OpenHLM: An Empirical Recipe for Whole-Body Humanoid Loco-Manipulation
Pith reviewed 2026-06-26 11:36 UTC · model grok-4.3
The pith
A phased empirical roadmap yields a whole-body humanoid VLA that outperforms prior models while using less than half the demonstration data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
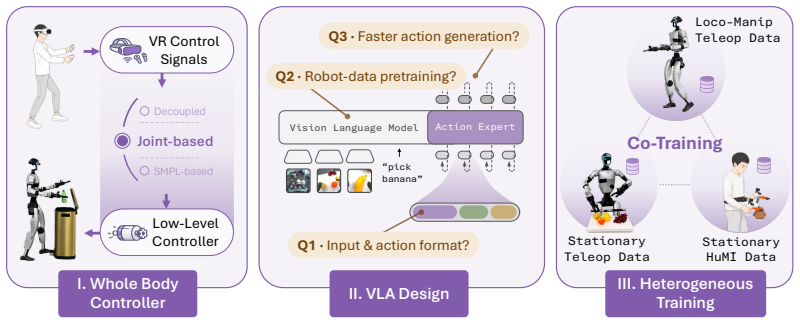
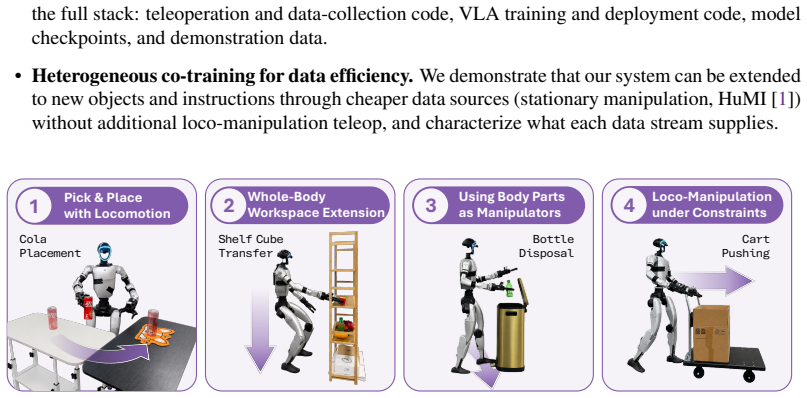
The authors show that a joint-based whole-body teleoperation interface, combined with pretraining on static and wheeled dual-arm data and co-training on humanoid-specific demonstrations, produces a policy that coordinates the entire kinematic chain. In a challenging long-horizon task, this policy exceeds the performance of two existing humanoid VLA baselines while requiring less than half the total demonstration time and without any additional whole-body teleoperation on the evaluation objects and instructions.
What carries the argument
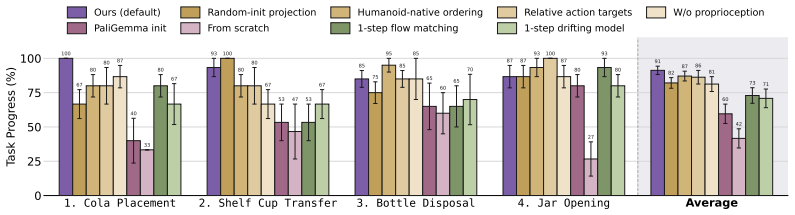
The three-phase empirical roadmap of one-variable-at-a-time experiments that isolates the contribution of teleoperation interface, pretraining sources, and heterogeneous co-training to whole-body policy performance.
If this is right
- Joint-based teleoperation that exposes all degrees of freedom produces higher-quality demonstrations than interfaces that hide part of the kinematic chain.
- A model pretrained on static and wheeled platforms transfers directly to a humanoid's full action space without architecture changes.
- Co-training with humanoid data collected via a simpler interface extends the policy to new objects and language instructions without new whole-body demonstrations.
- The resulting policy achieves higher success rates than prior humanoid VLAs on long-horizon tasks that require coordinated motion across a wide vertical range.
