MM-TRELLIS: Point-Cloud Guided Multi-Modal 3D Vehicle Generation in Autonomous Driving
Pith reviewed 2026-06-26 00:55 UTC · model grok-4.3
The pith
Integrating LiDAR point clouds with multi-view images in 3D generative models produces higher-fidelity vehicle meshes from driving scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
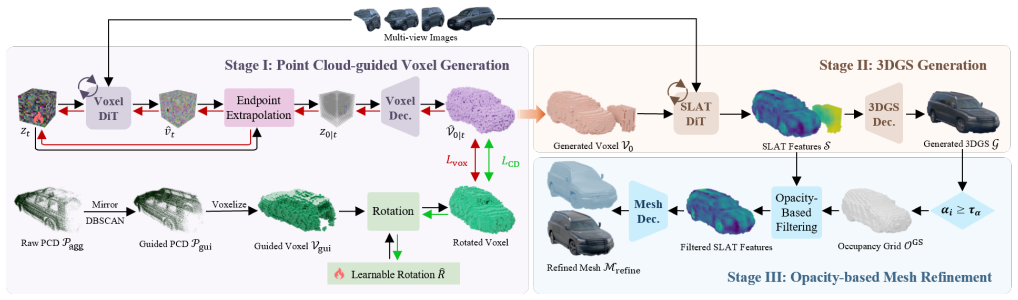
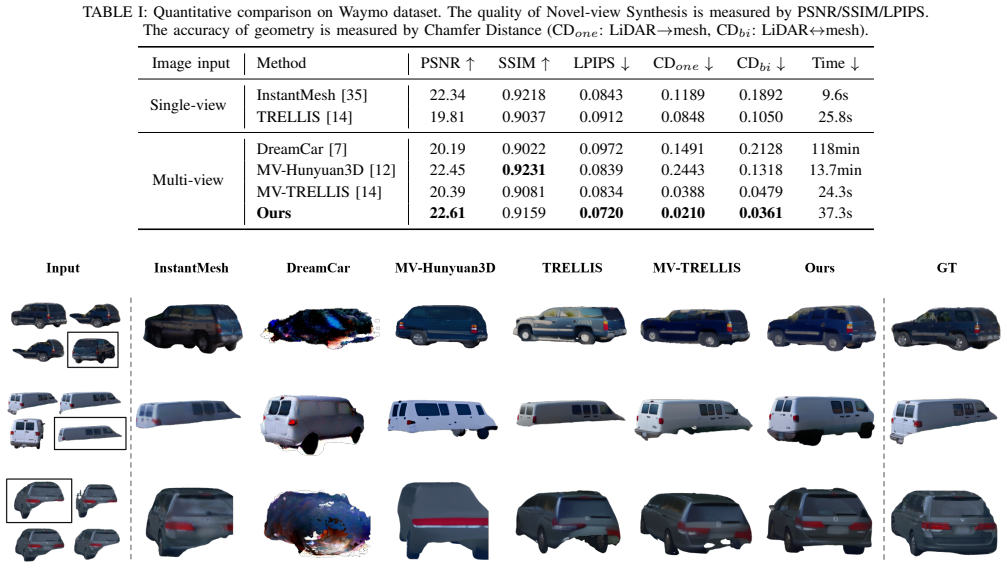
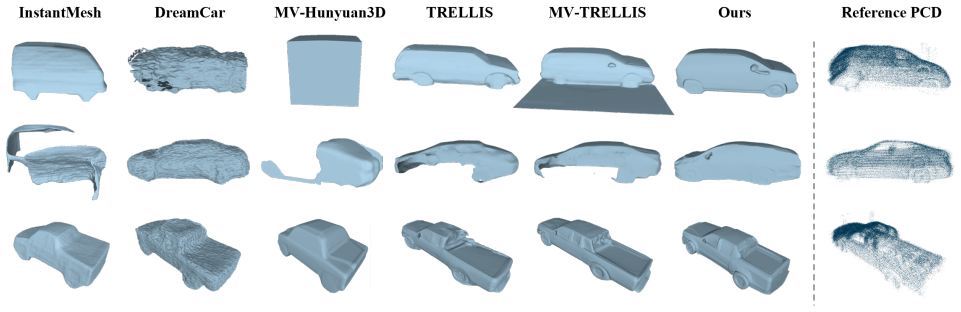
The central claim is that by cycling multi-view images as conditioning inputs and providing test-time LiDAR point cloud guidance to align with model priors and enforce consistency in the generated geometry, combined with voxel filtering based on 3D Gaussian Splatting opacity, MM-TRELLIS achieves superior high-fidelity 3D vehicle generation on the Waymo dataset over existing methods.
