KernelFlume: Elastic Core-Attention Scaling for Agentic Long-Context Decoding
Pith reviewed 2026-06-30 02:49 UTC · model grok-4.3
The pith
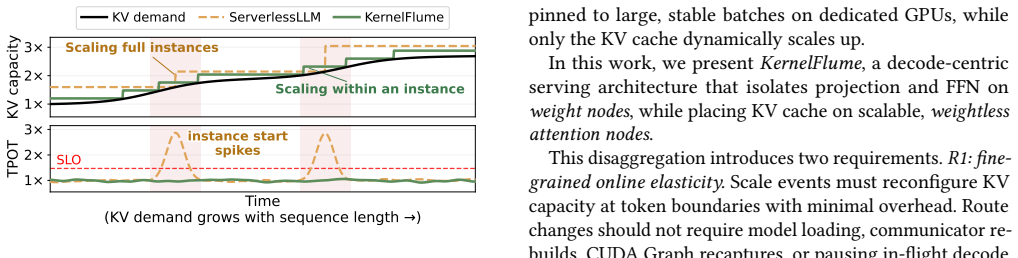
KernelFlume disaggregates core attention into elastic weightless nodes so KV capacity scales without full model replicas for bursty long-context agentic workloads.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
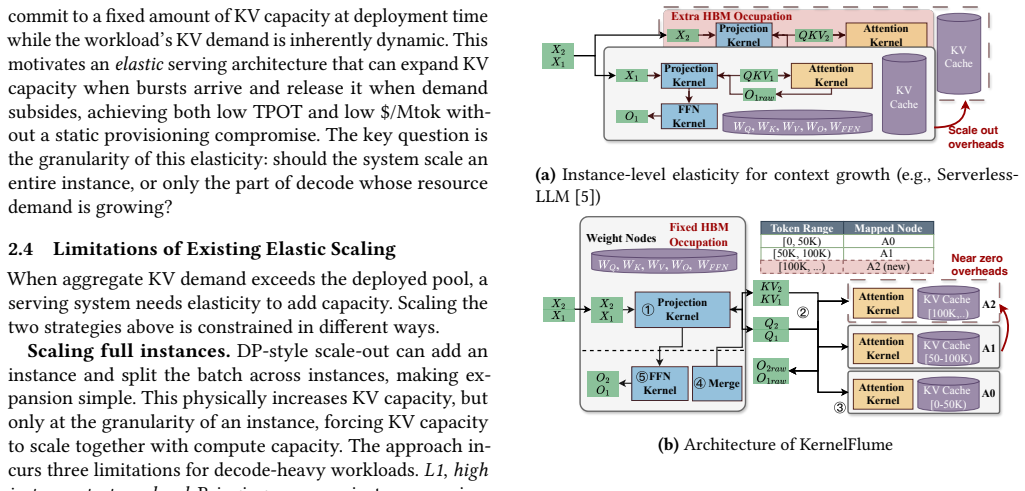
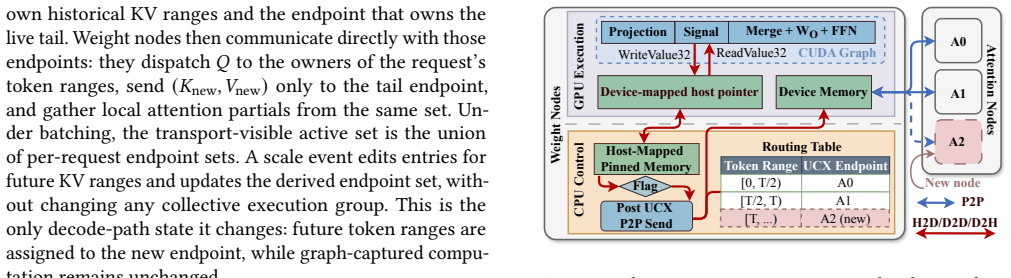
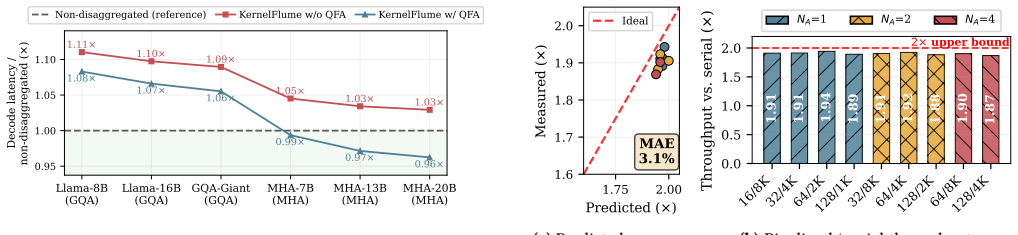
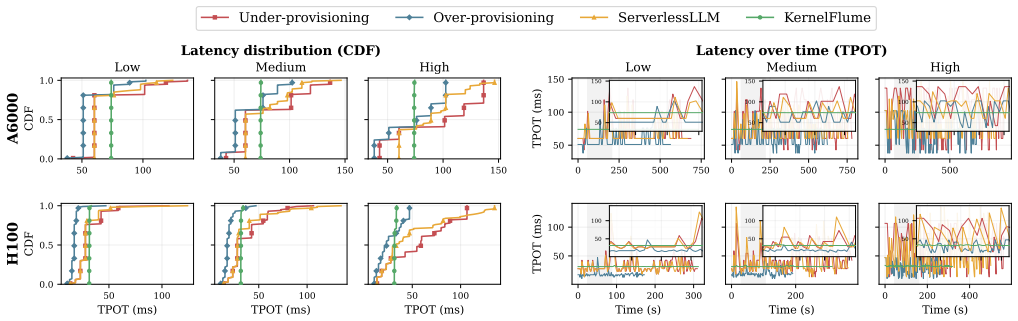
KernelFlume disaggregates the stable projection/FFN path from core-attention computation so that weight nodes run dense kernels while weightless attention nodes store KV partitions and scale with token-range demand; a routing table maps token ranges to attention-node endpoints, updates at token boundaries, and drives pre-registered UCX communication outside CUDA Graphs; query-first dispatch combined with inter-layer pipelining overlaps remote attention and communication with local work, producing flat p99 TPOTs of approximately 74 ms on A6000 and 34 ms on H100 under dynamic long-context agentic workloads and cost reductions of up to 32 percent and 61 percent relative to ServerlessLLM.
What carries the argument
The routing table that maps token ranges to attention-node endpoints and drives host-visible graph signals for UCX communication outside captured CUDA Graphs.
If this is right
- p99 TPOT remains flat at approximately 74 ms on A6000 and 34 ms on H100 during bursty demand.
- Cost per million output tokens falls by up to 32 percent on A6000 and 61 percent on H100 versus full-instance scaling.
- Simulation at larger model scales projects 56 to 66 percent cost reduction, widening to 80 to 85 percent with cheaper heterogeneous attention hardware.
- The cost advantage holds into the million-token context range.
Where Pith is reading between the lines
- The design could allow attention nodes to use cheaper or specialized hardware while weight nodes stay on high-end GPUs.
- The same token-range routing and pipelining pattern might apply to other disaggregated serving setups that separate KV storage from dense compute.
- Because the method avoids full model replication, it could reduce memory fragmentation when many concurrent long-context sessions share the same base weights.
Load-bearing premise
The separation of stable projection and FFN kernels from core-attention computation can be made elastic through a routing table and host-visible signals without adding unacceptable per-token latency.
What would settle it
Run the same dynamic long-context agentic trace on the A6000 testbed while scaling the number of attention nodes and check whether p99 TPOT rises above 74 ms or cost per million output tokens fails to drop below the ServerlessLLM baseline.
