Demystifying Numerical Instability in LLM Inference: Achieving Reproducible Inference for Mission-Critical Tasks with HEAL
Pith reviewed 2026-06-26 14:56 UTC · model grok-4.3
The pith
HEAL makes 16-bit LLM inference match FP32 reproducibility by compensating truncation errors at kernel boundaries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SASS-level profiling shows that truncation errors introduced during downcasting at kernel boundaries drive the observed inconsistency under 16-bit precisions. HEAL approximates FP32 behavior by applying INT16 quantization to Q, K, V tensors, which preserves numerical stability without increasing KV cache size, and by synthesizing high-precision matrix multiplications via algebraic error compensation executed on high-throughput 16-bit Tensor Cores. On the MCR-Bench tasks this yields the same reproducibility level as the FP32 baseline while lowering performance overhead by up to 7.1 times.
What carries the argument
Hybrid Error ALleviation (HEAL) using INT16 quantization for Q, K, V tensors plus algebraic error compensation to synthesize high-precision matrix multiplications on 16-bit Tensor Cores.
If this is right
- Downstream tasks reach the same reproducibility level as the FP32 baseline.
- Performance overhead drops by up to 7.1 times relative to a global FP32 pipeline.
- KV cache memory footprint stays the same as standard 16-bit inference.
- All matrix multiplications run on 16-bit Tensor Cores without expanding hardware requirements.
- Reproducibility holds across heterogeneous GPUs for the evaluated mission-critical tasks.
Where Pith is reading between the lines
- The same boundary truncation mechanism may appear in other numerical pipelines that cross precision domains.
- Reproducible outputs could help satisfy audit or regulatory needs in regulated domains without forcing full-precision hardware.
