Asymptotically Optimal Learning for Parametric Prophet Inequalities
Pith reviewed 2026-06-26 04:50 UTC · model grok-4.3
The pith
Exploiting parametric structure lets an online-only policy reach the optimal asymptotic competitive ratio in prophet inequalities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For i.i.d. rewards from an exponential-type parametric family with unknown theta, the optimal full-information asymptotic competitive ratio equals (theta/(theta-c+))^{c+/theta} / Gamma(1-c+/theta) when support is unbounded and equals 1 when support is bounded. A confidence-based dynamic-programming policy achieves exactly this ratio using only the online sequence of rewards.
What carries the argument
The confidence-based dynamic-programming policy that updates its value function at each step using shrinking confidence intervals on the unknown parameter theta.
If this is right
- The same optimal ratio is attained without any external offline samples.
- Distribution-specific convergence rates can be derived for canonical members such as the exponential and Pareto distributions.
- The result holds for both the unbounded-support and bounded-support members of the family.
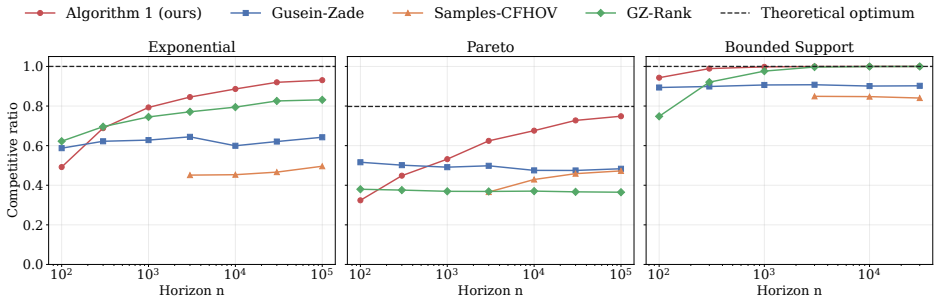
- Numerical experiments on synthetic instances confirm that the policy tracks the theoretical limit.
Where Pith is reading between the lines
- Parametric assumptions can substitute for large pre-collected datasets in certain online selection problems.
- The same confidence-set technique may extend to other online decision settings whose distributions belong to low-dimensional parametric families.
- When support is known to be bounded the limiting ratio of 1 indicates that perfect asymptotic performance becomes possible under the parametric restriction.
Load-bearing premise
Rewards are i.i.d. draws from a known exponential-type parametric family whose parameter value is unknown.
What would settle it
Run the policy on a long sequence of rewards drawn from a distribution outside the assumed parametric family and check whether the realized competitive ratio still approaches the claimed limit.
Figures
read the original abstract
We study learning in prophet inequalities with i.i.d. rewards drawn from an exponential-type parametric family with an unknown parameter $\theta$, a class that includes exponential, Pareto, and bounded-support power-family distributions. We first characterize the optimal full-information asymptotic competitive ratio for this family. In the unbounded-support case, the limit is $ {\left({\theta}/({\theta-c_+})\right)^{c_+/\theta}}/ {\Gamma(1-c_+/\theta)},$ while in the bounded-support case, the limit is $1$. We then propose a confidence-based dynamic-programming policy for online learning. By exploiting the explicit parametric structure, the policy achieves the same optimal asymptotic competitive ratio using only online observations, without external offline samples. We further derive distribution-specific convergence rates for canonical examples. Finally, numerical experiments on synthetic instances illustrate the performance of our algorithm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies prophet inequalities with i.i.d. rewards from an exponential-type parametric family with unknown parameter θ (including exponential, Pareto, and bounded power-family distributions). It first derives closed-form expressions for the optimal full-information asymptotic competitive ratio: (θ/(θ−c₊))^{c₊/θ} / Γ(1−c₊/θ) in the unbounded-support case and 1 in the bounded-support case. It then constructs a confidence-based dynamic-programming policy that learns θ from online observations only and matches this ratio asymptotically, without external offline samples. Distribution-specific convergence rates are derived for canonical examples, and synthetic numerical experiments are reported.
Significance. If the central claims hold, the work is significant for showing that explicit parametric structure can be leveraged to obtain asymptotically optimal competitive ratios in online prophet-inequality settings using only online data. The explicit ratio formulas, the matching online policy, and the distribution-specific rates constitute concrete, falsifiable contributions that advance the intersection of parametric statistics and online mechanism design.
major comments (1)
- The central claim that the online policy achieves the separately characterized optimal asymptotic ratio rests on the independence of the ratio derivation from the policy construction. Without access to the full derivations (e.g., the sections deriving the ratio and proving policy correctness), it is impossible to confirm whether the ratio is truly parameter-free with respect to the learning procedure or whether fitted quantities are shared, creating a potential circularity risk for the main theorem.
Simulated Author's Rebuttal
We thank the referee for their review and for highlighting the need to confirm separation between the ratio derivation and policy analysis. We address the concern directly below.
read point-by-point responses
-
Referee: The central claim that the online policy achieves the separately characterized optimal asymptotic ratio rests on the independence of the ratio derivation from the policy construction. Without access to the full derivations (e.g., the sections deriving the ratio and proving policy correctness), it is impossible to confirm whether the ratio is truly parameter-free with respect to the learning procedure or whether fitted quantities are shared, creating a potential circularity risk for the main theorem.
