Lite Any Stereo V2: Faster and Stronger Efficient Zero-Shot Stereo Matching
Pith reviewed 2026-06-26 00:23 UTC · model grok-4.3
The pith
Lite Any Stereo V2 demonstrates that efficient stereo models can exceed the zero-shot accuracy of larger iterative methods while running substantially faster.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
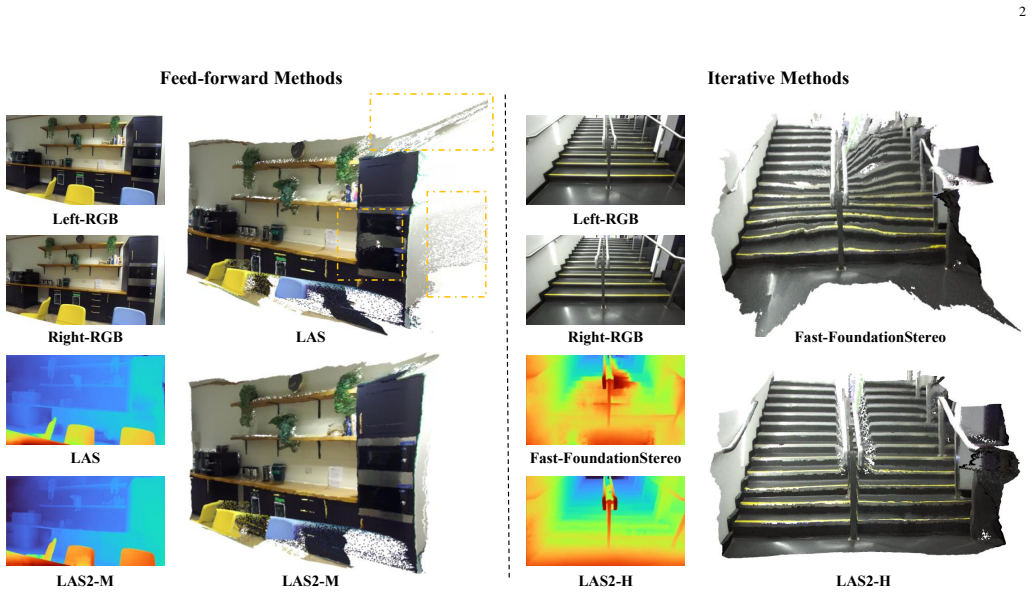
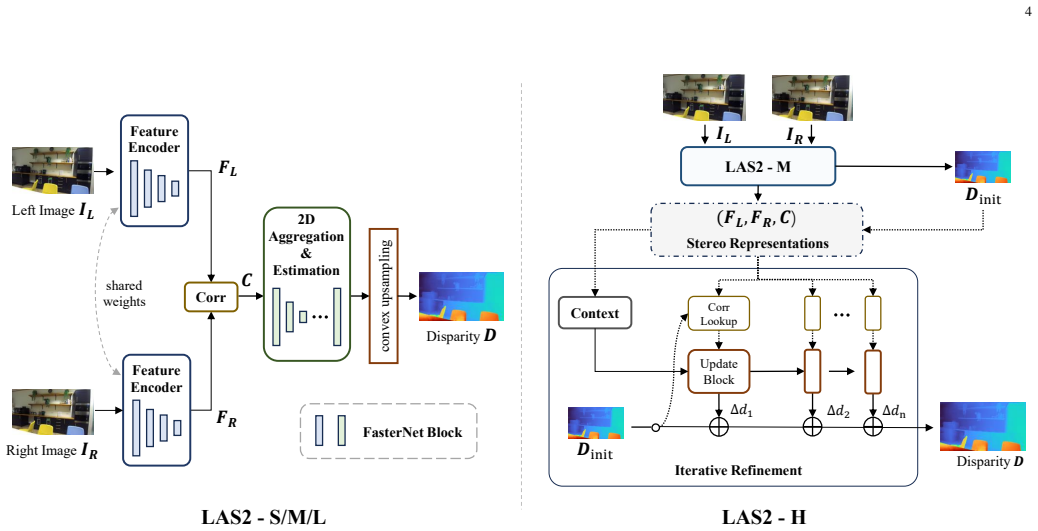
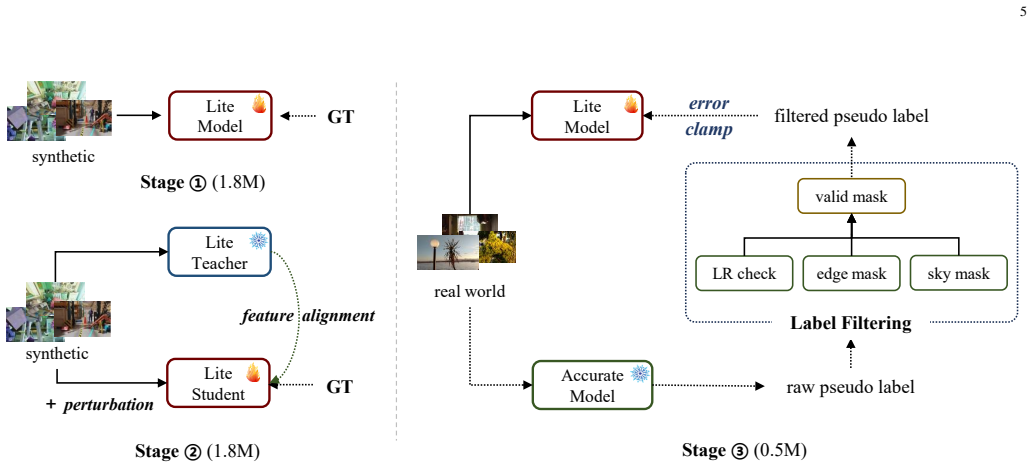
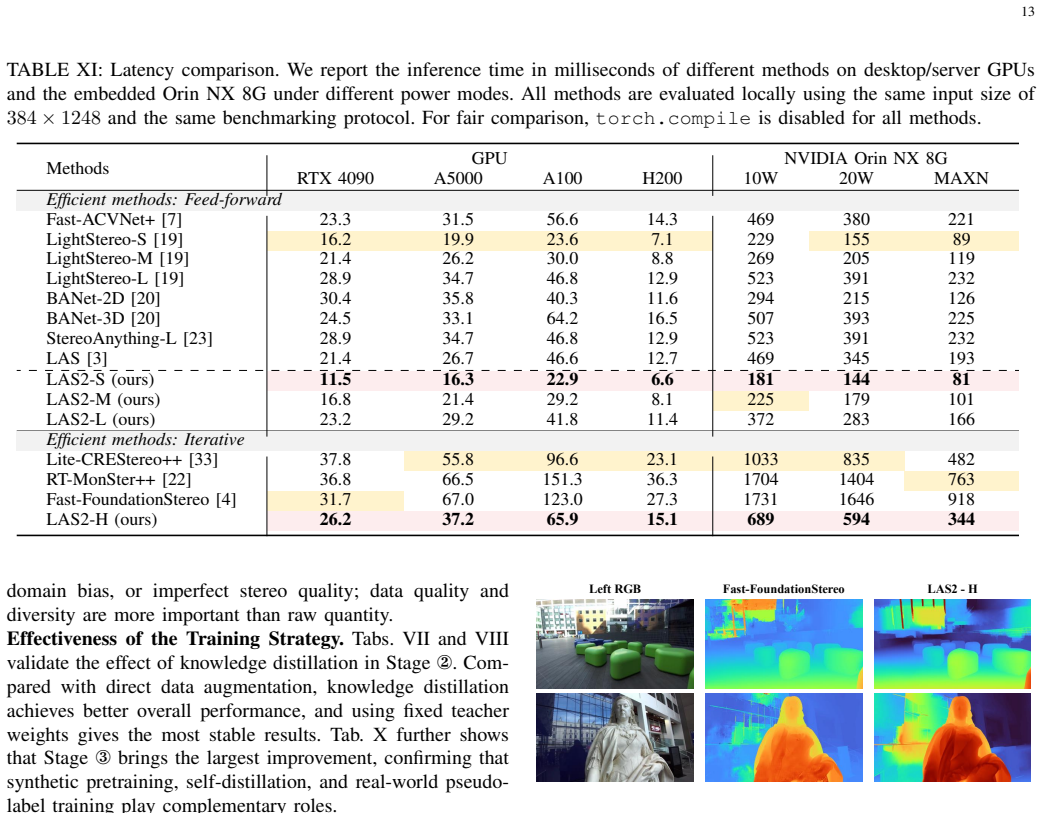
LAS2 revisits efficient stereo design with a 2D-only cost aggregation framework optimized for actual inference latency and applies a three-stage training strategy that combines synthetic supervision, self-distillation, and real-world knowledge distillation. Pseudo-label filtering and an error-clamping operation are added to improve the reliability of the real-world pseudo supervision. This produces a model family whose feed-forward and iterative variants reach state-of-the-art accuracy among efficient stereo methods while maintaining significantly lower latency, with the largest variant delivering stronger overall zero-shot performance than the iterative Fast-FoundationStereo at 1.8x and 2.7
What carries the argument
The 2D-only cost aggregation framework paired with a three-stage training strategy of synthetic supervision, self-distillation, and real-world knowledge distillation that uses pseudo-label filtering and error-clamping.
If this is right
- Efficient stereo models become viable for deployment on resource-constrained platforms without the accuracy penalty previously assumed.
- Zero-shot generalization in stereo matching can be improved through careful training progression rather than model scale alone.
- Trade-offs between speed and accuracy can be managed within a single model family for different hardware budgets.
- Real-world pseudo supervision can be made more stable by adding filtering and clamping steps during distillation.
Where Pith is reading between the lines
- Similar staged training with filtering may improve zero-shot transfer in related dense prediction tasks such as optical flow.
- Lower reliance on large foundation models could reduce overall training and inference energy costs for stereo applications.
- The latency-focused architecture choices may inform efficient designs for other real-time vision systems on edge hardware.
