ThinkProbe: Beyond Accuracy -- Structural Profiling of Open-Ended LLM Reasoning Traces via Non-Generative Thought Graphs
Pith reviewed 2026-06-30 09:19 UTC · model grok-4.3
The pith
LLM reasoning structure is a stable model-level property, with between-model variance exceeding between-domain variance by up to fourfold across four of five cognitive dimensions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
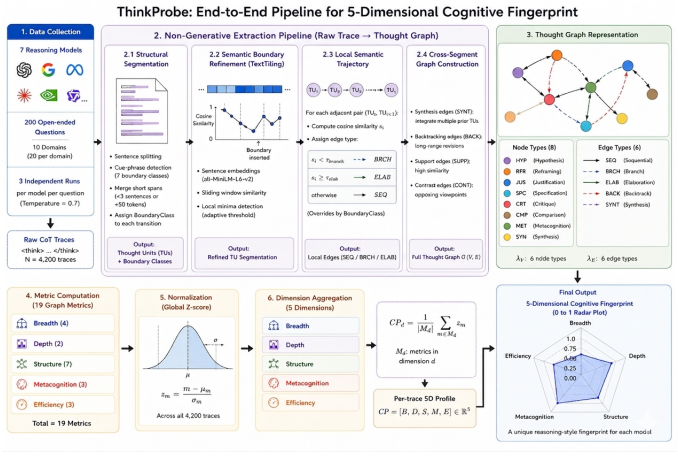
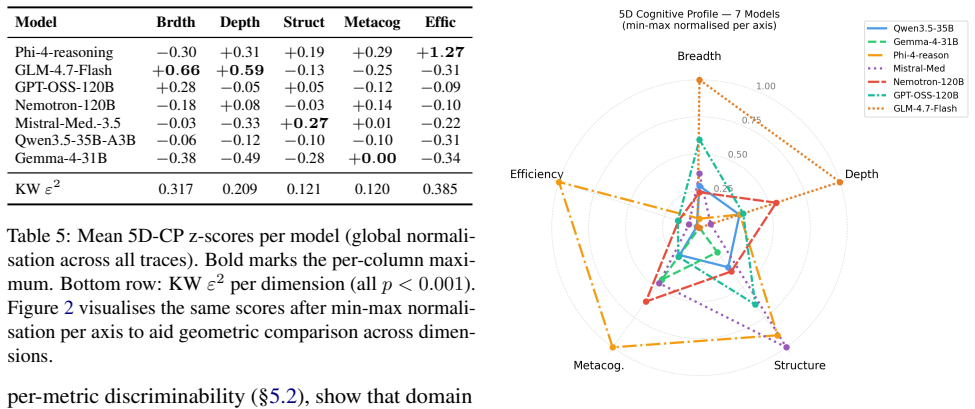
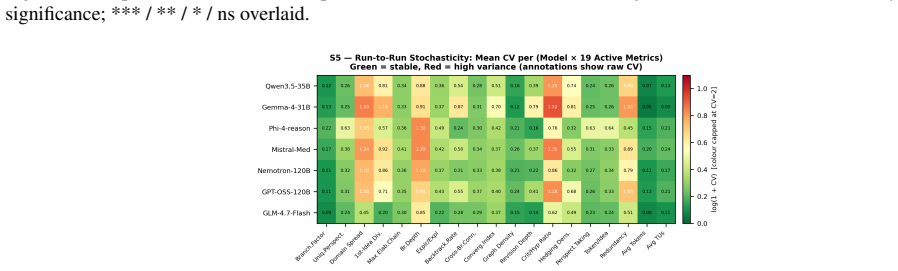
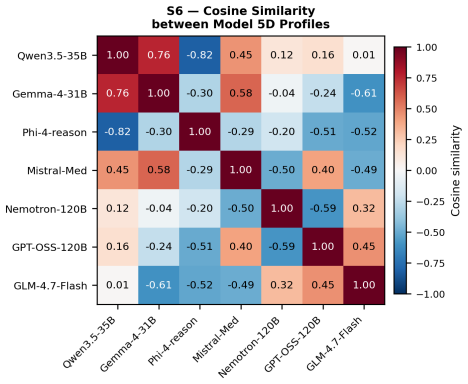
By representing each reasoning trace as a Thought Graph with eight node types and six edge types, ThinkProbe derives nineteen metrics grouped into Breadth, Depth, Structure, Metacognitive, and Efficiency dimensions. Analysis of 4200 traces shows that reasoning structure is a stable, model-level property where between-model variance exceeds between-domain variance by up to fourfold in four dimensions, while Structure varies with domain, exposing model-specific cognitive profiles invisible to accuracy evaluation.
