Equilibrium Reasoners: Learning Attractors Enables Scalable Reasoning
Pith reviewed 2026-05-21 04:53 UTC · model grok-4.3
The pith
Neural networks learn task-conditioned attractors in latent space so that iterative updates at test time converge to valid solutions and scale reasoning performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
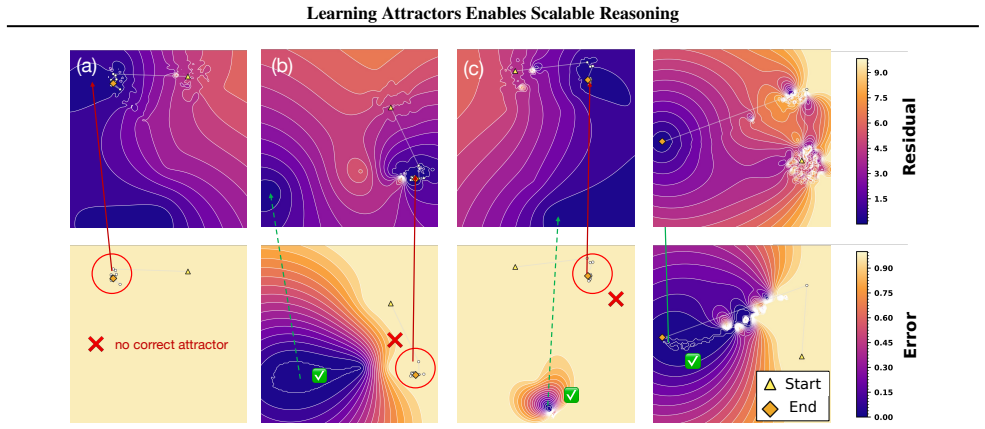
We hypothesize that generalizable reasoning arises from learning task-conditioned attractors: latent dynamical systems whose stable fixed points correspond to valid solutions. We formalize this process through Equilibrium Reasoners (EqR), which enable test-time scaling without external verifiers or task-specific priors. EqR scales internal dynamics along two axes: depth, by running more iterations, and breadth, by aggregating stochastic trajectories from multiple initializations. Empirically, gains from test-time scaling are tightly coupled with stronger convergence toward solution-aligned attractors. By unrolling up to the equivalent of 40,000 layers, scalable latent reasoning boosts the 2.
What carries the argument
Equilibrium Reasoners (EqR), models whose latent updates implement task-conditioned dynamical systems that converge to stable fixed points at valid solutions.
If this is right
- Accuracy on hard instances rises in direct proportion to how closely latent trajectories approach the solution attractor.
- Simpler problems converge in few steps while difficult ones require and benefit from thousands of additional iterations.
- Compute can be allocated adaptively by monitoring convergence speed during test-time execution.
- No external verifiers or task-specific priors are required for the scaling effect to appear.
Where Pith is reading between the lines
- The same attractor-training recipe could be applied to other structured reasoning domains such as theorem proving or planning to produce analogous test-time scaling.
- The perspective offers a possible dynamical explanation for why chain-of-thought or scratchpad methods improve performance in language models.
- One could deliberately perturb training to misalign attractors and test whether reasoning accuracy collapses while feedforward accuracy remains intact.
Load-bearing premise
Generalizable reasoning requires learning task-conditioned attractors whose stable fixed points are exactly the valid solutions rather than arising from some other internal process.
What would settle it
Finding high accuracy on Sudoku-Extreme while the iterated latent states fail to converge to the known solution configurations, or observing that accuracy improvements decouple from measured convergence strength.
