A Reproducible Universal Dependencies-Style Pipeline for Katharevousa Greek Parliamentary Text
Pith reviewed 2026-06-30 16:35 UTC · model grok-4.3
The pith
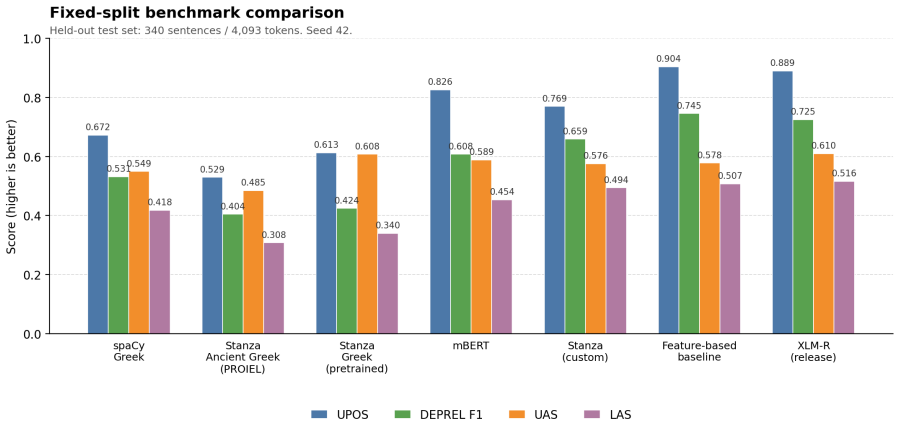
A reproducible pipeline builds a 1,697-sentence UD-style treebank for Katharevousa Greek parliamentary text on which an XLM-R model reaches 0.5162 LAS.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors construct a frozen reference set of 1,697 sentences from early post-junta Greek parliamentary questions, split into 1,357 training and 340 test sentences, using a pipeline of OCR reconstruction, schema-constrained LLM-assisted annotation, automatic validation, and deterministic CoNLL-U output. Under a uniform scoring protocol, off-the-shelf systems suffer register mismatch, with the strongest baseline (spaCy Greek) at 0.4183 LAS. The best model, an XLM-R parser, reaches 0.8893 UPOS accuracy, 0.7250 dependency-relation F1, 0.6098 UAS, and 0.5162 LAS—an absolute gain of 0.0980 over the baseline—while a feature-based parser remains competitive on UPOS and relation labeling. The full
What carries the argument
Schema-constrained LLM-assisted annotation followed by human review, automatic validation, and a fixed 1,357/340 train-test split on the 1,697-sentence treebank.
If this is right
- The released treebank becomes a benchmark for future Katharevousa Greek parsers under the same fixed split.
- Feature-based models can remain competitive with transformer models when training data is limited to a few thousand sentences.
- The OCR-to-CoNLL-U workflow can be rerun on additional parliamentary volumes to expand the resource without changing the evaluation protocol.
- Off-the-shelf modern Greek and Ancient Greek parsers are shown to be mismatched to this register, justifying domain-specific resources.
Where Pith is reading between the lines
- The same annotation workflow could be tested on other low-resource historical registers where OCR quality is the main bottleneck.
- Higher parsing accuracy on parliamentary questions might enable downstream tasks such as automated retrieval of legal arguments across decades of archives.
- The gap between custom and baseline models suggests that similar register-specific treebanks would be needed for other historical language varieties before large language models can be reliably applied.
Load-bearing premise
Human-reviewed LLM annotations produce syntactic labels accurate and consistent enough to serve as a reliable gold standard for parser evaluation.
What would settle it
Independent re-annotation of the 340-sentence test set by multiple linguists yielding low agreement on dependency arcs or labels would show the treebank is not a stable gold standard.