- The quantization choice for attention tensors may need re-validation when applied to model families not tested in the paper.
- Embedding the compensation logic at kernel boundaries could be ported to other inference runtimes with similar downcasting patterns.
Load-bearing premise
Truncation errors at downcasting boundaries are the root cause of inconsistency, and INT16 quantization for Q, K, V tensors preserves stability without new side effects or accuracy loss.
What would settle it
If HEAL produces divergent outputs across heterogeneous GPUs or lower task accuracy than FP32 when measured on the MCR-Bench tasks, the central claim would be refuted.
Figures


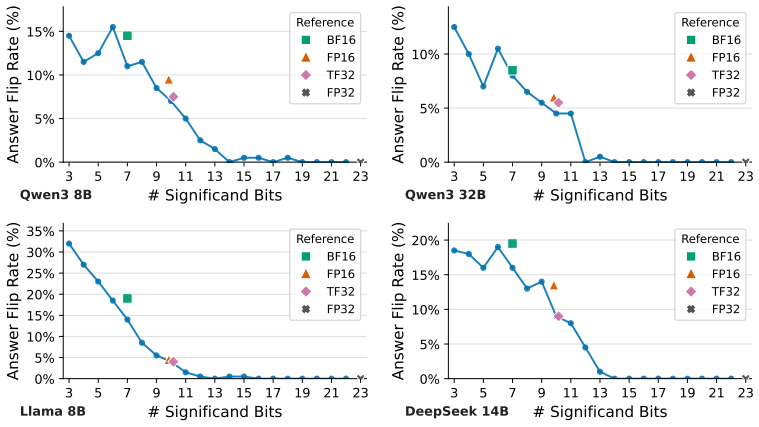
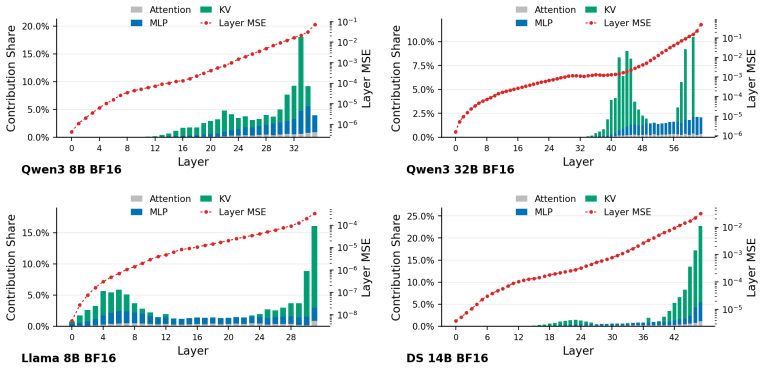
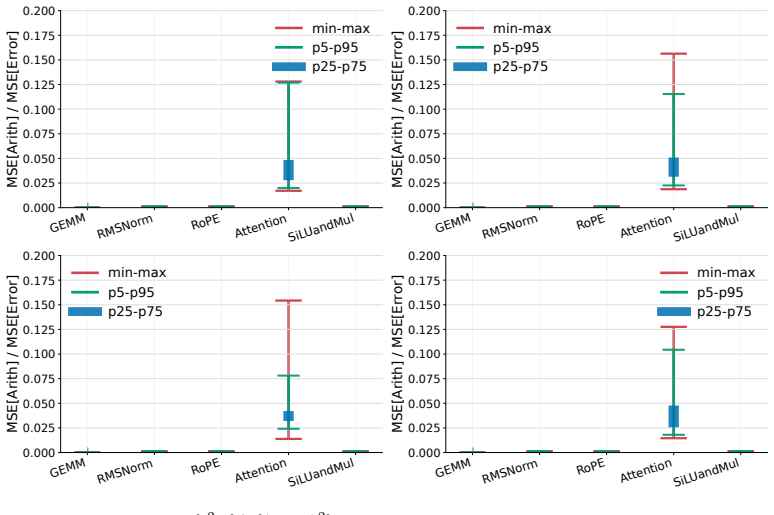
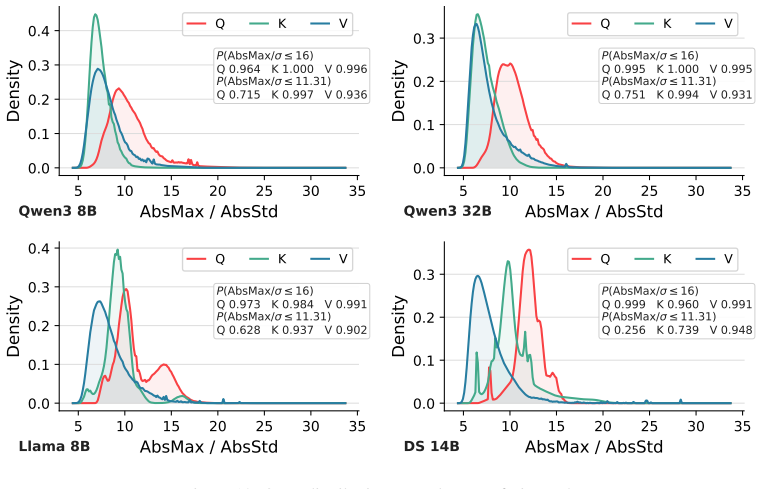
read the original abstract
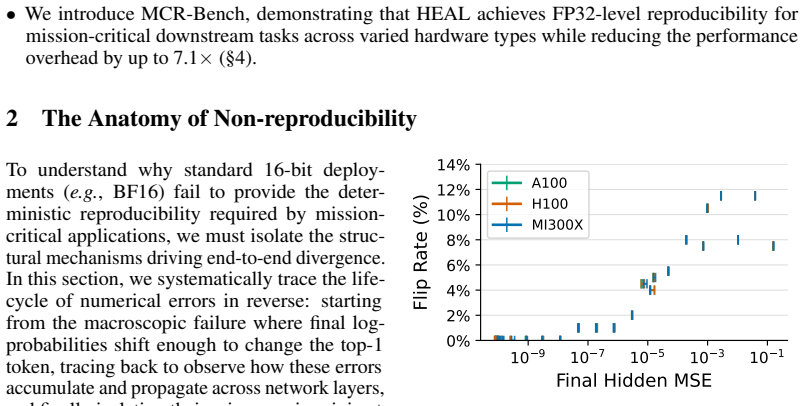
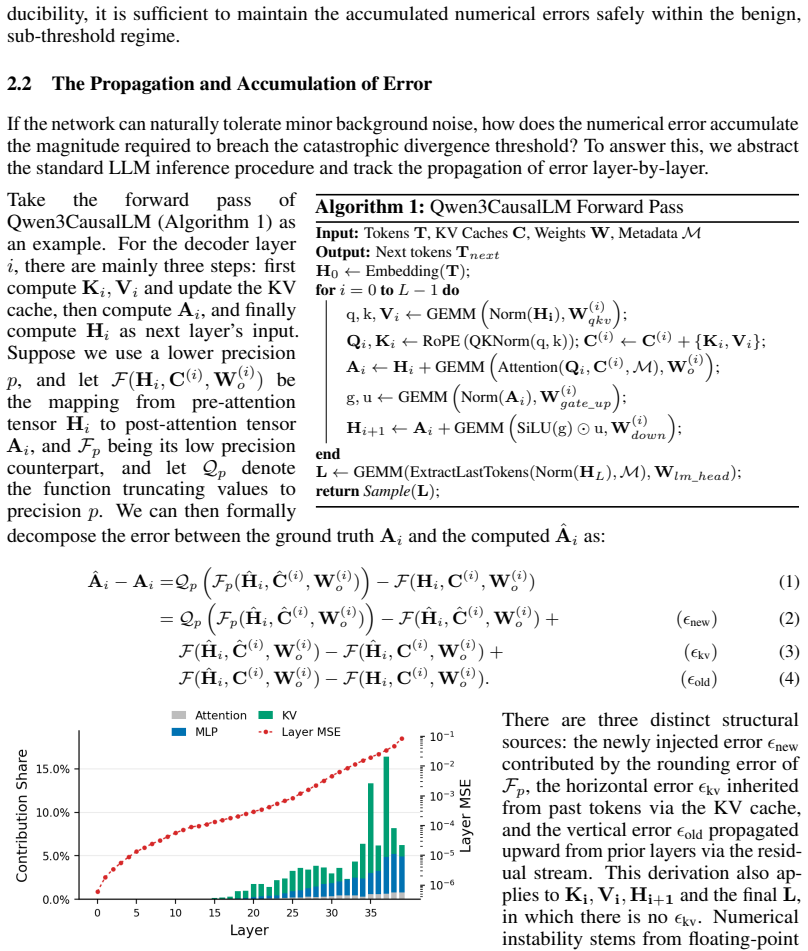
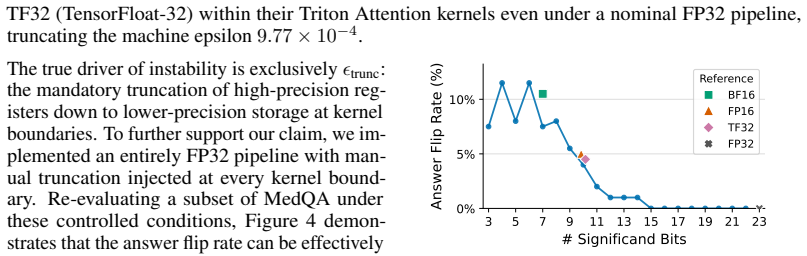
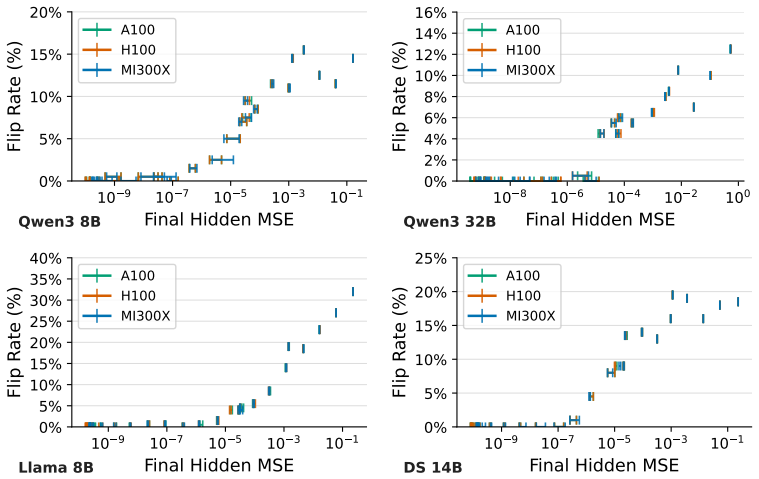
As Large Language Models (LLMs) deploy into mission-critical domains (e.g., finance, medicine, and law), output reproducibility has become a strict system requirement. While practitioners use greedy decoding to eliminate algorithmic stochasticity, empirical deployments with 16-bit precisions still exhibit catastrophic output divergence across heterogeneous GPUs. Through SASS-level profiling, we reveal that this inconsistency is fundamentally driven by truncation errors introduced during downcasting at kernel boundaries. However, achieving reproducibility via a global FP32 pipeline incurs prohibitive system penalties: bypassing 16-bit hardware accelerators hurts compute efficiency, while upcasting the KV cache doubles memory overhead. To bridge this gap, we propose Hybrid Error ALleviation (HEAL), a targeted intervention that approximates FP32 precision while