Scaling Self-Evolving Agents via Parametric Memory
Pith reviewed 2026-06-28 06:42 UTC · model grok-4.3
The pith
LLM agents absorb distilled supervision into fast LoRA weights to alter their policy within a single episode.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
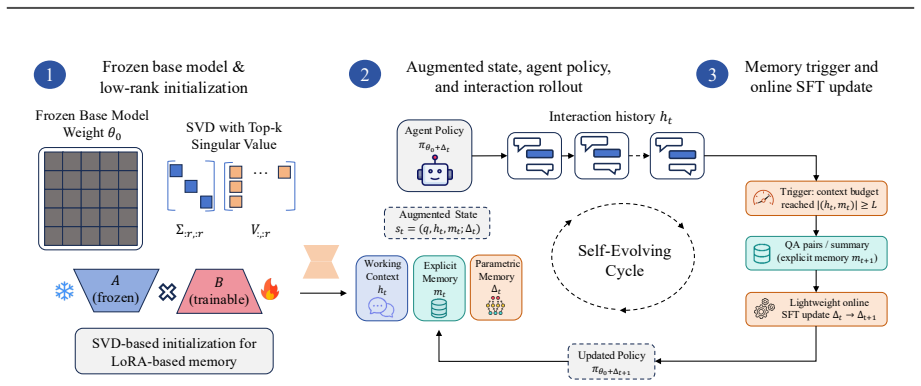
We introduce TMEM, a self-evolving parametric memory framework in which the agent not only compresses history into explicit memory but also absorbs distilled supervision into fast LoRA weights Δ_t via lightweight online updates, genuinely altering its future behavior within a single episode. We formalize this as an agentic decision process with fast-weight rollout dynamics: actions are sampled from π_{θ0+Δ_t}, while extraction actions produce supervision that updates Δ_t for subsequent decisions. This view makes the extraction policy directly optimizable by RL: training θ0 improves not only task actions but also the quality of the data used for online LoRA adaptation. We further propose SVD-
What carries the argument
Fast-weight rollout dynamics in which the policy π_{θ0+Δ_t} is updated online by LoRA from supervision produced by extraction actions during the same episode.
If this is right
- Training the base model θ0 simultaneously improves both direct task actions and the quality of supervision data used for online adaptation.
