BioLip: Language-Generalizable Lip-Sync Deepfake Detection via Biomechanical Constraint Violation Modeling
Pith reviewed 2026-05-21 00:13 UTC · model grok-4.3
The pith
Lip motion jerk and acceleration statistics detect deepfakes without audio or pixels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
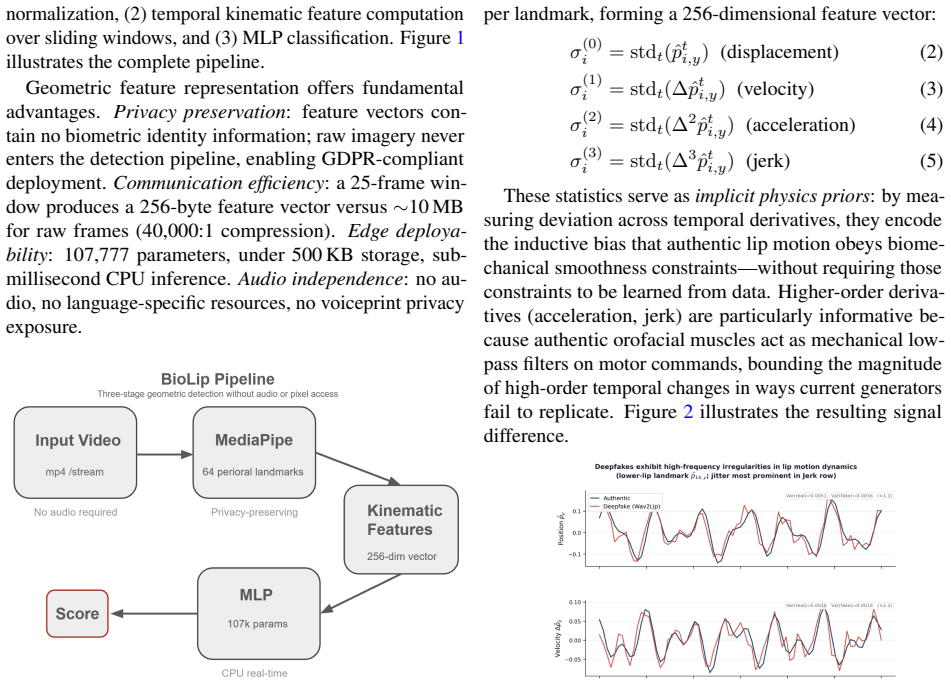
Real lip motion is constrained by tissue mechanics and neuromuscular bandwidth; current generators impose none of these constraints, producing trajectories with elevated variance in velocity, acceleration, and jerk that real speech does not exhibit. The method computes displacement, velocity, acceleration, and jerk statistics from 64 perioral landmarks over 25-frame windows and feeds them into a lightweight three-branch network using only landmark coordinates.
What carries the argument
Temporal lip jitter computed as displacement, velocity, acceleration, and jerk statistics from 64 perioral landmarks over 25-frame windows, classified by a three-branch network.
If this is right
- Detection works from landmark coordinates alone with no audio or pixel input required.
- Performance holds under language and generator distribution shifts.
- Only brief 25-frame segments supply the needed motion statistics.
- A lightweight three-branch network is sufficient for the classification task.
Where Pith is reading between the lines
- Generators that add biomechanical simulation would likely evade this detector and require new signals.
- The same variance-based approach could apply to other constrained facial or body motions in deepfakes.
- Combining the motion features with pixel or audio detectors might raise overall accuracy.
- Real-world tests on videos with natural head movement or variable frame rates would clarify practical limits.
Load-bearing premise
Current deepfake generators always produce higher variance in lip velocity, acceleration, and jerk than real speech, and these differences show up consistently in landmark statistics over short windows.
What would settle it
Create lip-sync videos using a generator that adds explicit limits on lip velocity and acceleration to match real biomechanical ranges, then measure whether detection accuracy falls near chance level.
Figures

read the original abstract
Existing lip-sync deepfake detectors rely on pixel artifacts or audio-visual correspondence, and both fail under generator or language shift because the features they learn are tied to the training distribution. We take a different approach. Authentic lip motion is constrained by tissue mechanics and neuromuscular bandwidth; current generators typically do not impose these constraints, producing trajectories with elevated variance in velocity, acceleration, and jerk that real speech does not exhibit. We exploit this signal, which we term temporal lip jitter, by computing kinematic statistics from 64 perioral landmarks over short sliding windows and feeding them into a lightweight three-branch network. The model uses only landmark coordinates: no pixels, no audio, and no voiceprint data. We train only on English data and test in a zero-shot setting on five unseen generators and seven languages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes BioLip, a lip-sync deepfake detector that exploits biomechanical constraints on real lip motion. Real trajectories exhibit limited variance in velocity, acceleration, and jerk due to tissue mechanics and neuromuscular bandwidth; current generators produce trajectories violating these constraints. The method extracts displacement/velocity/acceleration/jerk statistics from 64 perioral landmarks over 25-frame windows, feeds them to a lightweight three-branch network, and operates exclusively on landmark coordinates with no pixel or audio input, claiming improved language generalizability over artifact- or correspondence-based detectors.
