Selective Time Series Forecasting via Metalearning
Pith reviewed 2026-06-26 09:19 UTC · model grok-4.3
The pith
Metalearning on recent lags predicts the percentile rank of forecast errors, enabling selective rejection of hard samples that raises accuracy in both in-domain and transfer settings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
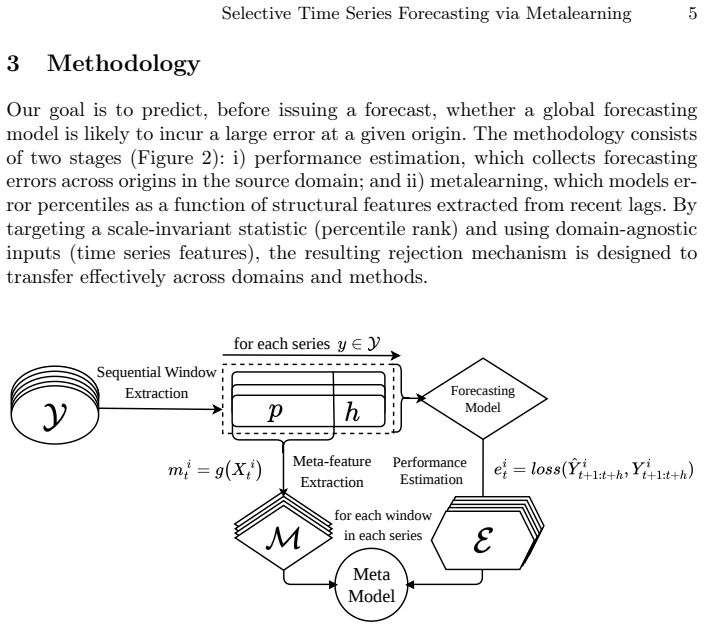
We propose a selective forecasting framework that addresses this limitation by modeling the empirical percentile of forecasting errors, that is, a scale-invariant statistic, based on structural characteristics extracted from recent lags via metalearning. By decoupling the rejection decision from the forecast itself and grounding it in domain-agnostic features, the framework enables effective abstention transfer across heterogeneous time series.
What carries the argument
The selective forecasting framework that models the empirical percentile of forecasting errors via metalearning on structural characteristics extracted from recent lags.
If this is right
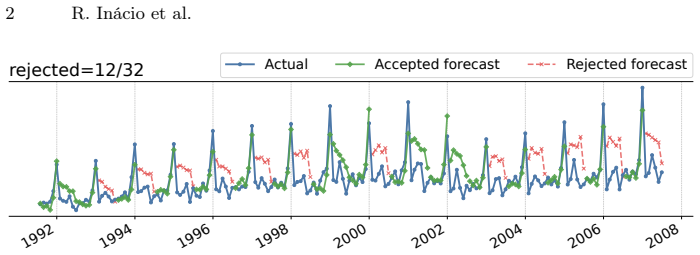
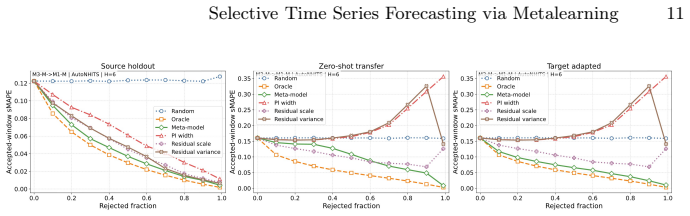
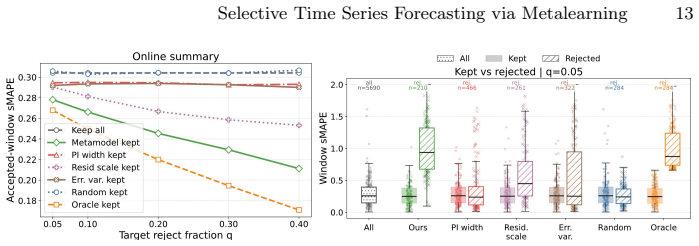
- Rejecting samples predicted as challenging consistently improves forecasting accuracy across coverage levels.