- SVD-based initialization of the LoRA subspace accelerates convergence of the online updates.
- The extraction policy becomes directly optimizable by reinforcement learning because it affects future decisions through the updated weights.
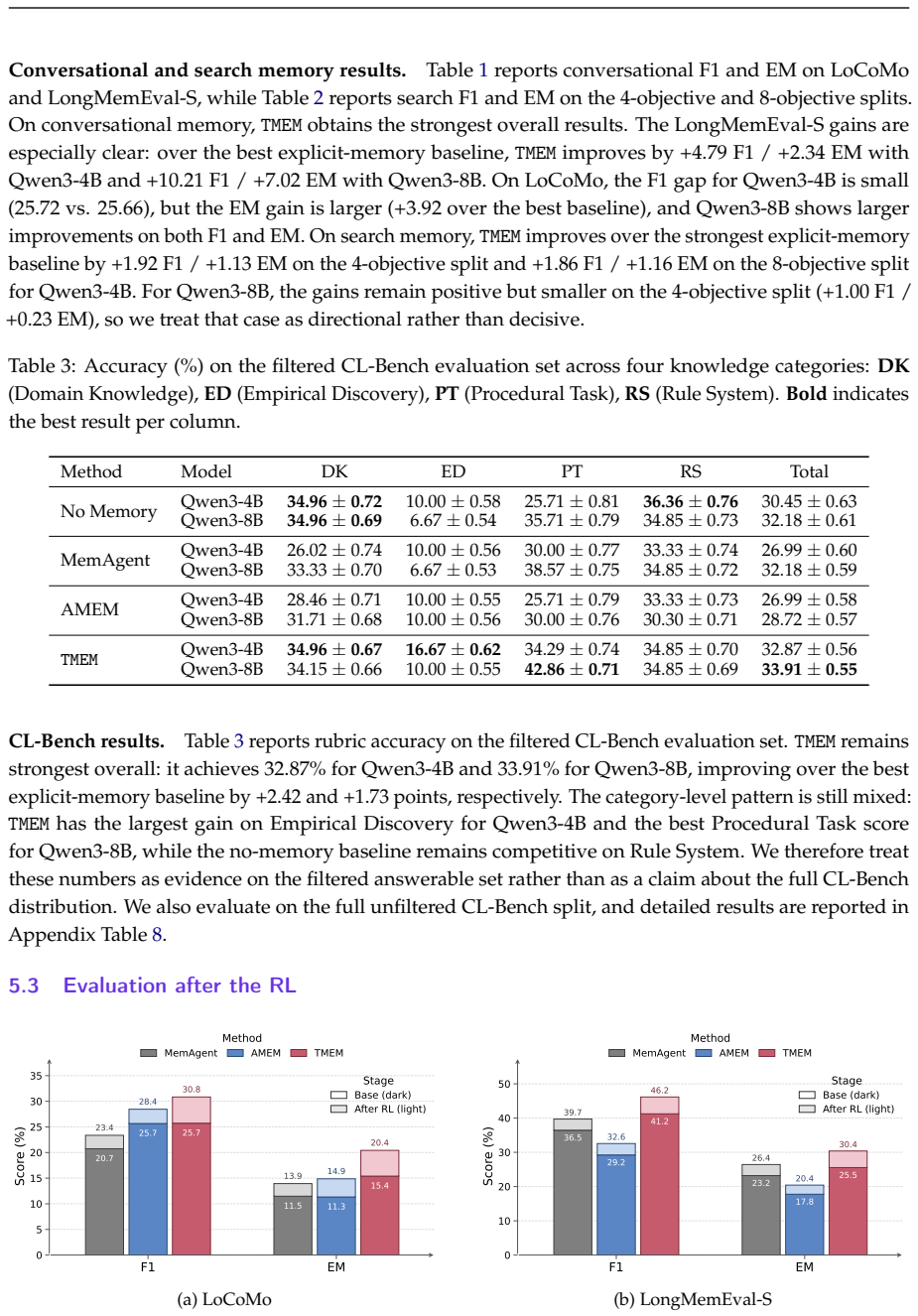
- TMEM outperforms summary-based and retrieval-based memory baselines on LoCoMo, LongMemEval-S, multi-objective search, and CL-Bench across model scales.
Where Pith is reading between the lines
- Agents could maintain performance over much longer interactions by evolving their weights instead of relying on ever-larger context windows.
- The same online-update loop could be shared among multiple agents so that one agent's extracted supervision improves the policy available to others.
- Deployed agents might require fewer full offline fine-tuning cycles if they can keep improving through lightweight parametric memory during use.
Load-bearing premise
Lightweight online LoRA updates from extracted supervision remain stable and beneficial across an episode without introducing instability or degrading performance on the primary task.
What would settle it
A controlled rollout in which online LoRA updates are applied and the agent's success rate on the main task falls below the frozen-parameter baseline after a few extraction steps would show the updates are not beneficial.
