Bridging the Modality Gap in Forensic Image Retrieval
Pith reviewed 2026-06-27 10:04 UTC · model grok-4.3
The pith
Fusing text descriptions from an MLLM with visual embeddings raises retrieval precision on forensic tattoos, sketches and faces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
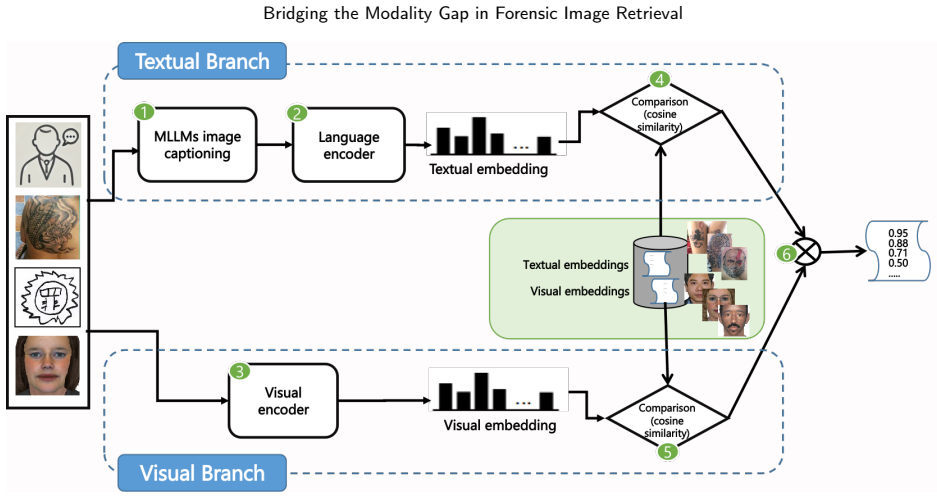
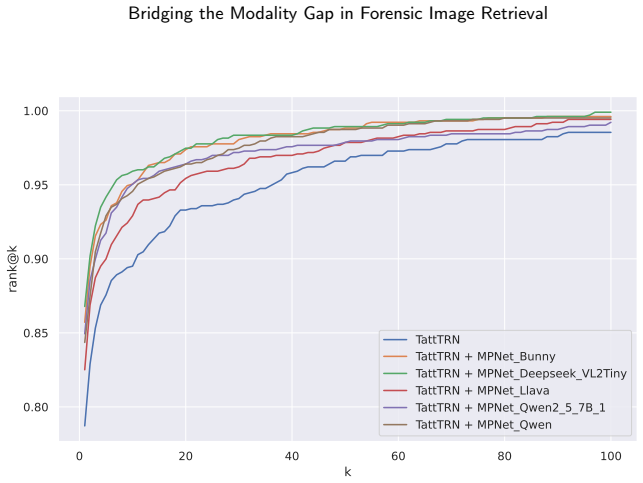
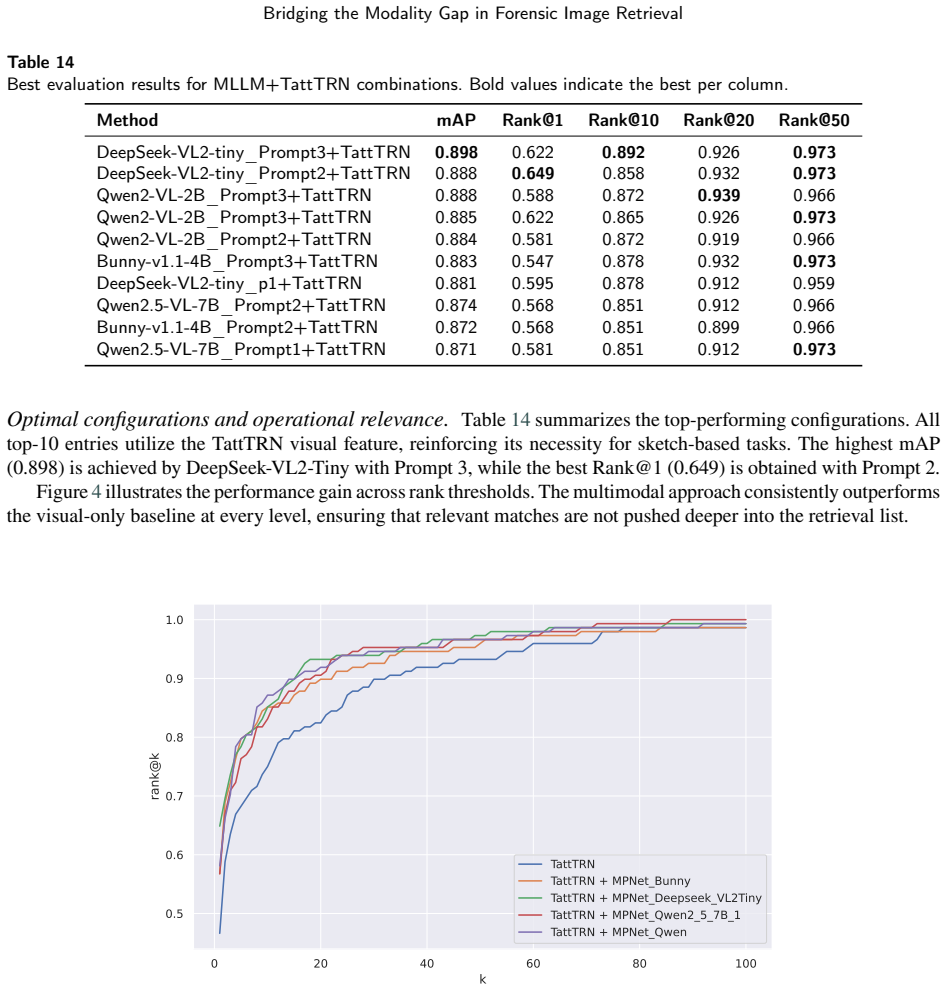
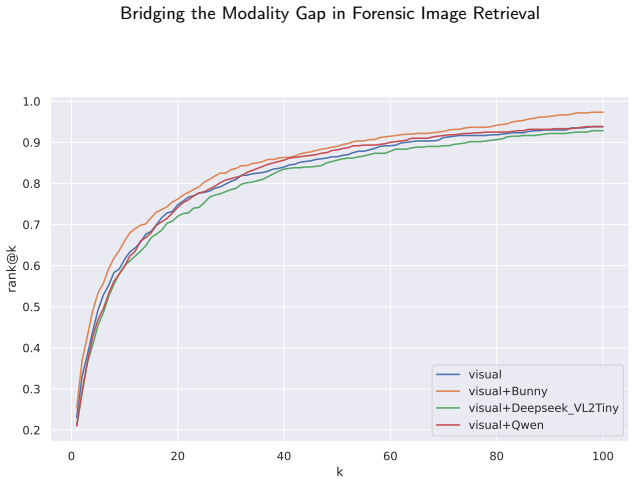
The paper claims that a multimodal retrieval pipeline, which automatically produces structured textual descriptions via an MLLM for all inputs and then fuses text-based and image-based similarity scores, consistently improves retrieval precision and robustness over visual-only or text-only baselines across tattoo image retrieval, text-guided tattoo retrieval, sketch-guided tattoo retrieval, and forensic face sketch retrieval.
What carries the argument
The multimodal fusion strategy that combines text- and image-based similarity scores derived from state-of-the-art visual feature extractors relevant to each task.
If this is right
- Tattoo retrieval from witness descriptions or hand-drawn sketches becomes more reliable than visual matching alone.
- Face retrieval from forensic sketches gains robustness when text descriptions supplement the sketch.
- A single pipeline can address multiple evidence types without task-specific redesign.
- Tasks that traditionally require manual expert comparison can be partially automated.
- Retrieval performance holds up better under noisy or partial visual input.
Where Pith is reading between the lines
- Investigators could query databases using only a verbal description without needing a reference image.
- The same fusion approach might extend to other forensic evidence such as clothing or vehicle descriptions.
- Integration into existing case-management systems could shorten the time between receiving a witness statement and generating candidate matches.
- Performance on very large galleries would need separate validation to confirm the observed gains scale.
Load-bearing premise
Automatically generated textual descriptions from the MLLM accurately and consistently capture the forensic-relevant features needed for effective text-based retrieval.
