Testing Agentic Workflows with Structural Coverage Criteria
Pith reviewed 2026-06-29 16:14 UTC · model grok-4.3
The pith
A typed coordination graph turns multi-agent workflow specifications into structural coverage obligations that tests must exercise.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The approach extracts a typed coordination graph from a workflow specification, derives coverage obligations over reachable agents, allowed tool edges, restricted tool edges, and delegation edges, and produces executable tests whose witnesses demonstrate that those obligations have been met at runtime. Evaluation on ten benchmarks shows that generated scenarios can witness substantial fractions of the allowed-tool and delegation obligations and can elicit restricted-call violations that separate workflows whose restrictions hold from those with concrete misrouting.
What carries the argument
The typed coordination graph, which encodes the declared agents, tool-access rules, restrictions, and delegation paths as nodes and edges and supplies the coverage obligations that generated tests must satisfy.
If this is right
- Test suites acquire an independent structural adequacy measure that can be checked without reference to task success.
- Restricted-tool obligations can surface concrete misrouting failures that end-to-end evaluation may miss.
- Gaps in delegation coverage become detectable before deployment.
- Workflows can be compared by how many of their declared structural obligations their test suites actually meet.
Where Pith is reading between the lines
- The same graph could be used to prioritize which parts of a workflow need additional semantic tests once structural coverage is reached.
- Coverage gaps identified early could guide refinement of the workflow specification itself rather than only its tests.
- The approach might apply to any workflow system that exposes explicit agent, tool, and delegation declarations.
Load-bearing premise
The coordination graph extracted from the specification accurately and completely represents the runtime coordination behavior of the workflow.
What would settle it
A workflow whose generated test suite achieves full graph coverage yet runtime traces show tool calls or delegations that violate the graph's declared edges or leave declared edges unexercised.
Figures
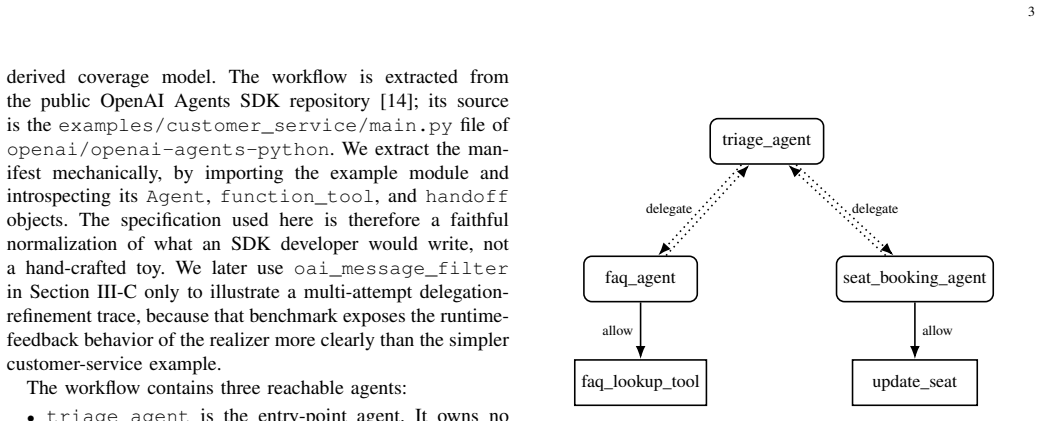

read the original abstract
Multi-agent systems increasingly expose explicit workflow structure: agents, tools, tool-access rules, restrictions, and delegation paths. Existing evaluations rely largely on end-to-end task success, benchmark scores, final-response quality, or prompt-level checks, which provide limited evidence that this declared coordination structure has actually been exercised. This makes it difficult to assess test-suite adequacy or detect structural regressions in tool access, restrictions, and inter-agent delegation. We address this gap with a structural testing approach for multi-agent workflow specifications. The approach represents each workflow as a typed coordination graph, derives coverage obligations over reachable agents, allowed tool edges, restricted tool edges, and delegation edges, and uses coverage-driven generation with DSPy-based scenario realization to produce executable tests. The graph fixes what must be covered; DSPy realizes those obligations as natural-language scenarios whose witnesses are checked at runtime. We implement the approach for OpenAI Agents SDK-style workflows and evaluate it on ten SDK-derived benchmarks comprising 49 reachable agents, 47 tools, and 403 structural obligations. Generated scenarios witness 54/75 allowed-tool obligations and 36/48 delegation obligations within a bounded refinement budget. The adversarial restricted-tool criterion elicits 23/248 restricted-call violations, separating workflows whose restrictions hold under probing from workflows with concrete misrouting failures. These results show that structural coverage provides a useful adequacy layer for multi-agent workflow testing: it does not replace semantic or end-to-end evaluation, but reveals whether declared agents, tool-access rules, restrictions, and delegation paths have been exercised.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a structural testing approach for multi-agent workflows. Workflows are modeled as typed coordination graphs from which coverage obligations are derived for reachable agents, allowed/restricted tool edges, and delegation edges. DSPy-based generation produces executable scenarios to satisfy these obligations, and the method is evaluated on ten OpenAI Agents SDK-derived benchmarks (49 agents, 47 tools, 403 obligations), reporting 54/75 allowed-tool coverage, 36/48 delegation coverage, and 23/248 restricted violations detected.
