A Generalized Tangent Approximation based Variational Inference Framework for Strongly Super-Gaussian Likelihoods
Pith reviewed 2026-05-22 20:26 UTC · model grok-4.3
The pith
A tangent transformation variational framework enables conjugate inference for strongly super-Gaussian likelihoods through convex duality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For a broad class of probability models with strongly super-Gaussian likelihoods, tangent minorants constructed via convex duality induce conjugacy between the likelihood and Gaussian priors on the parameters, yielding scalable variational inference together with convergence guarantees and near-minimax optimal bounds on the variational risk.
What carries the argument
Tangent minorants of the log-likelihood obtained from convex duality, which restore conjugacy with Gaussian priors.
Load-bearing premise
The data-generating mechanism satisfies mild assumptions that suffice to prove algorithmic convergence and near-minimax risk bounds.
What would settle it
A dataset generated from a strongly super-Gaussian likelihood on which the variational iterates fail to converge or the achieved risk exceeds the derived near-minimax bound.
Figures










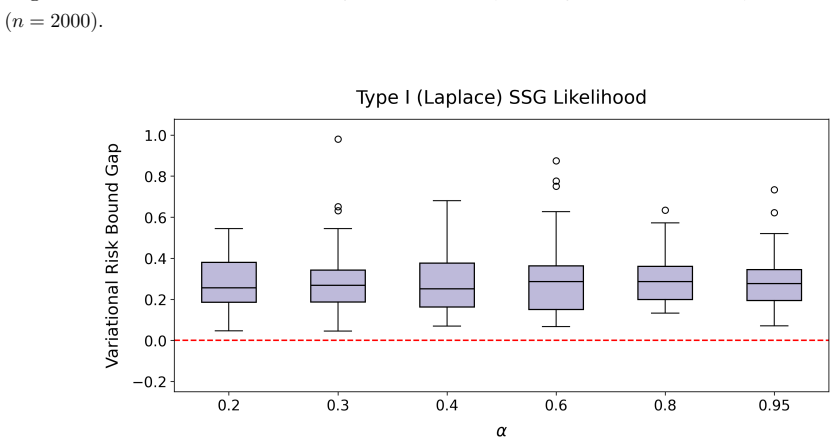


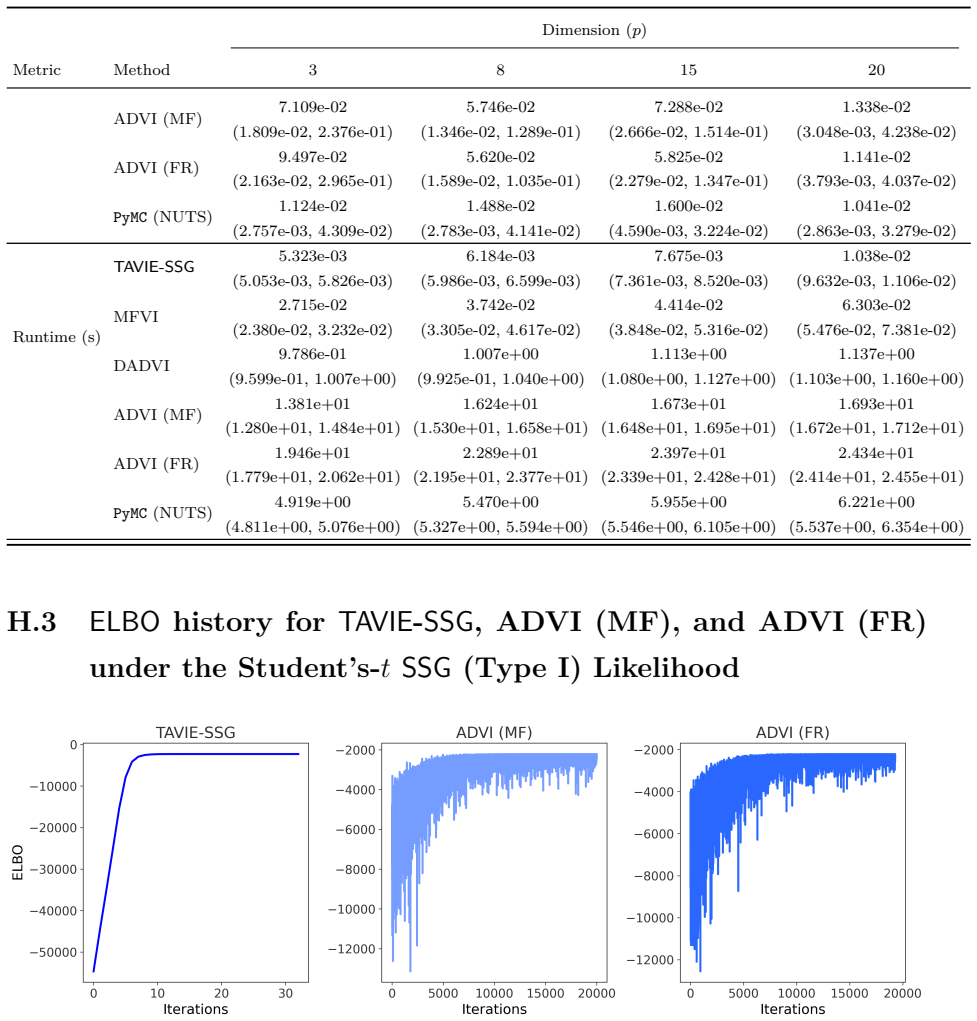

















read the original abstract
Variational inference, as an alternative to Markov chain Monte Carlo sampling, has played a transformative role in enabling scalable computation for complex Bayesian models. Nevertheless, existing approaches often depend on either rigid model-specific formulations or stochastic black-box optimization routines. Tangent approximation is a principled class of structured variational methods that exploits the geometry of the underlying probability model. However, its utility has largely been confined to logistic regression and related modeling regimes. In this article, we propose a novel variational framework based on tangent transformation for a broad class of probability models characterized by strongly super-Gaussian likelihoods. Our method leverages convex duality to construct tangent minorants of the log-likelihood, thereby inducing conjugacy with Gaussian priors over model parameters in an otherwise intractable setup. Under mild assumptions on the data-generating mechanism, we establish algorithmic convergence guarantees, a contribution that stands in contrast to the limited theoretical assurances typically available for black-box variational methods. Additionally, we derive near-minimax optimal bounds for the variational risk. Superior performance of our proposed methodology is illustrated on simulated and real-data scenarios that challenge state-of-the-art variational algorithms in terms of scalability and their ability to consistently capture complex underlying data structure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a generalized tangent approximation variational inference framework for a broad class of models with strongly super-Gaussian likelihoods. It uses convex duality to construct tangent minorants of the log-likelihood that induce conjugacy with Gaussian priors. The authors claim algorithmic convergence guarantees and near-minimax optimal bounds on variational risk under mild assumptions on the data-generating mechanism, while demonstrating improved scalability and performance over existing variational methods on simulated and real data.