What would settle it
A controlled test set in which MLLM descriptions systematically omit or misrepresent key distinguishing marks, after which the fused scores show no gain or a drop in precision relative to visual-only retrieval.
Figures
read the original abstract
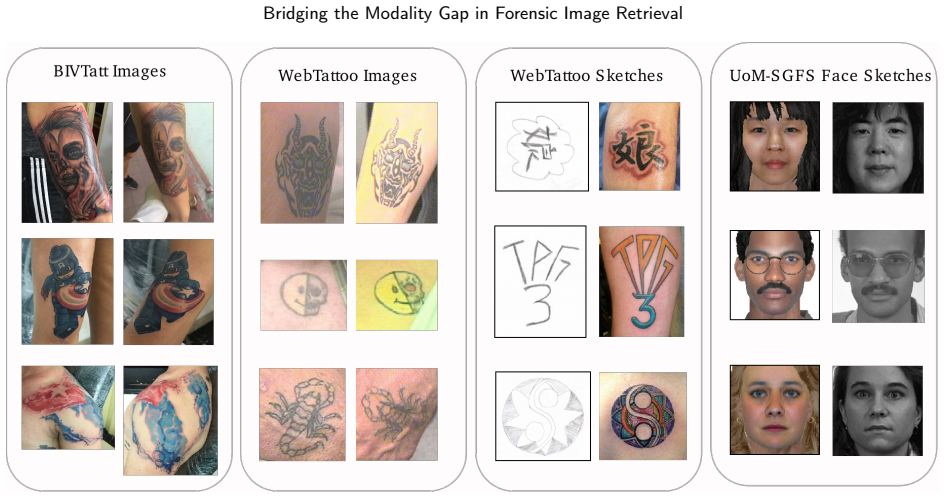
Automated image retrieval plays an increasingly critical role in modern forensic analysis, supporting investigative workflows that rely on efficient comparison of visual evidence. While prior work has focused primarily on developing and optimizing multimodal retrieval systems, limited attention has been paid to evaluating the forensic applicability of these technologies across diverse real-world scenarios. In this study, we present a unified retrieval framework adapted to four key forensic tasks: (1) tattoo image retrieval given a tattoo query image; (2) tattoo retrieval guided by human-expert textual descriptions, modelling the common situation where a witness verbally describes a tattoo; (3) tattoo retrieval from hand-drawn sketches; and (4) face retrieval from forensic face sketches. Our system leverages a multimodal large language model (MLLM) to automatically generate structured textual descriptions for all queries and gallery images, followed by sentence-transformer embedding for text-based comparison. We evaluate retrieval using visual-only embeddings, text-only embeddings and a multimodal fusion strategy that combines text- and image-based similarity scores derived from state-of-the-art visual feature extractors relevant to each task. The fusion of modalities consistently improves retrieval precision and robustness, especially in scenarios where visual information is limited or noisy (e.g., sketches, partial tattoos, or fragmented witness statements). This work highlights the forensic value of a unified multimodal retrieval pipeline and demonstrates how modern MLLMs can operationalize challenging forensic tasks that traditionally rely on manual expert analysis. Our results position multimodal retrieval as a promising tool for supporting investigative workflows involving tattoos, facial composites, and witness descriptions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a unified multimodal retrieval framework for four forensic tasks: tattoo retrieval from images, from expert textual descriptions, from hand-drawn sketches, and face retrieval from forensic sketches. It uses an MLLM to auto-generate structured textual descriptions for queries and gallery items, sentence-transformer embeddings for text-based retrieval, and score-level fusion with task-specific visual CNN embeddings. The central claim is that multimodal fusion consistently improves retrieval precision and robustness over visual-only or text-only baselines, especially when visual information is limited or noisy.
Significance. If the MLLM-generated descriptions prove reliable and the reported gains hold under rigorous controls, the work could offer a practical pipeline for forensic workflows that currently rely on manual expert matching of tattoos and sketches. The unified treatment of four distinct tasks and the emphasis on real-world noisy inputs are strengths, but the absence of any validation for the generated text descriptions makes the significance conditional on untested assumptions.
major comments (2)
- [Evaluation / Results] The headline result (fusion improves precision and robustness) is load-bearing on the assumption that MLLM-generated descriptions accurately capture the same discriminative forensic attributes used by visual CNNs or human experts. No human validation, inter-annotator agreement, or ablation replacing MLLM text with expert annotations is reported for any of the four tasks.