Authors: The optimal asymptotic competitive ratio is derived in Section 3 under the full-information model with known θ; the derivation uses only the parametric family and the definition of asymptotic competitive ratio and contains no reference to any estimator, online samples, or policy. The online policy and its analysis appear in Sections 4–5. The policy constructs confidence intervals for θ from the online sequence and plugs the resulting estimate into the threshold rule; the proof that the policy attains the same limit proceeds by showing that the estimation error is o(1) with high probability and therefore does not affect the limiting ratio. No fitted quantity enters the closed-form expression for the ratio, which remains a function solely of θ and c₊. The two parts of the argument are therefore logically independent. We will add a short clarifying sentence at the end of Section 3 and the beginning of Section 5 to make this separation explicit. revision: partial
Circularity Check
No significant circularity identified
full rationale
The paper separates the derivation into two independent steps: first characterizing the optimal full-information asymptotic competitive ratio (with closed-form expressions for unbounded and bounded cases), then constructing a confidence-based DP policy that learns θ online and asymptotically matches that ratio. The abstract and claims show no reduction of the ratio to policy outputs, no fitted parameters renamed as predictions, and no load-bearing self-citations. The parametric family is an explicit modeling assumption stated upfront, enabling the online result without creating definitional or constructional circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Rewards are i.i.d. from an exponential-type parametric family with unknown parameter theta
Reference graph
Works this paper leans on
-
[1]
ACM Transactions on Economics and Computation , volume=
Prophet inequalities with linear correlations and augmentations , author=. ACM Transactions on Economics and Computation , volume=. 2023 , publisher=
2023
-
[2]
arXiv preprint arXiv:2007.06110 , year=
Unknown IID prophets: Better bounds, streaming algorithms, and a new impossibility , author=. arXiv preprint arXiv:2007.06110 , year=
arXiv 2007
-
[3]
Mathematics of Operations Research , volume=
Optimal stopping of a random sequence with unknown distribution , author=. Mathematics of Operations Research , volume=. 2022 , publisher=
2022
-
[4]
Proceedings of the 2024 Annual ACM-SIAM Symposium on Discrete Algorithms (SODA) , pages=
Bandit algorithms for prophet inequality and pandora's box , author=. Proceedings of the 2024 Annual ACM-SIAM Symposium on Discrete Algorithms (SODA) , pages=. 2024 , organization=
2024
-
[5]
ACM SIGecom Exchanges , volume=
Recent developments in prophet inequalities , author=. ACM SIGecom Exchanges , volume=. 2019 , publisher=
2019
-
[6]
arXiv preprint arXiv:2205.05519 , year=
Prophet inequality on IID distributions: beating 1-1/e with a single query , author=. arXiv preprint arXiv:2205.05519 , year=
-
[7]
Proceedings of the 53rd Annual ACM SIGACT Symposium on Theory of Computing , pages=
Linear bandits with limited adaptivity and learning distributional optimal design , author=. Proceedings of the 53rd Annual ACM SIGACT Symposium on Theory of Computing , pages=
-
[8]
Advances in neural information processing systems , volume=
Improved algorithms for linear stochastic bandits , author=. Advances in neural information processing systems , volume=
-
[9]
Foundations of computational mathematics , volume=
User-friendly tail bounds for sums of random matrices , author=. Foundations of computational mathematics , volume=. 2012 , publisher=
2012
-
[10]
Semiamarts and finite values , author=
-
[11]
Probability on Banach spaces , volume=
On semiamarts, amarts, and processes with finite value , author=. Probability on Banach spaces , volume=. 1978 , publisher=
1978
-
[12]
The Annals of Probability , pages=
Comparisons of stop rule and supremum expectations of iid random variables , author=. The Annals of Probability , pages=. 1982 , publisher=
1982
-
[13]
Proceedings of the 49th Annual ACM SIGACT Symposium on Theory of Computing , pages=
Beating 1-1/e for ordered prophets , author=. Proceedings of the 49th Annual ACM SIGACT Symposium on Theory of Computing , pages=
-
[14]
The Annals of Probability , pages=
Comparison of threshold stop rules and maximum for independent nonnegative random variables , author=. The Annals of Probability , pages=. 1984 , publisher=
1984
-
[15]
Proceedings of the forty-second ACM symposium on Theory of computing , pages=
Multi-parameter mechanism design and sequential posted pricing , author=. Proceedings of the forty-second ACM symposium on Theory of computing , pages=
-
[16]
Proceedings of the 2017 ACM Conference on Economics and Computation , pages=
Posted price mechanisms for a random stream of customers , author=. Proceedings of the 2017 ACM Conference on Economics and Computation , pages=
2017
-
[17]
Proceedings of the 2019 ACM Conference on Economics and Computation , pages=