What carries the argument
LiDAR point cloud guidance during the denoising process, where the guidance is first aligned with model priors and then used to enforce consistency between generated geometry and the point cloud.
If this is right
- The generated models show improved geometric accuracy and cross-view consistency.
- Voxel filtering suppresses floaters leading to cleaner meshes.
- Performance exceeds that of prior vehicle generation techniques on real-world driving data.
- Native 3D generative models can be adapted for arbitrary multi-view inputs from driving scenes.
Where Pith is reading between the lines
- Similar guidance strategies might help other generative tasks involving in-the-wild data with available sensor measurements.
- The method implies that test-time enforcement of physical measurements can bridge gaps in current generative model capabilities.
- Applications could extend to generating full scenes rather than isolated vehicles if LiDAR covers broader areas.
Load-bearing premise
That the specific combination of image cycling, point cloud alignment and consistency enforcement, and opacity voxel filtering will reliably produce high-quality meshes without introducing new artifacts or degrading visual fidelity.
What would settle it
Running the method on Waymo dataset samples and finding that the output meshes contain more floaters or lower fidelity scores than competing approaches would disprove the performance advantage.
Figures




read the original abstract
Recovering realistic 3D vehicle models from autonomous driving scenes is crucial for synthesizing training data and building simulation environment. However, most existing vehicle generation methods fail to fully exploit multimodal sensors i.e. multi-view images and LiDAR point clouds) and rely on neural rendering based reconstruction, leading to low-quality mesh. Recently, native 3D generative models have made significant progress, yet they are not built for arbitrary multi-view inputs and often struggle with in-the-wild driving images. In this work, we present MM-TRELLIS, a multi-modal version of TRELLIS for in-the-wild 3D vehicle generation that integrates LiDAR and image sensors from autonomous driving datasets into native 3D generative models. Specifically, multi-view images are cycled as conditioning inputs, while LiDAR point clouds provide test-time guidance to ensure geometric accuracy and cross-view consistency. During denoising, we first align the guidance point cloud with the model priors, then enforce consistency between the generated geometry and the guidance point cloud. Finally, we introduce a voxel filtering strategy based on the opacity of 3D Gaussian Splatting to suppress floaters and produce clean meshes. Comprehensive experiments on Waymo dataset demonstrate our method outperforms existing methods in high-fidelity 3D vehicle generation. Code is available at https://github.com/HongliXiao/MM-TRELLIS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MM-TRELLIS, a multi-modal extension of TRELLIS for 3D vehicle generation from autonomous driving scenes. Multi-view images are cycled as conditioning inputs while LiDAR point clouds supply test-time guidance; during denoising the guidance cloud is aligned with model priors and consistency is enforced between generated geometry and the cloud. An opacity-based voxel filter derived from 3D Gaussian Splatting is used to suppress floaters and yield clean meshes. The method is claimed to outperform prior approaches on the Waymo dataset for high-fidelity 3D vehicle generation, with code released at https://github.com/HongliXiao/MM-TRELLIS.
Significance. If the quantitative results support the claims, the work offers a practical engineering route to higher-quality 3D assets for driving simulation by fusing image and LiDAR modalities inside a native 3D generative backbone. The public code release is a clear strength for reproducibility. The magnitude of any improvement, however, cannot be assessed from the information supplied.
major comments (1)
- [Abstract] Abstract: the central claim that the method 'outperforms existing methods in high-fidelity 3D vehicle generation' on Waymo is unsupported because no metrics, baselines, ablation tables, or experimental protocol are provided. Without these data it is impossible to determine whether the reported improvements are real or merely asserted.
minor comments (2)
- The description of the alignment step between the guidance point cloud and model priors during denoising is too brief to allow replication; a concrete procedure or pseudocode would help.
- The voxel-filtering strategy based on 3DGS opacity is introduced without stating the opacity threshold, voxel resolution, or any ablation that isolates its contribution to mesh cleanliness.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comment on the abstract. We agree that the performance claim requires explicit quantitative support within the abstract itself and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the method 'outperforms existing methods in high-fidelity 3D vehicle generation' on Waymo is unsupported because no metrics, baselines, ablation tables, or experimental protocol are provided. Without these data it is impossible to determine whether the reported improvements are real or merely asserted.