Figures













read the original abstract
Scaling test-time compute by iteratively updating a latent state has emerged as a powerful paradigm for reasoning. Yet the internal mechanisms that enable these iterative models to generalize beyond memorized patterns remain unclear. We hypothesize that generalizable reasoning arises from learning task-conditioned attractors: latent dynamical systems whose stable fixed points correspond to valid solutions. We formalize this process through Equilibrium Reasoners (EqR), which enable test-time scaling without external verifiers or task-specific priors. EqR scales internal dynamics along two axes: depth, by running more iterations, and breadth, by aggregating stochastic trajectories from multiple initializations. Empirically, gains from test-time scaling are tightly coupled with stronger convergence toward solution-aligned attractors. This attractor perspective allows neural networks to adaptively allocate test-time compute based on task difficulty. While simple cases converge within 1 to 5 iteration steps, harder cases benefit from massive test-time scaling. By unrolling up to the equivalent of 40,000 layers, scalable latent reasoning boosts accuracy from 2.6% for feedforward models to over 99% on Sudoku-Extreme. These results suggest that learned attractor landscapes provide a useful mechanistic lens for understanding scalable reasoning in iterative latent models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Equilibrium Reasoners (EqR), a framework for scalable latent reasoning in which neural networks learn task-conditioned attractors whose stable fixed points are hypothesized to correspond to valid solutions. The approach scales test-time compute along depth (by increasing the number of iterations) and breadth (by aggregating multiple stochastic trajectories), with the claim that performance gains are tightly coupled to stronger convergence toward solution-aligned attractors. On Sudoku-Extreme, unrolling dynamics equivalent to 40,000 layers raises accuracy from 2.6% (feedforward baseline) to over 99%.
Significance. If the attractor mechanism can be shown to operate independently of label-based supervision, the work would supply a dynamical-systems account of why iterative latent models generalize and scale, together with a practical method for adaptive test-time compute allocation. The reported scaling results on a hard constraint-satisfaction task would be a notable empirical contribution to the literature on test-time reasoning.
major comments (2)
- [Abstract / Hypothesis] Abstract and opening hypothesis paragraph: the claim that fixed points 'correspond to valid solutions' and that convergence is 'tightly coupled' to accuracy risks circularity if solution-alignment is measured by proximity to the same ground-truth labels used to compute the 99% accuracy figure. The manuscript must demonstrate that the learned fixed points satisfy the underlying task constraints (Sudoku rules, etc.) on held-out instances even when label information is withheld from the convergence metric.
- [Empirical Results] Empirical section reporting the Sudoku-Extreme results: the abstract states large gains and a correlation between convergence and accuracy, yet supplies no dataset splits, error bars, ablation controls, or explicit separation between the attractor fixed-point property and the supervised accuracy signal. Without these, the support for the mechanistic attractor hypothesis cannot be evaluated.
minor comments (1)
- [Methods / Scaling Description] Clarify the precise mapping from iteration count to 'equivalent of 40,000 layers' and whether this equivalence is architectural or merely computational.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important points for clarifying the independence of the attractor mechanism from label supervision and for improving the empirical reporting. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Hypothesis] Abstract and opening hypothesis paragraph: the claim that fixed points 'correspond to valid solutions' and that convergence is 'tightly coupled' to accuracy risks circularity if solution-alignment is measured by proximity to the same ground-truth labels used to compute the 99% accuracy figure. The manuscript must demonstrate that the learned fixed points satisfy the underlying task constraints (Sudoku rules, etc.) on held-out instances even when label information is withheld from the convergence metric.
Authors: We agree that explicit separation is necessary to substantiate the mechanistic claim. Convergence in EqR is defined via the fixed-point residual of the latent dynamics (||Δx|| < ε), which does not reference ground-truth labels during iteration. In the revision we will add a dedicated analysis on held-out Sudoku-Extreme instances showing that trajectories reaching this label-free convergence criterion decode to states satisfying all Sudoku constraints (unique rows, columns, and blocks) at rates that track the reported accuracy gains. This will demonstrate that the attractor property operates independently of the supervised accuracy metric. revision: yes
-
Referee: [Empirical Results] Empirical section reporting the Sudoku-Extreme results: the abstract states large gains and a correlation between convergence and accuracy, yet supplies no dataset splits, error bars, ablation controls, or explicit separation between the attractor fixed-point property and the supervised accuracy signal. Without these, the support for the mechanistic attractor hypothesis cannot be evaluated.