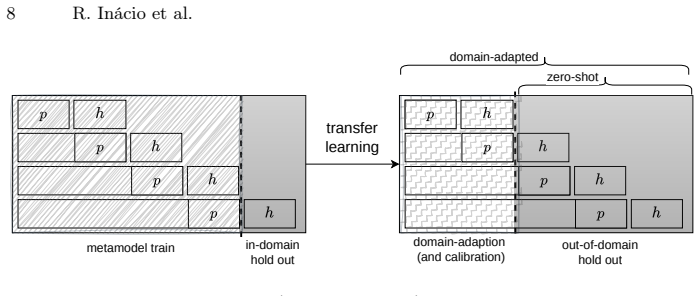
- The framework performs effectively in transfer learning settings across heterogeneous time series.
- Rejection decisions remain decoupled from the underlying forecast model.
- The scale-invariant error percentile provides a domain-agnostic alternative to proxies such as prediction-interval width.
Where Pith is reading between the lines
- The same lag-based metalearning signal could be tested for abstention in related sequential tasks such as anomaly detection or imputation.
- Integration with online updating schemes might allow the rejection model to adapt as new data streams arrive.
- Because the method is scale-invariant, it may extend naturally to multi-resolution or hierarchical forecasting problems.
Load-bearing premise
Structural characteristics extracted from recent lags can be used via metalearning to model the empirical percentile of forecasting errors in a scale-invariant and domain-agnostic manner that transfers across heterogeneous time series.
What would settle it
An experiment in which rejecting the samples flagged by the metalearning model produces no accuracy gain (or a loss) on a diverse collection of time series would falsify the central claim.
Figures
read the original abstract
Deep learning methods have achieved state-of-the-art in time series forecasting, yet their accuracy varies considerably across samples, as some instances remain inherently difficult to predict. Reject option mechanisms, which allow models to abstain from high-risk predictions, are well established in classification and regression but underexplored in forecasting. Existing abstention strategies typically rely on proxies, such as the width of the prediction interval or learned confidence scores derived from forecasts. However, these approaches are inherently tied to the training domain, limiting their ability to generalize. We propose a selective forecasting framework that addresses this limitation by modeling the empirical percentile of forecasting errors, that is, a scale-invariant statistic, based on structural characteristics extracted from recent lags via metalearning. By decoupling the rejection decision from the forecast itself and grounding it in domain-agnostic features, the framework enables effective abstention transfer across heterogeneous time series. Experiments in both in-domain and transfer learning settings show that rejecting samples predicted as challenging consistently improves forecasting accuracy across coverage levels.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a selective time series forecasting framework that models the empirical percentile of forecasting errors—a scale-invariant statistic—using metalearning on structural characteristics extracted from recent lags. This decouples the rejection decision from the base forecast itself, enabling domain-agnostic abstention that transfers across heterogeneous series. Experiments in both in-domain and transfer-learning settings are reported to show that rejecting samples predicted as challenging consistently improves forecasting accuracy across coverage levels.
Significance. If the empirical results hold under rigorous validation, the work would be significant for time-series forecasting by providing a transferable reject-option mechanism that avoids reliance on domain-tied proxies such as prediction-interval width. The emphasis on scale-invariant error percentiles and lag-derived structural features addresses a clear gap in existing abstention literature for forecasting.
minor comments (2)
- [Abstract] The abstract states that experiments demonstrate consistent accuracy gains but supplies no information on the number or identity of datasets, the base forecasters, the metalearning architecture, or the statistical tests employed; adding a concise experimental summary paragraph would strengthen the claim.
- Clarify how the structural characteristics are formally defined and extracted (e.g., which lag statistics or features) and whether any preprocessing steps are required for scale invariance.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision for our work on selective time series forecasting via metalearning. No major comments were raised in the report.