Load-bearing premise
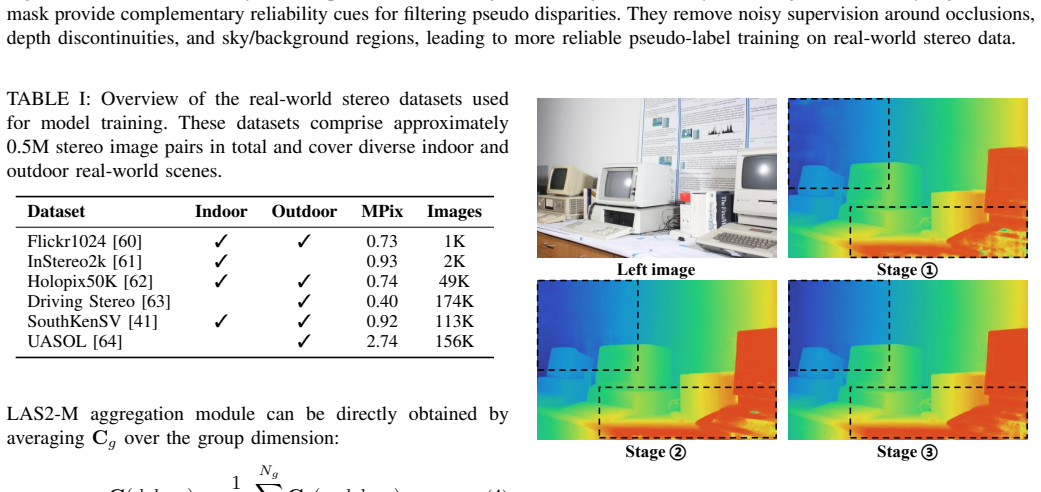
The three-stage training strategy with pseudo-label filtering and error-clamping produces reliable synthetic-to-real transfer without hidden biases or performance drops on unseen real scenes.
What would settle it
Run LAS2-H and Fast-FoundationStereo on a new, previously unseen real-world stereo dataset and measure whether LAS2-H still shows higher overall zero-shot accuracy.
Figures


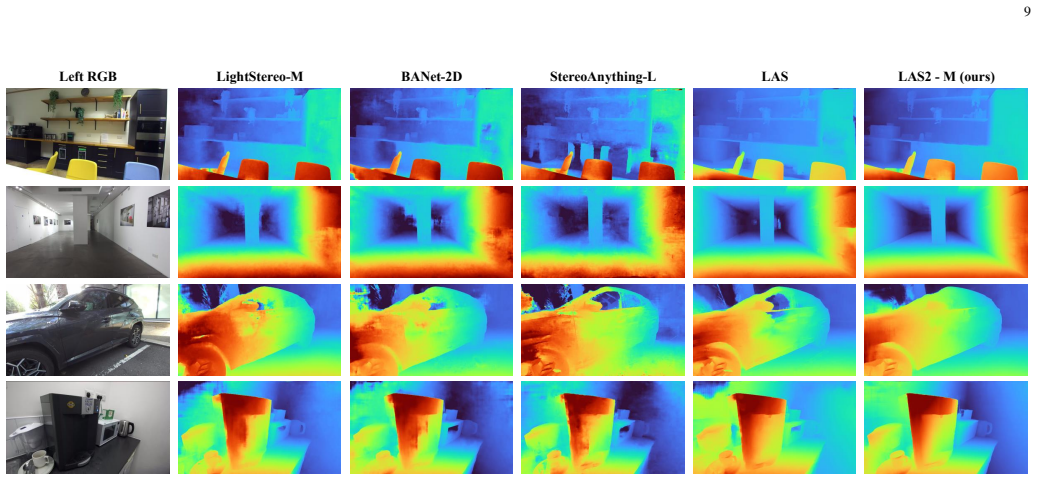
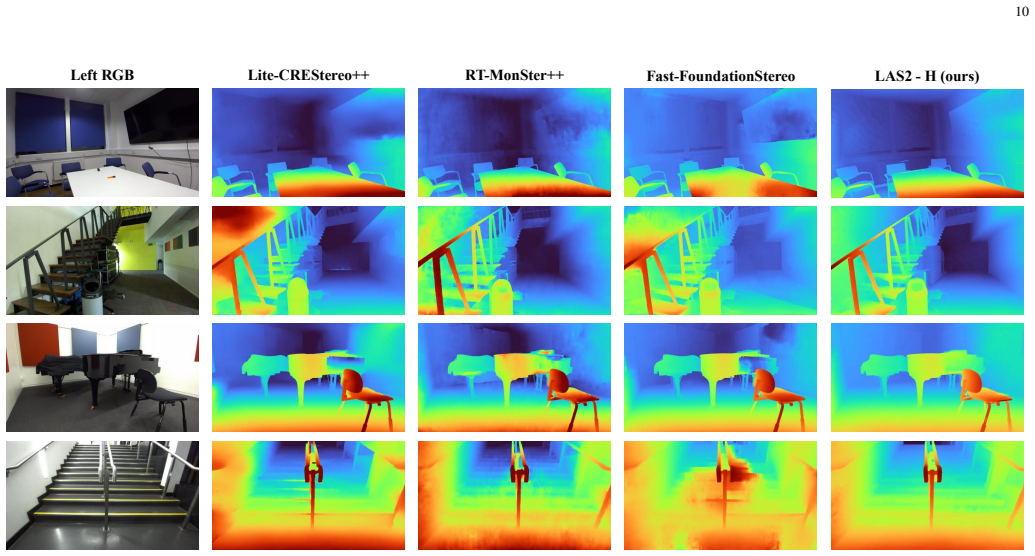
read the original abstract
Recent advances in stereo matching have achieved remarkable accuracy, but often rely on large models, heavy computation, or additional foundation-model priors, making them difficult to deploy on resource-constrained platforms. In contrast, efficient stereo models offer faster inference but are commonly considered less capable of strong zero-shot generalization. In this paper, we challenge this assumption by introducing Lite Any Stereo V2 (LAS2), an ultra-fast model series designed for efficient zero-shot stereo matching. LAS2 is developed from both architecture and training perspectives. Architecturally, we revisit efficient stereo design under practical deployment settings and propose a 2D-only cost aggregation framework, optimized for real inference latency rather than theoretical MACs alone. For training, we develop a three-stage strategy that combines synthetic supervision, self-distillation, and real-world knowledge distillation. To improve the reliability of real-world pseudo supervision, we further introduce pseudo-label filtering and an error-clamping operation, enabling smoother synthetic-to-real transfer. We instantiate LAS2 as a family of models, including feed-forward variants for different efficiency budgets and an iterative variant for higher accuracy. Extensive experiments show that LAS2 achieves state-of-the-art accuracy among efficient stereo methods while maintaining significantly lower latency. Specifically, LAS2-H achieves stronger overall zero-shot performance than the iterative method Fast-FoundationStereo, with 1.8x and 2.7x faster inference on H200 and Orin, respectively. The project page, demos, and code are available at https://tomtomtommi.github.io/LiteAnyStereoV2/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Lite Any Stereo V2 (LAS2), a family of efficient models for zero-shot stereo matching. Architecturally, it proposes a 2D-only cost aggregation framework optimized for real inference latency. Training uses a three-stage strategy of synthetic supervision, self-distillation, and real-world knowledge distillation, augmented by pseudo-label filtering and error-clamping to improve synthetic-to-real transfer. Experiments claim LAS2 achieves SOTA accuracy among efficient stereo methods, with the LAS2-H variant outperforming the iterative Fast-FoundationStereo in overall zero-shot performance while delivering 1.8x faster inference on H200 and 2.7x on Orin hardware.
Significance. If the empirical claims hold, the work would be significant for demonstrating that lightweight stereo models can achieve strong zero-shot generalization through targeted training rather than scale or foundation-model priors, with direct relevance to deployment on resource-constrained platforms. The explicit description of the three-stage pipeline, hardware-specific latency results, and code release are positive factors supporting reproducibility and verification.
minor comments (2)
- [Abstract] Abstract: the claim of 'stronger overall zero-shot performance' than Fast-FoundationStereo would benefit from a brief parenthetical listing of the primary zero-shot benchmarks (e.g., KITTI, Middlebury) on which the comparison is made.
- The manuscript would be strengthened by an explicit statement of the number of runs or error bars for the reported latency and accuracy numbers, even if only in a footnote or appendix.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation for minor revision. No major comments were raised in the report.
Circularity Check
No significant circularity identified
full rationale