- [Abstract] Abstract and §4 (presumed experimental section): the claim of 'consistent improvement' is stated without any quantitative metrics, datasets, baselines, or error analysis supplied in the provided abstract; the soundness of the fusion claim cannot be evaluated from the given material.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on validation of MLLM descriptions and the presentation of quantitative claims. We address each major comment below and outline planned revisions.
read point-by-point responses
-
Referee: [Evaluation / Results] The headline result (fusion improves precision and robustness) is load-bearing on the assumption that MLLM-generated descriptions accurately capture the same discriminative forensic attributes used by visual CNNs or human experts. No human validation, inter-annotator agreement, or ablation replacing MLLM text with expert annotations is reported for any of the four tasks.
Authors: We agree this is a substantive gap: the manuscript does not report human validation, inter-annotator agreement, or expert-annotation ablations for the MLLM text. The reported fusion gains are empirical but rest on the untested assumption that the generated descriptions align with forensic-discriminative attributes. In revision we will add a dedicated qualitative analysis subsection with side-by-side examples of MLLM outputs versus image content for each task, plus an explicit limitations paragraph acknowledging the lack of expert validation and outlining how such studies could be conducted in future work. revision: yes
-
Referee: [Abstract] Abstract and §4 (presumed experimental section): the claim of 'consistent improvement' is stated without any quantitative metrics, datasets, baselines, or error analysis supplied in the provided abstract; the soundness of the fusion claim cannot be evaluated from the given material.
Authors: The abstract is written as a high-level summary following standard length constraints and therefore omits specific numbers. All quantitative results (precision@K improvements, datasets, baselines, and error analysis) appear in the experimental section. We will revise the abstract to incorporate representative quantitative findings (e.g., average precision gains under fusion) while remaining within length limits. revision: yes
Circularity Check
No circularity: purely empirical evaluation of off-the-shelf components
full rationale
The manuscript presents an empirical comparison of visual-only, text-only, and fused retrieval pipelines across four forensic tasks. It applies an existing MLLM for description generation, a sentence-transformer for text embeddings, and task-specific visual CNNs, then reports standard retrieval metrics. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the derivation of results. The central claim (fusion improves performance) is supported by direct experimental outcomes rather than any self-referential reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Criminalistic Human Identification from Scar And Tattoo Marks
Balan, L., 2020. Criminalistic Human Identification from Scar And Tattoo Marks. European Journal of Law and Public Administration 7, 61–67
2020
-
[2]
Sketch-Based Multimodal Image Retrieval Using Deep Learning
Berno, B.C.S., 2021. Sketch-Based Multimodal Image Retrieval Using Deep Learning. Ph.D. thesis. Universidade Tecnológica Federal do Paraná, Curitiba. Programa de Pós-Graduação em Engenharia Elétrica e Informática Industrial
2021
-
[3]
Tattooinformationcreation:Towardsaholisticunderstandingoftattooinformationexperience
Campbell-Meier,J.,Krtalić,M.,2022. Tattooinformationcreation:Towardsaholisticunderstandingoftattooinformationexperience. Library and Information Science Research 44, 101161–101161. doi:doi.org/10.1016/j.lisr.2022.101161
-
[4]
Training-freein-contextforensicchainforimagemanipulation detection and localization
Chen,R.,Liu,B.,Miao,C.,Wang,X.,Li,Y.,Gong,T.,Chu,Q.,Yu,N.,2025. Training-freein-contextforensicchainforimagemanipulation detection and localization. URL:https://arxiv.org/abs/2510.10111, arXiv:2510.10111
