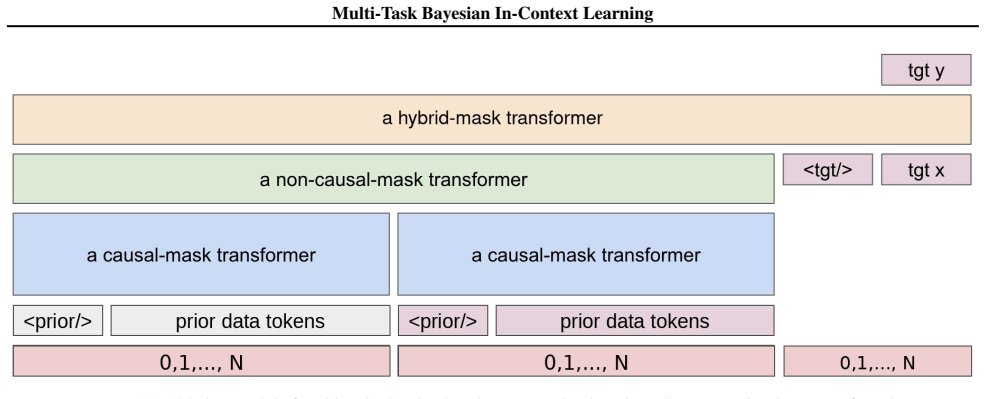
read the original abstract
Bayesian predictive inference provides a principled framework for uncertainty quantification, data efficiency, and robust generalization. However, exact inference is often intractable, and scalable approximations may remain computationally expensive or require restrictive modeling assumptions that degrade predictive performance. Prior-Data Fitted and in-context models have recently emerged as an amortized alternative by learning to map datasets directly to predictive distributions, but existing approaches are tightly coupled to the support of the training prior and lack explicit mechanisms for adapting to new priors at test time, resulting in limited robustness under distribution shift. We introduce a multi-task in-context learning framework for amortized hierarchical Bayesian predictive inference that explicitly represents prior information as a prefix of in-context datasets. A transformer trained on sequences of prior and target tasks learns to adapt its predictions across families of priors. On a suite of evaluations with increasing difficulty, including out-of-meta-distribution priors and priors with high-dimensional latent structures, our method matches oracle Bayesian predictors while being orders of magnitude faster. We further demonstrate its practical relevance on a real-world spatiotemporal temperature prediction benchmark. Code is available at https://github.com/martianmartina/multi-task-bayesian-icl/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a multi-task in-context learning framework for amortized hierarchical Bayesian predictive inference. Prior information is explicitly represented as a prefix of in-context datasets, and a transformer is trained on sequences of prior and target tasks to adapt predictions across families of priors. On evaluations with increasing difficulty (including out-of-meta-distribution priors and high-dimensional latent structures), the method is claimed to match oracle Bayesian predictors while being orders of magnitude faster; results are also shown on a real-world spatiotemporal temperature prediction benchmark. Code is provided.
Significance. If the empirical claims hold, the work offers a scalable amortized alternative to exact or approximate Bayesian inference that can adapt to new priors at test time, addressing a key limitation of prior-data fitted models. Matching oracle performance on OOD and high-dimensional cases, combined with substantial speedups and a real-world demonstration, would be a notable contribution to uncertainty quantification in machine learning. Open-sourcing the code supports reproducibility.
major comments (1)
- Abstract: the central claim that the method 'matches oracle Bayesian predictors' on out-of-meta-distribution priors and high-dimensional latent structures is load-bearing for the contribution, yet the abstract provides no experimental details, error bars, ablation results, or quantitative metrics to allow verification that the data support this assertion.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation for major revision. We address the single major comment below and agree that the abstract can be strengthened for greater transparency.
read point-by-point responses
-
Referee: Abstract: the central claim that the method 'matches oracle Bayesian predictors' on out-of-meta-distribution priors and high-dimensional latent structures is load-bearing for the contribution, yet the abstract provides no experimental details, error bars, ablation results, or quantitative metrics to allow verification that the data support this assertion.