Authors: We agree with the referee that the abstract should contain concrete metrics to substantiate the claim rather than relying solely on the Experiments section. The full manuscript already includes quantitative comparisons (metrics such as geometric fidelity measures, baselines from prior 3D generation methods, ablation studies, and the full Waymo evaluation protocol). In the revised version we will update the abstract to explicitly report key numerical results and briefly reference the experimental setup, ensuring the outperforming statement is directly supported by data. revision: yes
Circularity Check
No significant circularity identified
full rationale
The provided manuscript text describes MM-TRELLIS as a practical engineering extension that cycles multi-view images for conditioning, applies LiDAR point-cloud alignment and consistency enforcement during denoising, and uses opacity-based voxel filtering from 3D Gaussian Splatting on a TRELLIS backbone. No equations, parameter-fitting steps, predictions, or derivations appear that reduce by construction to the authors' own inputs. No self-citation chains or uniqueness theorems are invoked as load-bearing premises. The central claims rest on experimental comparisons on the Waymo dataset rather than tautological redefinitions, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scalability in perception for autonomous driving: Waymo open dataset,
P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V . Patnaik, P. Tsui, J. Guo, Y . Zhou, Y . Chai, B. Caineet al., “Scalability in perception for autonomous driving: Waymo open dataset,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 2446–2454
2020
-
[2]
Autorf: Learning 3d object radiance fields from single view observations,
N. M ¨uller, A. Simonelli, L. Porzi, S. R. Bulo, M. Nießner, and P. Kontschieder, “Autorf: Learning 3d object radiance fields from single view observations,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 3971–3980
2022
-
[3]
Sup-nerf: A streamlined unification of pose estimation and nerf for monocular 3d object reconstruction,
Y . Guo, A. Kumar, C. Zhao, R. Wang, X. Huang, and L. Ren, “Sup-nerf: A streamlined unification of pose estimation and nerf for monocular 3d object reconstruction,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 37–53
2024
-
[4]
Car-studio: learning car radiance fields from single-view and unlimited in-the-wild images,
T. Liu, H. Zhao, Y . Yu, G. Zhou, and M. Liu, “Car-studio: learning car radiance fields from single-view and unlimited in-the-wild images,” IEEE Robotics and Automation Letters, vol. 9, no. 3, 2024
2024
-
[5]
Drive-1-to-3: Enriching diffusion priors for novel view synthesis of real vehicles,
C. Lin, B. Zhuang, S. Sun, Z. Jiang, J. Cai, and M. Chandraker, “Drive-1-to-3: Enriching diffusion priors for novel view synthesis of real vehicles,”arXiv preprint arXiv:2412.14494, 2024
arXiv 2024
-
[6]
Discoscene: Spatially disentangled generative radiance fields for controllable 3d-aware scene synthesis,
Y . Xu, M. Chai, Z. Shi, S. Peng, I. Skorokhodov, A. Siarohin, C. Yang, Y . Shen, H.-Y . Lee, B. Zhouet al., “Discoscene: Spatially disentangled generative radiance fields for controllable 3d-aware scene synthesis,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 4402–4412
2023
-
[7]
Dreamcar: Leveraging car-specific prior for in-the-wild 3d car reconstruction,
X. Du, H. Sun, M. Lu, T. Zhu, and X. Yu, “Dreamcar: Leveraging car-specific prior for in-the-wild 3d car reconstruction,”IEEE Robotics and Automation Letters, 2024
2024
-
[8]
Gina-3d: Learning to generate implicit neural assets in the wild,
B. Shen, X. Yan, C. R. Qi, M. Najibi, B. Deng, L. Guibas, Y . Zhou, and D. Anguelov, “Gina-3d: Learning to generate implicit neural assets in the wild,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 4913–4926
2023
-
[9]
Stnerf: symmetric triplane neural radiance fields for novel view synthesis from single-view vehicle images,