arXiv 2025
-
[5]
Mobilefacenets:Efficientcnnsforaccuratereal-timefaceverificationonmobiledevices,in:Chinese conference on biometric recognition, Springer
Chen,S.,Liu,Y.,Gao,X.,Han,Z.,2018. Mobilefacenets:Efficientcnnsforaccuratereal-timefaceverificationonmobiledevices,in:Chinese conference on biometric recognition, Springer. pp. 428–438
2018
-
[6]
Big Data and Cognitive Computing 9
Colangelo,M.T.,Meleti,M.,Guizzardi,S.,Calciolari,E.,Galli,C.,2025.Acomparativeanalysisofsentencetransformermodelsforautomated journal recommendation using pubmed metadata. Big Data and Cognitive Computing 9. URL:https://www.mdpi.com/2504-2289/9/ 3/67, doi:10.3390/bdcc9030067
-
[7]
Arcface: Additive angular margin loss for deep face recognition, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp
Deng, J., Guo, J., Xue, N., Zafeiriou, S., 2019. Arcface: Additive angular margin loss for deep face recognition, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 4690–4699. First Author et al.:Preprint submitted to Elsevier Page 21 of 23 Bridging the Modality Gap in Forensic Image Retrieval
2019
-
[8]
A survey on composed image retrieval
Du, L., Deng, S., Li, Y., Li, J., Tian, Q., 2025. A survey on composed image retrieval. ACM Trans. Multimedia Comput. Commun. Appl. doi:10.1145/3723879
-
[9]
Galea, C., Farrugia, R.A., 2016. A large-scale software-generated face composite sketch database, in: 2016 International Conference of the Biometrics Special Interest Group (BIOSIG), pp. 1–5. doi:10.1109/BIOSIG.2016.7736902
-
[10]
González-Gazapo, R., Morales-González, A., Méndez-Vázquez, H., García-Borroto, M., 2025. Comprehensive evaluation of multimodal large language models for tattoo identification, in: 28th Iberoamerican Congress on Pattern Recognition, CIARP 2025, Bogotá, Colombia, November 25-28, 2025, Proceedings, Accepted to be published by Springer-Verlag
2025
-
[11]
Tatttrn: Template reconstruction network for tattoo retrieval, in: Proc
Gonzalez-Soler, L., Salwowski, M., Rathgeb, C., Fischer, D., 2024. Tatttrn: Template reconstruction network for tattoo retrieval, in: Proc. IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR)
2024
-
[12]
Tattoo based identification: Sketch to image matching
Han, H., Jain, A.K., 2013. Tattoo based identification: Sketch to image matching. 2013 International Conference on Biometrics (ICB) , 1–8URL:https://api.semanticscholar.org/CorpusID:18515563
2013
-
[13]
Tattoo image search at scale: Joint detection and compact representation learning
Han, H., Li, J., Jain, A.K., Shan, S., Chen, X., 2019. Tattoo image search at scale: Joint detection and compact representation learning. IEEE Transactions on Pattern Analysis and Machine Intelligence 41, 2333–2348. doi:10.1109/TPAMI.2019.2891584
-
[14]
Efficient multimodal learning from data-centric perspective
He, M., Liu, Y., Wu, B., Yuan, J., Wang, Y., Huang, T., Zhao, B., 2024. Efficient multimodal learning from data-centric perspective. arXiv preprint arXiv:2402.11530
arXiv 2024
-
[15]
Vlforgery face triad: Detection, localization and attribution via multimodal large language models
He, X., Zhou, Y., Fan, B., Li, B., Zhu, G., Ding, F., 2025. Vlforgery face triad: Detection, localization and attribution via multimodal large language models. URL:https://arxiv.org/abs/2503.06142, arXiv:2503.06142
arXiv 2025
-
[16]
Tattoo recognition technology is gaining acceptance as a crime-solving technique
Hodge, Jr., S.D., Meehan, J., 2021. Tattoo recognition technology is gaining acceptance as a crime-solving technique. Northern Illinois University Law Review 42
2021
-
[17]
Ontheforensicvalueoftattoosforhumanidentification–aliteraturereview
Ibrahim,E.,Canal,R.,Silva,R.F.,Heit,O.F.J.,Franco,A.,2024. Ontheforensicvalueoftattoosforhumanidentification–aliteraturereview. Revista Brasileira de Odontologia Legal 11
2024
-
[18]
Vision-by-language for training-free compositional image retrieval
Karthik, S., Roth, K., Mancini, M., Akata, Z., 2024. Vision-by-language for training-free compositional image retrieval. International Conference on Learning Representations (ICLR)