Significance. If the graph-to-runtime mapping holds, the work supplies a useful complementary adequacy criterion for agentic systems that focuses on exercise of declared coordination structure rather than only end-to-end task success. The separation of obligation derivation from scenario realization and the concrete numerical results on restriction probing are positive features.
major comments (2)
- [Abstract / Evaluation] Abstract and Evaluation section: the reported figures (54/75 allowed-tool, 36/48 delegation, 23/248 restricted) are given without any description of how obligations were enumerated from the graphs, how runtime witnesses were validated, or the procedure used to select the ten benchmarks independently of the proposed method. These details are load-bearing for interpreting the empirical support for the adequacy claim.
- [Approach / Evaluation] Approach and Evaluation sections: the central claim that satisfying graph-derived obligations exercises the actual coordination structure rests on the unvalidated assumption that the extracted typed coordination graph faithfully and completely represents runtime behavior; no dynamic trace comparison or counter-example analysis is supplied to support or bound this mapping.
minor comments (1)
- Define 'reachable agents' and the precise counting of structural obligations more explicitly (e.g., in a dedicated subsection or table) to support independent reproduction.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments highlight areas where additional clarity would strengthen the presentation of the empirical results and the scope of the central claim. We address each major comment below, indicating planned revisions.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: the reported figures (54/75 allowed-tool, 36/48 delegation, 23/248 restricted) are given without any description of how obligations were enumerated from the graphs, how runtime witnesses were validated, or the procedure used to select the ten benchmarks independently of the proposed method. These details are load-bearing for interpreting the empirical support for the adequacy claim.
Authors: We agree that the abstract and Evaluation section would benefit from explicit descriptions of these procedures. In the revised manuscript we will add a dedicated subsection in Evaluation that (1) details obligation enumeration by graph traversal over reachable agents, allowed/restricted tool edges, and delegation edges; (2) describes the runtime witness validation process, which inspects SDK execution logs for the presence of the required edges and agents; and (3) states that the ten benchmarks were drawn from publicly available OpenAI Agents SDK examples chosen for diversity in agent count and tool usage, without reference to the coverage criteria. These additions will make the reported coverage numbers interpretable. revision: yes
-
Referee: [Approach / Evaluation] Approach and Evaluation sections: the central claim that satisfying graph-derived obligations exercises the actual coordination structure rests on the unvalidated assumption that the extracted typed coordination graph faithfully and completely represents runtime behavior; no dynamic trace comparison or counter-example analysis is supplied to support or bound this mapping.
