S2M-Trek: From Single to Multi-Sphere Transport via Per-Frame Deep Sets on a Wheel-Legged Robot
Pith reviewed 2026-06-28 16:53 UTC · model grok-4.3
The pith
Per-Frame Deep Sets lets a wheel-legged robot carry five identical free-rolling spheres without dropping any.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
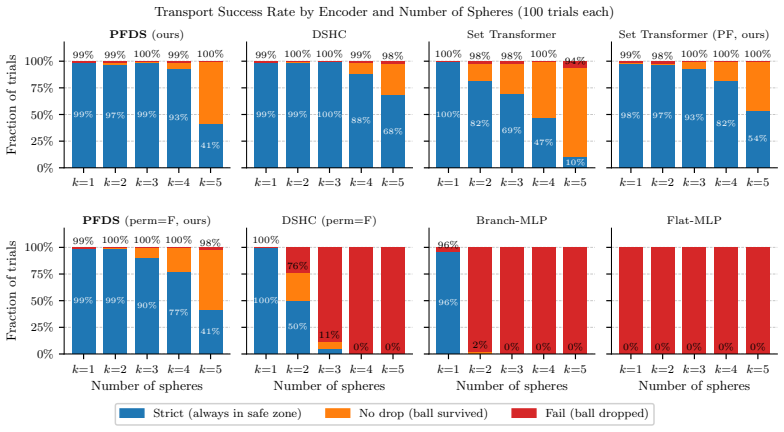
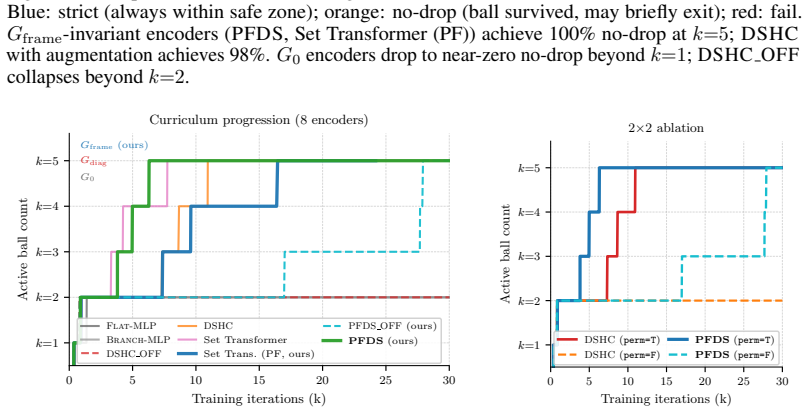
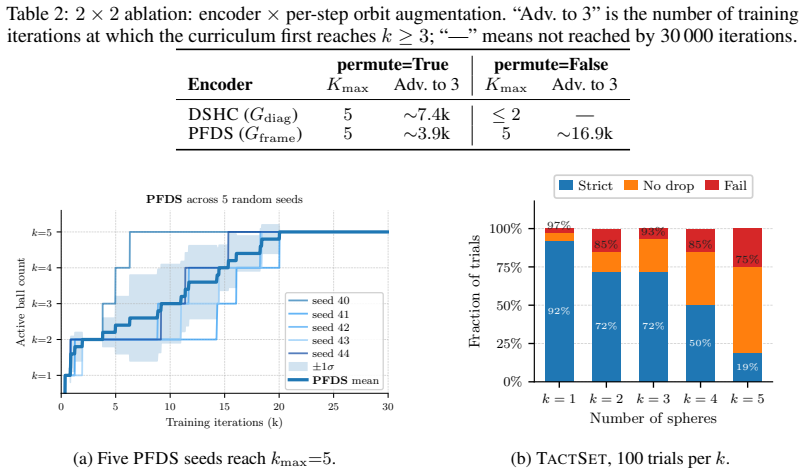
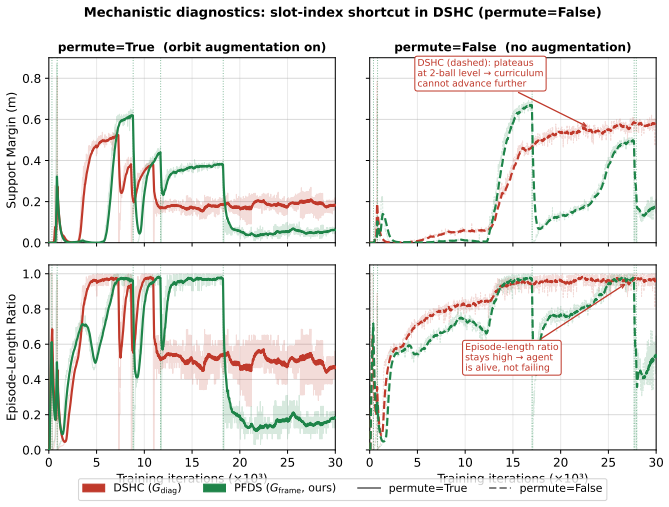
The paper claims that the per-frame permutation symmetry created by identical free-rolling spheres produces a symmetry mismatch with standard history-concatenation set encoders, causing them to plateau at or below two spheres, and that Per-Frame Deep Sets removes the mismatch by performing permutation-invariant pooling within each frame before temporal readout, thereby reaching five-sphere no-drop transport with 100 percent success across random seeds.
