FadeMem: Distance-Aware Memory Consolidation for Autoregressive Video Diffusion
Pith reviewed 2026-06-27 13:42 UTC · model grok-4.3
The pith
FadeMem merges older KV entries under power-law decay to keep long video generation consistent within fixed cache budget.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
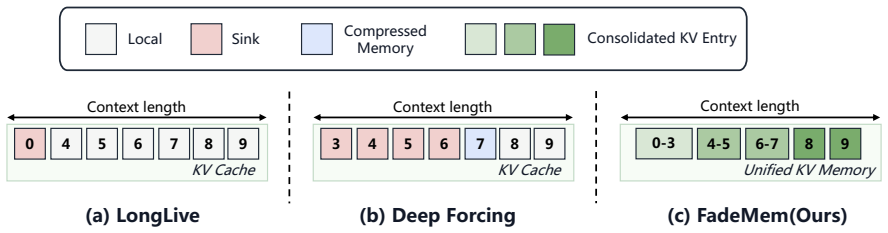
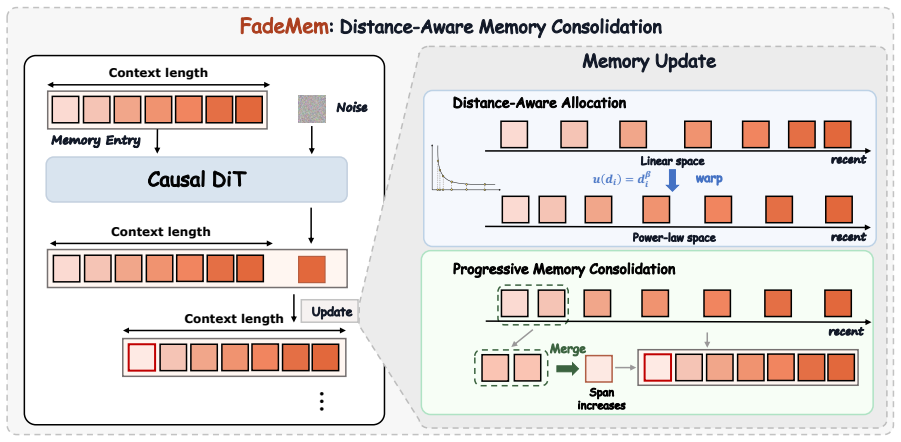
FadeMem is a distance-aware KV memory consolidation mechanism that organizes historical KV blocks into a temporal hierarchy under a fixed cache budget. New history enters as fine-grained entries while older adjacent entries are progressively merged under a power-law temporal allocation schedule. This layout is motivated by frequency-dependent temporal decay, in which fine details decorrelate quickly whereas coarse scene structure and identity remain useful over longer horizons, yielding a dense-near, sparse-far memory that preserves recent context for short-term dynamics and compact long-range anchors for identity and scene coherence.
What carries the argument
Distance-aware KV memory consolidation via power-law temporal allocation schedule that progressively merges adjacent older entries into a dense-near, sparse-far hierarchy.
If this is right
- Recent context remains available for short-term dynamics while long-range anchors support identity and scene coherence.
- Subject consistency, background stability, and temporal coherence improve over existing bounded-cache strategies.
- The method requires no architectural changes to the underlying autoregressive video diffusion model.
- A single fixed cache budget suffices for videos of arbitrary length under the power-law allocation.
Where Pith is reading between the lines
- The same hierarchical merging logic could apply to autoregressive models in other modalities that maintain growing context windows.
- Varying the exponent of the power-law schedule per video content type might further optimize the trade-off between memory use and coherence.
- Combining FadeMem with existing compression techniques such as token eviction could extend feasible video lengths beyond what either method achieves alone.
Load-bearing premise
Frequency-dependent temporal decay allows progressive merging of older KV entries to retain useful coarse scene structure and identity without measurable loss.
What would settle it
An ablation that replaces the power-law merging schedule with uniform or random merging within the same total cache size and shows equal or worse consistency metrics on videos exceeding the training lengths would falsify the claimed advantage of distance-aware consolidation.