Z. Liu, Z. Fu, G. Li, J. Hu, and Y . Yang, “Stnerf: symmetric triplane neural radiance fields for novel view synthesis from single-view vehicle images,”Applied Intelligence, vol. 55, no. 5, p. 322, 2025
2025
-
[10]
Genassets: Generating in-the-wild 3d assets in latent space,
Z. Yang, J. Wang, H. Zhang, S. Manivasagam, Y . Chen, and R. Ur- tasun, “Genassets: Generating in-the-wild 3d assets in latent space,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 22 392–22 403
2025
-
[11]
Clay: A controllable large-scale generative model for creating high-quality 3d assets,
L. Zhang, Z. Wang, Q. Zhang, Q. Qiu, A. Pang, H. Jiang, W. Yang, L. Xu, and J. Yu, “Clay: A controllable large-scale generative model for creating high-quality 3d assets,”ACM Transactions on Graphics (TOG), vol. 43, no. 4, pp. 1–20, 2024
2024
-
[12]
Hunyuan3d 2.0: Scaling diffusion models for high resolution textured 3d assets generation,
Z. Zhao, Z. Lai, Q. Lin, Y . Zhao, H. Liu, S. Yang, Y . Feng, M. Yang, S. Zhang, X. Yanget al., “Hunyuan3d 2.0: Scaling diffusion models for high resolution textured 3d assets generation,”arXiv preprint arXiv:2501.12202, 2025
Pith/arXiv arXiv 2025
-
[13]
Hunyuan3d 2.5: Towards high- fidelity 3d assets generation with ultimate details,
Z. Lai, Y . Zhao, H. Liu, Z. Zhao, Q. Lin, H. Shi, X. Yang, M. Yang, S. Yang, Y . Fenget al., “Hunyuan3d 2.5: Towards high- fidelity 3d assets generation with ultimate details,”arXiv preprint arXiv:2506.16504, 2025
Pith/arXiv arXiv 2025
-
[14]
Structured 3d latents for scalable and versatile 3d generation,
J. Xiang, Z. Lv, S. Xu, Y . Deng, R. Wang, B. Zhang, D. Chen, X. Tong, and J. Yang, “Structured 3d latents for scalable and versatile 3d generation,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 21 469–21 480
2025
-
[15]
Shapenet: An information-rich 3d model repository,
A. X. Chang, T. Funkhouser, L. Guibas, P. Hanrahan, Q. Huang, Z. Li, S. Savarese, M. Savva, S. Song, H. Suet al., “Shapenet: An information-rich 3d model repository,”arXiv preprint arXiv:1512.03012, 2015
Pith/arXiv arXiv 2015
-
[16]
Objaverse: A universe of annotated 3d objects,
M. Deitke, D. Schwenk, J. Salvador, L. Weihs, O. Michel, E. Vander- Bilt, L. Schmidt, K. Ehsani, A. Kembhavi, and A. Farhadi, “Objaverse: A universe of annotated 3d objects,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 13 142–13 153
2023
-
[17]
Objaverse-xl: A universe of 10m+ 3d objects,
M. Deitke, R. Liu, M. Wallingford, H. Ngo, O. Michel, A. Kusupati, A. Fan, C. Laforte, V . V oleti, S. Y . Gadreet al., “Objaverse-xl: A universe of 10m+ 3d objects,”Advances in Neural Information Processing Systems, vol. 36, pp. 35 799–35 813, 2023
2023
-
[18]
3d gaussian splatting for real-time radiance field rendering
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, and G. Drettakis, “3d gaussian splatting for real-time radiance field rendering.”ACM Trans. Graph., vol. 42, no. 4, pp. 139–1, 2023
2023
-
[19]
Giraffe: Representing scenes as com- positional generative neural feature fields,
M. Niemeyer and A. Geiger, “Giraffe: Representing scenes as com- positional generative neural feature fields,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 11 453–11 464
2021
-
[20]
Efficient geometry-aware 3d generative adversarial networks,
E. R. Chan, C. Z. Lin, M. A. Chan, K. Nagano, B. Pan, S. De Mello, O. Gallo, L. J. Guibas, J. Tremblay, S. Khamiset al., “Efficient geometry-aware 3d generative adversarial networks,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 16 123–16 133
2022
-
[21]
Madrive: Memory-augmented driving scene modeling,
P. Karpikova, D. Selikhanovych, K. Struminsky, R. Musaev, M. Golit- syna, and D. Baranchuk, “Madrive: Memory-augmented driving scene modeling,”arXiv preprint arXiv:2506.21520, 2025
arXiv 2025
-
[22]
Refsam: Efficiently adapting segmenting anything model for referring video object segmentation,