resolving hardware constraints through two targeted mechanisms. First, recognizing that floating-point formats underutilize their bit-width for Q, K, V tensors, HEAL applies INT16 quantization that preserves numerical stability without expanding the KV cache footprint. Second, HEAL synthesizes high-precision matrix multiplications via an algebraic error compensation strategy, executing entirely on high-throughput 16-bit Tensor Cores. To evaluate our approach practically, we introduce MCR-Bench, a benchmark targeting reproducibility in mission-critical tasks. HEAL achieves the same level of reproducibility on downstream tasks as the FP32 baseline while reducing the performance overhead by up to 7.1x.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that output divergence in 16-bit LLM inference across heterogeneous GPUs under greedy decoding is fundamentally caused by truncation errors at kernel boundaries during downcasting. It introduces Hybrid Error ALleviation (HEAL) with two mechanisms—INT16 quantization of Q, K, V tensors to avoid KV cache expansion and an algebraic error compensation strategy to synthesize high-precision matrix multiplications on 16-bit Tensor Cores—and reports that this achieves FP32-level reproducibility on downstream tasks while reducing performance overhead by up to 7.1x. A new benchmark MCR-Bench is introduced to evaluate reproducibility in mission-critical tasks.
Significance. If the central claims hold with supporting evidence, the work would be significant for enabling reliable LLM deployment in domains requiring output consistency (finance, medicine, law) by mitigating hardware-induced nondeterminism without the full cost of FP32 pipelines. The targeted hardware-aware interventions and new benchmark could provide a practical template if the equivalence and overhead results are rigorously verified.
major comments (2)