The paper's derivation consists of an architectural proposal (2D-only cost aggregation optimized for real latency) and an empirical training pipeline (three-stage synthetic supervision + self-distillation + real-world KD with filtering and clamping). All load-bearing claims are measured outcomes on standard zero-shot benchmarks and hardware-specific runtimes, not quantities that reduce to the inputs by definition or by self-citation. No equations or steps equate a claimed prediction to a fitted parameter, and external verification via code release and public datasets keeps the argument self-contained.
Axiom & Free-Parameter Ledger
free parameters (2)
- model architecture hyperparameters
- pseudo-label filtering thresholds
axioms (2)
- domain assumption Synthetic stereo data provides useful initial supervision for real-world generalization
- domain assumption Self-distillation and knowledge distillation improve zero-shot performance when combined with filtering
Reference graph
Works this paper leans on
-
[1]
Cooperative computation of stereo disparity,
D. Marr and T. Poggio, “Cooperative computation of stereo disparity,” inNeurocomputing: foundations of research, 1988, pp. 259–267
1988
-
[2]
Continuous 3d label stereo matching using local expansion moves,
T. Taniai, Y . Matsushita, Y . Sato, and T. Naemura, “Continuous 3d label stereo matching using local expansion moves,”IEEE TPAMI, vol. 40, no. 11, pp. 2725–2739, 2017
2017
-
[3]
Lite any stereo: Efficient zero-shot stereo matching,
J. Jing, W. Luo, Y . Mao, and K. Mikolajczyk, “Lite any stereo: Efficient zero-shot stereo matching,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2026, pp. 21 725–21 735
2026
-
[4]
Fast-FoundationStereo: Real-time zero-shot stereo matching,
B. Wen, S. Dewan, and S. Birchfield, “Fast-FoundationStereo: Real-time zero-shot stereo matching,”CVPR, 2026
2026
-
[5]
Raft-stereo: Multilevel recurrent field transforms for stereo matching,
L. Lipson, Z. Teed, and J. Deng, “Raft-stereo: Multilevel recurrent field transforms for stereo matching,”arXiv preprint arXiv:2109.07547, 2021
arXiv 2021
-
[6]
Practical stereo matching via cascaded recurrent network with adaptive correlation,
J. Li, P. Wang, P. Xiong, T. Cai, Z. Yan, L. Yang, J. Liu, H. Fan, and S. Liu, “Practical stereo matching via cascaded recurrent network with adaptive correlation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 16 263–16 272
2022
-
[7]
Accurate and efficient stereo matching via attention concatenation volume,
G. Xu, Y . Wang, J. Cheng, J. Tang, and X. Yang, “Accurate and efficient stereo matching via attention concatenation volume,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023
2023
-
[8]
Selective-stereo: Adaptive frequency information selection for stereo matching,
X. Wang, G. Xu, H. Jia, and X. Yang, “Selective-stereo: Adaptive frequency information selection for stereo matching,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 19 701–19 710
2024
-
[9]
A taxonomy and evaluation of dense two-frame stereo correspondence algorithms,
D. Scharstein and R. Szeliski, “A taxonomy and evaluation of dense two-frame stereo correspondence algorithms,”IJCV, vol. 47, no. 1, pp. 7–42, 2002
2002
-
[10]
A multi-view stereo benchmark with high- resolution images and multi-camera videos,
T. Schops, J. L. Schonberger, S. Galliani, T. Sattler, K. Schindler, M. Pollefeys, and A. Geiger, “A multi-view stereo benchmark with high- resolution images and multi-camera videos,” inCVPR, 2017, pp. 3260– 3269
2017
-
[11]
Are we ready for autonomous driving? the kitti vision benchmark suite,
A. Geiger, P. Lenz, and R. Urtasun, “Are we ready for autonomous driving? the kitti vision benchmark suite,” inCVPR, 2012, pp. 3354– 3361
2012
-
[12]
Object scene flow for autonomous vehicles,
M. Menze and A. Geiger, “Object scene flow for autonomous vehicles,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2015
2015
-
[13]
Depth anything: Unleashing the power of large-scale unlabeled data,
L. Yang, B. Kang, Z. Huang, X. Xu, J. Feng, and H. Zhao, “Depth anything: Unleashing the power of large-scale unlabeled data,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 10 371–10 381
2024
-
[14]
L. Yang, B. Kang, Z. Huang, Z. Zhao, X. Xu, J. Feng, and H. Zhao, “Depth anything v2,”arXiv preprint arXiv:2406.09414, 2024
Pith/arXiv arXiv 2024
-
[15]
Foundationstereo: Zero-shot stereo matching,
B. Wen, M. Trepte, J. Aribido, J. Kautz, O. Gallo, and S. Birchfield, “Foundationstereo: Zero-shot stereo matching,” 2025. [Online]. Available: https://arxiv.org/abs/2501.09898
