Video2Sim2Real: Full-Stack Autonomous Dexterous Skill Acquisition from a Single Human Video
Pith reviewed 2026-06-27 18:03 UTC · model grok-4.3
The pith
A single human video can produce dexterous robot skills that transfer better to the real world by reconstructing a digital twin and anchoring motions to object effects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
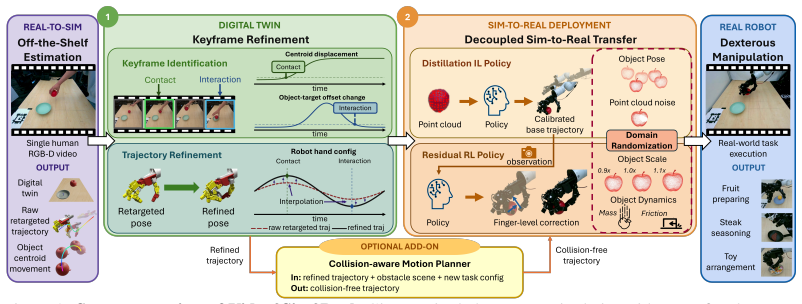
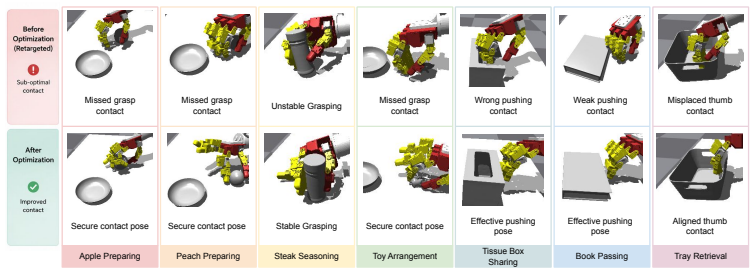
Video2Sim2Real reconstructs a simulator-ready digital twin from a single human video using off-the-shelf foundation models and extracts robot and object motion priors. It identifies object-centric keyframes to optimize robot configurations from simulator object data and treats these as anchors that refine the full robot motion to produce the demonstrated environmental effects. A decoupled sim-to-real approach learns recalibration of robot poses from noisy point clouds via imitation learning and applies residual reinforcement learning for local finger adaptations, while collision-aware motion planning supports generalization to new object poses.
What carries the argument
Object-centric keyframes used as anchors to optimize and refine robot configurations so that simulated object outcomes match the demonstration, paired with a decoupled sim-to-real strategy that separates perception recalibration from interaction adaptation.
If this is right
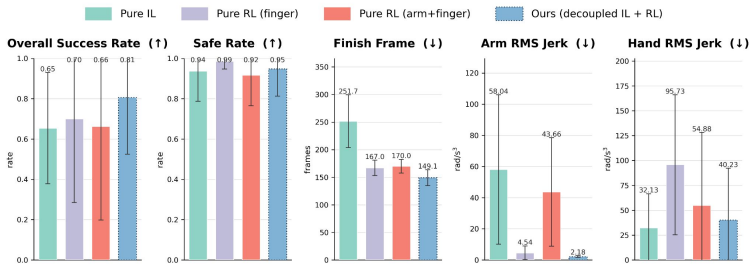
- Simulated task success, safety metrics, and trajectory coherence rise above multiple baselines on everyday manipulation tasks.
- Sim-to-real transfer outperforms existing techniques that copy human motion more directly.
- Collision-aware planning extends the learned skills to new spatial arrangements of objects.
- The method avoids treating extracted human motion as a fixed reference and instead optimizes for object impact.
Where Pith is reading between the lines
- The same object-centric anchoring idea could apply to videos that show only partial demonstrations if keyframe detection remains reliable.
- If foundation-model reconstruction improves, the pipeline might scale to longer-horizon tasks without additional human labeling.
- Decoupling perception correction from dynamics adaptation may reduce the need for perfect simulators in other robot learning settings.
Load-bearing premise
Off-the-shelf foundation models can produce a usable digital twin and motion priors from one video without perception errors that later stages cannot fix.