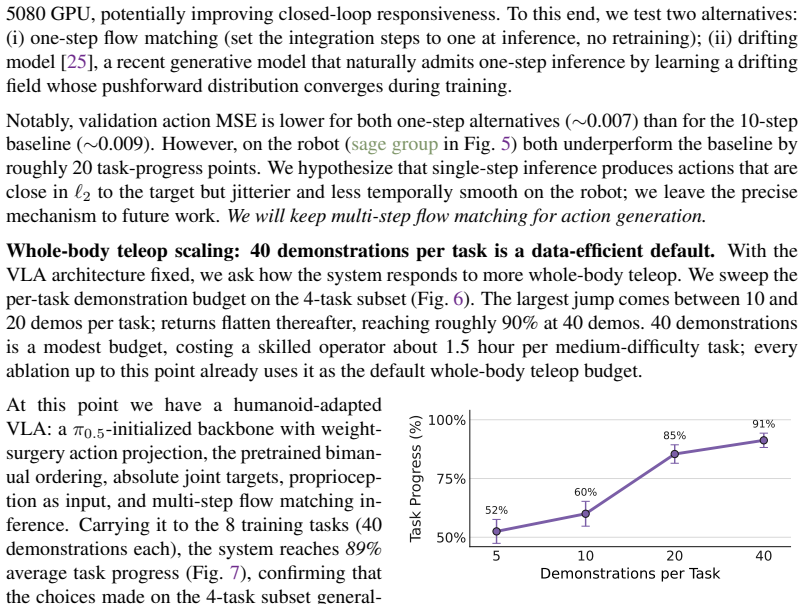
Where Pith is reading between the lines
- The same phased testing sequence could be applied to test whether other robot morphologies benefit from mixed-platform pretraining.
- If the co-training benefit holds under stricter distribution-shift controls, it would lower the data-collection barrier for deploying humanoids in new environments.
- The roadmap's emphasis on isolating one variable at a time offers a template for future empirical studies of whole-body control that avoid confounding multiple design changes.
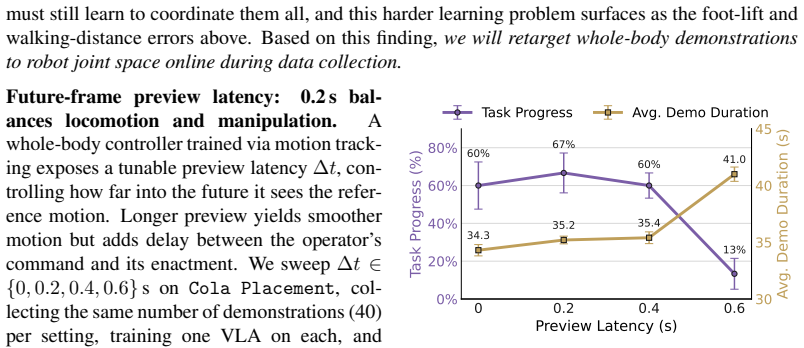
Load-bearing premise
That co-training on data collected from static, wheeled, and humanoid platforms will extend policy performance to new objects and instructions without any further whole-body teleoperation on those targets.
What would settle it
A side-by-side comparison in which the co-trained model shows no improvement, or a decline, in success rate on new objects and instructions relative to a model trained only on the original humanoid demonstrations when total data volume and task difficulty are held constant.
Figures





read the original abstract
Whole-body humanoid loco-manipulation requires coordinating the robot's entire kinematic chain. However, most existing systems typically decouple the upper and lower bodies into separate controllers, limiting such coordination and yielding behaviors similar to those of a wheeled dual-arm platform. In this paper, we ask what it takes to build a whole-body native vision-language-action (VLA) model that maps language and pixels directly to all of the humanoid's degrees of freedom. We conduct a systematic empirical study organized as a roadmap of one-variable-at-a-time experiments across three phases: whole-body teleoperation, VLA model design, and heterogeneous co-training. Our study yields several intriguing findings: a joint-based whole-body teleoperation interface outperforms alternatives that only partially expose the humanoid's degrees of freedom; a VLA pretrained on static and wheeled dual-arm platforms transfers surprisingly well to a humanoid's full action space; and co-training with HuMI, the humanoid analog of UMI, extends the policy to new objects and instructions without additional whole-body teleoperation on those targets. Following this roadmap yields OpenHLM, an open-source recipe for whole-body humanoid loco-manipulation. In a challenging long-horizon task that spans a wide vertical range of the humanoid, OpenHLM outperforms two state-of-the-art humanoid VLA baselines (GR00T N1.6 and $\Psi_0$) using less than half the total demonstration time. Our code, training data, and model checkpoints are available at [https://openhlm-project.github.io/].