Y . Li, J. Zhang, X. Teng, H. Zhang, X. Liu, and L. Lan, “Refsam: Efficiently adapting segmenting anything model for referring video object segmentation,”Neural Networks, p. 108000, 2025
2025
-
[23]
D 2GS: Dense depth regularization for lidar-free urban scene reconstruction,
K. Xia, J. Jia, K. Jin, Y . Bai, L. Sun, D. Tao, and Y . Zhang, “D 2GS: Dense depth regularization for lidar-free urban scene reconstruction,” arXiv preprint arXiv:2510.25173, 2025
arXiv 2025
-
[24]
C-woe: Clustering for out- of-distribution detection learning with wild outlier exposure,
L. Lan, Z. Hu, H. Li, T. Liu, and X. Liu, “C-woe: Clustering for out- of-distribution detection learning with wild outlier exposure,”IEEE Transactions on Image Processing, 2026
2026
-
[25]
Protocar: Learning 3d vehicle prototypes from single-view and unconstrained driving scene images,
H. Liu, H. Yu, B. Zou, J. Lyu, Q. Mei, J. Chen, and H. Ma, “Protocar: Learning 3d vehicle prototypes from single-view and unconstrained driving scene images,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 5, 2025, pp. 5460–5468
2025
-
[26]
Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation,
R. Chen, Y . Chen, N. Jiao, and K. Jia, “Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 22 246–22 256
2023
-
[27]
Magic123: One image to high-quality 3d object generation using both 2d and 3d diffusion priors,
G. Qian, J. Mai, A. Hamdi, J. Ren, A. Siarohin, B. Li, H.-Y . Lee, I. Skorokhodov, P. Wonka, S. Tulyakovet al., “Magic123: One image to high-quality 3d object generation using both 2d and 3d diffusion priors,” inThe Twelfth International Conference on Learning Representations
-
[28]
Magic3d: High-resolution text- to-3d content creation,
C.-H. Lin, J. Gao, L. Tang, T. Takikawa, X. Zeng, X. Huang, K. Kreis, S. Fidler, M.-Y . Liu, and T.-Y . Lin, “Magic3d: High-resolution text- to-3d content creation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 300–309
2023
-
[29]
Dreamfusion: Text- to-3d using 2d diffusion,
B. Poole, A. Jain, J. T. Barron, and B. Mildenhall, “Dreamfusion: Text- to-3d using 2d diffusion,” inThe Eleventh International Conference on Learning Representations, 2023
2023
-
[30]
Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation,
Z. Wang, C. Lu, Y . Wang, F. Bao, C. Li, H. Su, and J. Zhu, “Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation,”Advances in Neural Information Pro- cessing Systems, vol. 36, 2024
2024
-
[31]
Zero-1-to-3: Zero-shot one image to 3d object,
R. Liu, R. Wu, B. Van Hoorick, P. Tokmakov, S. Zakharov, and C. V ondrick, “Zero-1-to-3: Zero-shot one image to 3d object,” in Proceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 9298–9309
2023
-
[32]
Wonder3d: Single image to 3d using cross-domain diffusion,
X. Long, Y .-C. Guo, C. Lin, Y . Liu, Z. Dou, L. Liu, Y . Ma, S.-H. Zhang, M. Habermann, C. Theobaltet al., “Wonder3d: Single image to 3d using cross-domain diffusion,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 9970–9980
2024
-
[33]
Zero123++: a single image to consistent multi-view diffusion base model,
R. Shi, H. Chen, Z. Zhang, M. Liu, C. Xu, X. Wei, L. Chen, C. Zeng, and H. Su, “Zero123++: a single image to consistent multi-view diffusion base model,”arXiv preprint arXiv:2310.15110, 2023
Pith/arXiv arXiv 2023
-
[34]
Unique3d: High-quality and efficient 3d mesh generation from a single image,
K. Wu, F. Liu, Z. Cai, R. Yan, H. Wang, Y . Hu, Y . Duan, and K. Ma, “Unique3d: High-quality and efficient 3d mesh generation from a single image,”arXiv preprint arXiv:2405.20343, 2024
arXiv 2024
-
[35]
J. Xu, W. Cheng, Y . Gao, X. Wang, S. Gao, and Y . Shan, “Instantmesh: Efficient 3d mesh generation from a single image with sparse-view large reconstruction models,”arXiv preprint arXiv:2404.07191, 2024
Pith/arXiv arXiv 2024
-
[36]
3dshape2vecset: A 3d shape representation for neural fields and generative diffusion models,
B. Zhang, J. Tang, M. Niessner, and P. Wonka, “3dshape2vecset: A 3d shape representation for neural fields and generative diffusion models,” ACM Transactions On Graphics (TOG), vol. 42, no. 4, pp. 1–16, 2023