What carries the argument
The Thought Graph, a directed graph with cycles built from eight node types and six edge types via non-generative segmentation and linking, from which the nineteen metrics of the five-dimensional cognitive profile are computed.
If this is right
- Reasoning evaluation requires structural profiles in addition to accuracy to distinguish models.
- Each model possesses a characteristic cognitive profile that remains consistent across domains in four of five dimensions.
- The Structure dimension alone varies meaningfully with question domain while the others do not.
- Accuracy-based rankings overlook qualitatively different reasoning approaches across models.
- Non-generative graph construction yields reproducible cognitive characterizations without additional model calls.
Where Pith is reading between the lines
- Profiles could guide selection of models whose reasoning style matches a target task's demands.
- Changes to model training or architecture might be tracked by shifts in the same five-dimensional metrics.
- Similar graph-based profiling could be applied to human reasoning traces for direct comparison.
- The method opens a path to benchmarks that measure reasoning style rather than final correctness alone.
Load-bearing premise
The rule-based segmentation and discriminative semantic linking steps produce Thought Graphs whose nineteen derived metrics validly capture distinct cognitive dimensions rather than artifacts of the chosen node and edge definitions.
What would settle it
Re-running the full variance analysis after changing the definitions of the eight node types or six edge types and finding that between-model variance no longer exceeds between-domain variance by a similar margin would falsify the claim that the profiles reflect stable model properties.