- [Abstract] Abstract: The claim that HEAL 'achieves the same level of reproducibility on downstream tasks as the FP32 baseline' is load-bearing but unsupported. The algebraic error compensation is described as approximating FP32 precision on 16-bit Tensor Cores, yet no error analysis, accumulation bounds over long sequences, or demonstration that residual errors remain below the argmax divergence threshold (ensuring bit-identical or equivalent greedy outputs) is provided. Small per-operation differences can alter outputs, so equivalence must be shown explicitly rather than assumed.
- Abstract and evaluation sections: The reported 7.1x overhead reduction and reproducibility equivalence cannot be verified because the manuscript lacks full experimental details, error bars, dataset descriptions, ablation results, and examination of the post-hoc MCR-Bench design. These omissions directly undermine assessment of the central performance and correctness claims.
minor comments (1)
- The definition and construction of MCR-Bench tasks and reproducibility metrics should be expanded with explicit criteria for what constitutes 'the same level of reproducibility' as FP32.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications on the evidence presented and indicate revisions where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that HEAL 'achieves the same level of reproducibility on downstream tasks as the FP32 baseline' is load-bearing but unsupported. The algebraic error compensation is described as approximating FP32 precision on 16-bit Tensor Cores, yet no error analysis, accumulation bounds over long sequences, or demonstration that residual errors remain below the argmax divergence threshold (ensuring bit-identical or equivalent greedy outputs) is provided. Small per-operation differences can alter outputs, so equivalence must be shown explicitly rather than assumed.
