When Does Synthetic CT Transfer? A Label-Free Donor/Host Diagnostic for Medical Vision-Language Model Routing on Real Lung CT
Pith reviewed 2026-06-30 07:37 UTC · model grok-4.3
The pith
Donor-driven nodule properties on synthetic lung CT twins transfer to real scans while host-driven anatomy properties do not.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
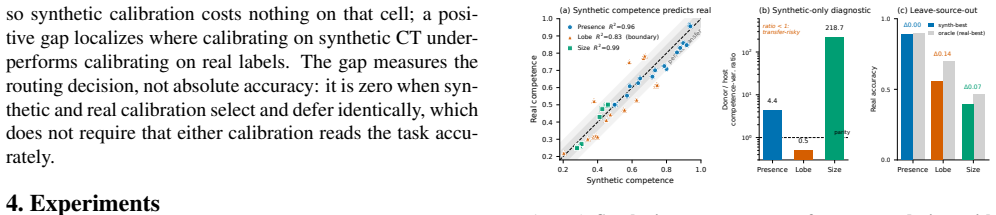
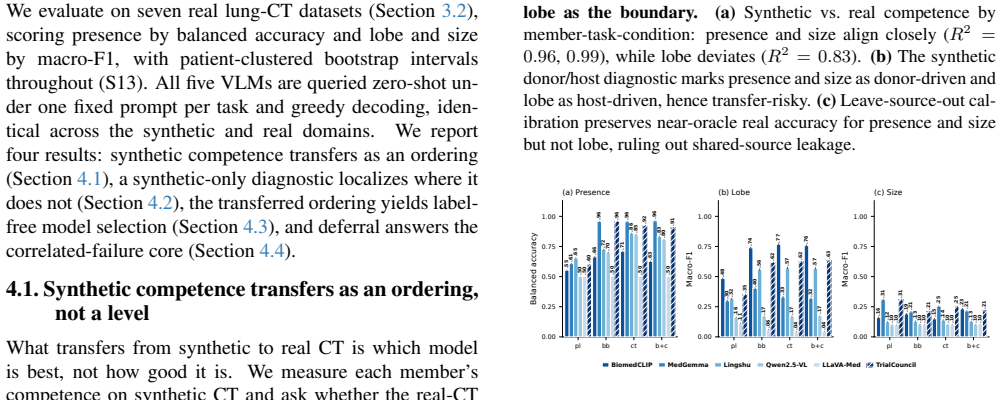
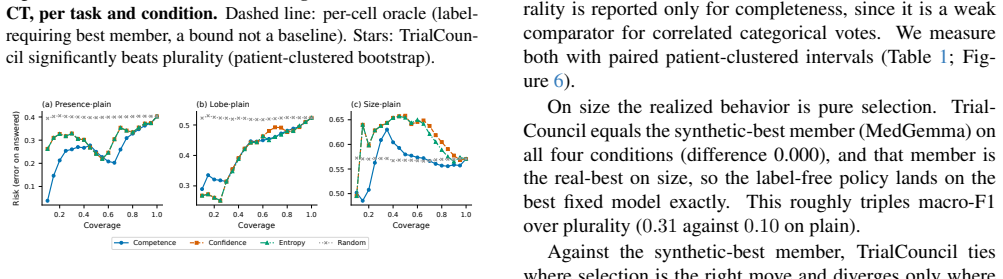
On synthetic digital twins, competence that is donor-driven (a property of the transplanted nodule) survives the synthetic to real change of host, while host-driven competence (a property of the surrounding anatomy) need not. The prediction holds in every case: presence and size orderings transfer (R2 >= 0.96), lobe does not; the split survives leave-source-out calibration, and the diagnostic names that boundary before any real label.
What carries the argument
The donor/host diagnostic on synthetic digital twins that labels nodule properties versus surrounding anatomy to forecast transfer.
If this is right
- Presence and size orderings from synthetic twins match real-data performance with R2 at or above 0.96.