Figures


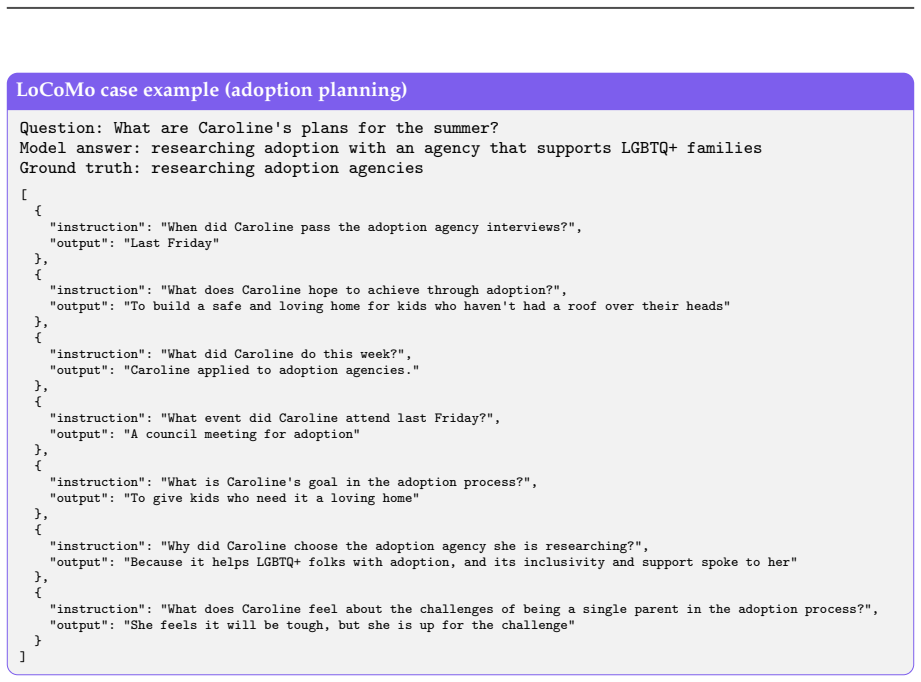


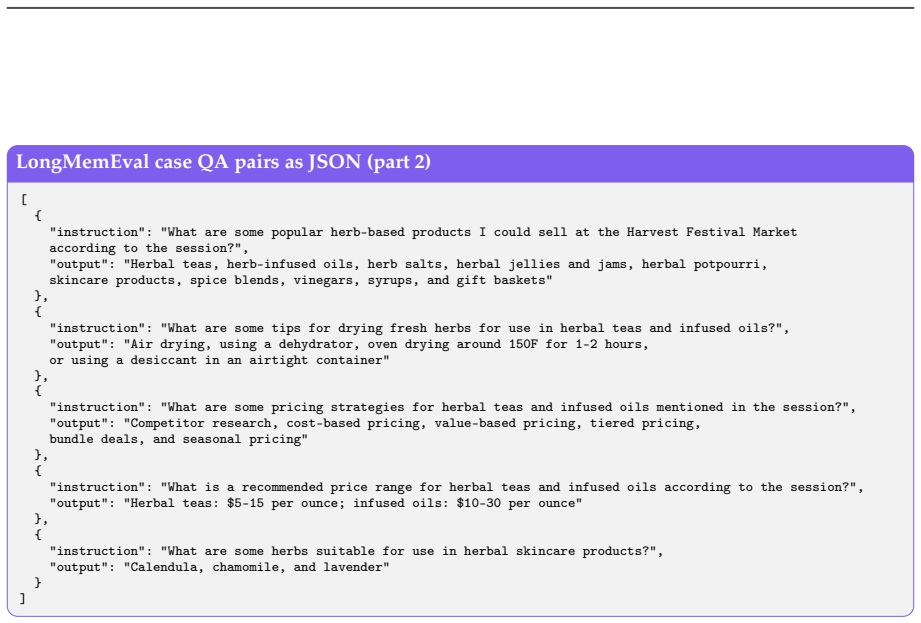



read the original abstract
Existing memory-augmented LLM agents store past experience exclusively in prompt space, as textual summaries or retrieved passages, while keeping model parameters frozen throughout a rollout. Such agents can \emph{look up} what they have seen but cannot \emph{learn from} it: their policy is unchanged by experience, and any information dropped from the context is permanently lost. We introduce \texttt{TMEM}, a self-evolving parametric memory framework in which the agent not only compresses history into explicit memory but also absorbs distilled supervision into fast LoRA weights $\Delta_t$ via lightweight online updates, genuinely altering its future behavior within a single episode. We formalize this as an agentic decision process with fast-weight rollout dynamics: actions are sampled from $\pi_{\theta_0+\Delta_t}$, while extraction actions produce supervision that updates $\Delta_t$ for subsequent decisions. This view makes the extraction policy directly optimizable by RL: training $\theta_0$ improves not only task actions but also the quality of the data used for online LoRA adaptation. We further propose SVD-based initialization of the LoRA subspace to accelerate online convergence. Experiments on LoCoMo, LongMemEval-S, multi-objective search, and CL-Bench show that \texttt{TMEM} consistently outperforms summary-based and retrieval-based baselines across different model scales.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TMEM, a self-evolving parametric memory framework for LLM agents. Unlike prior memory-augmented agents that store experience only as textual summaries or retrieved passages with frozen parameters, TMEM compresses history into explicit memory while also distilling supervision into fast LoRA weights Δ_t via lightweight online updates. This alters the policy π_θ0+Δt within a single episode. The approach is formalized as an agentic decision process with fast-weight rollout dynamics, where extraction actions produce supervision for online adaptation; the extraction policy is trained via RL. SVD-based LoRA initialization is proposed to speed convergence. Experiments on LoCoMo, LongMemEval-S, multi-objective search, and CL-Bench report consistent outperformance over summary- and retrieval-based baselines across model scales.