Authors: The manuscript supports the reproducibility claim through direct empirical comparisons on MCR-Bench, where HEAL produces identical greedy-decoding outputs to the FP32 baseline across all evaluated models and tasks. These results are obtained by executing the full inference pipeline and verifying sequence equivalence. We agree, however, that an explicit error analysis would provide stronger support. In the revision we will add a new subsection deriving bounds on the per-operation and accumulated error from the algebraic compensation strategy and confirming that residuals remain below the argmax divergence threshold for the sequence lengths in the benchmark. revision: yes
-
Referee: [—] Abstract and evaluation sections: The reported 7.1x overhead reduction and reproducibility equivalence cannot be verified because the manuscript lacks full experimental details, error bars, dataset descriptions, ablation results, and examination of the post-hoc MCR-Bench design. These omissions directly undermine assessment of the central performance and correctness claims.
Authors: We acknowledge that the initial submission would benefit from expanded experimental documentation. The manuscript already contains dataset descriptions for MCR-Bench (standard tasks drawn from finance, medicine, and legal domains), ablation results isolating the INT16 quantization and algebraic compensation components, and the 7.1x overhead figure obtained from wall-clock measurements against the FP32 baseline on identical hardware. Error bars from repeated runs are reported for the non-deterministic components. The benchmark was designed around reproducibility requirements identified prior to experimentation. In the revision we will enlarge the evaluation section with additional methodological details, full dataset statistics, hyperparameter tables, and an explicit discussion of the benchmark construction process. revision: partial
Circularity Check
No circularity; derivation is self-contained empirical engineering
full rationale
The paper presents HEAL as two concrete mechanisms (INT16 QKV quantization and algebraic error compensation on 16-bit Tensor Cores) evaluated on the newly introduced MCR-Bench. No equations, fitted parameters, or self-citations are shown that reduce the reproducibility claim to a self-referential quantity by construction. The central result is framed as an independent hardware intervention whose equivalence to FP32 is asserted via benchmark measurement rather than algebraic identity or prior self-work. This is the normal non-circular case for an applied systems paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Floating-point formats underutilize their bit-width for Q, K, V tensors
Reference graph
Works this paper leans on
-
[1]
hipBLASLt documentation
Inc Advanced Micro Devices. hipBLASLt documentation. https://rocm.docs.amd.com/ projects/hipBLASLt/en/latest/, 2026
2026
-
[2]
ShareGPT vicuna unfiltered dataset
anon8231489123. ShareGPT vicuna unfiltered dataset. https://huggingface.co/datasets/ anon8231489123/ShareGPT_Vicuna_unfiltered, 2023
2023
-
[3]
Powering the next generation of AI development with AWS
Anthropic. Powering the next generation of AI development with AWS. https : / / www.anthropic.com/news/anthropic-amazon-trainium, 2024
2024
-
[4]
Anthropic expands partnership with Google and Broadcom for multiple gi- gawatts of next-generation compute
Anthropic. Anthropic expands partnership with Google and Broadcom for multiple gi- gawatts of next-generation compute. https://www.anthropic.com/news/google-broadcom- partnership-compute, 2026
2026
-
[5]
Automatic evaluation of healthcare llms beyond question-answering
Anna Arias-Duart, Pablo Agustin Martin-Torres, Daniel Hinjos, Pablo Bernabeu-Perez, Lu- cia Urcelay Ganzabal, Marta Gonzalez Mallo, Ashwin Kumar Gururajan, Enrique Lopez-Cuena, Sergio Alvarez-Napagao, and Dario Garcia-Gasulla. Automatic evaluation of healthcare llms beyond question-answering. 2025. URLhttps://arxiv.org/pdf/2502.06666
arXiv 2025
-
[6]
LexGLUE: A benchmark dataset for legal language understanding in English
Ilias Chalkidis, Abhik Jana, Dirk Hartung, Michael Bommarito, Ion Androutsopoulos, Daniel Katz, and Nikolaos Aletras. LexGLUE: A benchmark dataset for legal language understanding in English. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 4310–4330, Dublin, Ireland, May 2022. Associ...