- Lobe assignment from synthetic twins does not match real-data performance.
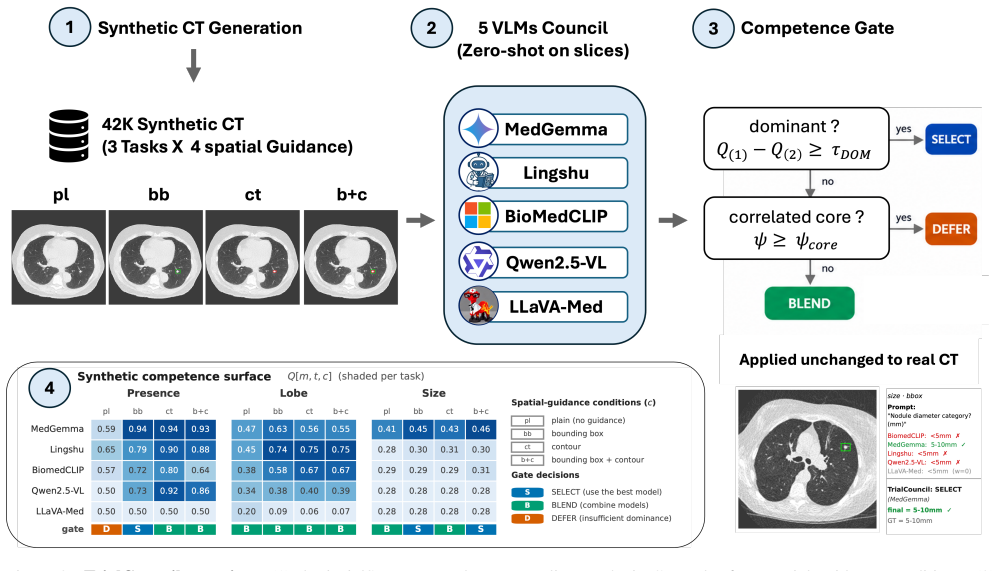
- A training-free council using only synthetic calibration selects the best model exactly where the diagnostic predicts transfer.
- The donor/host split remains stable under leave-source-out calibration across the tested tasks.
Where Pith is reading between the lines
- If the donor/host split generalizes, the same synthetic-twin test could route models on other organs or modalities without new labels.
- The approach implies that model selection for deployment can be done entirely on synthetic data when the competence type is known in advance.
- One could test whether the same donor/host distinction predicts transfer for non-VLM architectures or different synthetic generation methods.
Load-bearing premise
The synthetic digital twins accurately capture the real-data distinction between donor-driven and host-driven competences.
What would settle it
A real lung CT dataset in which nodule presence ordering from the synthetic twins fails to match actual model performance, or in which lobe assignment does transfer.
Figures


read the original abstract
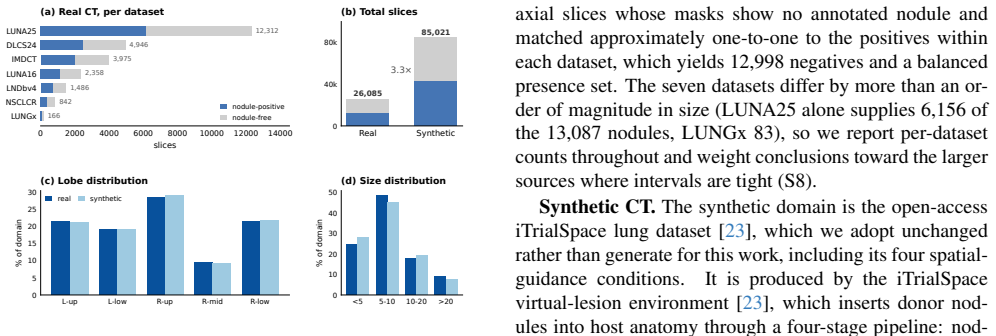
A synthetic measurement of model competence is useful only if it survives the move to real data, yet the real labels that would verify it are exactly what medical imaging lacks. We ask whether transfer can be predicted in advance, label-free, and answer with a mechanism: on synthetic digital twins, competence that is donor-driven (a property of the transplanted nodule) survives the synthetic to real change of host, while host-driven competence (a property of the surrounding anatomy) need not. We test this on three lung CT vision-language tasks chosen to span that axis, across five public VLMs, four guidance conditions, and seven real datasets. The prediction holds in every case: presence and size orderings transfer (R2 >= 0.96), lobe does not; the split survives leave-source-out calibration, and the diagnostic names that boundary before any real label. TrialCouncil, a training-free council calibrated only on synthetic CT, confirms it by matching the best fixed model exactly where transfer is predicted. The contribution is not the router but the finding that transfer itself is predictable, label-free, from synthetic data alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that transfer of VLM competence from synthetic digital twins to real lung CT can be predicted label-free by distinguishing donor-driven competences (nodule presence and size orderings, which transfer with R² ≥ 0.96) from host-driven competences (lobe, which does not). This holds across five VLMs, four guidance conditions, and seven real datasets; leave-source-out calibration on synthetics survives, and a training-free TrialCouncil router matches the best fixed model exactly where transfer is predicted.
Significance. If the synthetic twins faithfully capture the donor/host distinction, the result offers a concrete mechanism for label-free model routing in label-scarce medical imaging and shows that certain transfer behaviors are predictable from synthetic data alone. The explicit separation of competences that survive host change versus those that do not is a useful conceptual contribution.
