DASM: Domain-Aware Sharpness Minimization for Multi-Domain Voice Stream Steganalysis
Pith reviewed 2026-05-22 09:21 UTC · model grok-4.3
The pith
The DASM optimizer seeks flat minima while maintaining domain separation to improve generalization in multi-domain voice stream steganalysis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
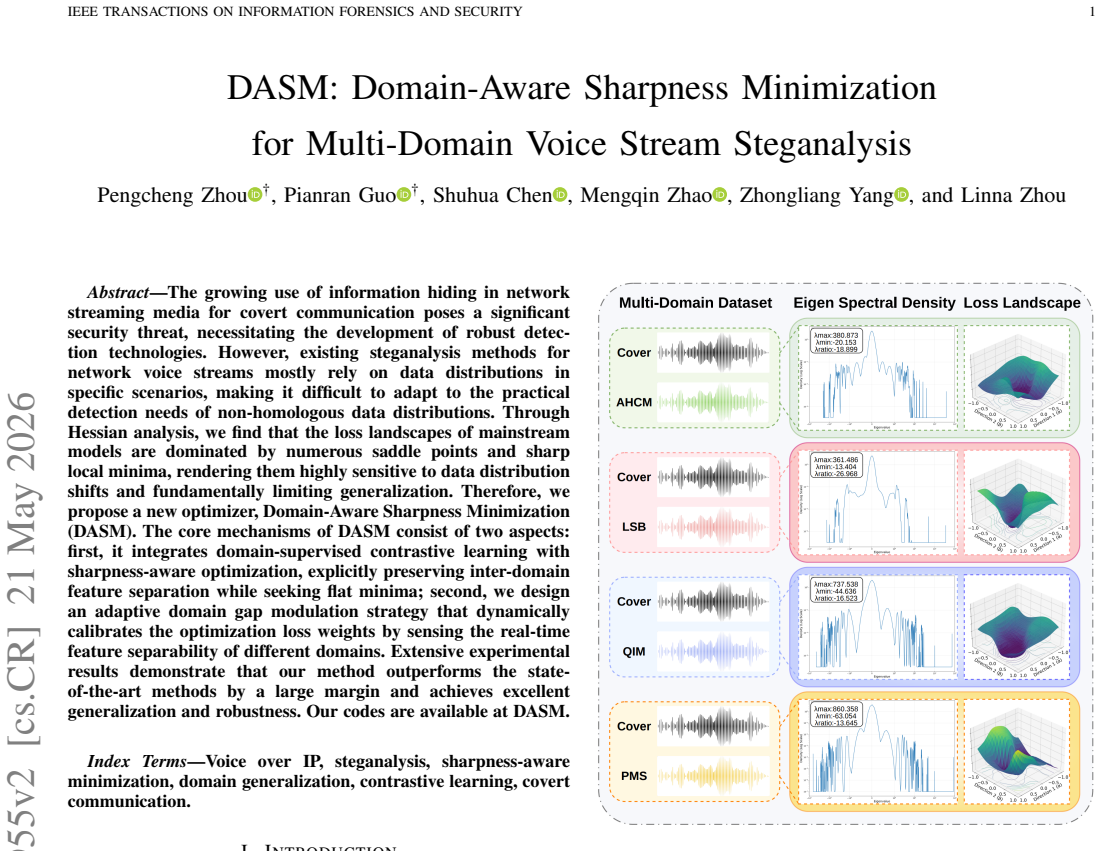
Through Hessian analysis, the loss landscapes of mainstream models are dominated by numerous saddle points and sharp local minima, rendering them highly sensitive to data distribution shifts and fundamentally limiting generalization. The proposed Domain-Aware Sharpness Minimization (DASM) integrates domain-supervised contrastive learning with sharpness-aware optimization to preserve inter-domain feature separation while seeking flat minima, and employs an adaptive domain gap modulation strategy that dynamically calibrates the optimization loss weights by sensing the real-time feature separability of different domains.
What carries the argument
Domain-Aware Sharpness Minimization (DASM), which combines domain-supervised contrastive learning for feature separation with sharpness-aware optimization and adaptive domain gap modulation to dynamically weight losses based on separability.
If this is right
- Models trained with DASM should detect steganographic content more accurately across varied network voice stream distributions.
- The approach reduces reliance on domain-specific training data for effective steganalysis.
- Flatter minima achieved through the combined contrastive and modulation techniques lead to improved robustness against distribution shifts.
- Real-time sensing of feature separability allows the optimizer to adapt weights during training for better performance.
Where Pith is reading between the lines
- Similar sharpness-aware methods with domain awareness could apply to other multi-domain detection tasks like image steganalysis or network anomaly detection.