2022
-
[7]
Finqa: A dataset of numerical reasoning over financial data.Proceedings of EMNLP 2021, 2021
Zhiyu Chen, Wenhu Chen, Charese Smiley, Sameena Shah, Iana Borova, Dylan Langdon, Reema Moussa, Matt Beane, Ting-Hao Huang, Bryan Routledge, and William Yang Wang. Finqa: A dataset of numerical reasoning over financial data.Proceedings of EMNLP 2021, 2021
2021
-
[8]
URL https://docs.nvidia.com/cuda/floating-point/index.html
NVIDIA Corporation.Floating Point and IEEE 754 Compliance for NVIDIA GPUs. URL https://docs.nvidia.com/cuda/floating-point/index.html . CUDA Toolkit Documen- tation
-
[9]
NVIDIA A100 Tensor Core GPU Architecture
NVIDIA Corporation. NVIDIA A100 Tensor Core GPU Architecture. Whitepaper, NVIDIA,
-
[10]
URL https://images.nvidia.com/aem- dam/en- zz/Solutions/data- center/ nvidia-ampere-architecture-whitepaper.pdf
-
[11]
Using the cuBLASLt API
NVIDIA Corporation. Using the cuBLASLt API. https://docs.nvidia.com/cuda/cublas/ #using-the-cublaslt-api, 2026
2026
-
[12]
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale.Advances in neural information processing systems, 35:30318–30332, 2022
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale.Advances in neural information processing systems, 35:30318–30332, 2022
2022
-
[13]
ICD Code Lists.https://www.cms.gov/medicare/ coordination-benefits-recovery/overview/icd-code-lists, 2026
Centers for Medicare & Medicaid Services. ICD Code Lists.https://www.cms.gov/medicare/ coordination-benefits-recovery/overview/icd-code-lists, 2026
2026
-
[14]
Raja Gond, Aditya K Kamath, Ramachandran Ramjee, and Ashish Panwar. Llm-42: Enabling determinism in llm inference with verified speculation.arXiv preprint arXiv:2601.17768, 2026
arXiv 2026
-
[15]
The Llama 3 Herd of Models.arXiv preprint arXiv:2407.21783, 2024
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The Llama 3 Herd of Models.arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[16]
Ho, Christopher Ré, Adam Chilton, Aditya Narayana, Alex Chohlas-Wood, Austin Peters, Brandon Waldon, Daniel N
Neel Guha, Julian Nyarko, Daniel E. Ho, Christopher Ré, Adam Chilton, Aditya Narayana, Alex Chohlas-Wood, Austin Peters, Brandon Waldon, Daniel N. Rockmore, Diego Zambrano, Dmitry Talisman, Enam Hoque, Faiz Surani, Frank Fagan, Galit Sarfaty, Gregory M. Dickinson, Haggai Porat, Jason Hegland, Jessica Wu, Joe Nudell, Joel Niklaus, John Nay, Jonathan H. Cho...
