Not All Objectives Are Born Equal: Priority-Constrained Descent for Hierarchical Multi-Objective Optimization
Pith reviewed 2026-06-30 07:27 UTC · model grok-4.3
The pith
Priority-Constrained Descent adjusts the primary gradient with the smallest distortion needed to guarantee secondary objective progress.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PCD computes a descent direction that stays as close as possible to the primary gradient while satisfying a linear constraint that ensures positive progress on each secondary objective; the minimal-distortion solution is controlled by tau in [0,1] and yields scale-invariant updates with closed-form solutions for two and three objectives.
What carries the argument
Priority-Constrained Descent, the optimization step that solves for the smallest change to the primary gradient satisfying secondary progress constraints.
If this is right
- Exact closed-form solutions exist for two-objective and three-objective cases.
- The update is invariant under independent rescaling of any objective.
- Secondary objectives are guaranteed to improve at each step for tau greater than zero.
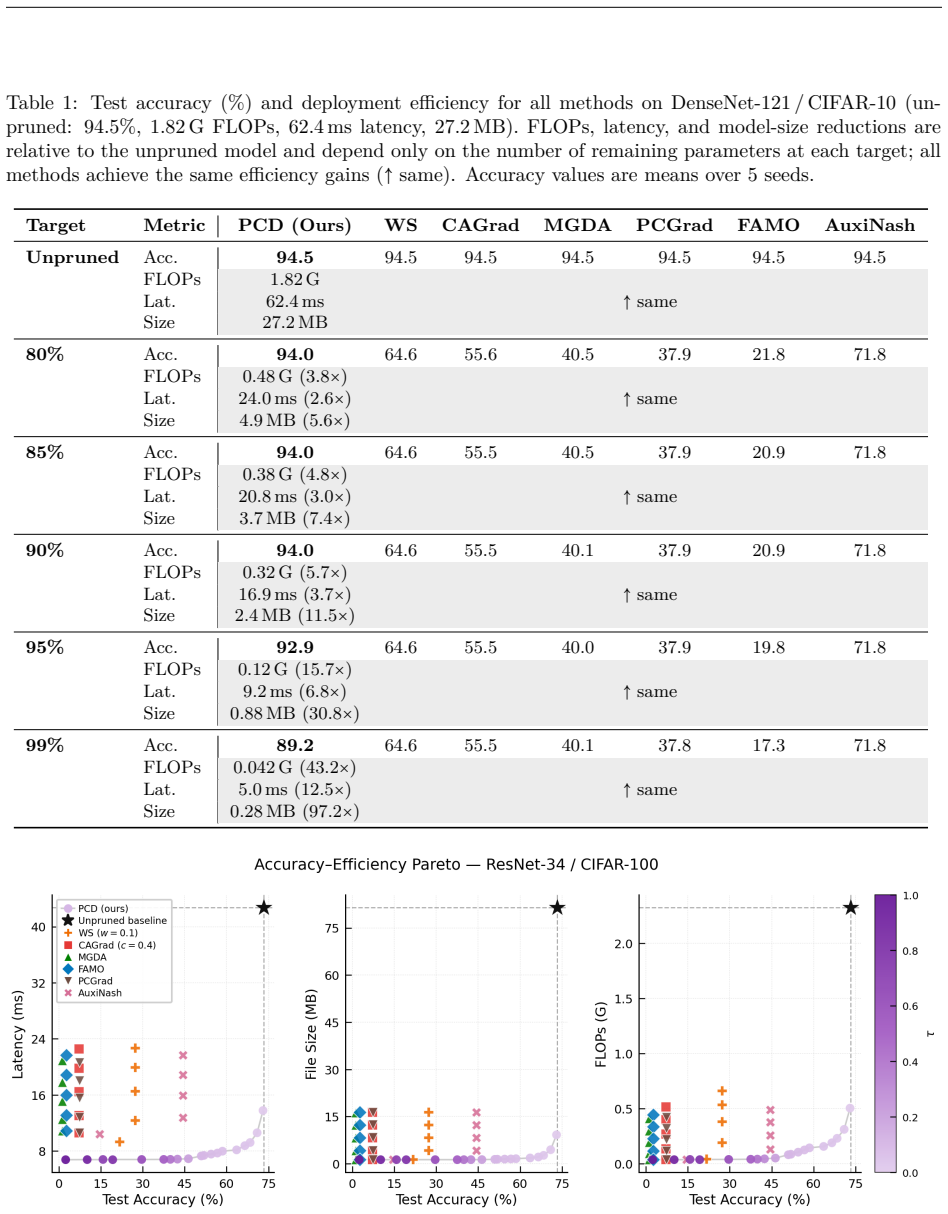
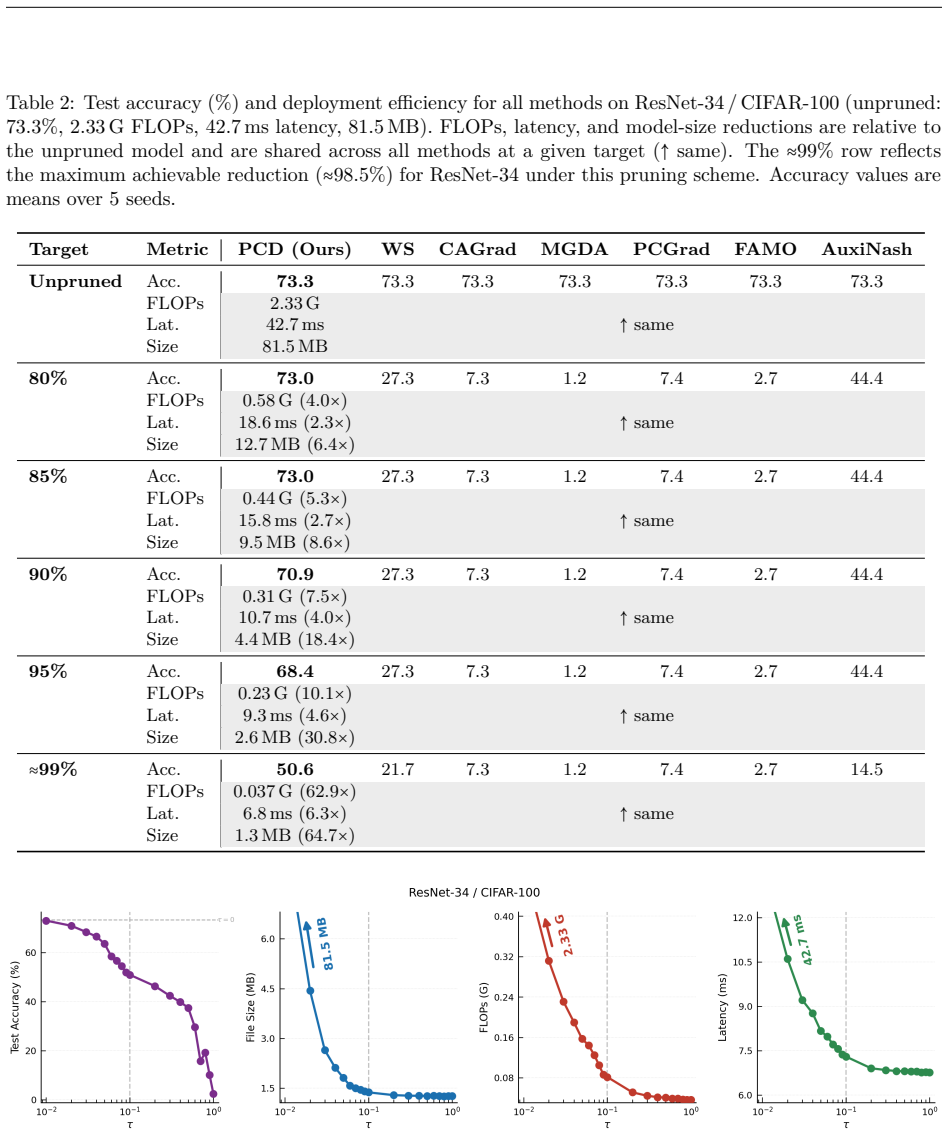
- Empirical evaluations demonstrate Pareto dominance over symmetric multi-objective baselines in compression and sparsity tasks.
Where Pith is reading between the lines
- The same minimal-distortion construction could be applied to safety-critical reinforcement learning where a primary reward must dominate auxiliary constraints.
- Iterative application of the two- and three-objective closed forms might yield practical approximations for larger numbers of objectives.