Authors: The coordination graph is extracted directly from the workflow specification (agent declarations, tool-access rules, and delegation paths). The adequacy claim concerns whether the declared structure is exercised, not whether the graph captures every possible runtime behavior. We acknowledge that the manuscript provides no dynamic trace comparison or counter-example analysis to bound the fidelity of the extraction. In revision we will add an explicit limitations paragraph in the Approach section clarifying the scope of the claim and noting that full runtime validation of the graph-to-execution mapping remains future work. revision: partial
Circularity Check
No significant circularity identified
full rationale
The paper derives coverage obligations directly from the typed coordination graph representation of the workflow specification, with no equations, fitted parameters, predictions that reduce to inputs by construction, or load-bearing self-citations. The central claims rest on the graph extraction and DSPy-based realization steps, which are defined independently without renaming known results or importing uniqueness theorems from prior author work. The evaluation numbers (e.g., 54/75) are presented as empirical outcomes under the stated assumptions rather than forced by definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cambridge University Press, 2nd edition, 2016
Paul Ammann and Jeff Offutt.Introduction to Software Testing. Cambridge University Press, 2nd edition, 2016
2016
-
[2]
Dspy documentation
DSPy Contributors. Dspy documentation. https://dspy.ai/, 2026. Ac- cessed: 2026-05-02
2026
-
[3]
Dspy documentation: Modules
DSPy Contributors. Dspy documentation: Modules. https://dspy.ai/learn/ programming/modules/, 2026. Accessed: 2026-05-02
2026
-
[4]
Dspy documentation: Signatures
DSPy Contributors. Dspy documentation: Signatures. https://dspy.ai/ learn/programming/signatures/, 2026. Accessed: 2026-05-02
2026
-
[5]
Evosuite: Automatic test suite generation for object-oriented software
Gordon Fraser and Andrea Arcuri. Evosuite: Automatic test suite generation for object-oriented software. InProceedings of the 19th ACM SIGSOFT Symposium and the 13th European Conference on Foundations of Software Engineering, pages 416–419, 2011
2011
-
[6]
An analysis and survey of the development of mutation testing.IEEE Transactions on Software Engineering, 37(5):649–678, 2011
Yue Jia and Mark Harman. An analysis and survey of the development of mutation testing.IEEE Transactions on Software Engineering, 37(5):649–678, 2011
2011
-
[7]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world github issues? InInternational Conference on Learning Representations, 2024. 14
2024
-
[8]
Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts. Dspy: Compiling declarative language model calls into self-improving pipelines. InInternational Conference on Learning Representations, 2024
2024
-
[9]
API-Bank: A Comprehensive Benchmark for Tool-Augmented LLMs
Ming Li et al. API-Bank: A comprehensive benchmark for tool- augmented LLMs.arXiv preprint arXiv:2304.08244, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Holistic evaluation of language models
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yao Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, et al. Holistic evaluation of language models. Transactions on Machine Learning Research, 2023
2023
-
[11]
AgentBench: Evaluating LLMs as Agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, et al. Agentbench: Evaluating LLMs as agents.arXiv preprint arXiv:2308.03688, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
GAIA: a benchmark for General AI Assistants
Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. GAIA: A benchmark for general AI assistants.arXiv preprint arXiv:2311.12983, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Myers, Corey Sandler, and Tom Badgett.The Art of Software Testing
Glenford J. Myers, Corey Sandler, and Tom Badgett.The Art of Software Testing. John Wiley & Sons, 3rd edition, 2011
2011
-
[14]
Agents sdk
OpenAI. Agents sdk. https://developers.openai.com/api/docs/guides/ agents, 2026. Accessed: 2026-05-02
2026
-
[15]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Yujia Qin, Ruyi Luo, Pan Ye, et al. ToolLLM: Facilitating large language models to master 16000+ real-world APIs.arXiv preprint arXiv:2307.16789, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Beyond accuracy: Behavioral testing of NLP models with CheckList
Marco Tulio Ribeiro, Tongshuang Wu, Carlos Guestrin, and Sameer Singh. Beyond accuracy: Behavioral testing of NLP models with CheckList. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4902–4912, 2020
2020
-
[17]
Morgan Kaufmann, 2006
Mark Utting and Bruno Legeard.Practical Model-Based Testing: A Tools Approach. Morgan Kaufmann, 2006
2006
-
[18]
Textflint: Unified multilingual robustness evaluation toolkit for natural language processing
Xiao Wang, Qin Liu, Tao Gui, Qi Zhang, Xuanjing Huang, et al. Textflint: Unified multilingual robustness evaluation toolkit for natural language processing. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstra- tions, pages 347...
2021
-
[19]
White, Doug Burger, and Chi Wang
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Has- san Awadallah, Ryen W. White, Doug Burger, and Chi Wang. Autogen: Enabling next-gen llm applications via multi-agent conversations. In First Conference on Language Modeling (COLM), 2024
2024
-
[20]
The Rise and Potential of Large Language Model Based Agents: A Survey
Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, Rui Zheng, Xiaoran Fan, Xiao Wang, Limao Xiong, Yuhao Zhou, Weiran Wang, Changhao Jiang, Yicheng Zou, Xiangyang Liu, Zhangyue Yin, Shi- han Dou, Rongxiang Weng, Wensen Cheng, Qi Zhang, Wenjuan Qin, Yongyan Zheng, Xipeng Qiu, Xuanjing Huang,...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations (ICLR), 2023
2023
-
[22]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. WebArena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.