What would settle it
Real-robot trials on the evaluated tasks where the initial digital twin contains errors that cause the imitation-learning recalibration and residual RL steps to fail consistently, producing lower success than baselines.
Figures






read the original abstract
Human manipulation videos are a convenient and intuitive source for robot learning. However, directly transferring human dexterity to robots remains challenging due to perception errors and embodiment gap. To address this, we introduce Video2Sim2Real, a full-stack framework for autonomous skill acquisition from a single human manipulation video. Our framework first uses off-the-shelf foundation models to reconstruct a simulator-ready digital twin and extract robot and object motion priors. Rather than treating the extracted robot motion as a reliable reference throughout execution, our key idea is to recover and leverage the most fundamental sources of supervision from the demonstrated skill: We identify object-centric keyframes to optimize the corresponding robot configurations using object information from the simulator, and use these configurations as anchors that refine the robot motion such that it ultimately has the desired impact on the environment. To bridge the remaining sim-to-real gap, we introduce a sim-to-real strategy that decouples robustness to noisy and incomplete perception from variations in hand-object interaction dynamics. Specifically, we learn to recalibrate robot configurations from noisy real-world point clouds via IL, and leverage residual RL to perform local finger-level adaptations to ensure for robust and effective interactions. Finally, a collision-aware motion planning module enables spatial generalization to novel object configurations. Across several everyday manipulation tasks, Video2Sim2Real improves simulated task success, safety, and trajectory coherence over numerous baselines, and achieves better sim-to-real transfer than existing techniques. These results demonstrate a promising path toward autonomous dexterous skill acquisition from human videos.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
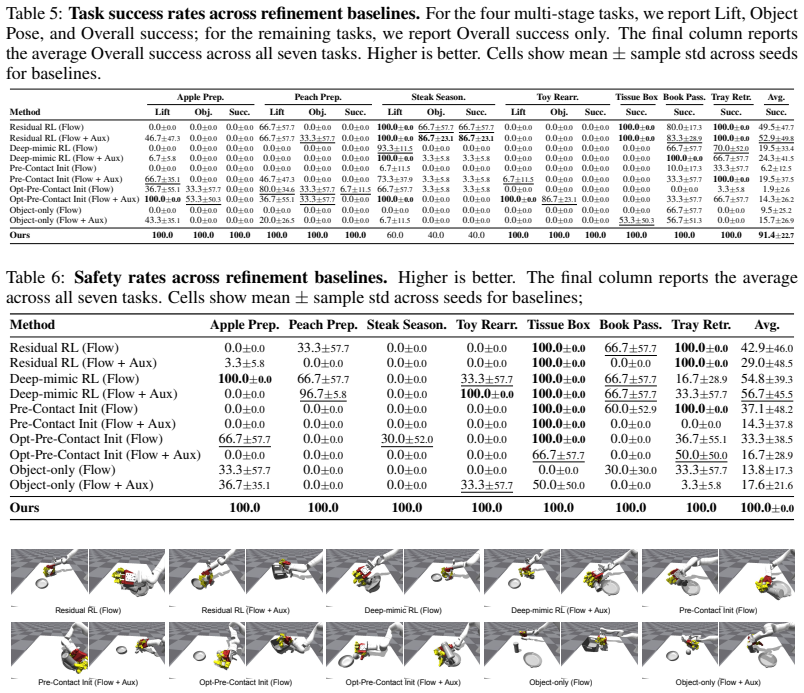
Summary. The paper introduces Video2Sim2Real, a full-stack framework for autonomous dexterous skill acquisition from a single human manipulation video. It leverages off-the-shelf foundation models to reconstruct a simulator-ready digital twin and extract motion priors. The core approach involves identifying object-centric keyframes to optimize robot configurations using simulator object information, using these as anchors to refine robot motion. For sim-to-real transfer, it decouples perception robustness (via imitation learning on noisy point clouds) from interaction dynamics (via residual RL for finger adaptations), and includes collision-aware motion planning for generalization to novel configurations. The paper claims that this method improves simulated task success, safety, and trajectory coherence over baselines and achieves better sim-to-real transfer on several everyday manipulation tasks.