Authors: We acknowledge that these details were insufficiently reported. The revised manuscript will specify the exact train/validation/test splits for Sudoku-Extreme, report standard error bars across multiple random seeds, and include targeted ablations that compare convergent EqR trajectories against non-convergent iterative baselines while holding supervision fixed. These additions will make the empirical support for the attractor hypothesis directly evaluable. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper hypothesizes that generalizable reasoning arises from task-conditioned attractors whose fixed points correspond to valid solutions, then reports that test-time scaling gains are empirically coupled to convergence toward solution-aligned attractors, with accuracy improvements demonstrated on Sudoku-Extreme via unrolling iterations. No equations, fitting procedures, or derivations are shown that reduce any claimed prediction or result to its inputs by construction. There are no self-citations, uniqueness theorems, or ansatzes invoked in the provided text that would create load-bearing circularity. The central claims remain independent of the accuracy metric and are presented as an empirical observation rather than a definitional equivalence, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Stable fixed points of the learned latent dynamics correspond to valid task solutions
invented entities (1)
-
task-conditioned attractors
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We hypothesize that generalizable reasoning arises from learning task-conditioned attractors: latent dynamical systems whose stable fixed points correspond to valid solutions.
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By unrolling up to the equivalent of 40,000 layers, scalable latent reasoning boosts accuracy from 2.6% for feedforward models to over 99% on Sudoku-Extreme
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Forty-first International Conference on Machine Learning , year=
Scaling Exponents Across Parameterizations and Optimizers , author=. Forty-first International Conference on Machine Learning , year=
-
[2]
International Conference on Learning Representations , year=
Adam: A Method for Stochastic Optimization , author=. International Conference on Learning Representations , year=
-
[3]
Advances in Neural Information Processing Systems , volume=
Path Independent Equilibrium Models Can Better Exploit Test-Time Computation , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
International Conference on Learning Representations , year=
Unbiasing Truncated Backpropagation Through Time , author=. International Conference on Learning Representations , year=
-
[5]
Proceedings of The 35th Uncertainty in Artificial Intelligence Conference , series=
Adaptively Truncating Backpropagation Through Time to Control Gradient Bias , author=. Proceedings of The 35th Uncertainty in Artificial Intelligence Conference , series=. 2020 , publisher=
work page 2020
-
[6]
Proceedings of the 35th International Conference on Machine Learning , series=
Reviving and Improving Recurrent Back-Propagation , author=. Proceedings of the 35th International Conference on Machine Learning , series=. 2018 , publisher=
work page 2018
-
[7]
Hochreiter, Sepp and Schmidhuber, J. Neural Computation , year=
-
[8]
NeurIPS 2022 Workshop on Neuro Causal and Symbolic AI (nCSI) , year=
Playgrounds for abstraction and reasoning , author=. NeurIPS 2022 Workshop on Neuro Causal and Symbolic AI (nCSI) , year=
work page 2022
-
[9]
Why Do Reasoning Models Loop? , author=
Wait, Wait, Wait... Why Do Reasoning Models Loop? , author=. 2025 , eprint=
work page 2025
-
[10]
Benhao Huang , year=
- [11]
-
[12]
Less is More: Recursive Reasoning with Tiny Networks , author=. 2025 , eprint=
work page 2025
-
[13]
Conference on Language Modeling , year=
Training Large Language Models to Reason in a Continuous Latent Space , author=. Conference on Language Modeling , year=
-
[14]
International Conference on Learning Representations , year=
Think before you speak: Training Language Models With Pause Tokens , author=. International Conference on Learning Representations , year=
-
[15]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics , pages=
SoftCoT: Soft Chain-of-Thought for Efficient Reasoning with LLMs , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics , pages=. 2025 , doi=