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts an empirical study organized as a one-variable-at-a-time roadmap across whole-body teleoperation, VLA model design, and heterogeneous co-training phases. It reports that a joint-based teleoperation interface, pretraining on static/wheeled platforms, and co-training with HuMI data together produce OpenHLM, an open-source whole-body VLA that outperforms GR00T N1.6 and Ψ0 on a long-horizon loco-manipulation task spanning wide vertical range while using less than half the total demonstration time. Code, training data, and checkpoints are released.
Significance. If the central efficiency result holds under controlled conditions, the work would supply a practical, reproducible recipe for scaling whole-body humanoid VLA policies by leveraging heterogeneous data sources, thereby lowering the barrier of whole-body teleoperation for new objects and instructions. The explicit release of code, training data, and model checkpoints is a clear strength that supports direct replication and extension by the community.
major comments (1)
- [Abstract] Abstract: the central claim that heterogeneous co-training on static, wheeled, and HuMI data extends policy performance to new objects/instructions without any additional whole-body teleoperation demonstrations underpins the reported <half demonstration-time advantage over GR00T N1.6 and Ψ0. No ablation that removes the co-training data while holding humanoid teleoperation fixed, no distribution-shift metrics (e.g., feature-space distance or held-out source-task success gap), and no explicit task-difficulty matching (vertical range, horizon length, object variability) between co-training and evaluation are described. This omission leaves open whether observed gains arise from the co-training mechanism or from model architecture, teleoperation interface, or evaluation conditions.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our manuscript. We provide a point-by-point response to the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that heterogeneous co-training on static, wheeled, and HuMI data extends policy performance to new objects/instructions without any additional whole-body teleoperation demonstrations underpins the reported <half demonstration-time advantage over GR00T N1.6 and Ψ0. No ablation that removes the co-training data while holding humanoid teleoperation fixed, no distribution-shift metrics (e.g., feature-space distance or held-out source-task success gap), and no explicit task-difficulty matching (vertical range, horizon length, object variability) between co-training and evaluation are described. This omission leaves open whether observed gains arise from the co-training mechanism or from model architecture, teleoperation interface, or evaluation conditions.
Authors: We agree that the manuscript would benefit from a more explicit isolation of the heterogeneous co-training effect. Our empirical study is organized as a one-variable-at-a-time roadmap, with the VLA model design phase incorporating pretraining on static and wheeled platforms, followed by the co-training phase with HuMI data. The performance advantage is demonstrated relative to GR00T N1.6 and Ψ0 baselines. However, we did not include an ablation that trains a model using only the humanoid teleoperation demonstrations without the heterogeneous data sources, nor did we report distribution-shift metrics or detailed task-difficulty matching. We will incorporate these analyses in the revised version to more rigorously support the contribution of the co-training mechanism. revision: yes
Circularity Check
Empirical study with no derivations or fitted predictions; results are direct experimental outcomes.