Figures

read the original abstract
Katharevousa Greek remains poorly served by contemporary NLP pipelines despite its importance for legal, administrative, and parliamentary archives. We present a reproducible workflow for building and evaluating a Universal Dependencies-style parsing resource for Katharevousa parliamentary questions from Greece's early post-junta period. The pipeline links OCR-aware reconstruction, schema-constrained LLM-assisted annotation, automatic validation, deterministic CoNLL-U snapshotting, fixed-split evaluation, and model-family comparison. The frozen automatically validated reference set contains 1{,}697 sentences, split into 1{,}357 training sentences and 340 held-out test sentences. We compare off-the-shelf Greek and Ancient Greek parsers, a feature-based parser, mBERT, XLM-R, and custom Stanza training under the same scoring protocol. Off-the-shelf systems show substantial register mismatch: the strongest external baseline, spaCy Greek, reaches 0.4183 LAS. The best structural parser, an XLM-R model, reaches 0.8893 UPOS accuracy, 0.7250 dependency-relation F1, 0.6098 UAS, and 0.5162 LAS, an absolute LAS gain of 0.0980 over the best external baseline. The feature-based model remains competitive for UPOS and relation labeling, indicating that transparent lexical-context features still matter at this data scale. Beyond scores, the paper contributes an auditable methodology for turning difficult historical parliamentary OCR into reusable syntactic NLP infrastructure. The entire pipeline -- code, schema, frozen reference annotations, fixed train/test split, and per-model benchmark reports -- is released as an open-access companion to this paper.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a reproducible pipeline for creating a UD-style treebank for Katharevousa Greek parliamentary texts, combining OCR-aware reconstruction, schema-constrained LLM-assisted annotation with human review, automatic validation, and deterministic CoNLL-U output. It releases a frozen 1,697-sentence reference set (1,357 train / 340 test) and benchmarks off-the-shelf parsers, mBERT, XLM-R, and custom Stanza models under a fixed protocol. The best result is an XLM-R model with 0.8893 UPOS, 0.7250 relation F1, 0.6098 UAS, and 0.5162 LAS (0.0980 absolute gain over spaCy Greek at 0.4183 LAS). All code, schema, annotations, and splits are released.
Significance. If the annotations are shown to be reliable, the work supplies a valuable open resource for an underserved historical Greek register with direct relevance to legal and parliamentary archives. The emphasis on full pipeline release, fixed splits, and multi-model comparison under identical conditions is a clear strength that supports reproducibility and follow-on research. The finding that feature-based models remain competitive at this scale also offers a useful data point for low-resource historical parsing.
major comments (1)
- [Annotation pipeline and human review description] The description of the annotation pipeline (schema-constrained LLM assistance + human review + automatic validation) supplies no quantitative reliability metrics: no inter-annotator agreement on dependencies, no fraction or types of LLM proposals altered by reviewers, and no error analysis of the final CoNLL-U. Because the headline LAS of 0.5162 and the 0.0980 gain over spaCy are measured against the 340-sentence held-out set treated as gold, the absence of these statistics makes it impossible to distinguish parser improvement from annotation artifacts.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on annotation reliability. We address the single major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Annotation pipeline and human review description] The description of the annotation pipeline (schema-constrained LLM assistance + human review + automatic validation) supplies no quantitative reliability metrics: no inter-annotator agreement on dependencies, no fraction or types of LLM proposals altered by reviewers, and no error analysis of the final CoNLL-U. Because the headline LAS of 0.5162 and the 0.0980 gain over spaCy are measured against the 340-sentence held-out set treated as gold, the absence of these statistics makes it impossible to distinguish parser improvement from annotation artifacts.
Authors: We agree this is a substantive gap. The revised manuscript will add: (1) the fraction and main categories of LLM proposals changed during human review, (2) a manual error analysis on a 50-sentence sample of the final CoNLL-U, and (3) further detail on the automatic validation rules applied. Inter-annotator agreement on dependencies cannot be reported because the treebank was produced by a single expert annotator; a second independent pass was not performed. We will release the raw LLM proposals alongside the final annotations to support future reliability studies. revision: yes
Circularity Check
Empirical resource creation and held-out benchmarking with no self-referential derivations
full rationale
The manuscript presents a pipeline for OCR reconstruction, schema-constrained LLM annotation with human review, automatic validation, and fixed-split evaluation of parsers on a 340-sentence test set. Reported LAS scores (0.5162 for XLM-R vs. 0.4183 for spaCy Greek) are measured directly against external off-the-shelf baselines on held-out data. No equations, predictions, or central claims reduce by construction to fitted parameters, self-citations, or renamed inputs. The work is self-contained as an empirical contribution; annotation reliability is asserted via the described process but does not create a circular derivation loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Universal Dependencies annotation guidelines can be applied to Katharevousa Greek with only schema-constrained LLM assistance and human review.