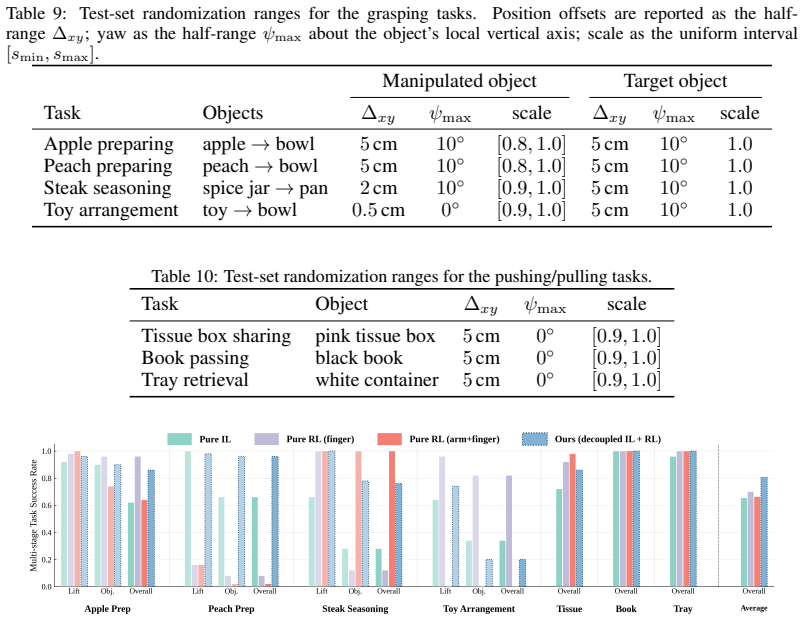
Significance. If the empirical results hold under scrutiny, this framework could significantly advance the field of robot learning by enabling skill acquisition from minimal human demonstration data, addressing both the perception and embodiment challenges in video-based transfer. The decoupling strategy in the sim-to-real module is a thoughtful design that could be applicable to other domains. The use of object-centric keyframes as anchors provides a principled way to handle the embodiment gap. However, the significance depends heavily on the reliability of the foundation model reconstructions and the robustness of the reported improvements, which require detailed validation.
major comments (2)
- [Abstract] Abstract: The central performance claims regarding improvements in task success, safety, and trajectory coherence, as well as better sim-to-real transfer, are stated without reference to specific quantitative results, number of tasks, baselines, or statistical tests. This makes it impossible to assess whether the improvements are substantial or if they could be affected by post-hoc choices in the experimental design.
- [Method] Method (Reconstruction and Keyframe Optimization): The assumption that off-the-shelf foundation models can reliably reconstruct a simulator-ready digital twin and extract usable priors from a single video without significant uncorrectable errors is load-bearing for the entire pipeline. No quantitative evaluation of reconstruction accuracy or sensitivity analysis to perception errors is mentioned, which is necessary to support the claim that downstream stages can correct for such errors.
minor comments (1)
- The abstract mentions 'numerous baselines' but does not specify what they are; this should be clarified in the experiments section for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and outline revisions that will strengthen the presentation of results and the supporting analysis.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claims regarding improvements in task success, safety, and trajectory coherence, as well as better sim-to-real transfer, are stated without reference to specific quantitative results, number of tasks, baselines, or statistical tests. This makes it impossible to assess whether the improvements are substantial or if they could be affected by post-hoc choices in the experimental design.
