UniCA: Bi-directional Cross-Attention with Positive Similarity Loss for Robust Multi-Modal Retrieval
Pith reviewed 2026-06-30 11:25 UTC · model grok-4.3
The pith
UniCA adds a bi-directional cross-attention block and positive similarity loss to enable explicit visual-textual alignment before retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
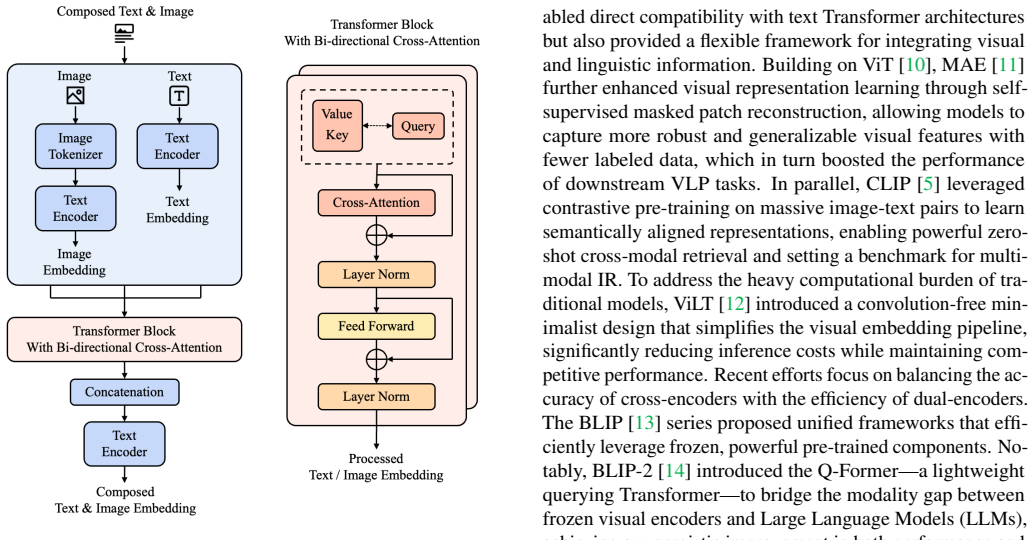
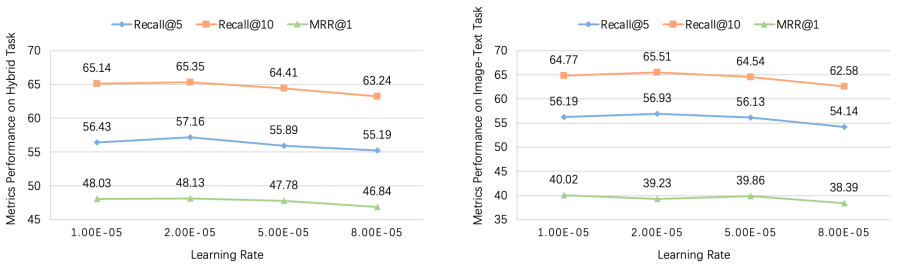
UniCA is a multi-modal retrieval model that uses a bi-directional cross-attention block to let visual and textual tokens perform active semantic exchange before concatenation, together with a Positive Similarity Loss that directly optimizes proximity between query and positive candidate embeddings. A reduced dataset UMR-S10 is introduced for efficiency. On the WebQA benchmark the model records gains of up to 4.09 percent Recall@5, 3.28 percent Recall@10, and 3.96 percent MRR@1 on the hybrid task relative to the baseline.
What carries the argument
The bi-directional cross-attention (Bi-CA) block that performs active semantic exchange between visual and textual tokens prior to concatenation.
If this is right
- Inter-modal correlations are captured more efficiently than with implicit self-attention alone.
- Absolute semantic proximity between query and positive candidates is directly optimized.
- The UMR-S10 dataset reduces computational cost while preserving semantic diversity and task representativeness.
- Deployment barriers are lowered through the lighter dataset and the enhanced fusion mechanism.
Where Pith is reading between the lines
- If the explicit token exchange proves decisive, similar bi-directional blocks could be inserted into other multi-modal encoders without full retraining.
- Smaller representative subsets like UMR-S10 may allow systematic testing of fusion variants under fixed compute budgets.
- The same alignment changes might improve downstream tasks such as visual question answering that also require tight image-text matching.