work page 2025
-
[16]
SoftCoT++: Test-Time Scaling with Soft Chain-of-Thought Reasoning , author=. 2025 , eprint=
work page 2025
-
[17]
International Conference on Learning Representations , year=
PonderLM: Pretraining Language Models to Ponder in Continuous Space , author=. International Conference on Learning Representations , year=
-
[18]
PonderLM-2: Pretraining LLM with Latent Thoughts in Continuous Space , author=. 2025 , eprint=
work page 2025
-
[19]
International Conference on Learning Representations , year=
SIM-CoT: Supervised Implicit Chain-of-Thought , author=. International Conference on Learning Representations , year=
-
[20]
Parallel Test-Time Scaling for Latent Reasoning Models , author=. 2025 , eprint=
work page 2025
-
[21]
SPOT: Span-level Pause-of-Thought for Efficient and Interpretable Latent Reasoning in Large Language Models , author=. 2026 , eprint=
work page 2026
-
[22]
Proceedings of the 38th International Conference on Machine Learning , series=
Stabilizing Equilibrium Models by Jacobian Regularization , author=. Proceedings of the 38th International Conference on Machine Learning , series=
-
[23]
TorchDEQ: A Library for Deep Equilibrium Models , author=. 2023 , eprint=
work page 2023
-
[24]
Advances in Neural Information Processing Systems , volume=
Deep Equilibrium Models , author=. Advances in Neural Information Processing Systems , volume=
-
[25]
A General Reinforcement Learning Algorithm that Masters Chess, Shogi, and Go Through Self-Play , author=. Science , volume=. 2018 , doi=
work page 2018
-
[26]
Advances in Neural Information Processing Systems , volume=
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
International Conference on Learning Representations , year=
Universal transformers , author=. International Conference on Learning Representations , year=
-
[28]
Scaling latent reasoning via looped language models , author=. 2025 , eprint=
work page 2025
-
[29]
Advances in Neural Information Processing Systems , year=
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach , author=. Advances in Neural Information Processing Systems , year=
-
[30]
Can You Learn an Algorithm? Generalizing from Easy to Hard Problems with Recurrent Networks , author=. 2021 , eprint=
work page 2021
-
[31]
Proceedings of the 40th International Conference on Machine Learning , series=
Looped Transformers as Programmable Computers , author=. Proceedings of the 40th International Conference on Machine Learning , series=
-
[32]
International Conference on Learning Representations , year=
Looped Transformers are Better at Learning Learning Algorithms , author=. International Conference on Learning Representations , year=
-
[33]
Proceedings of the 42nd International Conference on Machine Learning , year=
On Expressive Power of Looped Transformers: Theoretical Analysis and Enhancement via Timestep Encoding , author=. Proceedings of the 42nd International Conference on Machine Learning , year=
-
[34]
International Conference on Learning Representations , year=
Reasoning with Latent Thoughts: On the Power of Looped Transformers , author=. International Conference on Learning Representations , year=
-
[35]
International Conference on Learning Representations , year=
The Expressive Power of Transformers with Chain of Thought , author=. International Conference on Learning Representations , year=
-
[36]
Latent Chain-of-Thought? Decoding the Depth-Recurrent Transformer , author=. 2025 , eprint=
work page 2025
-
[37]
Two-Scale Latent Dynamics for Recurrent-Depth Transformers , author=. 2025 , eprint=
work page 2025
-
[38]
Inverse Depth Scaling From Most Layers Being Similar , author=. 2026 , eprint=
work page 2026
-
[39]
Loop, Think, & Generalize: Implicit Reasoning in Recurrent-Depth Transformers , author=. 2026 , eprint=
work page 2026
-
[40]
Relational Preference Encoding in Looped Transformer Internal States , author=. 2026 , eprint=
work page 2026
-
[41]
A Mechanistic Analysis of Looped Reasoning Language Models , author=. 2026 , eprint=
work page 2026
-
[42]
Stability and Generalization in Looped Transformers , author=. 2026 , eprint=
work page 2026
-
[43]
How Much Is One Recurrence Worth? Iso-Depth Scaling Laws for Looped Language Models , author=. 2026 , eprint=
work page 2026
-
[44]
Parcae: Scaling Laws For Stable Looped Language Models , author=. 2026 , eprint=