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical selective forecasting framework based on metalearning from lag-derived features to predict error percentiles. No equations, derivations, or self-citation chains are described that reduce the central claim (accuracy gains from abstention in in-domain and transfer settings) to a fitted quantity or input by construction. The approach decouples rejection from the base forecast using domain-agnostic structural characteristics, and the reported improvements rest on experimental results rather than any self-definitional or fitted-input reduction. This is the most common honest finding for papers whose contributions are primarily empirical.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Journal of Econometrics135(1-2), 31–53 (2006)
Aiolfi, M., Timmermann, A.: Persistence in forecasting performance and condi- tional combination strategies. Journal of Econometrics135(1-2), 31–53 (2006)
2006
-
[2]
Aksu, T., Woo, G., Liu, J., Liu, X., Liu, C., Savarese, S., Xiong, C., Sahoo, D.: GIFT-eval: A benchmark for general time series forecasting model evaluation (2024)
2024
-
[3]
International Journal of Forecasting27(3) (2011)
Athanasopoulos, G., Hyndman, R.J., Song, H., Wu, D.C.: The tourism forecasting competition. International Journal of Forecasting27(3) (2011)
2011
-
[4]
SoftwareX 11(2020) Selective Time Series Forecasting via Metalearning 15
Barandas, M., Folgado, D., Fernandes, L., Santos, S., Abreu, M., Bota, P., Liu, H., Schultz, T., Gamboa, H.: Tsfel: Time series feature extraction library. SoftwareX 11(2020) Selective Time Series Forecasting via Metalearning 15
2020
-
[5]
In: European big data management and analytics summer school, pp
Bontempi, G., Ben Taieb, S., Le Borgne, Y.A.: Machine learning strategies for time series forecasting. In: European big data management and analytics summer school, pp. 62–77. Springer (2012)
2012
-
[6]
Transactions on Machine Learning Research (2025)
Brusokas, J., Tirupathi, S., Zhang, D., Pedersen, T.B.: The time-energy model: Se- lective time-series forecasting using energy-based models. Transactions on Machine Learning Research (2025)
2025
-
[7]
Machine Learning113(7), 4523–4545 (2024)
Cerqueira, V., Moniz, N., Soares, C.: Vest: Automatic feature engineering for fore- casting. Machine Learning113(7), 4523–4545 (2024)
2024
-
[8]
In: Proceedings of the AAAI conference on artificial intelligence
Challu, C., Olivares, K.G., Oreshkin, B.N., Ramirez, F.G., Canseco, M.M., Dubrawski, A.: Nhits: Neural hierarchical interpolation for time series forecast- ing. In: Proceedings of the AAAI conference on artificial intelligence. vol. 37, pp. 6989–6997 (2023)
2023
-
[9]
IEEE Transactions on Information Theory16(1), 41–46 (1970)
Chow, C.: On optimum recognition error and reject tradeoff. IEEE Transactions on Information Theory16(1), 41–46 (1970)
1970
-
[10]
Journal of Machine Learning Research11(5) (2010)
El-Yaniv, R., et al.: On the foundations of noise-free selective classification. Journal of Machine Learning Research11(5) (2010)
2010
-
[11]
Feng, N., Lai, S., Zhou, X., Yang, J., Feng, K., Yin, Z., Zhou, F., Hu, Z., Yue, Y., Liang, Y., et al.: Towards reliable time series forecasting under future uncertainty: Ambiguity and novelty rejection mechanisms (2025)
2025
-
[12]
Ad- vances in neural information processing systems30(2017)
Geifman, Y., El-Yaniv, R.: Selective classification for deep neural networks. Ad- vances in neural information processing systems30(2017)
2017
-
[13]
Knowledge-Based Systems233, 107518 (2021)