Significance. If the online LoRA adaptation is shown to be stable and beneficial, the result would be significant: it provides a mechanism for agents to genuinely learn from experience inside an episode rather than merely retrieving prior context, with the RL training of the extraction policy directly optimizing the quality of adaptation data. The SVD initialization and formalization as fast-weight dynamics are concrete technical contributions that could be adopted more broadly.
major comments (2)
- [abstract and formalization of agentic decision process] The central claim that online LoRA updates 'genuinely alter' future behavior within one episode (abstract) is load-bearing but rests on an unverified assumption. The formalization of the agentic decision process with fast-weight rollout dynamics provides no analysis of update magnitude, interference between Δ_t and θ0, or primary-task performance trajectory during rollout; without per-episode validation or regularization beyond SVD initialization, it is possible that repeated updates degrade the original task objective or introduce compounding instability.
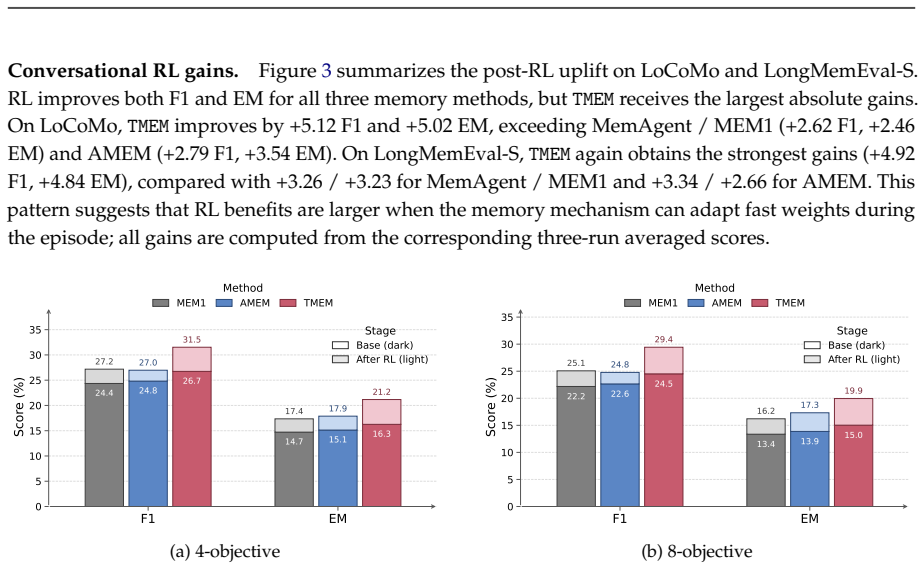
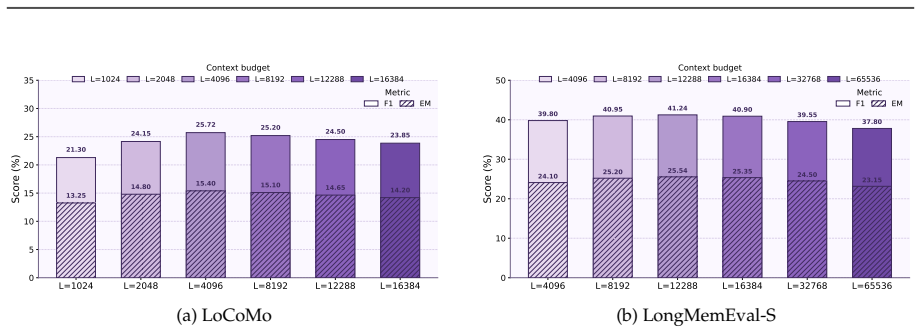
- [experiments] Experiments section reports outperformance on LoCoMo, LongMemEval-S, multi-objective search, and CL-Bench, but does not include ablations or diagnostics that would confirm the online updates are the source of gains rather than the explicit memory component alone. Task-performance curves over episode length or measurements of ||Δ_t|| would directly test the stability assumption.