- If the adaptive modulation proves key, it might be tested independently on other sharpness minimization optimizers.
- Extending this to real-time streaming detection could involve online updates to the domain gap modulation.
Load-bearing premise
The saddle points and sharp local minima found by Hessian analysis are the primary reason for poor generalization across domains in steganalysis models.
What would settle it
Training a standard model and a DASM model on one set of voice stream domains and testing both on a significantly different unseen domain distribution; if the performance gap is not large or consistent, the claim weakens.
Figures










read the original abstract
The growing use of information hiding in network streaming media for covert communication poses a significant security threat, necessitating the development of robust detection technologies. However, existing steganalysis methods for network voice streams mostly rely on data distributions in specific scenarios, making it difficult to adapt to the practical detection needs of non-homologous data distributions. Through Hessian analysis, we find that the loss landscapes of mainstream models are dominated by numerous saddle points and sharp local minima, rendering them highly sensitive to data distribution shifts and fundamentally limiting generalization. Therefore, we propose a new optimizer, Domain-Aware Sharpness Minimization (DASM). The core mechanisms of DASM consist of two aspects: first, it integrates domain-supervised contrastive learning with sharpness-aware optimization, explicitly preserving inter-domain feature separation while seeking flat minima; second, we design an adaptive domain gap modulation strategy that dynamically calibrates the optimization loss weights by sensing the real-time feature separability of different domains. Extensive experimental results demonstrate that our method outperforms the state-of-the-art methods by a large margin and achieves excellent generalization and robustness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that Hessian analysis of mainstream steganalysis models reveals loss landscapes dominated by saddle points and sharp local minima, which cause sensitivity to domain shifts and limit generalization in multi-domain voice stream steganalysis. It proposes Domain-Aware Sharpness Minimization (DASM), an optimizer that combines domain-supervised contrastive learning with sharpness-aware optimization to maintain inter-domain feature separation while seeking flat minima, plus an adaptive domain gap modulation strategy that dynamically adjusts loss weights based on real-time feature separability. Extensive experiments are reported to show large-margin outperformance over state-of-the-art methods along with strong generalization and robustness.
Significance. If the causal link between the identified loss-landscape geometry and cross-domain failure holds and the experimental gains are reproducible, the work could meaningfully advance practical steganalysis for network voice streams by offering a domain-aware optimizer that improves robustness to distribution shifts. The explicit coupling of contrastive separation with sharpness minimization is a targeted response to the stated problem and, if validated through ablations, could influence optimizer design in other security-related detection tasks.
major comments (2)
- [Hessian analysis section] The Hessian analysis (early sections describing the loss-landscape study) shows saddle points and sharp minima but does not establish that these geometric features are the primary cause of poor cross-domain generalization rather than domain-specific feature learning. The spectra are local and batch-dependent; without controls that isolate the contribution of the contrastive term versus the sharpness-minimization term, the claim that DASM's flat-minima component is load-bearing remains unverified.
- [Experimental evaluation section] The experimental claims of large-margin outperformance and excellent generalization rest on unspecified datasets, metrics, baselines, number of domains, statistical tests, and implementation details. Because the central generalization and robustness assertions depend on these results, the absence of this information prevents assessment of whether the data actually support the claims.
minor comments (2)
- [Method description] Clarify the precise formulation of the adaptive modulation weights and how they are computed from feature separability to improve reproducibility.
- [Abstract] The abstract would benefit from naming the specific voice-stream codecs or network conditions used in the multi-domain setting.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We address each major comment point by point below, indicating the revisions made to strengthen the paper.
read point-by-point responses
-
Referee: [Hessian analysis section] The Hessian analysis (early sections describing the loss-landscape study) shows saddle points and sharp minima but does not establish that these geometric features are the primary cause of poor cross-domain generalization rather than domain-specific feature learning. The spectra are local and batch-dependent; without controls that isolate the contribution of the contrastive term versus the sharpness-minimization term, the claim that DASM's flat-minima component is load-bearing remains unverified.
Authors: We agree that the Hessian analysis in the original submission offers correlational observations rather than direct causal evidence isolating loss-landscape geometry as the primary driver of cross-domain failure versus domain-specific feature learning. The spectra are indeed local and can vary with batch composition. To address this, we have added new ablation studies in the revised manuscript that fix the domain-supervised contrastive learning term and vary only the sharpness-aware minimization component. These controlled comparisons show a clear degradation in cross-domain generalization when the flat-minima term is removed. We have also extended the Hessian visualizations and eigenvalue spectra to multiple independent batches and larger effective sample sizes to reduce batch-dependence concerns. While these empirical controls support the contribution of the sharpness-minimization term, we acknowledge that a full theoretical proof of causality lies beyond the scope of the current empirical study. revision: partial
-
Referee: [Experimental evaluation section] The experimental claims of large-margin outperformance and excellent generalization rest on unspecified datasets, metrics, baselines, number of domains, statistical tests, and implementation details. Because the central generalization and robustness assertions depend on these results, the absence of this information prevents assessment of whether the data actually support the claims.