2024
-
[19]
Kiani Galoogahi, H., Sim, T., 2012. Face photo retrieval by sketch example, in: Proceedings of the 20th ACM International Conference on Multimedia, Association for Computing Machinery, New York, NY, USA. p. 949–952. URL:https://doi.org/10.1145/2393347. 2396354, doi:10.1145/2393347.2396354
-
[20]
Kim, J., Pozo, A.P., Yue, J., Li, H., Delp, E.J., 2015. Robust local and global shape context for tattoo image matching, in: 2015 IEEE International Conference on Image Processing, ICIP 2015, Quebec City, QC, Canada, September 27-30, 2015, IEEE. pp. 2194–2198. doi:10.1109/ICIP.2015.7351190
-
[21]
Bridging modalities: A survey of cross-modal image-text retrieval
Li, T., Kong, L., Yang, X., Wang, B., Xu, J., 2024. Bridging modalities: A survey of cross-modal image-text retrieval. Chinese Journal of Information Fusion 1, 79–92. URL:https://doi.org/10.62762/CJIF.2024.361895, doi:10.62762/CJIF.2024.361895
-
[22]
Visual instruction tuning, in: NeurIPS
Liu, H., Li, C., Wu, Q., Lee, Y.J., 2023. Visual instruction tuning, in: NeurIPS
2023
-
[23]
Martindez-Diaz, Y., Luevano, L.S., Mendez-Vazquez, H., Nicolas-Diaz, M., Chang, L., Gonzalez-Mendoza, M., 2019. Shufflefacenet: A lightweight face architecture for efficient and highly-accurate face recognition, in: Proceedings of the IEEE/CVF international conference on computer vision workshops, pp. 0–0
2019
-
[24]
Bench- marking lightweight face architectures on specific face recognition scenarios
Martínez-Díaz, Y., Nicolás-Díaz, M., Méndez-Vázquez, H., Luevano, L.S., Chang, L., Gonzalez-Mendoza, M., Sucar, L.E., 2021. Bench- marking lightweight face architectures on specific face recognition scenarios. Artif. Intell. Rev. 54, 6201–6244. URL:https://doi.org/ 10.1007/s10462-021-09974-2, doi:10.1007/s10462-021-09974-2
-
[25]
Morales-González,A.,Méndez-Vázquez,H.,García-Borroto,M.,2025. Multimodaltattoorecognitionbycombiningvisualfeaturesandllm- generated captions, in: IX International Congress on Artificial Intelligence and Pattern Recognition, IWAIPR 2025, Varadero, Cuba, October 14-17, 2025, Proceedings, Accepted to be published by Springer-Verlag
2025
-
[26]
Nicolás-Díaz, M., Morales-González, A., Méndez-Vázquez, H., 2019. Deep generic features for tattoo identification, in: Progress in Pattern Recognition,ImageAnalysis,ComputerVision,andApplications:24thIberoamericanCongress,CIARP2019,Havana,Cuba,October28-31, 2019, Proceedings, Springer-Verlag, Berlin, Heidelberg. p. 272–282
2019
-
[27]
Weighted average pooling of deep features for tattoo identification
Nicolás-Díaz, M., Morales-González, A., Méndez-Vázquez, H., 2022. Weighted average pooling of deep features for tattoo identification. Multimedia Tools Appl. 81, 25853–25875
2022
-
[28]
Approach for tattoo detection and identification based on yolov5 and similarity distance
Pocevič˙e, G., Stefanovič, P., Ramanauskait˙e, S., Pavlov, E., 2024. Approach for tattoo detection and identification based on yolov5 and similarity distance. Applied Sciences 14, 5576. doi:10.3390/app14135576
-
[29]
Learning transferable visual models from natural language supervision, in: Proceedings of the 38th International Conference on Machine Learning, PMLR
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I., 2021. Learning transferable visual models from natural language supervision, in: Proceedings of the 38th International Conference on Machine Learning, PMLR. pp. 8748–8763
2021
-
[30]
da Silva, R.T., Silvério Lopes, H., 2022. A transfer learning approach for the tattoo classification problem, in: 2022 IEEE Latin American Conference on Computational Intelligence (LA-CCI), pp. 1–6. doi:10.1109/LA-CCI54402.2022.9981650
-
[31]
Sohail, A., Patel, O.M., Choi, J., Venditti, J.C.S., Wu, A.J., 2025. Benchmarking multimodal large language models for forensic science and medicine: A comprehensive dataset and evaluation framework. medRxiv URL: https: //www.medrxiv.org/content/early/2025/07/07/2025.07.06.25330972, doi: 10.1101/2025.07.06.25330972, arXiv:https://www.medrxiv.org/content/e...