Godahewa, R., Bandara, K., Webb, G.I., Smyl, S., Bergmeir, C.: Ensembles of localised models for time series forecasting. Knowledge-Based Systems233, 107518 (2021)
2021
-
[14]
hewamalage et al
Hewamalage, H., Ackermann, K., Bergmeir, C.: Forecast evaluation for data scien- tists: common pitfalls and best practices: H. hewamalage et al. Data Mining and Knowledge Discovery (2023)
2023
-
[15]
OTexts (2018)
Hyndman, R.J., Athanasopoulos, G.: Forecasting: principles and practice. OTexts (2018)
2018
-
[16]
international Journal of forecasting36(1), 167–177 (2020)
Januschowski, T., Gasthaus, J., Wang, Y., Salinas, D., Flunkert, V., Bohlke- Schneider, M., Callot, L.: Criteria for classifying forecasting methods. international Journal of forecasting36(1), 167–177 (2020)
2020
-
[17]
In: International conference on learning representations
Liu, Z., Wang, Y., Vaidya, S., Ruehle, F., Halverson, J., Soljacic, M., Hou, T., Tegmark, M.: Kan: Kolmogorov–arnold networks. In: International conference on learning representations. vol. 2025, pp. 70367–70413 (2025)
2025
-
[18]
Journal of forecasting (1982)
Makridakis, S., Andersen, A., Carbone, R., Fildes, R., Hibon, M., Lewandowski, R., Newton, J., Parzen, E., Winkler, R.: The accuracy of extrapolation (time series) methods: Results of a forecasting competition. Journal of forecasting (1982)
1982
-
[19]
International journal of forecasting16(4), 451–476 (2000)
Makridakis, S., Hibon, M.: The m3-competition: results, conclusions and implica- tions. International journal of forecasting16(4), 451–476 (2000)
2000
-
[20]
International Journal of forecasting (2018)
Makridakis, S., Spiliotis, E., Assimakopoulos, V.: The m4 competition: Results, findings, conclusion and way forward. International Journal of forecasting (2018)
2018
-
[21]
Advances in neural information pro- cessing systems31(2018)
Prokhorenkova, L., Gusev, G., Vorobev, A., Dorogush, A.V., Gulin, A.: Catboost: unbiased boosting with categorical features. Advances in neural information pro- cessing systems31(2018)
2018
-
[22]
Journal of chemical information and modeling60(6), 2697–2717 (2020)
Scalia, G., Grambow, C.A., Pernici, B., Li, Y.P., Green, W.H.: Evaluating scal- able uncertainty estimation methods for deep learning-based molecular property prediction. Journal of chemical information and modeling60(6), 2697–2717 (2020)
2020
-
[23]
Journal of machine learn- ing research9(3) (2008) 16 R
Shafer, G., Vovk, V.: A tutorial on conformal prediction. Journal of machine learn- ing research9(3) (2008) 16 R. Inácio et al
2008
-
[24]
PMLR (2022)
Shah, A., Bu, Y., Lee, J.K., Das, S., Panda, R., Sattigeri, P., Wornell, G.W.: Selectiveregressionunderfairnesscriteria.In:InternationalConferenceonMachine Learning. PMLR (2022)
2022
-
[25]
Advances in neural information processing systems34, 6216–6228 (2021)
Stankeviciute, K., M Alaa, A., Van der Schaar, M.: Conformal time-series forecast- ing. Advances in neural information processing systems34, 6216–6228 (2021)
2021
-
[26]
Machine Learning with Applications p
Szabadváry, J.H., Löfström, T., Johansson, U., Sönströd, C., Ahlberg, E., Carls- son, L.: Classification with reject option: Distribution-free error guarantees via conformal prediction. Machine Learning with Applications p. 100664 (2025)
2025
-
[27]
Springer (2005)
Vovk, V., Gammerman, A., Shafer, G.: Algorithmic learning in a random world. Springer (2005)
2005
-
[28]
Ad- vances in Neural Information Processing Systems25(2012)
Wiener, Y., El-Yaniv, R.: Pointwise tracking the optimal regression function. Ad- vances in Neural Information Processing Systems25(2012)
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.