Authors: We apologize for the insufficient detail on experimental settings in the initial submission. In the revised manuscript we have inserted a new 'Experimental Setup' subsection that fully specifies the datasets (five distinct voice-stream domains drawn from public and collected sources), evaluation metrics (accuracy, AUC-ROC, and F1-score), baseline methods with citations, statistical tests (paired t-tests with p-values reported), and all implementation details including hyperparameters, optimizer settings, training protocol, and hardware. We have also released the source code and data splits to enable direct reproducibility. revision: yes
Circularity Check
No significant circularity; derivation relies on external Hessian analysis and experiments
full rationale
The paper's chain begins with Hessian-based observation of saddle points and sharp minima in mainstream models (treated as empirical input), then proposes DASM as a new optimizer combining contrastive learning, sharpness-aware optimization, and adaptive modulation. Performance is tied to extensive experiments rather than any fitted parameter renamed as prediction or self-referential definition. No load-bearing step reduces by construction to the inputs; the central claim remains independent of self-citation chains or ansatz smuggling.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Through Hessian analysis, we find that the loss landscapes of mainstream models are dominated by numerous saddle points and sharp local minima... propose a new optimizer, Domain-Aware Sharpness Minimization (DASM)
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
integrates domain-supervised contrastive learning with sharpness-aware optimization... adaptive domain gap modulation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Detection of pitch modulation information hiding based on codebook correlation network,
S.-B. Li, Y .-Z. Jia, J.-Y . Fuet al., “Detection of pitch modulation information hiding based on codebook correlation network,”Chinese Journal of Computers, vol. 37, no. 10, pp. 2107–2116, 2014
work page 2014
-
[2]
Steganalysis of qim steganography in low-bit-rate speech signals,
S. Li, Y . Jia, and C.-C. J. Kuo, “Steganalysis of qim steganography in low-bit-rate speech signals,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 25, no. 5, pp. 1011–1022, 2017
work page 2017
-
[3]
Fast detection of heterogeneous parallel steganography for streaming voice,
H. Wang, Z. Yang, Y . Huet al., “Fast detection of heterogeneous parallel steganography for streaming voice,” inProceedings of the 2021 ACM Workshop on Information Hiding and Multimedia Security. ACM, 2021, pp. 137–142
work page 2021
-
[4]
Detection of heterogeneous parallel steganography for low bit-rate voip speech streams,
Y . Hu, Y . Huang, Z. Yanget al., “Detection of heterogeneous parallel steganography for low bit-rate voip speech streams,”Neurocomputing, vol. 419, pp. 70–79, 2021
work page 2021
-
[5]
M. Wei, S. Li, P. Liuet al., “Frame-level steganalysis of qim steganog- raphy in compressed speech based on multi-dimensional perspective of codeword correlations,”Journal of Ambient Intelligence and Humanized Computing, vol. 14, no. 7, pp. 8421–8431, 2023
work page 2023
-
[6]
Detection of qim-based steganography in voip streams: A mobilevit-inspired model,
C. Zhang and S. Jiang, “Detection of qim-based steganography in voip streams: A mobilevit-inspired model,”IEEE Signal Processing Letters, vol. 31, pp. 1735–1739, 2024
work page 2024
-
[7]
Daef-vs: An efficient universal voip steganalysis framework based on domain-aware knowledge,
Z. Fang, P. Zhou, Z. Yang, Z. Zhou, and L. Zhou, “Daef-vs: An efficient universal voip steganalysis framework based on domain-aware knowledge,” inICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025, pp. 1–5
work page 2025
-
[8]
Efficient streaming voice steganalysis in challenging detection scenarios,
P. Zhou, Z. Fang, Z. Yang, Z. Zhou, and L. Zhou, “Efficient streaming voice steganalysis in challenging detection scenarios,”IEEE Transac- tions on Information Forensics and Security, vol. 20, pp. 5966–5977, 2025
work page 2025
-
[9]
An approach to information hiding in low bit-rate speech stream,