-
[32]
Song, K., Tan, X., Qin, T., Lu, J., Liu, T.Y., 2020. Mpnet: masked and permuted pre-training for language understanding, in: Proceedings of the 34th International Conference on Neural Information Processing Systems, Curran Associates Inc., Red Hook, NY, USA
2020
-
[33]
Análisis forense de imágenes de tatuajes para identificación de individuos
Teruel Leyva, L., Lucena de Ustariz, M.E., 2025. Análisis forense de imágenes de tatuajes para identificación de individuos. RECIMUNDO 9, 238–251
2025
-
[34]
Vasilaras,A.,Papadoudis,N.,Rizomiliotis,P.,2024. Artificialintelligenceinmobileforensics:Asurveyofcurrentstatus,ausecaseanalysis and ai alignment objectives. Forensic Science International: Digital Investigation 49, 301737. URL:https://www.sciencedirect.com/ First Author et al.:Preprint submitted to Elsevier Page 22 of 23 Bridging the Modality Gap in Fore...
-
[35]
Localdeepfeaturesforcompositefacesketch recognition
Vazquez,H.M.,Becerra-Riera,F.,Morales-González,A.,López-Avila,L.,Tistarelli,M.,2019. Localdeepfeaturesforcompositefacesketch recognition. 2019 7th International Workshop on Biometrics and Forensics (IWBF) , 1–6URL:https://api.semanticscholar.org/ CorpusID:195222350
2019
-
[36]
Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., Fan, Y., Dang, K., Du, M., Ren, X., Men, R., Liu, D., Zhou, C., Zhou, J., Lin, J., 2024. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191
Pith/arXiv arXiv 2024
-
[37]
Wickramasekara, A., Breitinger, F., Scanlon, M., 2025. Exploring the potential of large language models for improving digital forensic investigation efficiency. Forensic Science International: Digital Investigation 52, 301859. URL:https://www.sciencedirect.com/ science/article/pii/S2666281724001860, doi:https://doi.org/10.1016/j.fsidi.2024.301859
-
[38]
Training-freezero-shotcomposedimageretrievalviaweightedmodalityfusionandsimilarity
Wu,R.D.,Lin,Y.Y.,Yang,H.F.,2024a. Training-freezero-shotcomposedimageretrievalviaweightedmodalityfusionandsimilarity. URL: https://arxiv.org/abs/2409.04918, arXiv:2409.04918
-
[39]
Deepseek-vl2: Mixture-of-experts vision-language models for advanced multimodal understanding
Wu,Z.,Chen,X.,Pan,Z.,Liu,X.,Liu,W.,Dai,D.,Gao,H.,Ma,Y.,Wu,C.,Wang,B.,Xie,Z.,Wu,Y.,Hu,K.,Wang,J.,Sun,Y.,Li,Y.,Piao, Y., Guan, K., Liu, A., Xie, X., You, Y., Dong, K., Yu, X., Zhang, H., Zhao, L., Wang, Y., Ruan, C., 2024b. Deepseek-vl2: Mixture-of-experts vision-language models for advanced multimodal understanding. URL:https://arxiv.org/abs/2412.10302, ar...
-
[40]
TattoosinForensics:Retrieval,DetectionandSynthesis
Xu,X.,2021. TattoosinForensics:Retrieval,DetectionandSynthesis. Ph.D.thesis.SchoolofComputerScienceandEngineering,Forensics and Security Lab. doi:10.32657/10356/151535
-
[41]
Yang,Z.,Xue,D.,Qian,S.,Dong,W.,Xu,C.,2024.Ldre:Llm-baseddivergentreasoningandensembleforzero-shotcomposedimageretrieval, in: Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, Association for Computing Machinery, New York, NY, USA. p. 80–90. doi:10.1145/3626772.3657740. First Author et al.:Prep...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.