Figures
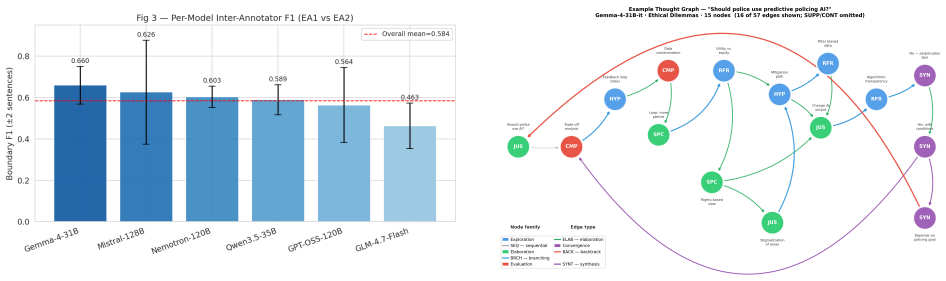
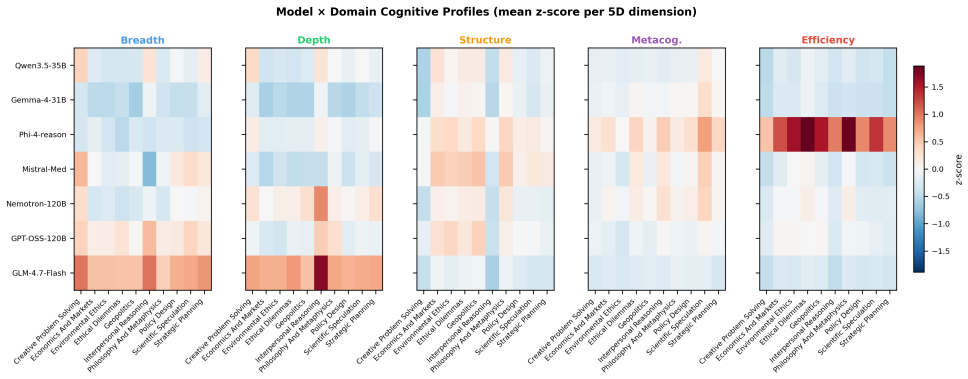
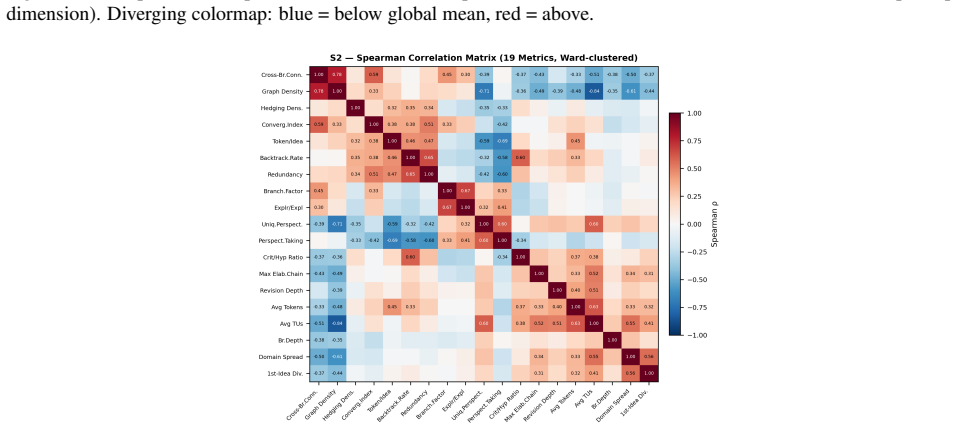
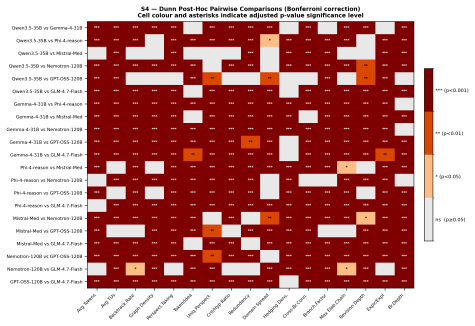
read the original abstract
We present ThinkProbe, a framework for structural analysis of LLM reasoning traces. ThinkProbe converts each trace into a Thought Graph a directed graph with cycles, 8 node types, and 6 edge types and derives a 19-metric five-dimensional cognitive profile (5D-CP: Breadth, Depth, Structure, Metacognitive, Efficiency) through a fully non-generative pipeline combining rule-based segmentation and discriminative semantic linking. Applied to 4{,}200 traces from 7 native reasoning models across 200 open-ended questions and 10 cognitive domains, ThinkProbe reveals that reasoning structure is a stable, model-level property: between-model variance exceeds between-domain variance by up to fourfold across four of five cognitive dimensions, with Structure showing genuine sensitivity to question domain, exposing qualitatively distinct cognitive profiles invisible to accuracy-based evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ThinkProbe, a non-generative framework that converts open-ended LLM reasoning traces into directed Thought Graphs (8 node types, 6 edge types) via rule-based segmentation and discriminative semantic linking. From these graphs it derives 19 metrics forming five-dimensional cognitive profiles (Breadth, Depth, Structure, Metacognitive, Efficiency). On 4,200 traces from 7 models across 200 questions in 10 domains, the analysis reports that between-model variance exceeds between-domain variance by up to fourfold on four of the five dimensions, while Structure alone shows domain sensitivity, revealing stable model-level reasoning profiles invisible to accuracy metrics.