- The method's behavior on non-convex loss surfaces remains to be checked, since the current derivations assume the existence of the required direction at every step.
Load-bearing premise
A direction always exists that keeps the primary gradient direction while still guaranteeing secondary progress, and this direction can be recovered in closed form.
What would settle it
A concrete multi-objective problem in which the closed-form PCD direction either violates the primary gradient alignment or fails to improve at least one secondary objective.
Figures
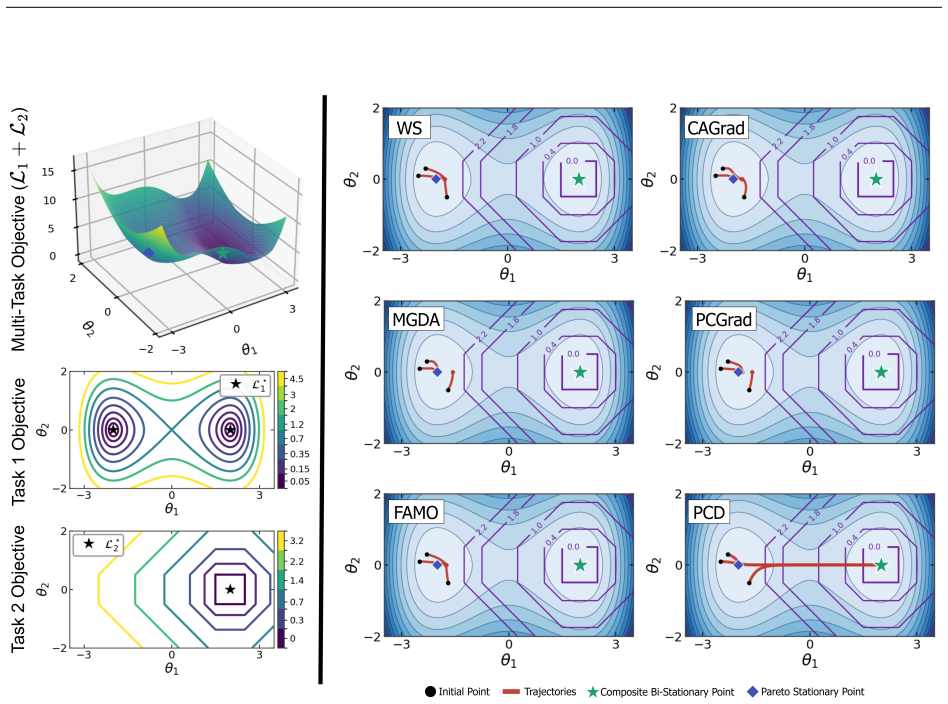
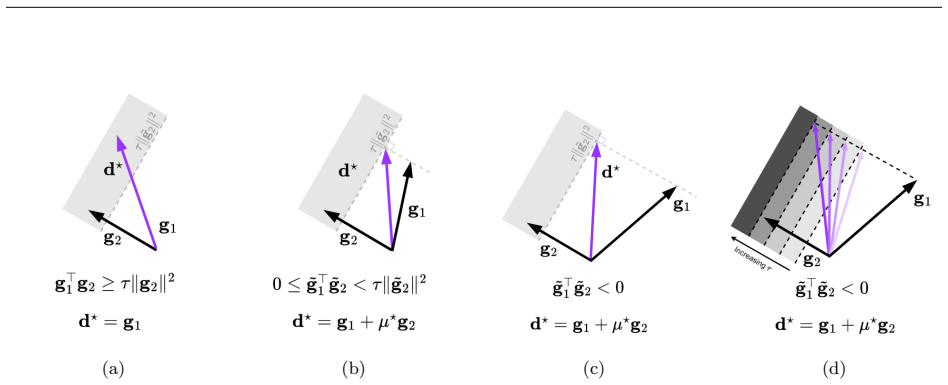
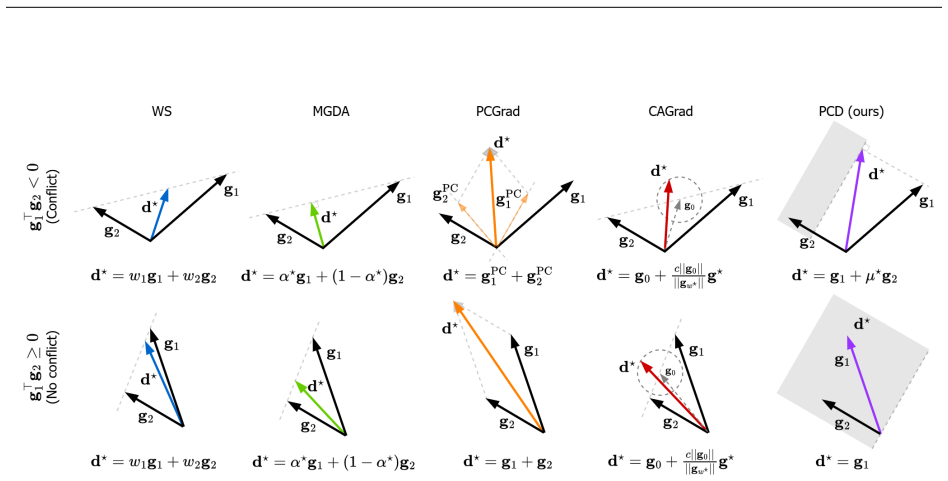
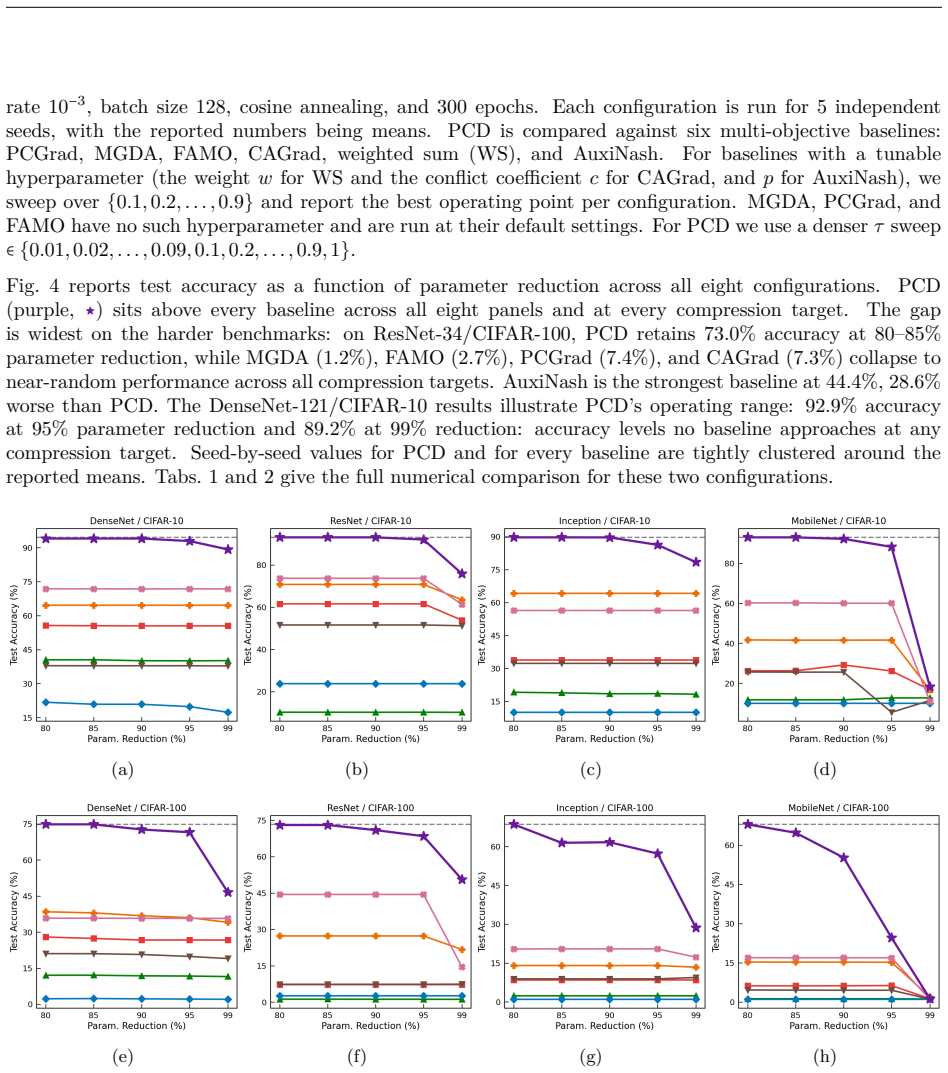
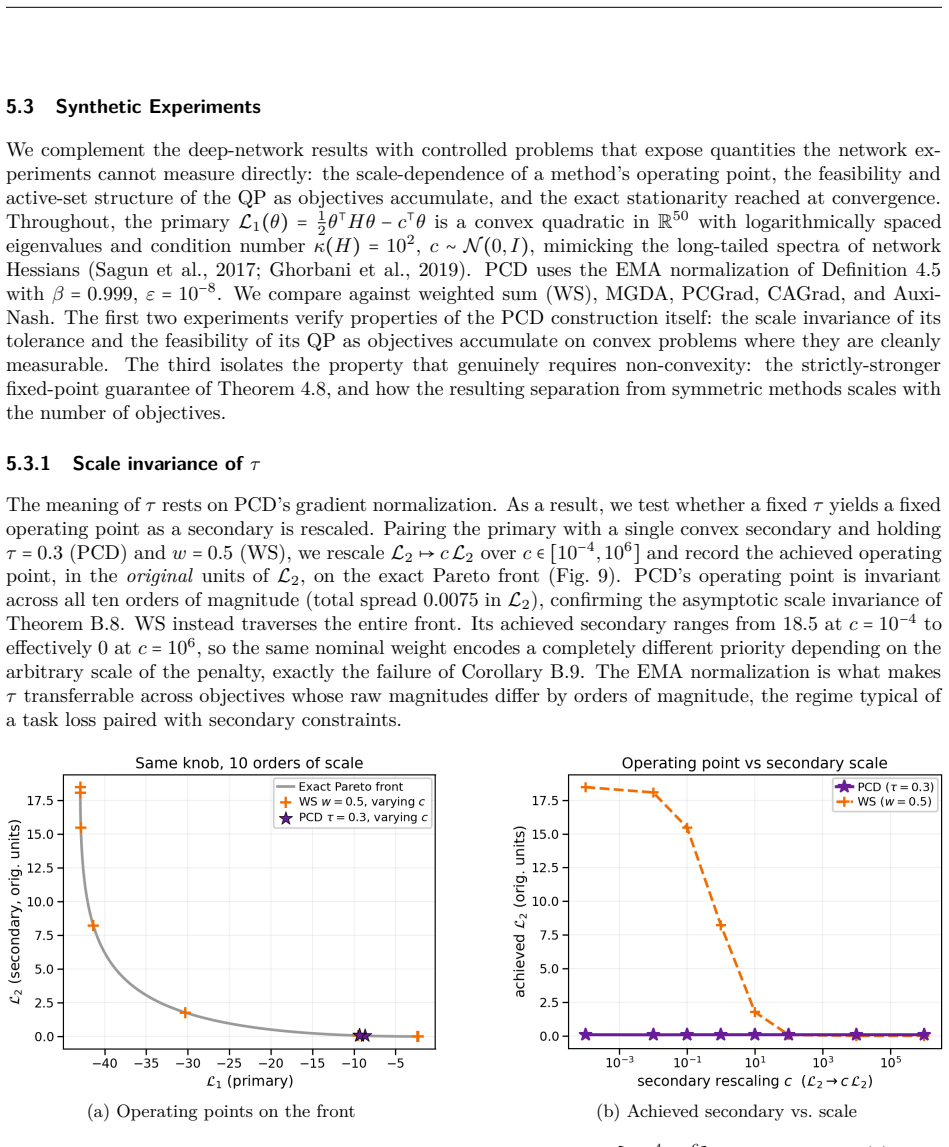
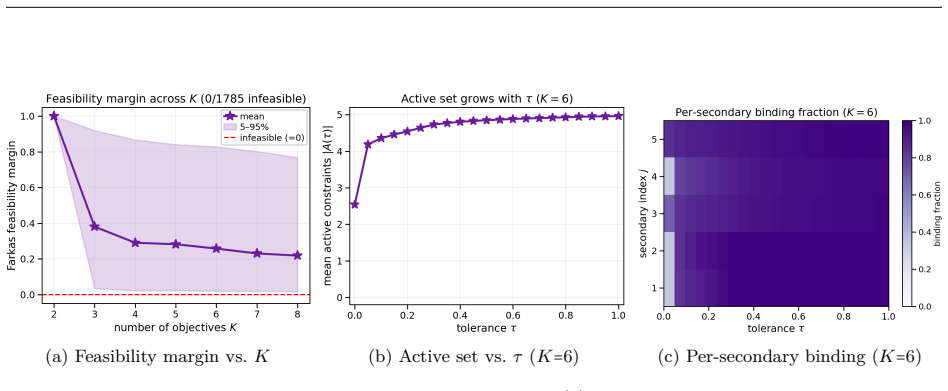
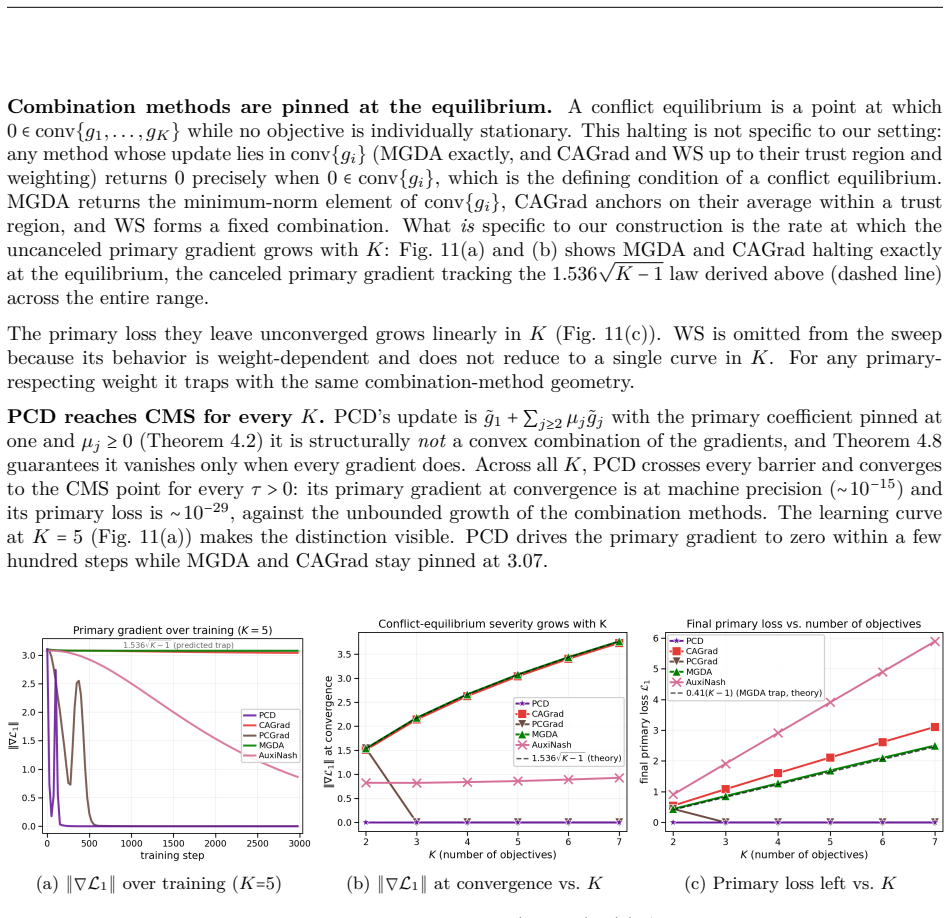
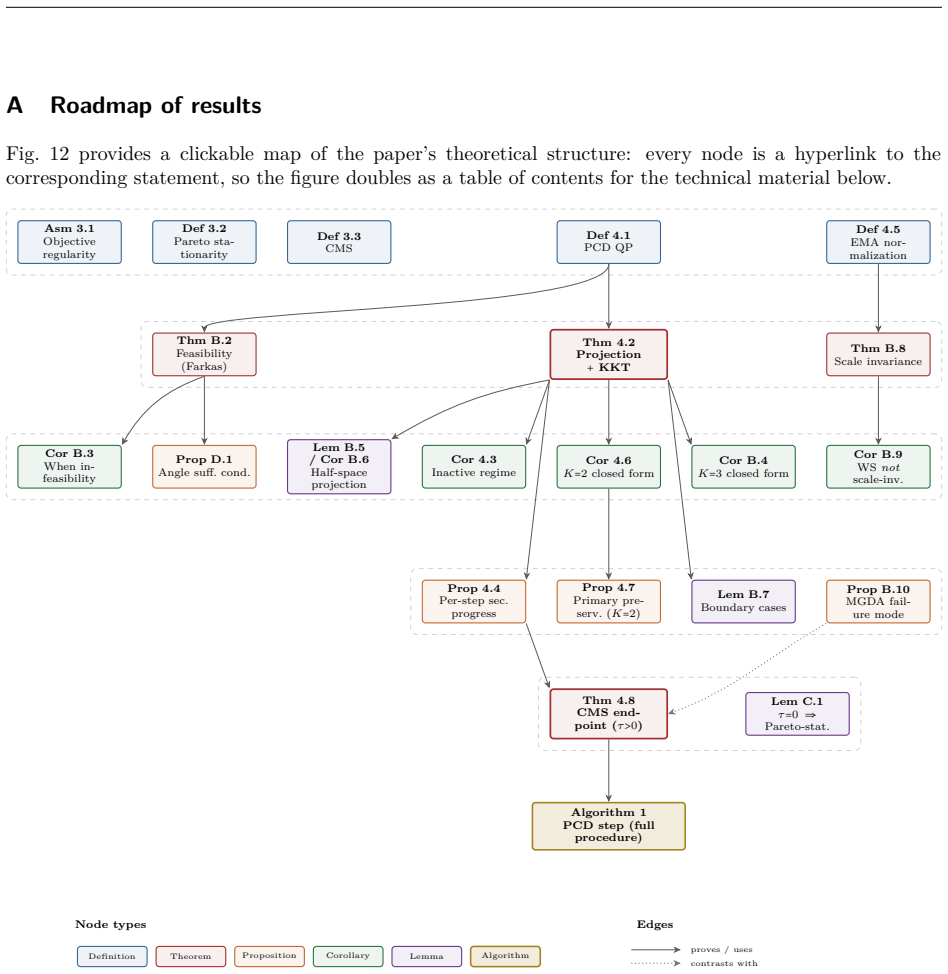