major comments (2)
- [Abstract and methods description of twin construction] The central claim rests on the unverified assumption that the synthetic digital twin construction (nodule transplantation and host variation) accurately reproduces the real-data distinction between donor-driven and host-driven competences. The reported leave-source-out validation is performed only on synthetic sources and does not test whether the observed transfer behavior generalizes to real host variation without real-label calibration.
- [Results on R² values and leave-source-out] The manuscript reports consistent high R² values and that the diagnostic 'names that boundary before any real label,' yet provides no error analysis, exact data exclusion rules, or ablation on how nodule/host synthesis parameters affect the donor/host split; without these, the load-bearing claim that the prediction holds 'in every case' cannot be fully assessed.
minor comments (2)
- Clarify the precise definition and measurement of 'donor-driven' versus 'host-driven' competence in the methods section to avoid ambiguity in replication.
- Add a table or figure explicitly showing per-task, per-VLM R² values and the leave-source-out splits rather than summarizing 'R² ≥ 0.96' and 'holds in every case.'
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope and robustness of our claims. We address each major comment below. We will add the requested error analysis, exclusion rules, and ablations (second comment). For the first comment, we clarify the validation strategy while acknowledging its inherent limits in a label-free setting.
read point-by-point responses
-
Referee: [Abstract and methods description of twin construction] The central claim rests on the unverified assumption that the synthetic digital twin construction (nodule transplantation and host variation) accurately reproduces the real-data distinction between donor-driven and host-driven competences. The reported leave-source-out validation is performed only on synthetic sources and does not test whether the observed transfer behavior generalizes to real host variation without real-label calibration.
Authors: We agree the leave-source-out is performed on synthetic sources to show the diagnostic generalizes across nodule sources without real labels. Our real-data verification applies the synthetic-calibrated diagnostic to seven real lung CT datasets and confirms the predicted pattern (donor-driven tasks transfer with R² ≥ 0.96; host-driven does not). A direct test of real host variation without any real-label calibration is not feasible, as it would require the labels the method is designed to avoid. We will revise the abstract and methods to explicitly distinguish synthetic calibration from real-data application of the diagnostic, making this scope clearer. revision: partial
-
Referee: [Results on R² values and leave-source-out] The manuscript reports consistent high R² values and that the diagnostic 'names that boundary before any real label,' yet provides no error analysis, exact data exclusion rules, or ablation on how nodule/host synthesis parameters affect the donor/host split; without these, the load-bearing claim that the prediction holds 'in every case' cannot be fully assessed.