Load-bearing premise
The observed gains on WebQA are produced by the bi-directional cross-attention block and positive similarity loss rather than other training or dataset factors.
What would settle it
An ablation experiment that removes the bi-directional cross-attention block and positive similarity loss from UniCA and checks whether hybrid-task Recall@5, Recall@10, and MRR@1 on WebQA fall back to baseline levels.
Figures
read the original abstract
Multi-modal retrieval has become increasingly critical for handling the growing volume of integrated visual-textual data in real-world applications, but existing frameworks rely on implicit fusion via text encoder self-attention, limiting explicit cross-modal semantic alignment. To address this gap, this paper proposes UniCA (Unified Cross-Attention Encoder), a multi-modal retrieval model with four key innovations: 1) a bi-directional cross-attention (Bi-CA) block that enables active semantic exchange between visual and textual tokens prior to concatenation, capturing inter-modal correlations more efficiently. 2) a Positive Similarity Loss that optimizes absolute semantic proximity between query and positive candidate embeddings. 3) a streamlined dataset UMR-S10 (Universal Multimodal Retrieval Sample 10%) to reduce computational costs while retaining semantic diversity and task representativeness. 4) an experimental validation on the WebQA benchmark demonstrates that UniCA outperforms the baseline model across Hybrid and Image-Text tasks, achieving improvements of up to 4.09% in Recall@5, 3.28% in Recall@10, and 3.96% in MRR@1 for the hybrid task. UniCA provides an efficient and robust solution for multi-modal retrieval, lowering deployment barriers through its lightweight dataset and enhanced fusion mechanism.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes UniCA, a multi-modal retrieval model with four innovations: a bi-directional cross-attention (Bi-CA) block for explicit visual-textual token exchange, a Positive Similarity Loss to optimize query-positive embedding proximity, the UMR-S10 reduced dataset for efficiency, and an experimental validation claiming up to 4.09% Recall@5, 3.28% Recall@10, and 3.96% MRR@1 gains over baseline on WebQA hybrid and image-text tasks.
Significance. If the reported gains can be rigorously attributed to Bi-CA and Positive Similarity Loss via controlled experiments, the approach could advance explicit cross-modal alignment in retrieval, offering a lightweight alternative to implicit fusion methods while reducing dataset size without losing representativeness.
major comments (2)
- [Abstract] Abstract: The central empirical claim of specific percentage improvements on WebQA is stated without any mention of baseline models, training procedures, hyperparameters, error bars, statistical tests, or ablation results, rendering it impossible to evaluate whether the data support attribution to the proposed mechanisms.
- [Abstract] Abstract and experimental validation: No ablation studies are described that hold training procedure, optimizer, hyperparameters, and UMR-S10 fixed while varying only the Bi-CA block (vs. standard self-attention) and Positive Similarity Loss term; without these, the measured deltas cannot be isolated from dataset shift or other unstated factors.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater transparency in the abstract and for controlled ablations. We address each point below and will revise the manuscript to strengthen the empirical claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim of specific percentage improvements on WebQA is stated without any mention of baseline models, training procedures, hyperparameters, error bars, statistical tests, or ablation results, rendering it impossible to evaluate whether the data support attribution to the proposed mechanisms.
Authors: We agree that the abstract's brevity omits key experimental details. The full paper describes the baseline (standard self-attention encoder), training procedure, and hyperparameters in Section 4, but we will revise the abstract to explicitly name the baseline, note the use of UMR-S10, and reference the reported metrics with their context. We will also add error bars and mention statistical significance testing in the experimental results section of the revision. revision: yes
-
Referee: [Abstract] Abstract and experimental validation: No ablation studies are described that hold training procedure, optimizer, hyperparameters, and UMR-S10 fixed while varying only the Bi-CA block (vs. standard self-attention) and Positive Similarity Loss term; without these, the measured deltas cannot be isolated from dataset shift or other unstated factors.
