Label tree semantic losses for rich multi-class medical image segmentation
Pith reviewed 2026-05-22 13:16 UTC · model grok-4.3
The pith
Tree-based semantic losses that respect label hierarchies improve multi-class medical image segmentation accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
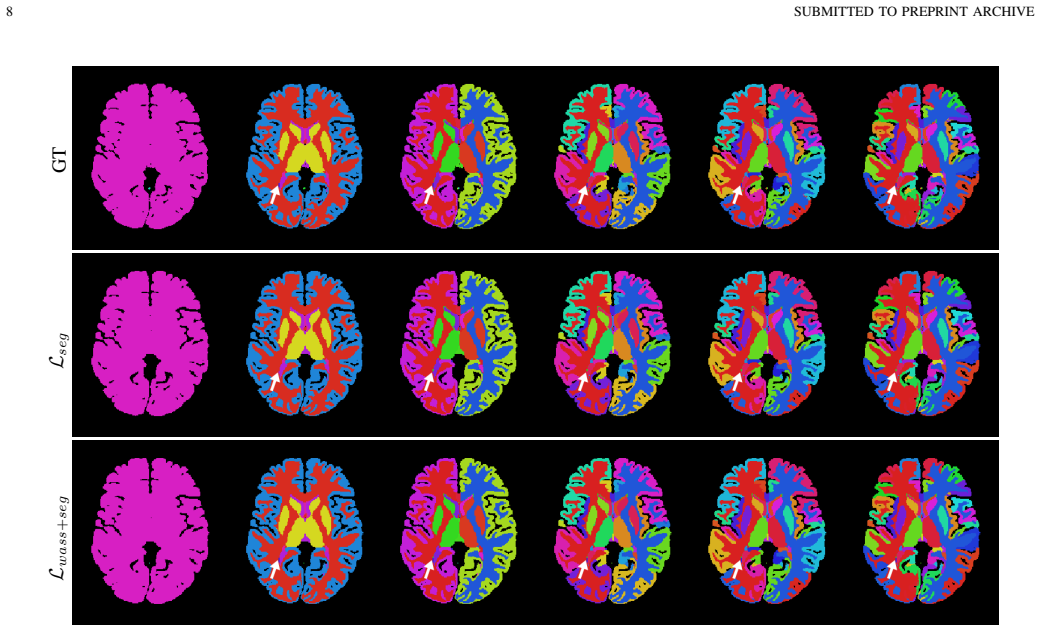
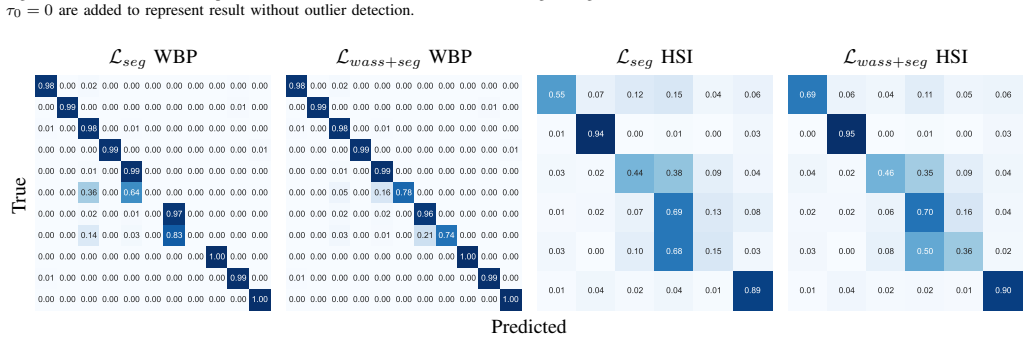
Two tree-based semantic loss functions exploit a hierarchical label organization to weight errors by semantic distance; when combined with sparse-annotation training, they produce consistent accuracy gains over baselines on whole-brain parcellation and neurosurgical hyperspectral imaging, with the Wasserstein-based compound loss and hierarchy-weighted top-level supervision each proving most effective in their respective regimes.
What carries the argument
Tree-based semantic loss functions that penalize prediction errors according to distance within a pre-specified label hierarchy.
If this is right
- The Wasserstein-based compound loss yields the largest gains on fully supervised whole-brain parcellation.
- Hierarchy-weighted top-level supervision performs best when annotations are sparse and background-free in hyperspectral imaging.
- The losses can be dropped into existing sparse-annotation frameworks without changing the underlying network architecture.
- Rich multi-class medical segmentation becomes more practical once inter-class semantics are explicitly penalized.
Where Pith is reading between the lines
- The same tree-loss idea could be tested on other clinical tasks whose labels form natural taxonomies, such as multi-organ CT segmentation with substructures.
- If the hierarchy could be inferred from data instead of supplied by experts, the method would require less manual curation.
- Better segmentation of fine anatomical classes may directly improve downstream clinical metrics such as surgical navigation precision or post-operative outcome prediction.
Load-bearing premise
The label hierarchy is specified correctly in advance and its branch distances genuinely reflect semantic dissimilarity among the classes.
What would settle it
Replacing the given label tree with a random or flat hierarchy on the same two tasks and observing no remaining improvement over standard losses would show that the semantic structure itself is not responsible for the reported gains.