Authors: We accept that additional reporting is needed to support the 'in every case' claim. In revision we will add: (i) bootstrap confidence intervals or standard errors on all reported R² values, (ii) explicit data exclusion criteria (nodule size thresholds, slice selection rules, and quality filters), and (iii) a sensitivity ablation varying nodule transplantation parameters (size, density) and host variation levels (lobe sampling, anatomy deformation) to quantify impact on the donor/host split. These will be placed in a new supplementary section with tables and figures. revision: yes
Circularity Check
No circularity; central diagnostic derived from synthetic data and validated independently on real datasets
full rationale
The paper constructs a donor/host diagnostic on synthetic digital twins to predict which competences transfer to real CT data, then evaluates the resulting predictions (R2 >= 0.96 for presence/size, failure for lobe) on seven independent real datasets using leave-source-out checks without any real-label calibration of the diagnostic itself. No equations, self-citations, or fitted parameters are shown to reduce the transfer prediction to a quantity defined from the target real data or to a self-referential ansatz. The derivation remains self-contained against external real-data benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthetic digital twins can be constructed to isolate donor-driven versus host-driven model competences that generalize to real CT distributions.
invented entities (2)
-
donor-driven competence
no independent evidence
-
host-driven competence
no independent evidence
Reference graph
Works this paper leans on
-
[1]
H. J. W. L. Aerts et al. Data from NSCLC-Radiomics (ver- sion 4). The Cancer Imaging Archive, dataset version 4,
-
[2]
2, 3, 11, 12
Data set. 2, 3, 11, 12
-
[3]
Lungx challenge for computerized lung nodule classification
Samuel G Armato III, Karen Drukker, Feng Li, Lubomir Hadjiiski, Georgia D Tourassi, Roger M Engelmann, 8 Maryellen L Giger, George Redmond, Keyvan Farahani, Justin S Kirby, et al. Lungx challenge for computerized lung nodule classification. Journal of Medical Imaging , 3 (4):044506–044506, 2016. 2, 3, 11, 12
2016
-
[4]
Evaluation of digital breast to- mosynthesis as replacement of full-field digital mammogra- phy using an in silico imaging trial
Aldo Badano, Christian G Graff, Andreu Badal, Diksha Sharma, Rongping Zeng, Frank W Samuelson, Stephen J Glick, and Kyle J Myers. Evaluation of digital breast to- mosynthesis as replacement of full-field digital mammogra- phy using an in silico imaging trial. JAMA network open, 1 (7):e185474, 2018. 1, 2
2018
-
[5]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen2.5-vl technical report. arXiv preprint arXiv:2511.21631, 2025. 1, 2, 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Open (clinical) llms are sensitive to instruction phrasings
Alberto Mario Ceballos-Arroyo, Monica Munnangi, Jiuding Sun, Karen Zhang, Jered McInerney, Byron C Wallace, and Silvio Amir. Open (clinical) llms are sensitive to instruction phrasings. In Proceedings of the 23rd workshop on biomed- ical natural language processing, pages 50–71, 2024. 1
2024
-
[7]
Regression with cost-based rejection