full rationale
The paper conducts a systematic empirical study organized as one-variable-at-a-time experiments across teleoperation, VLA model design, and heterogeneous co-training phases. All reported findings, including the outperformance of OpenHLM over baselines with less demonstration time, are presented as direct results from data collection and training runs. No equations, parameter fits, or derivations appear that could reduce a claimed prediction to its inputs by construction. Self-citations, if present, are not load-bearing for any central result, and the work is self-contained against external benchmarks without circular reductions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
R. Nai, B. Zheng, J. Zhao, H. Zhu, S. Dai, Z. Chen, Y . Hu, Y . Hu, T. Zhang, C. Wen, et al. Hu- manoid manipulation interface: Humanoid whole-body manipulation from robot-free demon- strations.arXiv preprint arXiv:2602.06643, 2026
arXiv 2026
- [2]
-
[3]
M. Liu, Z. Chen, X. Cheng, Y . Ji, R.-Z. Qiu, R. Yang, and X. Wang. Visual whole-body control for legged loco-manipulation.arXiv preprint arXiv:2403.16967, 2024
arXiv 2024
-
[4]
C. Lu, X. Cheng, J. Li, S. Yang, M. Ji, C. Yuan, G. Yang, S. Yi, and X. Wang. Mobile- television: Predictive motion priors for humanoid whole-body control. In2025 IEEE Interna- tional Conference on Robotics and Automation (ICRA), pages 5364–5371. IEEE, 2025
2025
-
[5]
Q. Ben, F. Jia, J. Zeng, J. Dong, D. Lin, and J. Pang. Homie: Humanoid loco-manipulation with isomorphic exoskeleton cockpit.arXiv preprint arXiv:2502.13013, 2025. 12
arXiv 2025
-
[6]
J. Li, X. Cheng, T. Huang, S. Yang, R.-Z. Qiu, and X. Wang. Amo: Adaptive motion optimiza- tion for hyper-dexterous humanoid whole-body control.arXiv preprint arXiv:2505.03738, 2025
arXiv 2025
-
[7]
Gr00t n1.6: An improved open foundation model for generalist hu- manoid robots.https://research.nvidia.com/labs/gear/gr00t-n1_6/, Dec
NVIDIA GEAR Team. Gr00t n1.6: An improved open foundation model for generalist hu- manoid robots.https://research.nvidia.com/labs/gear/gr00t-n1_6/, Dec. 2025. NVIDIA Research Blog, Accessed: 2026-05-06
2025
-
[8]
S. Wei, H. Jing, B. Li, Z. Zhao, J. Mao, Z. Ni, S. He, J. Liu, X. Liu, K. Kang, et al.Ψ 0: An open foundation model towards universal humanoid loco-manipulation.arXiv preprint arXiv:2603.12263, 2026
arXiv 2026
-
[9]
Y . Ze, S. Zhao, W. Wang, A. Kanazawa, R. Duan, P. Abbeel, G. Shi, J. Wu, and C. K. Liu. Twist2: Scalable, portable, and holistic humanoid data collection system.arXiv preprint arXiv:2511.02832, 2025
arXiv 2025
-
[10]
Introducing helix 02: Full-body autonomy.https://www.figure.ai/news/ helix-02, Jan
Figure AI. Introducing helix 02: Full-body autonomy.https://www.figure.ai/news/ helix-02, Jan. 2026. Figure AI Blog, Accessed: 2026-05-06
2026
-
[11]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[12]
T. He, Z. Luo, X. He, W. Xiao, C. Zhang, W. Zhang, K. Kitani, C. Liu, and G. Shi. Omnih2o: Universal and dexterous human-to-humanoid whole-body teleoperation and learning.arXiv preprint arXiv:2406.08858, 2024
arXiv 2024
-
[13]
Z. Luo, Y . Yuan, T. Wang, C. Li, S. Chen, F. Castaneda, Z.-A. Cao, J. Li, D. Minor, Q. Ben, et al. Sonic: Supersizing motion tracking for natural humanoid whole-body control.arXiv preprint arXiv:2511.07820, 2025
Pith/arXiv arXiv 2025
-
[14]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[15]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[16]
C. Chi, Z. Xu, C. Pan, E. Cousineau, B. Burchfiel, S. Feng, R. Tedrake, and S. Song. Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots.arXiv preprint arXiv:2402.10329, 2024
Pith/arXiv arXiv 2024
-
[17]