arXiv 2025
-
[17]
Defom-stereo: Depth foundation model based stereo matching,
H. Jiang, Z. Lou, L. Ding, R. Xu, M. Tan, W. Jiang, and R. Huang, “Defom-stereo: Depth foundation model based stereo matching,” 2025. [Online]. Available: https://arxiv.org/abs/2501.09466
arXiv 2025
-
[18]
Mobilestereonet: Towards lightweight deep networks for stereo matching,
F. Shamsafar, S. Woerz, R. Rahim, and A. Zell, “Mobilestereonet: Towards lightweight deep networks for stereo matching,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2022, pp. 2417–2426
2022
-
[19]
Lightstereo: Channel boost is all your need for efficient 2d cost aggregation,
X. Guo, C. Zhang, Y . Zhang, W. Zheng, D. Nie, M. Poggi, and L. Chen, “Lightstereo: Channel boost is all your need for efficient 2d cost aggregation,” 2024. [Online]. Available: https://arxiv.org/abs/2406.19833
arXiv 2024
-
[20]
Banet: Bilateral aggregation network for mobile stereo matching,
G. Xu, J. Liu, X. Wang, J. Cheng, Y . Deng, J. Zang, Y . Chen, and X. Yang, “Banet: Bilateral aggregation network for mobile stereo matching,”arXiv preprint arXiv:2503.03259, 2025
arXiv 2025
-
[21]
Igev++: Iterative multi-range geometry encoding volumes for stereo matching,
G. Xu, X. Wang, Z. Zhang, J. Cheng, C. Liao, and X. Yang, “Igev++: Iterative multi-range geometry encoding volumes for stereo matching,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[22]
Monster++: Unified stereo matching, multi-view stereo, and real-time stereo with monodepth priors,
J. Cheng, W. Liao, Z. Cai, L. Liu, G. Xu, X. Wang, Y . Wang, Z. Yuan, Y . Deng, J. Zang, Y . Shi, J. Tang, and X. Yang, “Monster++: Unified stereo matching, multi-view stereo, and real-time stereo with monodepth priors,” 2025. [Online]. Available: https://arxiv.org/abs/2501.08643
arXiv 2025
-
[23]
Stereo anything: Unifying stereo matching with large- scale mixed data,
X. Guo, C. Zhang, Y . Zhang, D. Nie, R. Wang, W. Zheng, M. Poggi, and L. Chen, “Stereo anything: Unifying stereo matching with large- scale mixed data,”arXiv preprint arXiv:2411.14053, 2024
arXiv 2024
-
[24]
A stereo matching algorithm with an adaptive window: Theory and experiment,
T. Kanade and M. Okutomi, “A stereo matching algorithm with an adaptive window: Theory and experiment,”IEEE transactions on pattern analysis and machine intelligence, vol. 16, no. 9, pp. 920–932, 1994
1994
-
[25]
Performance evaluation of scene registration and stereo matching for artographic feature extrac- tion,
Y . C. Hsieh, D. M. McKeown, and F. P. Perlant, “Performance evaluation of scene registration and stereo matching for artographic feature extrac- tion,”IEEE Transactions on Pattern Analysis & Machine Intelligence, vol. 14, no. 02, pp. 214–238, 1992
1992
-
[26]
Stereo matching with nonlinear diffu- sion,
D. Scharstein and R. Szeliski, “Stereo matching with nonlinear diffu- sion,”International journal of computer vision, vol. 28, pp. 155–174, 1998
1998
-
[27]
A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation,
N. Mayer, E. Ilg, P. Hausser, P. Fischer, D. Cremers, A. Dosovitskiy, and T. Brox, “A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation,” inCVPR, 2016, pp. 4040–4048. 15
2016
-
[28]
Pyramid stereo matching network,
J.-R. Chang and Y .-S. Chen, “Pyramid stereo matching network,” in CVPR, 2018, pp. 5410–5418
2018
-
[29]
Group-wise correlation stereo network,
X. Guo, K. Yang, W. Yang, X. Wang, and H. Li, “Group-wise correlation stereo network,” inCVPR, 2019, pp. 3273–3282
2019
-
[30]
Aanet: Adaptive aggregation network for efficient stereo matching,
H. Xu and J. Zhang, “Aanet: Adaptive aggregation network for efficient stereo matching,” inCVPR, 2020, pp. 1959–1968
2020
-
[31]
Hitnet: Hierarchical iterative tile refinement network for real-time stereo matching,
V . Tankovich, C. Hane, Y . Zhang, A. Kowdle, S. Fanello, and S. Bouaziz, “Hitnet: Hierarchical iterative tile refinement network for real-time stereo matching,” inCVPR, 2021, pp. 14 362–14 372
2021
-
[32]
Openstereo: A comprehensive benchmark for stereo matching and strong baseline,
X. Guo, C. Zhang, J. Lu, Y . Wang, Y . Duan, T. Yang, Z. Zhu, and L. Chen, “Openstereo: A comprehensive benchmark for stereo matching and strong baseline,”arXiv preprint arXiv:2312.00343, 2023