Xin Cheng, Yuzhou Cao, Haobo Wang, Hongxin Wei, Bo An, and Lei Feng. Regression with cost-based rejection. Advances in Neural Information Processing Systems , 36: 45172–45196, 2023. 2
2023
-
[8]
On optimum recognition error and reject trade- off
C Chow. On optimum recognition error and reject trade- off. IEEE Transactions on information theory, 16(1):41–46,
-
[9]
Selective classification for deep neural networks
Yonatan Geifman and Ran El-Yaniv. Selective classification for deep neural networks. Advances in neural information processing systems, 30, 2017. 2
2017
-
[10]
Shortcut learning in deep neural networks
Robert Geirhos, J ¨orn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Fe- lix A Wichmann. Shortcut learning in deep neural networks. Nature Machine Intelligence, 2(11):665–673, 2020. 2
2020
-
[11]
Maisi: Medical ai for synthetic imaging
Pengfei Guo, Can Zhao, Dong Yang, Ziyue Xu, Vish- wesh Nath, Yucheng Tang, Benjamin Simon, Mason Belue, Stephanie Harmon, Baris Turkbey, et al. Maisi: Medical ai for synthetic imaging. In 2025 IEEE/CVF Winter Con- ference on Applications of Computer Vision (WACV), pages 4430–4441. IEEE, 2025. 1, 2
2025
-
[12]
Vision-language mod- els for medical report generation and visual question answer- ing: A review
Iryna Hartsock and Ghulam Rasool. Vision-language mod- els for medical report generation and visual question answer- ing: A review. Frontiers in artificial intelligence, 7:1430984,
-
[13]
Llava-med: Training a large language- and-vision assistant for biomedicine in one day
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. Llava-med: Training a large language- and-vision assistant for biomedicine in one day. Advances in Neural Information Processing Systems, 36:28541–28564,
-
[14]
Consistent estimators for learning to defer to an expert
Hussein Mozannar and David Sontag. Consistent estimators for learning to defer to an expert. InInternational conference on machine learning, pages 7076–7087. PMLR, 2020. 2
2020
-
[15]
Lndb: a lung nodule database on computed tomography
Jo ˜ao Pedrosa, Guilherme Aresta, Carlos Ferreira, M ´arcio Rodrigues, Patr´ıcia Leit˜ao, Andr ´e Silva Carvalho, Jo ˜ao Re- belo, Eduardo Negr ˜ao, Isabel Ramos, Ant ´onio Cunha, et al. Lndb: a lung nodule database on computed tomography. arXiv preprint arXiv:1911.08434, 2019. 2, 3, 11, 12
-
[16]
Peeters, B
D. Peeters, B. Obreja, N. Antonissen, and C. Jacobs. The LUNA25 challenge: Public training and development set – annotation data. Zenodo, dataset version 1.0.0, 2025. Data set. 2, 3, 11, 12
2025
-
[17]
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroen- sri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, C ´ıan Hughes, Charles Lau, et al. Medgemma technical report. arXiv preprint arXiv:2507.05201, 2025. 1, 2, 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Validation, comparison, and combination of algorithms for automatic detection of pulmonary nodules in computed tomography images: the luna16 challenge
Arnaud Arindra Adiyoso Setio, Alberto Traverso, Thomas De Bel, Moira SN Berens, Cas Van Den Bogaard, Piergiorgio Cerello, Hao Chen, Qi Dou, Maria Evelina Fantacci, Bram Geurts, et al. Validation, comparison, and combination of algorithms for automatic detection of pulmonary nodules in computed tomography images: the luna16 challenge. Medi- cal image analy...