M. Shi, S. Peng, J. Chen, H. Jiang, Y . Li, D. Huang, P. Luo, H. Li, and L. Chen. Egohu- manoid: Unlocking in-the-wild loco-manipulation with robot-free egocentric demonstration. arXiv preprint arXiv:2602.10106, 2026
Pith/arXiv arXiv 2026
-
[18]
Decoupled wbc.https://nvlabs.github.io/ GR00T-WholeBodyControl/references/decoupled_wbc.html, 2026
NVIDIA GEAR Team. Decoupled wbc.https://nvlabs.github.io/ GR00T-WholeBodyControl/references/decoupled_wbc.html, 2026. GR00T- WholeBodyControl Documentation. Last updated: 2026-05-07. Accessed: 2026-05-14
2026
-
[19]
PICO Immersive Pte. Ltd. PICO 4 Ultra.https://www.picoxr.com/global/products/ pico4-ultra, 2024. Product webpage. Accessed: 2026-05-14
2024
-
[20]
J. P. Araujo, Y . Ze, P. Xu, J. Wu, and C. K. Liu. Retargeting matters: General motion retargeting for humanoid motion tracking.arXiv preprint arXiv:2510.02252, 2025
arXiv 2025
-
[21]
M. Loper, N. Mahmood, J. Romero, G. Pons-Moll, and M. J. Black. Smpl: A skinned multi- person linear model.ACM Transactions on Graphics (TOG), 34(6), Oct. 2015. doi:10.1145/ 2816795.2818013. URLhttps://doi.org/10.1145/2816795.2818013. 13
-
[22]
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al.π 0.5: a vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[23]
L. Beyer, A. Steiner, A. S. Pinto, A. Kolesnikov, X. Wang, D. Salz, M. Neumann, I. Alabdul- mohsin, M. Tschannen, E. Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer.arXiv preprint arXiv:2407.07726, 2024
Pith/arXiv arXiv 2024
-
[24]
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
Pith/arXiv arXiv 2022
-
[25]
M. Deng, H. Li, T. Li, Y . Du, and K. He. Generative modeling via drifting.arXiv preprint arXiv:2602.04770, 2026
Pith/arXiv arXiv 2026
-
[26]
VIVE Ultimate Tracker.https://www.vive.com/eu/accessory/ vive-ultimate-tracker/
HTC VIVE. VIVE Ultimate Tracker.https://www.vive.com/eu/accessory/ vive-ultimate-tracker/. Accessed: 2026-05-16
2026
-
[27]
Cosmos-reason2: Physical ai common sense and embodied reasoning models
NVIDIA. Cosmos-reason2: Physical ai common sense and embodied reasoning models. https://huggingface.co/nvidia/Cosmos-Reason2-8B, 2025. Accessed: 2026-05-17
2025
-
[28]
Peebles and S
W. Peebles and S. Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[29]
Y . Ze, Z. Chen, J. P. Ara´ujo, Z.-a. Cao, X. B. Peng, J. Wu, and C. K. Liu. Twist: Teleoperated whole-body imitation system.arXiv preprint arXiv:2505.02833, 2025
arXiv 2025
-
[30]
Z. Fu, Q. Zhao, Q. Wu, G. Wetzstein, and C. Finn. Humanplus: Humanoid shadowing and imitation from humans.arXiv preprint arXiv:2406.10454, 2024
arXiv 2024
- [31]
-
[32]
Q. Liao, T. E. Truong, X. Huang, Y . Gao, G. Tevet, K. Sreenath, and C. K. Liu. Beyondmimic: From motion tracking to versatile humanoid control via guided diffusion.arXiv preprint arXiv:2508.08241, 2025
Pith/arXiv arXiv 2025
-
[33]
W. Zeng, S. Lu, K. Yin, X. Niu, M. Dai, J. Wang, and J. Pang. Behavior foundation model for humanoid robots.arXiv preprint arXiv:2509.13780, 2025
arXiv 2025
-
[34]
Z. Chen, M. Ji, X. Cheng, X. Peng, X. B. Peng, and X. Wang. Gmt: General motion tracking for humanoid whole-body control.arXiv preprint arXiv:2506.14770, 2025
arXiv 2025
-
[35]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[36]
P. Intelligence, A. Amin, R. Aniceto, A. Balakrishna, K. Black, K. Conley, G. Connors, J. Darpinian, K. Dhabalia, J. DiCarlo, et al.π ∗ 0.6: A VLA That Learns From Experience. arXiv preprint arXiv:2511.14759, 2025
Pith/arXiv arXiv 2025
-
[37]
P. Intelligence, A. Amin, R. Aniceto, A. Balakrishna, G. Balke, K. Black, G. Bokinsky, S. Cao, T. Charbonnier, et al.π 0.7: A Steerable Generalist Robotic Foundation Model with Emergent Capabilities.arXiv preprint arXiv:2604.15483, 2026
Pith/arXiv arXiv 2026
-
[38]