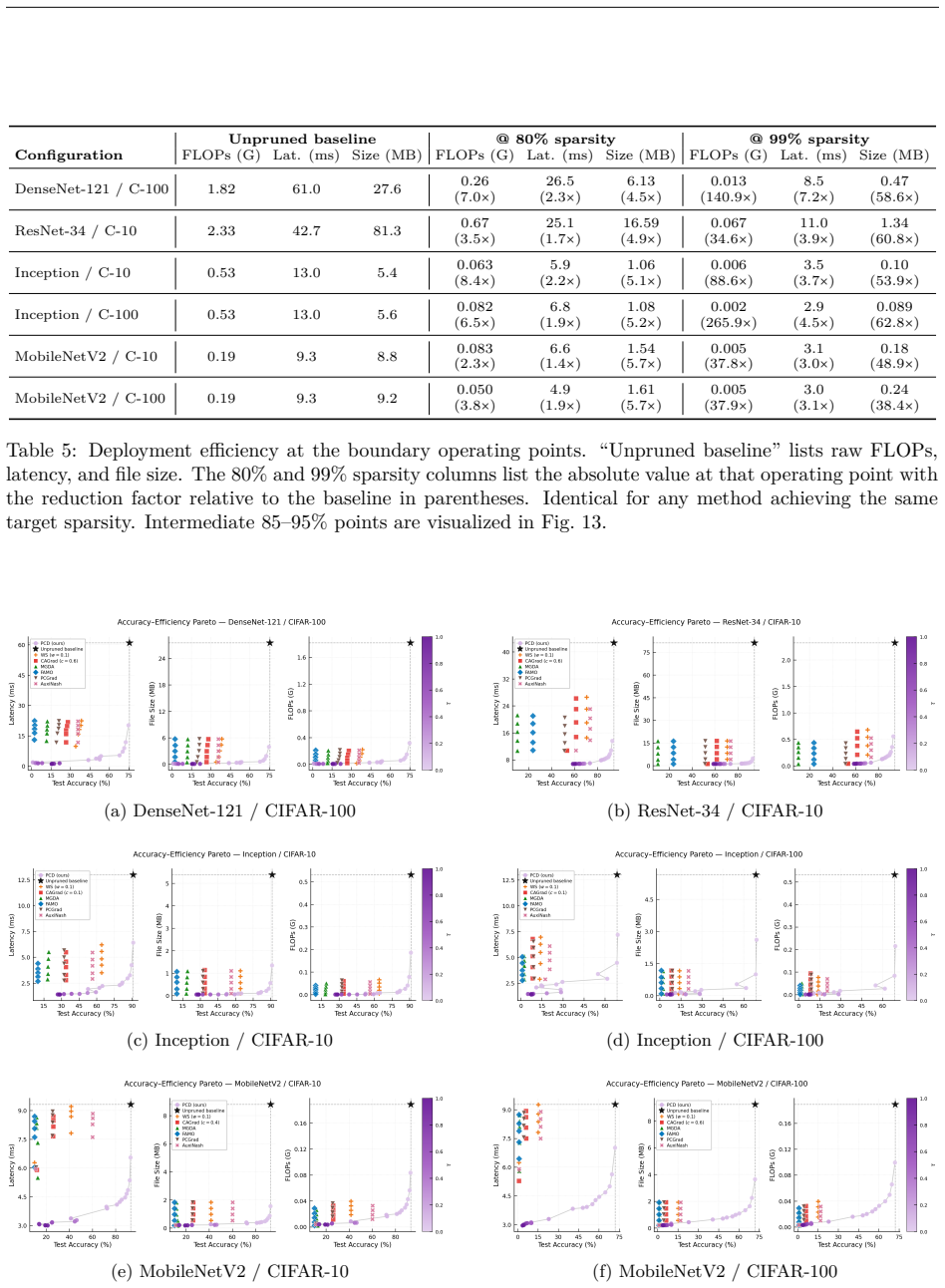
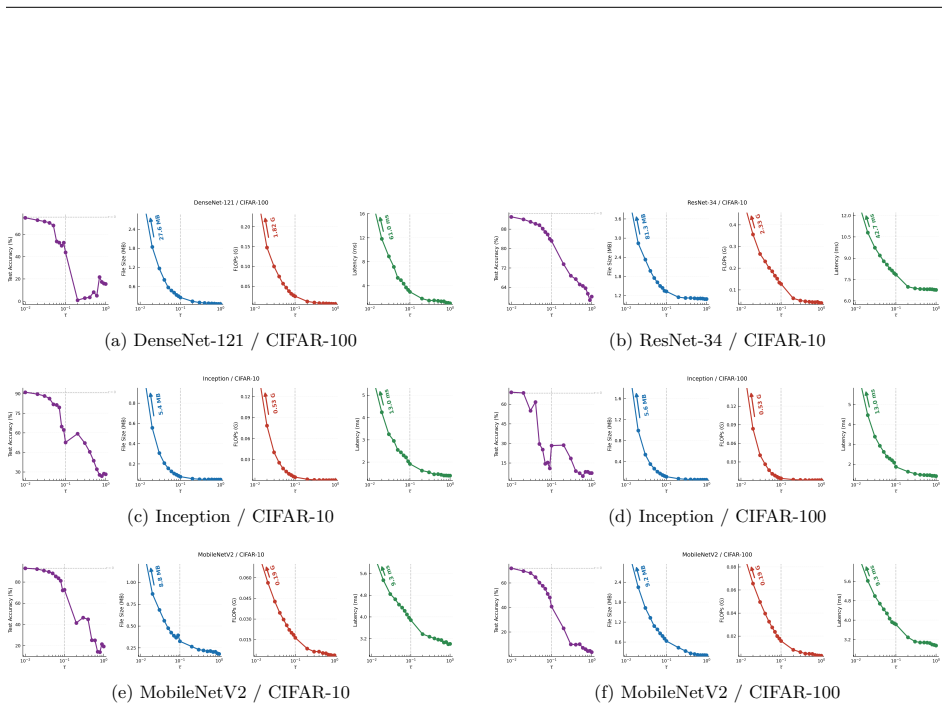
read the original abstract
Deep learning problems rarely involve objectives that are equal in importance. A primary objective defines the goal, whilst secondary objectives, such as sparsity, compression, or robustness constrain the solution. While existing multi-objective methods have proven effective in practice, they have a clear symmetry problem and neglect the inherent objective hierarchy built into these objective spaces. We introduce Priority-Constrained Descent (PCD), a gradient-based optimization framework designed to explicitly exploit hierarchical objective structures. PCD preserves the direction of primary descent whilst allowing for the minimal distortion necessary to guarantee progress on secondary objectives, controlled by a single $\tau \in [0, 1]$ that