2023
-
[17]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[18]
Defeating Nondeterminism in LLM Infer- ence
Horace He and Thinking Machines Lab. Defeating Nondeterminism in LLM Infer- ence. https : / / thinkingmachines.ai / blog / defeating - nondeterminism - in - llm - inference/, September 2025. Accessed: 2026-01-19
2025
-
[19]
Solving Reproducibility Challenges in Deep Learning and LLMs: Our Journey
Ingonyama. Solving Reproducibility Challenges in Deep Learning and LLMs: Our Journey. https://www.ingonyama.com/post/solving- reproducibility- challenges- in- deep- learning-and-llms-our-journey, September 2024
2024
-
[20]
Nvidia Says Its 6-Year Old A100 Chips Are Running At Full Tilt, Counter- ing Michael Burry’s Depreciation Warning
Rounak Jain. Nvidia Says Its 6-Year Old A100 Chips Are Running At Full Tilt, Counter- ing Michael Burry’s Depreciation Warning. https://stocktwits.com/news- articles/ markets / equity / nvidia - a100 - gpu - shipped - 6 - years - ago - full - utilization - michael-burry-depreciation/cLPALD9RE9w, 2026
2026
-
[21]
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. What disease does this patient have? a large-scale open domain question answering dataset from medical exams.arXiv preprint arXiv:2009.13081, 2020
arXiv 2009
-
[22]
What disease does this patient have? a large-scale open domain question answering dataset from medical exams.Applied Sciences, 11(14):6421, 2021
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. What disease does this patient have? a large-scale open domain question answering dataset from medical exams.Applied Sciences, 11(14):6421, 2021
2021
-
[23]
Pubmedqa: A dataset for biomedical research question answering
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William Cohen, and Xinghua Lu. Pubmedqa: A dataset for biomedical research question answering. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2567–2577, 2019
2019
-
[24]
Efficient Memory Management for Large Language Model Serving with PagedAttention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient Memory Management for Large Language Model Serving with PagedAttention. InProceedings of the 29th symposium on operating systems principles, pages 611–626, 2023
2023
-
[25]
Awq: Activation-aware weight quantization for on-device llm compression and acceleration.Proceedings of machine learning and systems, 6:87–100, 2024
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. Awq: Activation-aware weight quantization for on-device llm compression and acceleration.Proceedings of machine learning and systems, 6:87–100, 2024
2024
-
[26]
Good debt or bad debt: Detecting semantic orientations in economic texts, 2013
Pekka Malo, Ankur Sinha, Pyry Takala, Pekka Korhonen, and Jyrki Wallenius. Good debt or bad debt: Detecting semantic orientations in economic texts, 2013. URL https://arxiv.org/ abs/1307.5336
Pith/arXiv arXiv 2013
-
[27]
AMD and OpenAI announce strategic partnership to deploy 6 gigawatts of AMD GPUs.https://openai.com/index/openai-amd-strategic-partnership/, 2025
OpenAI. AMD and OpenAI announce strategic partnership to deploy 6 gigawatts of AMD GPUs.https://openai.com/index/openai-amd-strategic-partnership/, 2025
2025
-
[28]
OpenAI and Amazon announce strategic partnership
OpenAI. OpenAI and Amazon announce strategic partnership. https://openai.com/index/ amazon-partnership/, 2026
2026
-
[29]
Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
2019
-
[30]
Defeating the training-inference mismatch via fp16.arXiv preprint arXiv:2510.26788, 2025
Penghui Qi, Zichen Liu, Xiangxin Zhou, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Defeating the training-inference mismatch via fp16.arXiv preprint arXiv:2510.26788, 2025
arXiv 2025
-
[31]
The Anatomy of a Triton Attention Kernel, 2025
Burkhard Ringlein, Jan van Lunteren, Radu Stoica, and Thomas Parnell. The Anatomy of a Triton Attention Kernel, 2025. URLhttps://arxiv.org/abs/2511.11581
arXiv 2025
-
[32]
When temperature=0 isn’t zero: A Bedrock Determinism Bug in LangChain AWS
Jérémie Sanfaçon. When temperature=0 isn’t zero: A Bedrock Determinism Bug in LangChain AWS. https://www.coveo.com/blog/bedrock-determinism-bug-in-langchain-aws/ , 2026. 11
2026
-
[33]