minor comments (2)
- [formalization] Notation for the policy π_θ0+Δt and the timing of updates (Δ_t) should be defined more explicitly in the formalization to avoid ambiguity about when adaptation occurs relative to action sampling.
- [abstract] The abstract states that training θ0 improves both task actions and the quality of data for online adaptation; this interaction could be clarified with a short diagram or pseudocode.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, providing the strongest honest defense of the manuscript while noting where additional material will be incorporated in revision.
read point-by-point responses
-
Referee: [abstract and formalization of agentic decision process] The central claim that online LoRA updates 'genuinely alter' future behavior within one episode (abstract) is load-bearing but rests on an unverified assumption. The formalization of the agentic decision process with fast-weight rollout dynamics provides no analysis of update magnitude, interference between Δ_t and θ0, or primary-task performance trajectory during rollout; without per-episode validation or regularization beyond SVD initialization, it is possible that repeated updates degrade the original task objective or introduce compounding instability.
Authors: The formalization defines actions from π_{θ0+Δ_t} with extraction actions supplying supervision for Δ_t updates, and the empirical gains over frozen-parameter baselines provide supporting evidence that behavior changes. However, we agree that direct diagnostics of update magnitude and trajectory would strengthen the claim. In revision we will add per-episode ||Δ_t|| norms and primary-task performance curves to the experiments section. revision: yes
-
Referee: [experiments] Experiments section reports outperformance on LoCoMo, LongMemEval-S, multi-objective search, and CL-Bench, but does not include ablations or diagnostics that would confirm the online updates are the source of gains rather than the explicit memory component alone. Task-performance curves over episode length or measurements of ||Δ_t|| would directly test the stability assumption.
Authors: The reported baselines already isolate the parametric component: both summary-based and retrieval-based agents maintain explicit memory but keep parameters frozen, so the consistent gains are attributable to the online LoRA updates. That said, we acknowledge the value of the requested ablations and will add an explicit ablation removing online adaptation, together with the suggested performance curves and ||Δ_t|| measurements, in the revised manuscript. revision: yes
Circularity Check
No significant circularity detected; derivation is self-contained.
full rationale
The paper defines TMEM as a parametric memory framework using online LoRA updates Δ_t to alter policy behavior within an episode, formalizes the agentic process with extraction actions feeding supervision, proposes SVD initialization, and validates via RL training of θ_0 plus empirical comparisons on LoCoMo, LongMemEval-S, and other benchmarks. No equation or claim reduces a result to a fitted quantity defined by the same mechanism, no self-citation chain is invoked for uniqueness or load-bearing premises, and the central improvement is presented as an empirical outcome rather than a definitional tautology. The framework and its optimization are independent of the reported performance numbers.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Memory Depth, Not Memory Access: Selective Parametric Consolidation for Long-Running Language Agents
EVAF, a surprise- and valence-gated LoRA mechanism, provides memory depth for goal persistence in language agents via the loop-drift protocol, complementary to retrieval.