Authors: We agree that the abstract's central claim would benefit from greater specificity to allow readers to assess its support immediately. The full manuscript contains the requested experimental details, including error bars, ablation studies, and quantitative metrics across the OOD and high-dimensional cases. In the revised version we will update the abstract to incorporate brief quantitative indicators (e.g., relative log-likelihood gaps and runtime ratios) drawn directly from the reported results, while remaining within length constraints. This change will be made. revision: yes
Circularity Check
No significant circularity; empirical training and evaluation are self-contained
full rationale
The paper presents an empirical multi-task in-context learning approach where a transformer is trained on sequences of prior and target tasks to adapt predictions across prior families. No equations, derivations, or parameter-fitting steps are described that reduce any claimed prediction or result to the inputs by construction. Central claims rest on evaluations against oracle Bayesian predictors on OOD and high-dimensional cases, with no load-bearing self-citations or ansatzes that collapse the method to its own fitted quantities. This is a standard non-circular empirical setup.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A transformer can learn to map sequences of prior datasets plus target data to adapted predictive distributions across families of priors
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2502.07281 , year=
Supervised Contrastive Block Disentanglement , author=. arXiv preprint arXiv:2502.07281 , year=
-
[2]
Proceedings of the 6th Symposium on Advances in Approximate Bayesian Inference , pages =
Implicitly Bayesian Prediction Rules in Deep Learning , author =. Proceedings of the 6th Symposium on Advances in Approximate Bayesian Inference , pages =. 2024 , editor =
2024
-
[3]
Datos recuperados entre noviembre , year=
ERA5 hourly data on single levels from 1940 to present , author=. Datos recuperados entre noviembre , year=
1940
-
[4]
Su, Jianlin and Ahmed, Murtadha and Lu, Yu and Pan, Shengfeng and Bo, Wen and Liu, Yunfeng , title =. 2024 , issue_date =. doi:10.1016/j.neucom.2023.127063 , journal =
-
[5]
Copernicus climate change service (c3s) climate data store (cds) , volume=
ERA5 hourly data on single levels from 1940 to present , author=. Copernicus climate change service (c3s) climate data store (cds) , volume=
1940
-
[6]
Third Symposium on Advances in Approximate Bayesian Inference , year=
The Gaussian Neural Process , author=. Third Symposium on Advances in Approximate Bayesian Inference , year=
-
[7]
Advances in Neural Information Processing Systems , volume=
Episodic multi-task learning with heterogeneous neural processes , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Meta-in-context learning in large language models , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[9]
International Conference on Learning Representations , year=
Meta-Learning Probabilistic Inference for Prediction , author=. International Conference on Learning Representations , year=
-
[10]
Proceedings of the 6th Symposium on Advances in Approximate Bayesian Inference , pages =
In-Context In-Context Learning with Transformer Neural Processes , author =. Proceedings of the 6th Symposium on Advances in Approximate Bayesian Inference , pages =. 2024 , editor =
2024
-
[11]
NeurIPS 2025 Workshop: Reliable ML from Unreliable Data , year=
Robust Multi-task Modeling for Bayesian Optimization via In-Context Learning , author=. NeurIPS 2025 Workshop: Reliable ML from Unreliable Data , year=
2025
-
[12]
2026 , eprint=
Distribution Transformers: Fast Approximate Bayesian Inference With On-The-Fly Prior Adaptation , author=. 2026 , eprint=
2026
-
[13]
The 28th International Conference on Artificial Intelligence and Statistics , year=
Amortized Probabilistic Conditioning for Optimization, Simulation and Inference , author=. The 28th International Conference on Artificial Intelligence and Statistics , year=
-
[14]
Journal of machine learning research , volume=
Pyro: Deep universal probabilistic programming , author=. Journal of machine learning research , volume=
-
[15]
, author=
The No-U-Turn sampler: adaptively setting path lengths in Hamiltonian Monte Carlo. , author=. J. Mach. Learn. Res. , volume=
-
[16]
Advances in neural information processing systems , volume=
Neural ordinary differential equations , author=. Advances in neural information processing systems , volume=
-
[17]
ICLR 2024 Workshop on Secure and Trustworthy Large Language Models , year=
Are Large Language Models Bayesian? A Martingale Perspective on In-Context Learning , author=. ICLR 2024 Workshop on Secure and Trustworthy Large Language Models , year=
2024
-
[18]
Forty-first International Conference on Machine Learning , year=
All-in-one simulation-based inference , author=. Forty-first International Conference on Machine Learning , year=
-
[19]
and Chu, Eric and Behbahani, Feryal and Faust, Aleksandra and Larochelle, Hugo , booktitle =
Agarwal, Rishabh and Singh, Avi and Zhang, Lei and Bohnet, Bernd and Rosias, Luis and Chan, Stephanie and Zhang, Biao and Anand, Ankesh and Abbas, Zaheer and Nova, Azade and Co-Reyes, John D. and Chu, Eric and Behbahani, Feryal and Faust, Aleksandra and Larochelle, Hugo , booktitle =. Many-Shot In-Context Learning , volume =. doi:10.52202/079017-2447 , editor =