What carries the argument
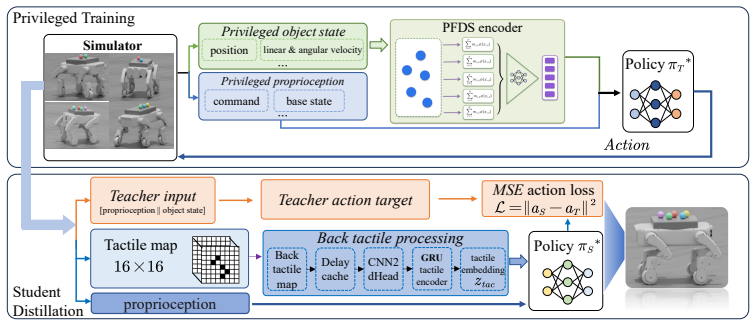
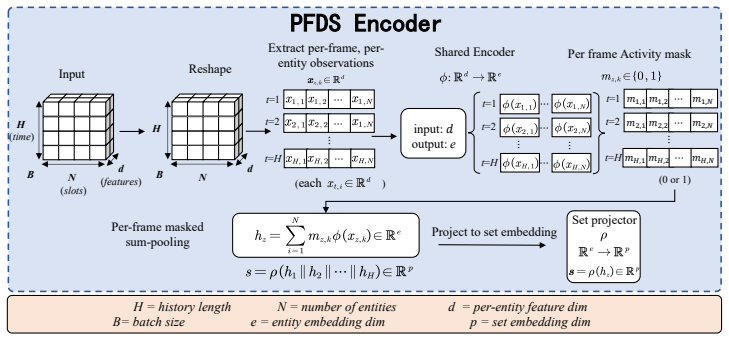
Per-Frame Deep Sets (PFDS), which performs permutation-invariant pooling within each history frame before temporal readout to enforce Gframe-invariance.
If this is right
- PFDS reaches the five-sphere stage with 100 percent no-drop transport in simulation across all five random seeds.
- PFDS is Gframe-invariant and universally approximates continuous Gframe-invariant policies.
- Distilling the PFDS teacher into TactSet via DAgger yields a policy that uses only a 16 by 16 Boolean union contact map while remaining Gframe-invariant.
- A 2 by 2 ablation separates the effects of encoder architecture from slot randomisation and shows both pathways matter.
Where Pith is reading between the lines
- The same per-frame pooling pattern could be applied to other multi-object tasks where identical items lack persistent identity across time steps.
- Replacing privileged sphere states with contact maps indicates the architecture can operate without direct object tracking once the policy is distilled.
- Because the encoder is provably Gframe-invariant, it may reduce the need for explicit data augmentation in other symmetric multi-body control problems.
Load-bearing premise
The observed training plateaus of flat MLPs, branch-wise encoders, and history-concatenation Deep Sets are caused by the per-frame permutation symmetry mismatch rather than reward shaping, curriculum design, or optimizer instability.
What would settle it
Running the history-concatenation Deep Sets baseline to the five-sphere stage while keeping ball-to-slot assignments randomized at every training step and checking whether it still plateaus or now succeeds.