arXiv 2023
-
[33]
Uncertainty guided adaptive warping for robust and efficient stereo matching,
J. Jing, J. Li, P. Xiong, J. Liu, S. Liu, Y . Guo, X. Deng, M. Xu, L. Jiang, and L. Sigal, “Uncertainty guided adaptive warping for robust and efficient stereo matching,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2023, pp. 3318–3327
2023
-
[34]
Iterative geometry encoding volume for stereo matching,
G. Xu, X. Wang, X. Ding, and X. Yang, “Iterative geometry encoding volume for stereo matching,” inProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, 2023, pp. 21 919– 21 928
2023
-
[35]
Context-enhanced stereo transformer,
W. Guo, Z. Li, Y . Yang, Z. Wang, R. H. Taylor, M. Unberath, A. Yuille, and Y . Li, “Context-enhanced stereo transformer,” inEuropean Confer- ence on Computer Vision. Springer, 2022, pp. 263–279
2022
-
[36]
Chitransformer: Towards reliable stereo from cues,
Q. Su and S. Ji, “Chitransformer: Towards reliable stereo from cues,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 1939–1949
2022
-
[37]
Croco v2: Improved cross-view completion pre-training for stereo matching and optical flow,
P. Weinzaepfel, T. Lucas, V . Leroy, Y . Cabon, V . Arora, R. Br ´egier, G. Csurka, L. Antsfeld, B. Chidlovskii, and J. Revaud, “Croco v2: Improved cross-view completion pre-training for stereo matching and optical flow,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 17 969–17 980
2023
-
[38]
Unifying flow, stereo and depth estimation,
H. Xu, J. Zhang, J. Cai, H. Rezatofighi, F. Yu, D. Tao, and A. Geiger, “Unifying flow, stereo and depth estimation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023
2023
-
[39]
Dynamicstereo: Consistent dynamic depth from stereo videos,
N. Karaev, I. Rocco, B. Graham, N. Neverova, A. Vedaldi, and C. Rup- precht, “Dynamicstereo: Consistent dynamic depth from stereo videos,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 13 229–13 239
2023
-
[40]
Match-stereo-videos: Bidirec- tional alignment for consistent dynamic stereo matching,
J. Jing, Y . Mao, and K. Mikolajczyk, “Match-stereo-videos: Bidirec- tional alignment for consistent dynamic stereo matching,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 415–432
2024
-
[41]
Match stereo videos via bidirectional alignment,
J. Jing, Y . Mao, A. Qiu, and K. Mikolajczyk, “Match stereo videos via bidirectional alignment,”IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1–16, 2026
2026
-
[42]
Stereo any video: Tem- porally consistent stereo matching,
J. Jing, W. Luo, Y . Mao, and K. Mikolajczyk, “Stereo any video: Tem- porally consistent stereo matching,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 20 836–20 846
2025
-
[43]
Domain- invariant stereo matching networks,
F. Zhang, X. Qi, R. Yang, V . Prisacariu, B. Wah, and P. Torr, “Domain- invariant stereo matching networks,” inEuropean Conference on Com- puter Vision. Springer, 2020, pp. 420–439
2020
-
[44]
Itsa: An information-theoretic approach to automatic shortcut avoidance and domain generalization in stereo matching networks,
W. Chuah, R. Tennakoon, R. Hoseinnezhad, A. Bab-Hadiashar, and D. Suter, “Itsa: An information-theoretic approach to automatic shortcut avoidance and domain generalization in stereo matching networks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 13 022–13 032
2022
-
[45]
Revisiting domain generalized stereo matching networks from a feature consistency perspective,
J. Zhang, X. Wang, X. Bai, C. Wang, L. Huang, Y . Chen, L. Gu, J. Zhou, T. Harada, and E. R. Hancock, “Revisiting domain generalized stereo matching networks from a feature consistency perspective,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 13 001–13 011
2022
-
[46]
Domain generalized stereo matching via hierarchical visual transformation,
T. Chang, X. Yang, T. Zhang, and M. Wang, “Domain generalized stereo matching via hierarchical visual transformation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 9559–9568
2023
-
[47]
Masked representation learning for domain generalized stereo matching,
Z. Rao, B. Xiong, M. He, Y . Dai, R. He, Z. Shen, and X. Li, “Masked representation learning for domain generalized stereo matching,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 5435–5444
2023
-
[48]
Cfnet: Cascade and fused cost volume for robust stereo matching,