R. Hoque, P. Huang, D. J. Yoon, M. Sivapurapu, and J. Zhang. Egodex: Learning dexterous manipulation from large-scale egocentric video.arXiv preprint arXiv:2505.11709, 2025
Pith/arXiv arXiv 2025
-
[39]
K. Liu, C. Guan, Z. Jia, Z. Wu, X. Liu, T. Wang, S. Liang, P. Chen, P. Zhang, H. Song, et al. Fastumi: A scalable and hardware-independent universal manipulation interface with dataset. arXiv preprint arXiv:2409.19499, 2024. 14
arXiv 2024
-
[40]
F. Lin, Y . Hu, P. Sheng, C. Wen, J. You, and Y . Gao. Data scaling laws in imitation learning for robotic manipulation. InInternational Conference on Learning Representations, volume 2025, pages 54877–54910, 2025
2025
-
[41]
J. Engel, K. Somasundaram, M. Goesele, A. Sun, A. Gamino, A. Turner, A. Talattof, A. Yuan, B. Souti, B. Meredith, et al. Project aria: A new tool for egocentric multi-modal ai research. arXiv preprint arXiv:2308.13561, 2023
Pith/arXiv arXiv 2023
-
[42]
Apple vision pro technical specifications.https://www.apple.com/sg/ apple-vision-pro/specs/, 2026
Apple Inc. Apple vision pro technical specifications.https://www.apple.com/sg/ apple-vision-pro/specs/, 2026. Accessed: 2026-05-18
2026
-
[43]
Meta quest 3.https://www.meta.com/quest/quest-3/, 2026
Meta Platforms, Inc. Meta quest 3.https://www.meta.com/quest/quest-3/, 2026. Ac- cessed: 2026-05-18
2026
-
[44]
Grauman, A
K. Grauman, A. Westbury, L. Torresani, K. Kitani, J. Malik, T. Afouras, K. Ashutosh, V . Baiyya, S. Bansal, B. Boote, et al. Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19383–19400, 2024
2024
-
[45]
Grauman, A
K. Grauman, A. Westbury, E. Byrne, Z. Chavis, A. Furnari, R. Girdhar, J. Hamburger, H. Jiang, M. Liu, X. Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18995–19012, 2022
2022
-
[46]
S. Nair, A. Rajeswaran, V . Kumar, C. Finn, and A. Gupta. R3m: A universal visual represen- tation for robot manipulation.arXiv preprint arXiv:2203.12601, 2022
Pith/arXiv arXiv 2022
-
[47]
Y . J. Ma, S. Sodhani, D. Jayaraman, O. Bastani, V . Kumar, and A. Zhang. Vip: Towards universal visual reward and representation via value-implicit pre-training.arXiv preprint arXiv:2210.00030, 2022
Pith/arXiv arXiv 2022
-
[48]
R. Yang, Q. Yu, Y . Wu, R. Yan, B. Li, A.-C. Cheng, X. Zou, Y . Fang, X. Cheng, R.-Z. Qiu, et al. Egovla: Learning vision-language-action models from egocentric human videos.arXiv preprint arXiv:2507.12440, 2025
Pith/arXiv arXiv 2025
-
[49]
S. Ye, J. Jang, B. Jeon, S. J. Joo, J. Yang, B. Peng, A. Mandlekar, R. Tan, Y .-W. Chao, B. Y . Lin, et al. Latent action pretraining from videos. InInternational Conference on Learning Representations, volume 2025, pages 28213–28239, 2025
2025
-
[50]
Q. Bu, Y . Yang, J. Cai, S. Gao, G. Ren, M. Yao, P. Luo, and H. Li. Univla: Learning to act anywhere with task-centric latent actions.arXiv preprint arXiv:2505.06111, 2025
Pith/arXiv arXiv 2025
-
[51]
C. Yuan, R. Zhou, M. Liu, Y . Hu, S. Wang, L. Yi, C. Wen, S. Zhang, and Y . Gao. Motiontrans: Human vr data enable motion-level learning for robotic manipulation policies.arXiv preprint arXiv:2509.17759, 2025
arXiv 2025
-
[52]
R.-Z. Qiu, S. Yang, X. Cheng, C. Chawla, J. Li, T. He, G. Yan, D. J. Yoon, R. Hoque, L. Paulsen, et al. Humanoid policy˜ human policy.arXiv preprint arXiv:2503.13441, 2025
arXiv 2025
-
[53]
CTAG2F90-D Electric Parallel Gripper
ChangingTek Robotics Technology (Suzhou) Co., Ltd. CTAG2F90-D Electric Parallel Gripper. https://en.changingtek.com/diandong/147. Accessed: 2026-05-29
2026
-
[54]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025. 15 Appendices A The HLM-12 Benchmark 17 A.1 The 12 Tasks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17 A.2 Overall Evaluation Protocol . . . . . . . . . . . . . . . . ...