Significance. If the central claim holds under rigorous controls, the work would be significant for shifting deepfake detection toward physically grounded, distribution-independent signals rather than learned correlations. It merits credit for the parameter-free kinematic formulation, the explicit modeling of falsifiable biomechanical predictions, and the minimal-input design that avoids voiceprint or pixel dependencies.
major comments (2)
- [Landmark extraction and feature computation sections] Landmark extraction and feature computation sections: The detection signal is constructed directly from higher-order derivative variances of 64 perioral landmarks. Landmark detectors are trained predominantly on real faces; when applied to deepfake frames they can exhibit domain-shift-induced jitter or inconsistent placement. This artifact would inflate precisely the velocity/acceleration/jerk statistics treated as evidence of missing biomechanical constraints, misattributing extraction error to generator physics. A control experiment quantifying landmark tracking error (e.g., reprojection consistency or manual annotation agreement) on matched real vs. generated sequences is required to establish that the observed variance differences originate from motion rather than detector domain shift.
- [Results and evaluation sections] Results and evaluation sections: The abstract asserts language-generalizability and superiority over pixel- and audio-visual baselines, yet the manuscript must supply cross-generator, cross-language tables with error bars, statistical significance tests, and ablation of the three-branch network. Without these, the claim that the kinematic features reliably separate real from generated motion cannot be assessed as load-bearing evidence.
minor comments (1)
- [Abstract] The abstract introduces the 25-frame window and 64-landmark count late; moving these specifics to the opening sentence would improve immediate clarity for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important aspects of validation for our biomechanical approach, and we address each point below with plans for revision.
read point-by-point responses
-
Referee: Landmark extraction and feature computation sections: The detection signal is constructed directly from higher-order derivative variances of 64 perioral landmarks. Landmark detectors are trained predominantly on real faces; when applied to deepfake frames they can exhibit domain-shift-induced jitter or inconsistent placement. This artifact would inflate precisely the velocity/acceleration/jerk statistics treated as evidence of missing biomechanical constraints, misattributing extraction error to generator physics. A control experiment quantifying landmark tracking error (e.g., reprojection consistency or manual annotation agreement) on matched real vs. generated sequences is required to establish that the observed variance differences originate from motion rather than detector domain shift.
Authors: We agree this is a substantive concern that must be ruled out. In the revised manuscript we will add the requested control experiment: we will report landmark reprojection consistency and inter-frame stability metrics on matched real/generated sequence pairs extracted with the identical detector. This will quantify any domain-shift contribution and confirm that the reported kinematic variance differences arise from motion properties. revision: yes
-
Referee: Results and evaluation sections: The abstract asserts language-generalizability and superiority over pixel- and audio-visual baselines, yet the manuscript must supply cross-generator, cross-language tables with error bars, statistical significance tests, and ablation of the three-branch network. Without these, the claim that the kinematic features reliably separate real from generated motion cannot be assessed as load-bearing evidence.
Authors: We concur that stronger quantitative support is needed. The revision will include expanded cross-generator and cross-language tables that report mean performance with standard-error bars across multiple runs, p-values from appropriate statistical tests, and a full ablation of the three-branch network demonstrating the incremental value of each kinematic statistic. revision: yes
Circularity Check
No significant circularity; derivation is self-contained from biomechanical premise to direct kinematic statistics
full rationale
The paper's core chain starts from the premise that real lip motion obeys tissue/neuromuscular constraints (producing lower variance in velocity/acceleration/jerk) while generators do not, then directly computes those exact statistics over 25-frame windows on 64 landmarks and feeds them to a classifier. No equation reduces the output statistic to a fitted parameter on the target data, no self-citation supplies a load-bearing uniqueness theorem, and the input quantities (landmark trajectories) are not defined in terms of the detection label. The method is therefore not tautological by construction; any performance gain would have to arise from the empirical distribution of the kinematic features rather than from re-labeling the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Real lip motion is constrained by tissue mechanics and neuromuscular bandwidth
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.