Figures

read the original abstract
Autoregressive video generators synthesize long videos by generating successive temporal segments, but their historical KV cache grows with video length. Existing bounded-cache methods reduce this cost with local windows, sink tokens, or compressed memory states, yet they usually assign fixed roles to different parts of the history. We propose FadeMem, a distance-aware KV memory consolidation mechanism that organizes historical KV blocks into a temporal hierarchy under a fixed cache budget. This design is motivated by frequency-dependent temporal decay: fine details decorrelate quickly, while coarse scene structure and identity remain useful over longer horizons. During generation, new history is inserted as fine-grained entries, while older adjacent entries are progressively merged under a power-law temporal allocation schedule, yielding a dense-near, sparse-far memory within one cache. Without architectural changes, FadeMem preserves recent context for short-term dynamics and compact long-range anchors for identity and scene coherence. Experiments show improved subject consistency, background stability, and temporal coherence over existing bounded-cache strategies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes FadeMem, a distance-aware KV memory consolidation mechanism for autoregressive video diffusion models. Historical KV blocks are organized into a temporal hierarchy under a fixed cache budget using a power-law allocation schedule motivated by frequency-dependent temporal decay (fine details decorrelate quickly while coarse structure and identity persist). New entries are inserted at fine granularity while older adjacent blocks are progressively merged, producing a dense-near/sparse-far layout. The design requires no architectural changes and is claimed to improve subject consistency, background stability, and temporal coherence relative to existing bounded-cache strategies.
Significance. If the performance claims are substantiated with rigorous ablations and quantitative evidence, the work could provide a practical, parameter-light technique for scaling autoregressive video generation to longer sequences by exploiting temporal decay structure in the KV cache. The approach is conceptually clean and avoids introducing new learned components.
major comments (2)
- [§3 (Method)] The central design choice rests on the unvalidated claim that frequency-dependent temporal decay permits progressive merging of adjacent KV blocks while retaining coarse scene structure and identity without measurable degradation in attention fidelity. No derivation, attention-map analysis, or ablation measuring post-merge fidelity is supplied to support the power-law schedule.
- [Abstract and §4 (Experiments)] The abstract asserts experimental superiority in subject consistency, background stability, and temporal coherence, yet supplies no quantitative metrics, baseline comparisons, ablation tables, or error bars. Without these, the performance claim cannot be evaluated and the reported gains could arise from implementation details rather than the proposed mechanism.
minor comments (2)
- [§3.1] Notation for the power-law allocation schedule and merge operation should be defined explicitly with equations rather than prose description.
- [Figure 2] Figure captions for any cache-layout diagrams should include the exact cache budget and merge thresholds used in the reported experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond to each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [§3 (Method)] The central design choice rests on the unvalidated claim that frequency-dependent temporal decay permits progressive merging of adjacent KV blocks while retaining coarse scene structure and identity without measurable degradation in attention fidelity. No derivation, attention-map analysis, or ablation measuring post-merge fidelity is supplied to support the power-law schedule.
Authors: We agree the manuscript would be strengthened by explicit validation of the merging step. The power-law schedule is motivated by established observations on frequency-dependent decorrelation in video signals, but the current text provides no derivation or post-merge attention analysis. We will add a targeted ablation measuring attention-output fidelity before and after merges at varying distances, plus a short derivation section grounded in the decay model. revision: yes
-
Referee: [Abstract and §4 (Experiments)] The abstract asserts experimental superiority in subject consistency, background stability, and temporal coherence, yet supplies no quantitative metrics, baseline comparisons, ablation tables, or error bars. Without these, the performance claim cannot be evaluated and the reported gains could arise from implementation details rather than the proposed mechanism.