Z. Shen, Y . Dai, and Z. Rao, “Cfnet: Cascade and fused cost volume for robust stereo matching,” inCVPR, 2021, pp. 13 906–13 915
2021
-
[49]
Stereo anywhere: Robust zero-shot deep stereo matching even where either stereo or mono fail,
L. Bartolomei, F. Tosi, M. Poggi, and S. Mattoccia, “Stereo anywhere: Robust zero-shot deep stereo matching even where either stereo or mono fail,”arXiv preprint arXiv:2412.04472, 2024
arXiv 2024
-
[50]
Learning representa- tions from foundation models for domain generalized stereo matching,
Y . Zhang, L. Wang, K. Li, Y . Wang, and Y . Guo, “Learning representa- tions from foundation models for domain generalized stereo matching,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 146– 162
2024
-
[51]
All-in-one: Transferring vision foundation models into stereo matching,
J. Zhou, H. Zhang, J. Yuan, P. Ye, T. Chen, H. Jiang, M. Chen, and Y . Zhang, “All-in-one: Transferring vision foundation models into stereo matching,”arXiv preprint arXiv:2412.09912, 2024
arXiv 2024
-
[52]
Stereonet: Guided hierarchical refinement for real-time edge-aware depth prediction,
S. Khamis, S. Fanello, C. Rhemann, A. Kowdle, J. Valentin, and S. Izadi, “Stereonet: Guided hierarchical refinement for real-time edge-aware depth prediction,” inECCV, 2018, pp. 573–590
2018
-
[53]
Deeppruner: Learning efficient stereo matching via differentiable patchmatch,
S. Duggal, S. Wang, W.-C. Ma, R. Hu, and R. Urtasun, “Deeppruner: Learning efficient stereo matching via differentiable patchmatch,” in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 4384–4393
2019
-
[54]
FADNet: A fast and accurate network for disparity estimation,
Q. Wang, S. Shi, S. Zheng, K. Zhao, and X. Chu, “FADNet: A fast and accurate network for disparity estimation,” in2020 IEEE International Conference on Robotics and Automation (ICRA 2020), 2020, pp. 101– 107
2020
-
[55]
Correlate-and-excite: Real-time stereo matching via guided cost volume excitation,
A. Bangunharcana, J. W. Cho, S. Lee, I. S. Kweon, K.-S. Kim, and S. Kim, “Correlate-and-excite: Real-time stereo matching via guided cost volume excitation,” in2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2021, pp. 3542–3548
2021
-
[56]
Bilateral grid learning for stereo matching networks,
B. Xu, Y . Xu, X. Yang, W. Jia, and Y . Guo, “Bilateral grid learning for stereo matching networks,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 12 497–12 506
2021
-
[57]
Attention concatenation volume for accurate and efficient stereo matching,
G. Xu, J. Cheng, P. Guo, and X. Yang, “Attention concatenation volume for accurate and efficient stereo matching,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 12 981–12 990
2022
-
[58]
Mobilenetv2: Inverted residuals and linear bottlenecks,
M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen, “Mobilenetv2: Inverted residuals and linear bottlenecks,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 4510–4520
2018
-
[59]
Run, don’t walk: chasing higher flops for faster neural networks,
J. Chen, S.-h. Kao, H. He, W. Zhuo, S. Wen, C.-H. Lee, and S.-H. G. Chan, “Run, don’t walk: chasing higher flops for faster neural networks,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 12 021–12 031
2023
-
[60]
Flickr1024: A large-scale dataset for stereo image super-resolution,
Y . Wang, L. Wang, J. Yang, W. An, and Y . Guo, “Flickr1024: A large-scale dataset for stereo image super-resolution,” inInternational Conference on Computer Vision Workshops, Oct 2019, pp. 3852–3857
2019
-
[61]
Instereo2k: a large real dataset for stereo matching in indoor scenes,
W. Bao, W. Wang, Y . Xu, Y . Guo, S. Hong, and X. Zhang, “Instereo2k: a large real dataset for stereo matching in indoor scenes,”Science China Information Sciences, vol. 63, no. 11, pp. 1–11, 2020
2020
-
[62]
Holopix50k: A large-scale in-the-wild stereo image dataset,
Y . Hua, P. Kohli, P. Uplavikar, A. Ravi, S. Gunaseelan, J. Orozco, and E. Li, “Holopix50k: A large-scale in-the-wild stereo image dataset,” in CVPR Workshop on Computer Vision for Augmented and Virtual Reality, Seattle, WA, 2020., June 2020
2020
-
[63]
Driving- stereo: A large-scale dataset for stereo matching in autonomous driving scenarios,