Figures

read the original abstract
We study the problem of scaling dynamic loco-manipulation from a single free-rolling sphere to multiple spheres transported simultaneously on the back of a wheel-legged quadruped, without fences, grippers, or mechanical stops. Multiple identical free-rolling spheres form an unordered set with no persistent identity: their ordering may change independently at each history frame, creating a \emph{per-frame permutation symmetry} that standard history-concatenation set encoders do not explicitly enforce -- these encoders impose only a shared, diagonal permutation symmetry over the full history. We show that this symmetry mismatch leads to a concrete failure mode in curriculum-based reinforcement learning. Within the same PPO training budget, flat MLPs and branch-wise encoders plateau at or below the two-sphere stage, while a history-concatenation Deep Sets baseline (\HCDS) fails to progress past the two-sphere stage in our runs unless ball-to-slot assignments are randomised during training, suggesting that it exploits slot indices as a curriculum shortcut rather than learning identity-free multi-sphere dynamics. We propose \textbf{Per-Frame Deep Sets (\PFDS)}, which performs permutation-invariant pooling within each history frame before temporal readout; we prove that \PFDS is $\Gframe$-invariant and universally approximates continuous $\Gframe$-invariant policies. A $2{\times}2$ ablation over encoder architecture and slot randomisation separates the architectural and data-augmentation pathways, and \PFDS reaches the five-sphere stage with 100\% no-drop transport in simulation across all five random seeds. We further distill the \PFDS teacher into \TactSet via DAgger, replacing privileged sphere-state observations with a $16{\times}16$ Boolean union contact map, yielding a compact and naturally $\Gframe$-invariant tactile representation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies scaling dynamic loco-manipulation on a wheel-legged quadruped from single-sphere to simultaneous multi-sphere transport without fences or grippers. It identifies a per-frame permutation symmetry (unordered spheres whose ordering can change independently across history frames) that standard history-concatenation encoders do not enforce, and shows via curriculum RL that flat MLPs, branch-wise encoders, and HCDS plateau at or below two spheres (HCDS only progresses when slot assignments are randomized). The authors introduce Per-Frame Deep Sets (PFDS), which applies permutation-invariant pooling within each frame before temporal readout; they prove PFDS is Gframe-invariant and universally approximates continuous Gframe-invariant policies. A 2×2 ablation over architecture and slot randomization shows PFDS reaching five-sphere transport with 100% no-drop success across five seeds in simulation; the policy is then distilled via DAgger to TactSet using a 16×16 Boolean contact map.
Significance. If the results hold, the work supplies a principled architectural fix for per-frame set symmetries in multi-object RL, supported by an explicit invariance proof, a universal-approximation guarantee, and reproducible 100% success across seeds. The 2×2 ablation cleanly separates architectural effects from data-augmentation effects, and the tactile distillation step demonstrates a practical path to sensor-based deployment. These elements together strengthen the case for PFDS-style encoders in other permutation-symmetric loco-manipulation or multi-body transport tasks.
major comments (2)
- [Ablation/results section] Ablation/results section: The 2×2 ablation holds reward, curriculum, PPO budget, and optimizer fixed while varying only encoder architecture and slot randomization, thereby showing that PFDS succeeds where the baselines fail under these conditions. However, it does not vary reward shaping, sphere-count curriculum schedule, or optimizer to test whether the same baselines could succeed under altered designs; without such controls the attribution of plateaus specifically to the per-frame vs. history-diagonal symmetry mismatch remains incompletely isolated.
- [Theoretical section] Theoretical section (proof of universal approximation): The manuscript states that PFDS universally approximates continuous Gframe-invariant policies, yet the provided abstract contains no equations and the full text must supply the precise function class, the statement of the theorem, and the key steps (e.g., density arguments or Stone-Weierstrass application) so that readers can verify applicability to the finite-history, discrete-action RL setting actually used.