Prophet inequalities for iid random variables from an unknown distribution , author=. Proceedings of the 2019 ACM Conference on Economics and Computation , pages=
2019
-
[18]
Contemporary Mathematics , volume=
A survey of prophet inequalities in optimal stopping theory , author=. Contemporary Mathematics , volume=
-
[19]
ACM SIGecom Exchanges , volume=
An economic view of prophet inequalities , author=. ACM SIGecom Exchanges , volume=. 2017 , publisher=
2017
-
[20]
Proceedings of the 13th ACM Conference on Electronic Commerce , pages=
Online prophet-inequality matching with applications to ad allocation , author=. Proceedings of the 13th ACM Conference on Electronic Commerce , pages=
-
[21]
arXiv preprint arXiv:2205.10302 , year=
Individual fairness in prophet inequalities , author=. arXiv preprint arXiv:2205.10302 , year=
-
[22]
Advances in Neural Information Processing Systems , volume=
Lookback prophet inequalities , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
arXiv preprint arXiv:2011.14929 , year=
Windowed Prophet Inequalities , author=. arXiv preprint arXiv:2011.14929 , year=
arXiv 2011
-
[24]
Theory of Probability & Its Applications , volume=
The problem of choice and the optimal stopping rule for a sequence of independent trials , author=. Theory of Probability & Its Applications , volume=. 1966 , publisher=
1966
-
[25]
The Annals of Statistics , volume=
A statistical version of prophet inequalities , author=. The Annals of Statistics , volume=. 1998 , publisher=
1998
-
[26]
arXiv preprint arXiv:2505.18828 , year=
Improved Regret and Contextual Linear Extension for Pandora's Box and Prophet Inequality , author=. arXiv preprint arXiv:2505.18828 , year=
-
[27]
Foundations and Trends
An introduction to matrix concentration inequalities , author=. Foundations and Trends. 2015 , publisher=
2015
-
[28]
Innovations in Theoretical Computer Science , year=
Optimal Single-Choice Prophet Inequalities from Samples , author=. Innovations in Theoretical Computer Science , year=
-
[29]
Proceedings of the Fourteenth Annual ACM-SIAM Symposium on Discrete Algorithms , pages=
The two-sided game of googol and sample-based prophet inequalities , author=. Proceedings of the Fourteenth Annual ACM-SIAM Symposium on Discrete Algorithms , pages=. 2020 , organization=
2020
-
[30]
Mathematics of Operations Research , volume=
Sample-driven optimal stopping: From the secretary problem to the iid prophet inequality , author=. Mathematics of Operations Research , volume=. 2024 , publisher=
2024
-
[31]
Proceedings of the Fourteenth Annual ACM-SIAM Symposium on Discrete Algorithms , pages=
Competitive analysis with a sample and the secretary problem , author=. Proceedings of the Fourteenth Annual ACM-SIAM Symposium on Discrete Algorithms , pages=. 2020 , organization=
2020
-
[32]
Proceedings of the 56th Annual ACM Symposium on Theory of Computing , pages=
Prophet inequalities require only a constant number of samples , author=. Proceedings of the 56th Annual ACM Symposium on Theory of Computing , pages=
-
[33]
International Conference on Machine Learning , pages=
On kernelized multi-armed bandits , author=. International Conference on Machine Learning , pages=. 2017 , organization=
2017
-
[34]
Advances in Neural Information Processing Systems , volume=
On the sublinear regret of GP-UCB , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
arXiv preprint arXiv:0912.3995 , year=
Gaussian process optimization in the bandit setting: No regret and experimental design , author=. arXiv preprint arXiv:0912.3995 , year=
-
[36]
Advances in neural information processing systems , volume=
Pure exploration in kernel and neural bandits , author=. Advances in neural information processing systems , volume=
-
[37]
The Annals of Mathematical Statistics , pages=
Asymptotic minimax character of the sample distribution function and of the classical multinomial estimator , author=. The Annals of Mathematical Statistics , pages=. 1956 , publisher=
1956
-
[38]
The Annals of Probability , pages=
The tight constant in the Dvoretzky-Kiefer-Wolfowitz inequality , author=. The Annals of Probability , pages=. 1990 , publisher=
1990
-
[39]
The Annals of Probability , volume=
Approximations to optimal stopping rules for exponential random variables , author=. The Annals of Probability , volume=. 1984 , publisher=
1984
-
[40]
1999 , publisher=
Regular variation, subexponentiality and their applications in probability theory , author=. 1999 , publisher=
1999
-
[41]
2026 , booktitle=
Learning in Prophet Inequalities with Noisy Observations , author=. 2026 , booktitle=
2026
-
[42]
Proceedings of the 26th ACM Conference on Economics and Computation , pages=
Minimization iid prophet inequality via extreme value theory: A unified approach , author=. Proceedings of the 26th ACM Conference on Economics and Computation , pages=
-
[43]
The Annals of Probability , volume=
The asymptotic behavior of the reward sequence in the optimal stopping of iid random variables , author=. The Annals of Probability , volume=. 1991 , publisher=
1991
-
[44]
Statistical science , volume=
Who solved the secretary problem? , author=. Statistical science , volume=. 1989 , publisher=
1989
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.