Figures




read the original abstract
LLM serving is increasingly dominated by long and dynamic decode workloads from agents, reasoning models, and extended conversations. When bursty long-context demand exceeds deployed capacity, existing serving systems typically scale out by launching additional serving instances with model replicas. This instance-level elasticity increases KV capacity only by provisioning another full copy of the model, inheriting startup latency, memory overhead, and batch fragmentation. We present KernelFlume, a decode-centric architecture that disaggregates the stable projection/FFN path from core-attention computation: weight nodes execute dense projection/FFN kernels, while weightless attention nodes store token-range KV partitions and scale with request-state demand. To make this separation elastic, KernelFlume maintains a routing table that maps token ranges to attention-node endpoints. It updates routes at token boundaries and uses host-visible graph signals to drive pre-registered UCX endpoint communication outside the captured CUDA Graph. To preserve low per-token latency after disaggregation, KernelFlume combines query-first core-attention dispatch with inter-layer kernel pipelining, overlapping remote attention and communication with local projection/FFN work. On real GPU testbeds (intra-node A6000 and cross-node H100), under a dynamic long-context agentic workload serving Llama-3.1-8B, KernelFlume sustains flat p99 TPOTs of ~74 ms on A6000 and ~34 ms on H100, while lowering cost per million output tokens by up to 32% and 61%, respectively, relative to full-instance elastic scaling with ServerlessLLM, a state-of-the-art instance-startup method. Replaying the same trace at larger model scale in simulation projects a 56--66% cost reduction over ServerlessLLM, widening to 80--85% with cheaper heterogeneous attention-node hardware and persisting into the million-token context range.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents KernelFlume, a decode-centric architecture that disaggregates stable projection/FFN kernels (executed on weight nodes) from core-attention computation (executed on weightless attention nodes that store token-range KV partitions). Elasticity is achieved via a routing table mapping token ranges to attention-node endpoints, updated at token boundaries, with host-visible graph signals driving pre-registered UCX communication outside the CUDA Graph. Query-first dispatch and inter-layer pipelining are used to overlap remote attention/communication with local work. On intra-node A6000 and cross-node H100 testbeds serving Llama-3.1-8B under a dynamic long-context agentic workload, the system reports flat p99 TPOTs of ~74 ms and ~34 ms respectively, with cost-per-million-output-tokens reductions of up to 32% and 61% versus full-instance elastic scaling with ServerlessLLM; simulation projects 56-85% savings at larger scales and million-token contexts.
Significance. If the reported flat p99 TPOTs hold under the claimed mechanisms, the work addresses a practical bottleneck in serving bursty long-context agentic workloads by avoiding full-model replication and its associated startup, memory, and fragmentation costs. The concrete GPU testbed numbers and heterogeneous-hardware projections provide a falsifiable basis for evaluating cost-efficiency gains in production LLM serving systems.
major comments (2)
- [Abstract] Abstract: the central claim of latency-neutral disaggregation (flat p99 TPOTs of ~74 ms / ~34 ms) rests on query-first dispatch plus inter-layer pipelining fully overlapping remote attention/UCX with local projection/FFN work and on routing-table updates at token boundaries not introducing jitter. No per-component latency breakdown, ablation of the routing/pipelining mechanisms, error bars, or workload-trace description is supplied to isolate these overheads from the end-to-end numbers; any residual non-overlapped time would directly affect the reported tails.
- [Abstract] Abstract: the cost-reduction claims (32%/61% on A6000/H100, widening to 80-85% with heterogeneous attention nodes) are load-bearing for the contribution yet are presented only as aggregate outcomes relative to ServerlessLLM; without an accounting of how KV-partition scaling, routing-table maintenance, and UCX registration costs are measured or amortized, it is impossible to assess whether the savings are robust to changes in request-state demand or context length.
minor comments (1)
- [Abstract] The abstract refers to 'real GPU testbeds (intra-node A6000 and cross-node H100)' and 'replaying the same trace at larger model scale in simulation' without specifying the exact hardware topology, interconnect, or simulation methodology; adding these details would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need for component-level breakdowns and cost accounting to support the latency and savings claims. We will perform a major revision incorporating the requested details, ablations, and analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of latency-neutral disaggregation (flat p99 TPOTs of ~74 ms / ~34 ms) rests on query-first dispatch plus inter-layer pipelining fully overlapping remote attention/UCX with local projection/FFN work and on routing-table updates at token boundaries not introducing jitter. No per-component latency breakdown, ablation of the routing/pipelining mechanisms, error bars, or workload-trace description is supplied to isolate these overheads from the end-to-end numbers; any residual non-overlapped time would directly affect the reported tails.