Significance. If the 19 metrics are shown to validly index distinct cognitive dimensions rather than artifacts of the chosen graph grammar, the result would be significant for shifting LLM evaluation from scalar accuracy to structural profiling. The fully non-generative pipeline is a methodological strength that supports reproducibility and reduces circularity risk relative to generative approaches.
major comments (3)
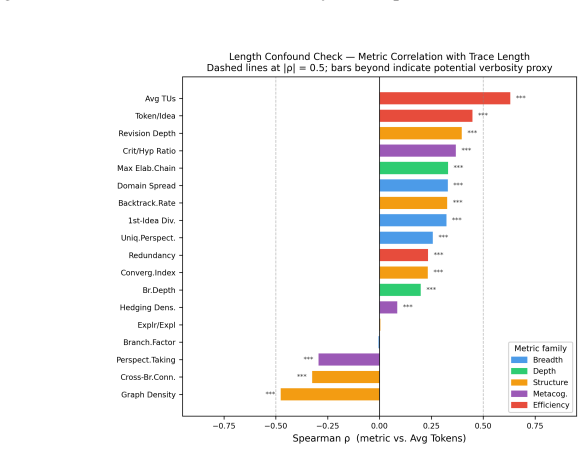
- [Abstract, §3] Abstract and §3 (Thought Graph Construction): the central claim that between-model variance exceeds between-domain variance by up to 4× on 4/5 dimensions rests on the 19 metrics validly capturing cognitive dimensions. No human validation, inter-rater reliability statistics, or ablation on alternative node/edge definitions are reported for the rule-based segmentation into 8 node types and discriminative linking into 6 edge types. This is load-bearing because systematic bias in the graph grammar toward model-specific output patterns would render the variance decomposition an artifact rather than a property of reasoning.
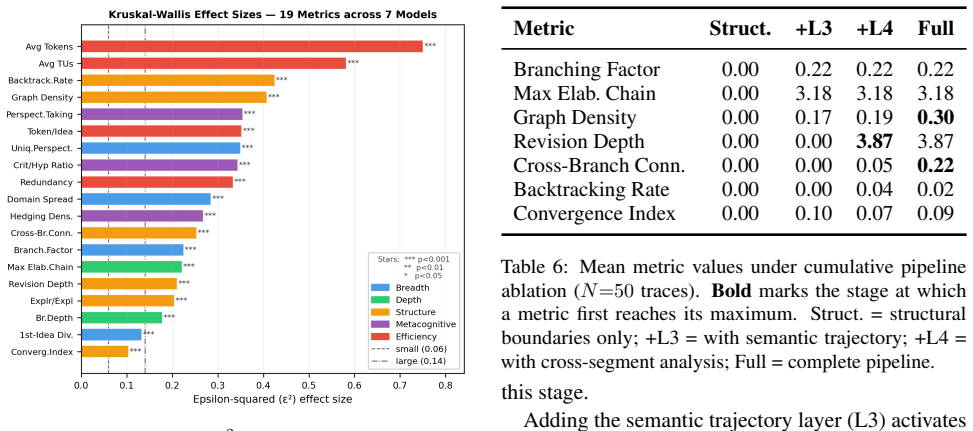
- [§4, §5] §4 (Variance Decomposition) and §5 (Results): the reported fourfold ratio is presented without the explicit statistical model (e.g., variance components from a crossed mixed-effects ANOVA or hierarchical model), the exact partitioning of the 4,200 traces, or checks that the 19 metrics were pre-specified rather than selected after data inspection. These details are required to evaluate whether the domain-sensitivity finding for Structure is robust or driven by post-hoc choices.