Figures


read the original abstract
Rich and accurate medical image segmentation is poised to underpin the next generation of AI-defined clinical practice by delineating critical anatomy for pre-operative planning, guiding real-time intra-operative navigation, and supporting precise post-operative assessment. However, commonly used learning methods for medical and surgical imaging segmentation tasks penalise all errors equivalently and thus fail to exploit any inter-class semantics in the label space. This becomes particularly problematic as the cardinality and richness of labels increases to include subtly different classes. In this work, we propose two tree-based semantic loss functions which take advantage of a hierarchical organisation of the labels. We further incorporate our losses in a recently proposed approach for training with sparse, background-free annotations to extend the applicability of our proposed losses. Extensive experiments are reported on two medical and surgical imaging segmentation tasks, namely head MRI for whole brain parcellation with full supervision and neurosurgical hyperspectral imaging for scene understanding with sparse annotations. Results demonstrate consistent improvements over the evaluated task-specific baselines, with the strongest support for the Wasserstein-based compound loss in whole-brain parcellation and for hierarchy-weighted top-level supervision in the sparse HSI setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes two tree-based semantic loss functions that exploit a hierarchical organization of labels to penalize errors according to semantic distances rather than treating all misclassifications equally. These losses are integrated into a sparse, background-free annotation training framework and evaluated on two tasks: fully supervised whole-brain parcellation from head MRI and sparsely annotated neurosurgical hyperspectral imaging for scene understanding. The abstract reports consistent improvements over task-specific baselines, with the strongest support for the Wasserstein-based compound loss in the first task and hierarchy-weighted top-level supervision in the second.
Significance. If the empirical gains prove robust, the work offers a practical way to inject label semantics into segmentation training for rich medical label spaces, which could improve utility for pre-operative planning and intra-operative guidance. The combination with sparse-annotation methods broadens applicability. The paper supplies reproducible experimental protocols on two distinct clinical tasks and reports gains for specific loss variants, which are positive attributes.
major comments (2)
- Abstract and experimental description: the central claim of consistent improvements attributable to semantic hierarchy is load-bearing, yet the manuscript provides no ablation on alternative hierarchies, no flat (non-hierarchical) baseline comparison, and no sensitivity checks on tree edge weights or scaling factors. Without these, it is unclear whether the reported gains stem from the semantic structure or from generic regularization effects.
- Methods and results sections: the hierarchy is treated as a fixed, correctly specified input whose distances match clinical importance, but no quantitative validation or clinical-expert agreement study is described. If the tree does not align with task-relevant semantics (e.g., functional vs. gross anatomical grouping), the Wasserstein and hierarchy-weighted losses lose their claimed advantage.
minor comments (2)
- Add error bars, statistical significance tests, and full ablation tables (including per-class metrics) to the experimental results so that robustness to post-hoc choices can be assessed.
- Clarify the precise mathematical definitions of the two proposed losses (including any weighting schemes or distance metrics on the tree) with explicit equations and pseudocode for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and describe the revisions we will make to improve the clarity and robustness of the claims.
read point-by-point responses
-
Referee: Abstract and experimental description: the central claim of consistent improvements attributable to semantic hierarchy is load-bearing, yet the manuscript provides no ablation on alternative hierarchies, no flat (non-hierarchical) baseline comparison, and no sensitivity checks on tree edge weights or scaling factors. Without these, it is unclear whether the reported gains stem from the semantic structure or from generic regularization effects.
Authors: We agree that the absence of these controls leaves the source of the gains open to interpretation. In the revised manuscript we will add (i) a flat baseline that replaces the tree-based losses with standard cross-entropy, (ii) a sensitivity analysis sweeping the edge-weight and scaling hyperparameters, and (iii) a short discussion of the clinical rationale for the chosen hierarchies together with a note that systematic exploration of alternative trees remains future work. These additions will directly test whether the observed improvements are attributable to the semantic structure. revision: yes
-
Referee: Methods and results sections: the hierarchy is treated as a fixed, correctly specified input whose distances match clinical importance, but no quantitative validation or clinical-expert agreement study is described. If the tree does not align with task-relevant semantics (e.g., functional vs. gross anatomical grouping), the Wasserstein and hierarchy-weighted losses lose their claimed advantage.
Authors: The label trees were constructed from established anatomical and functional parcellation schemes reported in the neuroimaging and neurosurgical literature, as stated in the Methods section. We acknowledge that a formal inter-expert agreement study would provide stronger quantitative support. Because such a study would require new expert consultations and data collection outside the present scope, we will instead add a dedicated limitations paragraph that (a) details the literature sources used to define the hierarchies, (b) discusses the risk of misalignment with alternative clinical groupings, and (c) qualifies the claims accordingly. This revision will make the dependence on hierarchy specification explicit without overstating the current evidence. revision: partial
Circularity Check
No significant circularity; empirical gains from proposed losses on pre-specified hierarchy
full rationale
The paper defines two new loss functions (Wasserstein-based and hierarchy-weighted) that operate on an externally provided label tree. These are incorporated into training and evaluated via experiments on whole-brain parcellation and hyperspectral imaging tasks, with reported improvements over task-specific baselines. No equation reduces a claimed prediction to a fitted parameter or input by construction. The hierarchy is treated as a fixed input rather than derived from the same data or equations. A citation to a prior sparse-annotation method exists but is not load-bearing for the central empirical claim and does not form a self-referential chain. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- tree edge weights or hierarchy scaling factors
axioms (1)
- domain assumption A pre-defined hierarchical organization of the label space exists and reflects clinically meaningful semantic relationships.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose two tree-based semantic loss functions which take advantage of a hierarchical organisation of the labels... Wasserstein distance-based segmentation loss that penalises mis-classifications based on the path length between the predicted and ground-truth labels in the tree
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
label hierarchy... derived from pre-existing guidelines... DKT protocol
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.