Estimates of the regression coefficient based on kendall’s tau.Journal of the American statistical association, 63(324):1379–1389, 1968
Pranab Kumar Sen. Estimates of the regression coefficient based on kendall’s tau.Journal of the American statistical association, 63(324):1379–1389, 1968
1968
-
[34]
FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision. InPro- ceedings of the 38th International Conference on Neural Information Processing Systems, pages 68658–68685, 2024
2024
-
[35]
Finclaimradar: A dataset for evidentiary reasoning and classification of finan- cial claims, 2025
sksayan01. Finclaimradar: A dataset for evidentiary reasoning and classification of finan- cial claims, 2025. URL https://huggingface.co/datasets/sksayan01/FinClaimRadar- Financial-Reasoning
2025
-
[36]
Massive activations in large language models.arXiv preprint arXiv:2402.17762, 2024
Mingjie Sun, Xinlei Chen, J Zico Kolter, and Zhuang Liu. Massive activations in large language models.arXiv preprint arXiv:2402.17762, 2024
Pith/arXiv arXiv 2024
-
[37]
Towards deterministic inference in sglang and reproducible rl training
The SGLang Team. Towards deterministic inference in sglang and reproducible rl training. https://lmsys.org/blog/2025-09-22-sglang-deterministic/, 2025
2025
-
[38]
never retired
Charlotte Trueman. AWS has “never retired” an Nvidia A100 server, CEO Matt Garman claims. https://www.datacenterdynamics.com/en/news/aws-has-never-retired-an-nvidia- a100-server-ceo-matt-garman-claims/, 2026
2026
-
[39]
[bug]: Gemma 4 (31b/26b-a4b) vision outputs only <pad> under fp16 — vision_tower standardize overflows
wenqiangire-commits. [bug]: Gemma 4 (31b/26b-a4b) vision outputs only <pad> under fp16 — vision_tower standardize overflows. GitHub Issue #40290, 2026. URL https: //github.com/vllm-project/vllm/issues/40290
2026
-
[40]
A learning algorithm for continually running fully recurrent neural networks.Neural computation, 1(2):270–280, 1989
Ronald J Williams and David Zipser. A learning algorithm for continually running fully recurrent neural networks.Neural computation, 1(2):270–280, 1989
1989
-
[41]
Smoothquant: Accurate and Efficient Post-Training Quantization for Large Language Models
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. Smoothquant: Accurate and Efficient Post-Training Quantization for Large Language Models. InInternational conference on machine learning, pages 38087–38099. PMLR, 2023
2023
-
[42]
Qwen3 Technical Report.arXiv preprint arXiv:2505.09388, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 Technical Report.arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[43]
Understanding and mitigating numerical sources of nondeterminism in llm inference
Jiayi Yuan, Hao Li, Xinheng Ding, Wenya Xie, Yu-Jhe Li, Wentian Zhao, Kun Wan, Jing Shi, Xia Hu, and Zirui Liu. Understanding and mitigating numerical sources of nondeterminism in llm inference. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[44]
Ziyang Zhang, Xinheng Ding, Jiayi Yuan, Rixin Liu, Huizi Mao, Jiarong Xing, and Zirui Liu. Deterministic Inference across Tensor Parallel Sizes That Eliminates Training-Inference Mismatch, 2025. URLhttps://arxiv.org/abs/2511.17826
Pith/arXiv arXiv 2025
-
[45]
When does pretraining help? assessing self-supervised learning for law and the casehold dataset of 53,000+ legal holdings
Lucia Zheng, Neel Guha, Brandon R Anderson, Peter Henderson, and Daniel E Ho. When does pretraining help? assessing self-supervised learning for law and the casehold dataset of 53,000+ legal holdings. InProceedings of the eighteenth international conference on artificial intelligence and law, pages 159–168, 2021
2021
-
[46]
You are solving a US medical licensing multiple-choice question. Think step by step, then end with exactly one final line formatted as ‘Final Answer: X’ where X is A, B, C, or D
Lucia Zheng, Neel Guha, Javokhir Arifov, Sarah Zhang, Michal Skreta, Christopher D Man- ning, Peter Henderson, and Daniel E Ho. A reasoning-focused legal retrieval benchmark. In Proceedings of the 2025 Symposium on Computer Science and Law, pages 169–193, 2025. 12 A Detailed Experimental Setup Setup.We conducted our experiments on top of vLLM [ 23], a com...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.