Reference graph
Works this paper leans on
-
[1]
Self-improving llm agents at test-time.arXiv preprint arXiv:2510.07841,
Emre Can Acikgoz, Cheng Qian, Heng Ji, Dilek Hakkani-Tür, and Gokhan Tur. Self-improving llm agents at test-time.arXiv preprint arXiv:2510.07841,
-
[2]
Doc-to-lora: Learning to instantly internalize contexts.arXiv preprint arXiv:2602.15902,
Rujikorn Charakorn, Edoardo Cetin, Shinnosuke Uesaka, and Robert Tjarko Lange. Doc-to-lora: Learning to instantly internalize contexts.arXiv preprint arXiv:2602.15902,
-
[3]
Xiaoyin Chen, Canwen Xu, Yite Wang, Boyi Liu, Zhewei Yao, and Yuxiong He. Learning to self-evolve. arXiv preprint arXiv:2603.18620,
-
[4]
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413,
-
[5]
Test-time learning for large language models.arXiv preprint arXiv:2505.20633,
Jinwu Hu, Zhitian Zhang, Guohao Chen, Xutao Wen, Chao Shuai, Wei Luo, Bin Xiao, Yuanqing Li, and Mingkui Tan. Test-time learning for large language models.arXiv preprint arXiv:2505.20633,
-
[6]
Guanghao Li, Wenhao Jiang, Mingfeng Chen, Yan Li, Hao Yu, Shuting Dong, Tao Ren, Ming Tang, and Chun Yuan. Scout: Teaching pre-trained language models to enhance reasoning via flow chain-of- thought.Advances in Neural Information Processing Systems, 38:95340–95364, 2026a. Zehao Li, Tao Ren, Zishi Zhang, Xi Chen, and Yijie Peng. Optimal low-rank stochastic...
-
[7]
Jiafeng Liang, Zhihao Zhu, Zihan Zhang, Baoqi Ren, Shixin Jiang, Runxuan Liu, Tao Ren, Ming Liu, See-Kiong Ng, and Bing Qin. Perception without engagement: Dissecting the causal discovery deficit in lmms.arXiv preprint arXiv:2605.09422,
-
[8]
Zichuan Lin, Feiyu Liu, Yijun Yang, Jiafei Lyu, Yiming Gao, Yicheng Liu, Zhicong Lu, Yangbin Yu, Mingyu Yang, Junyou Li, Deheng Ye, and Jie Jiang. Ui-voyager: A self-evolving gui agent learning via failed experience.arXiv preprint arXiv:2603.24533,
-
[9]
Miao Lu, Weiwei Sun, Weihua Du, Zhan Ling, Xuesong Yao, Kang Liu, and Jiecao Chen. Scaling llm multi- turn rl with end-to-end summarization-based context management.arXiv preprint arXiv:2510.06727,
-
[10]
Zhiwei Luo et al. Cl-bench: Evaluating continual learning capabilities of language model agents.arXiv preprint arXiv:2504.18978,
-
[11]
Memgpt: towards llms as operating systems.arXiv preprint arXiv:2310.08560,
Charles Packer, Vivian Fang, Shishir_G Patil, Kevin Lin, Sarah Wooders, and Joseph_E Gonzalez. Memgpt: towards llms as operating systems.arXiv preprint arXiv:2310.08560,
-
[12]
Tao Ren, Jinyang Jiang, Hui Yang, Wan Tian, Minhao Zou, Guanghao Li, Zishi Zhang, Qinghao Wang, Siyuan Qin, Yuxiang Zhao, and Rui Tao. Riskpo: Risk-based policy optimization via verifiable reward for llm post-training.arXiv preprint arXiv:2510.00911, 2025a. Tao Ren, Zishi Zhang, Jinyang Jiang, Guanghao Li, Zeliang Zhang, Mingqian Feng, and Yijie Peng. Flo...