B. Xiao, Y . Huang, and S. Tang, “An approach to information hiding in low bit-rate speech stream,” inIEEE GLOBECOM 2008-2008 IEEE global telecommunications conference. IEEE, 2008, pp. 1–5
work page 2008
-
[12]
Sharpness-aware minimization for efficiently improving generalization,
P. Foret, A. Kleiner, H. Mobahi, and B. Neyshabur, “Sharpness-aware minimization for efficiently improving generalization,” inInternational Conference on Learning Representations (ICLR), 2021
work page 2021
-
[13]
Efficient sharpness-aware minimization for improved training of neural networks,
J. Du, H. Yan, J. Feng, J. T. Zhou, L. Zhen, R. S. M. Goh, and V . Tan, “Efficient sharpness-aware minimization for improved training of neural networks,” inInternational Conference on Learning Representations, 2022. [Online]. Available: https: //openreview.net/forum?id=n0OeTdNRG0Q
work page 2022
-
[14]
Sharpness-aware gradient matching for domain generalization,
P. Wang, Z. Zhang, Z. Lei, and L. Zhang, “Sharpness-aware gradient matching for domain generalization,” inCVPR, 2023
work page 2023
-
[15]
Friendly-sam: Leveraging stochastic gradient noise for improved sharpness-aware minimization,
T. Zhang, H. Li, Z. Wanget al., “Friendly-sam: Leveraging stochastic gradient noise for improved sharpness-aware minimization,”Advances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[16]
Escaping saddle points for effective generalization on class-imbalanced data,
H. Rangwani, S. K. Aithal, M. Mishra, and V . B. R, “Escaping saddle points for effective generalization on class-imbalanced data,” inAdvances in Neural Information Processing Systems, S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, Eds., vol. 35. Curran Associates, Inc., 2022, pp. 22 791–22 805
work page 2022
-
[17]
Domain-inspired sharpness-aware minimization under domain shifts,
R. Zhang, Z. Fan, J. Yao, Y . Zhang, and Y . Wang, “Domain-inspired sharpness-aware minimization under domain shifts,”CoRR, vol. abs/2405.18861, 2024. [Online]. Available: https://doi.org/10.48550/ arXiv.2405.18861
-
[18]
Dgsam: Do- main generalization via individual sharpness-aware minimization,
Y . Song, Y . Hwang, J. Lee, H. Lee, and D.-Y . Lim, “Dgsam: Do- main generalization via individual sharpness-aware minimization,”arXiv preprint arXiv:2503.23430, 2025
-
[19]
T. Cedric, R. Adi, and I. Mcloughlin, “Data concealment in audio using a nonlinear frequency distribution of prbs coded data and frequency- domain lsb insertion,” in2000 TENCON Proceedings. Intelligent Sys- tems and Technologies for the New Millennium (Cat. No.00CH37119), vol. 1, 2000, pp. 275–278 vol.1
work page 2000
-
[20]
Increasing the capacity of lsb-based audio steganography,
N. Cvejic and T. Seppanen, “Increasing the capacity of lsb-based audio steganography,” in2002 IEEE Workshop on Multimedia Signal Processing., 2002, pp. 336–338
work page 2002
-
[21]
Hiding secret information using lsb based audio steganography,
A. Binny and M. Koilakuntla, “Hiding secret information using lsb based audio steganography,” in2014 International Conference on Soft Computing and Machine Intelligence. IEEE, 2014, pp. 56–59
work page 2014
-
[22]
Security enhancement of lsb-based audio steganography method,
J. Jezdimirovi ´c, N. Pekez, and J. Kova ˇcevi´c, “Security enhancement of lsb-based audio steganography method,” in2023 Zooming Innovation in Consumer Technologies Conference (ZINC). IEEE, 2023, pp. 77–82
work page 2023
-
[23]
B. Chen and G. Wornell, “Quantization index modulation: a class of provably good methods for digital watermarking and information embedding,”IEEE Transactions on Information Theory, vol. 47, no. 4, pp. 1423–1443, 2001
work page 2001
-
[24]
An approach to information hiding in low bit-rate speech stream,
B. Xiao, Y . Huang, and S. Tang, “An approach to information hiding in low bit-rate speech stream,” inIEEE GLOBECOM 2008 - 2008 IEEE Global Telecommunications Conference, 2008, pp. 1–5
work page 2008
-
[25]
Lpc parameters substitution for speech information hiding,
Z. jun WU, W. GAO, and W. Y ANG, “Lpc parameters substitution for speech information hiding,”The Journal of China Universities of Posts and Telecommunications, vol. 16, no. 6, pp. 103–112, 2009. [Online]. Available: https://www.sciencedirect.com/science/article/pii/ S1005888508602952
work page 2009
-
[26]
Improving security of quantization-index- modulation steganography in low bit-rate speech streams,