Authors: The experimental section (§4) already contains quantitative comparisons against bounded-cache baselines (local windows, sink tokens) using subject-consistency and temporal-coherence metrics, together with ablation tables. We acknowledge that the abstract does not cite these specific numbers or reference error bars. We will revise the abstract to summarize the key quantitative gains and point readers to the relevant tables and figures. revision: yes
Circularity Check
No significant circularity; design motivated by external empirical assumption
full rationale
The provided abstract and description present FadeMem as a new distance-aware consolidation scheme whose power-law schedule and dense-near/sparse-far layout are motivated by the stated frequency-dependent decay observation. No equations, fitted parameters, or self-citations appear that would make any claimed prediction or uniqueness reduce to the inputs by construction. The central mechanism is introduced as an independent design choice rather than a renaming or tautological re-derivation of prior quantities.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. 2023 b . https://openaccess.thecvf.com/content/CVPR2023/html/Blattmann_Align_Your_Latents_High-Resolution_Video_Synthesis_With_Latent_Diffusion_Models_CVPR_2023_paper.html Align your latents: High-resolution video synthesis with latent diffusion mod...
2023
-
[4]
Zefan Cai, Yichi Zhang, Bofei Gao, Yuhao Liu, Zitao Li, Hanxu Hu, Miao Zhang, Wenhao Jiang, Kelun Xu, Xiang Li, et al. 2024. https://arxiv.org/abs/2406.02069 PyramidKV : Dynamic KV cache compression based on pyramidal information funneling . arXiv preprint arXiv:2406.02069
Pith/arXiv arXiv 2024
-
[5]
Boyuan Chen, Diego Mart \' Mons \'o , Yilun Du, Max Simchowitz, Russ Tedrake, and Vincent Sitzmann. 2024. https://doi.org/10.52202/079017-0759 Diffusion forcing: Next-token prediction meets full-sequence diffusion . In Advances in Neural Information Processing Systems
-
[6]
Guibin Chen, Dixuan Lin, Jiangping Yang, Chunze Lin, Junchen Zhu, Mingyuan Fan, Hao Zhang, Sheng Chen, Zheng Chen, Chengcheng Ma, Weiming Xiong, Wei Wang, Nuo Pang, Kang Kang, Zhiheng Xu, Yuzhe Jin, Yupeng Liang, Yubing Song, Peng Zhao, Boyuan Xu, Di Qiu, Debang Li, Zhengcong Fei, Yang Li, and Yahui Zhou. 2025. https://arxiv.org/abs/2504.13074 SkyReels-V2...
Pith/arXiv arXiv 2025
-
[8]
Xueji Fang, Liyuan Ma, Zhiyang Chen, Mingyuan Zhou, and Guo-jun Qi. 2025. https://arxiv.org/abs/2505.17574 InfLVG : Reinforce inference-time consistent long video generation with GRPO . arXiv preprint arXiv:2505.17574
arXiv 2025
-
[10]
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richardson, Eran Levin, Guy Shiran, Nir Zabari, et al. 2025. https://arxiv.org/abs/2501.00103 LTX-Video : Realtime video latent diffusion . arXiv preprint arXiv:2501.00103
Pith/arXiv arXiv 2025
-
[11]
Roberto Henschel, Levon Khachatryan, Hayk Poghosyan, Daniil Hayrapetyan, Vahram Tadevosyan, Zhangyang Wang, Shant Navasardyan, and Humphrey Shi. 2025. https://openaccess.thecvf.com/content/CVPR2025/html/Henschel_StreamingT2V_Consistent_Dynamic_and_Extendable_Long_Video_Generation_from_Text_CVPR_2025_paper.html Streaming T2V : Consistent, dynamic, and exte...