work page 2026
-
[45]
AdaPonderLM: Gated Pondering Language Models with Token-Wise Adaptive Depth , author=. 2026 , eprint=
work page 2026
-
[46]
International Conference on Learning Representations , year=
LoopFormer: Elastic-Depth Looped Transformers for Latent Reasoning via Shortcut Modulation , author=. International Conference on Learning Representations , year=
-
[47]
Advances in Neural Information Processing Systems , year=
Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation , author=. Advances in Neural Information Processing Systems , year=
-
[48]
Understanding Dynamic Compute Allocation in Recurrent Transformers , author=. 2026 , eprint=
work page 2026
-
[49]
Think-at-Hard: Selective Latent Iterations to Improve Reasoning Language Models , author=. 2025 , eprint=
work page 2025
-
[50]
LoopViT: Scaling Visual ARC with Looped Transformers , author=. 2026 , eprint=
work page 2026
-
[51]
Conference on Language Modeling , year=
Beyond A*: Better Planning with Transformers via Search Dynamics Bootstrapping , author=. Conference on Language Modeling , year=
-
[52]
Are Your Reasoning Models Reasoning or Guessing? A Mechanistic Analysis of Hierarchical Reasoning Models , author=. 2026 , eprint=
work page 2026
-
[53]
International Conference on Learning Representations , year=
Sharpness-Aware Minimization for Efficiently Improving Generalization , author=. International Conference on Learning Representations , year=
-
[54]
International Conference on Learning Representations , year=
Is Attention Better Than Matrix Decomposition? , author=. International Conference on Learning Representations , year=
-
[55]
Advances in Neural Information Processing Systems , volume=
On Training Implicit Models , author=. Advances in Neural Information Processing Systems , volume=
-
[56]
Advances in Neural Information Processing Systems , volume=
Implicit Graph Neural Networks , author=. Advances in Neural Information Processing Systems , volume=
-
[57]
SIAM Journal on Mathematics of Data Science , volume=
Implicit Deep Learning , author=. SIAM Journal on Mathematics of Data Science , volume=. 2021 , doi=
work page 2021
- [58]
-
[59]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Deep Equilibrium Optical Flow Estimation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[60]
Golden Noise for Diffusion Models: A Learning Framework , author=. 2025 , eprint=
work page 2025
-
[61]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
InitNO: Boosting Text-to-Image Diffusion Models via Initial Noise Optimization , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[62]
Computer Vision -- ECCV 2024 , pages=
FreeInit: Bridging Initialization Gap in Video Diffusion Models , author=. Computer Vision -- ECCV 2024 , pages=. 2024 , doi=
work page 2024
-
[63]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
JFB: Jacobian-Free Backpropagation for Implicit Networks , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=. 2022 , doi=
work page 2022
-
[64]
Adaptive Computation Time for Recurrent Neural Networks , author=. 2017 , eprint=
work page 2017
-
[65]
Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=
RingFormer: Rethinking Recurrent Transformer with Adaptive Level Signals , author=. Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=. 2025 , doi=
work page 2025
-
[66]
Investigating Recurrent Transformers with Dynamic Halt , author=. 2025 , eprint=
work page 2025
-
[67]
Advances in Neural Information Processing Systems , year=
Towards Thinking-Optimal Scaling of Test-Time Compute for LLM Reasoning , author=. Advances in Neural Information Processing Systems , year=
-
[68]
International Conference on Learning Representations , year=
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters , author=. International Conference on Learning Representations , year=
-
[69]
Advances in Neural Information Processing Systems , year=
Does Thinking More always Help? Mirage of Test-Time Scaling in Reasoning Models , author=. Advances in Neural Information Processing Systems , year=
-
[70]
International Conference on Learning Representations , year=
Deep Think with Confidence , author=. International Conference on Learning Representations , year=
-
[71]
MatryoshkaThinking: Recursive Test-Time Scaling Enables Efficient Reasoning , author=. 2025 , eprint=
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.