Significance. If the theoretical results hold with explicit assumptions and derivations, the work would meaningfully extend tangent-based VI beyond logistic regression to a wider model class, providing rare convergence and optimality guarantees that contrast with black-box VI methods. The empirical illustrations of scalability and structure capture would add practical value in statistical modeling.
major comments (2)
- [Abstract and theoretical results section] The central claims of algorithmic convergence and near-minimax variational-risk bounds (Abstract) rest on 'mild assumptions on the data-generating mechanism,' but these assumptions are not explicitly stated, isolated from the strongly super-Gaussian property, or verified against the tangent-minorant construction. This directly weakens assessment of both the convergence guarantee and the optimality bound, as the skeptic note highlights; a dedicated theorem or proposition listing the precise conditions is required.
- [Method / variational framework section] The convex-duality construction of tangent minorants is load-bearing for inducing conjugacy with Gaussian priors across the claimed broad class. Without the explicit functional form of the minorant (e.g., the dual function or the specific tangent line parameterization) and a proof that it remains valid for general strongly super-Gaussian likelihoods rather than reducing to known special cases, the generality of the framework cannot be evaluated.
minor comments (2)
- [Experiments section] The abstract states superior performance on simulated and real-data scenarios, but the main text should include explicit comparison metrics, baseline methods, and reproducibility details (e.g., code or hyperparameter settings) to support the empirical claims.
- [Introduction / preliminaries] Notation for the tangent transformation and the resulting variational family should be introduced with a clear table or diagram early in the paper to aid readability for readers unfamiliar with prior tangent-approximation work.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important areas for improving the clarity and accessibility of our theoretical contributions. We address each major comment in turn below, indicating the revisions we plan to implement.
read point-by-point responses
-
Referee: [Abstract and theoretical results section] The central claims of algorithmic convergence and near-minimax variational-risk bounds (Abstract) rest on 'mild assumptions on the data-generating mechanism,' but these assumptions are not explicitly stated, isolated from the strongly super-Gaussian property, or verified against the tangent-minorant construction. This directly weakens assessment of both the convergence guarantee and the optimality bound, as the skeptic note highlights; a dedicated theorem or proposition listing the precise conditions is required.