arXiv 2025
-
[13]
Scaling long-horizon LLM agent via context-folding.arXiv preprint arXiv:2510.11967,
Weiwei Sun, Miao Lu, Zhan Ling, Kang Liu, Xuesong Yao, Yiming Yang, and Jiecao Chen. Scaling long-horizon LLM agent via context-folding.arXiv preprint arXiv:2510.11967,
-
[14]
End-to-end test-time training for long context.arXiv preprint arXiv:2512.23675,
Arnuv Tandon, Karan Dalal, Xinhao Li, Daniel Koceja, Marcel Rød, Sam Buchanan, Xiaolong Wang, Jure Leskovec, Sanmi Koyejo, Tatsunori Hashimoto, Carlos Guestrin, Jed McCaleb, Yejin Choi, and Yu Sun. End-to-end test-time training for long context.arXiv preprint arXiv:2512.23675,
-
[15]
Infmem: Learning system-2 memory control for long-context agent.arXiv preprint arXiv:2602.02704,
Xinyu Wang, Mingze Li, Peng Lu, Xiao-Wen Chang, Lifeng Shang, Jinping Li, Fei Mi, Prasanna Parthasarathi, and Yufei Cui. Infmem: Learning system-2 memory control for long-context agent.arXiv preprint arXiv:2602.02704,
-
[16]
Di Wu et al. Longmemeval: Benchmarking chat assistants on long-term interactive memory.arXiv preprint arXiv:2410.10813,
-
[17]
15 Sikuan Yan, Xiufeng Yang, Zuchao Huang, Ercong Nie, Zifeng Ding, Zonggen Li, Xiaowen Ma, Jinhe Bi, Kristian Kersting, Jeff Z Pan, et al. Memory-r1: Enhancing large language model agents to manage and utilize memories via reinforcement learning.arXiv preprint arXiv:2508.19828,
-
[18]
Chengyuan Yang, Zequn Sun, Wei Wei, and Wei Hu. Beyond static summarization: Proactive memory extraction for llm agents.arXiv preprint arXiv:2601.04463, 2026a. Hui Yang, Tao Ren, Jinyang Jiang, Wan Tian, and Yijie Peng. Omni-masked gradient descent: Memory- efficient optimization via mask traversal with improved convergence.arXiv preprint arXiv:2603.05960...
-
[19]
Hongli Yu, Tinghong Chen, Jiangtao Feng, Jiangjie Chen, Weinan Dai, Qiying Yu, Ya-Qin Zhang, Wei-Ying Ma, Jingjing Liu, Mingxuan Wang, et al. Memagent: Reshaping long-context llm with multi-conv rl-based memory agent.arXiv preprint arXiv:2507.02259,
-
[20]
Test-time training done right.arXiv preprint arXiv:2505.23884,
Tianyuan Zhang, Sai Bi, Yicong Hong, Kai Zhang, Fujun Luan, Songlin Yang, Kalyan Sunkavalli, William T Freeman, and Hao Tan. Test-time training done right.arXiv preprint arXiv:2505.23884,
-
[21]
doi: 10.1609/aaai.v38i17.29936. Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. Memorybank: Enhancing large language models with long-term memory. InProceedings of the AAAI conference on artificial intelligence, volume 38, pp. 19724–19731,
-
[22]
Recurrentgpt: Interactive generation of (arbitrarily) long text.arXiv preprint arXiv:2305.13304,
Wangchunshu Zhou, Yuchen Eleanor Jiang, Peng Cui, Tiannan Wang, Zhenxin Xiao, Yifan Hou, Ryan Cotterell, and Mrinmaya Sachan. Recurrentgpt: Interactive generation of (arbitrarily) long text.arXiv preprint arXiv:2305.13304,
-
[23]
Zijian Zhou, Ao Qu, Zhaoxuan Wu, Sunghwan Kim, Alok Prakash, Daniela Rus, Jinhua Zhao, Bryan Kian Hsiang Low, and Paul Pu Liang. Mem1: Learning to synergize memory and reasoning for efficient long-horizon agents.arXiv preprint arXiv:2506.15841,
-
[24]
Define thespectral alignment coefficient ρr(∆∗,W) = ∥∆∗Vr∥2 F ∥∆∗∥2 F ∈[0, 1], which measures the fraction of energy of∆ ∗ that falls into the top-rright singular subspace ofW
Under the LoRA parameterization ∆=BA with a fixed projection A∈R r×din (rank(A) =r) and a learnable coefficient matrixB∈R dout×r, the best achievable approximation error is E(A) =min B∈Rdout×r ∥∆∗ −BA∥ 2 F. Define thespectral alignment coefficient ρr(∆∗,W) = ∥∆∗Vr∥2 F ∥∆∗∥2 F ∈[0, 1], which measures the fraction of energy of∆ ∗ that falls into the top-rri...
2021
-
[25]
Romeo & Juliet\
Question: What color clothing do people of the Netherlands wear during Oranjegekte or to celebrate the national holiday Koningsdag?; What was the name of the 1996 loose adaptation of William Shakespeare's \"Romeo & Juliet\" written by James Gunn?; What American professional Hawaiian surfer born 18 October 1992 won the Rip Curl Pro Portugal?; What national...
1996
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.