- [§3.2] §3.2 (Metric Derivation): it is unclear how the 19 metrics are aggregated into the five named dimensions (5D-CP) and whether any dimensionality-reduction or factor-analytic validation was performed. Without this, the claim of five distinct cognitive profiles cannot be assessed for redundancy or construct validity.
minor comments (2)
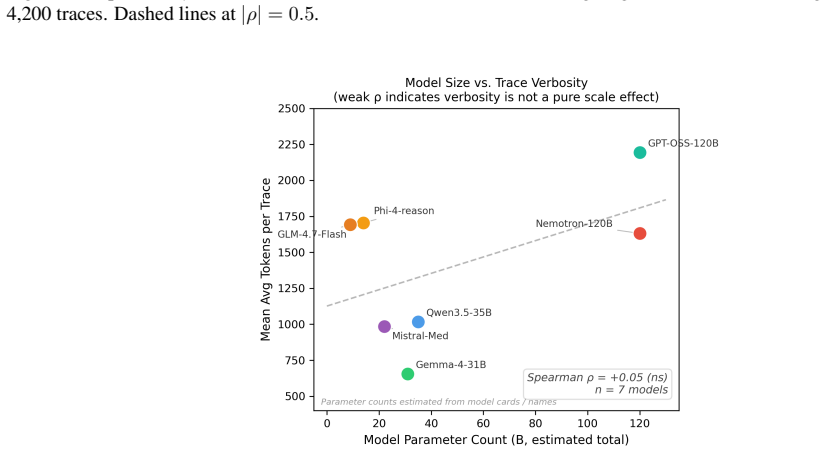
- [Table 1] Table 1 or equivalent: the exact distribution of the 4,200 traces across the 7 models and 10 domains should be reported to allow readers to verify balance in the crossed design.
- [§3] Notation: the distinction between 'node types' and 'edge types' is introduced in the abstract but the precise rule sets for each are only summarized; a supplementary table listing all 8+6 definitions would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the strengths of the non-generative pipeline. We address each major comment below with the strongest honest responses possible. We agree that additional clarifications on the statistical model and metric mapping are needed and will revise accordingly. For the graph grammar validation, we will expand the discussion of theoretical grounding while noting the design priorities of reproducibility.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (Thought Graph Construction): the central claim that between-model variance exceeds between-domain variance by up to 4× on 4/5 dimensions rests on the 19 metrics validly capturing cognitive dimensions. No human validation, inter-rater reliability statistics, or ablation on alternative node/edge definitions are reported for the rule-based segmentation into 8 node types and discriminative linking into 6 edge types. This is load-bearing because systematic bias in the graph grammar toward model-specific output patterns would render the variance decomposition an artifact rather than a property of reasoning.
Authors: The 8 node types and 6 edge types were defined deterministically from cognitive science principles distinguishing statement types (e.g., facts vs. inferences) and relations (e.g., support, contradiction) to enable fully reproducible, non-generative extraction. Human validation and ablations were not performed to avoid introducing subjectivity and to maintain the framework's objectivity across all 4,200 traces. We will revise §3 to add explicit theoretical references justifying each node/edge type and a limitations paragraph acknowledging the absence of inter-rater checks or alternative grammars as a point for future work. This does not change the core results but strengthens transparency. revision: partial
-
Referee: [§4, §5] §4 (Variance Decomposition) and §5 (Results): the reported fourfold ratio is presented without the explicit statistical model (e.g., variance components from a crossed mixed-effects ANOVA or hierarchical model), the exact partitioning of the 4,200 traces, or checks that the 19 metrics were pre-specified rather than selected after data inspection. These details are required to evaluate whether the domain-sensitivity finding for Structure is robust or driven by post-hoc choices.
Authors: The variance ratios derive from a crossed mixed-effects model treating model and domain as fixed effects with traces nested accordingly; the 4,200 traces comprise one trace per model-question pair across 7 models and 200 questions. All 19 metrics were pre-specified from the 5D-CP framework before data collection. We will insert the full model equation, variance component formulas, and partitioning description into a revised §4, plus a statement on pre-specification. This addresses the robustness concern directly. revision: yes
-
Referee: [§3.2] §3.2 (Metric Derivation): it is unclear how the 19 metrics are aggregated into the five named dimensions (5D-CP) and whether any dimensionality-reduction or factor-analytic validation was performed. Without this, the claim of five distinct cognitive profiles cannot be assessed for redundancy or construct validity.