Authors: We agree that the assumptions on the data-generating mechanism need to be stated more explicitly and isolated for rigorous evaluation. In the revised manuscript, we will add a dedicated Proposition in the theoretical results section that lists the precise conditions, clearly separates them from the strongly super-Gaussian property, and verifies their role in supporting both the algorithmic convergence and the near-minimax variational-risk bounds under the tangent-minorant construction. revision: yes
-
Referee: [Method / variational framework section] The convex-duality construction of tangent minorants is load-bearing for inducing conjugacy with Gaussian priors across the claimed broad class. Without the explicit functional form of the minorant (e.g., the dual function or the specific tangent line parameterization) and a proof that it remains valid for general strongly super-Gaussian likelihoods rather than reducing to known special cases, the generality of the framework cannot be evaluated.
Authors: The explicit functional form of the tangent minorant, including the dual function obtained via convex duality and the tangent line parameterization, is derived in Section 3.2, with the general validity proof provided in Appendix B. This construction applies to the full class of strongly super-Gaussian likelihoods and does not reduce to special cases. To address the evaluation concern, we will include a self-contained derivation sketch and a non-logistic example in the main text of the revised manuscript. revision: partial
Circularity Check
No significant circularity; derivation uses convex duality independently of fitted inputs or self-citations
full rationale
The paper constructs tangent minorants via convex duality for strongly super-Gaussian likelihoods to induce conjugacy with Gaussian priors, then derives convergence guarantees and near-minimax variational-risk bounds under mild data-generating assumptions. These steps are presented as novel extensions beyond logistic regression, without reducing the central claims to self-definitional equivalences, fitted parameters renamed as predictions, or load-bearing self-citations. The framework contrasts explicitly with black-box VI, and the bounds are obtained separately rather than by construction from the minorant itself. No equations or citations in the abstract or description exhibit the required reduction to inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mild assumptions on the data-generating mechanism
Reference graph
Works this paper leans on
-
[1]
J., Kochurov, M., Kumar, R., Lao, J., Luhmann, C
Abril-Pla, O., Andreani, V., Carroll, C., Dong, L., Fonnesbeck, C. J., Kochurov, M., Kumar, R., Lao, J., Luhmann, C. C., Martin, O. A., Osthege, M., Vieira, R., Wiecki, T. & Zinkov, R. (2023), ‘PyMC: a modern, and comprehensive probabilistic programming framework in Python’,PeerJ Computer Science9
work page 2023
-
[2]
Anderson, T. W. (1955), ‘The Integral of a Symmetric Unimodal Function over a Symmetric Convex Set and Some Probability Inequalities’,Proceedings of the American Mathematical Society6(2)
work page 1955
-
[3]
Ball, K. (1993), ‘The reverse isoperimetric problem for Gaussian measure’,Discrete & Computational Geometry10(4)
work page 1993
- [4]
-
[5]
Bolte, J., Sabach, S. & Teboulle, M. (2014), ‘Proximal alternating linearized minimization for nonconvex and nonsmooth problems’,Mathematical Programming146(1)
work page 2014
-
[6]
Bolte, J. et al. (2007), ‘The Łojasiewicz Inequality for Nonsmooth Subanalytic Functions with Applications to Subgradient Dynamical Systems’,SIAM Journal on Optimization 17(4)
work page 2007
-
[7]
Danskin, J. M. (1967),The Theory of Max–Min and Its Application to Weapons Allocation
work page 1967
-
[8]
Donsker, M. & Varadhan, S. (1983), ‘Asymptotic evaluation of certain Markov process expectations for large time. IV’,Communications on Pure and Applied Mathematics 36(2)
work page 1983
-
[9]
Ghosal, S. & van der Vaart, A. W. (2007), ‘Convergence rates of posterior distributions for noniid observations’,Annals of Statistics35(1)
work page 2007
-
[10]
Gil, M., Alajaji, F. & Linder, T. (2013), ‘Rényi divergence measures for commonly used univariate continuous distributions’,Information Sciences249
work page 2013
-
[11]
Giordano, R., Ingram, M. & Broderick, T. (2024), ‘Black box variational inference with a deterministic objective: Faster, more accurate, and even more black box’,Journal of Machine Learning Research25(18)
work page 2024
- [12]
-
[13]
Loshchilov, I. & Hutter, F. (2019), Decoupled Weight Decay Regularization,in‘International Conference on Learning Representations’
work page 2019
-
[14]
Patil, A., Huard, D. & Fonnesbeck, C. J. (2010), ‘PyMC: Bayesian stochastic modelling in Python’,Journal of statistical software35
work page 2010
-
[15]
Seabold, S. & Perktold, J. (2010), statsmodels: Econometric and statistical modeling with python,in‘9th Python in Science Conference’
work page 2010
-
[16]
Wand, M. P., Ormerod, J. T., Padoan, S. A. & Frühwirth, R. (2011), ‘Mean Field Variational Bayes for Elaborate Distributions’,Bayesian Analysis6(4). 104
work page 2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.