2025
-
[12]
Kingma, Ben Poole, Mohammad Norouzi, David J
Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P. Kingma, Ben Poole, Mohammad Norouzi, David J. Fleet, et al. 2022 a . https://arxiv.org/abs/2210.02303 Imagen video: High definition video generation with diffusion models . arXiv preprint arXiv:2210.02303
Pith/arXiv arXiv 2022
-
[13]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. https://proceedings.neurips.cc/paper/2020/hash/4c5bcfec8584af0d967f1ab10179ca4b-Abstract.html Denoising diffusion probabilistic models . In Advances in Neural Information Processing Systems
2020
-
[17]
Sihui Ji, Xi Chen, Shuai Yang, Xin Tao, Pengfei Wan, and Hengshuang Zhao. 2025. https://arxiv.org/abs/2512.14699 MemFlow : Flowing adaptive memory for consistent and efficient long video narratives . arXiv preprint arXiv:2512.14699
arXiv 2025
-
[18]
Youngrae Kim, Qixin Hu, C.-C. Jay Kuo, and Peter A. Beerel. 2026. https://arxiv.org/abs/2603.12513 MemRoPE : Training-free infinite video generation via evolving memory tokens . arXiv preprint arXiv:2603.12513
arXiv 2026
-
[19]
Akio Kodaira, Tingbo Hou, Ji Hou, Markos Georgopoulos, Felix Juefei-Xu, Masayoshi Tomizuka, and Yue Zhao. 2025. https://arxiv.org/abs/2507.03745 StreamDiT : Real-time streaming text-to-video generation . arXiv preprint arXiv:2507.03745
arXiv 2025
-
[21]
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. 2024. https://arxiv.org/abs/2412.03603 HunyuanVideo : A systematic framework for large video generative models . arXiv preprint arXiv:2412.03603
Pith/arXiv arXiv 2024
-
[24]
Yu Lu, Yuanzhi Liang, Linchao Zhu, and Yi Yang. 2024. FreeLong : Training-free long video generation with SpectralBlend temporal attention. In The Thirty-eighth Annual Conference on Neural Information Processing Systems
2024
-
[25]
Yu Lu and Yi Yang. 2025. https://arxiv.org/abs/2507.00162 FreeLong++ : Training-free long video generation via multi-band SpectralFusion . arXiv preprint arXiv:2507.00162
arXiv 2025
-
[26]
William Peebles and Saining Xie. 2023. https://doi.org/10.1109/ICCV51070.2023.00387 Scalable diffusion models with transformers . In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4195--4205
-
[27]
Adam Polyak, Amit Zohar, Andrew Brown, Andros Tjandra, Anushka Sinha, Aidan Lee, Bowen Li, Ching-Yao Chuang, Oran Gafni, Lijun Gong, et al. 2024. https://arxiv.org/abs/2410.13720 Movie Gen : A cast of media foundation models . arXiv preprint arXiv:2410.13720
Pith/arXiv arXiv 2024
-
[28]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj \"o rn Ommer. 2022. https://doi.org/10.1109/CVPR52688.2022.01042 High-resolution image synthesis with latent diffusion models . In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684--10695
-
[29]
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Sen Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, et al. 2022. https://arxiv.org/abs/2209.14792 Make-A-Video : Text-to-video generation without text-video data . arXiv preprint arXiv:2209.14792
Pith/arXiv arXiv 2022
-
[30]
Jiaming Song, Chenlin Meng, and Stefano Ermon. 2021 a . https://openreview.net/forum?id=St1giarCHLP Denoising diffusion implicit models . In International Conference on Learning Representations
2021
-
[31]
Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. 2021 b . https://openreview.net/forum?id=PxTIG12RRHS Score-based generative modeling through stochastic differential equations . In International Conference on Learning Representations
2021
-
[32]
Hansi Teng, Hongyu Jia, Lei Sun, Lingzhi Li, Maolin Li, Mingqiu Tang, Shuai Han, Tianning Zhang, W. Q. Zhang, Weifeng Luo, Xiaoyang Kang, Yuchen Sun, Yue Cao, Yunpeng Huang, Yutong Lin, Yuxin Fang, Zewei Tao, Zheng Zhang, Zhongshu Wang, Zixun Liu, Dai Shi, Guoli Su, Hanwen Sun, Hong Pan, Jie Wang, Jiexin Sheng, Min Cui, Min Hu, Ming Yan, Shucheng Yin, Sir...