-
[20]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[21]
International Conference on Machine Learning , pages=
Transformers learn in-context by gradient descent , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[22]
Forty-second International Conference on Machine Learning , year=
Can Transformers Learn Full Bayesian Inference in Context? , author=. Forty-second International Conference on Machine Learning , year=
-
[23]
Workshop on Efficient Systems for Foundation Models @ ICML2023 , year=
A Closer Look at In-Context Learning under Distribution Shifts , author=. Workshop on Efficient Systems for Foundation Models @ ICML2023 , year=
-
[24]
Journal of Machine Learning Research , volume=
Trained transformers learn linear models in-context , author=. Journal of Machine Learning Research , volume=
-
[25]
Advances in neural information processing systems , volume=
Pretraining task diversity and the emergence of non-bayesian in-context learning for regression , author=. Advances in neural information processing systems , volume=
-
[26]
Advances in Neural Information Processing Systems , volume=
Llm processes: Numerical predictive distributions conditioned on natural language , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
International conference on artificial intelligence and statistics , pages=
Benchmarking simulation-based inference , author=. International conference on artificial intelligence and statistics , pages=. 2021 , organization=
2021
-
[28]
International conference on artificial neural networks , pages=
Learning to learn using gradient descent , author=. International conference on artificial neural networks , pages=. 2001 , organization=
2001
-
[29]
International conference on machine learning , pages=
Meta-learning with memory-augmented neural networks , author=. International conference on machine learning , pages=. 2016 , organization=
2016
-
[30]
International conference on machine learning , pages=
Model-agnostic meta-learning for fast adaptation of deep networks , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[31]
arXiv preprint arXiv:2212.04458 , year=
General-purpose in-context learning by meta-learning transformers , author=. arXiv preprint arXiv:2212.04458 , year=
-
[32]
The Eleventh International Conference on Learning Representations , year=
What learning algorithm is in-context learning? Investigations with linear models , author=. The Eleventh International Conference on Learning Representations , year=
-
[33]
What Can Transformers Learn In-Context? A Case Study of Simple Function Classes , volume =
Garg, Shivam and Tsipras, Dimitris and Liang, Percy S and Valiant, Gregory , booktitle =. What Can Transformers Learn In-Context? A Case Study of Simple Function Classes , volume =
-
[34]
International Conference on Learning Representations , year=
Transformers Can Do Bayesian Inference , author=. International Conference on Learning Representations , year=
-
[35]
Noah Hollmann and Samuel M. Tab. The Eleventh International Conference on Learning Representations , year=
-
[36]
International Conference on Learning Representations , year=
An Explanation of In-context Learning as Implicit Bayesian Inference , author=. International Conference on Learning Representations , year=
-
[37]
Neurocomputing , volume=
Roformer: Enhanced transformer with rotary position embedding , author=. Neurocomputing , volume=. 2024 , publisher=
2024
-
[38]
and Kucukelbir, Alp and McAuliffe, Jon D
Blei, David M. and Kucukelbir, Alp and McAuliffe, Jon D. , year=. Variational Inference: A Review for Statisticians , volume=. Journal of the American Statistical Association , publisher=
-
[39]
Neural computation , volume=
A practical Bayesian framework for backpropagation networks , author=. Neural computation , volume=. 1992 , publisher=
1992
-
[40]
1996 , publisher=
Bayesian leaning for neural networks , author=. 1996 , publisher=
1996
-
[41]
Machine learning , volume=
An introduction to MCMC for machine learning , author=. Machine learning , volume=. 2003 , publisher=
2003
-
[42]
ArXiv , year=
Neural Processes , author=. ArXiv , year=
-
[43]
5th International Conference on Learning Representations , pages=
Towards a Neural Statistician , author=. 5th International Conference on Learning Representations , pages=
-
[44]
2020, Proceedings of the National Academy of Sciences, 117, 48, 30055
Cranmer, Kyle and Brehmer, Johann and Louppe, Gilles , year=. The frontier of simulation-based inference , volume=. Proceedings of the National Academy of Sciences , publisher=. doi:10.1073/pnas.1912789117 , number=
-
[45]
Forty-second International Conference on Machine Learning Position Paper Track , year=
Position: The Future of Bayesian Prediction Is Prior-Fitted , author=. Forty-second International Conference on Machine Learning Position Paper Track , year=
-
[46]
Forty-second International Conference on Machine Learning , year=
Does learning the right latent variables necessarily improve in-context learning? , author=. Forty-second International Conference on Machine Learning , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.