Authors: We agree that the abstract would be clearer with concrete quantitative anchors. In the revised manuscript we will expand the final sentence to report the number of tasks evaluated (five everyday manipulation tasks), the specific metrics (task success rate, safety violations, trajectory coherence), the number and identity of baselines, and the magnitude of improvements (e.g., average success-rate gains and statistical significance where computed). This change will allow readers to evaluate the scale of the reported gains directly from the abstract. revision: yes
-
Referee: [Method] Method (Reconstruction and Keyframe Optimization): The assumption that off-the-shelf foundation models can reliably reconstruct a simulator-ready digital twin and extract usable priors from a single video without significant uncorrectable errors is load-bearing for the entire pipeline. No quantitative evaluation of reconstruction accuracy or sensitivity analysis to perception errors is mentioned, which is necessary to support the claim that downstream stages can correct for such errors.
Authors: We acknowledge that the reconstruction step is foundational and that an explicit quantitative assessment of its accuracy would strengthen the paper. Although the end-to-end results demonstrate that the subsequent keyframe optimization and sim-to-real modules can tolerate the level of reconstruction noise present in our experiments, we agree that a dedicated sensitivity study is warranted. In revision we will add (i) quantitative reconstruction metrics (e.g., Chamfer distance and pose error on the reconstructed objects) and (ii) a controlled sensitivity analysis that injects increasing levels of perception noise and reports downstream task success. These additions will be placed in a new subsection or appendix. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and reader summary describe a procedural pipeline relying on off-the-shelf foundation models for reconstruction, keyframe optimization, IL, residual RL, and motion planning. No equations, fitted parameters renamed as predictions, self-definitional steps, or load-bearing self-citations are present in the given text. The approach is presented as a sequence of independent modules without any reduction of outputs to inputs by construction. The full manuscript is referenced but not supplied here; absent explicit equations or derivations in the available content, no circularity can be exhibited per the hard rules requiring direct quotes and specific reductions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A. M. Okamura, N. Smaby, and M. R. Cutkosky. An overview of dexterous manipulation. In Proceedings 2000 ICRA. Millennium Conference. IEEE International Conference on Robotics and Automation. Symposia Proceedings (Cat. No. 00CH37065), volume 1, pages 255–262, 2000
2000
-
[2]
S. An, Z. Meng, C. Tang, Y . Zhou, T. Liu, F. Ding, S. Zhang, Y . Mu, R. Song, W. Zhang, et al. Dexterous manipulation through imitation learning: A survey.arXiv preprint arXiv:2504.03515, 2025
arXiv 2025
-
[3]
A. Rajeswaran, V . Kumar, A. Gupta, G. Vezzani, J. Schulman, E. Todorov, and S. Levine. Learning complex dexterous manipulation with deep reinforcement learning and demonstra- tions.arXiv preprint arXiv:1709.10087, 2017
Pith/arXiv arXiv 2017
-
[4]