Pith/arXiv arXiv 2025
-
[34]
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. 2024. https://openreview.net/forum?id=NG7sS51zVF Efficient streaming language models with attention sinks . In International Conference on Learning Representations
2024
-
[35]
Shuo Yang, Tianyuan Zhao, Wenhao Wang, Mengzhao Chen, Xiang Li, Yuhang Hu, Yuhong Yang, Guanying Lin, Bolei Zhou, Ziwei Liu, et al. 2025. https://arxiv.org/abs/2509.22622 LongLive : Real-time interactive long video generation . arXiv preprint arXiv:2509.22622
Pith/arXiv arXiv 2025
-
[36]
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuan Yang, Wenya Hong, Xiaohan Zhang, Guanyu Feng, et al. 2024. https://arxiv.org/abs/2408.06072 CogVideoX : Text-to-video diffusion models with an expert transformer . arXiv preprint arXiv:2408.06072
Pith/arXiv arXiv 2024
-
[37]
Hidir Yesiltepe, Tuna Han Salih Meral, Adil Kaan Akan, Kaan Oktay, and Pinar Yanardag. 2025. https://arxiv.org/abs/2511.20649 Infinity-RoPE : Action-controllable infinite video generation emerges from autoregressive self-rollout . arXiv preprint arXiv:2511.20649
arXiv 2025
-
[39]
Freeman, Fredo Durand, Eli Shechtman, and Xun Huang
Tianwei Yin, Qiang Zhang, Richard Zhang, William T. Freeman, Fredo Durand, Eli Shechtman, and Xun Huang. 2025. https://openaccess.thecvf.com/content/CVPR2025/html/Yin_From_Slow_Bidirectional_to_Fast_Autoregressive_Video_Diffusion_Models_CVPR_2025_paper.html From slow bidirectional to fast autoregressive video diffusion models . In Proceedings of the IEEE/...
2025
-
[42]
Xinyao Zhang, Wenkai Dong, Yuxin Song, Bo Fang, Qi Zhang, Jing Wang, Fan Chen, Hui Zhang, Haocheng Feng, Yu Lu, et al. 2026. SAMA : Factorized semantic anchoring and motion alignment for instruction-guided video editing. arXiv preprint arXiv:2603.19228
arXiv 2026
-
[43]
2020 , url =
Denoising Diffusion Probabilistic Models , author =. 2020 , url =
2020
-
[44]
2021 , url =
Denoising Diffusion Implicit Models , author =. 2021 , url =
2021
-
[45]
2021 , url =
Score-Based Generative Modeling through Stochastic Differential Equations , author =. 2021 , url =
2021
-
[46]
2022 , doi =
High-Resolution Image Synthesis with Latent Diffusion Models , author =. 2022 , doi =
2022
-
[47]
2023 , doi =
Scalable Diffusion Models with Transformers , author =. 2023 , doi =
2023
-
[48]
arXiv preprint arXiv:2204.03458 , year =
Video Diffusion Models , author =. arXiv preprint arXiv:2204.03458 , year =
-
[49]
and Poole, Ben and Norouzi, Mohammad and Fleet, David J
Ho, Jonathan and Chan, William and Saharia, Chitwan and Whang, Jay and Gao, Ruiqi and Gritsenko, Alexey and Kingma, Diederik P. and Poole, Ben and Norouzi, Mohammad and Fleet, David J. and others , journal =. 2022 , url =
2022
-
[50]
2022 , url =
Singer, Uriel and Polyak, Adam and Hayes, Thomas and Yin, Xi and An, Jie and Zhang, Sen and Hu, Qiyuan and Yang, Harry and Ashual, Oron and Gafni, Oran and others , journal =. 2022 , url =
2022
-
[51]
2023 , url =
Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models , author =. 2023 , url =
2023
-
[52]
arXiv preprint arXiv:2311.15127 , year =
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets , author =. arXiv preprint arXiv:2311.15127 , year =
-
[53]
arXiv preprint arXiv:2312.14125 , year =
Kondratyuk, Dan and Yu, Lijun and Gu, Xi and Lezama, Jos. arXiv preprint arXiv:2312.14125 , year =
-
[54]
2024 , url =
Yang, Zhuoyi and Teng, Jiayan and Zheng, Wendi and Ding, Ming and Huang, Shiyu and Xu, Jiazheng and Yang, Yuan and Hong, Wenya and Zhang, Xiaohan and Feng, Guanyu and others , journal =. 2024 , url =