G. Yang, X. Song, C. Huang, Z. Deng, J. Shi, and B. Zhou, “Driving- stereo: A large-scale dataset for stereo matching in autonomous driving scenarios,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 899–908
2019
-
[64]
Uasol, a large-scale high-resolution outdoor stereo dataset,
Z. Bauer, F. Gomez-Donoso, E. Cruz, S. Orts-Escolano, and M. Cazorla, “Uasol, a large-scale high-resolution outdoor stereo dataset,”Scientific data, vol. 6, no. 1, p. 162, 2019
2019
-
[65]
Falling things: A synthetic dataset for 3d object detection and pose estimation,
J. Tremblay, T. To, and S. Birchfield, “Falling things: A synthetic dataset for 3d object detection and pose estimation,” inCVPRW, 2018, pp. 2038–2041
2018
-
[66]
Virtual kitti 2,
Y . Cabon, N. Murray, and M. Humenberger, “Virtual kitti 2,” 2020
2020
-
[67]
Tartanair: A dataset to push the limits of visual slam,
W. Wang, D. Zhu, X. Wang, Y . Hu, Y . Qiu, C. Wang, Y . Hu, A. Kapoor, and S. Scherer, “Tartanair: A dataset to push the limits of visual slam,” 2020
2020
-
[68]
Q. Wang, S. Zheng, Q. Yan, F. Deng, K. Zhao, and X. Chu, “Irs: A large naturalistic indoor robotics stereo dataset to train deep models for dis- parity and surface normal estimation,”arXiv preprint arXiv:1912.09678, 2019
arXiv 1912
-
[69]
A naturalistic open source movie for optical flow evaluation,
D. J. Butler, J. Wulff, G. B. Stanley, and M. J. Black, “A naturalistic open source movie for optical flow evaluation,” inECCV, 2012, pp. 611–625
2012
-
[70]
Spring: A high-resolution high-detail dataset and benchmark for scene flow, optical flow and stereo,
L. Mehl, J. Schmalfuss, A. Jahedi, Y . Nalivayko, and A. Bruhn, “Spring: A high-resolution high-detail dataset and benchmark for scene flow, optical flow and stereo,” inProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[71]
Promptstereo: Zero-shot stereo matching via structure and motion prompts,
X. Wang, H. Yang, H. Wang, J. Cheng, G. Xu, M. Lin, and X. Yang, “Promptstereo: Zero-shot stereo matching via structure and motion prompts,”arXiv preprint arXiv:2603.01650, 2026
arXiv 2026
-
[72]
Acceleration of stochastic approxima- tion by averaging,
B. T. Polyak and A. B. Juditsky, “Acceleration of stochastic approxima- tion by averaging,”SIAM journal on control and optimization, vol. 30, no. 4, pp. 838–855, 1992
1992
-
[73]
Sam 3: Segment anything with concepts,
N. Carion, L. Gustafson, Y .-T. Hu, S. Debnath, R. Hu, D. Suris, C. Ryali, K. V . Alwala, H. Khedr, A. Huanget al., “Sam 3: Segment anything with concepts,”arXiv preprint arXiv:2511.16719, 2025. 16
Pith/arXiv arXiv 2025
-
[74]
Stereo4d: Learning how things move in 3d from internet stereo videos,
L. Jin, R. Tucker, Z. Li, D. Fouhey, N. Snavely, and A. Holynski, “Stereo4d: Learning how things move in 3d from internet stereo videos,” arXiv preprint, 2024
2024
-
[75]
Structure- guided ranking loss for single image depth prediction,
K. Xian, J. Zhang, O. Wang, L. Mai, Z. Lin, and Z. Cao, “Structure- guided ranking loss for single image depth prediction,” inThe IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020
2020
-
[76]
Confidence aware stereo matching for realistic cluttered scenario,
J. Min and Y . Jeon, “Confidence aware stereo matching for realistic cluttered scenario,” in2024 IEEE International Conference on Image Processing (ICIP). IEEE, 2024, pp. 3491–3497
2024
-
[77]
Adam: A method for stochastic optimization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014
Pith/arXiv arXiv 2014
-
[78]
A convnet for the 2020s,
Z. Liu, H. Mao, C.-Y . Wu, C. Feichtenhofer, T. Darrell, and S. Xie, “A convnet for the 2020s,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 11 976–11 986
2022
-
[79]
Searching for mobilenetv3,
A. Howard, M. Sandler, G. Chu, L.-C. Chen, B. Chen, M. Tan, W. Wang, Y . Zhu, R. Pang, V . Vasudevanet al., “Searching for mobilenetv3,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 1314–1324
2019
-
[80]
Efficientnetv2: Smaller models and faster training,
M. Tan and Q. Le, “Efficientnetv2: Smaller models and faster training,” inInternational conference on machine learning. PMLR, 2021, pp. 10 096–10 106
2021
-
[81]
Ghostnet: More features from cheap operations,
K. Han, Y . Wang, Q. Tian, J. Guo, C. Xu, and C. Xu, “Ghostnet: More features from cheap operations,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 1580– 1589
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.