dictates the strength of the distortion. The resulting formulation is invariant to objective scaling and admits exact closed-form solutions for problems with two and three objectives. We evaluate PCD within structured network compression settings, unstructured sparsity and low-rankness, and across a variety of synthetic experiments, showing Pareto dominance and better per-objective performance with secondary progress guarantees over existing methods, further exhibiting the interpretable trade-off that $\tau$ provides.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Priority-Constrained Descent (PCD), a gradient-based method for hierarchical multi-objective optimization. PCD is claimed to preserve the exact descent direction of a primary objective while applying the minimal distortion (controlled by a scalar τ ∈ [0,1]) needed to guarantee descent on secondary objectives. The formulation is asserted to be invariant to objective scaling and to admit exact closed-form solutions for the two- and three-objective cases. Experiments on structured/unstructured network compression, low-rankness, and synthetic tasks report Pareto dominance and explicit secondary-progress guarantees relative to existing multi-objective baselines.
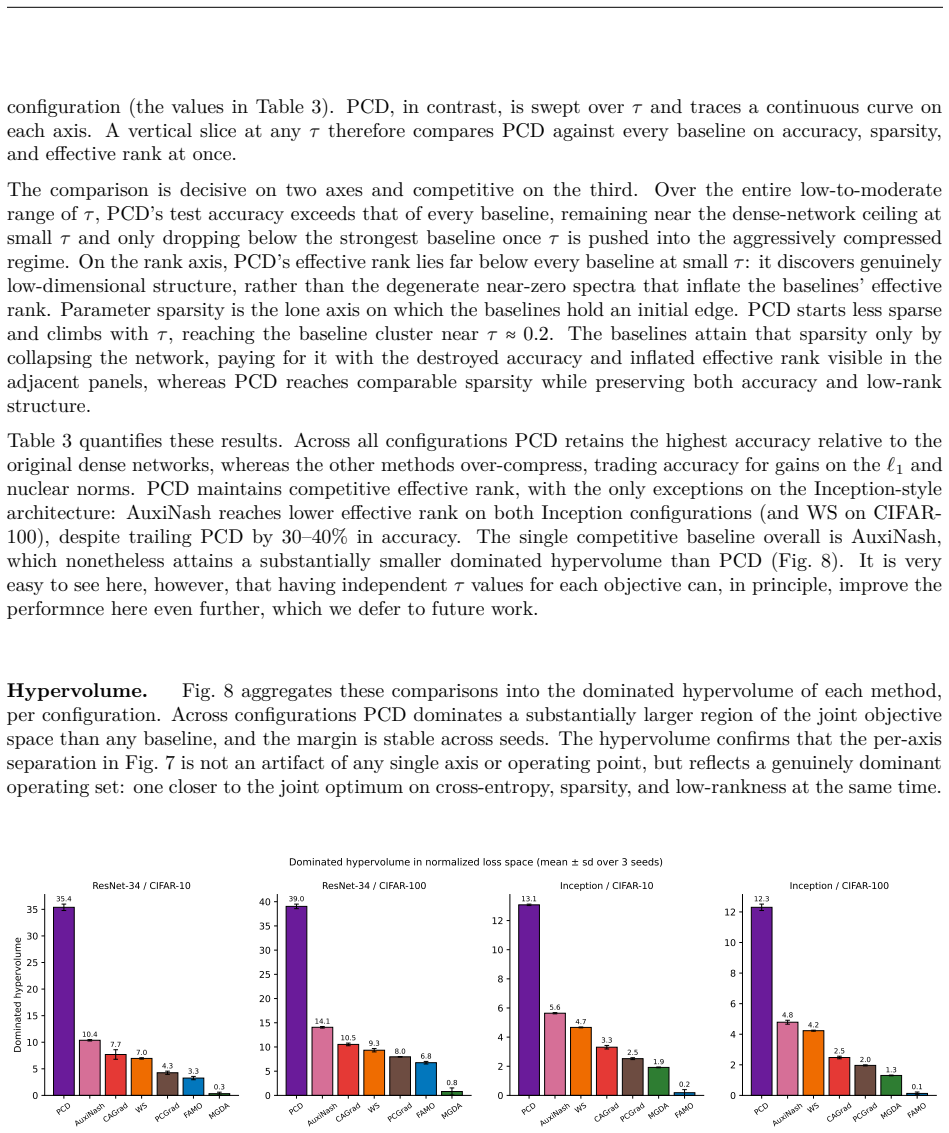
Significance. If the closed-form derivations are valid and the direction always exists without hidden assumptions on gradient angles or norms, PCD would supply a practical, single-parameter, scaling-invariant alternative to symmetric Pareto methods, directly exploiting the objective hierarchies common in compression and robustness tasks. The explicit secondary-progress guarantee and interpretable τ-tradeoff would be useful strengths.