Y . Liu, W. C. Shin, Y . Han, Z. Chen, H. Ravichandar, and D. Xu. Immimic: Cross-domain imitation from human videos via mapping and interpolation.arXiv preprint arXiv:2509.10952, 2025
arXiv 2025
- [5]
-
[6]
Kareer, D
S. Kareer, D. Patel, R. Punamiya, P. Mathur, S. Cheng, C. Wang, J. Hoffman, and D. Xu. Egomimic: Scaling imitation learning via egocentric video.2025 IEEE International Confer- ence on Robotics and Automation (ICRA), pages 13226–13233, 2024
2025
-
[7]
Qin, Y .-H
Y . Qin, Y .-H. Wu, S. Liu, H. Jiang, R. Yang, Y . Fu, and X. Wang. Dexmv: Imitation learning for dexterous manipulation from human videos. InEuropean Conference on Computer Vision, pages 570–587. Springer, 2022
2022
-
[8]
S. H. Allu, N. Khargonkar, T. Summers, J. Yao, Y . Xiang, et al. Hrt1: One-shot human-to-robot trajectory transfer for mobile manipulation.arXiv preprint arXiv:2510.21026, 2025
arXiv 2025
- [9]
-
[10]
H. Chen, B. Sun, A. Zhang, M. Pollefeys, and S. Leutenegger. Vidbot: Learning generalizable 3d actions from in-the-wild 2d human videos for zero-shot robotic manipulation. InProceed- ings of the Computer Vision and Pattern Recognition Conference, pages 27661–27672, 2025
2025
-
[11]
Pavlakos, D
G. Pavlakos, D. Shan, I. Radosavovic, A. Kanazawa, D. Fouhey, and J. Malik. Reconstructing hands in 3d with transformers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9826–9836, 2024
2024
-
[12]
Y . Qin, W. Yang, B. Huang, K. Van Wyk, H. Su, X. Wang, Y .-W. Chao, and D. Fox. Anyteleop: A general vision-based dexterous robot arm-hand teleoperation system.arXiv preprint arXiv:2307.04577, 2023
arXiv 2023
-
[13]
C. Pan, C. Wang, H. Qi, Z. Liu, H. Bharadhwaj, A. Sharma, T. Wu, G. Shi, J. Malik, and F. Hogan. Spider: Scalable physics-informed dexterous retargeting.arXiv preprint arXiv:2511.09484, 2025
arXiv 2025
-
[14]
Y . Chen, C. Wang, Y . Yang, and C. K. Liu. Object-centric dexterous manipulation from human motion data.arXiv preprint arXiv:2411.04005, 2024
arXiv 2024
-
[15]
Guzey, Y
I. Guzey, Y . Dai, G. Savva, R. Bhirangi, and L. Pinto. Bridging the human to robot dexterity gap through object-oriented rewards. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 3344–3351. IEEE, 2025. 10
2025
-
[16]
Z. Chen, S. Chen, E. Arlaud, I. Laptev, and C. Schmid. Vividex: Learning vision-based dex- terous manipulation from human videos. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 3336–3343. IEEE, 2025
2025
-
[17]
X. B. Peng, P. Abbeel, S. Levine, and M. Van de Panne. Deepmimic: Example-guided deep re- inforcement learning of physics-based character skills.ACM Transactions On Graphics (TOG), 37(4):1–14, 2018
2018
-
[18]
L. Yang, X. Huang, Z. Wu, A. Kanazawa, P. Abbeel, C. Sferrazza, C. K. Liu, R. Duan, and G. Shi. Omniretarget: Interaction-preserving data generation for humanoid whole-body loco- manipulation and scene interaction.arXiv preprint arXiv:2509.26633, 2025
Pith/arXiv arXiv 2025
-
[19]
T. G. W. Lum, O. Y . Lee, C. K. Liu, and J. Bohg. Crossing the human-robot embodiment gap with sim-to-real rl using one human demonstration.arXiv preprint arXiv:2504.12609, 2025
arXiv 2025
-
[20]
P. Dan, K. Kedia, A. Chao, E. W. Duan, M. A. Pace, W.-C. Ma, and S. Choudhury. X-sim: Cross-embodiment learning via real-to-sim-to-real.ArXiv, abs/2505.07096, 2025
arXiv 2025
- [21]
-
[22]
K. Yu, S. Zhang, H. Soora, F. Huang, H. Huang, P. Tokekar, and R. Gao. Genflowrl: Shap- ing rewards with generative object-centric flow in visual reinforcement learning.ArXiv, abs/2508.11049, 2025