Authors: We agree that isolating the overheads of query-first dispatch, inter-layer pipelining, and routing-table updates is important for validating the flat p99 TPOT claims. In the revised manuscript we will add a dedicated subsection with per-component latency breakdowns (local projection/FFN, remote attention, UCX communication) measured via CUDA events, plus ablations that disable pipelining and routing updates individually. Error bars from five independent runs will be reported on all end-to-end and component metrics. The workload trace (synthetic agentic long-context benchmark with context lengths drawn from 4k–128k tokens and bursty arrivals) will be described in expanded detail in Section 4.1, including arrival-rate distribution and context-growth model. revision: yes
-
Referee: [Abstract] Abstract: the cost-reduction claims (32%/61% on A6000/H100, widening to 80-85% with heterogeneous attention nodes) are load-bearing for the contribution yet are presented only as aggregate outcomes relative to ServerlessLLM; without an accounting of how KV-partition scaling, routing-table maintenance, and UCX registration costs are measured or amortized, it is impossible to assess whether the savings are robust to changes in request-state demand or context length.
Authors: We concur that an explicit cost-component breakdown is required to demonstrate robustness. The revision will include a new cost-modeling subsection that itemizes (1) KV-partition memory scaling (measured per-token KV cache size on attention nodes), (2) routing-table maintenance (host CPU cycles per token-boundary update), and (3) UCX registration (amortized over attention-node lifetime). We will add sensitivity plots showing cost per million tokens versus context length and request-state demand, plus an appendix table with raw component costs for both testbeds and the simulated larger-scale scenarios. revision: yes
Circularity Check
No circularity: architecture and empirical results only
full rationale
The manuscript presents a systems design (disaggregation of projection/FFN from attention via routing table, UCX, query-first dispatch, and pipelining) together with end-to-end latency and cost measurements on A6000/H100 testbeds under an agentic trace. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. Performance numbers are reported as direct observations relative to ServerlessLLM (an external baseline), not reductions to any internal definition or prior self-result. The derivation chain is therefore self-contained experimental reporting.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S Gulavani, Alexey Tumanov, and Ramachandran Ramjee. 2024. Taming Throughput-Latency Tradeoff in LLM Infer- ence with Sarathi-Serve. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). USENIX Association, Santa Clara, CA, 117–134.https://www.usen...
2024
-
[2]
Qiaoling Chen, Zhisheng Ye, Tian Tang, Peng Sun, Boyu Tian, Guoteng Wang, Shenggui Li, Yonggang Wen, Zhenhua Han, and Tianwei Zhang. 2026. CONCUR: High-Throughput Agentic Batch Inference of LLM via Congestion-Based Concurrency Control. arXiv preprint arXiv:2601.22705.https://arxiv.org/abs/2601.22705
-
[3]
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
-
[4]
Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems35 (2022), 16344–16359
2022
-
[5]
DeepSeek-AI. 2025. DeepEP: An Efficient Expert-Parallel Communi- cation Library.https://github.com/deepseek-ai/DeepEP. Accessed: 2025-03-01
2025
-
[6]
Yao Fu, Leyang Xue, Yeqi Huang, Andrei-Octavian Brabete, Dmitrii Ustiugov, Yuvraj Patel, and Luo Mai. 2024. ServerlessLLM: Low- Latency Serverless Inference for Large Language Models. InProceed- ings of the 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI). USENIX Association, 135–153
2024
-
[7]
Bin Gao, Zhuomin He, Puru Sharma, Qingxuan Kang, Djordje Jevdjic, Junbo Deng, Xingkun Yang, Zhou Yu, and Pengfei Zuo. 2024. Cost- Efficient Large Language Model Serving for Multi-turn Conversations with CachedAttention. In2024 USENIX Annual Technical Conference (USENIX ATC 24). USENIX Association, Santa Clara, CA, 111–126. https://www.usenix.org/conferenc...