major comments (1)
- [PCD derivation (closed-form solutions for 2-3 objectives)] The central claim of an exact closed-form PCD direction for two and three objectives that simultaneously preserves the primary gradient direction and guarantees negative inner product with each secondary gradient (while remaining scaling-invariant) appears to rest on an unstated existence assumption. When a secondary gradient lies in the half-space opposite the primary, no direction sufficiently aligned with the primary can satisfy the secondary constraint; the minimal-distortion solution then either fails to exist or requires an implicit projection whose closed form would depend on relative magnitudes, contradicting the parameter-free and scaling-invariant assertions. This is load-bearing for the closed-form and guarantee claims.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback on our manuscript. We appreciate the positive assessment of PCD's potential as a practical alternative for hierarchical multi-objective optimization. We address the single major comment below.
read point-by-point responses
-
Referee: The central claim of an exact closed-form PCD direction for two and three objectives that simultaneously preserves the primary gradient direction and guarantees negative inner product with each secondary gradient (while remaining scaling-invariant) appears to rest on an unstated existence assumption. When a secondary gradient lies in the half-space opposite the primary, no direction sufficiently aligned with the primary can satisfy the secondary constraint; the minimal-distortion solution then either fails to exist or requires an implicit projection whose closed form would depend on relative magnitudes, contradicting the parameter-free and scaling-invariant assertions. This is load-bearing for the closed-form and guarantee claims.
Authors: We acknowledge the validity of this observation. The closed-form solutions for the two- and three-objective cases are derived under the assumption that a direction exists which remains sufficiently aligned with the primary descent direction while satisfying the secondary descent constraints (negative inner products). This assumption fails to hold when a secondary gradient lies in direct opposition to the primary (i.e., when any direction satisfying primary descent necessarily produces ascent on the secondary objective). In such cases, achieving the secondary constraint requires distortion that depends on relative gradient magnitudes, which would indeed affect the claimed scaling invariance. We agree that the existence condition is load-bearing and was not explicitly stated. We will revise the manuscript to (i) explicitly articulate the conditions under which the closed-form PCD direction exists and (ii) discuss the opposing-gradient case, including how the method behaves (e.g., via tau modulation or fallback to primary-only descent). This clarification will be added without altering the core algorithmic claims for the settings where the direction exists. revision: yes
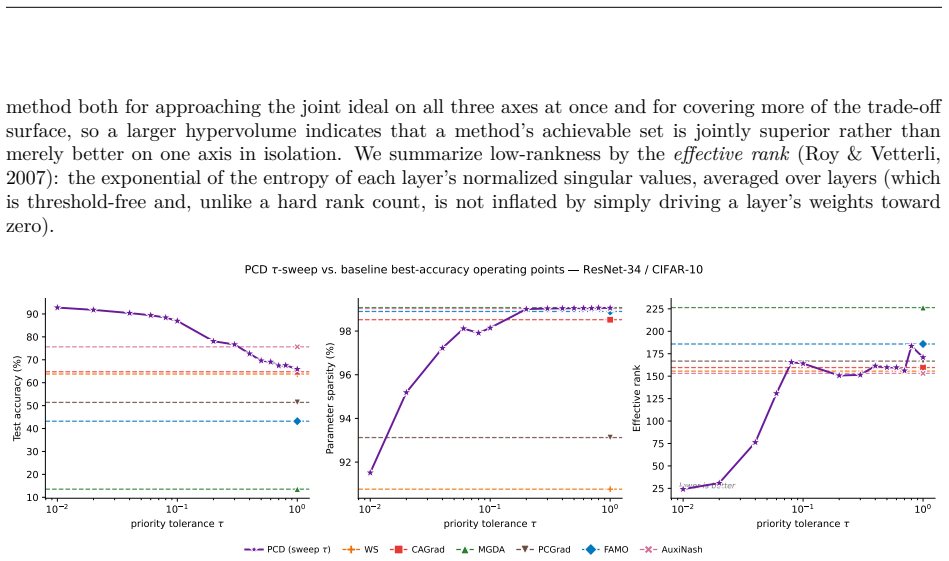
Circularity Check
No circularity; PCD derivation is self-contained from gradient constraints
full rationale
The paper derives Priority-Constrained Descent directly from the requirement to preserve the primary gradient direction while enforcing negative inner products with secondary gradients, using an explicit scalar τ for distortion control. No equations reduce to fitted inputs by construction, no self-citations are invoked as load-bearing uniqueness theorems, and the closed-form solutions for 2-3 objectives are presented as algebraic results of the quadratic program without renaming known patterns or smuggling ansatzes. The scaling invariance follows from the formulation itself rather than data-dependent fitting. The derivation chain remains independent of the target results and does not rely on prior author work for its central claims.
Axiom & Free-Parameter Ledger
free parameters (1)
- tau
axioms (2)
- domain assumption All objectives are differentiable so that gradients exist and can be combined.