2024
-
[55]
2024 , url =
Kong, Weijie and Tian, Qi and Zhang, Zijian and Min, Rox and Dai, Zuozhuo and Zhou, Jin and Xiong, Jiangfeng and Li, Xin and Wu, Bo and Zhang, Jianwei and others , journal =. 2024 , url =
2024
-
[56]
Polyak, Adam and Zohar, Amit and Brown, Andrew and Tjandra, Andros and Sinha, Anushka and Lee, Aidan and Li, Bowen and Chuang, Ching-Yao and Gafni, Oran and Gong, Lijun and others , journal =. Movie. 2024 , url =
2024
-
[57]
arXiv preprint arXiv:2503.20314 , year =
Wan: Open and Advanced Large-Scale Video Generative Models , author =. arXiv preprint arXiv:2503.20314 , year =
-
[58]
Zhang, Xinyao and Dong, Wenkai and Song, Yuxin and Fang, Bo and Zhang, Qi and Wang, Jing and Chen, Fan and Zhang, Hui and Feng, Haocheng and Lu, Yu and others , journal =
-
[59]
2025 , url =
From Slow Bidirectional to Fast Autoregressive Video Diffusion Models , author =. 2025 , url =
2025
-
[60]
arXiv preprint arXiv:2506.08009 , year =
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion , author =. arXiv preprint arXiv:2506.08009 , year =
-
[61]
2025 , url =
Yang, Shuo and Zhao, Tianyuan and Wang, Wenhao and Chen, Mengzhao and Li, Xiang and Hu, Yuhang and Yang, Yuhong and Lin, Guanying and Zhou, Bolei and Liu, Ziwei and others , journal =. 2025 , url =
2025
-
[62]
2024 , url =
Efficient Streaming Language Models with Attention Sinks , author =. 2024 , url =
2024
-
[63]
arXiv preprint arXiv:2512.05081 , year =
Deep Forcing: Training-Free Long Video Generation with Deep Sink and Participative Compression , author =. arXiv preprint arXiv:2512.05081 , year =
-
[64]
Jay and Beerel, Peter A
Kim, Youngrae and Hu, Qixin and Kuo, C.-C. Jay and Beerel, Peter A. , journal =. 2026 , url =
2026
-
[65]
arXiv preprint arXiv:2602.06028 , year =
Context Forcing: Consistent Autoregressive Video Generation with Long Context , author =. arXiv preprint arXiv:2602.06028 , year =
-
[66]
2024 , doi =
Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion , author =. 2024 , doi =
2024
-
[67]
Streaming
Henschel, Roberto and Khachatryan, Levon and Poghosyan, Hayk and Hayrapetyan, Daniil and Tadevosyan, Vahram and Wang, Zhangyang and Navasardyan, Shant and Shi, Humphrey , booktitle = CVPR, pages =. Streaming. 2025 , url =
2025
-
[68]
2025 , url =
Kodaira, Akio and Hou, Tingbo and Hou, Ji and Georgopoulos, Markos and Juefei-Xu, Felix and Tomizuka, Masayoshi and Zhao, Yue , journal =. 2025 , url =
2025
-
[69]
2025 , url =
HaCohen, Yoav and Chiprut, Nisan and Brazowski, Benny and Shalem, Daniel and Moshe, Dudu and Richardson, Eitan and Levin, Eran and Shiran, Guy and Zabari, Nir and others , journal =. 2025 , url =
2025
-
[70]
2025 , url =
Fang, Xueji and Ma, Liyuan and Chen, Zhiyang and Zhou, Mingyuan and Qi, Guo-jun , journal =. 2025 , url =
2025
-
[71]
2025 , url =
Chen, Guibin and Lin, Dixuan and Yang, Jiangping and Lin, Chunze and Zhu, Junchen and Fan, Mingyuan and Zhang, Hao and Chen, Sheng and Chen, Zheng and Ma, Chengcheng and Xiong, Weiming and Wang, Wei and Pang, Nuo and Kang, Kang and Xu, Zhiheng and Jin, Yuzhe and Liang, Yupeng and Song, Yubing and Zhao, Peng and Xu, Boyuan and Qiu, Di and Li, Debang and Fe...
2025
-
[72]
Teng, Hansi and Jia, Hongyu and Sun, Lei and Li, Lingzhi and Li, Maolin and Tang, Mingqiu and Han, Shuai and Zhang, Tianning and Zhang, W. Q. and Luo, Weifeng and Kang, Xiaoyang and Sun, Yuchen and Cao, Yue and Huang, Yunpeng and Lin, Yutong and Fang, Yuxin and Tao, Zewei and Zhang, Zheng and Wang, Zhongshu and Liu, Zixun and Shi, Dai and Su, Guoli and Su...