2017
-
[19]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outra- geously large neural networks: The sparsely-gated mixture- of-experts layer. arXiv preprint arXiv:1701.06538, 2017. 2
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[20]
To ensemble or not: Assessing majority voting strategies for phishing detection with large language models
Fouad Trad and Ali Chehab. To ensemble or not: Assessing majority voting strategies for phishing detection with large language models. In International Conference on Intelligent Systems and Pattern Recognition, pages 158–173. Springer,
-
[21]
Nodmaisi: Nodule-oriented medical ai for syn- thetic imaging
Fakrul Islam Tushar, Ehsan Samei, Cynthia Rudin, and Joseph Y Lo. Nodmaisi: Nodule-oriented medical ai for syn- thetic imaging. arXiv preprint arXiv:2512.18038, 2025. 1, 2
-
[22]
Virtual lung screening trial (vlst): An in silico study inspired by the national lung screening trial for lung cancer detection
Fakrul Islam Tushar, Liesbeth Vancoillie, Cindy McCabe, Amareswararao Kavuri, Lavsen Dahal, Brian Harrawood, Milo Fryling, Mojtaba Zarei, Saman Sotoudeh-Paima, Fong Chi Ho, et al. Virtual lung screening trial (vlst): An in silico study inspired by the national lung screening trial for lung cancer detection. Medical Image Analysis, 103:103576,
-
[23]
Utility of the virtual imaging trials methodology for objective characterization of ai systems and training data
Fakrul Islam Tushar, Lavsen Dahal, Saman Sotoudeh-Paima, Ehsan Abadi, William P Segars, Joseph Y Lo, and Ehsan Samei. Utility of the virtual imaging trials methodology for objective characterization of ai systems and training data. Journal of Medical Imaging, 13(1):014506, 2026. 2
2026
-
[24]
iTRIALSPACE: Programmable Virtual Lesion Trials for Controlled Evaluation of Lung CT Models
Fakrul Islam Tushar, Umme Hafsa Momy, Joseph Y Lo, and Geoffrey D Rubin. itrialspace: Programmable virtual le- sion trials for controlled evaluation of lung ct models. arXiv preprint arXiv:2605.05761, 2026. 1, 2, 3, 4, 11, 12
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
The duke lung cancer screening (dlcs) dataset: a ref- erence dataset of annotated low-dose screening thoracic ct
Avivah J Wang, Fakrul Islam Tushar, Michael R Harowicz, Betty C Tong, Kyle J Lafata, Tina D Tailor, and Joseph Y Lo. The duke lung cancer screening (dlcs) dataset: a ref- erence dataset of annotated low-dose screening thoracic ct. Radiology: Artificial Intelligence, 7(4):e240248, 2025. 2, 3, 11, 12
2025
-
[26]
Tent: Fully Test-time Adaptation by Entropy Minimization
Dequan Wang, Evan Shelhamer, Shaoteng Liu, Bruno Ol- shausen, and Trevor Darrell. Tent: Fully test-time adaptation by entropy minimization. arXiv preprint arXiv:2006.10726,
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[27]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny 9 Zhou. Self-consistency improves chain of thought reason- ing in language models. arXiv preprint arXiv:2203.11171 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Cares: A comprehensive benchmark of trustwor- thiness in medical vision language models.Advances in Neu- ral Information Processing Systems , 37:140334–140365,
Peng Xia, Ze Chen, Juanxi Tian, Yangrui Gong, Ruibo Hou, Yue Xu, Zhenbang Wu, Zhiyuan Fan, Yiyang Zhou, Kangyu Zhu, et al. Cares: A comprehensive benchmark of trustwor- thiness in medical vision language models.Advances in Neu- ral Information Processing Systems , 37:140334–140365,
-
[29]
Lingshu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning
Weiwen Xu, Hou Pong Chan, Long Li, Mahani Aljunied, Ruifeng Yuan, Jianyu Wang, Chenghao Xiao, Guizhen Chen, Chaoqun Liu, Zhaodonghui Li, et al. Lingshu: A general- ist foundation model for unified multimodal medical under- standing and reasoning. arXiv preprint arXiv:2506.07044 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Sheng Zhang, Yanbo Xu, Naoto Usuyama, Hanwen Xu, Jaspreet Bagga, Robert Tinn, Sam Preston, Rajesh Rao, Mu Wei, Naveen Valluri, et al. Biomedclip: a multimodal biomedical foundation model pretrained from fifteen million scientific image-text pairs.arXiv preprint arXiv:2303.00915,
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
No, there is no nodule
Mengmeng Zhao, Gang Xue, Bingxi He, Jiajun Deng, Tingt- ing Wang, Yifan Zhong, Shenghui Li, Yang Wang, Yiming He, Tao Chen, et al. Integrated multiomics signatures to op- timize the accurate diagnosis of lung cancer. Nature commu- nications, 16(1):84, 2025. 2, 3, 11, 12 10 Supplementary Material S1. Datasets and task construction We use seven public lung-...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.