Reference graph
Works this paper leans on
-
[1]
Unsupervised cross-lingual representation learning at scale
Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. Unsupervised cross-lingual representation learning at scale. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 8440–8451. Association for Co...
2020
-
[2]
BERT: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4171–4186. Association for Computational Linguistics, 2019
2019
-
[3]
A neural network model for low- resource universal dependency parsing
Long Duong, Trevor Cohn, Steven Bird, and Paul Cook. A neural network model for low- resource universal dependency parsing. InProceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 339–348. Association for Computational Linguistics, 2015
2015
-
[4]
Digitization of written parliamentary questions from the historical archive (1974–1977) of the hellenic parliament
Fotios Fitsilis, Basilis Gatos, Konstantinos Palaiologos, Panagiotis Kaddas, Charalambis Kyrkos, Maria-Eleni Georgoulea, Yiannis Armenakis, Christina Tasouli, George Mikros, Olivier Rozenberg, and Eleni Kiousi. Digitization of written parliamentary questions from the historical archive (1974–1977) of the hellenic parliament. In H. Mouchère and A. Zhu, edi...
1974
-
[5]
75 languages, 1 model: Parsing universal dependencies universally
Dan Kondratyuk and Milan Straka. 75 languages, 1 model: Parsing universal dependencies universally. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, pages 2779–2795. Association for Computational Linguistics, 2019
2019
-
[6]
Oxford University Press, 2009
Peter Mackridge.Language and National Identity in Greece, 1766–1976. Oxford University Press, 2009
1976
-
[7]
Semi-supervised contextual historical text normal- ization
Peter Makarov and Simon Clematide. Semi-supervised contextual historical text normal- ization. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7284–7295. Association for Computational Linguistics, 2020
2020
-
[8]
Computational stylistics of post-junta greek parliamentary questions: Katharevousa, party style, and democratic reconstruction (1976–1977), 2025
George Mikros and Fotios Fitsilis. Computational stylistics of post-junta greek parliamentary questions: Katharevousa, party style, and democratic reconstruction (1976–1977), 2025. Manuscript submitted to Digital Scholarship in the Humanities. 10
1976
-
[9]
Manning, Sampo Pyysalo, Sebastian Schuster, Francis Tyers, and Daniel Zeman
Joakim Nivre, Marie-Catherine de Marneffe, Filip Ginter, Jan Hajič, Christopher D. Manning, Sampo Pyysalo, Sebastian Schuster, Francis Tyers, and Daniel Zeman. Universal depen- dencies v2: An evergrowing multilingual treebank collection. InProceedings of the Twelfth Language Resources and Evaluation Conference, pages 4034–4043. European Language Resources...
2020
-
[10]
Peng Qi, Yuhao Zhang, Yuhui Zhang, Jason Bolton, and Christopher D. Manning. Stanza: A python natural language processing toolkit for many human languages. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pages 101–108. Association for Computational Linguistics, 2020
2020
-
[11]
Low-resource post processing of noisy OCR output for historical corpus digitisation
Caitlin Richter, Matthew Wickes, Deniz Beser, and Mitch Marcus. Low-resource post processing of noisy OCR output for historical corpus digitisation. InProceedings of the Eleventh International Conference on Language Resources and Evaluation. European Lan- guage Resources Association, 2018
2018
-
[12]
CoNLL-U format.https://universaldependencies.org/format
Universal Dependencies. CoNLL-U format.https://universaldependencies.org/format. html, 2026. Accessed 2026-05-05
2026
-
[13]
Multilingual universal dependency parsing from raw text with low-resource language enhancement
Yingting Wu, Hai Zhao, and Jia-Jun Tong. Multilingual universal dependency parsing from raw text with low-resource language enhancement. InProceedings of the CoNLL 2018 Shared Task: Multilingual Parsing from Raw Text to Universal Dependencies, pages 74–80. Association for Computational Linguistics, 2018. 11
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.