2023
-
[37]
Hunyuan3d 2.1: From images to high-fidelity 3d assets with production-ready pbr material,
T. Hunyuan3D, S. Yang, M. Yang, Y . Feng, X. Huang, S. Zhang, Z. He, D. Luo, H. Liu, Y . Zhaoet al., “Hunyuan3d 2.1: From images to high-fidelity 3d assets with production-ready pbr material,”arXiv preprint arXiv:2506.15442, 2025
Pith/arXiv arXiv 2025
-
[38]
Dora: Sampling and benchmarking for 3d shape variational auto-encoders,
R. Chen, J. Zhang, Y . Liang, G. Luo, W. Li, J. Liu, X. Li, X. Long, J. Feng, and P. Tan, “Dora: Sampling and benchmarking for 3d shape variational auto-encoders,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 16 251–16 261
2025
-
[39]
Michelangelo: Conditional 3d shape generation based on shape-image-text aligned latent representation,
Z. Zhao, W. Liu, X. Chen, X. Zeng, R. Wang, P. Cheng, B. Fu, T. Chen, G. Yu, and S. Gao, “Michelangelo: Conditional 3d shape generation based on shape-image-text aligned latent representation,”Advances in neural information processing systems, vol. 36, pp. 73 969–73 982, 2023
2023
-
[40]
Hi3dgen: High-fidelity 3d geometry generation from images via normal bridging,
C. Ye, Y . Wu, Z. Lu, J. Chang, X. Guo, J. Zhou, H. Zhao, and X. Han, “Hi3dgen: High-fidelity 3d geometry generation from images via normal bridging,”arXiv preprint arXiv:2503.22236, vol. 3, p. 2, 2025
arXiv 2025
-
[41]
Sparc3d: Sparse rep- resentation and construction for high-resolution 3d shapes modeling,
Z. Li, Y . Wang, H. Zheng, Y . Luo, and B. Wen, “Sparc3d: Sparse rep- resentation and construction for high-resolution 3d shapes modeling,” arXiv preprint arXiv:2505.14521, 2025
arXiv 2025
-
[42]
Direct3d-s2: Gigascale 3d generation made easy with spatial sparse attention,
S. Wu, Y . Lin, F. Zhang, Y . Zeng, Y . Yang, Y . Bao, J. Qian, S. Zhu, X. Cao, P. Torret al., “Direct3d-s2: Gigascale 3d generation made easy with spatial sparse attention,”arXiv preprint arXiv:2505.17412, 2025
arXiv 2025
-
[43]
A density-based algorithm for discovering clusters in large spatial databases with noise,
M. Ester, H.-P. Kriegel, J. Sander, X. Xuet al., “A density-based algorithm for discovering clusters in large spatial databases with noise,” inkdd, vol. 96, no. 34, 1996, pp. 226–231
1996
-
[44]
Marigold-dc: Zero-shot monocular depth completion with guided diffusion,
M. Viola, K. Qu, N. Metzger, B. Ke, A. Becker, K. Schindler, and A. Obukhov, “Marigold-dc: Zero-shot monocular depth completion with guided diffusion,”arXiv preprint arXiv:2412.13389, 2024
arXiv 2024
-
[45]
Flow matching for generative modeling,
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,”arXiv preprint arXiv:2210.02747, 2022
Pith/arXiv arXiv 2022
-
[46]
Enhanced diffusion sampling via extrap- olation with multiple ode solutions,
J. Choi, J. Kang, and B. Han, “Enhanced diffusion sampling via extrap- olation with multiple ode solutions,”arXiv preprint arXiv:2504.01855, 2025
arXiv 2025
-
[47]
Image quality assessment: from error visibility to structural similarity,
Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: from error visibility to structural similarity,”IEEE transactions on image processing, vol. 13, no. 4, pp. 600–612, 2004
2004
-
[48]
The unreasonable effectiveness of deep features as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 586–595
2018
-
[49]
Vggt: Visual geometry grounded transformer,
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny, “Vggt: Visual geometry grounded transformer,” inPro- ceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 5294–5306
2025
-
[50]
3drealcar: An in-the-wild rgb-d car dataset with 360-degree views,
X. Du, H. Sun, S. Wang, Z. Wu, H. Sheng, J. Ying, M. Lu, T. Zhu, K. Zhan, and X. Yu, “3drealcar: An in-the-wild rgb-d car dataset with 360-degree views,”arXiv preprint arXiv:2406.04875, 2024
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.