Authors: The 19 metrics are grouped into the five dimensions via a priori theoretical mapping (e.g., node/edge counts and unique entities to Breadth; longest paths and branching to Depth) drawn from cognitive profiling literature, without any post-hoc factor analysis or dimensionality reduction. We will add an explicit mapping table to §3.2 and a paragraph explaining that the dimensions are conceptually motivated rather than empirically reduced, thereby preserving interpretability while allowing readers to assess potential overlap. revision: yes
Circularity Check
No circularity: empirical variance ratios derived from independently constructed metrics
full rationale
The paper defines a rule-based, non-generative pipeline that segments traces into fixed node/edge types and computes 19 metrics; these metrics are then used to calculate between-model vs. between-domain variance ratios on held-out traces. No equations, parameters, or self-citations are shown that would make the reported variance ratios equivalent to the segmentation rules by construction. The central claim is an empirical observation on the output of the pipeline rather than a tautological restatement of its definitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
Besta, Maciej and Blach, Nils and Kubicek, Ales and Gerstenberger, Robert and Podstawski, Michal and Gianinazzi, Lukas and Gajda, Joanna and Lehmann, Tomasz and Niewiadomski, Hubert and Nyczyk, Piotr and Hoefler, Torsten , title =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =. 2024 , doi =
2024
-
[2]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Mapping the Minds of LLMs: A Graph-Based Analysis of Reasoning LLMs , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[3]
arXiv preprint arXiv:2506.02532 , year=
Reasoningflow: Semantic structure of complex reasoning traces , author=. arXiv preprint arXiv:2506.02532 , year=
-
[4]
arXiv preprint arXiv:2603.07078 , year=
CoTJudger: A Graph-Driven Framework for Automatic Evaluation of Chain-of-Thought Efficiency and Redundancy in LRMs , author=. arXiv preprint arXiv:2603.07078 , year=
-
[5]
and Schulz, Eric , title =
Coda-Forno, Julian and Binz, Marcel and Wang, Jane X. and Schulz, Eric , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[6]
arXiv preprint arXiv:2511.16660 , year=
Cognitive foundations for reasoning and their manifestation in llms , author=. arXiv preprint arXiv:2511.16660 , year=
-
[7]
2025 , eprint =
Dong, Jianshuo and Fu, Yaqian and Hu, Cheng and Zhang, Cheng and Qiu, Han , title =. 2025 , eprint =
2025
-
[8]
Submitted to Transactions on Machine Learning Research , year=
MetaCog-Bench: A Process-Based Benchmark for Evaluating Metacognitive Monitoring and Control in Large Language Models , author=. Submitted to Transactions on Machine Learning Research , year=
-
[9]
Ryan Liu, Jiayi Geng, Addison J
Think-bench: Evaluating thinking efficiency and chain-of-thought quality of large reasoning models , author=. arXiv preprint arXiv:2505.22113 , year=
-
[10]
arXiv preprint arXiv:2508.13141 , year=
Optimalthinkingbench: Evaluating over and underthinking in llms , author=. arXiv preprint arXiv:2508.13141 , year=
-
[11]
Do LLMs Really Need 10+ Thoughts for" Find the Time 1000 Days Later"? Towards Structural Understanding of LLM Overthinking , author=. arXiv preprint arXiv:2510.07880 , year=
-
[12]
2025 , eprint =
Huang, Shulin and Yang, Liang and Song, Yiyang and Chen, Siyuan and Cui, Leyang and Wan, Zhenghua and Zeng, Qin and Wen, Yimin and Shao, Kun and Zhang, Wei and Wang, Jun and Zhang, Yue , title =. 2025 , eprint =
2025
-
[13]
arXiv preprint arXiv:2602.13904 , year=
Diagnosing Pathological Chain-of-Thought in Reasoning Models , author=. arXiv preprint arXiv:2602.13904 , year=