arXiv 2025
-
[23]
B. Sundaralingam, S. K. S. Hari, A. Fishman, C. Garrett, K. Van Wyk, V . Blukis, A. Millane, H. Oleynikova, A. Handa, F. Ramos, et al. curobo: Parallelized collision-free minimum-jerk robot motion generation.arXiv preprint arXiv:2310.17274, 2023
arXiv 2023
-
[24]
K. Yu, Y . Han, Q. Wang, V . Saxena, D. Xu, and Y . Zhao. Mimictouch: Leveraging multi-modal human tactile demonstrations for contact-rich manipulation. InConference on Robot Learning, 2023
2023
- [25]
-
[26]
Ankile, A
L. Ankile, A. Simeonov, I. Shenfeld, M. M. L. Torn ´e, and P. Agrawal. From imitation to refinement - residual rl for precise assembly.2025 IEEE International Conference on Robotics and Automation (ICRA), pages 01–08, 2024
2025
-
[27]
Y . Rong, T. Shiratori, and H. Joo. Frankmocap: A monocular 3d whole-body pose estimation system via regression and integration. InProceedings of the IEEE/CVF International Confer- ence on Computer Vision, pages 1749–1759, 2021
2021
-
[28]
A. Sivakumar, K. Shaw, and D. Pathak. Robotic telekinesis: Learning a robotic hand imitator by watching humans on youtube.arXiv preprint arXiv:2202.10448, 2022
arXiv 2022
-
[29]
T. He, Z. Luo, X. He, W. Xiao, C. Zhang, W. Zhang, K. Kitani, C. Liu, and G. Shi. Omnih2o: Universal and dexterous human-to-humanoid whole-body teleoperation and learning.arXiv preprint arXiv:2406.08858, 2024
arXiv 2024
-
[30]
Handa, K
A. Handa, K. Van Wyk, W. Yang, J. Liang, Y .-W. Chao, Q. Wan, S. Birchfield, N. Ratliff, and D. Fox. Dexpilot: Vision-based teleoperation of dexterous robotic hand-arm system. In2020 IEEE International Conference on Robotics and Automation (ICRA), pages 9164–9170. IEEE, 2020
2020
-
[31]
Y . Han, Z. Chen, K. A. Williams, and H. Ravichandar. Learning prehensile dexterity by imi- tating and emulating state-only observations.IEEE Robotics and Automation Letters, 2024. 11
2024
-
[32]
B. Zhou, H. Yuan, Y . Fu, and Z. Lu. Learning diverse bimanual dexterous manipulation skills from human demonstrations.arXiv preprint arXiv:2410.02477, 2024
arXiv 2024
-
[33]
K. Ye, Y . Wu, S. Hu, J. Li, M. Liu, Y . Chen, and R. Huang.{Gen2Real}: Towards demo- free dexterous manipulation by harnessing generated video.arXiv preprint arXiv:2509.14178, 2025
arXiv 2025
- [34]
-
[35]
H. G. Singh, A. Loquercio, C. Sferrazza, J. Wu, H. Qi, P. Abbeel, and J. Malik. Hand-object interaction pretraining from videos.2025 IEEE International Conference on Robotics and Automation (ICRA), pages 3352–3360, 2024
2025
-
[36]
X. Liu, J. Adalibieke, Q. Han, Y . Qin, and L. Yi. Dextrack: Towards generalizable neu- ral tracking control for dexterous manipulation from human references.arXiv preprint arXiv:2502.09614, 2025
arXiv 2025
-
[37]
Xu, Y .-W
S. Xu, Y .-W. Chao, L. Bian, A. Mousavian, Y .-X. Wang, L. Gui, and W. Yang. Dexplore: Scalable neural control for dexterous manipulation from reference scoped exploration. InCon- ference on Robot Learning, pages 2184–2199. PMLR, 2025
2025
-
[38]
J. Hsieh, K.-H. Tu, K.-H. Hung, and T.-W. Ke. Dexman: Learning bimanual dexterous manip- ulation from human and generated videos.arXiv preprint arXiv:2510.08475, 2025
arXiv 2025
- [39]
-
[40]
W. Ye, F. Liu, Z. Ding, Y . Gao, O. Rybkin, and P. Abbeel. Video2policy: Scaling up manipu- lation tasks in simulation through internet videos.arXiv preprint arXiv:2502.09886, 2025
arXiv 2025
-
[41]