2024
-
[8]
Daya Guo, Dejian Yang, He Zhang, Junxiao Song, Runxin Zhang, Ruoyu Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. 2025. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Re- inforcement Learning. arXiv preprint arXiv:2501.12948.https: //arxiv.org/abs/2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Roger W Hockney. 1994. The communication challenge for MPP: Intel Paragon and Meiko CS-2.Parallel Comput.20, 3 (1994), 389–398
1994
-
[10]
Cunchen Hu, Heyang Huang, Junhao Hu, Jiang Xu, Xusheng Chen, Tao Xie, Chenxi Wang, Sa Wang, Yungang Bao, Ninghui Sun, and Yizhou Shan. 2024. MemServe: Context Caching for Disaggregated LLM Serving with Elastic Memory Pool. arXiv preprint arXiv:2406.17565. https://arxiv.org/abs/2406.17565
-
[11]
Inferact. 2026. Codex SWE-bench Pro Agentic Serving Traces.https: //huggingface.co/datasets/Inferact/codex_swebenchpro_traces. Hug- ging Face Datasets
2026
- [12]
-
[13]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica
-
[14]
InProceedings of the 29th Symposium on Operating Systems Principles(Koblenz, Germany) (SOSP ’23)
vLLM: Efficient Memory Management for Large Language Model Serving with PagedAttention. InProceedings of the 29th Symposium on Operating Systems Principles (SOSP). ACM, 611–626. doi:10.1145/ 3600006.3613165
-
[15]
Lambda, RunPod, and BurnCloud. 2026. Cloud GPU On-Demand Hourly Pricing.https://lambda.ai/pricing;https://www.runpod.io/ gpu-models/rtx-a6000;https://www.autodl.com/. On-demand rates: NVIDIA H100 80 GB ∼$3/hr (Lambda, $2.99–3.29); RTX A6000 48 GB $0.49/hr (RunPod); H20 96 GB $1/hr (AutoDL, CNY 7.58≈ $1.05). Ac- cessed June 2026
2026
-
[16]
Bin Lin, Tao Peng, Chen Zhang, Minmin Sun, Lanbo Li, Hanyu Zhao, Wencong Xiao, Qi Xu, Xiafei Qiu, Shen Li, Zhigang Ji, Yong Li, and Wei Lin. 2024. Infinite-LLM: Efficient LLM Service for Long Con- text with DistAttention and Distributed KVCache. arXiv preprint arXiv:2401.02669.https://arxiv.org/abs/2401.02669
-
[17]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al
-
[18]
Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437. https://arxiv.org/abs/2412.19437
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Hao Liu, Matei Zaharia, and Pieter Abbeel. 2023. Ring attention with blockwise transformers for near-infinite context. arXiv preprint arXiv:2310.01889.https://arxiv.org/abs/2310.01889
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Xupeng Miao, Chunan Shi, Jiangfei Duan, Xiaoli Xi, Dahua Lin, Bin Cui, and Zhihao Jia. 2024. SpotServe: Serving Generative Large Language Models on Preemptible Instances. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS). ACM, 1112–1126. doi:10. 1145/3620665.3640411
-
[21]
Maxim Milakov and Natalia Gimelshein. 2018. Online normalizer calculation for softmax. arXiv preprint arXiv:1805.02867.https: //arxiv.org/abs/1805.02867
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[22]
NVIDIA. 2023. NCCL: NVIDIA Collective Communications Library. https://developer.nvidia.com/nccl. 13
2023
-
[23]
NVIDIA Corporation. 2024. NVSHMEM: NVIDIA OpenSHMEM Li- brary for GPU Clusters.https://developer.nvidia.com/nvshmem
2024
-
[24]
Charles Packer, Vivian Fang, Shishir_G Patil, Kevin Lin, Sarah Wooders, and Joseph_E Gonzalez. 2023. MemGPT: Towards LLMs as Operating Systems. arXiv preprint arXiv:2310.08560.https://arxiv.org/abs/2310. 08560Accessed: 2026-03-22
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. 2024. Splitwise: Efficient Generative LLM Inference Using Phase Splitting. InProceedings of the 51st Annual International Symposium on Computer Architecture. IEEE, Los Alamitos, CA, USA, 118–132. doi:10.1109/ISCA59077.2024.00019
-
[26]
Yifan Qiao, Trong Dao Le, Ao Shen, Zhewen Li, and Bowen Wang
-
[27]
https://vllm.ai/blog/2026-05-06-mooncake-store
Serving Agentic Workloads at Scale with vLLM × Mooncake. https://vllm.ai/blog/2026-05-06-mooncake-store. vLLM Blog
2026
-
[28]
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Heyi Tang, Feng Ren, Teng Ma, Shangming Cai, Yineng Zhang, Mingxing Zhang, et al. 2025. Mooncake: A KVCache-centric Disaggregated Architecture for LLM Serving. ACM Transactions on Storage, online first. doi:10.1145/ 3773772
2025
-
[29]
Pavel Shamis, Manjunath Gorentla Venkata, M. Graham Lopez, Matthew B. Baker, Oscar Hernandez, Yossi Iber, Jose L. Abellan, Aure- lien Bouteiller, George Bosilca, Jack Dongarra, et al. 2015. UCX: An Open Source Framework for HPC Network APIs and Beyond. InPro- ceedings of the 2015 IEEE 23rd Annual Symposium on High-Performance Interconnects. IEEE, Santa Cl...