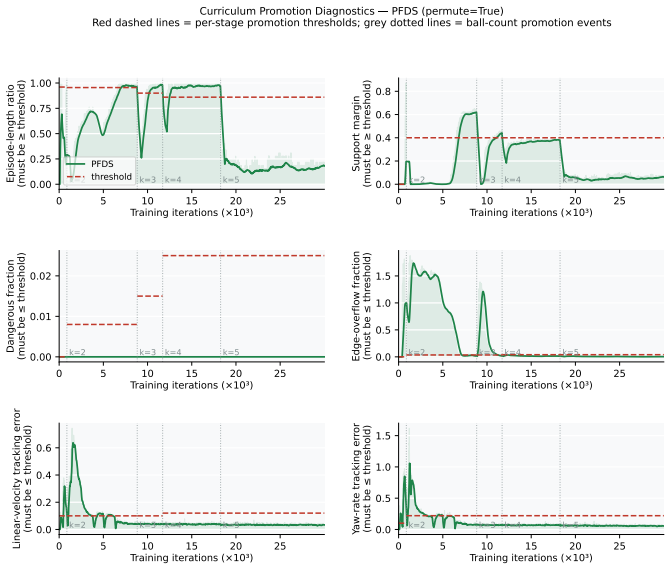
minor comments (1)
- [Abstract] Abstract: The symbols Gframe and HCDS are used without prior definition; a parenthetical gloss on first appearance would improve immediate readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below, clarifying our design choices and committing to revisions where appropriate to improve clarity and completeness.
read point-by-point responses
-
Referee: [Ablation/results section] Ablation/results section: The 2×2 ablation holds reward, curriculum, PPO budget, and optimizer fixed while varying only encoder architecture and slot randomization, thereby showing that PFDS succeeds where the baselines fail under these conditions. However, it does not vary reward shaping, sphere-count curriculum schedule, or optimizer to test whether the same baselines could succeed under altered designs; without such controls the attribution of plateaus specifically to the per-frame vs. history-diagonal symmetry mismatch remains incompletely isolated.
Authors: The 2×2 ablation was intentionally designed to hold all other factors fixed in order to isolate the contribution of the encoder architecture (and the effect of slot randomization as a data-augmentation control). Under these standard PPO settings, the baselines consistently plateau while PFDS succeeds, which directly supports our claim regarding the per-frame symmetry mismatch. We acknowledge that additional sweeps over reward shaping or curriculum schedules could offer further robustness evidence; we will add a dedicated limitations paragraph in the revised ablation section discussing this scope and noting it as an avenue for future investigation. This constitutes a partial revision. revision: partial
-
Referee: [Theoretical section] Theoretical section (proof of universal approximation): The manuscript states that PFDS universally approximates continuous Gframe-invariant policies, yet the provided abstract contains no equations and the full text must supply the precise function class, the statement of the theorem, and the key steps (e.g., density arguments or Stone-Weierstrass application) so that readers can verify applicability to the finite-history, discrete-action RL setting actually used.
Authors: The full manuscript contains the formal theorem statement, the definition of the function class (continuous Gframe-invariant maps from finite histories of unordered sets to actions), the invariance proof for PFDS, and the universal-approximation argument that composes per-frame Deep Sets universality with a temporal readout. To address the concern about explicit presentation, we will expand the theoretical section in the revision with the complete theorem, key proof steps (including the density argument), and a brief discussion of its applicability to the finite-history discrete-action setting used in our experiments. revision: yes
Circularity Check
No significant circularity; empirical results and architectural invariance claim are self-contained
full rationale
The paper's core claims rest on empirical PPO training outcomes across encoder architectures (flat MLP, branch-wise, HCDS, PFDS) under fixed reward/curriculum/optimizer conditions, plus a direct architectural definition of per-frame pooling that yields Gframe-invariance by construction. No equations reduce a prediction to a fitted input, no self-citation chain supports the main result, and the universal-approximation statement is presented as following from the per-frame pooling definition without further reduction to external fitted values. The ablation isolates architecture under the stated conditions but does not rely on circular renaming or imported uniqueness theorems. The derivation chain is therefore independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Deep Sets perform permutation-invariant pooling and can universally approximate invariant functions
Reference graph
Works this paper leans on
-
[1]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