Katara, Z
P. Katara, Z. Xian, and K. Fragkiadaki. Gen2sim: Scaling up robot learning in simulation with generative models. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6672–6679. IEEE, 2024
2024
- [42]
-
[43]
J. Yu, K. Hari, K. El-Refai, A. Dalal, J. Kerr, C. M. Kim, R. Cheng, M. Z. Irshad, and K. Gold- berg. Persistent object gaussian splat (pogs) for tracking human and robot manipulation of irregularly shaped objects.arXiv preprint arXiv:2503.05189, 2025
arXiv 2025
-
[44]
Z. Q. Chen, A. Walsman, M. Memmel, K. Mo, A. Fang, K. Vemuri, A. Wu, D. Fox, and A. Gupta. Urdformer: A pipeline for constructing articulated simulation environments from real-world images.ArXiv, abs/2405.11656, 2024
arXiv 2024
-
[45]
H. Jiang, H.-Y . Hsu, K. Zhang, H.-N. Yu, S. Wang, and Y . Li. Phystwin: Physics-informed reconstruction and simulation of deformable objects from videos.ArXiv, abs/2503.17973, 2025
arXiv 2025
-
[46]
Patel, X
S. Patel, X. Yin, W. Huang, S. Garg, H. Nayyeri, F.-F. Li, S. Lazebnik, and Y . Li. A real-to- sim-to-real approach to robotic manipulation with vlm-generated iterative keypoint rewards. 2025 IEEE International Conference on Robotics and Automation (ICRA), pages 8258–8266, 2025
2025
-
[47]
A. Maddukuri, Z. Jiang, L. Y . Chen, S. Nasiriany, Y . Xie, Y . Fang, W. Huang, Z. Wang, Z. Xu, N. Chernyadev, S. Reed, K. Goldberg, A. Mandlekar, L. Fan, and Y . Zhu. Sim-and-real co- training: A simple recipe for vision-based robotic manipulation.ArXiv, abs/2503.24361, 2025. 12
arXiv 2025
-
[48]
Jiang, Y
Z. Jiang, Y . Xie, K. Lin, Z. Xu, W. Wan, A. Mandlekar, L. Fan, and Y . Zhu. Dexmimicgen: Automated data generation for bimanual dexterous manipulation via imitation learning.2025 IEEE International Conference on Robotics and Automation (ICRA), pages 16923–16930, 2024
2025
-
[49]
L. Wang, R. Guo, Q. H. Vuong, Y . Qin, H. Su, and H. I. Christensen. A real2sim2real method for robust object grasping with neural surface reconstruction.2023 IEEE 19th International Conference on Automation Science and Engineering (CASE), pages 1–8, 2022
2023
-
[50]
M. Lepert, J. Fang, and J. Bohg. Phantom: Training robots without robots using only human videos.ArXiv, abs/2503.00779, 2025
Pith/arXiv arXiv 2025
-
[51]
J. Yu, L. Fu, H. Huang, K. El-Refai, R. Ambrus, R. Cheng, M. Z. Irshad, and K. Goldberg. Real2render2real: Scaling robot data without dynamics simulation or robot hardware.ArXiv, abs/2505.09601, 2025
arXiv 2025
-
[52]
Tobin, R
J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel. Domain randomiza- tion for transferring deep neural networks from simulation to the real world.2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 23–30, 2017
2017
-
[53]
J. Mu, S. Yang, Y . Bao, H. Bae, T. Wei, L. Xu, B. Li, H. Xu, and J. Pang. Deximit: Learning bimanual dexterous manipulation from monocular human videos.arXiv preprint arXiv:2602.10105, 2026
arXiv 2026
-
[54]
H. Chen, T. Dong, T. Wu, L. Wang, Y . Jangir, Y . Niu, Y . Ye, H. Bharadhwaj, Z. Erickson, and J. Ichnowski. Dexterous manipulation policies from rgb human videos via 3d hand-object trajectory reconstruction, 2026
2026
-
[55]
G. Team. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of con- text.ArXiv, abs/2403.05530, 2024
Pith/arXiv arXiv 2024
-
[56]
N. Carion, L. Gustafson, Y .-T. Hu, S. Debnath, R. Hu, D. Suris, C. Ryali, K. V . Alwala, H. Khedr, A. Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