2025
-
[73]
arXiv preprint arXiv:2504.12626 , year =
Frame Context Packing and Drift Prevention in Next-Frame-Prediction Video Diffusion Models , author =. arXiv preprint arXiv:2504.12626 , year =
-
[74]
arXiv preprint arXiv:2510.02283 , year =
Self-Forcing++: Towards Minute-Scale High-Quality Video Generation , author =. arXiv preprint arXiv:2510.02283 , year =
-
[75]
arXiv preprint arXiv:2509.25161 , year =
Rolling Forcing: Autoregressive Long Video Diffusion in Real Time , author =. arXiv preprint arXiv:2509.25161 , year =
-
[76]
arXiv preprint arXiv:2503.19325 , year =
Long-Context Autoregressive Video Modeling with Next-Frame Prediction , author =. arXiv preprint arXiv:2503.19325 , year =
-
[77]
Lu, Yu and Liang, Yuanzhi and Zhu, Linchao and Yang, Yi , booktitle =
-
[78]
2025 , url =
Lu, Yu and Yang, Yi , journal =. 2025 , url =
2025
-
[79]
2021 , url =
Su, Jianlin and Lu, Yu and Pan, Shengfeng and Wen, Bo and Liu, Yunfeng , journal =. 2021 , url =
2021
-
[80]
2025 , url =
Yesiltepe, Hidir and Meral, Tuna Han Salih and Akan, Adil Kaan and Oktay, Kaan and Yanardag, Pinar , journal =. 2025 , url =
2025
-
[81]
2025 , url =
Ji, Sihui and Chen, Xi and Yang, Shuai and Tao, Xin and Wan, Pengfei and Zhao, Hengshuang , journal =. 2025 , url =
2025
-
[82]
arXiv preprint arXiv:2506.03141 , year =
Context as Memory: Scene-Consistent Interactive Long Video Generation with Memory Retrieval , author =. arXiv preprint arXiv:2506.03141 , year =
-
[83]
arXiv preprint arXiv:2508.21058 , year =
Mixture of Contexts for Long Video Generation , author =. arXiv preprint arXiv:2508.21058 , year =
-
[84]
2023 , url =
Zhang, Zhenyu and Sheng, Ying and Zhou, Tianyi and Chen, Tianlong and Zheng, Lianmin and Cai, Ruisi and Song, Zhao and Tian, Yuandong and R. 2023 , url =
2023
-
[85]
Snapkv: Llm knows what you are looking for before generation
Li, Yuhong and Huang, Yingbing and Yang, Bowen and Venkitesh, Bharat and Locatelli, Acyr and Ye, Hanchen and Cai, Tianle and Lewis, Patrick and Chen, Deming , booktitle = NeurIPS, year =. doi:10.52202/079017-0722 , url =
-
[86]
2024 , url =
Cai, Zefan and Zhang, Yichi and Gao, Bofei and Liu, Yuhao and Li, Zitao and Hu, Hanxu and Zhang, Miao and Jiang, Wenhao and Xu, Kelun and Li, Xiang and others , journal =. 2024 , url =
2024
-
[87]
2024 , doi =
Huang, Ziqi and He, Yinan and Yu, Jiashuo and Zhang, Fan and Si, Chenyang and Jiang, Yuming and Zhang, Yuanhan and Wu, Tianxing and Jin, Qingyang and Chanpaisit, Nattapol and Wang, Yaohui and Chen, Xinyuan and Wang, Limin and Lin, Dahua and Qiao, Yu and Liu, Ziwei , booktitle = CVPR, pages =. 2024 , doi =
2024
-
[88]
Huang, Ziqi and Zhang, Fan and Xu, Xiaojie and He, Yinan and Yu, Jiashuo and Dong, Ziyue and Ma, Qianli and Chanpaisit, Nattapol and Si, Chenyang and Jiang, Yuming and others , journal = PAMI, year =. doi:10.1109/TPAMI.2025.3633890 , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.