-
[14]
Advances in Neural Information Processing Systems , volume =
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and Ichter, Brian and Xia, Fei and Chi, Ed and Le, Quoc and Zhou, Denny , title =. Advances in Neural Information Processing Systems , volume =
-
[15]
and Cao, Yuan and Narasimhan, Karthik , title =
Yao, Shunyu and Yu, Dian and Zhao, Jeffrey and Shafran, Izhak and Griffiths, Thomas L. and Cao, Yuan and Narasimhan, Karthik , title =. Advances in Neural Information Processing Systems , volume =
-
[16]
International Conference on Learning Representations , year =
Wang, Xuezhi and Wei, Jason and Schuurmans, Dale and Le, Quoc and Chi, Ed and Narang, Sharan and Chowdhery, Aakanksha and Zhou, Denny , title =. International Conference on Learning Representations , year =
-
[17]
International Conference on Learning Representations , year =
Golovneva, Olga and Chen, Moya and Poff, Spencer and Corredor, Martin and Zettlemoyer, Luke and Fazel-Zarandi, Maryam and Celikyilmaz, Asli , title =. International Conference on Learning Representations , year =
-
[18]
International Conference on Learning Representations , year =
Lightman, Hunter and Kosaraju, Vineet and Burda, Yura and Edwards, Harri and Baker, Bowen and Lee, Teddy and Leike, Jan and Schulman, John and Sutskever, Ilya and Cobbe, Karl , title =. International Conference on Learning Representations , year =
-
[19]
Measuring Mathematical Problem Solving With the
Hendrycks, Dan and Burns, Collin and Kadavath, Saurav and Arora, Akul and Basart, Steven and Tang, Eric and Song, Dawn and Steinhardt, Jacob , booktitle=. Measuring Mathematical Problem Solving With the. 2021 , url=
2021
-
[20]
International Conference on Learning Representations , year =
Hendrycks, Dan and Burns, Collin and Basart, Steven and Zou, Andy and Mazeika, Mantas and Song, Dawn and Steinhardt, Jacob , title =. International Conference on Learning Representations , year =
-
[21]
2021 , eprint =
Cobbe, Karl and Kosaraju, Vineet and Bavarian, Mohammad and Chen, Mark and Jun, Heewoo and Kaiser, Lukasz and Plappert, Matthias and Tworek, Jerry and Hilton, Jacob and Nakano, Reiichiro and Hesse, Christopher and Schulman, John , title =. 2021 , eprint =
2021
-
[22]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , year=
What makes a good reasoning chain? uncovering structural patterns in long chain-of-thought reasoning , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , year=
2025
-
[23]
Schoenfeld's Anatomy of Mathematical Reasoning by Language Models
Schoenfeld's Anatomy of Mathematical Reasoning by Language Models , author=. arXiv preprint arXiv:2512.19995 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Phi-4-reasoning Technical Report
Phi-4-reasoning technical report , author=. arXiv preprint arXiv:2504.21318 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
ArXiv , year=
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models , author=. ArXiv , year=
-
[26]
2025 , url =
NVIDIA Nemotron 3: Efficient and Open Intelligence , author =. 2025 , url =
2025
-
[27]
2025 , eprint=
gpt-oss-120b & gpt-oss-20b Model Card , author=. 2025 , eprint=
2025
-
[28]
2026 , month =
Mistral Medium 3.5 128B , author =. 2026 , month =
2026
-
[29]
2026 , month =
Gemma 4 31B. 2026 , month =
2026
-
[30]
, title =
March, James G. , title =. Organization Science , volume =. 1991 , pages =
1991
-
[31]
Sentence-
Reimers, Nils and Gurevych, Iryna , booktitle =. Sentence-. 2019 , publisher =
2019
-
[32]
2020 , url =
Wang, Wenhui and Bao, Hangbo and Huang, Shaohan and Dong, Li and Wei, Furu , journal =. 2020 , url =
2020
-
[33]
2021 , howpublished =
sentence-transformers/all-. 2021 , howpublished =
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.