Pith/arXiv arXiv 2025
-
[55]
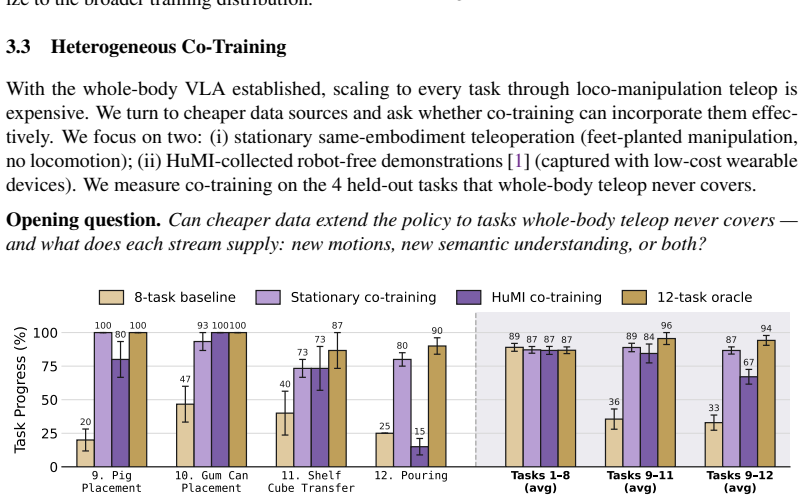
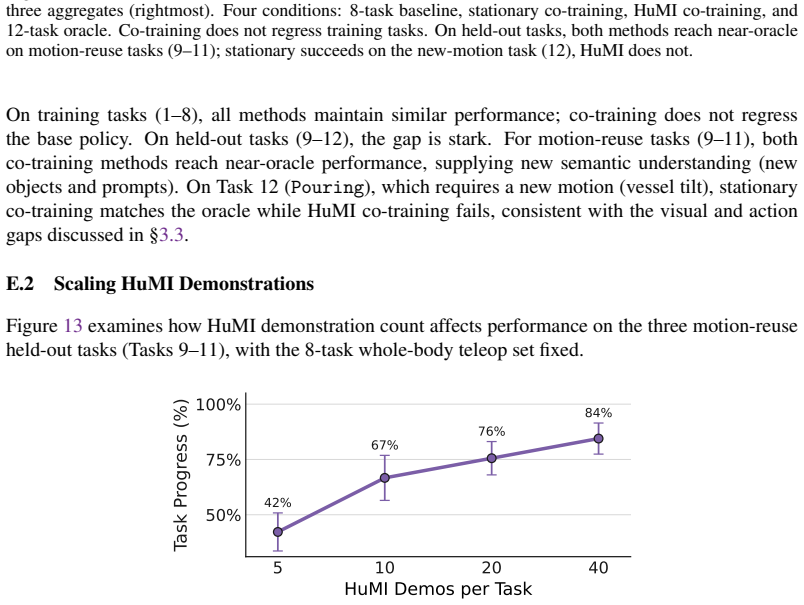
Four conditions: 8-task baseline, stationary co-training, HuMI co-training, and 12-task oracle
Pouring Tasks 1 8 (avg) Tasks 9 11 (avg) Tasks 9 12 (avg) 0 25 50 75 100T ask Progress (%) 100 93 87 87 93 87 80 93 85 100 95 85 87 100100100 92 92 72 88 85 70 95 95 90 75 85 80 80 80 80 67 20 100 80 100 47 93 100100 40 73 73 87 25 80 15 90 89 87 87 87 36 89 84 96 33 87 67 94 8-task baseline Stationary co-training HuMI co-training 12-task oracle Figure 12...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.