-
[30]
Ying Sheng, Lianmin Zheng, Binhang Yuan, Zhuohan Li, Max Ryabinin, Beidi Chen, Percy Liang, Christopher Ré, Ion Stoica, and Ce Zhang
-
[31]
InProceedings of the 40th Interna- tional Conference on Machine Learning (ICML)
FlexGen: High-Throughput Generative Inference of Large Lan- guage Models with a Single GPU. InProceedings of the 40th Interna- tional Conference on Machine Learning (ICML). 31094–31116
-
[32]
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. 2019. Megatron-lm: Training multi- billion parameter language models using model parallelism. arXiv preprint arXiv:1909.08053.https://arxiv.org/abs/1909.08053
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[33]
Yuxin Wang, Yuhan Chen, Zeyu Li, Xueze Kang, Yuchu Fang, Yeju Zhou, Yang Zheng, Zhenheng Tang, Xin He, Rui Guo, et al . 2025. Burstgpt: A real-world workload dataset to optimize llm serving sys- tems. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 5831–5841
2025
-
[34]
Samuel Williams, Andrew Waterman, and David Patterson. 2009. Roofline: An insightful visual performance model for multicore archi- tectures.Commun. ACM52, 4 (2009), 65–76
2009
-
[35]
Bingyang Wu, Shengyu Liu, Yinmin Zhong, Peng Sun, Xuanzhe Liu, and Xin Jin. 2024. LoongServe: Efficiently Serving Long-Context Large Language Models with Elastic Sequence Parallelism. InProceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles. Association for Computing Machinery, New York, NY, USA, 640–654. doi:10.1145/3694715.3695948
-
[36]
Haoran Wu, Can Xiao, Jiayi Nie, Xuan Guo, Binglei Lou, Jeffrey T. H. Wong, Zhiwen Mo, Cheng Zhang, Przemyslaw Forys, Wayne Luk, Hongxiang Fan, Jianyi Cheng, Timothy M. Jones, Rika Antonova, Robert Mullins, and Aaron Zhao. 2025. Combating the Memory Walls: Optimization Pathways for Long-Context Agentic LLM Inference. arXiv preprint arXiv:2509.09505.https:/...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Yongtong Wu, Shaoyuan Chen, Yinmin Zhong, Rilin Huang, Yixuan Tan, Wentao Zhang, Liyue Zhang, Shangyan Zhou, Yuxuan Liu, Shun- feng Zhou, Mingxing Zhang, Xin Jin, and Panpan Huang. 2026. Du- alPath: Breaking the Storage Bandwidth Bottleneck in Agentic LLM Inference.arXiv preprint arXiv:2602.21548(2026)
-
[38]
Amy Yang, Jingyi Yang, Aya Ibrahim, Xinfeng Xie, Bangsheng Tang, Grigory Sizov, Jeremy Reizenstein, Jongsoo Park, and Jianyu Huang
- [39]
-
[40]
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. 2022. Orca: A Distributed Serving System for Transformer-Based Generative Models. InProceedings of the 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI). USENIX Association, 521–538
2022
- [41]
-
[42]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Jeff Huang, Chuyue Sun, Cody Hao Yu, Shiyi Cao, Christos Kober, Liang Shi, Ziniu Wu, et al
-
[43]
InAdvances in Neural Information Processing Systems (NeurIPS)
SGLang: Efficient Execution of Structured Language Model Pro- grams. InAdvances in Neural Information Processing Systems (NeurIPS)
-
[44]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xu- anzhe Liu, Xin Jin, and Hao Zhang. 2024. {DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 193–210
2024
- [45]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.