H. Tian, J. Liu, and S. Li, “Improving security of quantization-index- modulation steganography in low bit-rate speech streams,”Multimedia Syst., vol. 20, no. 2, p. 143–154, Mar. 2014. [Online]. Available: https://doi.org/10.1007/s00530-013-0302-8
-
[27]
Spm: estimating payload locations of qim-based steganography in low-bit-rate compressed speeches,
C. Zhang, S. Jiang, and Z. Chen, “Spm: estimating payload locations of qim-based steganography in low-bit-rate compressed speeches,” Multimedia Tools and Applications, vol. 83, no. 37, pp. 85 227–85 252,
-
[28]
Available: https://doi.org/10.1007/s11042-024-19501-4
[Online]. Available: https://doi.org/10.1007/s11042-024-19501-4
-
[29]
Data hiding in pitch delay data of the adaptive multi-rate narrow-band speech codec,
A. Nishimura, “Data hiding in pitch delay data of the adaptive multi-rate narrow-band speech codec,” in2009 fifth international conference on intelligent information hiding and multimedia signal processing. IEEE, 2009, pp. 483–486
work page 2009
-
[30]
Steganography integration into a low-bit rate speech codec,
Y . Huang, C. Liu, S. Tang, and S. Bai, “Steganography integration into a low-bit rate speech codec,”IEEE transactions on information forensics and security, vol. 7, no. 6, pp. 1865–1875, 2012
work page 2012
-
[31]
Pitch-based steganography for speex voice codec,
A. Janicki, “Pitch-based steganography for speex voice codec,”Security and communication networks, vol. 9, no. 15, pp. 2923–2933, 2016
work page 2016
-
[32]
A method of speech information hiding in inactive frame based on pitch modulation,
Z. Wu, C. Zhang, and J. Guo, “A method of speech information hiding in inactive frame based on pitch modulation,”International Journal of Information and Computer Security, vol. 22, no. 1, pp. 1–27, 2023
work page 2023
-
[33]
Ahcm: Adaptive huffman code mapping for audio steganography based on psychoacoustic model,
X. Yi, K. Yang, X. Zhao, Y . Wang, and H. Yu, “Ahcm: Adaptive huffman code mapping for audio steganography based on psychoacoustic model,” IEEE Transactions on Information Forensics and Security, vol. 14, no. 8, pp. 2217–2231, 2019
work page 2019
-
[34]
Mdi2: A high-dimensional feature for voip steganalysis,
M. Qiao, W. Zhang, T. Zhanget al., “Mdi2: A high-dimensional feature for voip steganalysis,”IEEE Transactions on Information Forensics and Security, vol. 14, no. 10, pp. 2589–2603, 2019
work page 2019
-
[35]
Co-occurrence matrix based steganal- ysis for low-bit-rate voip streams,
Y . Liu, Y . Huang, and X. Zhang, “Co-occurrence matrix based steganal- ysis for low-bit-rate voip streams,” inProceedings of the ACM Workshop on Information Hiding and Multimedia Security, 2020, pp. 45–56
work page 2020
-
[36]
On large-batch training for deep learning: Generalization gap and sharp minima,
N. S. Keskar, D. Mudigere, J. Nocedalet al., “On large-batch training for deep learning: Generalization gap and sharp minima,”International Conference on Learning Representations (ICLR), 2017
work page 2017
-
[37]
A discriminative feature learning approach for deep face recognition,
Y . Wen, K. Zhang, Z. Li, and Y . Qiao, “A discriminative feature learning approach for deep face recognition,” inEuropean conference on computer vision. Springer, 2016, pp. 499–515
work page 2016
-
[38]
Unsupervised learning of visual features by contrasting cluster assign- ments,
M. Caron, I. Misra, J. Mairal, P. Goyal, P. Bojanowski, and A. Joulin, “Unsupervised learning of visual features by contrasting cluster assign- ments,”Advances in neural information processing systems, vol. 33, pp. 9912–9924, 2020
work page 2020
-
[39]
A theory of learning from different domains,
S. Ben-David, J. Blitzer, K. Crammer, A. Kulesza, F. Pereira, and J. W. Vaughan, “A theory of learning from different domains,”Machine Learning, vol. 79, no. 1, pp. 151–175, 2010
work page 2010
-
[40]
Visualizing the loss landscape of neural nets,
H. Li, Z. Xu, G. Taylor, C. Studer, and T. Goldstein, “Visualizing the loss landscape of neural nets,” inAdvances in Neural Information Processing Systems, S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, Eds., vol. 31. Curran Associates, Inc., 2018. [Online]. Available: https://proceedings.neurips.cc/paper files/paper/20...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.