- domain assumption A strict primary-versus-secondary hierarchy among objectives is known in advance and remains fixed during optimization.
Reference graph
Works this paper leans on
-
[1]
IEEE Transactions on Emerging Topics in Computational Intelligence , year=
Pmgda: A preference-based multiple gradient descent algorithm , author=. IEEE Transactions on Emerging Topics in Computational Intelligence , year=
-
[2]
Multiple-gradient descent algorithm (MGDA) , author=
-
[3]
Advances in neural information processing systems , volume=
Gradient surgery for multi-task learning , author=. Advances in neural information processing systems , volume=
-
[4]
Advances in neural information processing systems , volume=
Conflict-averse gradient descent for multi-task learning , author=. Advances in neural information processing systems , volume=
-
[5]
Advances in Neural Information Processing Systems , volume=
Famo: Fast adaptive multitask optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
Structural and multidisciplinary optimization , volume=
The weighted sum method for multi-objective optimization: new insights , author=. Structural and multidisciplinary optimization , volume=. 2010 , publisher=
2010
-
[7]
Advances in neural information processing systems , volume=
Do current multi-task optimization methods in deep learning even help? , author=. Advances in neural information processing systems , volume=
-
[8]
Advances in neural information processing systems , volume=
Multi-task learning as multi-objective optimization , author=. Advances in neural information processing systems , volume=
-
[9]
arXiv preprint arXiv:2108.00597 , year=
Exact Pareto optimal search for multi-task learning and multi-criteria decision-making , author=. arXiv preprint arXiv:2108.00597 , year=
-
[10]
International Conference on Machine Learning , pages=
Multi-Task Learning as a Bargaining Game , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[11]
International Conference on Machine Learning , pages=
Auxiliary learning as an asymmetric bargaining game , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[12]
Proximal alternating minimization and projection methods for nonconvex problems: An approach based on the Kurdyka-
Attouch, H. Proximal alternating minimization and projection methods for nonconvex problems: An approach based on the Kurdyka-. Mathematics of operations research , volume=. 2010 , publisher=
2010
-
[13]
Mathematical programming , volume=
Convergence of descent methods for semi-algebraic and tame problems: proximal algorithms, forward--backward splitting, and regularized Gauss--Seidel methods , author=. Mathematical programming , volume=. 2013 , publisher=
2013
-
[14]
Mathematical Programming , volume=
Proximal alternating linearized minimization for nonconvex and nonsmooth problems , author=. Mathematical Programming , volume=. 2014 , publisher=
2014
-
[15]
1998 , publisher=
Variational analysis , author=. 1998 , publisher=
1998
-
[16]
Mathematical methods of operations research , volume=
Steepest descent methods for multicriteria optimization , author=. Mathematical methods of operations research , volume=. 2000 , publisher=
2000
-
[17]
1999 , publisher=
Nonlinear multiobjective optimization , author=. 1999 , publisher=
1999
-
[18]
The Eleventh International Conference On Learning Representations , year=
Mitigating gradient bias in multi-objective learning: A provably convergent approach , author=. The Eleventh International Conference On Learning Representations , year=
-
[19]
ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Variance reduction can improve trade-off in multi-objective learning , author=. ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2024 , organization=
2024
-
[20]
arXiv preprint arXiv:2010.04104 , year=
Learning the pareto front with hypernetworks , author=. arXiv preprint arXiv:2010.04104 , year=
-
[21]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Multi-task learning using uncertainty to weigh losses for scene geometry and semantics , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[22]
International conference on machine learning , pages=
Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[23]
International conference on learning representations , year=
Towards impartial multi-task learning , author=. International conference on learning representations , year=
-
[24]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Independent component alignment for multi-task learning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[25]
arXiv preprint arXiv:2504.01212 , year=
Cooper: A library for constrained optimization in deep learning , author=. arXiv preprint arXiv:2504.01212 , year=
-
[26]
Learning multiple layers of features from tiny images.(2009) , author=
2009
-
[27]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[28]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Densely connected convolutional networks , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[29]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Mobilenets: Efficient convolutional neural networks for mobile vision applications , author=. arXiv preprint arXiv:1704.04861 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Mobilenetv2: Inverted residuals and linear bottlenecks , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[31]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Going deeper with convolutions , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[32]
SIAM journal on optimization , volume=
Normal-boundary intersection: A new method for generating the Pareto surface in nonlinear multicriteria optimization problems , author=. SIAM journal on optimization , volume=. 1998 , publisher=
1998
-
[33]
Empirical Analysis of the Hessian of Over-Parametrized Neural Networks
Empirical analysis of the hessian of over-parametrized neural networks , author=. arXiv preprint arXiv:1706.04454 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
International Conference on Machine Learning , pages=
An investigation into neural net optimization via hessian eigenvalue density , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[35]
Revisiting
Jaggi, Martin , booktitle =. Revisiting. 2013 , editor =
2013
-
[36]
Top , volume=
Farkas’ lemma: three decades of generalizations for mathematical optimization , author=. Top , volume=. 2014 , publisher=
2014
-
[37]
and Tucker, Albert W
Gale, David and Kuhn, Harold W. and Tucker, Albert W. , title =. Activity analysis of production and allocation , pages =
-
[38]
IEEE transactions on pattern analysis and machine intelligence , volume=
Structured pruning for deep convolutional neural networks: A survey , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2023 , publisher=
2023
-
[39]
arXiv preprint arXiv:2508.15008 , year=
Neural Network Quantization for Microcontrollers: A Comprehensive Survey of Methods, Platforms, and Applications , author=. arXiv preprint arXiv:2508.15008 , year=
-
[40]
IEEE transactions on pattern analysis and machine intelligence , volume=
A comprehensive survey of continual learning: Theory, method and application , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2024 , publisher=
2024
-
[41]
Knowledge-Based Systems , volume=
A survey on federated learning , author=. Knowledge-Based Systems , volume=. 2021 , publisher=
2021
-
[42]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Low-rank compression of neural nets: Learning the rank of each layer , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[43]
Adam: A Method for Stochastic Optimization
Adam: A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
2007 15th European signal processing conference , pages=
The effective rank: A measure of effective dimensionality , author=. 2007 15th European signal processing conference , pages=. 2007 , organization=
2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.