M. Mittal et al. Isaac lab: A GPU-accelerated simulation framework for multi-modal robot learning.arXiv preprint arXiv:2511.04831, 2025. doi:10.48550/arXiv.2511.04831. URL https://arxiv.org/abs/2511.04831
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.04831 2025
-
[2]
J. Hwangbo, J. Lee, A. Dosovitskiy, D. Bellicoso, V . Tsounis, V . Koltun, and M. Hutter. Learning agile and dynamic motor skills for legged robots.Science Robotics, 4(26):eaau5872, 2019. doi:10.1126/scirobotics.aau5872
-
[3]
Rudin, D
N. Rudin, D. Hoeller, P. Reist, and M. Hutter. Learning to walk in minutes using massively parallel deep reinforcement learning. InProceedings of the 5th Conference on Robot Learning, volume 164 ofProceedings of Machine Learning Research, pages 91–100. PMLR, 2022. URL https://proceedings.mlr.press/v164/rudin22a.html
2022
-
[4]
T. Miki, J. Lee, J. Hwangbo, L. Wellhausen, V . Koltun, and M. Hutter. Learning robust perceptive locomotion for quadrupedal robots in the wild.Science Robotics, 7(62):eabk2822,
-
[5]
doi:10.1126/scirobotics.abk2822
-
[6]
A. Kumar, Z. Fu, D. Pathak, and J. Malik. RMA: Rapid motor adaptation for legged robots. InProceedings of Robotics: Science and Systems, Virtual, July 2021. doi:10.15607/RSS.2021. XVII.011. URLhttps://www.roboticsproceedings.org/rss17/p011.html
-
[7]
Y . Ji, G. B. Margolis, and P. Agrawal. DribbleBot: Dynamic legged manipulation in the wild. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 5155–5162. IEEE, 2023. doi:10.1109/ICRA48891.2023.10160325
-
[8]
Z. He, K. Lei, Y . Ze, K. Sreenath, Z. Li, and H. Xu. Learning visual quadrupedal loco- manipulation from demonstrations. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 9102–9109. IEEE, 2024. doi:10.1109/IROS58592.2024. 10802742
-
[9]
M. Liu, Z. Chen, X. Cheng, Y . Ji, R.-Z. Qiu, R. Yang, and X. Wang. Visual whole-body control for legged loco-manipulation. InProceedings of The 8th Conference on Robot Learning, volume 270 ofProceedings of Machine Learning Research, pages 234–257. PMLR, 2025. URL https://proceedings.mlr.press/v270/liu25b.html
2025
-
[10]
C. Lin, Y . R. Song, B. Huo, M. Yu, Y . Wang, S. Liu, Y . Yang, W. Yu, T. Zhang, J. Tan, Y . Luo, and D. Zhao. Locotouch: Learning dynamic quadrupedal transport with tactile sensing. In Proceedings of the 9th Conference on Robot Learning, volume 305 ofProceedings of Machine Learning Research, pages 2779–2801. PMLR, 2025. URL https://proceedings.mlr. press...
2025
-
[11]
Zaheer, S
M. Zaheer, S. Kottur, S. Ravanbakhsh, B. Poczos, R. Salakhutdinov, and A. Smola. Deep sets. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
-
[12]
J. Lee, Y . Lee, J. Kim, A. R. Kosiorek, S. Choi, and Y . W. Teh. Set transformer: A framework for attention-based permutation-invariant neural networks. InProceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 3744–3753. PMLR, 2019. 9
2019
-
[13]
C. R. Qi, H. Su, K. Mo, and L. J. Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. In2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 652–660. IEEE, 2017. doi:10.1109/CVPR.2017.16
-
[14]
Maron, O
H. Maron, O. Litany, G. Chechik, and E. Fetaya. On learning sets of symmetric elements. InProceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 6734–6744. PMLR, 2020
2020
-
[15]
van der Pol, D
E. van der Pol, D. Worrall, H. van Hoof, F. Oliehoek, and M. Welling. Mdp homomorphic networks: Group symmetries in reinforcement learning. InAdvances in Neural Information Processing Systems, volume 33, pages 4199–4210, 2020
2020
-
[16]
van der Pol, F
E. van der Pol, F. A. Oliehoek, H. van Hoof, and M. Welling. Multi-agent MDP homomorphic networks. InInternational Conference on Learning Representations, 2022. URL https: //openreview.net/forum?id=H7HDG--DJF0
2022
-
[17]
X. Zhu, Y . Qi, Y . Zhu, R. Walters, and R. Platt. EquAct: An SE(3)-equivariant multi-task trans- former for 3d robotic manipulation. InInternational Conference on Learning Representations,
-
[18]
URLhttps://openreview.net/forum?id=d1wuA8oIH0
-
[19]
Hoang, H