Pith/arXiv arXiv 2025
-
[57]
X. Chen, F.-J. Chu, P. Gleize, K. J. Liang, A. Sax, H. Tang, W. Wang, M. Guo, T. Hardin, X. Li, et al. Sam 3d: 3dfy anything in images.arXiv preprint arXiv:2511.16624, 2025
Pith/arXiv arXiv 2025
-
[58]
K. Zakka. Mink: Python inverse kinematics based on MuJoCo, May 2025. URLhttps: //github.com/kevinzakka/mink
2025
- [59]
- [60]
-
[61]
Z. Xue, S. Deng, Z. Chen, Y . Wang, Z. Yuan, and H. Xu. Demogen: Synthetic demonstration generation for data-efficient visuomotor policy learning.ArXiv, abs/2502.16932, 2025
arXiv 2025
-
[62]
Y . Ze, G. Zhang, K. Zhang, C. Hu, M. Wang, and H. Xu. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations.arXiv preprint arXiv:2403.03954, 2024
Pith/arXiv arXiv 2024
-
[63]
N. R. Arachchige, Z. Chen, W. Jung, W. C. Shin, R. Bansal, P. Barroso, Y . H. He, Y . C. Lin, B. Joffe, S. Kousik, et al. Sail: Faster-than-demonstration execution of imitation learning policies.arXiv preprint arXiv:2506.11948, 2025. 13
arXiv 2025
-
[64]
C. R. Qi, H. Su, K. Mo, and L. J. Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 652–660, 2017
2017
-
[65]
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[66]
K. Shaw, A. Agarwal, and D. Pathak. Leap hand: Low-cost, efficient, and anthropomorphic hand for robot learning.arXiv preprint arXiv:2309.06440, 2023
arXiv 2023
-
[67]
V . Makoviychuk, L. Wawrzyniak, Y . Guo, M. Lu, K. Storey, M. Macklin, D. Hoeller, N. Rudin, A. Allshire, A. Handa, et al. Isaac gym: High performance gpu-based physics simulation for robot learning.arXiv preprint arXiv:2108.10470, 2021
Pith/arXiv arXiv 2021
-
[68]
B. Wen, W. Yang, J. Kautz, and S. Birchfield. Foundationpose: Unified 6d pose estimation and tracking of novel objects. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17868–17879, 2024
2024
-
[69]
Y . Gan, L. Zhu, D. Shan, B. Shi, H. Yin, B. Ivanovic, S. Han, T. Darrell, J. Malik, M. Pavone, et al. Foundationmotion: Auto-labeling and reasoning about spatial movement in videos.arXiv preprint arXiv:2512.10927, 2025
arXiv 2025
-
[70]
Z. Cao, F. Hong, Z. Chen, L. Pan, and Z. Liu. Physx-anything: Simulation-ready physical 3d assets from single image.arXiv preprint arXiv:2511.13648, 2025
arXiv 2025
-
[71]
H. Xia, E. Su, M. Memmel, A. Jain, R. Yu, N. Mbiziwo-Tiapo, A. Farhadi, A. Gupta, S. Wang, and W.-C. Ma. Drawer: Digital reconstruction and articulation with environment realism. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 21771–21782, 2025
2025
-
[72]
H. Xia, X. Li, Z. Li, Q. Ma, J. Xu, M.-Y . Liu, Y . Cui, T.-Y . Lin, W.-C. Ma, S. Wang, S. Song, and F. Wei. Sage: Scalable agentic 3d scene generation for embodied ai, 2026
2026
-
[73]
Pfaff, T
N. Pfaff, T. Cohn, S. Zakharov, R. Cory, and R. Tedrake. Scenesmith: Agentic generation of simulation-ready indoor scenes, 2026
2026
-
[74]
H. Lin, S. Chen, J. Liew, D. Y . Chen, Z. Li, G. Shi, J. Feng, and B. Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
Pith/arXiv arXiv 2025
-
[75]
S. Guo, X. Yu, Y . Sha, Y . Ju, M. Zhu, and J. Wang. Online camera auto-calibration appliable to road surveillance.Machine Vision and Applications, 35(4):91, 2024. 14 Appendices A Module details In this section, we provide the implementation details of each module. A.1 Off-the-shelf Estimation Modules The off-the-shelf estimation modules are primarily use...
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.