Authors: We acknowledge the absence of such isolated ablations in the current version. To directly address attribution, the revised manuscript will include new ablation experiments that keep the training procedure, optimizer, hyperparameters, and UMR-S10 dataset fixed while independently adding/removing the Bi-CA block and the Positive Similarity Loss term. These results will be reported with the same metrics to isolate their contributions. revision: yes
Circularity Check
No circularity: purely empirical claims with no derivations or self-referential reductions
full rationale
The paper advances four listed innovations and reports measured lifts on WebQA (up to 4.09% R@5 etc. on hybrid task). No equations, fitted parameters, or theoretical derivations appear in the abstract or described claims. The central assertions are framed as experimental outcomes rather than predictions derived from inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked to justify mechanisms. The derivation chain is therefore self-contained as standard empirical validation; the skeptic concern about missing ablations pertains to causal attribution strength, not circularity of any claimed derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Dense passage retrieval for open-domain question answering,
V . Karpukhin, B. Oguz, S. Min, P. Lewis, L. Wu, S. Edunov, D. Chen, and W.-t. Yih, “Dense passage retrieval for open-domain question answering,” inPro- ceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), 2020, pp. 6769– 6781
2020
-
[2]
Unsupervised Dense Information Retrieval with Contrastive Learning
G. Izacard, M. Caron, L. Hosseini, S. Riedel, P. Bo- janowski, A. Joulin, and E. Grave, “Unsupervised dense information retrieval with contrastive learning,”arXiv preprint arXiv:2112.09118, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
C-pack: Packed resources for general chinese embeddings,
S. Xiao, Z. Liu, P. Zhang, N. Muennighoff, D. Lian, and J.-Y . Nie, “C-pack: Packed resources for general chinese embeddings,” inProceedings of the 47th international ACM SIGIR conference on research and development in information retrieval, 2024, pp. 641–649
2024
-
[4]
Lxmert: Learning cross- modality encoder representations from transformers,
H. Tan and M. Bansal, “Lxmert: Learning cross- modality encoder representations from transformers,” inProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language pro- cessing (EMNLP-IJCNLP), 2019, pp. 5100–5111
2019
-
[5]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
2021
-
[6]
Vista: Visualized text embedding for universal multi-modal retrieval,
J. Zhou, Z. Liu, S. Xiao, B. Zhao, and Y . Xiong, “Vista: Visualized text embedding for universal multi-modal retrieval,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), 2024, pp. 3185–3200
2024
-
[7]
Bert: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” inProceedings of the 2019 conference of the North American chapter of the asso- ciation for computational linguistics: human language technologies, volume 1 (long and short papers), 2019, pp. 4171–4186
2019
-
[8]
Large dual en- coders are generalizable retrievers,
J. Ni, C. Qu, J. Lu, Z. Dai, G. H. Abrego, J. Ma, V . Zhao, Y . Luan, K. Hall, M.-W. Changet al., “Large dual en- coders are generalizable retrievers,” inProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 2022, pp. 9844–9855
2022
-
[9]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
L. Wang, N. Yang, X. Huang, B. Jiao, L. Yang, D. Jiang, R. Majumder, and F. Wei, “Text embeddings by weakly- supervised contrastive pre-training,”arXiv preprint arXiv:2212.03533, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weis- senborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Min- derer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[11]
Masked autoencoders are scalable vision learners,
K. He, X. Chen, S. Xie, Y . Li, P. Dollár, and R. Girshick, “Masked autoencoders are scalable vision learners,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 16 000–16 009
2022
-
[12]
Vilt: Vision-and-language transformer without convolution or region supervi- sion,
W. Kim, B. Son, and I. Kim, “Vilt: Vision-and-language transformer without convolution or region supervi- sion,” inInternational conference on machine learning. PMLR, 2021, pp. 5583–5594
2021
-
[13]
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation,
J. Li, D. Li, C. Xiong, and S. Hoi, “Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation,” inInternational confer- ence on machine learning. PMLR, 2022, pp. 12 888– 12 900
2022
-
[14]
Blip-2: Bootstrap- ping language-image pre-training with frozen image encoders and large language models,
J. Li, D. Li, S. Savarese, and S. Hoi, “Blip-2: Bootstrap- ping language-image pre-training with frozen image encoders and large language models,” inInternational conference on machine learning. PMLR, 2023, pp. 19 730–19 742
2023
-
[15]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural informa- tion processing systems, vol. 30, 2017
2017
-
[16]
Webqa: Multihop and multimodal qa,
Y . Chang, M. Narang, H. Suzuki, G. Cao, J. Gao, and Y . Bisk, “Webqa: Multihop and multimodal qa,” inPro- ceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, 2022, pp. 16 495–16 504. 6
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.