T. Hoang, H. Le, P. Becker, V . A. Ngo, and G. Neumann. Geometry-aware RL for manipu- lation of varying shapes and deformable objects. InInternational Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=jBOhVc0tsT
2025
-
[20]
McClellan, N
J. McClellan, N. Haghani, J. Winder, F. Huang, and P. Tokekar. Boosting sample ef- ficiency and generalization in multi-agent reinforcement learning via equivariance. In Advances in Neural Information Processing Systems, volume 37, pages 41132–41156,
-
[21]
URL https://proceedings.neurips.cc/paper_files/paper/2024/hash/ 4830a9b95a2f63fc4b3fe09abc18f045-Abstract-Conference.html
2024
-
[22]
R. S. Dahiya, G. Metta, M. Valle, and G. Sandini. Tactile sensing–from humans to humanoids. IEEE Transactions on Robotics, 26(1):1–20, 2010. doi:10.1109/TRO.2009.2033627
-
[23]
S. Luo, J. Bimbo, R. Dahiya, and H. Liu. Robot tactile perception of object properties: A review. Mechatronics, 48:54–67, 2017. doi:10.1016/j.mechatronics.2017.11.002
-
[24]
M. B. Villalonga, A. Rodriguez, B. Lim, E. Valls, and T. Sechopoulos. Tactile object pose estimation from the first touch with geometric contact rendering. InProceedings of the 2020 Conference on Robot Learning, volume 155 ofProceedings of Machine Learning Re- search, pages 1015–1029. PMLR, 2021. URL https://proceedings.mlr.press/v155/ villalonga21a.html
2020
-
[25]
J. Lloyd and N. F. Lepora. Pose-and-shear-based tactile servoing.The International Journal of Robotics Research, 43(7):1024–1055, 2024. doi:10.1177/02783649231225811
-
[26]
S. Ross, G. Gordon, and D. Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the Fourteenth International Conference on Arti- ficial Intelligence and Statistics, pages 627–635. JMLR Workshop and Conference Proceedings, 2011
2011
-
[27]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[28]
5, 359–366,https: //doi.org/10.1016/0893-6080(89)90020-8
K. Hornik, M. Stinchcombe, and H. White. Multilayer feedforward networks are universal approximators.Neural Networks, 2(5):359–366, 1989. doi:10.1016/0893-6080(89)90020-8
-
[29]
R. T. Rockafellar and S. Uryasev. Optimization of conditional value-at-risk.Journal of Risk, 2 (3):21–41, 2000. doi:10.21314/JOR.2000.038. 10
-
[30]
Y . Bengio, J. Louradour, R. Collobert, and J. Weston. Curriculum learning. InProceedings of the 26th Annual International Conference on Machine Learning, pages 41–48. ACM, 2009. doi:10.1145/1553374.1553380
-
[31]
Narvekar, B
S. Narvekar, B. Peng, M. Leonetti, J. Sinapov, M. E. Taylor, and P. Stone. Curriculum learning for reinforcement learning domains: A framework and survey.Journal of Machine Learning Research, 21(181):1–50, 2020. URLhttps://jmlr.org/papers/v21/20-212.html. A Proof Details A.1 Preliminaries: Permutation andG frame-Invariance For completeness we recall the t...
2020
-
[32]
2.Robot falls: the projected gravity vector indicates a roll angle|arcsin(g b,y)|>90 ◦
Ball falls below robot base: any active ball’sz-position drops below the robot base z-position, ∃i∈ A t :p i,z < probot,z. 2.Robot falls: the projected gravity vector indicates a roll angle|arcsin(g b,y)|>90 ◦. 3.Base height too low: the robot base height falls below the minimum standing height threshold. Note: the base contact termination (body contact w...
-
[33]
Episode-length ratio ≥0.85 : the mean episode length divided by the maximum episode length exceeds 85%, indicating the agent consistently survives to episode end
-
[34]
Support margin ≥µ ∗ k: mean minimum support margin across active balls exceeds the level threshold
-
[35]
Dangerous fraction ≤f ∗ d,k: the fraction of timesteps with any ball in a dangerous state (near edge) is below the level threshold
-
[36]
Support margin
Edge-overflow fraction ≤f ∗ e,k: the fraction of timesteps with any ball outside the plate boundary is below the level threshold. 5.Linear velocity tracking error≤ϵ ∗ v,k: mean∥ˆvxy −v xy cmd∥2 is below threshold. 6.Angular velocity tracking error≤ϵ ∗ ω,k: mean|ˆωz −ω z,cmd|is below threshold. All conditions must hold simultaneously for required successes...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.